↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current text-to-video generation methods struggle with high-fidelity identity preservation, especially when dealing with multiple identities in a single video. Existing approaches often require extensive fine-tuning or lack adaptability, hindering widespread applicability. Training-based methods are resource-intensive and struggle to maintain consistency across multiple identities. The paper addresses these limitations.
The proposed method, Ingredients, uses a novel three-module framework: (1) a facial extractor that captures versatile facial features; (2) a multi-scale projector that maps facial embeddings into video diffusion transformers; and (3) an ID router that dynamically allocates identities to different space-time regions. A multi-stage training protocol is implemented. The results demonstrate superior performance compared to existing methods, with significant improvements in identity preservation, content flexibility, and overall video quality. The framework is training-free and open-source, making it accessible to a wider community of researchers.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel framework for high-fidelity multi-identity video customization using video diffusion transformers. It addresses the limitations of existing methods by offering a training-free approach, achieving superior performance in terms of identity preservation and content flexibility. This opens new avenues for research in personalized video generation, impacting areas like AI-generated portraits and video animation. The publicly available code and data also encourage further research and development in this field.
Visual Insights#

🔼 This figure showcases the capabilities of the proposed ‘Ingredients’ framework for multi-identity video customization. Multiple reference images of different individuals are used as input. The resulting videos demonstrate the ability of the model to generate realistic and personalized video content, successfully incorporating the distinct facial features of each individual while maintaining identity consistency throughout the video.
read the caption
Figure 1: Examples of multi-ID customized video results from our proposed Ingredients. Given a reference with multiple human image set, our method can generate realistic and personalized videos while preserving specific human identity consistent.
| Methods | Face Sim. ↑ (%) | CLIPScore ↑ (%) | FID ↓ |
|---|---|---|---|
| CogvideoX | 2.8 | 28.3 | - |
| Inversion | 35.6 | 24.3 | 154.2 |
| Ingredients | 77.1 | 26.7 | 106.3 |
🔼 Table 1 presents a quantitative comparison of the proposed ‘Ingredients’ method against two baseline approaches for multi-human video generation. The first baseline, ‘CogVideoX’, serves as a text-only model, meaning it generates video based solely on text prompts without any visual conditioning or input. The second baseline, ‘Inversion’, represents a tuning-based textual inversion method, indicating that the model undergoes fine-tuning for each specific identity to enhance customization. The table compares the performance of these three methods across three key metrics: Face Similarity (measuring how similar generated faces are to the input faces), CLIPScore (evaluating the alignment between the generated video and the text prompt), and Fréchet Inception Distance (FID, measuring the visual quality of the generated videos). Higher Face Similarity and CLIPScore values, along with a lower FID value, indicate superior performance. This comparison allows for an objective assessment of the Ingredients framework’s effectiveness in generating high-quality, identity-consistent videos compared to alternative methods.
read the caption
Table 1: Compare between our method and baseline approaches on multiple human video generation. Cogvideox served as the text-only baseline without any video conditioning while Inversion is tuning-based textual inversion.
In-depth insights#
Multi-ID Video#
The concept of “Multi-ID Video” in the context of a research paper likely refers to techniques for generating videos that seamlessly incorporate multiple distinct human identities. This is a challenging problem because it requires sophisticated methods to preserve individual facial features and identities while avoiding blending or inconsistencies. A key aspect involves the management of different IDs within the video’s temporal and spatial dimensions, ensuring smooth transitions between identities and accurate representation of each person in the scene. The development of such techniques likely involves advanced models (e.g., diffusion transformers) and training protocols to enable precise control over identity representation and the integration of multiple ID sources. Successful approaches would likely address challenges in consistent identity preservation, avoiding blurring or unnatural blending of facial features, as well as maintaining control over other aspects of video generation (e.g., text prompts, scene context) without impacting identity fidelity.
Diffusion Control#
Diffusion models, known for their impressive generative capabilities, often lack fine-grained control. A critical aspect of improving these models is diffusion control, which focuses on techniques to precisely guide the diffusion process. This control can manifest in various ways, from manipulating the initial noise to directly influencing intermediate steps. Effective diffusion control methods enable the generation of highly customized outputs that adhere to specific constraints and user specifications. Different methods target different levels of control, ranging from coarse-grained manipulation of overall style or content to highly precise modification of individual elements. Understanding and addressing challenges like mode collapse and ensuring high-fidelity output are crucial in developing effective diffusion control. This involves carefully considering the trade-off between control and output quality, as overly constrained models may produce less creative results. Advanced techniques may combine multiple control signals, allowing for complex and nuanced control, but this raises new challenges in managing interactions between different control mechanisms. Future research should prioritize exploring novel ways to enhance controllability while maintaining the diversity and quality of the generated content, possibly through the use of hybrid approaches or more sophisticated learning techniques. The development of robust and versatile diffusion control methods is key to unlocking the full potential of diffusion models for various applications.
Ingredients Model#
The conceptual ‘Ingredients Model’ for video personalization, as described, is a multi-stage framework leveraging video diffusion transformers. Its core innovation lies in the sophisticated approach to incorporating multiple custom identity photos. Three key modules work in concert: a facial extractor providing versatile features, a multi-scale projector mapping these features into the video transformer’s latent space, and an ID router intelligently allocating identities across space-time regions. This training-free approach avoids the scalability issues of fine-tuning, making it more practical. The multi-stage training further enhances performance and control. By strategically combining and optimizing various elements, the model successfully tackles the challenges of preserving identity consistency across multiple individuals, enabling high-fidelity and natural-looking personalized videos.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a complex model. In the context of a video generation model, this might involve removing or modifying specific modules (e.g., facial feature extractors, identity routers) to assess their impact on overall performance. Key metrics like identity preservation, visual fidelity, and text adherence would be carefully measured after each ablation. The results would highlight the critical components responsible for the model’s success and provide valuable insights into design choices. Well-designed ablation studies not only validate the model’s architecture, but they also provide a path for potential future improvements by identifying areas for optimization or enhancement. Analyzing the results should offer a nuanced understanding of the model’s strengths and weaknesses, informing future research directions. The impact of different initialization strategies, loss functions, and training protocols on the model’s ability to generate high-fidelity videos with consistent identity preservation should be thoroughly examined. This detailed investigation of individual components enables a more comprehensive understanding of the whole. Careful consideration should be given to ensure that the ablations are properly controlled and interpreted to avoid misinterpretations.
Future Directions#
Future research should prioritize improving the robustness and controllability of multi-ID video generation. Addressing inconsistencies and artifacts, such as faces appearing pasted or unnatural, is crucial. This involves refining the facial feature extraction, exploring alternative routing mechanisms, and improving the training process to better handle diverse prompts and reference images. Exploring alternative model architectures beyond diffusion transformers could unlock greater efficiency and scalability. Further investigation into the interaction between global and local identity features within the latent space is warranted, seeking to strike an optimal balance between ID preservation and prompt adherence. Finally, expanding the dataset’s diversity and creating standardized evaluation metrics for multi-ID video generation are essential for benchmarking progress and advancing the field.
More visual insights#
More on figures

🔼 The Ingredients framework uses three main modules to customize videos with multiple identities. The facial extractor identifies and extracts distinct facial features for each person. A q-former projector maps these features into the video diffusion transformer at multiple scales. Finally, the ID router strategically places these identities into the video based on their location and time, adapting to different regions of the video without needing extra prompts or predefined layouts. The system trains in two phases: aligning facial embeddings and then fine-tuning the router.
read the caption
Figure 2: Overview of Ingredients framework. The proposed method consists of three key modules: a facial extractor, a q-former-based projector, and an ID router. The facial extractor collects versatile editable facial features with a decoupling strategy for each ID. The q-former projector map multi-scale facial embedding into different layers of video diffusion transformers. The ID router combines and distributes ID embeddings to their respective locations adaptively without the intervention for prompts and layouts. The entire training process of the framework is curated into two stages, i.e., the facial embedding alignment stage and the router fine-tuning stage.

🔼 Figure 3 presents a qualitative comparison of various multi-identity (multi-ID) video personalization methods. It contrasts the results of the proposed ‘Ingredients’ method against a training-based approach (textual inversion). The figure showcases that Ingredients, unlike textual inversion, effectively routes and focuses attention on the relevant regions of the video, resulting in improved consistency in maintaining individual identities and strong adherence to the provided textual prompts. The visualization highlights the superior performance of Ingredients in preserving distinct identities while accurately reflecting the desired content.
read the caption
Figure 3: Qualitative comparison of different personalization methods on multi-ID video customization. It can been seen that compared with training-based customization, i.e., textual inversion, our method can clearly routing and attention the respect regions, benefits to ID consistency as well as strong prompt following.

🔼 Figure 4 showcases instances where the Ingredients model fails to produce satisfactory multi-human video customizations. The generated videos exhibit flaws such as characters that appear to be directly copied and pasted from the source images, leading to unnatural and jarring transitions. Another issue is evident in instances where the background and elements surrounding the subjects are inconsistent, displaying signs of ‘out-painting’ where the AI attempts to generate areas outside the boundaries of the original image, leading to a mismatch between the figures and their environment. The resulting videos lack a cohesive visual narrative and do not maintain the consistency aimed for.
read the caption
Figure 4: Additional bad examples of multi-human customization. Our Ingredients involves failures that generated characters appearing as though they were directly copied-pasted and out-painting, leading to an inconsistent video scenes.

🔼 Figure 5 visualizes how the routing network within the video diffusion transformer assigns different identities at various cross-attention layers. The visualization uses a heatmap to show the assignment of two distinct human IDs (white and black pixels) across different time steps and layers. It demonstrates that with the addition of the routing loss, the network successfully identifies the individual identities earlier in the generation process and with greater clarity. The routing becomes more refined and accurate with deeper layers, highlighting the effectiveness of the routing loss in improving ID separation and consistency.
read the caption
Figure 5: Visualization of routing map within each cross-attention layer of video diffusion transformers. We can see that with the routing loss, the routing network can discern different human IDs at earlier timesetps and in a more pronounced manner.

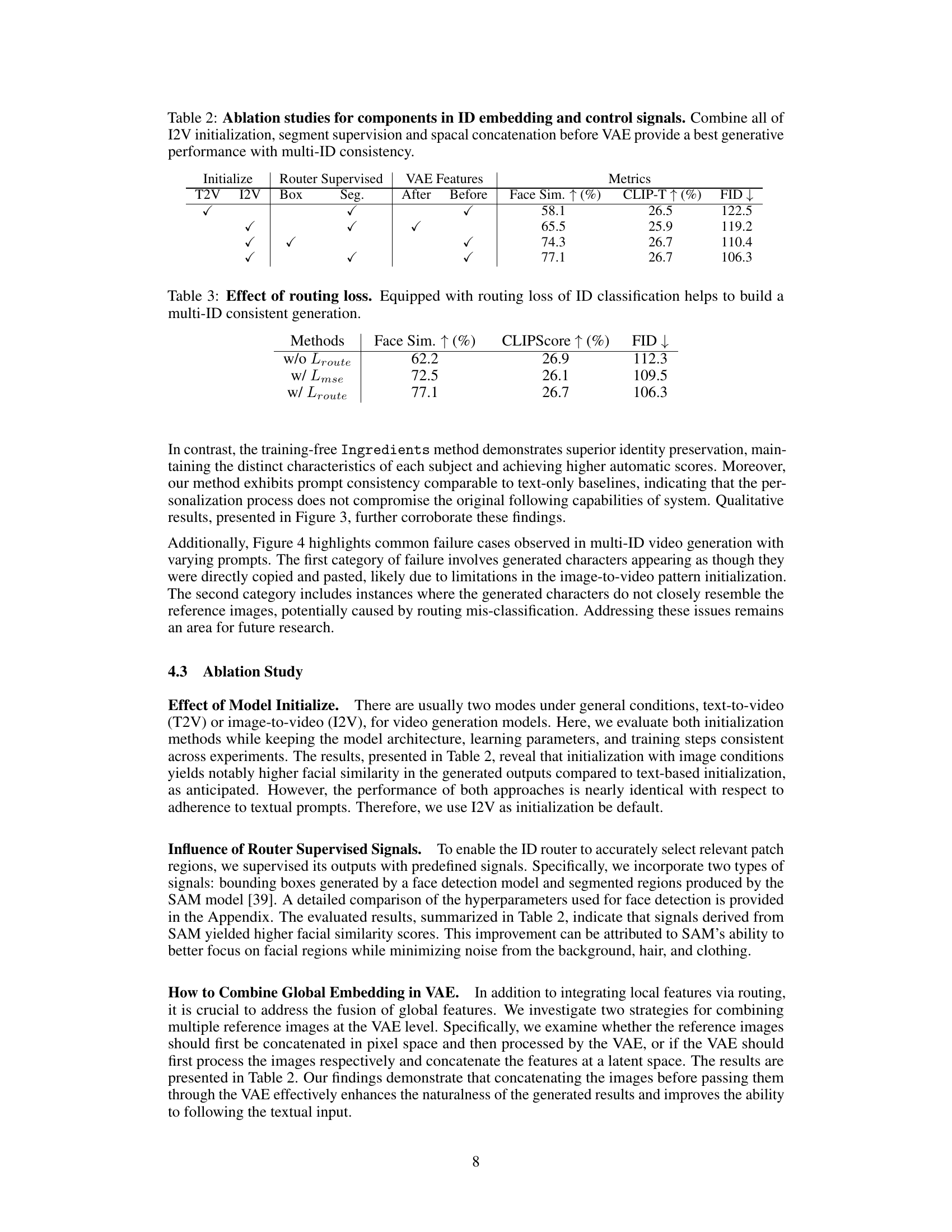
🔼 This figure displays the training loss curves for two loss functions during the router fine-tuning stage of the Ingredients model. The x-axis represents the training steps, and the y-axis represents the loss value. The blue curve shows the routing loss, while the orange curve shows the diffusion loss. As training progresses (increasing number of steps), the routing loss decreases significantly, indicating that the ID router is becoming more accurate in assigning identities to different regions of the video frames. Conversely, the diffusion loss remains relatively constant throughout the training, demonstrating that the overall generative quality of the model is maintained. The stable diffusion loss while the routing loss decreases significantly demonstrates that the model successfully refines the identity assignment without compromising the video generation quality.
read the caption
Figure 6: The curve of different training loss in router fine-tuning stage. We can see that with training steps increases, routing loss significantly decreases, the router becomes more accurate, while the diffusion loss remains almost unchanged, maintaining the original generative performance.

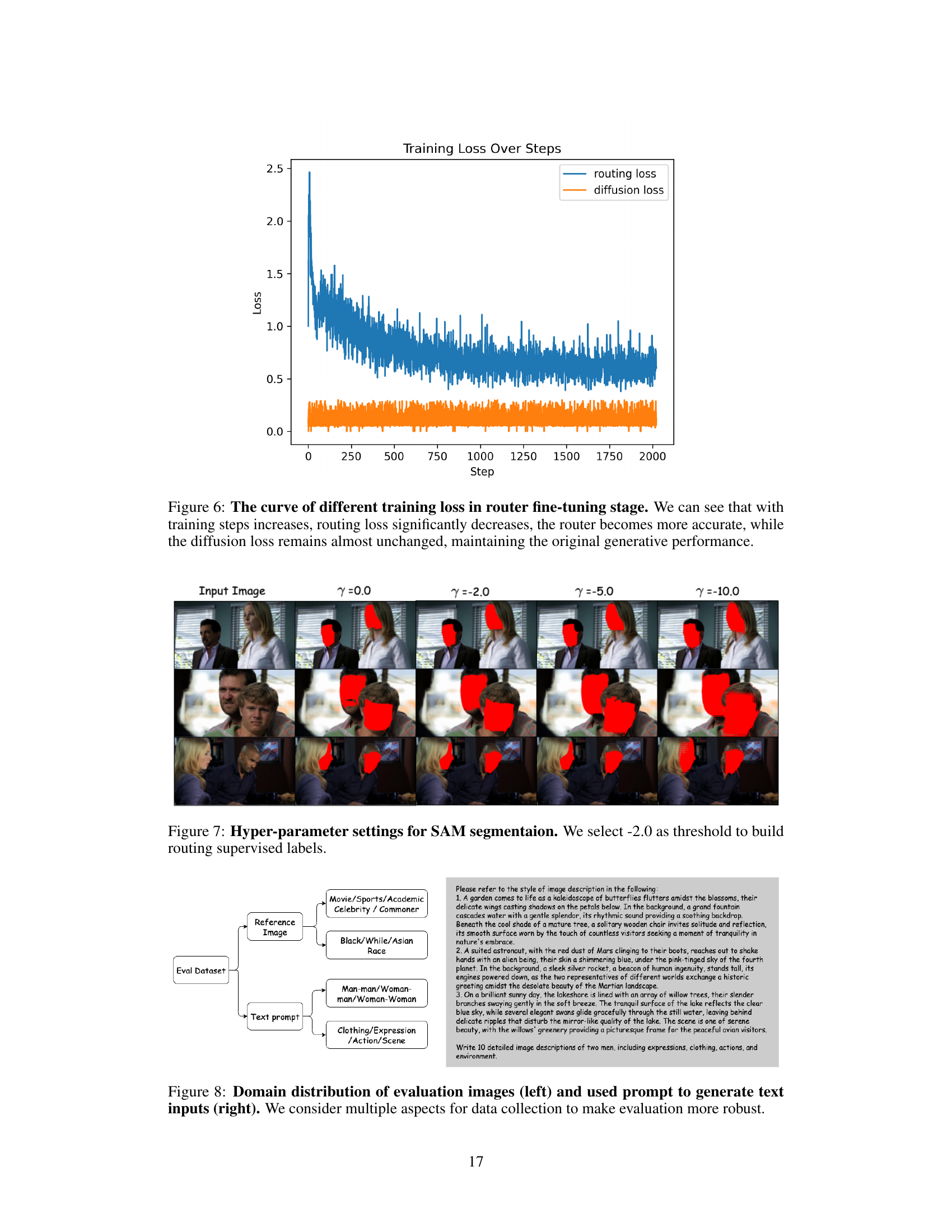
🔼 This figure showcases the hyperparameter tuning process for the Segment Anything Model (SAM) used in the Ingredients framework. Specifically, it illustrates how different threshold values (-2.0, -5.0, -10.0, and 0.0) impact the resulting segmentation masks. This is crucial because SAM’s output is used to generate training labels for the ‘router’ component. The goal is to optimize the threshold to precisely define the facial regions for multi-identity video generation, ensuring accurate assignment of identities to the corresponding spatial regions of the video. The image shows examples of how the segmentation mask changes depending on the threshold value chosen. The optimal threshold of -2.0 is selected for the experiment to generate the training supervision labels.
read the caption
Figure 7: Hyper-parameter settings for SAM segmentaion. We select -2.0 as threshold to build routing supervised labels.

🔼 Figure 8 shows the variety of data used for evaluating the model’s performance. The left side displays the diverse set of images used as references, highlighting differences in race, gender, clothing, and activities. The right side presents examples of the detailed textual prompts that were used, illustrating that prompts incorporate multiple aspects (e.g., clothing, location, interactions) for generating the videos. By including such diversity in both image and text, the evaluation becomes more robust and less susceptible to bias from a limited range of inputs.
read the caption
Figure 8: Domain distribution of evaluation images (left) and used prompt to generate text inputs (right). We consider multiple aspects for data collection to make evaluation more robust.
More on tables
| Initialize | Router Supervised | VAE Features | Metrics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| T2V | I2V | Box | Seg. | After | Before | Face Sim. ↑ (%) | CLIP-T ↑ (%) | FID ↓ | |
| ✓ | ✓ | ✓ | 58.1 | 26.5 | 122.5 | ||||
| ✓ | ✓ | ✓ | 65.5 | 25.9 | 119.2 | ||||
| ✓ | ✓ | ✓ | 74.3 | 26.7 | 110.4 | ||||
| ✓ | ✓ | ✓ | 77.1 | 26.7 | 106.3 |
🔼 This ablation study analyzes the impact of different components on the Ingredients framework’s performance in multi-ID video generation. It examines the effects of different initialization methods (text-to-video vs. image-to-video), segment supervision (using bounding boxes and SAM segmentation masks), and the spatial concatenation of features before the Variational Autoencoder (VAE). The results show that combining image-to-video initialization, SAM-based segment supervision, and concatenating features before the VAE leads to the best performance in terms of multi-ID consistency, demonstrating the importance of these components for effective facial identity preservation.
read the caption
Table 2: Ablation studies for components in ID embedding and control signals. Combine all of I2V initialization, segment supervision and spacal concatenation before VAE provide a best generative performance with multi-ID consistency.
| Methods | Face Sim. ↑ (%) | CLIPScore ↑ (%) | FID ↓ |
|---|---|---|---|
| w/o $L_{route}$ | 62.2 | 26.9 | 112.3 |
| w/ $L_{mse}$ | 72.5 | 26.1 | 109.5 |
| w/ $L_{route}$ | 77.1 | 26.7 | 106.3 |
🔼 This table presents an ablation study on the impact of the routing loss component within the Ingredients framework. It compares the performance of the model when the routing loss is omitted, replaced with a mean squared error (MSE) loss, and when the original ID classification-based routing loss is used. The results are measured by Face Similarity (higher is better), CLIPScore (higher is better), and Fréchet Inception Distance (FID, lower is better) scores, which respectively quantify the similarity of generated faces to real faces, the alignment of generated videos with textual prompts, and the overall quality of the generated video. This demonstrates the effectiveness of the proposed routing loss in generating videos with multi-ID consistency.
read the caption
Table 3: Effect of routing loss. Equipped with routing loss of ID classification helps to build a multi-ID consistent generation.
Full paper#