↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for facial expression editing often struggle with preserving identity, background, and pose while offering limited control over the intensity of expressions. Existing models either lack intuitiveness in manipulation or result in unrealistic deformations. They often work with less interpretable latent spaces, making it hard for non-experts to achieve desired results. Many approaches utilize GANs, while recent works use diffusion models but don’t provide sufficient control over specific facial features or lack photorealism.
MagicFace, utilizes action units (AUs) as intuitive and interpretable controls for expression editing. By incorporating an ID encoder to maintain identity and an attribute controller to preserve background and pose, the model achieves high-fidelity results while allowing for granular control over AU variations. The model utilizes a pre-trained Stable Diffusion model and a unique AU variation method, resulting in photorealistic edits. Experiments demonstrate that MagicFace significantly outperforms existing methods in both quality and controllability, showcasing its effectiveness for precise and flexible facial expression editing.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MagicFace, a novel approach to high-fidelity facial expression editing that offers fine-grained control and high-quality results. It addresses limitations of existing methods by using action units (AUs) for precise expression control, preserving identity, and leveraging the power of diffusion models. This opens avenues for research in interpretable AI, realistic image generation, and applications in virtual characters, animation, and media. The code’s public availability further facilitates broader adoption and future research.
Visual Insights#

🔼 Figure 1 showcases the capabilities of the MagicFace model in editing facial expressions. It demonstrates how the model takes an input portrait and a set of Action Unit (AU) changes. These AUs represent specific changes to facial muscle movements, allowing for fine-grained control over the expression. The model then produces an edited image that accurately reflects the specified AU changes while maintaining the identity, pose, background, and fine details of the original portrait. This highlights MagicFace’s ability to create realistic and controlled facial expression edits.
read the caption
Figure 1: MagicFace takes in the AU changes based on the input portrait and edit the portrait to exhibit different expressions. The edited image respects the AU condition and preserve identity, pose, background as well as other facial details.
| Method | AU | ID | background RMSE ( ) ) | head pose RMSE () |
|---|---|---|---|---|
| DeltaEdit [37] | N/A | 0.743 | 0.126 | 0.075 |
| FaceEdit | N/A | 0.513 | 0.044 | 0.032 |
| DALLE-3 | 0.512 | 0.763 | 0.224 | 0.208 |
| DiffAE [14] | N/A | 0.579 | 0.161 | 0.183 |
| GANmut [38] | N/A | [0.495] | 0.059 | 0.032 |
| FaceAdapter [39] | [0.427] | 0.567 | [0.056] | [0.034] |
| MagicFace (Ours) | 0.261 | 0.473 | 0.044 | 0.032 |
🔼 This table compares the performance of different facial expression editing methods across multiple metrics. Specifically, it evaluates the accuracy of Action Unit (AU) intensity prediction, the preservation of the original identity in the edited image, the fidelity of background preservation, and how well the head pose is maintained. The results are presented as mean squared error (MSE) for AU accuracy, L2 distance for identity preservation, root mean squared error (RMSE) for background preservation, and RMSE for head pose preservation. The best and second-best performing methods for each metric are highlighted in bold and square brackets, respectively. Methods unable to produce a result for a given metric are noted as N/A.
read the caption
TABLE I: Comparison of methods in terms of AU accuracy, identity preservation and image similarity. N/A denotes incomputable. The best and second best results are reported in bold and [square brackets], respectively.
In-depth insights#
AU-Based Editing#
AU-based editing, as presented in the research paper, offers a novel approach to facial expression manipulation. It leverages Action Units (AUs), the fundamental components of facial expressions, as direct control parameters. This method provides fine-grained control over the intensity and location of specific expression changes, enabling precise and localized edits rather than broad, less-interpretable alterations. The use of AUs also offers a more intuitive and user-friendly interface for editing facial expressions, as compared to methods that rely on latent space manipulation or other less-interpretable coding schemes. A key advantage highlighted is the ability to produce high-fidelity results, maintaining identity, pose, and background consistency. However, challenges might arise from the potential for inaccuracies in AU estimation, especially when dealing with non-frontal views or varied lighting conditions. Future research could explore the development of more robust AU estimation methods and the extension of this approach to incorporate additional facial features and attributes for even more comprehensive control over facial expression editing.
Diffusion Model#
Diffusion models are a powerful class of generative models that have recently achieved state-of-the-art results in image generation. They work by gradually adding noise to an image until it becomes pure noise, and then learning to reverse this process to generate new images. This approach offers several advantages. They often produce high-quality, realistic images, surpassing previous methods like GANs. Further, they are more stable to train and less prone to mode collapse. However, diffusion models are computationally expensive, requiring significant resources for both training and inference. The use of a pre-trained Stable Diffusion model in MagicFace demonstrates the potential of leveraging these models for image editing tasks, particularly those requiring high fidelity, as they efficiently learn underlying data distributions and can be conditioned for precise control. Conditioning techniques, such as those using AU variations in MagicFace, allows for targeted modifications while maintaining crucial aspects of the image. The paper highlights the successful integration of a diffusion model within an overall architecture incorporating additional components, like an ID encoder for identity preservation, to overcome limitations of solely using a diffusion model for complex tasks like facial expression editing.
ID Preservation#
ID preservation is a crucial aspect of high-fidelity facial expression editing. The goal is to modify expressions without altering the person’s identity. This requires careful attention to facial details, ensuring that the features remain consistent and recognizable even as the expression changes. Methods achieving this often involve incorporating an identity encoder or leveraging pre-trained models to learn identity features and maintain consistency, preventing unwanted changes to attributes like pose, hair, and background. Techniques such as self-attention mechanisms and careful conditioning of the generative models play a vital role in ensuring the identity is preserved. Failure to achieve strong ID preservation results in unnatural looking edits, where the person’s identity becomes ambiguous or distorted. A successful method demonstrates consistent and recognizable identity preservation across various AU combinations and intensity levels, providing realistic and high-quality edited images.
Attribute Control#
The concept of ‘Attribute Control’ in the context of facial expression editing is crucial for achieving high-fidelity results. It addresses the challenge of maintaining consistent identity, pose, and background while manipulating facial expressions. Effective attribute control ensures that the edited image retains the original subject’s identity without unwanted distortions or artifacts. This often involves sophisticated techniques like separating the face from its background, employing a dedicated attribute controller to manage pose and background information independently from expression changes, and merging appearance features from the input identity image to ensure high consistency and reduce identity loss. The effectiveness of attribute control directly correlates with the realism and quality of the edited facial expression. Without robust attribute control, alterations could lead to unnatural-looking results, where the identity of the person is lost or changed, and background/pose are inconsistent with the subject’s image. Therefore, a well-designed attribute control system is paramount for generating convincing and high-quality facial expression edits, creating a natural and seamless transition between original and edited images.
Ablation Study#
The ablation study systematically evaluates the contribution of different model components to the overall performance. Removing the ID encoder significantly impacts identity preservation, highlighting its crucial role in maintaining consistent facial features. Replacing the ID encoder with simpler alternatives, like a convolutional layer or CLIP image encoder, demonstrates the effectiveness of the chosen architecture. The AU dropout technique, combined with classifier-free guidance, improves controllability and generates more diverse, high-quality images. The study provides a quantitative analysis showcasing the impact of these design decisions on metrics such as AU accuracy, identity preservation, and background consistency, underscoring the importance of each component for achieving high-fidelity facial expression editing. Experimenting with different guidance scales reveals an optimal range, revealing a balance between detailed control and avoiding over-stylization. Overall, the ablation study provides strong evidence supporting the design choices made, validating the proposed architecture’s efficacy.
More visual insights#
More on figures

🔼 Figure 2 shows a chart illustrating different facial action units (AUs) and their intensity levels. Each AU represents a specific muscle movement in the face, and the intensity scale (A-E) indicates the strength of that movement, ranging from minimal (A) to maximal (E). The figure only displays some commonly used AUs; for a complete list and detailed descriptions, please refer to reference [15] in the paper.
read the caption
Figure 2: A display showcasing various action units and their corresponding intensity scales. Only a set of commonly used AUs are displayed here. For a complete collection of AUs with descriptions see [15].

🔼 This figure illustrates the MagicFace architecture and workflow. During training, it uses pairs of images of the same person but with varying poses, backgrounds, and expressions. One image serves as the identity reference, and the other as the target for expression editing. An AU (Action Unit) estimator calculates the differences in AU intensities between the identity and target images. These AU variations are fed, along with processed pose and background information (from an Attribute Controller), into a denoising UNet. A dedicated ID (Identity) encoder processes the identity image, using self-attention to integrate its features into the UNet, maintaining identity consistency. At inference time, the model parses pose and background from a single input image, enabling expression editing while preserving identity and other attributes.
read the caption
Figure 3: Overview of MagicFace. During training, a pair of images with the same identity but different pose, background as well as expressions is used respectively as the identity image and the target. AU variations are computed by an estimator and then sent into the denoising UNet as AU condition. Pose and background of the target is parsed into an image condition independently, dealed with an Attribute Controller and then inputted to the denoising UNet. ID encoder takes in the encoded identity image to edit for target AUs, where features in each transformer blocks are merged into the corresponding ones of the denoising UNet via self-attention. During inference, the conditional image will be parsed from the identity image.

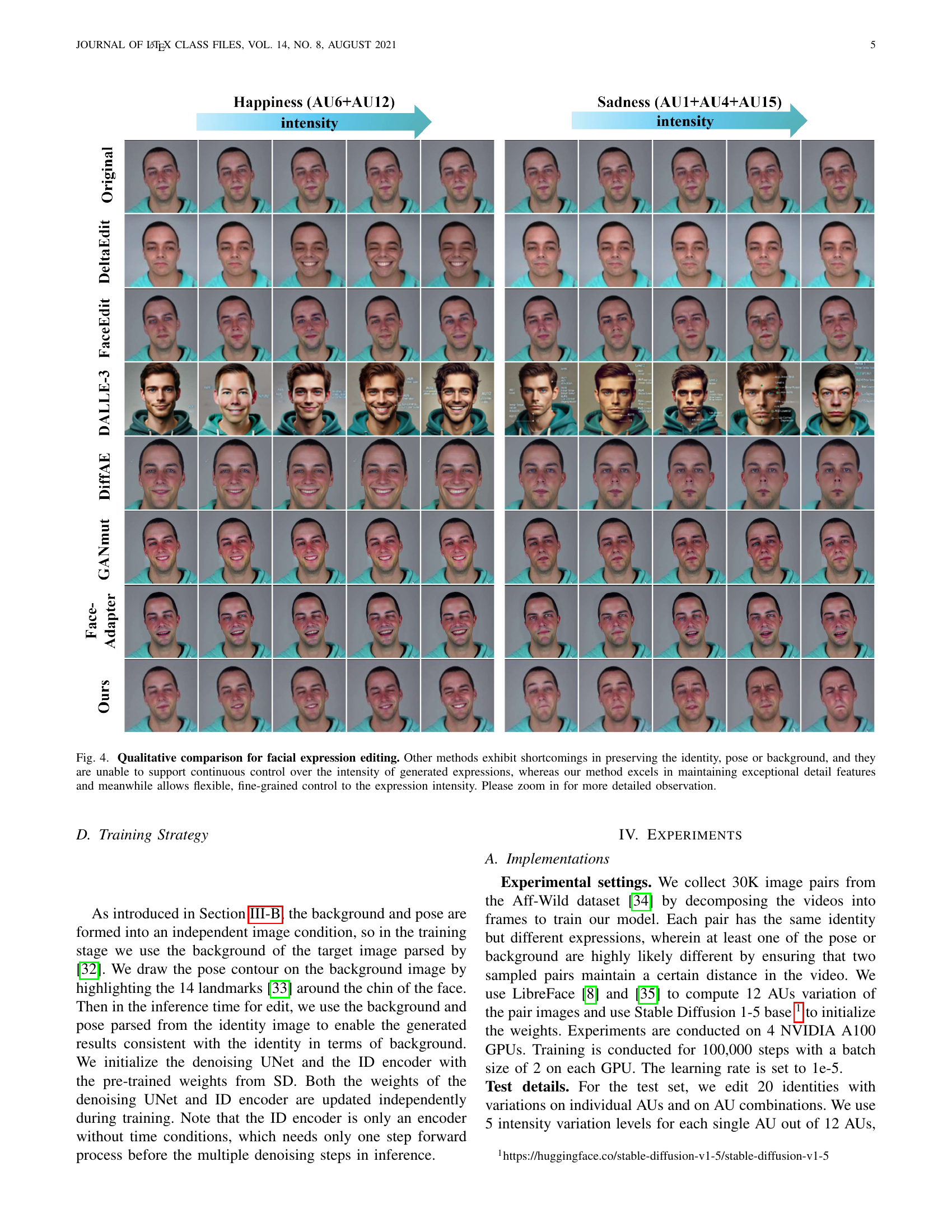
🔼 Figure 4 presents a qualitative comparison of various facial expression editing methods. The results highlight the superior performance of the proposed MagicFace model. While other methods struggle to maintain consistent identity, pose, and background details across different expression levels, MagicFace excels in preserving these details while allowing for highly precise and flexible control over the intensity of generated expressions. The figure encourages closer inspection to fully appreciate the fine details of the generated expressions.
read the caption
Figure 4: Qualitative comparison for facial expression editing. Other methods exhibit shortcomings in preserving the identity, pose or background, and they are unable to support continuous control over the intensity of generated expressions, whereas our method excels in maintaining exceptional detail features and meanwhile allows flexible, fine-grained control to the expression intensity. Please zoom in for more detailed observation.

🔼 This figure compares the performance of a facial expression editing model trained on a laboratory dataset versus a model trained on a more diverse, real-world dataset. The first row shows results from images belonging to the laboratory dataset. The second row shows the model’s performance on images from natural settings. The comparison highlights the model’s limited ability to generalize when trained solely on controlled, lab-based data. The lack of generalization to real-world scenarios is a key finding of the study, emphasizing the limitations of using solely controlled datasets for training.
read the caption
Figure 5: Results of using laboratory dataset for training. In lab setting, the model cannot generalize to image from natural settings (the second row).

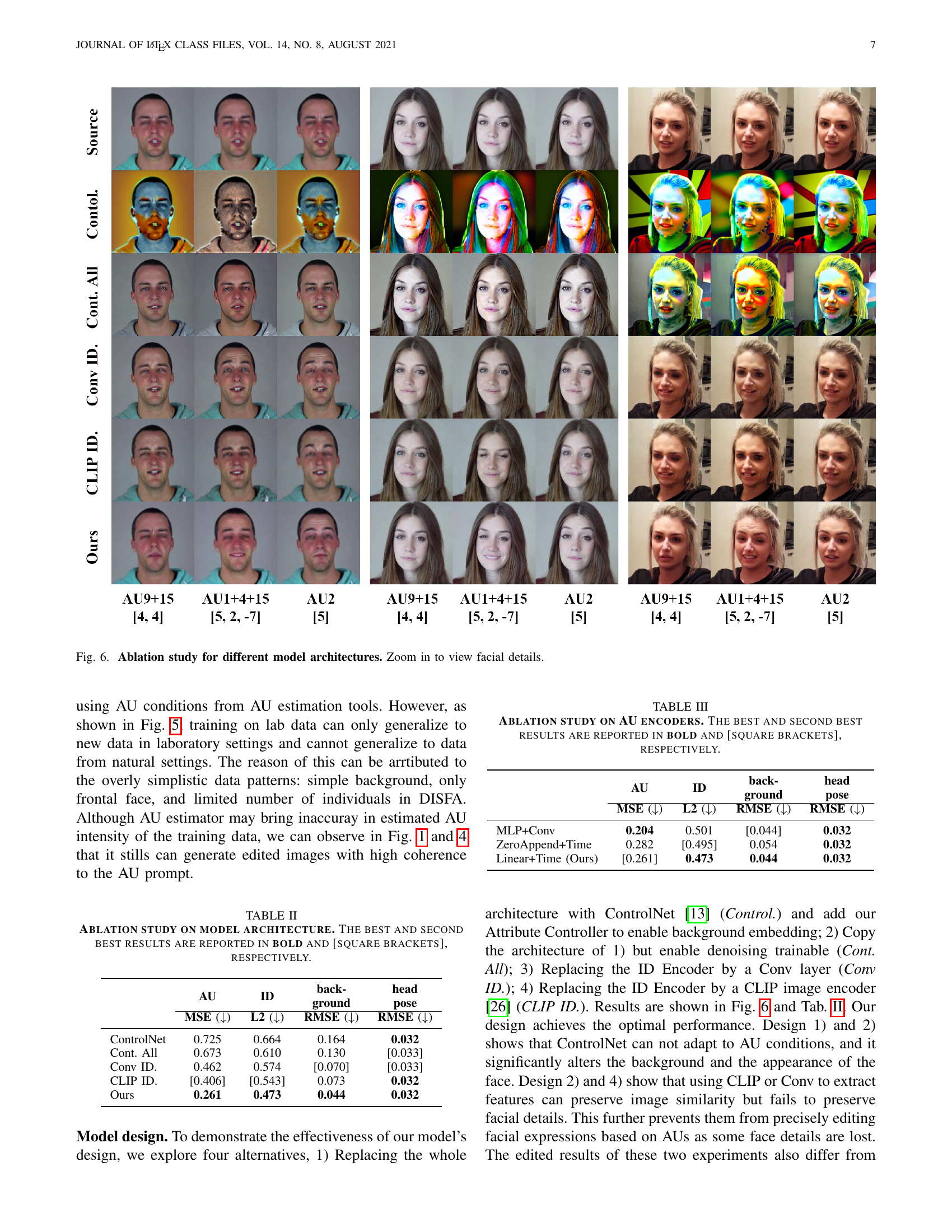
🔼 Figure 6 presents an ablation study comparing MagicFace’s performance against alternative model architectures. The study explores four variations: using ControlNet alone with the addition of the Attribute Controller, training only the denoising UNet portion, replacing the identity encoder with a simple convolutional layer, and substituting a CLIP image encoder for the identity encoder. The results, shown as a series of facial image edits for different AU (Action Unit) combinations for each model architecture, visually demonstrate the impact of each design choice on the ability to maintain identity, accuracy of AU expression, background consistency and pose. This ablation helps to highlight the contribution of each component in MagicFace to achieving high-fidelity facial expression editing.
read the caption
Figure 6: Ablation study for different model architectures. Zoom in to view facial details.

🔼 Figure 7 demonstrates the model’s ability to generalize to out-of-distribution data. The left side shows results of editing real human faces with extreme facial expressions (AU values beyond the typical 0-5 range). The right side shows the same capability applied to cartoon characters, which are visually distinct from the training data. This showcases the model’s robustness and adaptability beyond the scope of its training set.
read the caption
Figure 7: Demonstration of out-of-domain testing for extreme expressions as well as unseen styles. Some AUs are out of the range [0, 5]. The left column displays the editing results of real person photos with extreme expressions and the right column displays that of the cartoon characters.

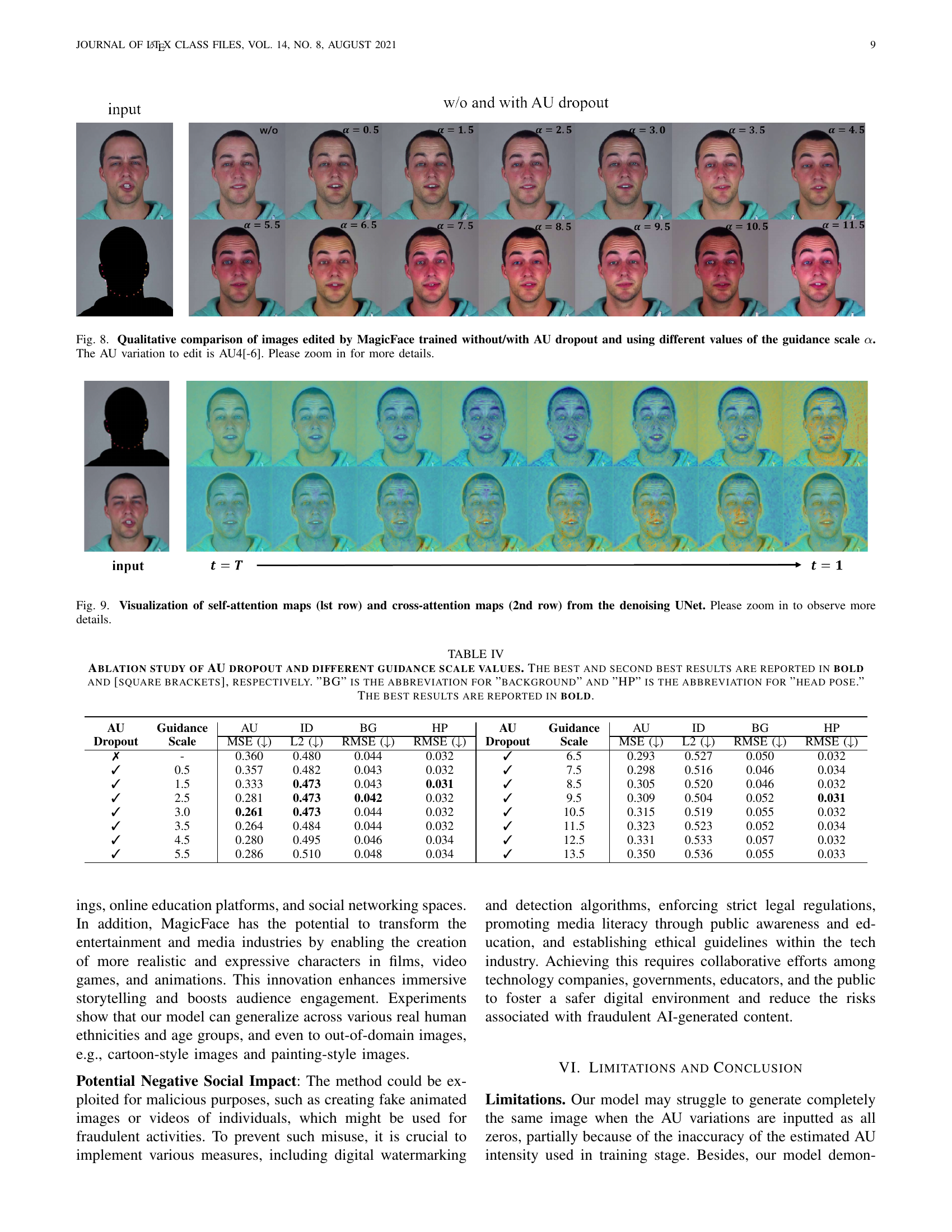
🔼 Figure 8 displays a comparison of facial images edited using the MagicFace model. The experiment investigates the effect of AU dropout (a technique to randomly drop action unit information during training) and the guidance scale (α) on the quality of generated images. The target AU (Action Unit) modified in all examples is AU4, with a decrease in intensity (-6). The top row shows the input image, while subsequent rows present the results obtained with the AU dropout disabled and different values of α (ranging from 0.5 to 13.5). The images demonstrate that using AU dropout and adjusting the value of α allows for a finer level of control over the resulting facial expression and overall image quality. The best quality results are produced with a guidance scale α around 3.0. It shows how different parameter settings affect the image synthesis results and facial expressions.
read the caption
Figure 8: Qualitative comparison of images edited by MagicFace trained without/with AU dropout and using different values of the guidance scale α𝛼\alphaitalic_α. The AU variation to edit is AU4[-6]. Please zoom in for more details.

🔼 Figure 9 visualizes the attention weights within the self-attention and cross-attention mechanisms of the denoising UNet used in MagicFace. The top row displays self-attention maps, illustrating how the model focuses on different parts of the input image at various stages of the denoising process. The bottom row shows cross-attention maps, highlighting the model’s attention to the AU variation condition (input AU values) and its interaction with image features. The figure emphasizes the dynamic shift of attention from a more holistic view to a more focused attention on facial regions related to the specified AU changes as the denoising progresses. Zooming in reveals more detailed changes in attention weight distributions.
read the caption
Figure 9: Visualization of self-attention maps (lst row) and cross-attention maps (2nd row) from the denoising UNet. Please zoom in to observe more details.
More on tables
| Method | AU (↓) | ID (↓) | background RMSE (↓) | head pose RMSE (↓) |
|---|---|---|---|---|
| ControlNet | 0.725 | 0.664 | 0.164 | 0.032 |
| Cont. All | 0.673 | 0.610 | 0.130 | [0.033] |
| Conv ID. | 0.462 | 0.574 | [0.070] | [0.033] |
| CLIP ID. | [0.406] | [0.543] | 0.073 | 0.032 |
| Ours | 0.261 | 0.473 | 0.044 | 0.032 |
🔼 This ablation study analyzes the impact of different model architectures on the performance of facial expression editing. The table compares the Mean Squared Error (MSE) for AU intensity, L2 distance for identity preservation, Root Mean Squared Error (RMSE) for background preservation, and RMSE for head pose preservation across five different model configurations: using ControlNet with the Attribute Controller, using ControlNet with both the Attribute Controller and trainable denoising modules, replacing the ID Encoder with a convolutional layer, replacing the ID Encoder with the CLIP image encoder, and the authors’ proposed method. The best and second-best results for each metric are highlighted.
read the caption
TABLE II: Ablation study on model architecture. The best and second best results are reported in bold and [square brackets], respectively.
| AU | ID | background | headpose | |
|---|---|---|---|---|
| MSE (↓) | L2 (↓) | RMSE (↓) | RMSE (↓) | |
| MLP+Conv | 0.204 | 0.501 | [0.044] | 0.032 |
| ZeroAppend+Time | 0.282 | [0.495] | 0.054 | 0.032 |
| Linear+Time (Ours) | [0.261] | 0.473 | 0.044 | 0.032 |
🔼 This table presents the results of an ablation study comparing different AU (Action Unit) encoder methods used in the MagicFace model. The study investigates how different encodings of action unit variations affect the model’s performance in terms of AU accuracy, identity preservation, background preservation, and head pose preservation. Three different AU encoding methods are compared: MLP+Conv (Multi-Layer Perceptron followed by a Convolutional layer), ZeroAppend+Time (appending zeros to the AU vector and concatenating with time embeddings), and Linear+Time (a linear layer mapping AUs into feature vectors, then concatenating them with time embeddings). The table shows the Mean Squared Error (MSE) for AU accuracy, L2 distance for identity preservation, Root Mean Squared Error (RMSE) for background preservation, and RMSE for head pose preservation. The best and second-best results for each metric are highlighted in bold and square brackets, respectively, to aid comparison.
read the caption
TABLE III: Ablation study on AU encoders. The best and second best results are reported in bold and [square brackets], respectively.
| AU | Guidance | AU | ID | BG | HP | AU | Guidance | AU | ID | BG | HP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dropout | Scale | MSE (↓) | L2 (↓) | RMSE (↓) | RMSE (↓) | Dropout | Scale | MSE (↓) | L2 (↓) | RMSE (↓) | RMSE (↓) |
| ✗ | - | 0.360 | 0.480 | 0.044 | 0.032 | ✓ | 6.5 | 0.293 | 0.527 | 0.050 | 0.032 |
| ✓ | 0.5 | 0.357 | 0.482 | 0.043 | 0.032 | ✓ | 7.5 | 0.298 | 0.516 | 0.046 | 0.034 |
| ✓ | 1.5 | 0.333 | 0.473 | 0.043 | 0.031 | ✓ | 8.5 | 0.305 | 0.520 | 0.046 | 0.032 |
| ✓ | 2.5 | 0.281 | 0.473 | 0.042 | 0.032 | ✓ | 9.5 | 0.309 | 0.504 | 0.052 | 0.031 |
| ✓ | 3.0 | 0.261 | 0.473 | 0.044 | 0.032 | ✓ | 10.5 | 0.315 | 0.519 | 0.055 | 0.032 |
| ✓ | 3.5 | 0.264 | 0.484 | 0.044 | 0.032 | ✓ | 11.5 | 0.323 | 0.523 | 0.052 | 0.034 |
| ✓ | 4.5 | 0.280 | 0.495 | 0.046 | 0.034 | ✓ | 12.5 | 0.331 | 0.533 | 0.057 | 0.032 |
| ✓ | 5.5 | 0.286 | 0.510 | 0.048 | 0.034 | ✓ | 13.5 | 0.350 | 0.536 | 0.055 | 0.033 |
🔼 This ablation study investigates the impact of AU dropout and varying guidance scales on the performance of the MagicFace model. Metrics evaluated include AU accuracy (MSE), identity preservation (L2), background preservation (RMSE), and head pose preservation (RMSE). Results are shown for different AU dropout settings (with and without) and a range of guidance scales (α). The table highlights the optimal combination for achieving the best performance across all four metrics.
read the caption
TABLE IV: Ablation study of AU dropout and different guidance scale values. The best and second best results are reported in bold and [square brackets], respectively. ”BG” is the abbreviation for ”background” and ”HP” is the abbreviation for ”head pose.” The best results are reported in bold.
Full paper#