↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many AI systems aim to automate scientific discovery, but lack rigorous benchmarks. This paper introduces BoxingGym, a benchmark with 10 environments to evaluate AI agents’ experimental design and model discovery capabilities. Each environment is a generative model, allowing for interactive experiments and quantitative evaluation using expected information gain (EIG) and communication-based metrics.
The study uses BoxingGym to evaluate two baseline agents: a language-based agent and one augmented with statistical models. Results show current LLMs like GPT-4 struggle with both experimental design and model discovery, suggesting that augmenting LLMs with explicit statistical models doesn’t reliably improve results. This work sets a new standard for evaluating AI for science and creates a benchmark that will drive future research, highlighting areas where improvements are needed to achieve true AI-driven scientific discovery.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel benchmark, BoxingGym, for evaluating AI agents’ abilities in automated experimental design and model discovery. This addresses a critical gap in current AI research by providing a standardized and quantitative evaluation framework. The findings highlight the challenges faced by current LLMs in these tasks, opening up new research directions and paving the way for more advanced AI systems capable of true scientific discovery. Its focus on integrating experimental design and model building will inspire work on more robust and effective AI for scientific research.
Visual Insights#

🔼 BoxingGym is a framework designed to evaluate AI agents’ capabilities in experimental design and model discovery. The figure shows the iterative process: 1) a user defines a goal; 2) the AI agent (scientist) formulates a theory; 3) the theory guides experiments in a simulated world, yielding new data; 4) the scientist analyzes data (new and old) to refine the theory; 5) the scientist explains the findings to a novice agent; 6) both agents’ performance is evaluated based on how well they achieve the initial goal (cast as a prediction problem).
read the caption
Figure 1: Overview of BoxingGym. The BoxingGym Framework is designed to holistically evaluate experimental design and model discovery capabilities in the spirit of George Box [6]. 1) The process starts with a user defining a goal for the scientist agent. 2) The scientist formulates a theory. 3) This theory guides the experimental design, where the scientist interacts with a simulated world to gather new data. 4) The scientist then analyzes the new and old data to propose and refine theories. This iterative process continues for several iterations. 5) The scientist is then asked to explain the findings to a novice. 6) We evaluate the novice and the scientist by casting the goal as a prediction problem.
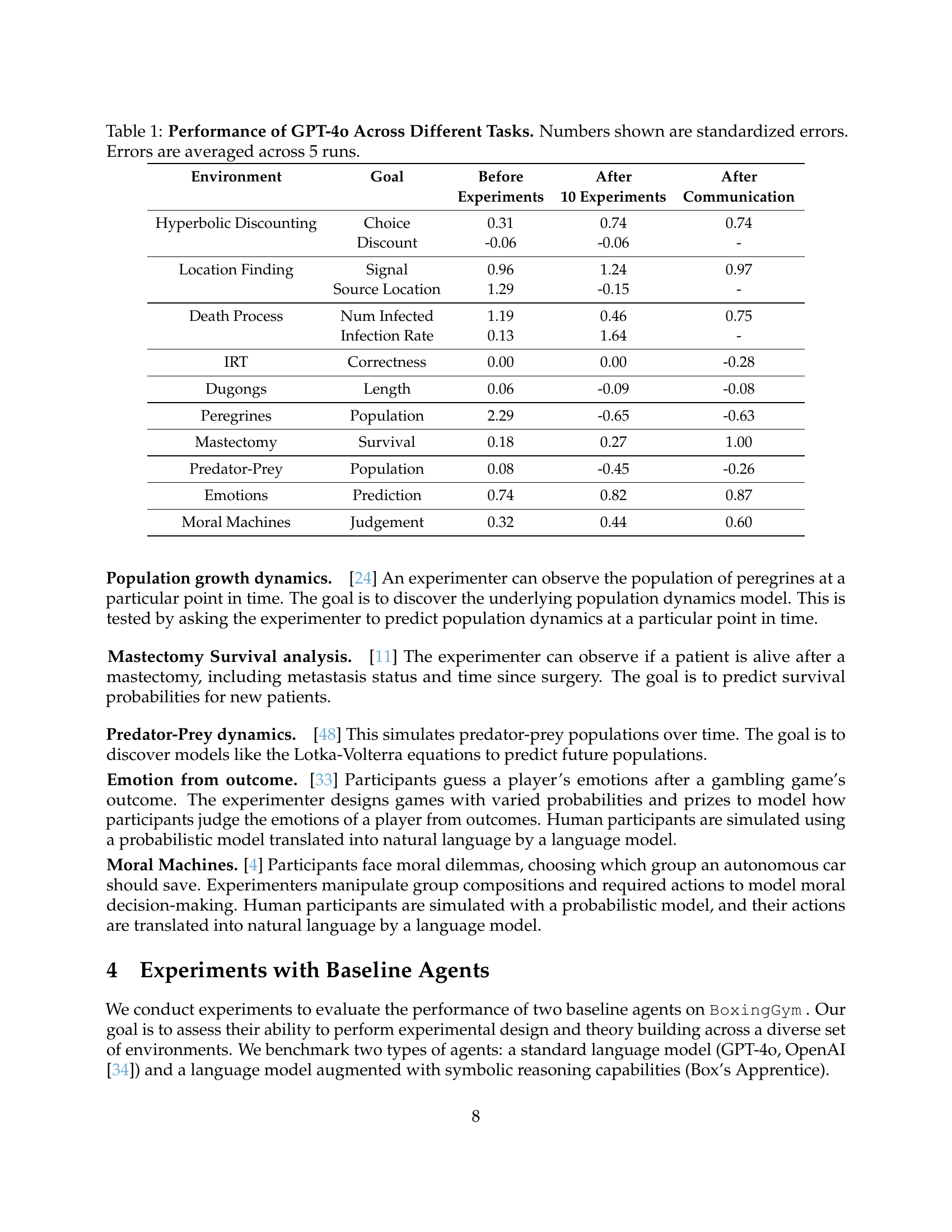
| Environment | Goal | Before | After | After |
|---|---|---|---|---|
| Experiments | 10 Experiments | Communication | ||
| Hyperbolic Discounting | Choice | 0.31 | 0.74 | 0.74 |
| Discount | -0.06 | -0.06 | - | |
| Location Finding | Signal | 0.96 | 1.24 | 0.97 |
| Source Location | 1.29 | -0.15 | - | |
| Death Process | Num Infected | 1.19 | 0.46 | 0.75 |
| Infection Rate | 0.13 | 1.64 | - | |
| IRT | Correctness | 0.00 | 0.00 | -0.28 |
| Dugongs | Length | 0.06 | -0.09 | -0.08 |
| Peregrines | Population | 2.29 | -0.65 | -0.63 |
| Mastectomy | Survival | 0.18 | 0.27 | 1.00 |
| Predator-Prey | Population | 0.08 | -0.45 | -0.26 |
| Emotions | Prediction | 0.74 | 0.82 | 0.87 |
| Moral Machines | Judgement | 0.32 | 0.44 | 0.60 |
🔼 This table presents the performance of GPT-40 on ten different scientific tasks, each designed to evaluate aspects of experimental design and model discovery. The results show the standardized error in predictions made by the model before any experimentation, after 10 experiments, and after an explanation of the experiments was provided to a ’novice’ agent. This allows for comparison of the model’s ability to improve its predictions both through data collection and through communicating its findings.
read the caption
Table 1: Performance of GPT-4o Across Different Tasks. Numbers shown are standardized errors. Errors are averaged across 5 runs.
In-depth insights#
Automated Science#
The concept of “Automated Science” represents a significant advancement in scientific research, leveraging the power of artificial intelligence and machine learning to automate various stages of the scientific method. This includes automating hypothesis generation, experimental design, data collection, analysis, and model building. The use of large language models (LLMs) exhibits promise in automating the generation and refinement of scientific theories. However, challenges remain: bias in algorithms, the need for human oversight in interpreting findings, and handling stochasticity in scientific models. It is crucial to address issues of explainability and transparency to foster trust in results and avoid perpetuating existing biases. While the potential to accelerate discovery is immense, a nuanced approach is needed to ensure responsible and effective automation, integrating human judgment and intuition with computational power for a synergistic approach.
BoxingGym Benchmarks#
BoxingGym is a novel benchmark designed for evaluating AI agents’ capabilities in automated scientific discovery. It uniquely integrates experimental design and model discovery, moving beyond isolated evaluations of each aspect. The benchmark comprises ten environments, each modeled as a generative probabilistic model, enabling tractable and quantitative assessments. These environments are diverse, spanning various real-world scientific domains, ensuring that AI agents must adapt their approach and demonstrate flexibility in handling different representations of scientific theories. The evaluation process is rigorous, leveraging expected information gain (EIG) to assess experimental design and a communication-based metric to evaluate model discovery. This latter metric necessitates the generation of natural language explanations, emphasizing a critical aspect of scientific progress: effective communication of findings. The use of both standard metrics and the communication approach provides a holistic view of AI agent performance, helping to identify areas of strength and weakness in the overall scientific discovery pipeline. Finally, BoxingGym’s modular design allows for easy expansion and adaptability, making it a valuable tool for future research and development in AI-driven science.
LLM’s Struggle#
The heading “LLM’s Struggle” aptly captures the core finding of the research paper: Large Language Models (LLMs), despite their advancements in natural language processing and knowledge representation, face significant challenges in performing tasks requiring scientific reasoning and experimentation. The study highlights the LLM’s difficulty in both experimental design (strategically choosing informative experiments) and model discovery (proposing, refining, and explaining scientific models accurately). The limitations aren’t solely due to the lack of knowledge, but also stem from an apparent inability to integrate and reason effectively with data collected through active experimentation. The use of expected information gain (EIG) and communication-based evaluation further underscores the limitations, revealing significant discrepancies between LLM performance and ideal scientific approaches. This struggle underscores a crucial need for future research focusing on bridging the gap between LLM capabilities and the complexities of scientific inquiry, possibly through integration of explicit statistical models, improved explanation generation, and more effective strategies for knowledge representation and reasoning within dynamic experimental settings.
Communication Eval#
A communication-based evaluation approach assesses how effectively a model’s explanation of experimental findings enables a novice agent to make accurate predictions. This method is advantageous because it accommodates diverse forms of scientific theories, rather than relying on a specific representation. The evaluation involves a scientist agent interacting with an environment, generating an explanation based on their findings. A novice agent, without interacting with the environment, receives this explanation and attempts to predict outcomes. Successful explanations empower the novice agent to perform well. This method complements standard model evaluation metrics, creating a more holistic assessment of the model’s overall discovery and communication capabilities. This approach is especially valuable for benchmarking scientific agents and highlights the importance of clear and informative communication in scientific discovery.
Future Research#
Future research directions stemming from this work are manifold. Extending BoxingGym to encompass a broader range of scientific domains, beyond the current 10, is crucial for establishing its generalizability and robustness. This includes incorporating diverse fields such as biology, chemistry, and social sciences, thereby increasing the benchmark’s complexity and real-world relevance. Improving the agent evaluation metrics is another key direction. While information gain and communication-based metrics offer valuable insights, refining them to better capture nuanced aspects of scientific discovery (e.g., model parsimony, hypothesis generation) is essential. Exploring more sophisticated interfaces between agents and environments holds significant potential. This might involve enhancing the natural language interface, integrating visual data visualization, or incorporating symbolic reasoning capabilities to empower more effective knowledge representation and communication within the scientific discovery process. Finally, investigating the impact of resource constraints (time, cost) on agent performance would greatly enhance the benchmark’s practical applicability, making it more reflective of real-world scientific practice.
More visual insights#
More on figures
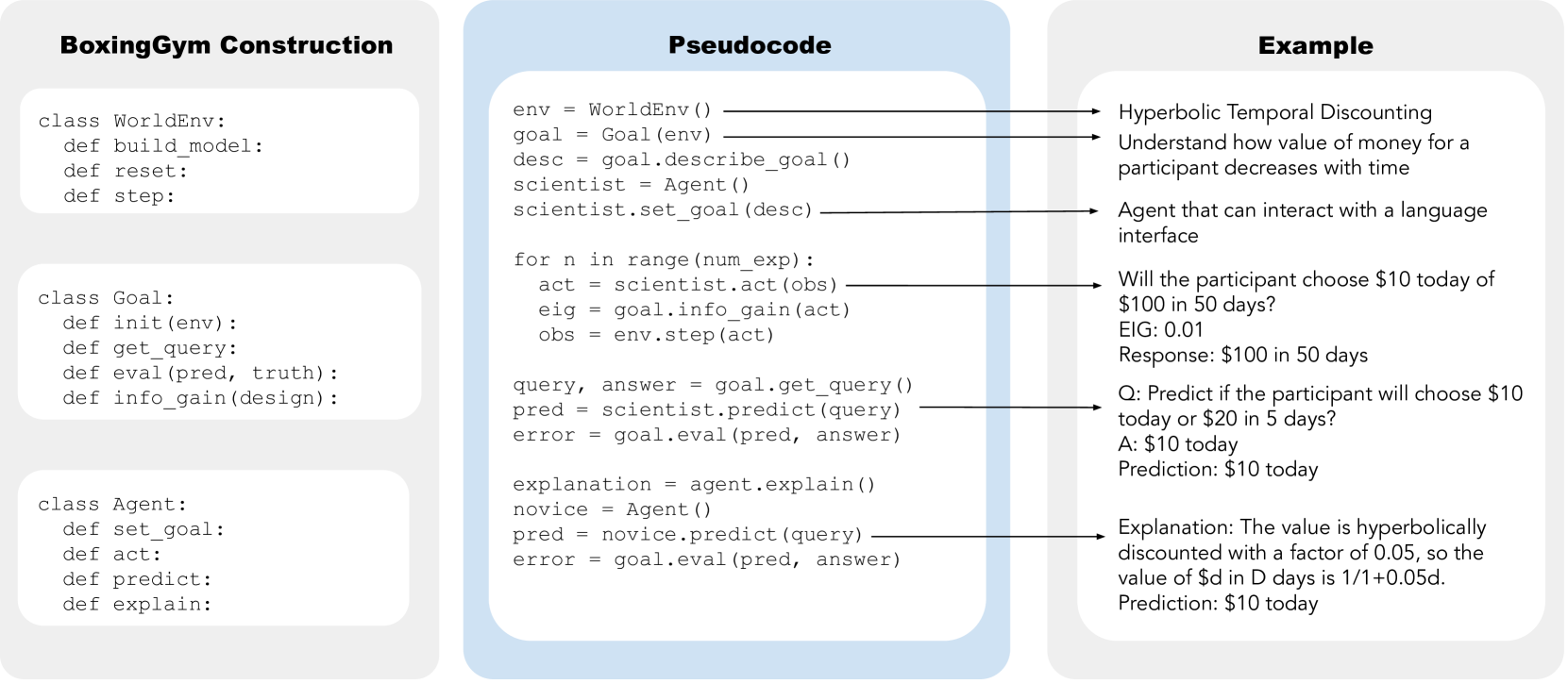
🔼 Figure 2 illustrates the modular design of BoxingGym using Python pseudocode. The left panel shows the class structure for defining environments (WorldEnv), goals (Goal), and agents (Agent). The classes encapsulate functions for building models, resetting states, taking steps in the environment, defining goals, evaluating goal achievement, calculating information gain, setting goals, acting in the environment, making predictions, and providing explanations. The center panel provides a pseudocode algorithm that details the workflow of BoxingGym. This involves an iterative process of goal setting, proposing a theory, designing experiments, collecting data, analyzing and refining the theory, explaining the results to a novice, and evaluating goal achievement. The right panel presents an example of the hyperbolic temporal discounting environment illustrating how an agent would interact with it and subsequently explain the obtained results to a novice.
read the caption
Figure 2: Python pseudocode examples. (left) BoxingGym is instantiated as modular classes and methods for the environment (WorldEnv), goals (Goal), and agents (Agent). (center) Pseudocode illustrating the workflow of setting goals, performing experiments, predicting outcomes, and providing explanations. (right) An example, hyperbolic temporal discounting, where the agent predicts a participant’s choice between immediate and delayed rewards and explains the concept to a novice.

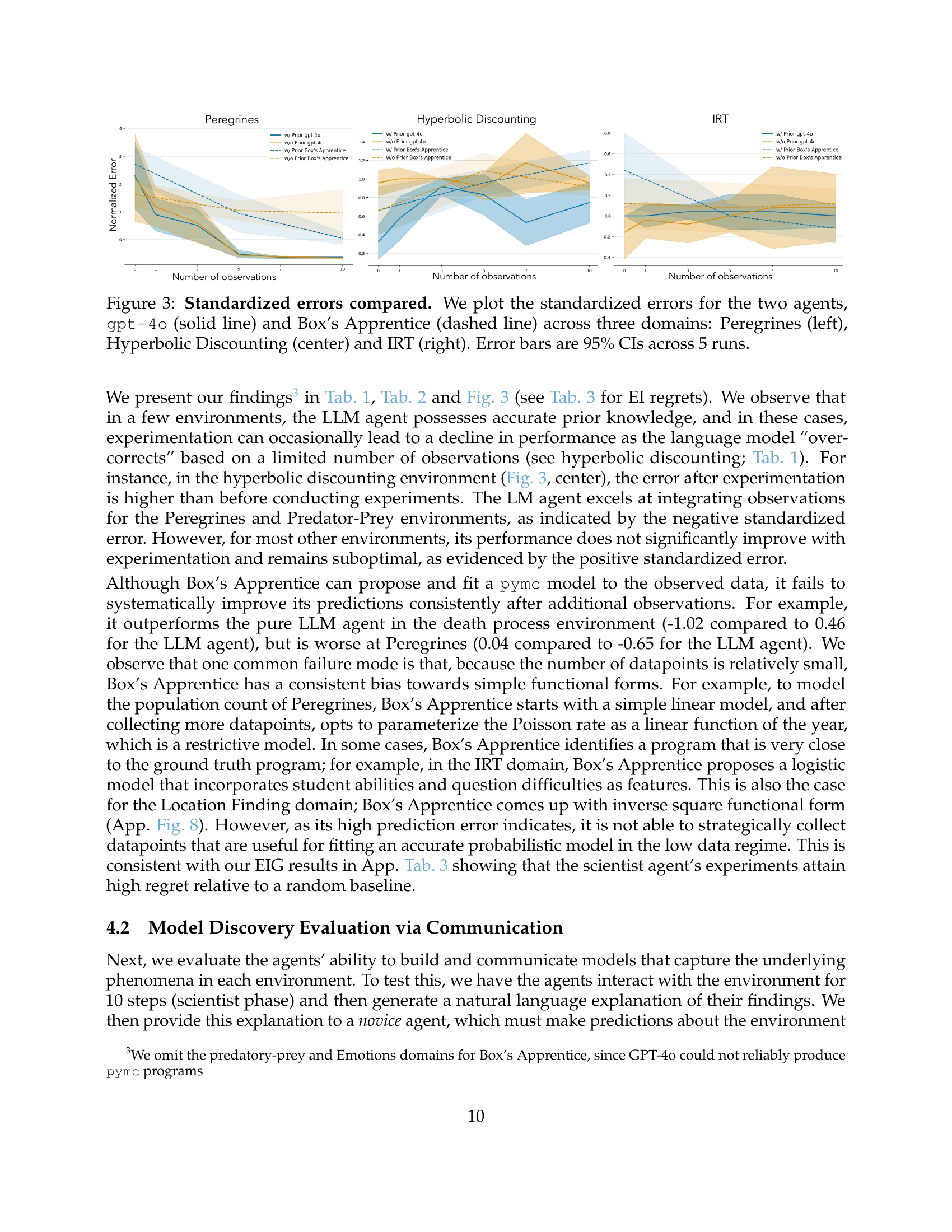
🔼 Figure 3 displays a comparison of standardized errors achieved by two different AI agents, GPT-40 and Box’s Apprentice, across three distinct experimental domains. The standardized errors, which measure the deviation of predictions from the actual values, are plotted against the number of observations made. For each domain, the performance of both agents is illustrated, with GPT-40’s results represented by a solid line and Box’s Apprentice’s by a dashed line. The chart provides a visual representation of how the accuracy of each agent changes as more data is collected. Error bars, indicating the 95% confidence intervals across 5 runs, are included to show the uncertainty associated with the measurements.
read the caption
Figure 3: Standardized errors compared. We plot the standardized errors for the two agents, gpt-4o (solid line) and Box’s Apprentice (dashed line) across three domains: Peregrines (left), Hyperbolic Discounting (center) and IRT (right). Error bars are 95% CIs across 5 runs.
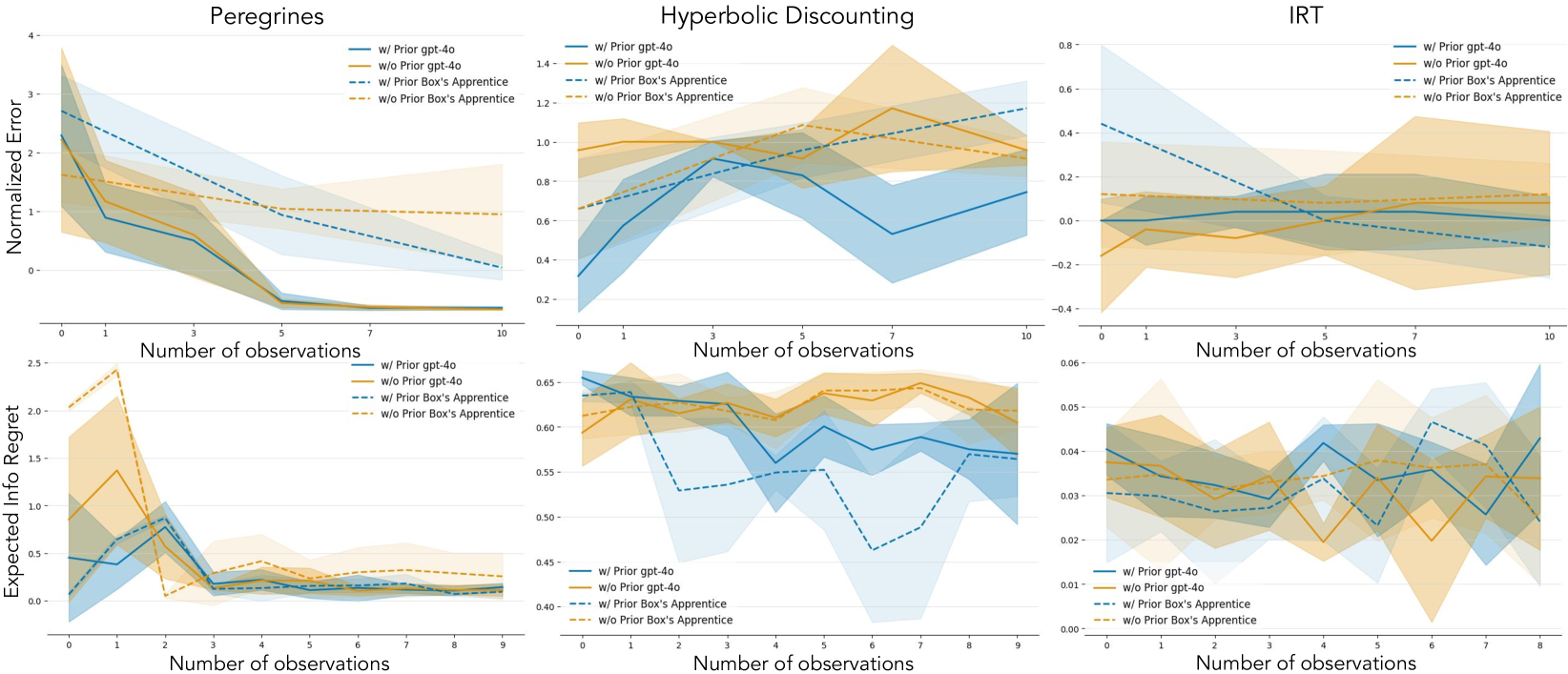
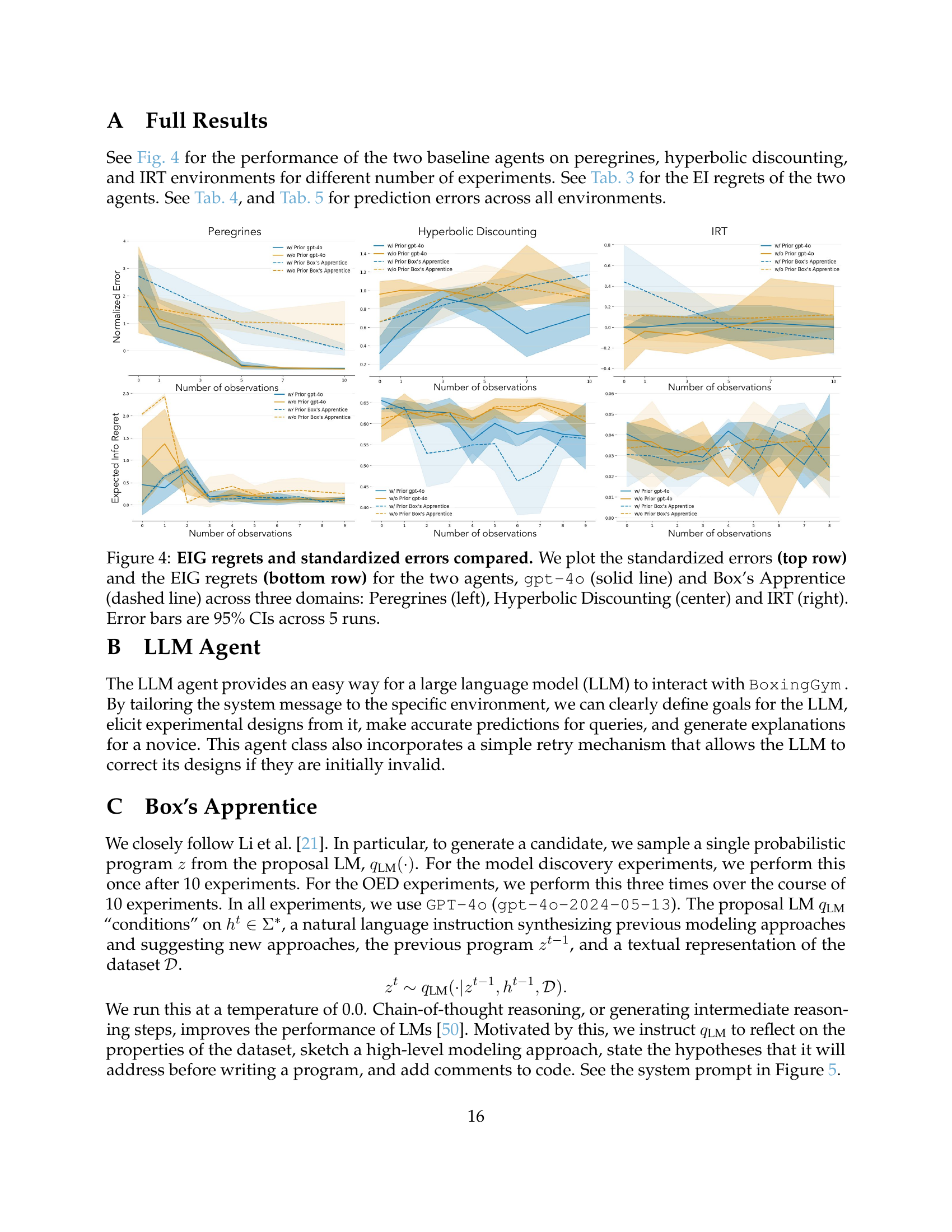
🔼 Figure 4 displays a comparison of standardized prediction errors and expected information gain (EIG) regrets for two different AI agents, GPT-4 and Box’s Apprentice, across three distinct experimental domains: the population dynamics of peregrine falcons, hyperbolic temporal discounting, and item response theory (IRT). The top row presents standardized errors, illustrating the accuracy of predictions made by each agent before and after conducting experiments. The bottom row shows the EIG regrets, which quantify how effectively each agent utilized the experiments to reduce uncertainty about the underlying models. The figure depicts the performance of both agents with and without prior knowledge about the domains. Error bars represent 95% confidence intervals across five independent runs for each agent and experiment.
read the caption
Figure 4: EIG regrets and standardized errors compared. We plot the standardized errors (top row) and the EIG regrets (bottom row) for the two agents, gpt-4o (solid line) and Box’s Apprentice (dashed line) across three domains: Peregrines (left), Hyperbolic Discounting (center) and IRT (right). Error bars are 95% CIs across 5 runs.
More on tables
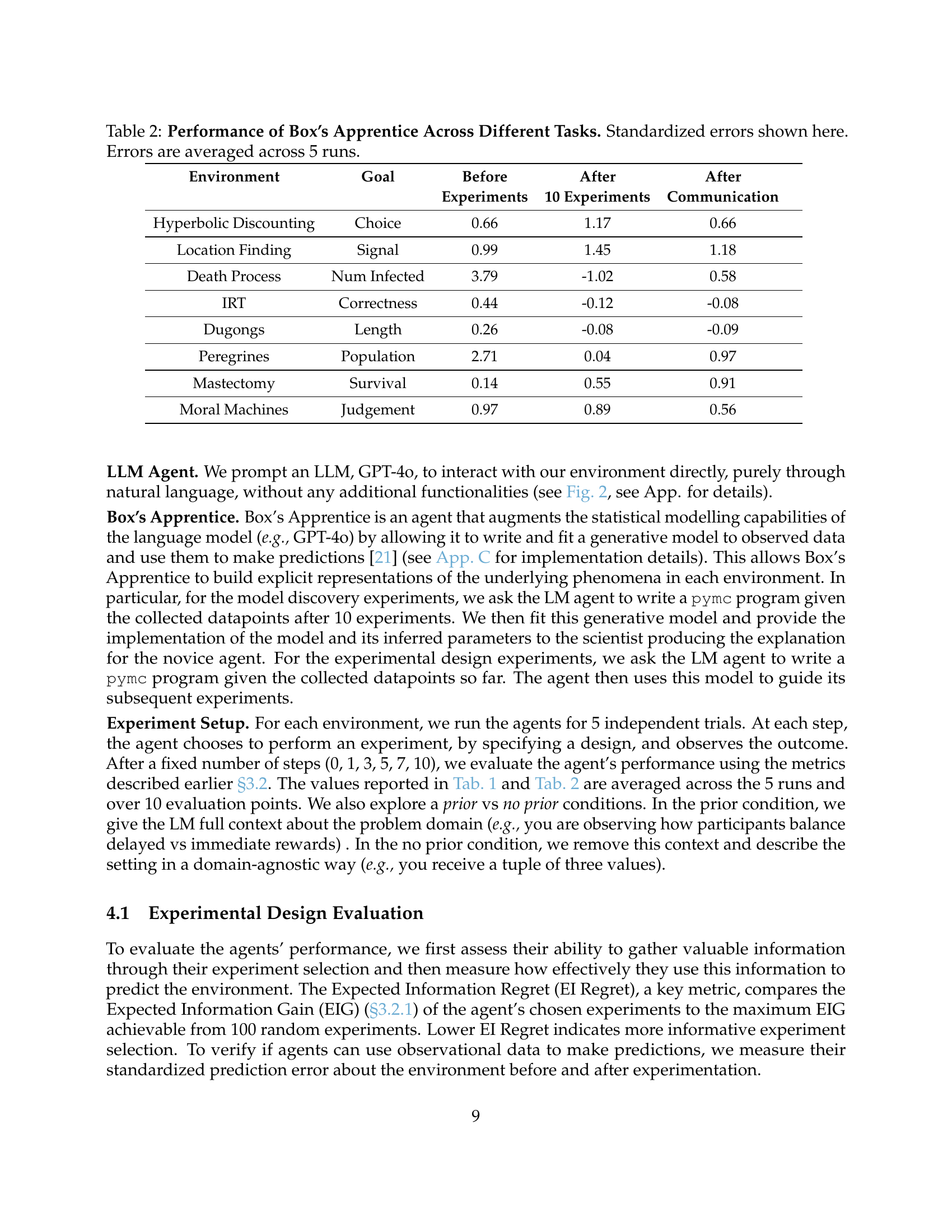
| Environment | Goal | Before | After | After |
|---|---|---|---|---|
| Experiments | 10 Experiments | Communication | ||
| Hyperbolic Discounting | Choice | 0.66 | 1.17 | 0.66 |
| Location Finding | Signal | 0.99 | 1.45 | 1.18 |
| Death Process | Num Infected | 3.79 | -1.02 | 0.58 |
| IRT | Correctness | 0.44 | -0.12 | -0.08 |
| Dugongs | Length | 0.26 | -0.08 | -0.09 |
| Peregrines | Population | 2.71 | 0.04 | 0.97 |
| Mastectomy | Survival | 0.14 | 0.55 | 0.91 |
| Moral Machines | Judgement | 0.97 | 0.89 | 0.56 |
🔼 This table presents the results of evaluating Box’s Apprentice, a language model augmented with symbolic reasoning capabilities, across various tasks within the BoxingGym benchmark. For each task (e.g., Hyperbolic Discounting, Location Finding), it shows the standardized error of the agent’s predictions before any experiments, after 10 experiments, and after an explanation provided to a novice agent. Standardized error is a measure of how well the model’s predictions match the actual outcomes, relative to a baseline model. Lower values indicate better performance. The errors reported are averages across five independent runs for each task, providing a measure of the reliability of the results.
read the caption
Table 2: Performance of Box’s Apprentice Across Different Tasks. Standardized errors shown here. Errors are averaged across 5 runs.
| Env | Goal | EI Regret (gpt-4o) | EI Regret (box’s apprentice) |
|---|---|---|---|
| Hyperbolic Discounting | Choice | 0.57 / 0.61 | 0.55 / 0.62 |
| Discount | 0.69 / - | - / - | |
| Location Finding | Signal | 15.3 / 11.8 | 12.6 / 15.3 |
| Source Location | 16.8 / - | - / - | |
| Death Process | Num Infected | 0.037 / 0.042 | 0.029 / 0.019 |
| Infection Rate | 0.108 / - | - / - | |
| IRT | Correctness | 0.035 / 0.031 | 0.031 / 0.033 |
| Dugongs | Length | 0.20 / 0.17 | 0.19 / 0.20 |
| Peregrines | Population | 0.26 / 0.38 | 0.25 / 0.66 |
| Mastectomy | Survival | 0.084 / 0.082 | 0.079 / 0.075 |
| Predator-Prey | Population | - / - | - / - |
| Emotions | Prediction | 0.538 / - | - / - |
| Moral Machines | Judgement | 0.046 / - | 0.045 / - |
🔼 This table presents the Expected Information Gain (EIG) regrets for two different agents, GPT-40 and Box’s Apprentice, across a variety of tasks. EIG regret quantifies how far from optimal the agents’ experiment choices were. Lower values indicate better choices. The table is broken down by task and shows the regret when providing the agents with prior information (context about the task) versus no prior information. The results are presented as a ratio; the first value is the regret with prior and the second value is with no prior.
read the caption
Table 3: EI Regrets for GPT-4o and Box’s Apprentice Across Different Tasks. EI regrets for prior and no prior conditinos are separated by ‘/’.
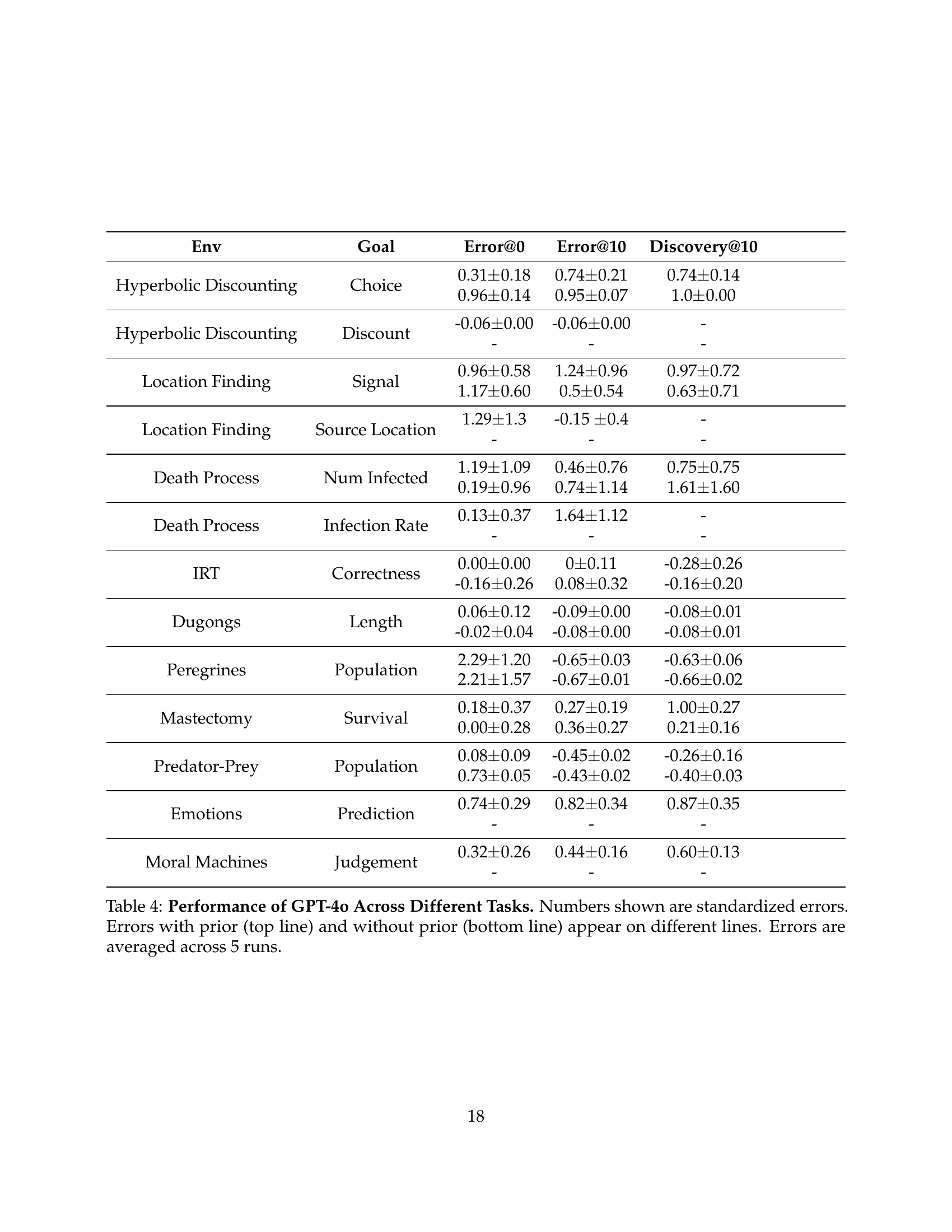
| Env | Goal | Error@0 | Error@10 | Discovery@10 |
|---|---|---|---|---|
| Hyperbolic Discounting | Choice | 0.31 ± 0.18 0.96 ± 0.14 | 0.74 ± 0.21 0.95 ± 0.07 | 0.74 ± 0.14 1.0 ± 0.00 |
| Hyperbolic Discounting | Discount | -0.06 ± 0.00 - | -0.06 ± 0.00 - | - |
| Location Finding | Signal | 0.96 ± 0.58 1.17 ± 0.60 | 1.24 ± 0.96 0.5 ± 0.54 | 0.97 ± 0.72 0.63 ± 0.71 |
| Location Finding | Source Location | 1.29 ± 1.3 - | -0.15 ± 0.4 - | - |
| Death Process | Num Infected | 1.19 ± 1.09 0.19 ± 0.96 | 0.46 ± 0.76 0.74 ± 1.14 | 0.75 ± 0.75 1.61 ± 1.60 |
| Death Process | Infection Rate | 0.13 ± 0.37 - | 1.64 ± 1.12 - | - |
| IRT | Correctness | 0.00 ± 0.00 -0.16 ± 0.26 | 0 ± 0.11 0.08 ± 0.32 | -0.28 ± 0.26 -0.16 ± 0.20 |
| Dugongs | Length | 0.06 ± 0.12 -0.02 ± 0.04 | -0.09 ± 0.00 -0.08 ± 0.00 | -0.08 ± 0.01 -0.08 ± 0.01 |
| Peregrines | Population | 2.29 ± 1.20 2.21 ± 1.57 | -0.65 ± 0.03 -0.67 ± 0.01 | -0.63 ± 0.06 -0.66 ± 0.02 |
| Mastectomy | Survival | 0.18 ± 0.37 0.00 ± 0.28 | 0.27 ± 0.19 0.36 ± 0.27 | 1.00 ± 0.27 0.21 ± 0.16 |
| Predator-Prey | Population | 0.08 ± 0.09 0.73 ± 0.05 | -0.45 ± 0.02 -0.43 ± 0.02 | -0.26 ± 0.16 -0.40 ± 0.03 |
| Emotions | Prediction | 0.74 ± 0.29 - | 0.82 ± 0.34 - | 0.87 ± 0.35 - |
| Moral Machines | Judgement | 0.32 ± 0.26 - | 0.44 ± 0.16 - | 0.60 ± 0.13 - |
🔼 This table presents the performance of GPT-40, a large language model, on ten different tasks from the BoxingGym benchmark. The tasks are drawn from various scientific domains and test both experimental design and model discovery. The table shows standardized errors in predictions for each task before experiments, after 10 experiments, and after providing a natural language explanation to a novice agent. The use of standardized errors allows for comparison across tasks. The table also shows the impact of providing prior information about each task on the model’s performance, with results for both ‘with prior’ and ‘without prior’ conditions.
read the caption
Table 4: Performance of GPT-4o Across Different Tasks. Numbers shown are standardized errors. Errors with prior (top line) and without prior (bottom line) appear on different lines. Errors are averaged across 5 runs.
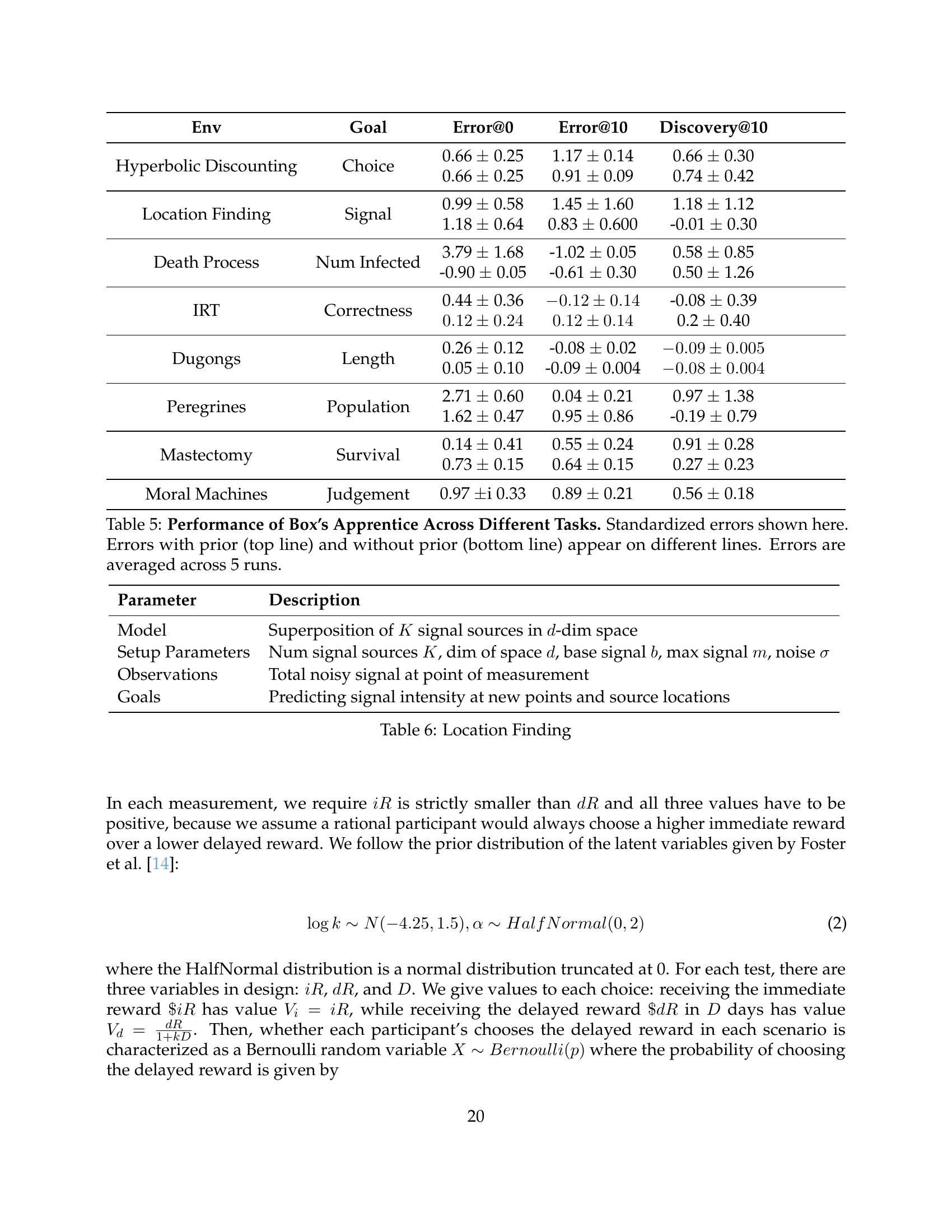
| Env | Goal | Error@0 | Error@10 | Discovery@10 |
|---|---|---|---|---|
| Hyperbolic Discounting | Choice | 0.66 ± 0.25 0.66 ± 0.25 | 1.17 ± 0.14 0.91 ± 0.09 | 0.66 ± 0.30 0.74 ± 0.42 |
| Location Finding | Signal | 0.99 ± 0.58 1.18 ± 0.64 | 1.45 ± 1.60 0.83 ± 0.600 | 1.18 ± 1.12 -0.01 ± 0.30 |
| Death Process | Num Infected | 3.79 ± 1.68 -0.90 ± 0.05 | -1.02 ± 0.05 -0.61 ± 0.30 | 0.58 ± 0.85 0.50 ± 1.26 |
| IRT | Correctness | 0.44 ± 0.36 0.12 ± 0.24 | -0.12 ± 0.14 0.12 ± 0.14 | -0.08 ± 0.39 0.2 ± 0.40 |
| Dugongs | Length | 0.26 ± 0.12 0.05 ± 0.10 | -0.08 ± 0.02 -0.09 ± 0.004 | -0.09 ± 0.005 -0.08 ± 0.004 |
| Peregrines | Population | 2.71 ± 0.60 1.62 ± 0.47 | 0.04 ± 0.21 0.95 ± 0.86 | 0.97 ± 1.38 -0.19 ± 0.79 |
| Mastectomy | Survival | 0.14 ± 0.41 0.73 ± 0.15 | 0.55 ± 0.24 0.64 ± 0.15 | 0.91 ± 0.28 0.27 ± 0.23 |
| Moral Machines | Judgement | 0.97 ±i 0.33 | 0.89 ± 0.21 | 0.56 ± 0.18 |
🔼 This table presents the performance of Box’s Apprentice, a language model augmented with symbolic reasoning capabilities, across ten different scientific tasks within the BoxingGym benchmark. The results show the standardized errors in predictions made by the model both before and after conducting experiments. The table is divided to show performance with and without prior knowledge about the task domain. Standardized errors, averaged over five runs, are provided for each task, reflecting the model’s prediction accuracy. The ‘before experiments’ column represents predictions made with only prior knowledge; the ‘after 10 experiments’ column shows performance after a set number of experimental interactions; and the ‘after communication’ column indicates the accuracy achieved when the model’s findings are conveyed to a novice agent through a natural language explanation. This comprehensive assessment allows for a detailed analysis of the model’s strengths and weaknesses in various scientific scenarios.
read the caption
Table 5: Performance of Box’s Apprentice Across Different Tasks. Standardized errors shown here. Errors with prior (top line) and without prior (bottom line) appear on different lines. Errors are averaged across 5 runs.
| Parameter | Description |
|---|---|
| Model | Superposition of K signal sources in d-dim space |
| Setup Parameters | Num signal sources K, dim of space d, base signal b, max signal m, noise σ |
| Observations | Total noisy signal at point of measurement |
| Goals | Predicting signal intensity at new points and source locations |
🔼 This table details the Location Finding environment, a sub-environment within the BoxingGym benchmark. It outlines the environment’s setup, parameters, observations, and goals. Specifically, it describes a scenario where hidden signal sources emit signals that are measured at various points. The goal is to either predict the signal at any point or locate the sources. The table’s rows describe the parameters such as the number of signal sources, dimensions of the space, base signal strength, maximum signal, and signal noise, the observations (noisy superimposed signals), and the goals (predicting the signal intensity or finding source locations).
read the caption
Table 6: Location Finding
| Parameter | Description |
|---|---|
| Model | Human decision-making in temporal discounting of rewards |
| Setup Parameters | Params of the discount function (ϵ, mean and std for log k, scale for α) |
| Observations | Choice between immediate iR and delayed reward dR at delay D |
| Goals | Predicting choices and the value of the discount factor |
🔼 This table describes the experimental setup and parameters for the Hyperbolic Discounting environment within the BoxingGym framework. It details the model used (human decision-making in temporal discounting of rewards), the parameters of that model (discount function parameters), the observations collected (choices between immediate and delayed rewards with varying delays), and the goals of the experiment (predicting choices made and the value of the discount factor).
read the caption
Table 7: Hyperbolic Discounting
| Parameter | Description |
|---|---|
| Model | The spread of an infection over time |
| Setup Parameters | Pop size 𝑁, params of the infetion rate (𝜇, 𝜎, upper and lower bounds) |
| Observations | Number of infected individuals at observation time |
| Goals | Predicting the number of infected individuals at a time and the infection rate |
🔼 Table 8 details the ‘Death Process’ environment in the BoxingGym benchmark. It outlines the model parameters (population size, infection rate parameters), the observations collected (number of infected individuals at different times), and the goals of the experiments (predicting the number of infected individuals at a given time and estimating the infection rate). The environment simulates the spread of a disease within a population, allowing agents to test their abilities in experimental design and model discovery.
read the caption
Table 8: Death Process
| Param | Description |
|---|---|
| Model | Student performance on multi-question exams |
| Setup Parameters | Number of students , number of questions , student-question pair to predict |
| Observations | Outcomes of various student-question pairs |
| Goals | Predicting the correctness of student responses to questions |
🔼 This table details the Item Response Theory (IRT) model used in the BoxingGym benchmark. It outlines the model parameters (number of students and questions), the observations made (student responses), and the goal of predicting the correctness of student responses to questions. The table also implicitly describes different variations of IRT models (1PL, 2PL, 3PL) with varying levels of complexity regarding the parameters included (difficulty, discrimination, and guessing).
read the caption
Table 9: IRT Model
| Parameter | Description |
|---|---|
| Model | Bayesian hierarchical model |
| Setup Parameters | alpha, beta, lambda, lower limit, upper limit |
| Observations | Length of dugong at a given age |
| Goals | Predicting the length of dugongs at different ages |
🔼 This table details the Dugongs environment in the BoxingGym framework. It outlines the model used (Bayesian hierarchical), the parameters involved (α, β, λ, lower and upper limits), the type of observations made (length of dugong at a given age), and the goals of the environment (predicting the length of dugongs at different ages).
read the caption
Table 10: Dugongs Environment
| Parameter | Description |
|---|---|
| Model | Poisson regression model |
| Setup Parameters | Regression params: α, β1, β2, and β3 |
| Observations | Population count of peregrine falcons at a given time |
| Goals | Predicting the population of peregrines at different times |
🔼 This table describes the Peregrine Falcon population dynamics environment used in the BoxingGym benchmark. It details the model used (Poisson regression), its parameters (regression coefficients α, β₁, β₂, β₃), the observations collected (population counts at various times), and the goal of the experiment (predicting future populations). The model simulates population changes over time using a Poisson distribution with a mean that is a function of time and the regression parameters, enabling testing of an agent’s ability to model dynamic systems.
read the caption
Table 11: Peregrine Environment
| Parameter | Description |
|---|---|
| Model | Survival analysis using a Bayesian approach |
| Setup Parameters | num_patients, time_upper_bound, lambda, beta |
| Observations | Whether a selected patient is alive or dead |
| Goals | Predict survival based on time since surgery and if the cancer had metastasized |
🔼 This table details the simulated environment for survival analysis in the context of mastectomies. It outlines the model used (Bayesian approach), the parameters defining the simulation (number of patients, upper time bound, lambda, beta), what data the simulated experiment generates (whether each patient is alive or dead), and ultimately, the goal of the experiment (predicting survival outcomes based on time since surgery and metastasis status).
read the caption
Table 12: Survival Analysis Environment
| Parameter | Description |
|---|---|
| Model | Lotka-Volterra equations |
| Setup Parameters | Initial prey population, initial predator population, α, β, γ, and δ |
| Observations | Populations of prey and predators at a given time |
| Goals | Predicting populations |
🔼 This table describes the Predator-Prey environment in the BoxingGym benchmark. It outlines the model used (Lotka-Volterra equations), the parameters involved (initial populations of prey and predators, interaction parameters α, β, γ, and δ), the type of observations collected (populations of prey and predators at different time points), and the goals of the environment (predicting population dynamics).
read the caption
Table 13: Predator-Prey Environment
| Parameter | Description |
|---|---|
| Model | Forward regression model with priors for emotional response |
| Setup Parameters | Prize values, probabilities, outcome, LLM |
| Observations | Prediction in natural language of how a player feels and why |
| Goals | Predicting what a participant thinks a player feels on a likert scale of 8 emotions. |
🔼 This table describes the experimental setup of the Emotions from Outcomes environment in the BoxingGym benchmark. It details the parameters (prize values, probabilities of outcomes, actual outcome) used to model a participant’s prediction of a player’s emotions after a game. The observations are free-form natural language descriptions, and the goals are to predict participant emotional responses on an 8-point Likert scale for various emotions (Happiness, Sadness, Anger, Surprise, Fear, Disgust, Contentment, Disappointment).
read the caption
Table 14: Emotions From Outcomes Environment
| Parameter | Description |
|---|---|
| Model | Logistic regression model with priors for moral decision-making |
| Setup Parameters | Character attributes, intervention type, LLM |
| Observations | Prediction in natural language of which group to save and why |
| Goals | Predicting which group participants choose to save |
🔼 This table details the Moral Machines environment used in the BoxingGym benchmark. It describes the model used (logistic regression with priors), the parameters (character attributes and intervention type), how interactions occur (LLM-based predictions in natural language), and the ultimate goal of the environment (predicting which group of characters participants choose to save in moral dilemmas involving autonomous vehicles).
read the caption
Table 15: Moral Machines Environment
Full paper#