TL;DR#
Current video object insertion methods struggle with preserving object details and accurately modeling motion, often leading to suboptimal results. Many existing approaches are two-stage processes, making them susceptible to errors. They also often lack the ability to inject the object’s identity throughout the video leading to identity and motion inconsistencies in the later frames.
VideoAnydoor overcomes these limitations by introducing an end-to-end framework. It uses an ID extractor to ensure consistent object identity, and a pixel warper that aligns pixel details with user-specified trajectories for precise motion control. This approach, combined with a novel training strategy that uses a mix of real and simulated video data, significantly improves the quality of video object insertion and enables users to precisely control the objects’ motion with trajectory lines or boxes.
Key Takeaways#
Why does it matter?#
This paper is important because it presents VideoAnydoor, a novel framework for high-fidelity video object insertion with precise motion control. This addresses a critical challenge in video editing, offering significant improvements over existing methods. Its end-to-end architecture and zero-shot capability are particularly noteworthy, expanding possibilities for various video manipulation tasks. The research opens new avenues for exploring improved video generation, editing, and synthesis techniques, benefiting researchers across computer vision and multimedia domains.
Visual Insights#
🔼 Figure 1 showcases VideoAnydoor’s video object insertion capabilities. The top row displays examples of object insertion where VideoAnydoor maintains fine details of the inserted objects while allowing users to precisely control object motion using bounding boxes or point trajectories. The bottom row compares VideoAnydoor’s results to those of other methods, highlighting its superior performance in preserving object fidelity and enabling smooth, controlled motion. Users can also iteratively add multiple objects or swap existing ones within the same video using VideoAnydoor.
read the caption
Figure 1: Demonstrations for video object insertion. VideoAnydoor preserves the fine-grained object details and enables users to control the motion with boxes or point trajectories. Based on the robust insertion, users could further add multiple objects iteratively or swap objects in the same video. Compared with the previous works, VideoAnydoor demonstrates significant superiority.
| Dataset | Type | # Samples | Mask Quality | Video Quality |
|---|---|---|---|---|
| YouTubeVOS [44] | Video | 4,453 | High | Low |
| YouTubeVIS [44] | Video | 2,883 | High | Low |
| UVO [7] | Video | 10,337 | High | Low |
| MOSE [6] | Video | 2,149 | High | High |
| VIPSeg [22] | Video | 3,110 | High | High |
| VSPW [23] | Video | 3,536 | High | High |
| SAM2 [28] | Video | 51,000 | High | High |
| Pexel | Video | 6,000 | Medium | High |
| MVImgNet [47] | Video | 219,188 | High | High |
| ViViD [8] | Video | 9,700 | High | High |
| CHDTF [53] | Video | 362 | High | High |
| CelebV-HQ [54] | Video | 35,666 | High | High |
| Pexel | Image | 95,000 | Medium | High |
🔼 This table presents the datasets used to train the VideoAnydoor model. It details the type of data (video or image), the number of samples available, and the quality of both the mask (object segmentation) and the video/image resolution. High-quality data indicates higher resolution, while low-quality signifies lower resolution. This information is crucial because the quality and diversity of the training data significantly affect the performance of the model.
read the caption
Table 1: Statistics of datasets used for training our VideoAnydoor. “quality” particularly refers to the image resolution.
In-depth insights#
ID Preservation#
ID preservation in video object insertion is a critical challenge, aiming to maintain the visual identity of the inserted object throughout the video. The paper tackles this by leveraging an ID extractor to capture a compact and discriminative representation of the object from its reference image. This representation, injected into the video generation process, ensures consistent visual fidelity. The key here is not simply transferring the object’s appearance but capturing its inherent identity. This approach addresses the problem of identity collapse in previous methods where the object’s visual characteristics might degrade over time or become inconsistent. A crucial component is the pixel warper, which assists in accurate placement and manipulation of the object while preserving its details. The effectiveness is enhanced by a reweight reconstruction loss, which prioritizes accuracy in object regions, and a training strategy combining both videos and static images, ensuring robustness and high-quality results. The successful ID preservation contributes significantly to the high-fidelity nature of the video insertion, resulting in realistic and visually compelling output. The research highlights that preserving fine-grained details and preventing identity degradation significantly impacts the overall quality and realism of the video edit. Quantitative and qualitative evaluations further confirm the approach’s superior performance in this aspect compared to existing methods.
Motion Control#
Precise motion control is a crucial aspect of high-fidelity video object insertion. The paper introduces a novel approach using a pixel warper that leverages keypoint trajectories to warp pixel details according to desired motion. This is not a simple two-stage process, but rather a more sophisticated method that addresses the challenges of aligning the motion trajectory of the inserted object while preserving its identity. The pixel warper is key to achieving fine-grained control, allowing for manipulation of the object’s movement with accuracy. The incorporation of a reweighted reconstruction loss further enhances this fine-grained control by weighting the contributions of regions inside bounding boxes and those along trajectories. This strategy emphasizes the importance of key regions for both identity and motion, thereby improving the overall quality of insertion. Further enhancing the effectiveness of the motion control is a training strategy that uses both videos and static images, which mitigates the challenges of limited high-quality video data. This combined approach, along with the innovative pixel warper, results in superior motion control compared to existing methods, demonstrating the significant advancements made in this research.
Pixel Warper#
The Pixel Warper module is a crucial component of the proposed VideoAnydoor framework, designed to address the challenge of achieving both high-fidelity detail preservation and precise motion control during video object insertion. It cleverly tackles the limitations of previous two-stage methods that often struggle with consistent object identity and motion across frames. The core innovation lies in its ability to directly model the fine-grained appearance details and motion trajectories simultaneously. Unlike methods relying solely on text or coarse trajectory guidance, the Pixel Warper utilizes a reference image with keypoints and their corresponding trajectories. This enables pixel-level warping based on the desired motion, resulting in accurate alignment of the inserted object with the video background while preserving fine details. The combination of pixel-level warping with diffusion-based in-painting significantly enhances the quality of the insertion compared to alternative methods. Furthermore, the proposed training strategies involving both real videos and synthetic image sequences, along with the reweighted reconstruction loss, all significantly contribute to the overall success of this novel method. The reweighting further emphasizes fidelity within the inserted object and its trajectory, preventing blurry or inconsistent results.
Training Strategy#
The authors implemented a novel training strategy to address the scarcity of high-quality video data for video object insertion. They cleverly combined real videos with synthetically generated video data from high-quality images, enhancing training diversity and mitigating the limitations imposed by real-world data. Specifically, they used techniques like random translation and gradual cropping of images to create sequences simulating video motion. This image-to-video augmentation strategy proved crucial in improving the appearance details and motion alignment in the generated videos. Furthermore, they introduced a reweighted reconstruction loss to preferentially focus on regions within bounding boxes and around trajectories, further optimizing the model’s ability to accurately preserve object identity and motion within the edited videos. This loss function ensures that the most critical aspects of the video are appropriately weighted during training, thus improving overall quality and consistency. The combination of data augmentation and a specialized loss function represents a significant contribution to training a robust and high-performing model for zero-shot video object insertion.
Future Directions#
Future research could explore enhancing VideoAnydoor’s robustness by addressing limitations like handling complex logos and improving performance with limited training data. Expanding the range of supported video editing tasks beyond those demonstrated is crucial, potentially integrating advanced features such as realistic object interactions and more sophisticated motion control algorithms. A deeper investigation into the trade-offs between computational cost and fidelity would be valuable, allowing for optimization based on application requirements. Further research could also focus on developing more intuitive and user-friendly interfaces for generating motion trajectories, making the system accessible to a broader user base. Finally, exploring the potential of applying VideoAnydoor to more diverse video editing applications, such as high-resolution video manipulation and real-time video effects, would significantly broaden its impact. Addressing ethical considerations related to deepfake technology stemming from the potential for misuse would also be a vital step.
More visual insights#
More on figures

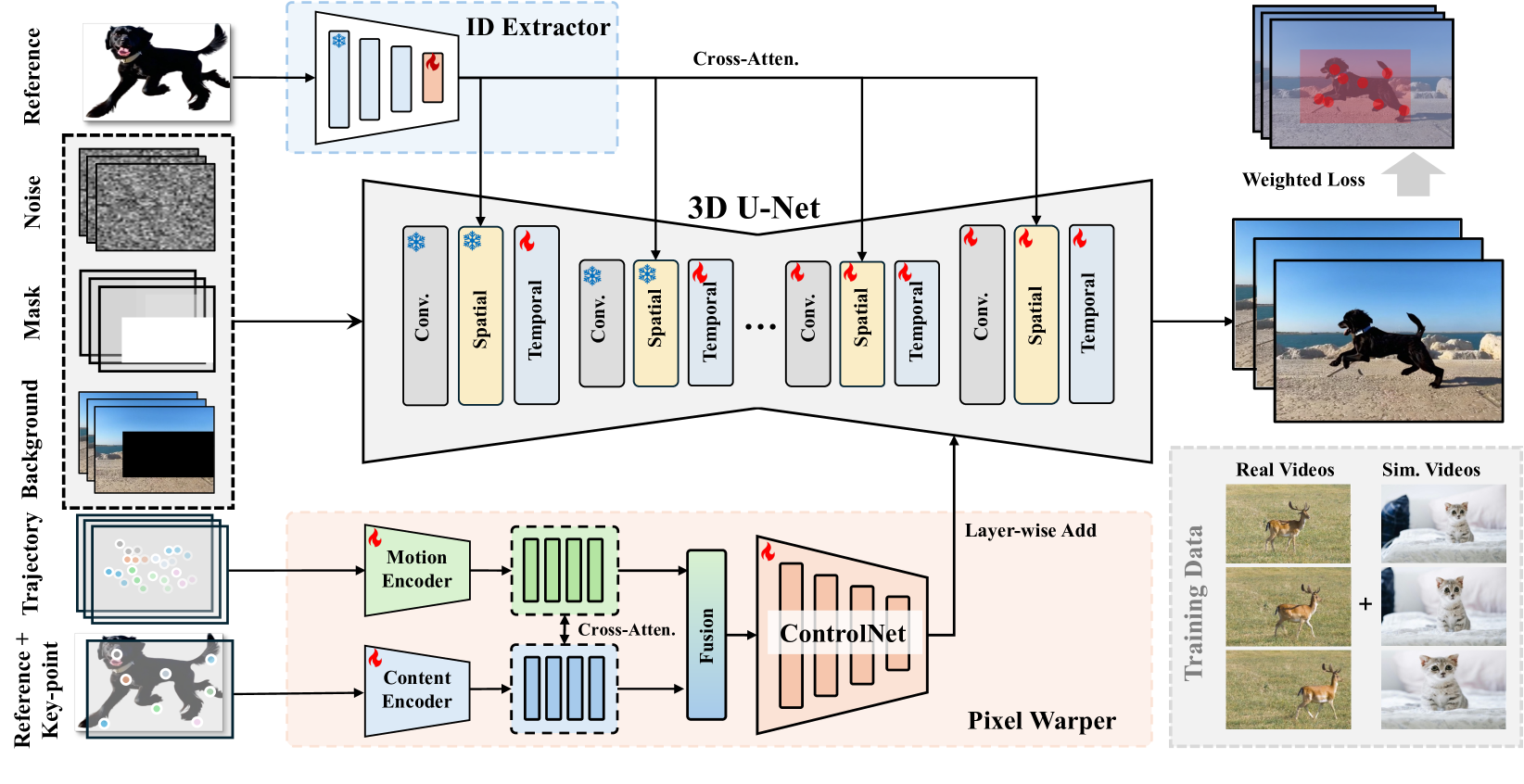
🔼 The figure illustrates the architecture of VideoAnydoor, a video object insertion framework. It begins by concatenating the original video, object masks, and the masked video, feeding this into a 3D U-Net. Simultaneously, a background-removed reference image is processed by an ID extractor, and the resulting features are incorporated into the 3D U-Net. A pixel warper module utilizes a reference image with keypoints and trajectory information to generate content and motion encodings. These encodings are then fused via cross-attention mechanisms and fed into a ControlNet for fine-grained control of motion and identity. The entire framework is trained using a reweighted reconstruction loss function and a mixed dataset of real and simulated video data to overcome data limitations.
read the caption
Figure 2: The pipelines of our VideoAnydoor. First, we input the concatenation of the original video, object masks, and masked video into the 3D U-Net. Meanwhile, the background-removed reference image is fed into the ID extractor, and the obtained features are injected into the 3D U-Net. In our pixel warper, the reference image marked with key points and the trajectories are utilized as inputs for the content and motion encoders. Then, the extracted embeddings are input into cross-attentions for further fusion. The fused results serve as the input of a ControlNet, which extracts multi-scale features for fine-grained injection of motion and identity. The framework is trained with reweight reconstruction losses. We use a blend of real videos and image-simulated videos for training to compensate for the data scarcity.

🔼 This figure illustrates the process of generating trajectories for training the VideoAnydoor model. The process begins by using a method (likely X-pose) to initially identify keypoints within the first frame of a video. If insufficient keypoints are detected, a grid-based approach is used as a fallback. Subsequently, a non-maximum suppression (NMS) step is applied to reduce redundancy by removing densely clustered points, retaining only those points demonstrating significant movement. The resulting, more sparsely distributed set of keypoints, each with associated motion trajectories, provides more robust and precise motion guidance for training the model.
read the caption
Figure 3: Pipeline of trajectory generation for training data. We first perform NMS to filter out densely-distributed points and then select points with larger motion. The retained ones can be sparsely distributed in each part of the target and contain more motion information, thus inducing more precise control.

🔼 Figure 4 presents a comparison of video editing results between VideoAnydoor and three other state-of-the-art methods (ReVideo, AnyV2V, and a baseline representing the original video). The comparison highlights VideoAnydoor’s superior performance in precisely controlling both the motion and content of inserted objects within videos. The figure visually demonstrates the differences in the quality and accuracy of object insertion and motion between the different methods, showing VideoAnydoor’s ability to maintain fine-grained details while achieving seamless integration of objects into the video sequences.
read the caption
Figure 4: Comparison results between VideoAnydoor and existing state-of-the-art video editing works. Our VideoAnydoor can achieve superior performance on precise control of both motion and content.

🔼 Figure 5 showcases VideoAnydoor’s capability for precise motion control. The examples demonstrate that by providing reference images with marked keypoints and their corresponding trajectories, VideoAnydoor accurately inserts objects into videos while perfectly matching the specified movements. This highlights the system’s ability to handle fine-grained motion control and achieve seamless integration of objects into dynamic video scenes.
read the caption
Figure 5: Demonstrations for precise motion control. VideoAnydoor can achieve precise alignment with the given trajectories and objects when using a pair of reference images marked with key-points and corresponding trajectory maps as input.

🔼 Figure 6 showcases additional examples of VideoAnydoor’s capabilities. The examples highlight the model’s ability to maintain fine details, such as logos on a car, while simultaneously achieving smooth and accurate motion control, as demonstrated by the fluid movement of a cat’s tail. This is achieved using the pixel warper component of the VideoAnydoor framework.
read the caption
Figure 6: More visual examples of VideoAnydoor. It preserves fine-grained details (e.g., logos on the car) and achieves smooth motion control (e.g., the tail of the cat) with our pixel warper.

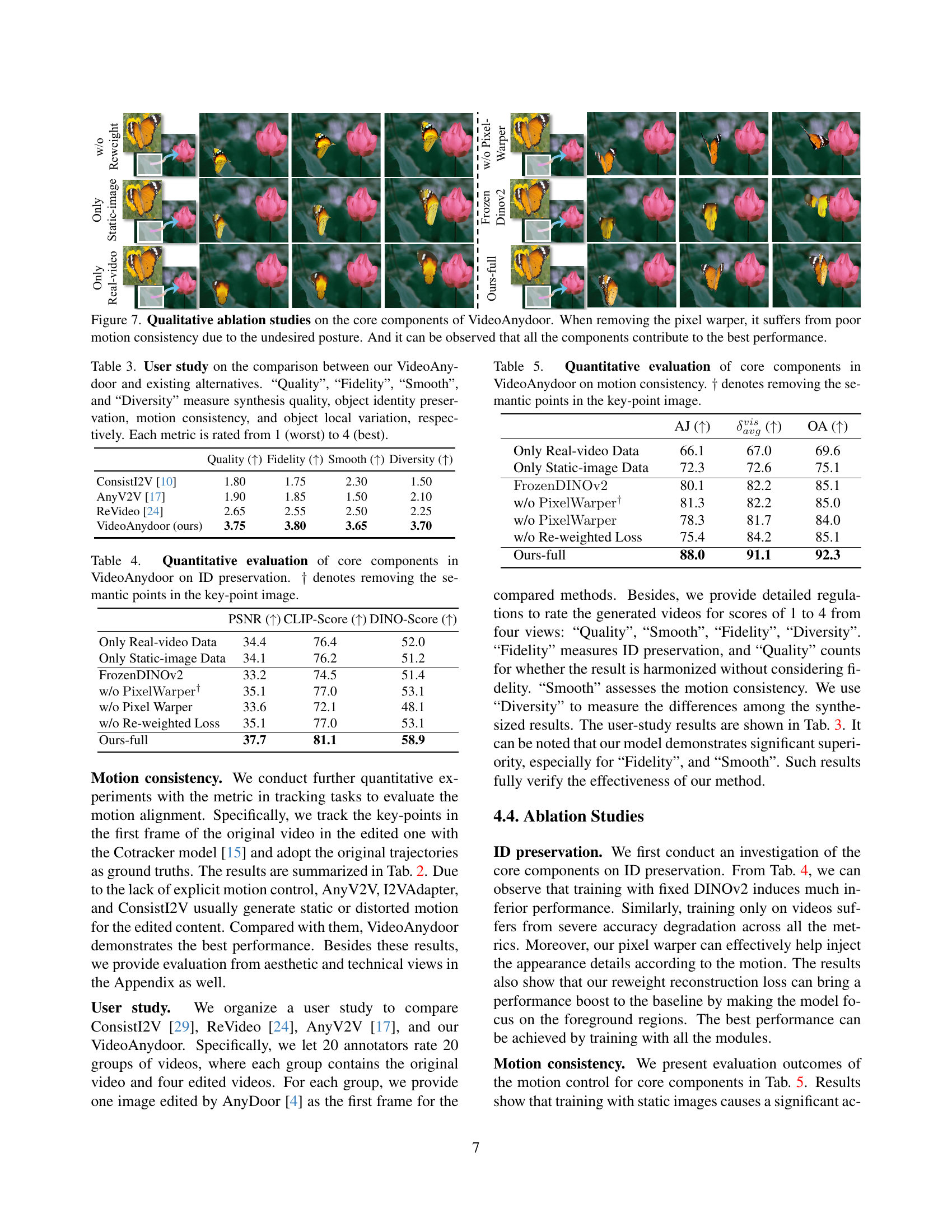
🔼 Figure 7 presents a qualitative ablation study on the core components of the VideoAnydoor model. The figure shows several variations of the model, each with one or more components removed (e.g., removing the pixel warper, removing the re-weighted loss, etc.). By comparing the results of these variations to the full model, the figure demonstrates the contribution of each component to the overall performance of the model. Specifically, it highlights that removing the pixel warper leads to poor motion consistency due to the resulting undesired object postures. The experiment clearly shows that the combined effect of all components leads to superior performance, showcasing the synergistic relationship between different parts of the VideoAnydoor framework.
read the caption
Figure 7: Qualitative ablation studies on the core components of VideoAnydoor. When removing the pixel warper, it suffers from poor motion consistency due to the undesired posture. And it can be observed that all the components contribute to the best performance.
More on tables
| Method | PSNR ( ) ) | CLIP-Score () | DINO-Score () | AJ () |  () () | OA () |
|---|---|---|---|---|---|---|
| ConsistI2V [29] | 25.1 | 64.7 | 40.6 | 49.3 | 51.1 | 57.2 |
| I2VAdapter [41] | 24.3 | 67.1 | 42.2 | 51.2 | 53.7 | 59.9 |
| AnyV2V [17] | 30.1 | 70.2 | 47.2 | 54.1 | 55.8 | 61.1 |
| ReVideo [24] | 33.5 | 74.2 | 51.7 | 79.2 | 81.4 | 83.2 |
| VideoAnydoor (ours) | 37.7 | 81.2 | 58.9 | 88.0 | 91.1 | 92.3 |
🔼 This table presents a quantitative comparison of VideoAnydoor against several other video editing methods. Six automatic metrics evaluate both the content and motion quality of the video edits. The metrics show that VideoAnydoor significantly outperforms the other methods in all aspects of video editing.
read the caption
Table 2: Quantitative comparison between our VideoAnydoor and other related work. Six automatic metrics are employed for the performance evaluation of both content and motion. VideoAnydoor outperforms these methods across all the metrics.
| Method | Quality (↑) | Fidelity (↑) | Smooth (↑) | Diversity (↑) |
|---|---|---|---|---|
| ConsistI2V [10] | 1.80 | 1.75 | 2.30 | 1.50 |
| AnyV2V [17] | 1.90 | 1.85 | 1.50 | 2.10 |
| ReVideo [24] | 2.65 | 2.55 | 2.50 | 2.25 |
| VideoAnydoor (ours) | 3.75 | 3.80 | 3.65 | 3.70 |
🔼 This table presents the results of a user study comparing VideoAnydoor to other video editing methods. Four aspects of video quality were rated on a scale of 1 to 4 (1 being worst, 4 being best): Quality (overall synthesis quality), Fidelity (how well the object’s identity was preserved), Smoothness (motion consistency), and Diversity (variation in the object’s appearance). The comparison helps illustrate VideoAnydoor’s strengths in these areas.
read the caption
Table 3: User study on the comparison between our VideoAnydoor and existing alternatives. “Quality”, “Fidelity”, “Smooth”, and “Diversity” measure synthesis quality, object identity preservation, motion consistency, and object local variation, respectively. Each metric is rated from 1 (worst) to 4 (best).
| Method | PSNR () | CLIP-Score () | DINO-Score () |
|---|---|---|---|
| Only Real-video Data | 34.4 | 76.4 | 52.0 |
| Only Static-image Data | 34.1 | 76.2 | 51.2 |
| FrozenDINOv2 | 33.2 | 74.5 | 51.4 |
| w/o | 35.1 | 77.0 | 53.1 |
| w/o Pixel Warper | 33.6 | 72.1 | 48.1 |
| w/o Re-weighted Loss | 35.1 | 77.0 | 53.1 |
| Ours-full | 37.7 | 81.1 | 58.9 |
🔼 Table 4 presents a quantitative analysis of VideoAnydoor’s core components’ impact on identity preservation. The metrics used are PSNR (Peak Signal-to-Noise Ratio), CLIP-Score (a measure of visual similarity using CLIP embeddings), and DINO-Score (another visual similarity metric based on DINOv2). The table compares the full VideoAnydoor model’s performance to several ablation studies. These studies examine the effects of removing key components, such as using only real video data during training, using only static image data, excluding the pixel warper module, and removing the reweighted loss function. The ‘+ denotes an ablation study where semantic points are removed from the keypoint image. This allows for a clear understanding of each component’s individual contribution to maintaining identity in the generated videos.
read the caption
Table 4: Quantitative evaluation of core components in VideoAnydoor on ID preservation. ††\dagger† denotes removing the semantic points in the key-point image.
| Method | AJ () | () | OA () |
|---|---|---|---|
| Only Real-video Data | 66.1 | 67.0 | 69.6 |
| Only Static-image Data | 72.3 | 72.6 | 75.1 |
| FrozenDINOv2 | 80.1 | 82.2 | 85.1 |
| w/o | 81.3 | 82.2 | 85.0 |
| w/o | 78.3 | 81.7 | 84.0 |
| w/o Re-weighted Loss | 75.4 | 84.2 | 85.1 |
| Ours-full | 88.0 | 91.1 | 92.3 |
🔼 This table presents a quantitative analysis of VideoAnydoor’s core components’ impact on motion consistency. It compares the performance of the full model against versions where key components are removed or modified. Specifically, it shows how metrics such as Average Jaccard (AJ), Structural Similarity Index (SSIM), and Overall Accuracy (OA) change when elements like the pixel warper or the re-weighted loss are excluded. The impact of training only on real videos versus a combination of real and static images is also examined. The symbol † indicates the removal of semantic points from the keypoint image. The results illustrate the contribution of each component in achieving high motion consistency in video object insertion.
read the caption
Table 5: Quantitative evaluation of core components in VideoAnydoor on motion consistency. ††\dagger† denotes removing the semantic points in the key-point image.
| Method | AJ () | () | OA () |
|---|---|---|---|
| Random X-Pose points | 80.4 | 82.2 | 82.8 |
| Grid points | 82.6 | 83.7 | 85.2 |
| w/o NMS | 82.3 | 83.1 | 84.6 |
| Tight box | 83.2 | 85.4 | 86.1 |
| Ours-full | 88.0 | 91.1 | 92.3 |
🔼 This table presents a detailed quantitative analysis of the pixel warper component within the VideoAnydoor model, focusing specifically on its impact on motion consistency during video generation. The results are based on several different training configurations. The key metrics evaluated are the average Jaccard index (AJ), the average Structural Similarity Index (SSIM), and the overall accuracy (OA), all commonly used to measure video quality and motion fidelity. The different training conditions assessed include: using randomly sampled X-Pose points for motion trajectory generation, using points on a grid, training without non-maximum suppression (NMS) of densely clustered points, and training with tightly-surrounded bounding boxes around objects. The ‘Ours-full’ row indicates the performance with the full, optimized VideoAnydoor setup. The analysis helps to determine the relative effectiveness of various training and keypoint selection techniques in achieving optimal motion consistency in the video object insertion task.
read the caption
Table 6: Detailed quantitative evaluation of the pixel warper in VideoAnydoor on motion consistency. “Tight box” denotes training with tightly-surrounded boxes.
Full paper#