↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large language models (LLMs) have shown remarkable progress, yet they still face limitations in robustness and complex reasoning. This paper explores test-time computing, a technique that enhances model performance by increasing computational effort during inference. Early test-time computing methods focused on adapting System-1 models—those that rely on pattern recognition—to address issues like distribution shifts. However, the paper’s focus is on advancing LLMs to exhibit System-2 thinking, which involves more deliberate and complex reasoning processes.
The paper organizes its survey according to the shift from System-1 to System-2 thinking. It details various test-time computing techniques for each type of model, including parameter updates, input modification, representation editing, and output calibration for System-1 models. For System-2 models, the paper highlights techniques like repeated sampling, self-correction, and tree search. The study also identifies and discusses several challenges and future research directions, such as achieving generalizable System-2 models, efficient scaling strategies, and extending test-time computing to multimodal scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and deep learning due to its comprehensive survey of test-time computing scaling, a rapidly evolving field. Its framework for understanding the transition from System-1 to System-2 thinking models opens up new research avenues, particularly in the area of multimodal reasoning and efficient scaling strategies for LLMs. By highlighting the limitations of current approaches and proposing future directions, it guides researchers towards more robust and efficient AI systems. The findings are highly relevant to ongoing efforts to improve the reasoning capabilities and generalization of large language models.
Visual Insights#

🔼 This figure illustrates the difference between test-time computing in System-1 and System-2 models. System-1 models are perceptual and primarily utilize test-time adaptation to handle distribution shifts, using methods such as parameter updates, input modification, representation editing, and output calibration. In contrast, System-2 models are cognitive and focus on test-time reasoning, involving techniques like repeated sampling, self-correction, and tree search to solve complex problems. The figure visually represents these two approaches, highlighting the different strategies employed in each system.
read the caption
Figure 1: Illustration of test-time computing in the System-1 and System-2 model.
| Category | sub-category | Representative Methods | Tasks | Verifier/Critic | Train-free |
|---|---|---|---|---|---|
| Repeat Sampling | Majority voting | CoT-SC (2023d) | Math, QA | self-consistency | ✓ |
| PROVE (2024) | Math | compiler | ✓ | ||
| Best-of-N | Cobbe et al. (2021) | Math | ORM | ✗ | |
| DiVeRSe (2023c) | Math | PRM | ✗ | ||
| Self-correction | Human feedback | NL-EDIT (2021) | Semantic parsing | Human | ✗ |
| FBNET (2022) | Code | Human | ✗ | ||
| External tools | DrRepair (2020) | Code | compiler | ✗ | |
| Self-debug (2024c) | Code | compiler | ✓ | ||
| CRITIC (2024) | Math, QA, Detoxifying | text-to-text APIs | ✓ | ||
| External models | REFINER (2024) | Math, Reason | critic model | ✗ | |
| Shepherd (2023b) | QA | critic model | ✗ | ||
| Multiagent Debate (2023) | Math, Reason | multi-agent debate | ✓ | ||
| MAD (2024b) | Translation, Math | multi-agent debate | ✓ | ||
| Intrinsic feedback | Self-Refine (2023) | Math, Code, Controlled generation | self-critique | ✓ | |
| Reflexion (2023) | QA | self-critique | ✓ | ||
| RCI (2023) | Code, QA | self-critique | ✓ | ||
| Tree Search | Uninformed search | ToT (2023) | Planing, Creative writing | self-critique | ✓ |
| Xie et al. (2023) | Math | self-critique | ✓ | ||
| Heuristic search | RAP (2023) | Planing, Math, Logical | self-critique | ✓ | |
| TS-LLM (2024b) | Planing, Math, Logical | ORM | ✗ | ||
| rStar (2024) | Math, QA | multi-agent consistency | ✓ | ||
| ReST-MCTS* (2024a) | Math, QA | PRM | ✗ |
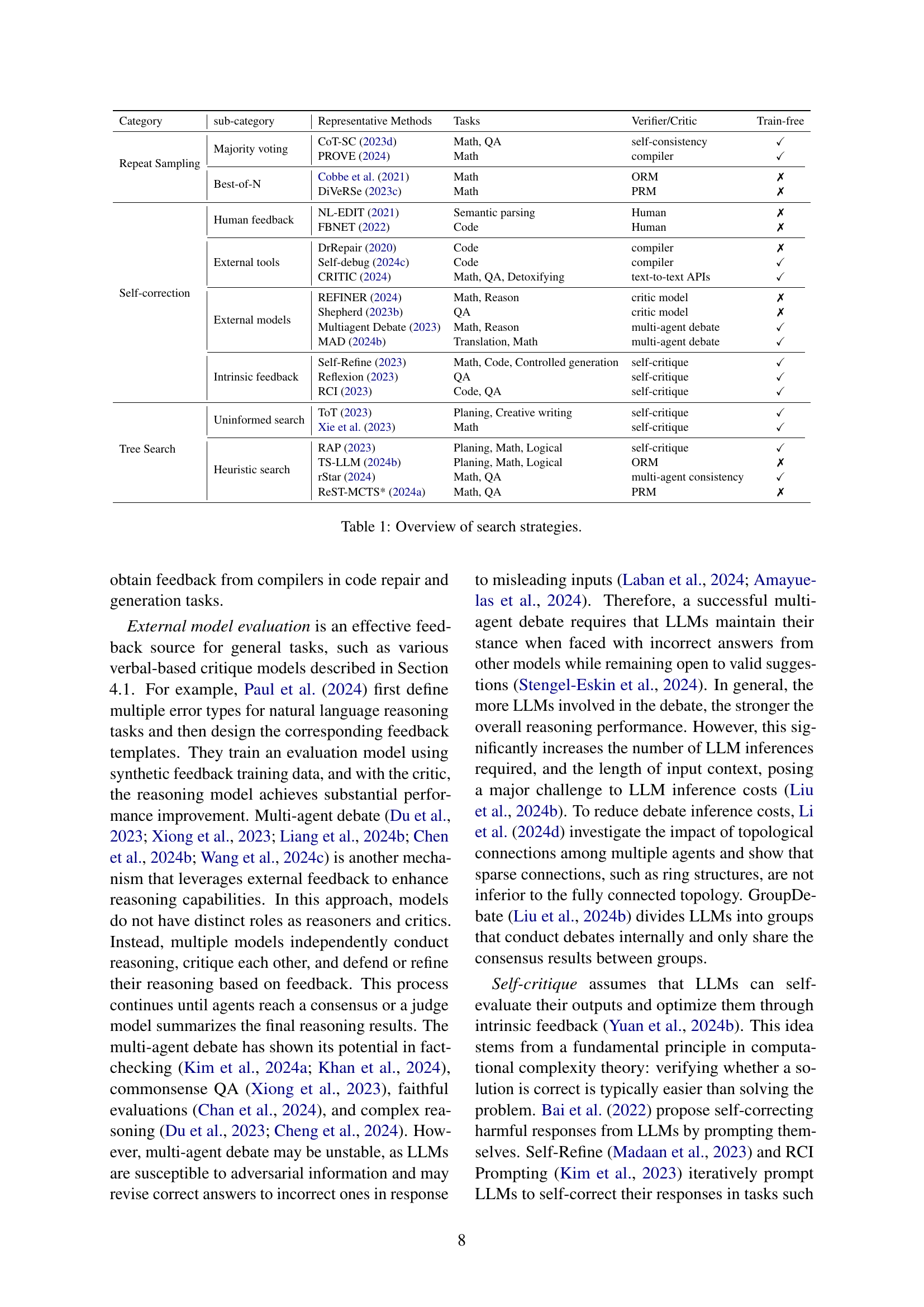
🔼 This table provides a comprehensive overview of various search strategies employed in test-time reasoning within large language models (LLMs). It categorizes methods into three main groups: repeated sampling, self-correction, and tree search, and further breaks down each category into subcategories based on their underlying mechanisms (e.g., majority voting, best-of-N sampling for repeated sampling). For each method, the table lists representative papers, the tasks they are typically applied to, the type of verifier or critic used (if any), and whether the method requires additional training.
read the caption
Table 1: Overview of search strategies.
Full paper#