↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Many current large language models (LLMs) struggle to generate truly personalized responses, especially when user data is scarce. Existing personalization methods often rely solely on user history, limiting their effectiveness. This is a critical problem because real-world applications often face cold-start scenarios with new users who lack extensive histories.
To tackle this, researchers developed Personalized Graph-based Retrieval-Augmented Generation (PGraphRAG). This innovative framework uses user-centric knowledge graphs to enrich personalization. By integrating structured user knowledge into the retrieval process and augmenting prompts with relevant context, PGraphRAG provides more relevant, contextually appropriate, and user-preference-aligned responses. The framework was evaluated using a new benchmark dataset designed to test personalized text generation in real-world settings with limited user history. The results showed that PGraphRAG significantly outperforms state-of-the-art methods across various tasks, proving the effectiveness of graph-based retrieval for personalization.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of existing personalized LLM benchmarks that rely heavily on user history. By introducing a novel graph-based approach and a new benchmark dataset with sparse user data, it opens avenues for more robust and realistic personalized LLM evaluation and development, significantly impacting future research in this rapidly evolving field.
Visual Insights#

🔼 This figure illustrates the architecture of the Personalized Graph-based Retrieval-Augmented Generation (PGraphRAG) framework. The framework begins by creating user-centric knowledge graphs from user data including documents, attributes, and interaction history. These graphs then serve as input for a retrieval model which identifies relevant information based on a given input prompt. This retrieved context is appended to the prompt before being sent to a language model. The language model generates personalized text output, which is then evaluated (E(ŷ, y)) to measure performance. The figure visually represents the data flow and processing steps within the PGraphRAG framework.
read the caption
Figure 1: Overview of the proposed personalized graph-based retrieval-augmented generation framework, PGraphRAG. We first construct user-centric graphs from user history and interactions. Then, the resulting structured data is utilized for retrieval. The retrieved information is provided to the language models for context in generating text tailored to user i𝑖iitalic_i.
| Dataset | Train Size | Validation Size | Test Size |
|---|---|---|---|
| User-Product Review | 20,000 | 2,500 | 2,500 |
| Multilingual Product Review | 20,000 | 2,500 | 2,500 |
| Stylized Feedback | 20,000 | 2,500 | 2,500 |
| Hotel Experiences | 9,000 | 2,500 | 2,500 |
🔼 Table 1 presents a statistical overview of the Personalized Graph-based Benchmark for Text Generation. It details the average input and output lengths (in words) for each of the 12 tasks within the benchmark. These averages were calculated using the GPT-40-mini model and the BM25 retrieval method applied to the test set. Additionally, the table provides the average size of the user profiles (measured by the number of user reviews) used in each task. This information is crucial for understanding the characteristics and scale of the data used to evaluate personalized text generation models.
read the caption
Table 1: Data Statistics for PGraph Benchmark. The table reports the average input length and average output length in words (done for the test set on GPT-4o-mini on BM25 back on all methods). The average profile size for each task is by user review size.
In-depth insights#
Graph-Based RAG#
Graph-based Retrieval Augmented Generation (RAG) systems offer a novel approach to enhancing personalized large language models (LLMs). Unlike traditional RAG, which often relies on simple keyword matching or vector similarity, a graph-based approach can capture richer semantic relationships between pieces of information. By representing knowledge as a graph, where nodes are entities and edges represent relationships, the system can perform more sophisticated retrieval, identifying not just semantically similar information but also conceptually related contexts. This is particularly useful for personalized tasks, as it allows the model to consider nuanced relationships relevant to a specific user. Graph structures can incorporate diverse user data, such as demographics, preferences, and interactions, which are difficult to integrate effectively using simpler retrieval methods. The result is the potential for substantially improved personalized responses, especially for users with limited historical data, thereby mitigating the ‘cold-start’ problem. Furthermore, the graph structure can naturally handle complex relationships and multi-faceted contexts, which often lead to more relevant and comprehensive LLM outputs. However, building and maintaining effective knowledge graphs requires significant effort, and the increased complexity introduces challenges in terms of efficiency and scalability.
Personalized Benchmarks#
The concept of “Personalized Benchmarks” in evaluating large language models (LLMs) is crucial. Traditional NLP benchmarks often fail to capture the nuances of personalized text generation, focusing instead on general language understanding and generation. A key challenge is the lack of standardized datasets that effectively assess personalization capabilities, especially considering variations in user profiles and context. Therefore, creating personalized benchmarks requires careful consideration of factors like user history, preferences, and interaction styles. Data sparsity and cold-start problems need to be addressed, ensuring the benchmarks are robust even with limited user information. The design should include a variety of tasks spanning different text generation types (long vs. short) and modalities (classification, rating). Finally, evaluation metrics must reflect the unique aspects of personalized outputs, going beyond standard metrics like ROUGE and BLEU to incorporate factors such as relevance, appropriateness, and user satisfaction.
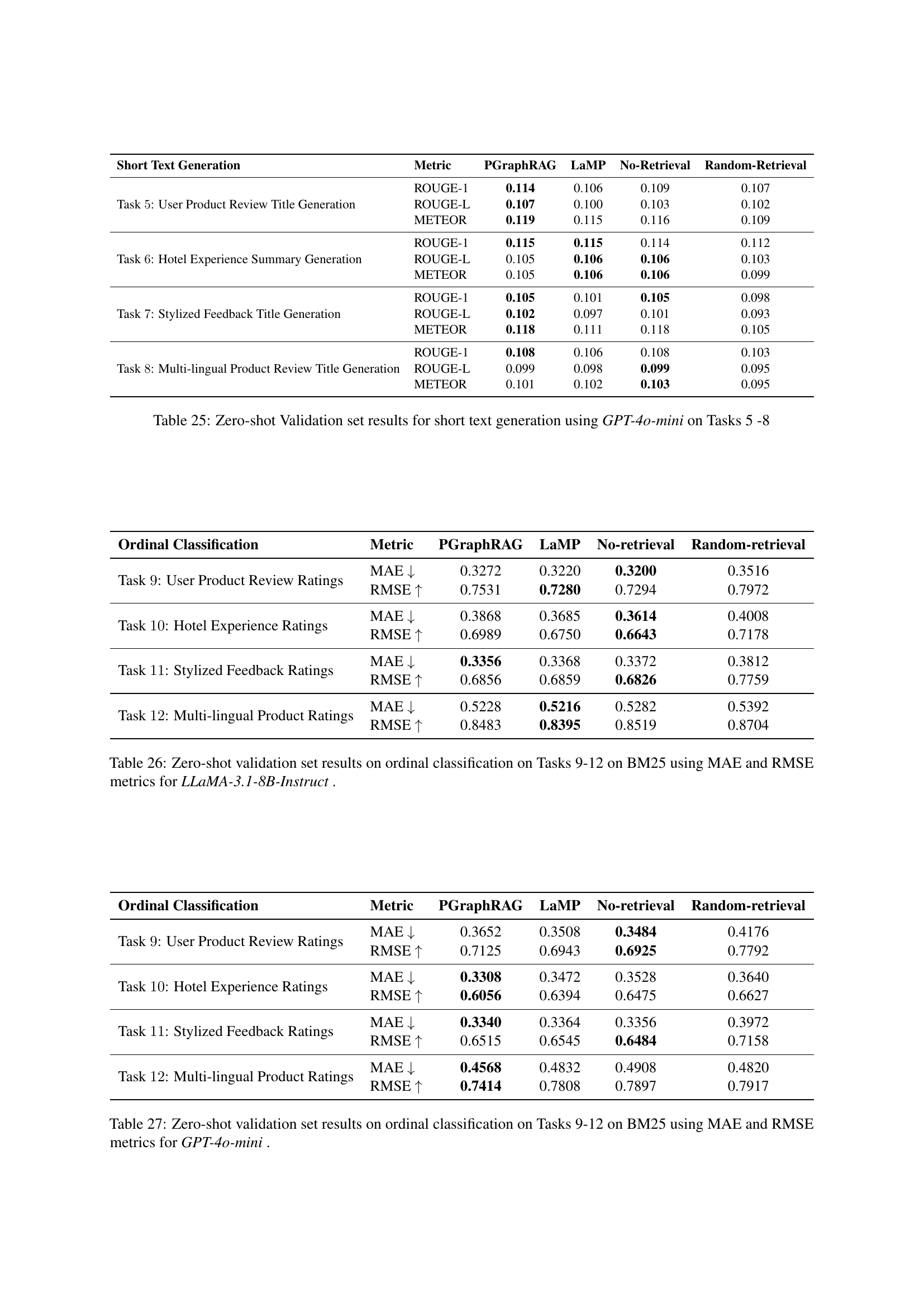
PGraphRAG Framework#
The PGraphRAG framework is a novel approach to personalized text generation for large language models (LLMs). It leverages user-centric knowledge graphs to enrich personalization, moving beyond the limitations of relying solely on user history. By directly integrating structured user knowledge into the retrieval process and augmenting prompts with relevant context, PGraphRAG enhances contextual understanding and output quality, especially crucial in cold-start scenarios. The framework’s use of structured graphs allows it to represent complex user information effectively and generate accurate, personalized responses even with limited user history. This approach presents a significant advance in personalization for LLMs, offering a more robust and comprehensive solution for generating truly tailored outputs. The framework’s ability to handle sparse data is a key strength, demonstrating its applicability in real-world scenarios where user history is limited.
Ablation Experiments#
Ablation experiments systematically remove components of a model to understand their individual contributions. In this context, it would involve progressively removing features of the personalization approach to isolate the impact of each. For instance, one could test performance with only user history, only knowledge graph data, or neither; evaluating the effect on personalization accuracy. Results would reveal which components are most critical and guide future model improvements, and highlight potential redundancies or areas for optimization. The methodology should clearly define which parts are removed and how the remaining components are adapted.. A thorough ablation study also considers the impact of various hyperparameter choices on model effectiveness. A comprehensive ablation study strengthens the paper’s claims by providing strong empirical evidence for its design choices. Furthermore, negative results are as valuable as positive ones, shedding light on unexpected interactions between features and guiding directions for subsequent research.
Future of Personalization#
The future of personalization in LLMs hinges on robust and adaptable methods that transcend reliance on solely user history. Graph-based approaches offer a promising pathway, enriching personalization by incorporating structured knowledge to understand nuanced user preferences and contexts even with limited data. This opens opportunities for effective cold-start personalization, improving user experiences from the outset. Further advancements should explore richer knowledge graphs, integrating diverse data sources beyond explicit user interactions to capture implicit preferences and contextual understanding. Advanced retrieval methods, beyond simple keyword matching, are needed for efficient and accurate knowledge integration. Finally, benchmarking efforts must evolve to encompass the full spectrum of personalization challenges, addressing the limitations of relying solely on easily-accessible, plentiful user history, focusing instead on real-world scenarios where data is often sparse.
More visual insights#
More on figures

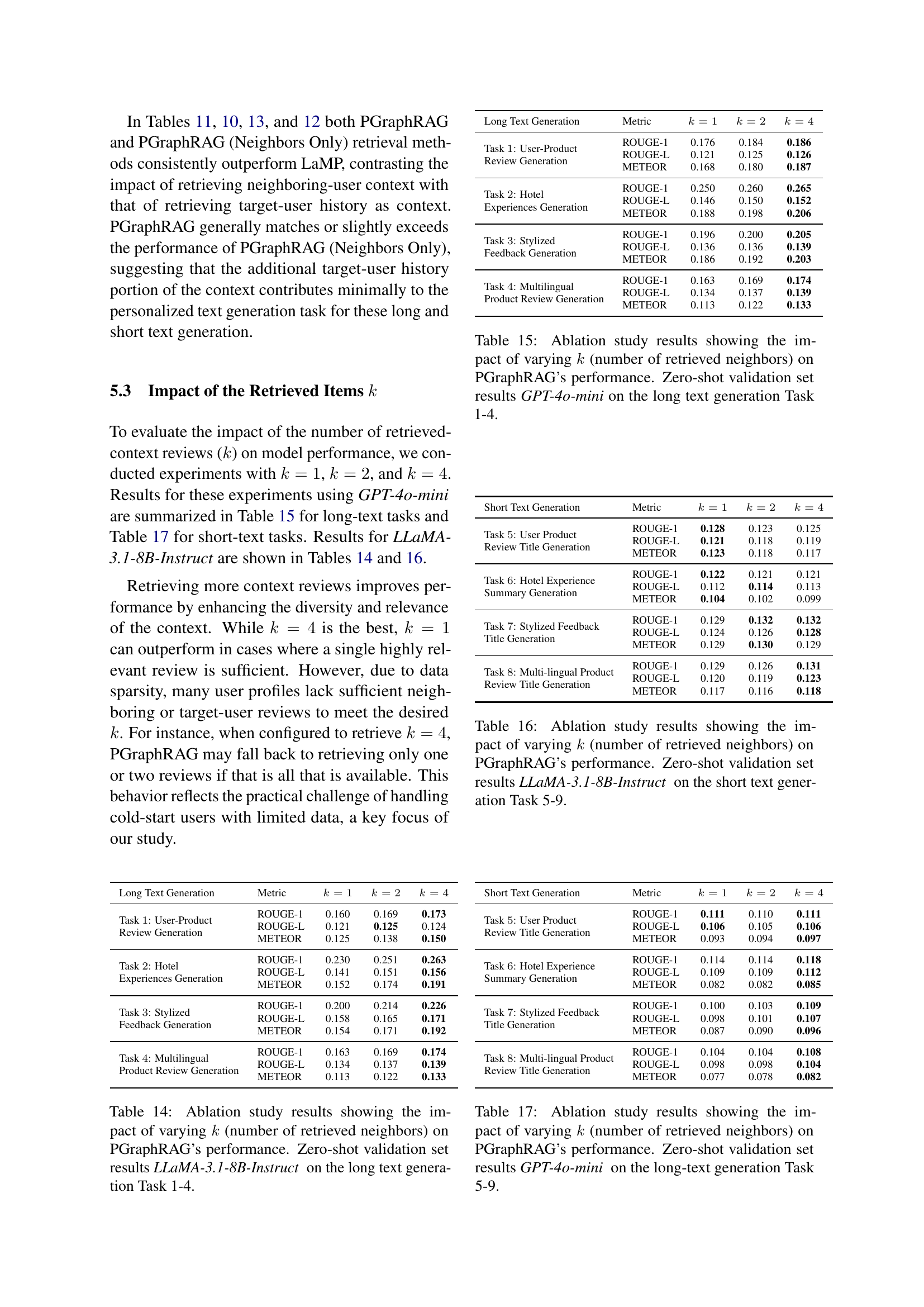
🔼 This figure shows the distribution of Amazon user reviews based on the number of reviews per user. The vast majority of users have very few reviews (one or two), indicated by the steep curve on the left. A red vertical line highlights the minimum number of reviews required to be included in the datasets of other personalization benchmarks (LaMP and LongLaMP). This demonstrates a key challenge in personalization: the scarcity of user data for many individuals.
read the caption
Figure 2: The user profile distribution for Amazon user-product dataset which highlights how most users have a small profile size with few reviews. The red vertical line marks the minimum profile size in other benchmarks (e.g., LaMP, LongLaMP).

🔼 This figure presents a comparative analysis of the performance of two large language models, GPT-40-mini and GPT-01, across various datasets and evaluation metrics specifically focused on the long-text generation task. The bar chart visually compares the ROUGE-1, ROUGE-L, and METEOR scores achieved by each model on each dataset, providing a clear and concise overview of their relative strengths and weaknesses in this specific NLP application.
read the caption
Figure 3: Comparison of GPT-4o-mini and GPT-o1 performance across all datasets and metrics for the long-text generation task.

🔼 This figure displays the results of an ablation study conducted to determine the optimal length constraint for short-text generation using the PGraphRAG model. Three different length constraints (3, 5, and 10 words) were tested, and the performance was measured using ROUGE-1, ROUGE-L, and METEOR metrics. The results show the impact of these constraints on the model’s ability to generate short text, which is important for personalized text generation. The evaluation was performed on the validation set.
read the caption
Figure 4: Impact of length constraints of 3, 5, and 10 on short-text generation tasks using PGraphRAG, evaluated on the validation set.

🔼 Figure 5 presents three example prompt configurations used in the Personalized Graph-based Retrieval-Augmented Generation (PGraphRAG) framework. The prompts are tailored for different task types within the PGraphRAG benchmark: long text generation (Tasks 1-4), short text generation (Tasks 5-8), and ordinal classification (Tasks 9-12). Each example illustrates how user reviews and neighboring user reviews are included in the prompt to provide context for the language model. The bracketed placeholders ([…]) in the prompts indicate where actual user data is inserted during model training and evaluation. The figure highlights how PGraphRAG leverages both a user’s personal review history and the reviews of similar users to generate highly personalized outputs.
read the caption
Figure 5: Examples of different prompt configurations used in each task type for PGraphRAG. Teletype text is replaced with realistic data for each task.
More on tables
| (User Only) | ||||
|---|---|---|---|---|
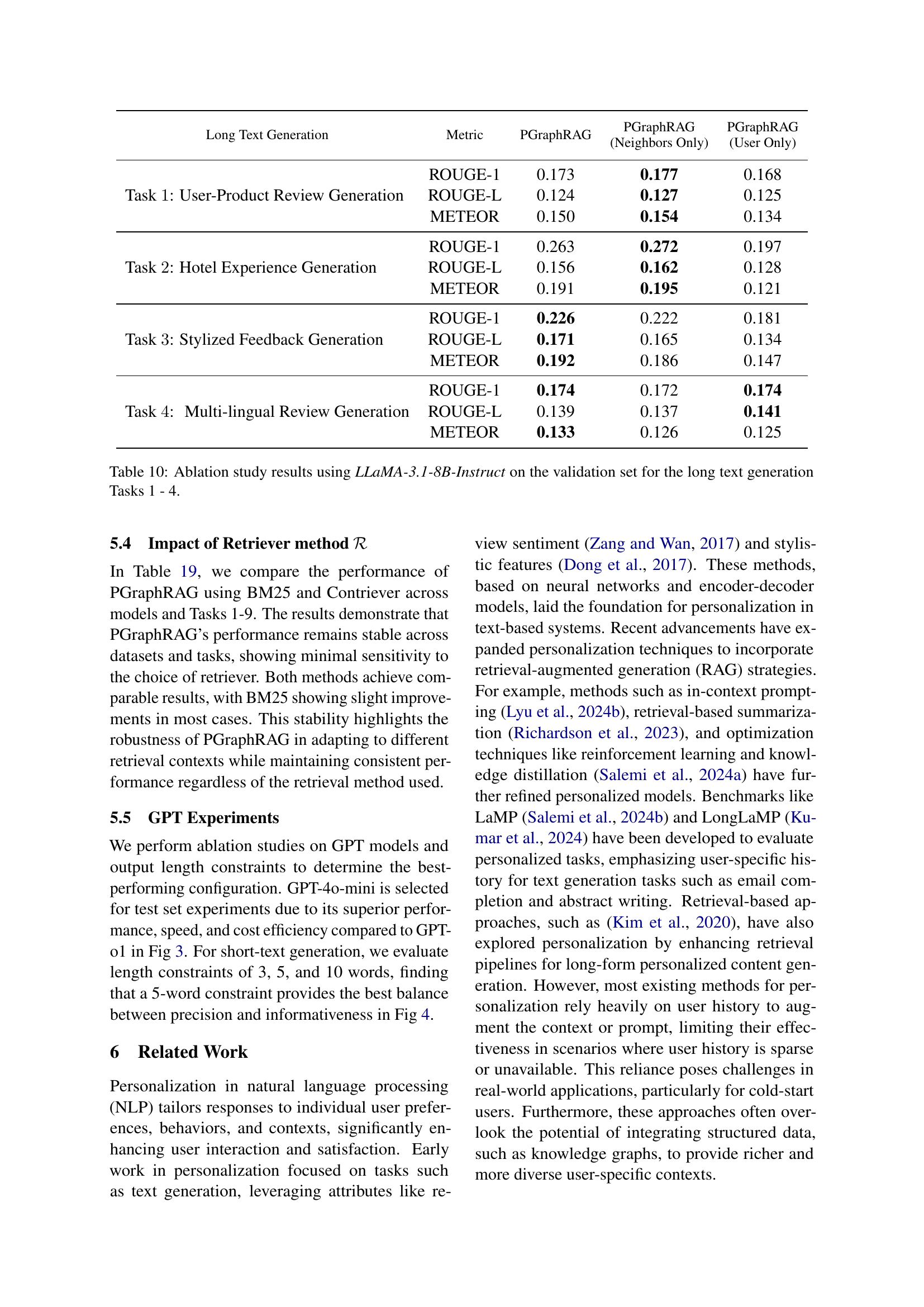
| Task 1: User-Product Review Generation | ROUGE-1 | 0.173 | 0.177 | 0.168 |
| ROUGE-L | 0.124 | 0.127 | 0.125 | |
| METEOR | 0.150 | 0.154 | 0.134 | |
| Task 2: Hotel Experience Generation | ROUGE-1 | 0.263 | 0.272 | 0.197 |
| ROUGE-L | 0.156 | 0.162 | 0.128 | |
| METEOR | 0.191 | 0.195 | 0.121 | |
| Task 3: Stylized Feedback Generation | ROUGE-1 | 0.226 | 0.222 | 0.181 |
| ROUGE-L | 0.171 | 0.165 | 0.134 | |
| METEOR | 0.192 | 0.186 | 0.147 | |
| Task 4: Multi-lingual Review Generation | ROUGE-1 | 0.174 | 0.172 | 0.174 |
| ROUGE-L | 0.139 | 0.137 | 0.141 | |
| METEOR | 0.133 | 0.126 | 0.125 |
🔼 This table presents a summary of the key statistics for the four datasets employed in the personalized text generation tasks within the Personalized Graph-based Benchmark for LLMs. For each dataset (User-Product Graph, Multilingual Product Graph, Stylized Feedback Graph, and Hotel Experiences Graph), it provides the total number of users, the number of items reviewed or mentioned, the total number of edges or reviews, and the average degree of the graph. The average degree metric indicates the average number of connections each node (user or item) has in the graph.
read the caption
Table 2: Graph statistics for the datasets used in the personalized tasks. The table provides the number of users, items, edges (reviews), and the average degree for each dataset: User-Product Graph, Multilingual Product Graph, Stylized Feedback Graph, and Hotel Experiences Graph.
| (User Only) | ||||
|---|---|---|---|---|
| Task 1: User-Product Review Generation | ROUGE-1 | 0.186 | 0.185 | 0.169 |
| ROUGE-L | 0.126 | 0.125 | 0.114 | |
| METEOR | 0.187 | 0.185 | 0.170 | |
| Task 2: Hotel Experience Generation | ROUGE-1 | 0.265 | 0.268 | 0.217 |
| ROUGE-L | 0.152 | 0.153 | 0.132 | |
| METEOR | 0.206 | 0.209 | 0.161 | |
| Task 3: Stylized Feedback Generation | ROUGE-1 | 0.205 | 0.204 | 0.178 |
| ROUGE-L | 0.139 | 0.138 | 0.121 | |
| METEOR | 0.203 | 0.198 | 0.178 | |
| Task 4: Multilingual Product Review Generation | ROUGE-1 | 0.191 | 0.190 | 0.164 |
| ROUGE-L | 0.142 | 0.140 | 0.123 | |
| METEOR | 0.173 | 0.169 | 0.155 |
🔼 This table shows the sizes of the training, validation, and test sets for four different datasets used in the Personalized Graph-based Benchmark for Text Generation. Each dataset represents a different type of user-generated text: User-Product Reviews, Multilingual Product Reviews, Stylized Feedback, and Hotel Experiences. The split sizes ensure that each user’s review history is contained within only one set (train, validation, or test). This design is crucial for evaluating personalized models effectively, as it prevents data leakage and ensures a fair comparison of model performance.
read the caption
Table 3: Dataset split sizes for training, validation, and testing across four datasets: User-Product Review, Multilingual Product Review, Stylized Feedback, and Hotel Experiences.
| Long Text Generation | Metric | k=1 | k=2 | k=4 |
|---|---|---|---|---|
| Task 1: User-Product Review Generation | ROUGE-1 | 0.160 | 0.169 | 0.173 |
| ROUGE-L | 0.121 | 0.125 | 0.124 | |
| METEOR | 0.125 | 0.138 | 0.150 | |
| Task 2: Hotel Experiences Generation | ROUGE-1 | 0.230 | 0.251 | 0.263 |
| ROUGE-L | 0.141 | 0.151 | 0.156 | |
| METEOR | 0.152 | 0.174 | 0.191 | |
| Task 3: Stylized Feedback Generation | ROUGE-1 | 0.200 | 0.214 | 0.226 |
| ROUGE-L | 0.158 | 0.165 | 0.171 | |
| METEOR | 0.154 | 0.171 | 0.192 | |
| Task 4: Multilingual Product Review Generation | ROUGE-1 | 0.163 | 0.169 | 0.174 |
| ROUGE-L | 0.134 | 0.137 | 0.139 | |
| METEOR | 0.113 | 0.122 | 0.133 |
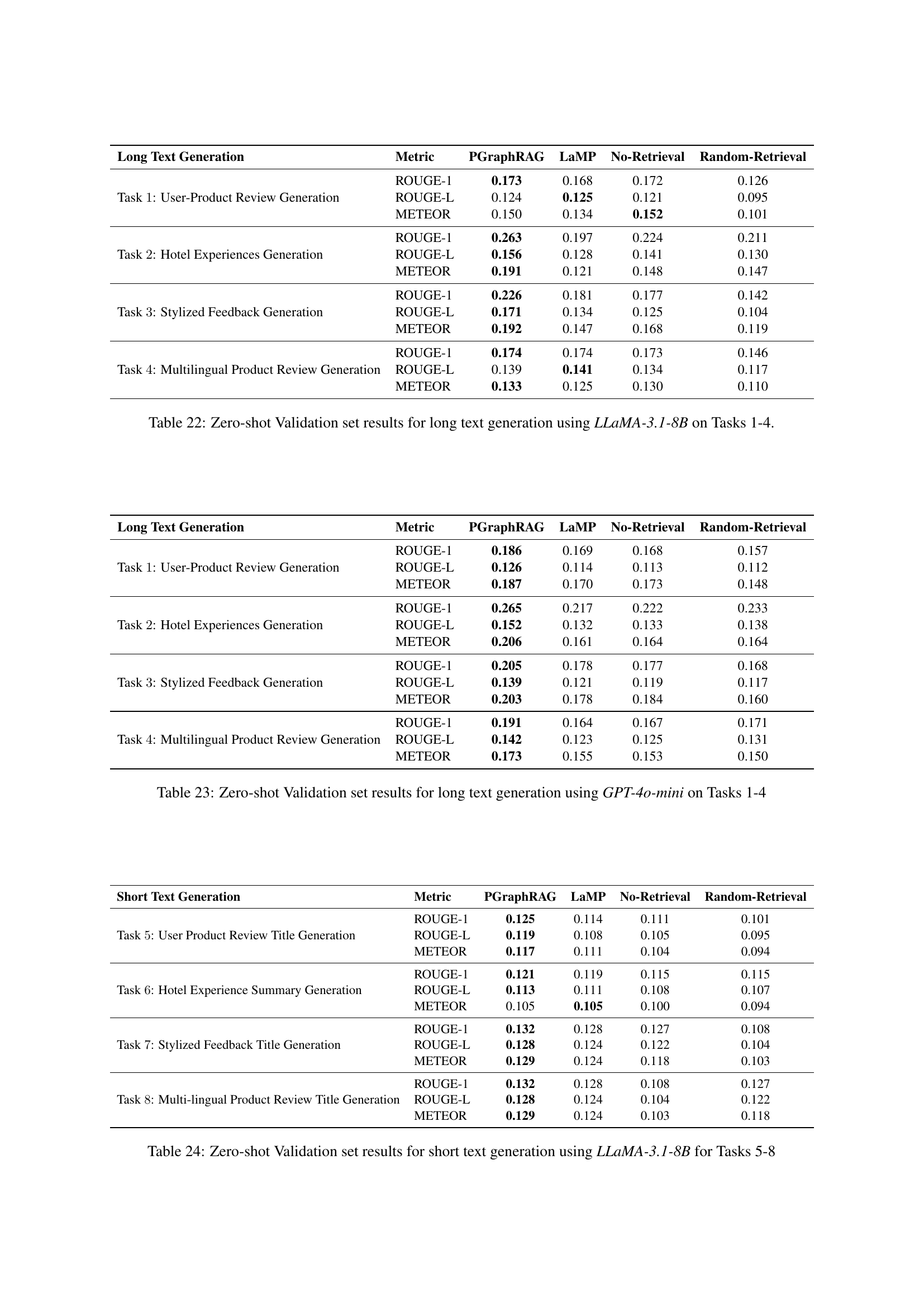
🔼 This table presents the results of a zero-shot evaluation of long text generation models using the LLaMA-3.1-8B model. The performance is measured using ROUGE-1, ROUGE-L, and METEOR metrics across four different long text generation tasks. The best-performing retriever (BM25 or Contriever) and the optimal number of retrieved items (k) were determined through a prior validation process. The table shows the scores for each metric and task, allowing for a comparison of the model’s performance in various scenarios.
read the caption
Table 4: Zero-shot test set results for long text generation using LLaMA-3.1-8B. The choice of retriever and k𝑘kitalic_k were tuned using the validation set.
| Long Text Generation | Metric | k=1 | k=2 | k=4 |
|---|---|---|---|---|
| Task 1: User-Product Review Generation | ROUGE-1 | 0.176 | 0.184 | 0.186 |
| ROUGE-L | 0.121 | 0.125 | 0.126 | |
| METEOR | 0.168 | 0.180 | 0.187 | |
| Task 2: Hotel Experiences Generation | ROUGE-1 | 0.250 | 0.260 | 0.265 |
| ROUGE-L | 0.146 | 0.150 | 0.152 | |
| METEOR | 0.188 | 0.198 | 0.206 | |
| Task 3: Stylized Feedback Generation | ROUGE-1 | 0.196 | 0.200 | 0.205 |
| ROUGE-L | 0.136 | 0.136 | 0.139 | |
| METEOR | 0.186 | 0.192 | 0.203 | |
| Task 4: Multilingual Product Review Generation | ROUGE-1 | 0.163 | 0.169 | 0.174 |
| ROUGE-L | 0.134 | 0.137 | 0.139 | |
| METEOR | 0.113 | 0.122 | 0.133 |
🔼 This table presents the results of zero-shot testing on long text generation tasks using the GPT-40-mini language model. The performance is measured across four different tasks: User Product Review Generation, Hotel Experiences Generation, Stylized Feedback Generation, and Multilingual Product Review Generation. For each task, multiple metrics (ROUGE-1, ROUGE-L, and METEOR) are reported. The model’s performance is determined without any fine-tuning on the test data. The best performing retriever (BM25 or Contriever) and the optimal number of retrieved items (k) were selected based on the validation set’s performance.
read the caption
Table 5: Zero-shot test set results for long text generation using GPT-4o-mini. The choice of retriever and k𝑘kitalic_k were tuned using the validation set.
| Short Text Generation | Metric | k=1 | k=2 | k=4 |
|---|---|---|---|---|
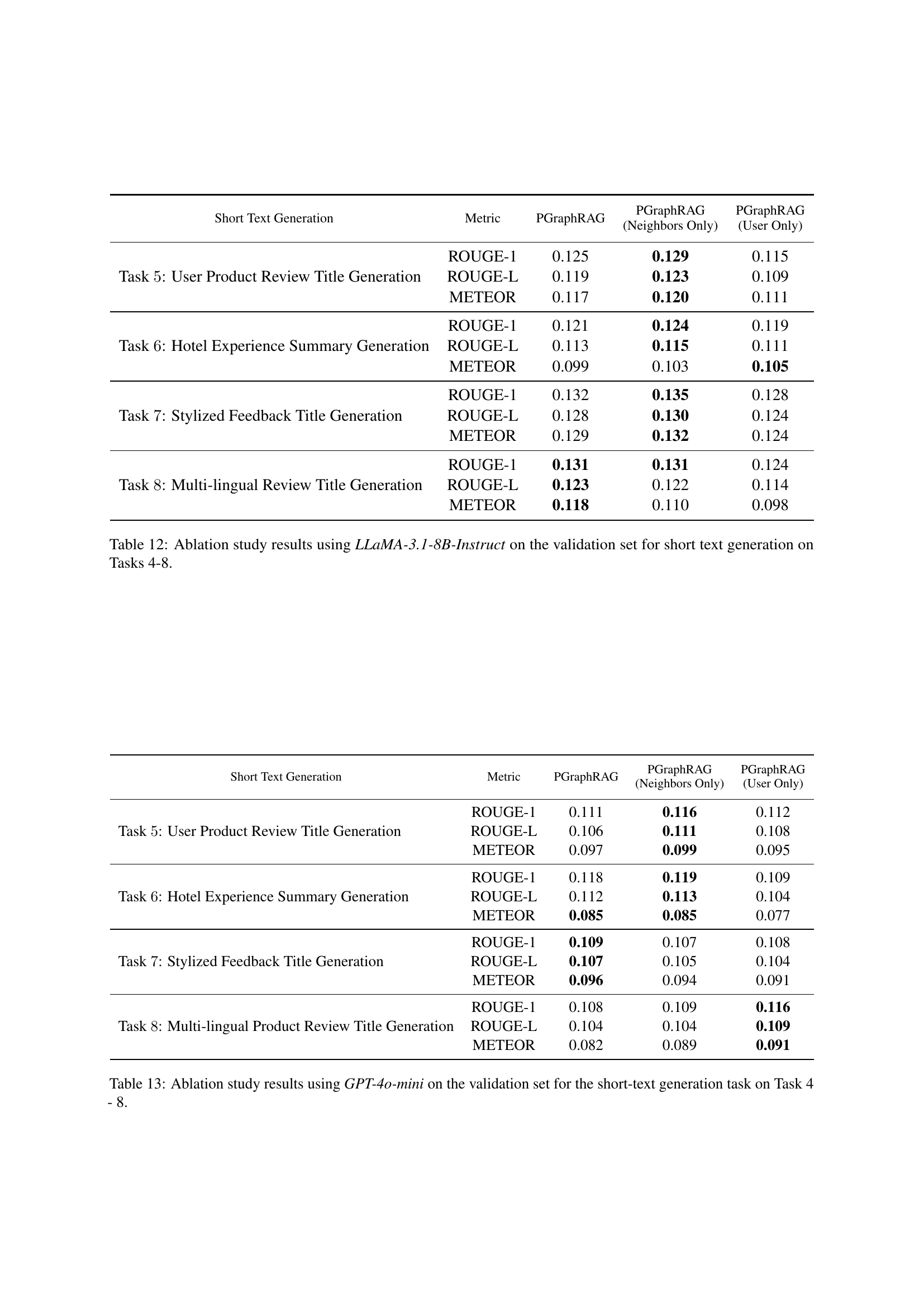
| Task 5: User Product Review Title Generation | ROUGE-1 | 0.128 | 0.123 | 0.125 |
| ROUGE-L | 0.121 | 0.118 | 0.119 | |
| METEOR | 0.123 | 0.118 | 0.117 | |
| Task 6: Hotel Experience Summary Generation | ROUGE-1 | 0.122 | 0.121 | 0.121 |
| ROUGE-L | 0.112 | 0.114 | 0.113 | |
| METEOR | 0.104 | 0.102 | 0.099 | |
| Task 7: Stylized Feedback Title Generation | ROUGE-1 | 0.129 | 0.132 | 0.132 |
| ROUGE-L | 0.124 | 0.126 | 0.128 | |
| METEOR | 0.129 | 0.130 | 0.129 | |
| Task 8: Multi-lingual Product Review Title Generation | ROUGE-1 | 0.129 | 0.126 | 0.131 |
| ROUGE-L | 0.120 | 0.119 | 0.123 | |
| METEOR | 0.117 | 0.116 | 0.118 |
🔼 This table presents the zero-shot test results for short text generation tasks using the LLaMA-3.1-8B language model. It shows the performance of the PGraphRAG model, along with several baseline methods (LaMP, No-Retrieval, and Random-Retrieval), across various metrics (ROUGE-1, ROUGE-L, and METEOR). The retriever and the number of retrieved items (k) used in PGraphRAG were optimized based on the validation set results. The table provides a comprehensive evaluation of the model’s ability to generate short personalized texts.
read the caption
Table 6: Zero-shot test set results for short text generation using LLaMA-3.1-8B. The choice of retriever and k𝑘kitalic_k were tuned using the validation set.
| Short Text Generation | Metric | k=1 | k=2 | k=4 |
|---|---|---|---|---|
| Task 5: User Product Review Title Generation | ROUGE-1 | 0.111 | 0.110 | 0.111 |
| ROUGE-L | 0.106 | 0.105 | 0.106 | |
| METEOR | 0.093 | 0.094 | 0.097 | |
| Task 6: Hotel Experience Summary Generation | ROUGE-1 | 0.114 | 0.114 | 0.118 |
| ROUGE-L | 0.109 | 0.109 | 0.112 | |
| METEOR | 0.082 | 0.082 | 0.085 | |
| Task 7: Stylized Feedback Title Generation | ROUGE-1 | 0.100 | 0.103 | 0.109 |
| ROUGE-L | 0.098 | 0.101 | 0.107 | |
| METEOR | 0.087 | 0.090 | 0.096 | |
| Task 8: Multi-lingual Product Review Title Generation | ROUGE-1 | 0.104 | 0.104 | 0.108 |
| ROUGE-L | 0.098 | 0.098 | 0.104 | |
| METEOR | 0.077 | 0.078 | 0.082 |
🔼 This table presents the results of zero-shot testing on short-text generation tasks using the GPT-40-mini language model. The performance metrics (ROUGE-1, ROUGE-L, METEOR) are shown for four different tasks: User Product Review Title Generation, Hotel Experience Summary Generation, Stylized Feedback Title Generation, and Multi-lingual Product Review Title Generation. The model’s performance is evaluated without any fine-tuning on the test set; the best-performing retriever (BM25 or Contriever) and optimal number of retrieved items (k) were determined using the validation set. This allows for a comparison of the model’s ability to generate short-text outputs in various scenarios, based solely on the provided input and user profile information.
read the caption
Table 7: Zero-shot test set results for short text generation using GPT-4o-mini. The choice of retriever and k𝑘kitalic_k were tuned using the validation set.
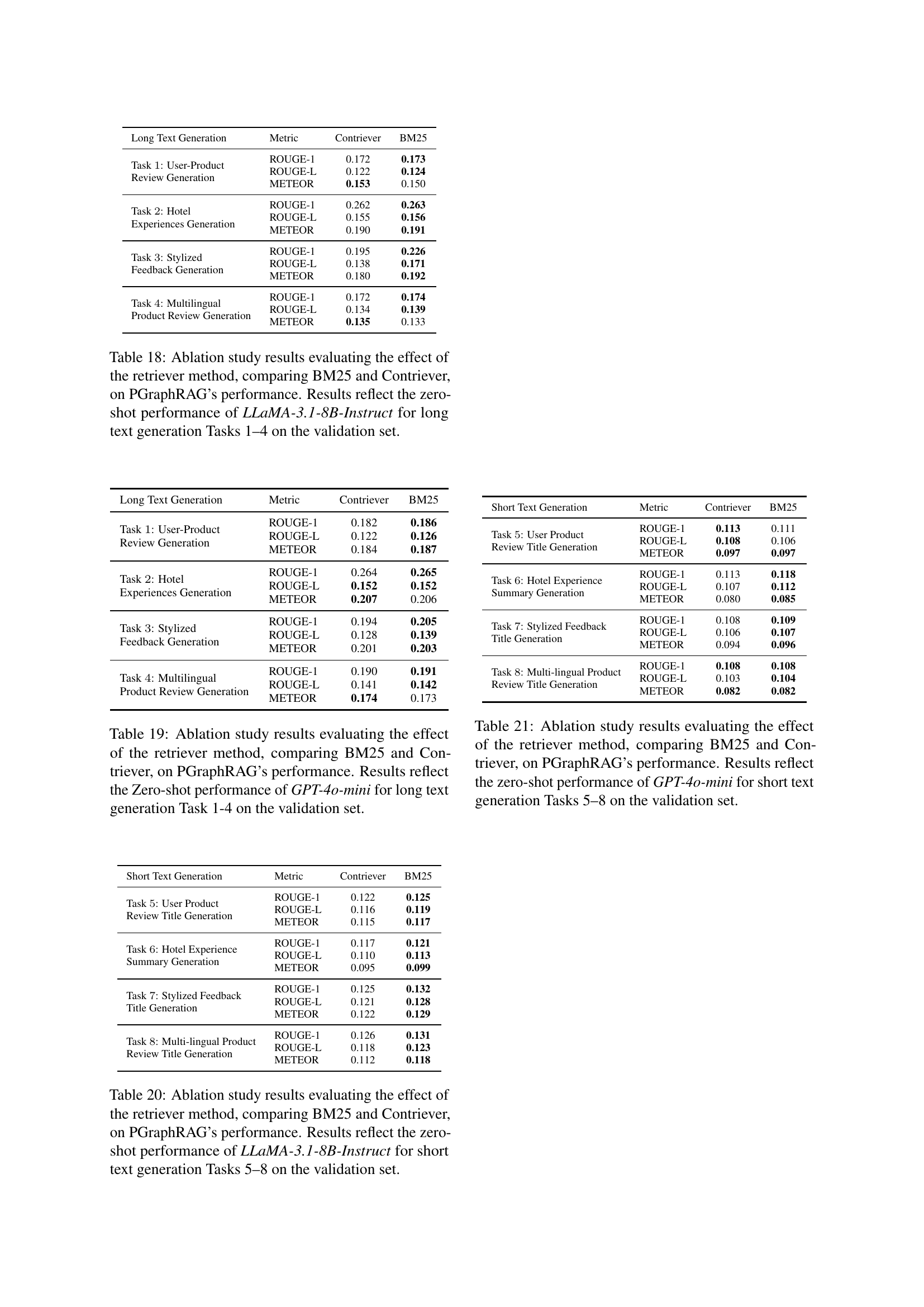
| Long Text Generation | Metric | Contriever | BM25 |
|---|---|---|---|
| Task 1: User-Product Review Generation | ROUGE-1 | 0.172 | 0.173 |
| ROUGE-L | 0.122 | 0.124 | |
| METEOR | 0.153 | 0.150 | |
| Task 2: Hotel Experiences Generation | ROUGE-1 | 0.262 | 0.263 |
| ROUGE-L | 0.155 | 0.156 | |
| METEOR | 0.190 | 0.191 | |
| Task 3: Stylized Feedback Generation | ROUGE-1 | 0.195 | 0.226 |
| ROUGE-L | 0.138 | 0.171 | |
| METEOR | 0.180 | 0.192 | |
| Task 4: Multilingual Product Review Generation | ROUGE-1 | 0.172 | 0.174 |
| ROUGE-L | 0.134 | 0.139 | |
| METEOR | 0.135 | 0.133 |
🔼 This table presents the performance of the LLaMA-3.1-8B-Instruct language model on four ordinal classification tasks (Tasks 9-12 from the paper’s benchmark). The model’s performance is evaluated using two metrics: Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE). Lower MAE and RMSE values indicate better performance. The results are for a zero-shot setting, meaning the model was not fine-tuned for these specific tasks, and BM25 was used as the retrieval method.
read the caption
Table 8: Zero-shot test set results on ordinal classification on Tasks 9-12 on BM25 using MAE and RMSE metrics for LLaMA-3.1-8B-Instruct .
| Long Text Generation | Metric | Contriever | BM25 |
|---|---|---|---|
| Task 1: User-Product Review Generation | ROUGE-1 | 0.182 | 0.186 |
| ROUGE-L | 0.122 | 0.126 | |
| METEOR | 0.184 | 0.187 | |
| Task 2: Hotel Experiences Generation | ROUGE-1 | 0.264 | 0.265 |
| ROUGE-L | 0.152 | 0.152 | |
| METEOR | 0.207 | 0.206 | |
| Task 3: Stylized Feedback Generation | ROUGE-1 | 0.194 | 0.205 |
| ROUGE-L | 0.128 | 0.139 | |
| METEOR | 0.201 | 0.203 | |
| Task 4: Multilingual Product Review Generation | ROUGE-1 | 0.190 | 0.191 |
| ROUGE-L | 0.141 | 0.142 | |
| METEOR | 0.174 | 0.173 |
🔼 This table presents the results of a zero-shot evaluation of the PGraphRAG model on four ordinal classification tasks (Tasks 9-12) using the GPT-40-mini language model. The evaluation metrics employed are Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE), both common metrics for assessing the accuracy of regression models. Lower MAE and RMSE values indicate better model performance. BM25 was used as the retrieval method. The table likely shows the MAE and RMSE scores for each task, potentially broken down by different methods or baselines for comparison.
read the caption
Table 9: Zero-shot test set results on ordinal classification on Tasks 9-12 on BM25 using MAE and RMSE metrics for GPT-4o-mini .
| Short Text Generation | Metric | Contriever | BM25 |
|---|---|---|---|
| Task 5: User Product Review Title Generation | ROUGE-1 | 0.122 | 0.125 |
| ROUGE-L | 0.116 | 0.119 | |
| METEOR | 0.115 | 0.117 | |
| Task 6: Hotel Experience Summary Generation | ROUGE-1 | 0.117 | 0.121 |
| ROUGE-L | 0.110 | 0.113 | |
| METEOR | 0.095 | 0.099 | |
| Task 7: Stylized Feedback Title Generation | ROUGE-1 | 0.125 | 0.132 |
| ROUGE-L | 0.121 | 0.128 | |
| METEOR | 0.122 | 0.129 | |
| Task 8: Multi-lingual Product Review Title Generation | ROUGE-1 | 0.126 | 0.131 |
| ROUGE-L | 0.118 | 0.123 | |
| METEOR | 0.112 | 0.118 |
🔼 This table presents the results of an ablation study conducted to evaluate the impact of different components of the PGraphRAG model on the performance of long text generation tasks. Specifically, it compares the performance of the full PGraphRAG model against two variants: one using only the target user’s history (‘User Only’), and another using only the history of neighboring users (‘Neighbors Only’). The study uses the LLaMA-3.1-8B-Instruct language model and focuses on four long text generation tasks from the Personalized Graph-based Benchmark for Text Generation.
read the caption
Table 10: Ablation study results using LLaMA-3.1-8B-Instruct on the validation set for the long text generation Tasks 1 - 4.
| Short Text Generation | Metric | Contriever | BM25 |
|---|---|---|---|
| Task 5: User Product Review Title Generation | ROUGE-1 | 0.113 | 0.111 |
| ROUGE-L | 0.108 | 0.106 | |
| METEOR | 0.097 | 0.097 | |
| Task 6: Hotel Experience Summary Generation | ROUGE-1 | 0.113 | 0.118 |
| ROUGE-L | 0.107 | 0.112 | |
| METEOR | 0.080 | 0.085 | |
| Task 7: Stylized Feedback Title Generation | ROUGE-1 | 0.108 | 0.109 |
| ROUGE-L | 0.106 | 0.107 | |
| METEOR | 0.094 | 0.096 | |
| Task 8: Multi-lingual Product Review Title Generation | ROUGE-1 | 0.108 | 0.108 |
| ROUGE-L | 0.103 | 0.104 | |
| METEOR | 0.082 | 0.082 |
🔼 This table presents the ablation study results obtained using the GPT-40-mini model on the validation set. The study focuses on long text generation tasks (Tasks 1-4). It compares the performance of three variations of the PGraphRAG model: the full PGraphRAG model, a version using only neighboring user reviews, and a version using only the target user’s reviews. The comparison is done using ROUGE-1, ROUGE-L, and METEOR metrics, to assess the impact of different user context information sources on model performance.
read the caption
Table 11: Ablation study results using GPT-4o-mini on the validation set for long text generation tasks across Tasks 1-4.
Full paper#