↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large Language Models (LLMs) are rapidly growing but their security vulnerabilities remain a significant concern. Current methods for identifying these vulnerabilities are often manual, time-consuming, and limited in scope. This makes it difficult to keep up with the rapid advancement in LLMs and ensures the safety of these powerful models.
AUTO-RT tackles this challenge using a reinforcement learning approach to automatically explore and optimize attack strategies. By incorporating early termination and progressive reward tracking, AUTO-RT significantly improves efficiency, discovers a wider range of vulnerabilities, and achieves faster detection compared to previous methods. The framework is designed to be versatile, functioning effectively on both white-box and black-box models. The results highlight the potential of AUTO-RT for enhancing LLM safety and security.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AUTO-RT, a novel framework for automatically finding security vulnerabilities in large language models (LLMs). This addresses a critical need in the rapidly evolving field of LLM safety and security, offering a more efficient and scalable alternative to manual methods. The research opens new avenues for automated red-teaming, improving the speed and effectiveness of vulnerability discovery and paving the way for more robust and reliable LLMs. Its versatile approach works on both white-box and black-box models, expanding its potential impact across the LLM research community.
Visual Insights#

🔼 The figure illustrates the key difference between Auto-RT and prior red-teaming techniques. Traditional methods evaluate the safety of large language models (LLMs) using pre-defined attack strategies. They focus on finding existing vulnerabilities within the model’s responses to these known attacks. In contrast, Auto-RT takes a more proactive and comprehensive approach. It begins by automatically exploring and generating a wide variety of attack strategies. Then, it uses these novel strategies to assess the LLM’s safety, enabling the identification of previously unknown vulnerabilities. This automated exploration process makes Auto-RT more efficient and scalable than existing methods.
read the caption
Figure 1: Comparison between previous red-teaming approaches and Auto-RT. Previous works focused on identifying safety flaws of the target model under given attack strategies, whereas Auto-RT directly explores systematic safety flaws in target models starting from searching strategies itself, enabling a fully automated process.
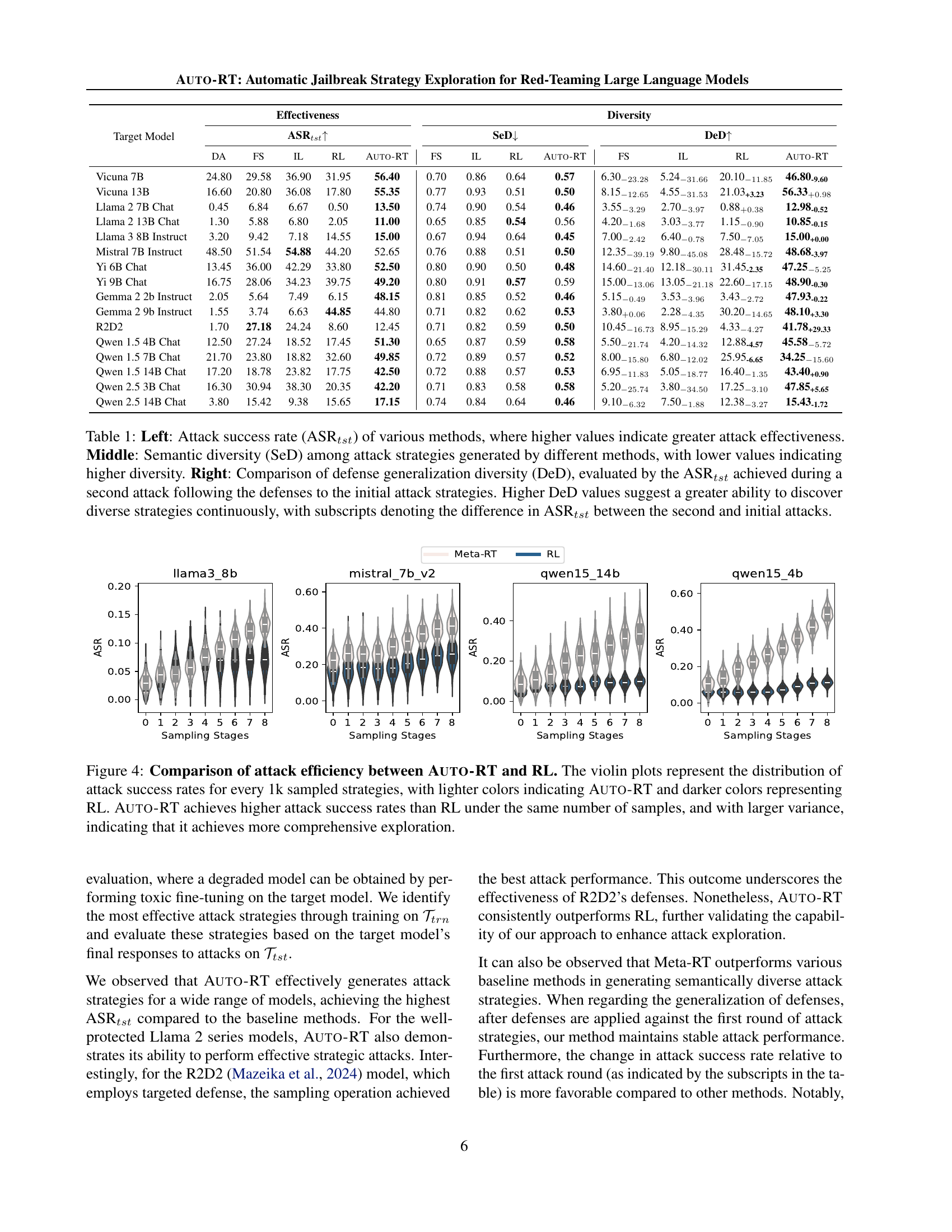
🔼 This table presents a comparison of different attack methods against various large language models (LLMs). The ‘Effectiveness’ section shows the Attack Success Rate (ASR), which is the percentage of successful attacks out of 100 attempts on a test dataset. Higher ASR indicates a more effective attack method. The ‘Diversity’ section includes two sub-metrics: Semantic Diversity (SeD) and Defense Generalization Diversity (DeD). SeD measures the similarity of generated attack strategies; lower values signify higher diversity. DeD measures the success rate of a second round of attacks after defenses are implemented based on the initial attack strategies. Higher DeD indicates a better ability to discover diverse strategies against adaptive defenses. The difference between the second and initial attack success rates is shown with subscripts.
read the caption
Table 1: Left: Attack success rate (ASRtst) of various methods, where higher values indicate greater attack effectiveness. Middle: Semantic diversity (SeD) among attack strategies generated by different methods, with lower values indicating higher diversity. Right: Comparison of defense generalization diversity (DeD), evaluated by the ASRtst achieved during a second attack following the defenses to the initial attack strategies. Higher DeD values suggest a greater ability to discover diverse strategies continuously, with subscripts denoting the difference in ASRtst between the second and initial attacks.
In-depth insights#
Auto-Red Teaming#
Auto-red teaming, as a concept, presents a paradigm shift in evaluating the robustness of Large Language Models (LLMs). Traditional red teaming often relies on pre-defined attack strategies, limiting its ability to discover unforeseen vulnerabilities. Automating this process offers the potential for more comprehensive and efficient vulnerability detection. Reinforcement learning emerges as a key technique, enabling the system to learn and adapt attack strategies in response to the LLM’s defenses. A crucial aspect is the design of the reward function, which should incentivize the discovery of both high-severity and high-exploitability vulnerabilities. Early termination mechanisms can significantly enhance efficiency, allowing the algorithm to focus on promising strategies and avoid wasted computational resources. The use of degraded models within the reward shaping process may facilitate more efficient exploration by providing denser feedback signals. Overall, auto-red teaming represents a promising avenue to continuously improve the security and safety of LLMs, but careful consideration of reward function design and exploration strategies are crucial for its success.
RL Framework#
A reinforcement learning (RL) framework for red-teaming large language models (LLMs) would involve designing an agent that learns to generate effective attack strategies. The framework would need to define a clear reward function, measuring the success of an attack strategy in eliciting undesired behavior from the LLM. This might involve aspects like the toxicity or harmfulness of the LLM’s response. The RL agent would learn through trial and error, iteratively refining its attack strategies based on the feedback from the reward function. Key challenges include designing a reward function that is both robust and meaningful, handling the potentially high dimensionality of the action space (the space of possible attack strategies), and efficiently exploring the vast landscape of potential vulnerabilities. A successful RL framework would require careful consideration of these aspects. It could be evaluated based on its ability to discover novel vulnerabilities, its efficiency in exploration, and the generalizability of its findings across various LLMs. The use of intermediate reward signals or shaping could be critical to improve learning efficiency and help the agent focus on promising attack strategies. Moreover, incorporating diversity measures into the reward would help to explore a broader range of vulnerabilities.
Reward Shaping#
Reward shaping, in the context of reinforcement learning for red-teaming large language models, addresses the challenge of sparse rewards. Traditional reward signals in this setting are infrequent, hindering efficient learning of effective attack strategies. By incorporating additional domain-specific information, reward shaping densifies the reward landscape, guiding the learning agent towards successful attacks more effectively. This is particularly crucial in scenarios where the target model is robust and only yields strong reward signals upon successful jailbreaks. Progressive Reward Tracking, a mechanism introduced in the paper, uses a sequence of increasingly vulnerable target models to provide more consistent and informative feedback throughout the learning process. This technique enhances learning speed and overall success rates by gradually increasing reward density as the agent’s strategies evolve. The choice of degraded models and mechanisms like First Inverse Rate (FIR) are essential for optimizing the effectiveness of progressive reward shaping, ensuring that the additional reward does not mislead the agent away from the actual goal. In essence, reward shaping plays a critical role in balancing exploration-exploitation trade-offs, accelerating the discovery of vulnerabilities, and ultimately, enhancing the robustness of the red-teaming approach.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a research paper on automated red-teaming of large language models (LLMs), an ablation study would likely focus on the different techniques or modules used to generate and optimize attack strategies. Key components to analyze would include the strategy generation algorithm, the query rephrasing module, and reward shaping mechanisms. By removing one element at a time, the study quantifies the impact on the effectiveness, efficiency and diversity of the generated attacks, revealing which parts are most critical for successful jailbreaking. The results of such a study would be crucial in understanding the model’s architecture and prioritizing areas for improvement or further research. A well-designed ablation study will provide valuable insights into how each component contributes to the overall performance of the system, helping researchers understand what aspects are most critical to enhance the robustness of LLM security defenses.
Future Works#
Future work in this area could explore several promising avenues. Expanding the scope of AUTO-RT to encompass a broader range of LLM architectures and sizes is crucial for establishing its generalizability and effectiveness. Investigating more sophisticated reward shaping techniques beyond the FIR metric, perhaps incorporating human feedback or external knowledge sources, could significantly improve strategy discovery. Furthermore, a deeper analysis of the generated attack strategies themselves is needed to understand the underlying vulnerabilities they exploit and improve defense mechanisms. Exploring the integration of AUTO-RT with other red-teaming methodologies, such as those employing adversarial training or model patching, might create a more robust and comprehensive red-teaming system. Finally, research into the potential for AUTO-RT to be applied beyond red-teaming, for example, to enhance LLM alignment or improve model robustness, is an important next step.
More visual insights#
More on figures

🔼 AUTO-RT’s framework is composed of two main parts: Early-terminated Exploration and Progressive Reward Tracking. Early-terminated Exploration assesses the diversity of generated attack strategies and the consistency between the rephrased prompt and the original toxic behavior. If either fails, the process stops early, applying a penalty. Progressive Reward Tracking improves exploration efficiency by using a degraded model (a less capable version of the main language model) to generate denser safety reward signals, guiding the search toward successful attacks more effectively. This method refines the search trajectory and helps to identify vulnerabilities faster.
read the caption
Figure 2: The framework of Auto-RT, comprising two key components: 1) Early-terminated Exploration, which assesses the diversity of the generated strategies and the consistency of the rephrased prompt with the initial toxic behavior to determine the necessity of safety evaluation. If either constraint is unmet, the process immediately terminate, and a penalty is applied; 2) Progressive Reward Tracking, which enhances the density of safety rewards by utilizing a degrade model derived from the target model, thereby improving the efficiency and effectiveness of the exploration process.

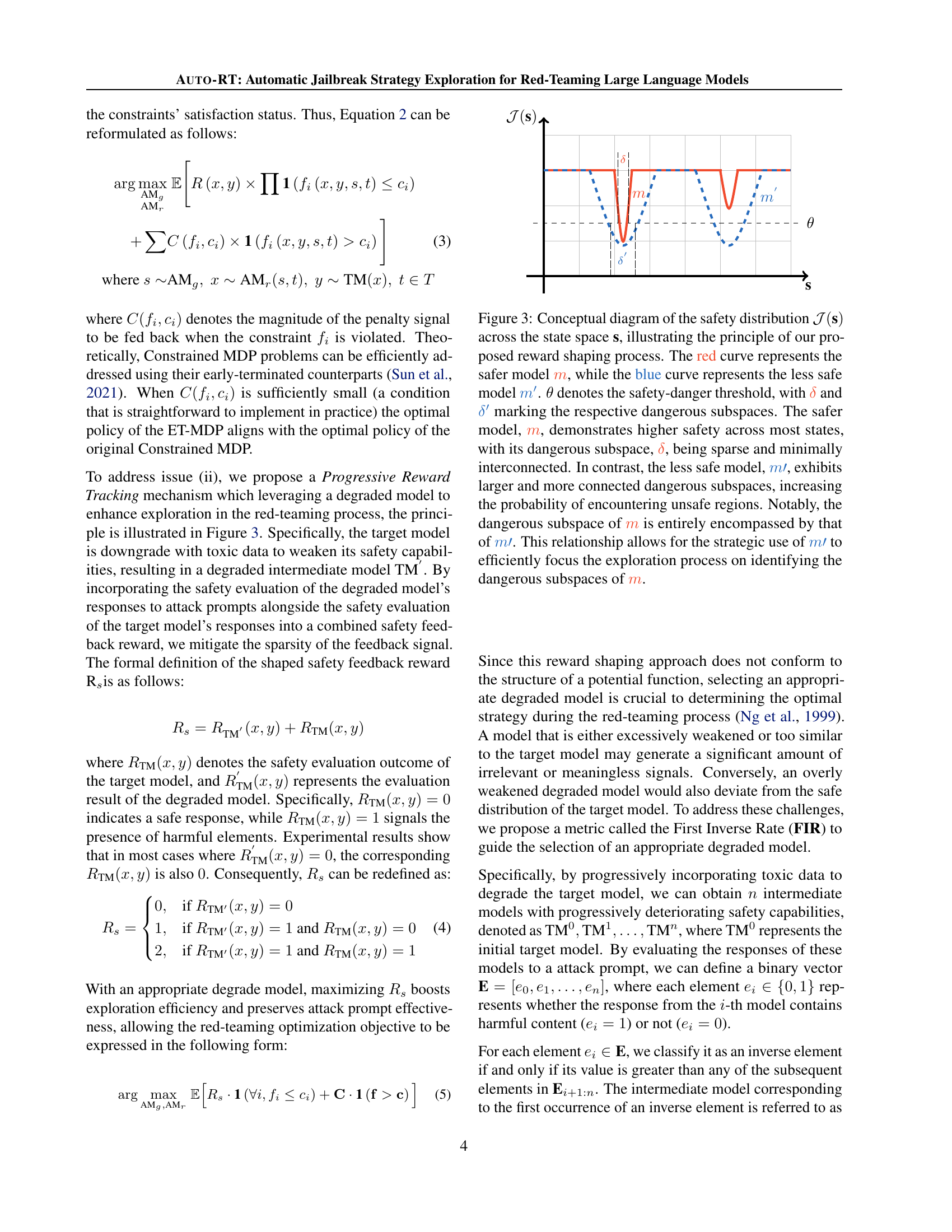
🔼 This figure illustrates the reward shaping process using two models: a safer model (red curve) and a less safe model (blue curve). The x-axis represents the state space, and the y-axis represents the safety distribution. The safer model has a smaller and less connected dangerous subspace (δ), while the less safe model has a larger and more interconnected dangerous subspace (δ’). Using the less safe model allows focusing the exploration on the dangerous subspaces of the safer model.
read the caption
Figure 3: Conceptual diagram of the safety distribution 𝒥(s)𝒥s\mathcal{J}(\textbf{s})caligraphic_J ( s ) across the state space s, illustrating the principle of our proposed reward shaping process. The red curve represents the safer model m𝑚{\color[rgb]{1,0.23,0.13}\definecolor[named]{pgfstrokecolor}{rgb}{1,0.23,0.13}% \pgfsys@color@cmyk@stroke{0}{0.77}{0.87}{0}\pgfsys@color@cmyk@fill{0}{0.77}{0.% 87}{0}m}italic_m, while the blue curve represents the less safe model m′superscript𝑚′{\color[rgb]{0.0600000000000001,0.46,1}\definecolor[named]{pgfstrokecolor}{rgb% }{0.0600000000000001,0.46,1}\pgfsys@color@cmyk@stroke{0.94}{0.54}{0}{0}% \pgfsys@color@cmyk@fill{0.94}{0.54}{0}{0}m^{\prime}}italic_m start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT. θ𝜃\thetaitalic_θ denotes the safety-danger threshold, with δ𝛿{\color[rgb]{1,0.23,0.13}\definecolor[named]{pgfstrokecolor}{rgb}{1,0.23,0.13}% \pgfsys@color@cmyk@stroke{0}{0.77}{0.87}{0}\pgfsys@color@cmyk@fill{0}{0.77}{0.% 87}{0}\delta}italic_δ and δ′superscript𝛿′{\color[rgb]{0.0600000000000001,0.46,1}\definecolor[named]{pgfstrokecolor}{rgb% }{0.0600000000000001,0.46,1}\pgfsys@color@cmyk@stroke{0.94}{0.54}{0}{0}% \pgfsys@color@cmyk@fill{0.94}{0.54}{0}{0}\delta^{\prime}}italic_δ start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT marking the respective dangerous subspaces. The safer model, m𝑚{\color[rgb]{1,0.23,0.13}\definecolor[named]{pgfstrokecolor}{rgb}{1,0.23,0.13}% \pgfsys@color@cmyk@stroke{0}{0.77}{0.87}{0}\pgfsys@color@cmyk@fill{0}{0.77}{0.% 87}{0}m}italic_m, demonstrates higher safety across most states, with its dangerous subspace, δ𝛿{\color[rgb]{1,0.23,0.13}\definecolor[named]{pgfstrokecolor}{rgb}{1,0.23,0.13}% \pgfsys@color@cmyk@stroke{0}{0.77}{0.87}{0}\pgfsys@color@cmyk@fill{0}{0.77}{0.% 87}{0}\delta}italic_δ, being sparse and minimally interconnected. In contrast, the less safe model, m′{\color[rgb]{0.0600000000000001,0.46,1}\definecolor[named]{pgfstrokecolor}{rgb% }{0.0600000000000001,0.46,1}\pgfsys@color@cmyk@stroke{0.94}{0.54}{0}{0}% \pgfsys@color@cmyk@fill{0.94}{0.54}{0}{0}m{\prime}}italic_m ′, exhibits larger and more connected dangerous subspaces, increasing the probability of encountering unsafe regions. Notably, the dangerous subspace of m𝑚{\color[rgb]{1,0.23,0.13}\definecolor[named]{pgfstrokecolor}{rgb}{1,0.23,0.13}% \pgfsys@color@cmyk@stroke{0}{0.77}{0.87}{0}\pgfsys@color@cmyk@fill{0}{0.77}{0.% 87}{0}m}italic_m is entirely encompassed by that of m′{\color[rgb]{0.0600000000000001,0.46,1}\definecolor[named]{pgfstrokecolor}{rgb% }{0.0600000000000001,0.46,1}\pgfsys@color@cmyk@stroke{0.94}{0.54}{0}{0}% \pgfsys@color@cmyk@fill{0.94}{0.54}{0}{0}m{\prime}}italic_m ′. This relationship allows for the strategic use of m′{\color[rgb]{0.0600000000000001,0.46,1}\definecolor[named]{pgfstrokecolor}{rgb% }{0.0600000000000001,0.46,1}\pgfsys@color@cmyk@stroke{0.94}{0.54}{0}{0}% \pgfsys@color@cmyk@fill{0.94}{0.54}{0}{0}m{\prime}}italic_m ′ to efficiently focus the exploration process on identifying the dangerous subspaces of m𝑚{\color[rgb]{1,0.23,0.13}\definecolor[named]{pgfstrokecolor}{rgb}{1,0.23,0.13}% \pgfsys@color@cmyk@stroke{0}{0.77}{0.87}{0}\pgfsys@color@cmyk@fill{0}{0.77}{0.% 87}{0}m}italic_m.

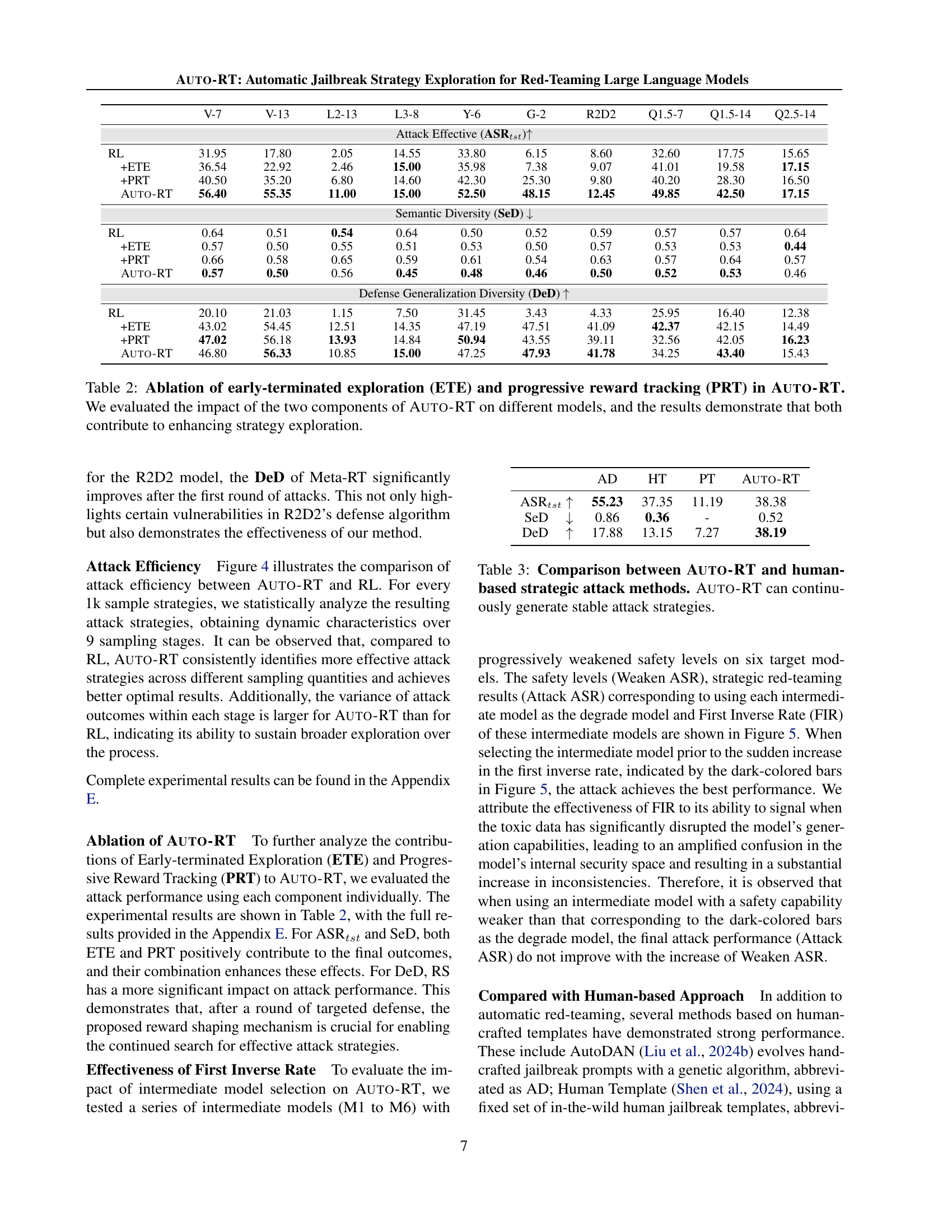
🔼 Figure 4 presents a comparison of the attack efficiency between Auto-RT and RL. The violin plots illustrate the distribution of attack success rates for sets of 1,000 sampled strategies. Lighter colors represent Auto-RT, while darker colors represent RL. The figure demonstrates that Auto-RT consistently achieves higher attack success rates than RL using the same number of samples. Furthermore, the larger variance in Auto-RT’s success rates suggests a broader and more thorough exploration of the strategy space, leading to the discovery of a wider range of vulnerabilities.
read the caption
Figure 4: Comparison of attack efficiency between Auto-RT and RL. The violin plots represent the distribution of attack success rates for every 1k sampled strategies, with lighter colors indicating Auto-RT and darker colors representing RL. Auto-RT achieves higher attack success rates than RL under the same number of samples, and with larger variance, indicating that it achieves more comprehensive exploration.

🔼 Figure 5 illustrates the impact of using different degraded models on the red-teaming process. Six intermediate models (M1-M6) were created by fine-tuning six target models with increasing amounts of toxic data. The figure plots three key metrics against the intermediate models: Attack ASR (the success rate of attacks on the original target model after using reward shaping with the intermediate model), Weaken ASR (the safety level of the intermediate model itself), and Weaken FIR (the rate at which the intermediate model produces unsafe responses). The optimal results are achieved when the final degraded model is selected just before a sharp increase in the Weaken FIR, which is indicated by the dark-colored bars in the graph. This suggests that selecting a model with sufficiently degraded safety capabilities but not excessively weak is crucial for effective reward shaping.
read the caption
Figure 5: The relationship between the red-teaming outcomes (Attack ASR) following reward shaping with a series of intermediate models (M1 to M6), the safety levels of these models (Weaken ASR), and their first inverse rate for additional toxic behavior (Weaken FIR). These intermediate models are derived by fine-tuning on six target models using varying amounts of toxic data.The optimal red-teaming results are achieved by selecting the last intermediate model before a sudden spike in FIR (represented by the dark-colored bar in the figure) as the degrade model for reward shaping.

🔼 Figure 6 shows the prompt used in the AUTO-RT framework for generating new attack strategies. The prompt instructs the model to create a novel rephrasing strategy that modifies user queries while preserving their intent. It specifies constraints to ensure diversity and maintain the original query meaning, and requests strategies that are easy to understand and apply. The prompt includes example strategies to guide the model’s generation process, thus allowing for a more targeted and effective search for vulnerabilities.
read the caption
Figure 6: Complete prompt for new strategies exploration. seed examples are demonstrations selected from existing strategies based on different settings.

🔼 This figure displays the prompt template used in the AUTO-RT framework for the query rephrasing stage. The prompt instructs the model to rephrase a given toxic query according to a specific attack strategy. This attack strategy is dynamically generated by the attack model within the AUTO-RT system, and is fed as input to the rephrasing process. The goal is to modify the query while maintaining its original intent, but in a way that is more likely to elicit a harmful response from the target language model. The prompt includes example rephrased queries to guide the model in generating consistent and effective rephrased queries. This ensures the model produces variations of the original toxic query that could still trigger unsafe behaviors, even if the original phrasing was blocked or filtered by the target model.
read the caption
Figure 7: Complete the prompt for attack query rephrasing using the provided attack strategy. The attack strategy is sampled from the attack model, and the toxic query represents the initial toxic behavior.

🔼 This figure shows the prompt used for the consistency judge module in the AUTO-RT framework. This module assesses whether the original query and its rephrased version (modified using a generated attack strategy) maintain the same intent. The prompt guides the judge to determine similarity based on several criteria: If both queries can be answered by the same response, share similar key terms, or represent the same underlying request, then their intent is considered the same. Conversely, different intent would be assigned if the queries yield different responses or lack similar key terms. The prompt includes example scenarios for better understanding.
read the caption
Figure 8: Complete the prompt for judging query intent. Verify that the original query and the rephrased query, modified with the attack strategy, share a similar intent by assessing their purposes.
More on tables
| V-7 | V-13 | L2-13 | L3-8 | Y-6 | G-2 | R2D2 | Q1.5-7 | Q1.5-14 | Q2.5-14 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Attack Effective (ASRtst) ↑ | ||||||||||
| RL | 31.95 | 17.80 | 2.05 | 14.55 | 33.80 | 6.15 | 8.60 | 32.60 | 17.75 | 15.65 |
| +ETE | 36.54 | 22.92 | 2.46 | 15.00 | 35.98 | 7.38 | 9.07 | 41.01 | 19.58 | 17.15 |
| +PRT | 40.50 | 35.20 | 6.80 | 14.60 | 42.30 | 25.30 | 9.80 | 40.20 | 28.30 | 16.50 |
| Auto-RT | 56.40 | 55.35 | 11.00 | 15.00 | 52.50 | 48.15 | 12.45 | 49.85 | 42.50 | 17.15 |
| Semantic Diversity (SeD) ↓ | ||||||||||
| RL | 0.64 | 0.51 | 0.54 | 0.64 | 0.50 | 0.52 | 0.59 | 0.57 | 0.57 | 0.64 |
| +ETE | 0.57 | 0.50 | 0.55 | 0.51 | 0.53 | 0.50 | 0.57 | 0.53 | 0.53 | 0.44 |
| +PRT | 0.66 | 0.58 | 0.65 | 0.59 | 0.61 | 0.54 | 0.63 | 0.57 | 0.64 | 0.57 |
| Auto-RT | 0.57 | 0.50 | 0.56 | 0.45 | 0.48 | 0.46 | 0.50 | 0.52 | 0.53 | 0.46 |
| Defense Generalization Diversity (DeD) ↑ | ||||||||||
| RL | 20.10 | 21.03 | 1.15 | 7.50 | 31.45 | 3.43 | 4.33 | 25.95 | 16.40 | 12.38 |
| +ETE | 43.02 | 54.45 | 12.51 | 14.35 | 47.19 | 47.51 | 41.09 | 42.37 | 42.15 | 14.49 |
| +PRT | 47.02 | 56.18 | 13.93 | 14.84 | 50.94 | 43.55 | 39.11 | 32.56 | 42.05 | 16.23 |
| Auto-RT | 46.80 | 56.33 | 10.85 | 15.00 | 47.25 | 47.93 | 41.78 | 34.25 | 43.40 | 15.43 |
🔼 This table presents the results of an ablation study on the AUTO-RT model, specifically analyzing the contributions of two key components: Early-Terminated Exploration (ETE) and Progressive Reward Tracking (PRT). The study evaluates the impact of each component individually and in combination across various large language models (LLMs). The metrics used to assess the effectiveness of the components include Attack Success Rate (ASR), Semantic Diversity (SeD), and Defense Generalization Diversity (DeD). The results show how these components improve the efficiency and effectiveness of discovering vulnerabilities in LLMs.
read the caption
Table 2: Ablation of early-terminated exploration (ETE) and progressive reward tracking (PRT) in Auto-RT. We evaluated the impact of the two components of Auto-RT on different models, and the results demonstrate that both contribute to enhancing strategy exploration.
| AD | HT | PT | Auto-RT | |
|---|---|---|---|---|
| ASRtst ↑ | 55.23 | 37.35 | 11.19 | 38.38 |
| SeD ↓ | 0.86 | 0.36 | - | 0.52 |
| DeD ↑ | 17.88 | 13.15 | 7.27 | 38.19 |
🔼 Table 3 presents a comparison of the attack effectiveness and diversity of Auto-RT against human-crafted attack strategies. The metrics used include attack success rate (ASR), semantic diversity (SeD), and defense generalization diversity (DeD). The results demonstrate that Auto-RT not only achieves high initial attack success rates but also maintains its effectiveness against subsequent attacks employing defensive strategies, highlighting its ability to consistently generate diverse and effective attack strategies.
read the caption
Table 3: Comparison between Auto-RT and human-based strategic attack methods. Auto-RT can continuously generate stable attack strategies.
| Model | Attack Effectiveness (ASRtst) ↑ | Semantic Diversity (SeD) ↓ | Defense Generalization Diversity (DeD) ↑ |
|---|---|---|---|
| Llama 3 70B | |||
| Qwen 2.5 72B | |||
| — | — | — | — |
| FS | 5.49 | 0.87 | 1.17-4.32 |
| IL | 6.80 | 0.64 | 0.92-5.88 |
| RL | 4.99 | 0.53 | 4.15-0.84 |
| Auto-RT | 14.88 | 0.52 | 15.00+0.12 |
| — | — | — | — |
| FS | 3.53 | 0.82 | 3.05-0.48 |
| IL | 6.22 | 0.73 | 1.20-5.02 |
| RL | 4.53 | 0.52 | 4.33-0.2 |
| Auto-RT | 14.47 | 0.61 | 14.15-0.32 |
🔼 This table presents the results of experiments evaluating the performance of AUTO-RT in a black-box setting. Instead of directly accessing model weights for degrading the target models, the approach uses in-context learning. This simulates scenarios where direct access to model internals is unavailable. The table shows attack effectiveness (ASR), semantic diversity (SeD), and defense generalization diversity (DeD) metrics, allowing comparison of the method’s effectiveness and diversity of attacks. Specifically, this is tested using Llama 3 70B Instruct and Qwen 2.5 72B Instruct as target models to test the approach’s capabilities under various constraints.
read the caption
Table 4: Attack performance when using In-Context Learning approach to construct degrade model in black-box setting for simulating models with inaccessible weights.
| RL | +ETE | +PRT | +ETE+PRT(Auto-RT) | |
|---|---|---|---|---|
| Vicuna 7B | 31.95 | 36.54 | 40.50 | 56.40 |
| Vicuna 13B | 17.80 | 22.92 | 35.20 | 55.35 |
| Llama 2 7B Chat | 0.50 | 0.62 | 8.20 | 13.50 |
| Llama 2 13B Chat | 2.05 | 2.46 | 6.80 | 11.00 |
| Llama 3 8B Instruct | 14.55 | 15.00 | 14.60 | 15.00 |
| Mistral 7B Instruct | 44.20 | 48.13 | 47.00 | 52.65 |
| Yi 6B Chat | 33.80 | 35.98 | 42.30 | 52.50 |
| Yi 9B Chat | 39.75 | 49.20 | 44.00 | 49.20 |
| Gemma 2 2b Instruct | 6.15 | 7.38 | 25.30 | 48.15 |
| Gemma 2 9b Instruct | 44.85 | 44.80 | 44.70 | 44.80 |
| R2D2 | 8.60 | 9.07 | 9.80 | 12.45 |
| Qwen 1.5 4B Chat | 17.45 | 22.55 | 32.60 | 51.30 |
| Qwen 1.5 7B Chat | 32.60 | 41.01 | 40.20 | 49.85 |
| Qwen 1.5 14B Chat | 17.75 | 19.58 | 28.30 | 42.50 |
| Qwen 2.5 3B Chat | 20.35 | 22.29 | 30.80 | 42.20 |
| Qwen 2.5 14B Chat | 15.65 | 17.15 | 16.50 | 17.15 |
🔼 This table presents the results of an ablation study evaluating the impact of different components of the AUTO-RT framework on its effectiveness in achieving attack success rates. Specifically, it shows the average attack success rate (ASR) achieved by the AUTO-RT model with various combinations of its core components (Early-terminated Exploration and Progressive Reward Tracking), and compares these results to a baseline RL approach on 16 different large language models. This allows for a quantitative assessment of each component’s contribution to the overall performance of AUTO-RT.
read the caption
Table 5: The ablation results of the Attack Effectiveness with different components on all target models.
| RL | +ETE | +PRT | +ETE+PRT(Auto-RT) | |
|---|---|---|---|---|
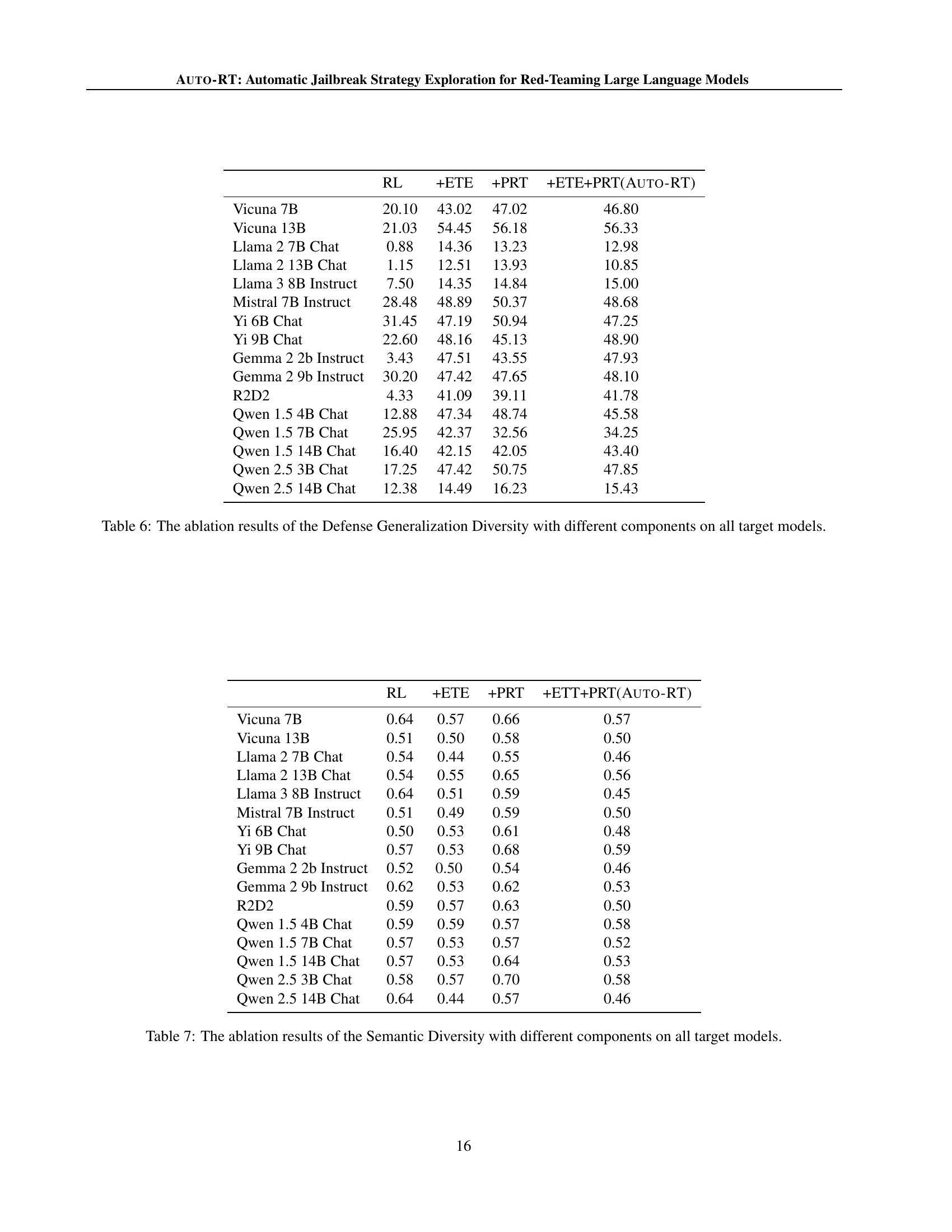
| Vicuna 7B | 20.10 | 43.02 | 47.02 | 46.80 |
| Vicuna 13B | 21.03 | 54.45 | 56.18 | 56.33 |
| Llama 2 7B Chat | 0.88 | 14.36 | 13.23 | 12.98 |
| Llama 2 13B Chat | 1.15 | 12.51 | 13.93 | 10.85 |
| Llama 3 8B Instruct | 7.50 | 14.35 | 14.84 | 15.00 |
| Mistral 7B Instruct | 28.48 | 48.89 | 50.37 | 48.68 |
| Yi 6B Chat | 31.45 | 47.19 | 50.94 | 47.25 |
| Yi 9B Chat | 22.60 | 48.16 | 45.13 | 48.90 |
| Gemma 2 2B Instruct | 3.43 | 47.51 | 43.55 | 47.93 |
| Gemma 2 9B Instruct | 30.20 | 47.42 | 47.65 | 48.10 |
| R2D2 | 4.33 | 41.09 | 39.11 | 41.78 |
| Qwen 1.5 4B Chat | 12.88 | 47.34 | 48.74 | 45.58 |
| Qwen 1.5 7B Chat | 25.95 | 42.37 | 32.56 | 34.25 |
| Qwen 1.5 14B Chat | 16.40 | 42.15 | 42.05 | 43.40 |
| Qwen 2.5 3B Chat | 17.25 | 47.42 | 50.75 | 47.85 |
| Qwen 2.5 14B Chat | 12.38 | 14.49 | 16.23 | 15.43 |
🔼 This table presents the results of an ablation study on the Defense Generalization Diversity metric. The study evaluates the impact of two key components of AUTO-RT, Early-terminated Exploration (ETE) and Progressive Reward Tracking (PRT), on the ability of the model to generate diverse attack strategies that are robust to defensive measures. It shows the Defense Generalization Diversity (DeD) for several baseline methods (RL, RL+ETE, RL+PRT) and AUTO-RT across various large language models (LLMs). Higher DeD values indicate a greater ability to discover diverse strategies that remain effective even after defenses are implemented based on previous attack strategies.
read the caption
Table 6: The ablation results of the Defense Generalization Diversity with different components on all target models.
| RL | +ETE | +PRT | +ETT+PRT(Auto-RT) | |
|---|---|---|---|---|
| Vicuna 7B | 0.64 | 0.57 | 0.66 | 0.57 |
| Vicuna 13B | 0.51 | 0.50 | 0.58 | 0.50 |
| Llama 2 7B Chat | 0.54 | 0.44 | 0.55 | 0.46 |
| Llama 2 13B Chat | 0.54 | 0.55 | 0.65 | 0.56 |
| Llama 3 8B Instruct | 0.64 | 0.51 | 0.59 | 0.45 |
| Mistral 7B Instruct | 0.51 | 0.49 | 0.59 | 0.50 |
| Yi 6B Chat | 0.50 | 0.53 | 0.61 | 0.48 |
| Yi 9B Chat | 0.57 | 0.53 | 0.68 | 0.59 |
| Gemma 2 2b Instruct | 0.52 | 0.50 | 0.54 | 0.46 |
| Gemma 2 9b Instruct | 0.62 | 0.53 | 0.62 | 0.53 |
| R2D2 | 0.59 | 0.57 | 0.63 | 0.50 |
| Qwen 1.5 4B Chat | 0.59 | 0.59 | 0.57 | 0.58 |
| Qwen 1.5 7B Chat | 0.57 | 0.53 | 0.57 | 0.52 |
| Qwen 1.5 14B Chat | 0.57 | 0.53 | 0.64 | 0.53 |
| Qwen 2.5 3B Chat | 0.58 | 0.57 | 0.70 | 0.58 |
| Qwen 2.5 14B Chat | 0.64 | 0.44 | 0.57 | 0.46 |
🔼 This table presents a detailed breakdown of the impact of different components within the AUTO-RT framework on the semantic diversity of generated attack strategies. It shows how the inclusion of early-terminated exploration (ETE) and progressive reward tracking (PRT) individually and in combination affects the diversity of attacks across various language models. Lower values of semantic diversity (SeD) indicate higher diversity.
read the caption
Table 7: The ablation results of the Semantic Diversity with different components on all target models.
Full paper#