↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current robotic manipulation models struggle with planning future actions based on real-time observations due to data scarcity and the difficulty of aligning various modalities (language, vision, action). Many existing methods are limited by their reliance on large-scale datasets, complex algorithms, or the representational capacity of language, particularly for complex tasks. Additionally, the sim-to-real gap makes it difficult to transfer knowledge gained in simulation to real-world scenarios.
EnerVerse tackles these challenges head-on. It introduces a novel framework that leverages convolutional and bidirectional attention mechanisms for robust future space generation, incorporating a sparse memory context for handling long sequences and a Free Anchor View (FAV) space that enhances observation and analysis. The system further includes a data engine pipeline integrating a generative model with 4D Gaussian Splatting to iteratively improve data quality, thus bridging the sim-to-real gap. Experiments demonstrate that EnerVerse substantially enhances policy predictive capabilities, resulting in improved performance, particularly for long-range manipulation tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical challenge of data scarcity and sim-to-real gap in robotics by introducing a novel data engine pipeline. It significantly advances embodied AI by proposing a comprehensive framework for generating high-quality, diverse robotic manipulation datasets and enhancing the model’s predictive capabilities. This work also introduces the concept of Free Anchor View, offering enhanced flexibility and adaptability across various tasks and settings. The proposed method’s success in long-range tasks opens exciting avenues for future research in robotic manipulation and embodied AI.
Visual Insights#

🔼 EnerVerse is composed of three main parts: initial reconstruction, free anchor view rendering, and chunk-wise autoregressive generation. Initial reconstruction creates a 3D point cloud from camera images mounted on the robot, using anchor views to adapt to the environment and specific task needs. Free anchor view rendering then generates images from these anchor points, offering a comprehensive view of the scene. Finally, chunk-wise autoregressive generation uses a multi-view video diffusion model to create sequences of images in chunks, guided by task instructions. A policy head can then be added to generate the robot actions needed to complete the task.
read the caption
Figure 1: The overview of our proposed EnerVerse model, consisting of three key components. First, Initial Reconstruction uses observation images from cameras mounted on the robot to build an initial 3D point cloud, with anchor views set to adapt to the environment and meet task-specific requirements. Second, Free Anchor View Renders generates rendered images from these anchor perspectives to provide comprehensive scene representations. Finally, Chunk-wise Autoregressive Generation employs a multi-view video diffusion to produce image sequences in chunks based on task instructions. When integrated with a policy head, this module can generate robotic actions to execute the given task.
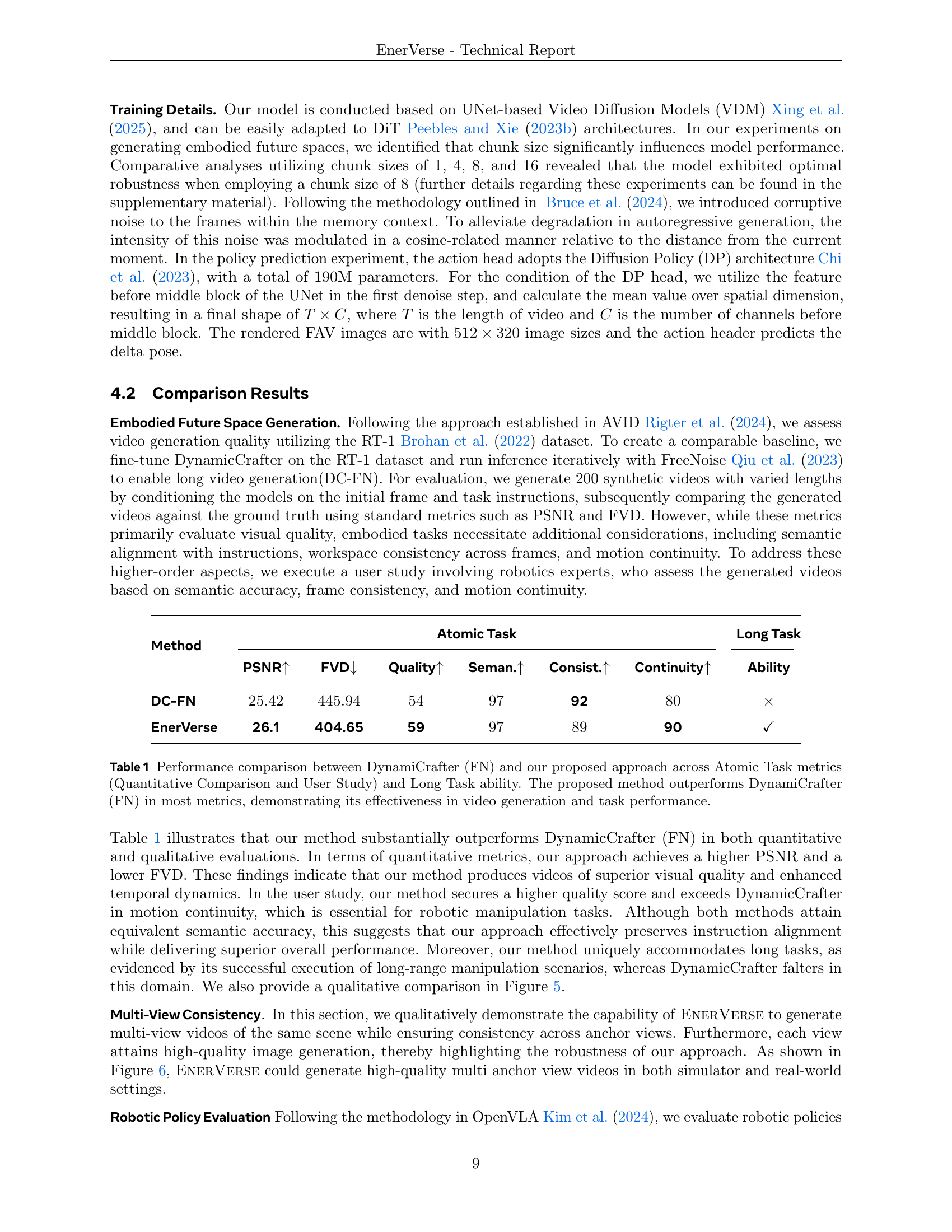
| Method | PSNR↑ | FVD↓ | Quality↑ | Seman↑ | Consist↑ | Continuity↑ | Long Task |
|---|---|---|---|---|---|---|---|
| DC-FN | 25.42 | 445.94 | 54 | 97 | 92 | 80 | × |
| EnerVerse | 26.1 | 404.65 | 59 | 97 | 89 | 90 | ✓ |
🔼 This table presents a quantitative and qualitative comparison of video generation performance between DynamicCrafter (with FreeNoise, denoted as DC-FN), a state-of-the-art baseline video generation model, and the proposed EnerVerse model. The comparison is done across several metrics related to video quality (PSNR and FVD), and task performance (Semantic Alignment, Consistency, Continuity, and Long Task Ability). Atomic Task metrics assess performance on short, simple tasks, while Long Task Ability evaluates performance on longer, more complex tasks. A user study involving robotics experts contributed to the qualitative assessment. The results demonstrate that EnerVerse significantly outperforms the baseline in most metrics, highlighting its improved performance in both video generation and robotic manipulation tasks.
read the caption
Table 1: Performance comparison between DynamiCrafter (FN) and our proposed approach across Atomic Task metrics (Quantitative Comparison and User Study) and Long Task ability. The proposed method outperforms DynamiCrafter (FN) in most metrics, demonstrating its effectiveness in video generation and task performance.
In-depth insights#
Embodied Future Space#
The concept of “Embodied Future Space” in robotics research represents a significant advancement in enabling robots to more effectively plan and execute complex manipulation tasks. It moves beyond simply reacting to immediate sensory input by allowing robots to generate predictions about the future states of the environment. This predictive capability is achieved by constructing a model that projects likely future scenarios based on current observations and task goals. This predictive model goes beyond simple extrapolation, integrating factors like physics, object properties, and the robot’s own actions. The crucial aspect is the embodiment; the future space isn’t an abstract representation, but rather grounded in the physical realities of the robot’s interaction with the world. This grounding allows for more robust and adaptable decision-making, particularly in dynamic and unpredictable environments. By considering the entire embodied future space, robots can anticipate potential obstacles, plan sequences of actions more effectively, and ultimately achieve a higher degree of success in complex manipulation tasks.
Chunkwise Generation#
The concept of “Chunkwise Generation” in the context of video prediction for robotics is a clever approach to address the challenges of generating long, coherent video sequences. By breaking down the generation process into smaller, manageable chunks, the model can maintain consistency and continuity more effectively. This chunking strategy allows the model to better focus on local temporal dependencies within each chunk, thus improving the accuracy and realism of the generated frames. This approach is particularly beneficial for tasks requiring long-range prediction, as it mitigates the accumulation of errors that can occur when generating very long sequences in a single pass. The use of bidirectional attention within each chunk further enhances the quality of the generated videos by allowing the model to capture both past and future context. The combination of chunking and bidirectional attention strikes a balance between local and global context awareness, resulting in a more robust and generalized model.
Free Anchor View#
The concept of “Free Anchor View” (FAV) presents a significant advancement in robotic perception. Instead of relying on fixed camera positions, FAV allows for flexible, arbitrarily positioned virtual viewpoints. This offers crucial advantages, particularly in challenging environments with physical constraints or occlusion issues. By generating rendered images from these FAVs, the system mitigates motion modeling ambiguities inherent in body-mounted cameras and enhances the robot’s adaptability across diverse tasks and settings. The generation of multi-view perspectives from FAV implicitly constructs a richer 3D understanding of the scene, thereby significantly improving the accuracy and robustness of downstream tasks like manipulation and planning. Furthermore, the use of FAVs addresses the limitations of traditional, static camera setups, creating a more generalized and adaptable approach to robotic vision. This is especially beneficial for complex tasks demanding whole-body motion or navigating confined spaces. The innovative integration of FAVs with a data engine pipeline employing 4D Gaussian Splatting (4DGS) demonstrates a practical strategy for generating high-quality data, effectively bridging the sim-to-real gap, and bolstering the overall effectiveness of the approach.
Data Engine#
The ‘Data Engine’ concept presented in this research paper is crucial for bridging the sim-to-real gap in robotic manipulation. The core idea revolves around iteratively improving data quality and diversity using a generative model and 4D Gaussian Splatting (4DGS). This synergistic approach creates a data flywheel effect, where synthetic data generated by the model is enhanced through 4DGS, leading to more realistic and varied training data. This cycle continuously refines the model’s understanding of real-world scenarios, ultimately improving the performance of the robotic manipulation system. The focus on multi-camera observations, realized through the Free Anchor View (FAV) system, further enhances the richness and completeness of the training data, addressing limitations of traditional single-view approaches. This makes the training data more robust and generalizable, a significant contribution toward creating more adaptable and reliable robots. The emphasis is on generating high-quality data efficiently, mitigating the high costs and labor involved in traditional methods, making the system both effective and scalable.
Policy Integration#
Policy integration in robotics research involves seamlessly merging learned policies with other model components, such as perception and world modeling. Effective policy integration is crucial for enabling robots to translate high-level goals into appropriate actions in complex and dynamic environments. The challenge lies in creating robust and adaptable systems that can handle noisy sensor data, unpredictable events, and the inherent uncertainties of the physical world. Successful integration often requires careful consideration of the interplay between various model components and their respective learning processes. Techniques such as reinforcement learning, imitation learning, and direct policy optimization are frequently used, but their success hinges on the effective alignment of policies with other modules. A deep understanding of the task, environment, and robot capabilities is essential for designing successful policy integration strategies. Furthermore, efficient and scalable methods are needed to enable real-time performance in complex scenarios. The choice of policy architecture and training methods will significantly affect the performance and adaptability of the overall robotic system. Finally, rigorous evaluation is critical to assess the effectiveness of the policy integration approach and identify areas for improvement.
More visual insights#
More on figures

🔼 Figure 2 illustrates the ENERVERSE model’s next-chunk diffusion process. Panel (a) details how multi-view observations and ray direction maps from camera 𝑖 are used to generate initial 3D reconstructions. These reconstructions form the basis for creating several Free Anchor Views (FAVs). A rendered frame from a FAV serves as context for subsequent chunks. The ray direction map is concatenated with the video latent to synthesize the next FAV sequence. Camera observations are optional, only used when cameras are static. Panel (b) shows the chunk-wise autoregressive training process. Randomly selected clean frames from consecutive sequences are combined with noisy frames to predict denoised latents iteratively until an End-of-Sequence (EOS) frame is reached. While (b) shows one view for simplicity, the model supports multi-view generation.
read the caption
Figure 2: The architecture of our proposed next-chunk diffusion model. As shown in Figure (a), a sequence of observational frames, captured by camera i𝑖iitalic_i and accompanied by the corresponding ray direction map, is utilized as observation priors. Leveraging these camera observations, an initial 3D reconstruction is obtained through depth wrapping and rendering Lassner and Zollhofer (2021), then several Free Anchor Views are established accordingly. In addition to camera observational frames, a render frame from the FAV is also employed as context priors for the subsequent chunk diffusion models. To synthesize the anchor view i+1𝑖1i+1italic_i + 1 sequence, the respective ray direction map is concatenated with the video latent. Notably, the observational image from the camera is optional and used only when the camera is static. If all sensors are in motion, the rendered image alone can serve as the context prior. In the context of the chunk-wise autoregressive training process, as depicted in Figure (b), clean frames selected at random from consecutive sequences are concatenated with noisy frames to forecast denoised latents. During the inference phase, once denoised frames are produced, they are utilized as the new set of clean frames for the following inference step. This iterative process persists until the predefined End-Of-Sequence (EOS) frame is encountered. Notably, we visualize only one view in Figure (b) to simplify the demonstration of the autoregressive generation process, but multi-view generation is fully supported by the model.

🔼 EnerVerse uses a data engine pipeline to iteratively improve the quality of its training data. The pipeline starts with real-world observations from multiple cameras and rendered images from virtual anchor views. These images are fed into a multi-view video generator to produce denoised videos. The videos, along with camera pose information, are then used by 4D Gaussian Splatting (4DGS) to reconstruct a 4D scene representation. This 4D model is then rendered from the anchor views to create high-precision images, which are fed back into the pipeline. This iterative process refines the data, improving motion consistency and reconstruction quality, and bridges the sim-to-real gap. The resulting high-fidelity data is suitable for training robotic manipulation tasks.
read the caption
Figure 3: The pipeline for EnerVerse as a data engine. Observation images captured from multiple cameras, along with rendered images from anchor views, are processed by the multi-view video generator to produce denoised multi-view videos. These videos, paired with their corresponding camera poses, are utilized in 4D Gaussian Splatting (4D GS) for 4D scene reconstruction. The reconstructed content is rendered from anchor views to generate high-precision images, which are iteratively fed back into the pipeline to enhance motion consistency and reconstruction quality. This iterative loop combines geometric consistency with generative refinement, delivering high-fidelity outputs for tasks such as robotic manipulation.

🔼 Figure 4 illustrates the generation of Free Anchor Views (FAVs) within the LIBERO benchmark. A single observation image (Anchor View 1) is captured by a camera mounted on the robot. This image is then processed to reconstruct a 3D point cloud representing the scene. Using this point cloud, two additional synthetic views (Anchor Views 2 and 3) are rendered from different perspectives. These synthetic views demonstrate the ability of the system to generate varied viewpoints from a single observation, enriching the robot’s understanding of the scene beyond what is visible from a single camera angle.
read the caption
Figure 4: Visualization of FAVs generation on the LIBERO benchmark. Anchor View 1 represents the observation image captured by a mounted camera. Anchor View 2 and Anchor View 3 are generated by rendering from a point cloud reconstructed from Anchor View 1 using depth wrapping.

🔼 Figure 5 presents a qualitative comparison of single-view video generation between EnerVerse and DynamiCrafter (with FreeNoise) using the RT-1 dataset. EnerVerse correctly predicts the end-of-sequence (EOS) frame at the 42nd frame. The figure shows frames 8, 16, 24, and 41 from both models’ generated sequences. DynamiCrafter’s output loses logical coherence and contains many hallucinations as the sequence length increases. In contrast, EnerVerse generates a logically coherent and complete future space for the entire task, correctly predicting the EOS frame, highlighting its superior performance in long-range tasks.
read the caption
Figure 5: Qualitative comparison for single view video generation between EnerVerse and DynamiCrafter(FN) on RT-1 dataset. Since EnerVerse predict EOS frame at 42th frame for this task, we visualize 8th, 16th, 24th and 41th frame sampled from both generated sequence. The sequences generated by DynamiCrafter(FN) did not maintain the logic of the long-range task, producing many hallucinations as the sequence grew. In contrast, the sequence generated by EnerVerse was logically coherent, continuously and completely generating the future space of the entire task, and accurately predicting the EOS (End of Sequence) frame.

🔼 Figure 6 presents a qualitative comparison of multi-anchor view video generation. The left side shows results from the LIBERO benchmark, a simulated robotics environment, while the right side showcases results from real-world robotic manipulation tasks collected using the AgiBot World dataset. In both scenarios, one camera view is fixed (an RGB sensor), and several generated anchor views offer additional perspectives. The generated frames are evenly sampled from the full sequence. To highlight the consistency of the generated objects across different views, red rectangles are used to outline the objects.
read the caption
Figure 6: Qualitative results for multi anchor view generation on LIBERO benchmark (left) and real-world manipulation data (right), collected from AgiBot World AgiBot (2024). One view is overlapped with a fixed RGB sensor and other views are manully set. Visualized Frames are uniformly sampled from generated sequence. We emphasize the consistency of objects across views by highlighting them with a red rectangle.

🔼 This figure demonstrates the impact of using a sparse memory mechanism versus a consecutive memory mechanism on video generation. The top row shows the results of using consecutive frames as context for the generation model. This approach leads to instability and model collapse, as evidenced by the degradation in video quality and coherence. The bottom row shows the improved results of using a sparse memory mechanism, which selectively retains only the most important historical frames. This approach significantly enhances the robustness of the generation model and avoids model collapse, resulting in significantly improved video quality. Furthermore, the sparse method reduces computational resources.
read the caption
Figure 7: Ablation results for context memory mechanism in video generation. Providing history information to the generation model with consecutive context (first line) often leads to unexpected model collapse while the model with sparse memory (second line) shows robust performance and save mush computing resources.

🔼 This figure visualizes attention maps from different layers and heads within the model’s architecture. Each map shows the model’s attention distribution when predicting actions over eight time steps. The y-axis represents the predicted action space (Query), while the x-axis represents the Key-Value space containing information from both the sparse memory (first four columns) and the predicted future space (last eight columns). The color intensity (yellow to dark red) represents the attention weight, with yellow indicating high attention and dark red indicating low attention. These visualizations demonstrate how the model balances its attention between previously stored information (sparse memory) and future predictions when making action decisions. The shift in attention from sparse memory to future predictions over time is also highlighted.
read the caption
Figure 8: Attention maps from different attention heads and layers of the model. The y-axis represents the predicted action space (the Query), spanning 8 steps, while the x-axis represents the Key-Value space. The first 4 columns in the KV space correspond to information from the Sparse Memory space, while the last 8 columns correspond to the predicted future space. These maps highlight how the model attends to sparse memory conditions (left) and future space conditions (right) when predicting actions. The bright yellow indicates a higher attention score while dark red indicates a lower one.
More on tables
| Model | Visual Input | Spatial | Object | Goal | Long | Avg. |
|---|---|---|---|---|---|---|
| Diffusion Policy | One Third View | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Octo | One Third View | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| OpenVLA | One Third View | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| MDT | One Third & One Wrist View | 78.5 | 87.5 | 73.5 | 64.8 | 76.1 |
| One Third & One Wrist View | 74.3 | 90.1 | 81.8 | 78.6 | 83.5 | |
| EnerVerse | One FAV | 92.1 | 93.2 | 78.1 | 73.0 | 84.1 |
| EnerVerse | Three FAVs | 91.2 | 97.7 | 85.0 | 80.0 | 88.5 |
🔼 This table presents a quantitative comparison of different robotic policy models on the LIBERO benchmark, a standard test suite for evaluating robotic manipulation skills. The benchmark consists of four sub-suites (Spatial, Object, Goal, and Long), each assessing different aspects of robotic capabilities. The table shows the success rate of each model across these sub-suites under two different input scenarios: a single camera view and three camera views (representing multiple perspectives). ENERVerse, the proposed model in the paper, is compared against several other state-of-the-art models. The results highlight ENERVerse’s superior performance, especially when utilizing multiple visual inputs, demonstrating its ability to effectively integrate information from multiple perspectives and improve task completion success.
read the caption
Table 2: Evaluation results on the LIBERO benchmark across four task suites. Our method achieves superior performance in both single and multi-visual input settings.
| Setup | w/o Sparse Memory | w Sparse Memory |
|---|---|---|
| LIBERO-Long-SV | 30.8 | 73 |
🔼 This table presents a comparison of the performance on the LIBERO-Long task, a subset of the LIBERO benchmark focusing on long-range manipulation tasks, with and without the use of a sparse memory mechanism within the ENERVERSE model. It highlights how the sparse memory mechanism improves model robustness and efficiency by reducing redundancy and mitigating the risk of model collapse, particularly during the handling of long sequences. The table likely shows success rates or other relevant metrics to quantify this performance difference.
read the caption
Table 3: Performance comparison on the LIBERO-Long task with and without Sparse Memory.
| Strategy | All-Scratch | With DC Pretrain. | One-Stage Co-Train | Two-Stage Finetune |
|---|---|---|---|---|
| LIBERO-Spatial | Failed | 79 | 86.3 | 92.1 |
🔼 This table presents a comparison of four different training strategies used for the robotic policy in the LIBERO-Spatial task suite. The strategies are: training from scratch, training with pretrained weights from a general video generator, one-stage co-training (optimizing both the policy and video generation simultaneously), and a two-stage approach (pretraining the video generator and then fine-tuning with only the policy loss). The metric used to evaluate these strategies is the task success rate, representing the percentage of successful task completions.
read the caption
Table 4: Performance comparison of different training strategies on the LIBERO-Spatial task suite. The metrics are the task success rates.
Full paper#