↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current multimodal large language models (MLLMs) primarily focus on integrating vision and text, neglecting the crucial role of speech in natural interaction. This often leads to performance limitations and latency issues due to the need for separate automatic speech recognition (ASR) and text-to-speech (TTS) modules. Furthermore, modality conflicts during training can hinder the development of truly multimodal systems.
This paper introduces VITA-1.5, a novel MLLM that addresses these challenges through a three-stage training approach. It progressively introduces speech data, starting with vision-language training, followed by audio input processing, and finally, end-to-end speech generation. This approach effectively mitigates modality conflicts and allows for fluent, real-time interactions. VITA-1.5’s performance on various image, video, and speech benchmarks demonstrates its strong multimodal capabilities and near real-time efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it presents VITA-1.5, a significant advancement in real-time multimodal interaction. It addresses the challenge of integrating vision and speech in LLMs, a crucial area for human-computer interaction. The open-source nature of VITA-1.5 fosters further research and development in this field, potentially leading to more natural and efficient human-computer interfaces.
Visual Insights#

🔼 Figure 1 showcases VITA-1.5’s real-time vision and speech interaction capabilities. The image displays a user interacting with the system using a mobile phone equipped with a camera. The model processes both visual input from the camera and audio from the user’s speech, enabling a fluent conversational interaction. The image highlights the system’s end-to-end nature, suggesting seamless integration of visual and audio processing within the language model. A YouTube link is provided for a demonstration video, allowing readers to directly experience the model’s functionality.
read the caption
Figure 1: VITA-1.5 enables near real-time vision and speech interaction via an end-to-end framework. It allows you to turn on the camera and have a fluent speech conversation. Please see our demo video at this YouTube link.
| Data Scenario | QA Type | Dataset Name | Questions (K) | Language |
|---|---|---|---|---|
| General Image | Description | ShareGPT4V | 99.50 | Eng |
| ALLaVA-Caption | 697.40 | Eng | ||
| ShareGTP4o-Image | 55.50 | Eng | ||
| Synthetic Data | 593.70 | CN | ||
| General Image | QA | LLaVA-150K | 218.36 | CN |
| LLaVA-Mixture-sample | 1872.10 | Eng | ||
| LVIS-Instruct | 939.36 | Eng | ||
| ScienceQA | 12.72 | Eng | ||
| ChatQA | 7.39 | Eng | ||
| LLaVA-OV General | 1754.65 | Eng | ||
| LLaVA-OV Math Reasoning | 1140.92 | Eng | ||
| Synthetic Data | 212.68 | CN | ||
| OCR & Diagram | Description | Anyword-3M | 1709.30 | CN |
| ICDAR2019-LSVT | 366.30 | CN | ||
| UReader | 100.00 | Eng | ||
| SynDOG-EN | 100.00 | Eng | ||
| SynDOG-CN | 101.90 | CN | ||
| OCR & Diagram | QA | ICDAR2019-LSVT-QA | 630.08 | CN |
| LLaVA-OV Doc Chart Screen | 4431.50 | Eng | ||
| LLaVA-OV General OCR | 404.20 | Eng | ||
| General Video | Description | ShareGemini | 205.70 | CN |
| Synthetic Data | 569.40 | CN & Eng | ||
| General Video | QA | Synthetic Data | 4336.30 | CN & Eng |
| Pure Text | QA | Synthetic Data | 1574.20 | CN & Eng |
| Total | 22133.16 | CN & Eng |
🔼 Table 1 details the datasets used for training the VITA-1.5 multimodal large language model. It’s broken down by data type (image captioning, image QA, OCR & diagrams, video data, and pure text data), providing the dataset name, number of questions (in thousands), and language(s) for each. Synthetic image data was generated using open-source datasets like Wukong, LAION, and CC12M.
read the caption
Table 1: Training data of multimodal instruction tuning. The images of the synthetic data come from open-source datasets like Wukong [19], LAION [46], and CC12M [5].
In-depth insights#
Multimodal LLM#
Multimodal LLMs represent a significant advancement in AI, integrating multiple modalities like text, vision, and speech for enhanced interaction and understanding. Current research focuses heavily on vision-language integration, but speech is crucial for natural, real-time interaction. The challenge lies in effectively combining these modalities, as their inherent differences can lead to training conflicts and reduced performance. A key area of focus is developing efficient training methodologies that progressively incorporate each modality, mitigating these conflicts. For example, some approaches start with vision-language training and subsequently add speech, while carefully managing the model’s capacity to handle all input types. Efficient speech processing is another key focus, aiming to replace separate ASR and TTS modules with end-to-end models to reduce latency and improve coherence. Ultimately, the goal is to create multimodal LLMs that achieve near real-time, human-like interactions, significantly expanding the capabilities and potential applications of large language models.
3-Stage Training#
The paper’s proposed “3-Stage Training” strategy offers a compelling approach to multimodal learning by sequentially introducing visual, audio, and speech generation capabilities. Stage 1 focuses solely on vision and language, establishing a strong foundation before introducing audio. This staged approach cleverly mitigates potential conflicts between modalities, preventing the introduction of speech data from negatively impacting visual understanding. Stage 2 integrates audio understanding, building upon the existing vision-language model. The careful addition of audio data, coupled with a speech encoder, allows the model to process and comprehend speech input effectively, paving the way for speech generation. Finally, Stage 3 enables end-to-end speech generation, eliminating the need for external TTS systems and streamlining the process significantly. This innovative method enhances efficiency and leads to more natural, real-time multimodal interaction. The strategy’s progressive nature is key, ensuring that each modality is integrated effectively without compromising performance in other domains. This is a significant advancement in multimodal learning, highlighting a thoughtful methodology for achieving high-performance, real-time systems.
Speech Integration#
The integration of speech capabilities into large language models (LLMs) presents a significant challenge, but also a substantial opportunity for creating more natural and versatile AI systems. This paper’s approach tackles the inherent difficulties of integrating speech with vision and text modalities in LLMs by employing a multi-stage training methodology. This strategy mitigates modality conflicts by progressively introducing speech data, ensuring the model maintains its vision-language capabilities while effectively acquiring speech understanding and generation abilities. The omission of separate Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) modules is a key innovation, contributing to significant improvements in real-time performance. This end-to-end approach directly outputs speech, thus enhancing fluency and naturalness of interaction. Furthermore, the evaluation results demonstrate the success of this strategy, showcasing comparable performance to existing advanced models on vision-language benchmarks, and leading performance on speech tasks. The three-stage training allows a systematic integration of speech, while mitigating potential negative influences on other modalities. Ultimately, this research makes a strong contribution to the field by demonstrating a viable path for creating truly multimodal LLMs, enabling more seamless and natural human-computer interaction.
Real-Time Interaction#
The concept of “Real-Time Interaction” in the context of vision and speech interaction within large language models (LLMs) is a crucial advancement. The paper highlights the challenges of integrating speech with vision and text modalities, noting that prior models often relied on separate Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) modules, leading to latency and reduced coherence. VITA-1.5 addresses this by proposing a novel end-to-end training methodology that eliminates the need for external ASR and TTS components, resulting in a significant speed boost and improved naturalness of interaction. This approach fosters a more fluid and natural dialogue, bridging the gap between human-computer interaction and the capabilities of LLMs. The near real-time performance achieved by VITA-1.5 demonstrates a significant step forward, enabling more practical applications in fields like virtual assistants and human-computer interaction systems. The focus on efficiency and seamless integration underscores the importance of optimizing LLMs for interactive, real-time applications. Future development in this area will likely emphasize reducing computational costs further, while maintaining or improving the quality of real-time responses and expanding the range of supported languages and dialects.
Open-Source model#
The proliferation of open-source large language models (LLMs) is rapidly transforming the field of artificial intelligence, offering researchers and developers unprecedented access to powerful tools and fostering rapid innovation. This trend is especially significant in the multimodal domain, where open-source models are striving to match the capabilities of their closed-source counterparts. A key challenge highlighted in the research is the integration of vision and speech modalities, which is significantly more complex than integrating only vision and text. While several open-source models excel in vision-language tasks, they often lag behind in speech capabilities, sometimes relying on external, potentially latency-inducing modules like ASR and TTS. The paper’s contribution, VITA-1.5, directly addresses this challenge by implementing an end-to-end speech generation module, eliminating the need for external systems and significantly accelerating response times. This advancement underscores the importance of open-source initiatives not only for accessibility but also for pushing the boundaries of what is possible in multimodal AI. VITA-1.5’s success in nearing real-time vision and speech interaction with strong performance on relevant benchmarks serves as a strong example for future open-source developments. This success shows the potential for open-source models to match and eventually surpass the capabilities of closed-source models in the near future.
More visual insights#
More on figures

🔼 VITA-1.5’s architecture integrates vision and audio encoders with adapters, connecting them to a large language model (LLM). Unlike its predecessor, VITA-1.0, it features an end-to-end speech generation module, eliminating the need for a separate text-to-speech (TTS) system. This design improves efficiency and coherence in speech output.
read the caption
Figure 2: Overall Architecture of VITA-1.5. The input side consists of vision and audio encoders, along with their adapters connected to a LLM. The output side has an end-to-end speech generation module, rather than directly using an external TTS model as the initial VITA-1.0 version [16].

🔼 This figure illustrates the three-stage training pipeline of the VITA-1.5 model. Each stage progressively integrates a new modality (vision and then audio) into the Language Learning Model (LLM), mitigating conflicts between modalities. Stage 1 focuses solely on vision and language, establishing the model’s visual understanding. Stage 2 introduces audio input processing, enabling the model to understand and respond to audio. Finally, Stage 3 develops speech output capabilities, enabling end-to-end speech generation without external TTS modules. The figure details the specific data used at each stage and the proportions used, referring to Table 1 for exact figures. It shows the model architecture and data flow at each training stage, clearly illustrating the incremental approach to multi-modal learning.
read the caption
Figure 3: Training Pipeline of VITA-1.5. The training process is divided into three stages to incrementally incorporate vision and audio into the LLM while relieving modality conflicts. Stage I focuses on Vision-Language Training, including vision alignment (Stage 1.1, using 20% caption data from Table 1), vision understanding (Stage 1.2, using 100% caption data), and instruction tuning for visual QA (Stage 1.3, using 20% caption data and 100% QA data). Stage 2 introduces Audio Input Tuning, with audio alignment (Stage 2.1, utilizing 11,000 hours of speech-transcription pairs) and instruction tuning for speech QA (Stage 2.2, sampling 4% caption data and 20% QA data). Finally, Stage 3 focuses on Audio Output Tuning, including the training of the codec model (Stage 3.1, using 3,000 hours of text-speech data) and speech decoder training (Stage 3.2). The percentages shown in the image correspond to the data sampling ratios specified in Table 1.
More on tables
| Questions (K) |
|---|
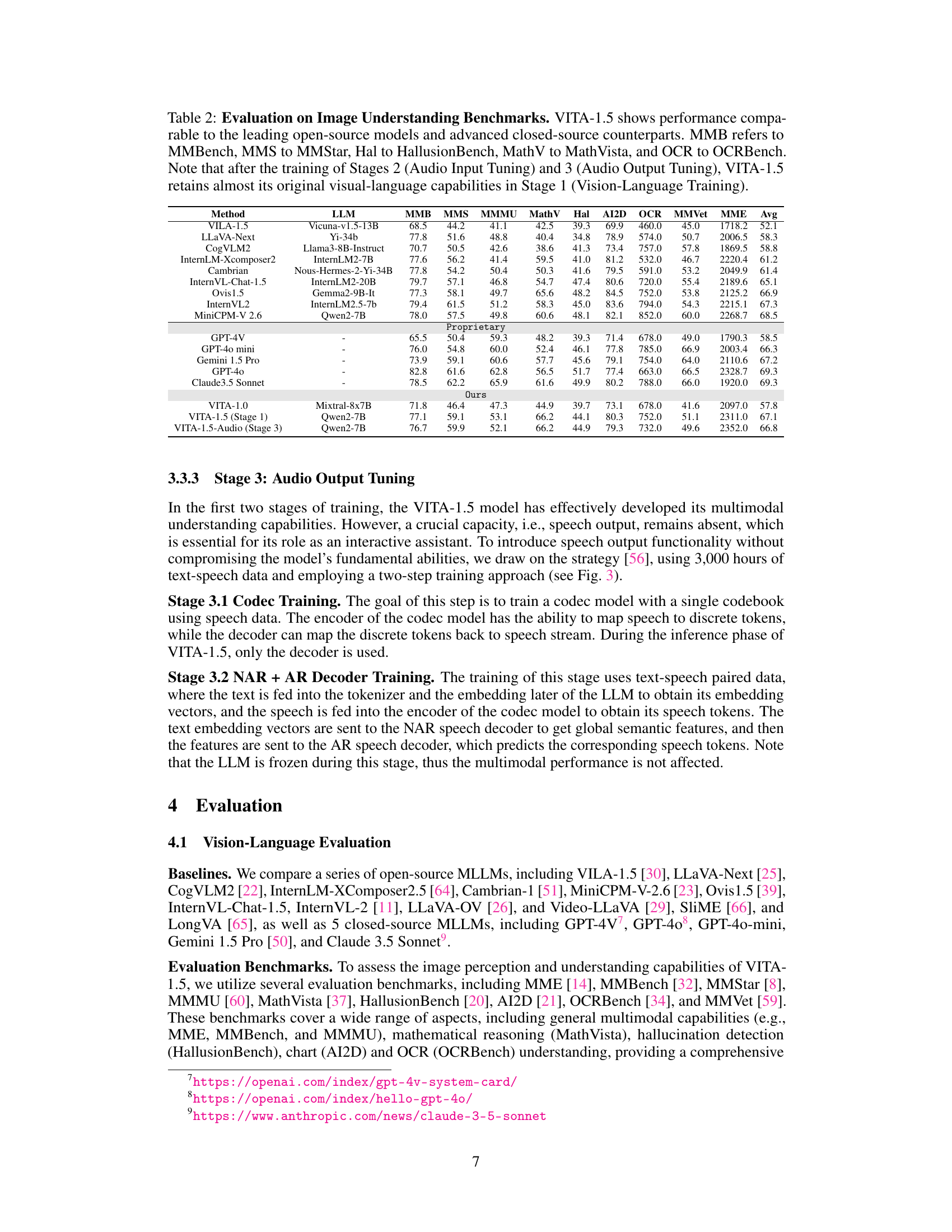
🔼 Table 2 presents a comprehensive evaluation of VITA-1.5’s image understanding capabilities by comparing its performance against leading open-source and closed-source large language models (LLMs) across multiple benchmark datasets. These benchmarks assess various aspects of image understanding, including general multimodal capabilities (MMBench, MMStar), hallucination detection (HallusionBench), mathematical reasoning (MathVista), and optical character recognition (OCRBench). The results show that VITA-1.5 achieves performance comparable to top-performing models, demonstrating its robust image understanding abilities. Importantly, the table also highlights that the model retains its strong visual-language capabilities even after undergoing additional audio training stages (Stages 2 and 3).
read the caption
Table 2: Evaluation on Image Understanding Benchmarks. VITA-1.5 shows performance comparable to the leading open-source models and advanced closed-source counterparts. MMB refers to MMBench, MMS to MMStar, Hal to HallusionBench, MathV to MathVista, and OCR to OCRBench. Note that after the training of Stages 2 (Audio Input Tuning) and 3 (Audio Output Tuning), VITA-1.5 retains almost its original visual-language capabilities in Stage 1 (Vision-Language Training).
| Method | LLM | MMB | MMB | MMS | MMMU | MathV | Hal | AI2D | OCR | MMVet | MME | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VILA-1.5 | Vicuna-v1.5-13B | 68.5 | 44.2 | 41.1 | 42.5 | 39.3 | 69.9 | 460.0 | 45.0 | 1718.2 | 52.1 | |
| LLaVA-Next | Yi-34b | 77.8 | 51.6 | 48.8 | 40.4 | 34.8 | 78.9 | 574.0 | 50.7 | 2006.5 | 58.3 | |
| CogVLM2 | Llama3-8B-Instruct | 70.7 | 50.5 | 42.6 | 38.6 | 41.3 | 73.4 | 757.0 | 57.8 | 1869.5 | 58.8 | |
| InternLM-Xcomposer2 | InternLM2-7B | 77.6 | 56.2 | 41.4 | 59.5 | 41.0 | 81.2 | 532.0 | 46.7 | 2220.4 | 61.2 | |
| Cambrian | Nous-Hermes-2-Yi-34B | 77.8 | 54.2 | 50.4 | 50.3 | 41.6 | 79.5 | 591.0 | 53.2 | 2049.9 | 61.4 | |
| InternVL-Chat-1.5 | InternLM2-20B | 79.7 | 57.1 | 46.8 | 54.7 | 47.4 | 80.6 | 720.0 | 55.4 | 2189.6 | 65.1 | |
| Ovis1.5 | Gemma2-9B-It | 77.3 | 58.1 | 49.7 | 65.6 | 48.2 | 84.5 | 752.0 | 53.8 | 2125.2 | 66.9 | |
| InternVL2 | InternLM2.5-7b | 79.4 | 61.5 | 51.2 | 58.3 | 45.0 | 83.6 | 794.0 | 54.3 | 2215.1 | 67.3 | |
| MiniCPM-V 2.6 | Qwen2-7B | 78.0 | 57.5 | 49.8 | 60.6 | 48.1 | 82.1 | 852.0 | 60.0 | 2268.7 | 68.5 | |
| Proprietary | ||||||||||||
| GPT-4V | - | 65.5 | 50.4 | 59.3 | 48.2 | 39.3 | 71.4 | 678.0 | 49.0 | 1790.3 | 58.5 | |
| GPT-4o mini | - | 76.0 | 54.8 | 60.0 | 52.4 | 46.1 | 77.8 | 785.0 | 66.9 | 2003.4 | 66.3 | |
| Gemini 1.5 Pro | - | 73.9 | 59.1 | 60.6 | 57.7 | 45.6 | 79.1 | 754.0 | 64.0 | 2110.6 | 67.2 | |
| GPT-4o | - | 82.8 | 61.6 | 62.8 | 56.5 | 51.7 | 77.4 | 663.0 | 66.5 | 2328.7 | 69.3 | |
| Claude3.5 Sonnet | - | 78.5 | 62.2 | 65.9 | 61.6 | 49.9 | 80.2 | 788.0 | 66.0 | 1920.0 | 69.3 | |
| Ours | ||||||||||||
| VITA-1.0 | Mixtral-8x7B | 71.8 | 46.4 | 47.3 | 44.9 | 39.7 | 73.1 | 678.0 | 41.6 | 2097.0 | 57.8 | |
| VITA-1.5 (Stage 1) | Qwen2-7B | 77.1 | 59.1 | 53.1 | 66.2 | 44.1 | 80.3 | 752.0 | 51.1 | 2311.0 | 67.1 | |
| VITA-1.5-Audio (Stage 3) | Qwen2-7B | 76.7 | 59.9 | 52.1 | 66.2 | 44.9 | 79.3 | 732.0 | 49.6 | 2352.0 | 66.8 |
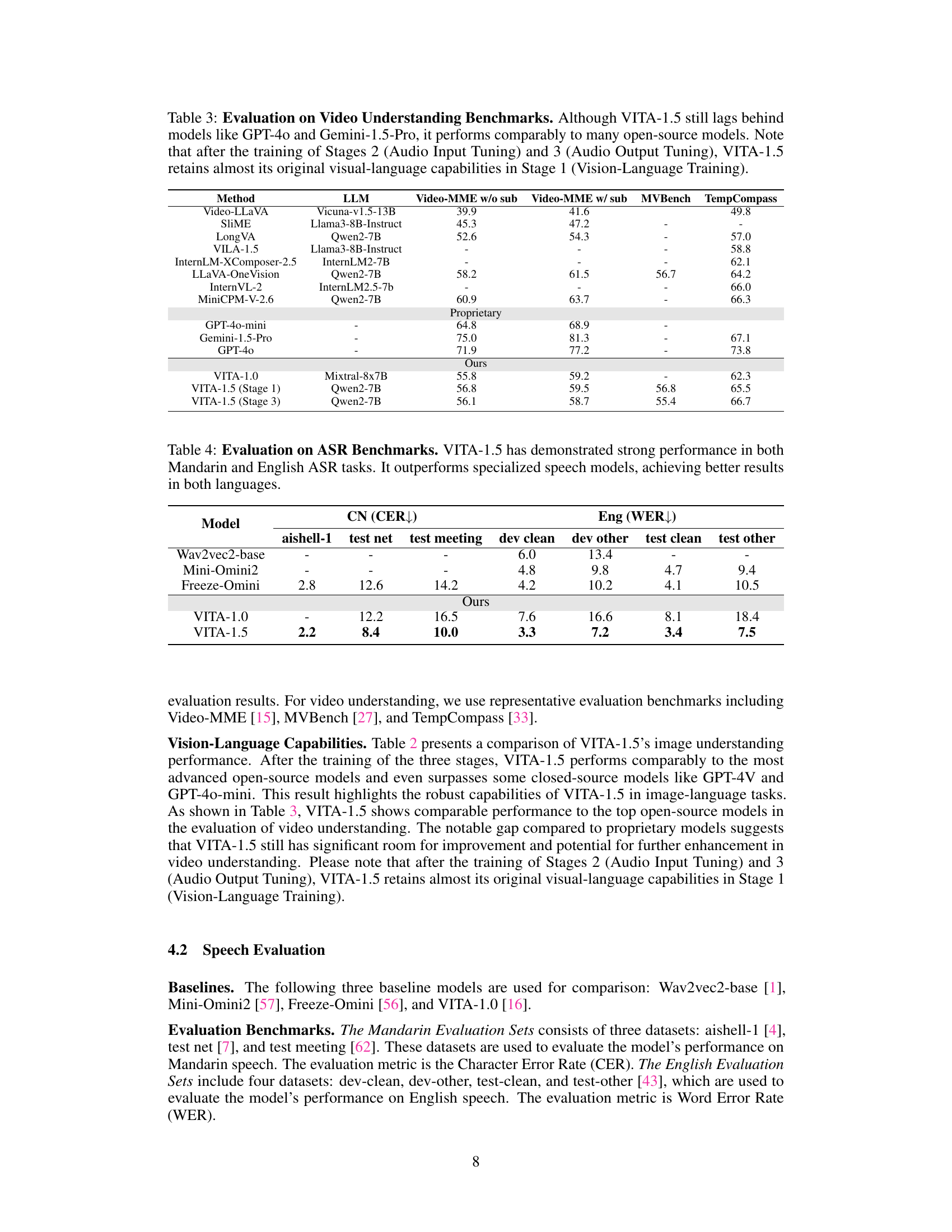
🔼 Table 3 presents a comprehensive evaluation of VITA-1.5’s video understanding capabilities, comparing its performance against several leading open-source and proprietary large language models (LLMs) across multiple benchmarks. The benchmarks assess various aspects of video understanding, including video-text alignment, video question answering, and overall video comprehension. While VITA-1.5 doesn’t surpass the performance of top-tier proprietary models like GPT-40 and Gemini, it demonstrates performance on par with many other open-source models. Importantly, the table notes that the audio training stages (2 and 3) do not significantly impact VITA-1.5’s original visual-language abilities established in Stage 1.
read the caption
Table 3: Evaluation on Video Understanding Benchmarks. Although VITA-1.5 still lags behind models like GPT-4o and Gemini-1.5-Pro, it performs comparably to many open-source models. Note that after the training of Stages 2 (Audio Input Tuning) and 3 (Audio Output Tuning), VITA-1.5 retains almost its original visual-language capabilities in Stage 1 (Vision-Language Training).
| Method | LLM | Video-MME w/o sub | Video-MME w/ sub | MVBench | TempCompass |
|---|---|---|---|---|---|
| Video-LLaVA | Vicuna-v1.5-13B | 39.9 | 41.6 | 49.8 | |
| SliME | Llama3-8B-Instruct | 45.3 | 47.2 | - | - |
| LongVA | Qwen2-7B | 52.6 | 54.3 | - | 57.0 |
| VILA-1.5 | Llama3-8B-Instruct | - | - | - | 58.8 |
| InternLM-XComposer-2.5 | InternLM2-7B | - | - | - | 62.1 |
| LLaVA-OneVision | Qwen2-7B | 58.2 | 61.5 | 56.7 | 64.2 |
| InternVL-2 | InternLM2.5-7b | - | - | - | 66.0 |
| MiniCPM-V-2.6 | Qwen2-7B | 60.9 | 63.7 | - | 66.3 |
| GPT-4o-mini | - | 64.8 | 68.9 | - | |
| Gemini-1.5-Pro | - | 75.0 | 81.3 | - | 67.1 |
| GPT-4o | - | 71.9 | 77.2 | - | 73.8 |
| VITA-1.0 | Mixtral-8x7B | 55.8 | 59.2 | - | 62.3 |
| VITA-1.5 (Stage 1) | Qwen2-7B | 56.8 | 59.5 | 56.8 | 65.5 |
| VITA-1.5 (Stage 3) | Qwen2-7B | 56.1 | 58.7 | 55.4 | 66.7 |
🔼 Table 4 presents a comprehensive evaluation of VITA-1.5’s performance on Automatic Speech Recognition (ASR) tasks, using both Mandarin and English datasets. The table compares VITA-1.5 against several baseline ASR models, showcasing its character error rate (CER) for Mandarin and word error rate (WER) for English. The results highlight VITA-1.5’s superior performance compared to specialized speech models, demonstrating its ability to achieve state-of-the-art results in both languages. This underscores VITA-1.5’s robust speech capabilities.
read the caption
Table 4: Evaluation on ASR Benchmarks. VITA-1.5 has demonstrated strong performance in both Mandarin and English ASR tasks. It outperforms specialized speech models, achieving better results in both languages.
Full paper#