↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Monocular depth estimation (MDE) is crucial for various applications but faces challenges like slow inference speed and overfitting in diffusion models, especially when adapting generative features for discriminative tasks. Existing methods either rely on large-scale datasets, resulting in time-consuming training, or suffer from low inference speed and suboptimal results.
DepthMaster, a single-step diffusion model, overcomes these issues. It introduces a Feature Alignment module to enhance feature representation by integrating high-quality semantic features, and a Fourier Enhancement module to balance low-frequency structure and high-frequency details, mimicking the iterative refinement process for visual quality. A two-stage training strategy is employed for optimal performance, leading to state-of-the-art results across various benchmarks. The model demonstrates superior detail preservation and generalization capabilities compared to existing diffusion-based and data-driven approaches.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves monocular depth estimation, a crucial task in various fields like autonomous driving and virtual reality. It addresses the limitations of existing diffusion models, such as slow inference speed and overfitting to texture details, thus advancing the state-of-the-art. Its novel modules open up exciting avenues of research, such as exploring more effective feature alignment and frequency enhancement techniques for generative models in discriminative tasks.
Visual Insights#

🔼 This figure visualizes three different approaches to monocular depth estimation: a diffusion-denoising method, a single-step method with Feature Alignment, and a final single-step model incorporating both Feature Alignment and Fourier Enhancement. The diffusion-denoising method is shown to overfit to texture details, while the single-step method with Feature Alignment improves this but produces blurry results. The final model effectively combines global scene structure and fine-grained details.
read the caption
Figure 1: Visualization of different paradigms. “Denoise” refers to predicting depth in a diffusion-denoising way. Limited by the feature representation capability of the denoising network, predictions tend to overfit texture details and miss the real structure, as highlighted with yellow boxes in Column 3. “Stage1” alleviates this issue with the Feature Alignment module, but suffers from blurry outputs due to removing the iterative process, as highlighted with red boxes in Column 4. “Stage2” presents the final model fine-tuned with the Fourier Enhancement module, which exhibits excellent generalization and fine-grained details.
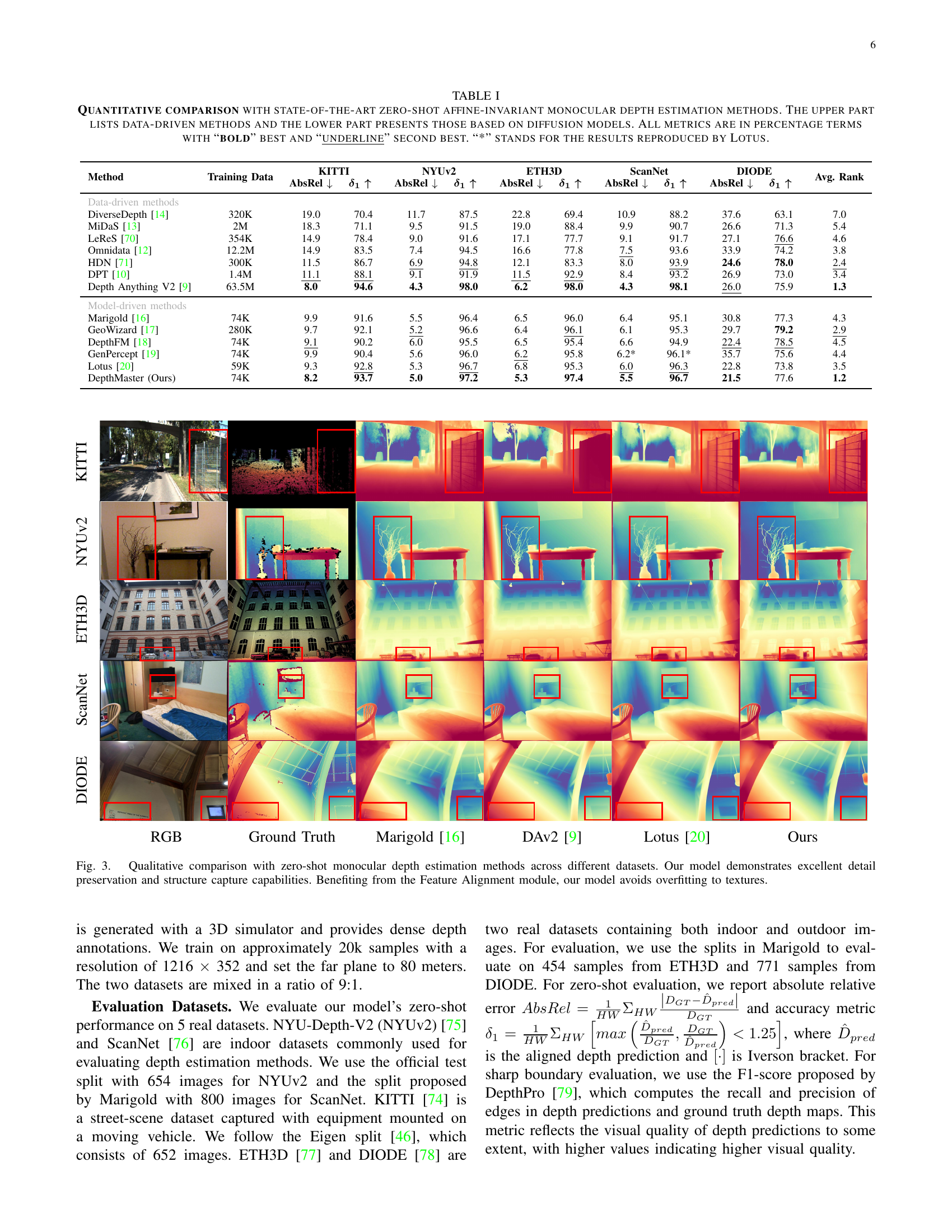
| Method | Training Data | KITTI | NYUv2 | ETH3D | ScanNet | DIODE | Avg. Rank | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data-driven methods | ||||||||||||
| DiverseDepth [14] | 320K | 19.0 | 70.4 | 11.7 | 87.5 | 22.8 | 69.4 | 10.9 | 88.2 | 37.6 | 63.1 | 7.0 |
| MiDaS [13] | 2M | 18.3 | 71.1 | 9.5 | 91.5 | 19.0 | 88.4 | 9.9 | 90.7 | 26.6 | 71.3 | 5.4 |
| LeReS [70] | 354K | 14.9 | 78.4 | 9.0 | 91.6 | 17.1 | 77.7 | 9.1 | 91.7 | 27.1 | 76.6 | 4.6 |
| Omnidata [12] | 12.2M | 14.9 | 83.5 | 7.4 | 94.5 | 16.6 | 77.8 | 7.5 | 93.6 | 33.9 | 74.2 | 3.8 |
| HDN [71] | 300K | 11.5 | 86.7 | 6.9 | 94.8 | 12.1 | 83.3 | 8.0 | 93.9 | 24.6 | 78.0 | 2.4 |
| DPT [10] | 1.4M | 11.1 | 88.1 | 9.1 | 91.9 | 11.5 | 92.9 | 8.4 | 93.2 | 26.9 | 73.0 | 3.4 |
| Depth Anything V2 [9] | 63.5M | 8.0 | 94.6 | 4.3 | 98.0 | 6.2 | 98.0 | 4.3 | 98.1 | 26.0 | 75.9 | 1.3 |
| Model-driven methods | ||||||||||||
| Marigold [16] | 74K | 9.9 | 91.6 | 5.5 | 96.4 | 6.5 | 96.0 | 6.4 | 95.1 | 30.8 | 77.3 | 4.3 |
| GeoWizard [17] | 280K | 9.7 | 92.1 | 5.2 | 96.6 | 6.4 | 96.1 | 6.1 | 95.3 | 29.7 | 79.2 | 2.9 |
| DepthFM [18] | 74K | 9.1 | 90.2 | 6.0 | 95.5 | 6.5 | 95.4 | 6.6 | 94.9 | 22.4 | 78.5 | 4.5 |
| GenPercept [19] | 74K | 9.9 | 90.4 | 5.6 | 96.0 | 6.2 | 95.8 | 6.2* | 96.1* | 35.7 | 75.6 | 4.4 |
| Lotus [20] | 59K | 9.3 | 92.8 | 5.3 | 96.7 | 6.8 | 95.3 | 6.0 | 96.3 | 22.8 | 73.8 | 3.5 |
| DepthMaster (Ours) | 74K | 8.2 | 93.7 | 5.0 | 97.2 | 5.3 | 97.4 | 5.5 | 96.7 | 21.5 | 77.6 | 1.2 |
🔼 This table presents a quantitative comparison of different zero-shot monocular depth estimation methods, categorized into data-driven and diffusion model-based approaches. Metrics such as Absolute Relative error (AbsRel) and Inverse scale consistency (δ1) are shown, evaluating the accuracy of depth prediction. The table highlights the top-performing methods for each dataset (KITTI, NYU-V2, ETH3D, ScanNet, DIODE) using bold for the best and underlined for the second-best performance. Results marked with an asterisk (*) indicate values reproduced from the Lotus method. This allows for a clear comparison between data-driven and model-driven methods and to identify the best-performing techniques within each category.
read the caption
TABLE I: Quantitative comparison with state-of-the-art zero-shot affine-invariant monocular depth estimation methods. The upper part lists data-driven methods and the lower part presents those based on diffusion models. All metrics are in percentage terms with “bold” best and “underline” second best. “*” stands for the results reproduced by Lotus.
In-depth insights#
Diff. Model Adaptation#
Adapting diffusion models for monocular depth estimation presents unique challenges. The generative nature of diffusion models, excelling at detail generation, conflicts with the discriminative task of depth estimation which prioritizes accuracy and structural integrity. Directly applying diffusion models often leads to overfitting on texture details, neglecting crucial structural information. Therefore, effective adaptation strategies must focus on bridging this gap between generative and discriminative feature representations. This involves refining the model’s ability to discern relevant structural features from less important textural details. Successful strategies likely involve incorporating high-quality semantic information from external sources, aligning the model’s internal representations with these external guides. Additionally, addressing the inherent iterative nature of diffusion models by proposing efficient single-step alternatives is crucial to improve inference speed, while simultaneously finding techniques to retain the fine-grained details usually achieved through iterative refinement is needed. This could involve novel loss functions or architectural modifications that encourage a better balance between capturing global structure and fine details in a single forward pass. In summary, adapting diffusion models necessitates a thoughtful approach focusing on feature alignment, efficient model architectures, and optimization methods capable of producing high-quality depth maps in a fast and effective manner.
Feature Alignment#
The concept of ‘Feature Alignment’ in the context of this research paper is crucial for bridging the gap between generative and discriminative models. The core idea is to leverage the strengths of pre-trained generative models, specifically their ability to capture high-quality semantic features, while mitigating their weaknesses in discriminative tasks like depth estimation. Generative models, trained on massive datasets for image reconstruction, often overfit on fine-grained details (textures), which hinders their performance in accurate depth prediction. The proposed Feature Alignment module directly addresses this. By aligning the feature distributions of the generative model (U-Net) with those from a high-quality external encoder (like DINOv2), the model learns to prioritize semantically meaningful information rather than superficial textures. This alignment process effectively introduces crucial high-level contextual understanding into the depth estimation process, leading to more robust and generalized depth maps. The alignment is achieved by minimizing the distance (Kullback-Leibler divergence) between the feature representations from both models, improving the overall representational capability of the generative model for the task of discriminative depth estimation.
Fourier Enhancement#
The Fourier Enhancement module is a crucial component of the DepthMaster model, designed to address the lack of fine-grained details inherent in single-step deterministic depth estimation frameworks. By operating in the frequency domain, it cleverly simulates the iterative refinement process of multi-step diffusion models, achieving high visual quality in a single forward pass. The module’s strength lies in its adaptive balancing of low-frequency structural features and high-frequency details. This is accomplished using a two-component approach: a spatial pass for structure and a frequency pass for details. A modulator network dynamically controls the balance, effectively mimicking the iterative refinement of detail seen in multi-step models. This addresses a key limitation of single-step methods, bridging the gap between speed and quality, while maintaining the efficiency of a deterministic approach. Its integration within DepthMaster significantly improves visual quality and demonstrates the potential of frequency-domain manipulation to enhance the performance of diffusion models in discriminative tasks such as depth estimation.
Two-Stage Training#
The paper’s proposed two-stage training strategy is a crucial element for bridging the gap between generative and discriminative learning in the context of monocular depth estimation. Stage one focuses on learning global scene structure, leveraging a Feature Alignment module to align the model’s feature distributions with those of a high-quality external encoder. This mitigates overfitting to texture details often found in generative models. By concentrating on structure in the first stage, the model builds a robust foundation for accurate depth perception. In stage two, the focus shifts to detail refinement. The Fourier Enhancement module adaptively balances low and high-frequency details, effectively simulating the iterative refinement process of traditional diffusion models without the computational overhead. This two-stage process allows for effective learning of both global scene understanding and fine-grained details, resulting in significantly improved depth estimation accuracy and visual quality. The sequential nature of the training elegantly addresses the trade-off between capturing structural information and preserving fine-grained details.
Zero-Shot Limits#
The concept of “Zero-Shot Limits” in the context of a research paper likely explores the boundaries of zero-shot learning. It would delve into the inherent limitations of models trained without any direct exposure to the target task’s data. This section likely investigates the factors restricting performance, such as the reliance on transferable knowledge from source domains, the mismatch between source and target data distributions, and the complexity of the target task itself. Analyzing these limits is crucial for understanding when zero-shot learning succeeds or fails and for guiding future research towards improving its robustness and capabilities. A key aspect might involve identifying scenarios where zero-shot learning is particularly challenging or even inappropriate, highlighting cases where task-specific training data is essential for acceptable performance. This discussion would provide valuable insights into the practical applicability and scope of zero-shot learning and suggest potential areas for improvement.
More visual insights#
More on tables
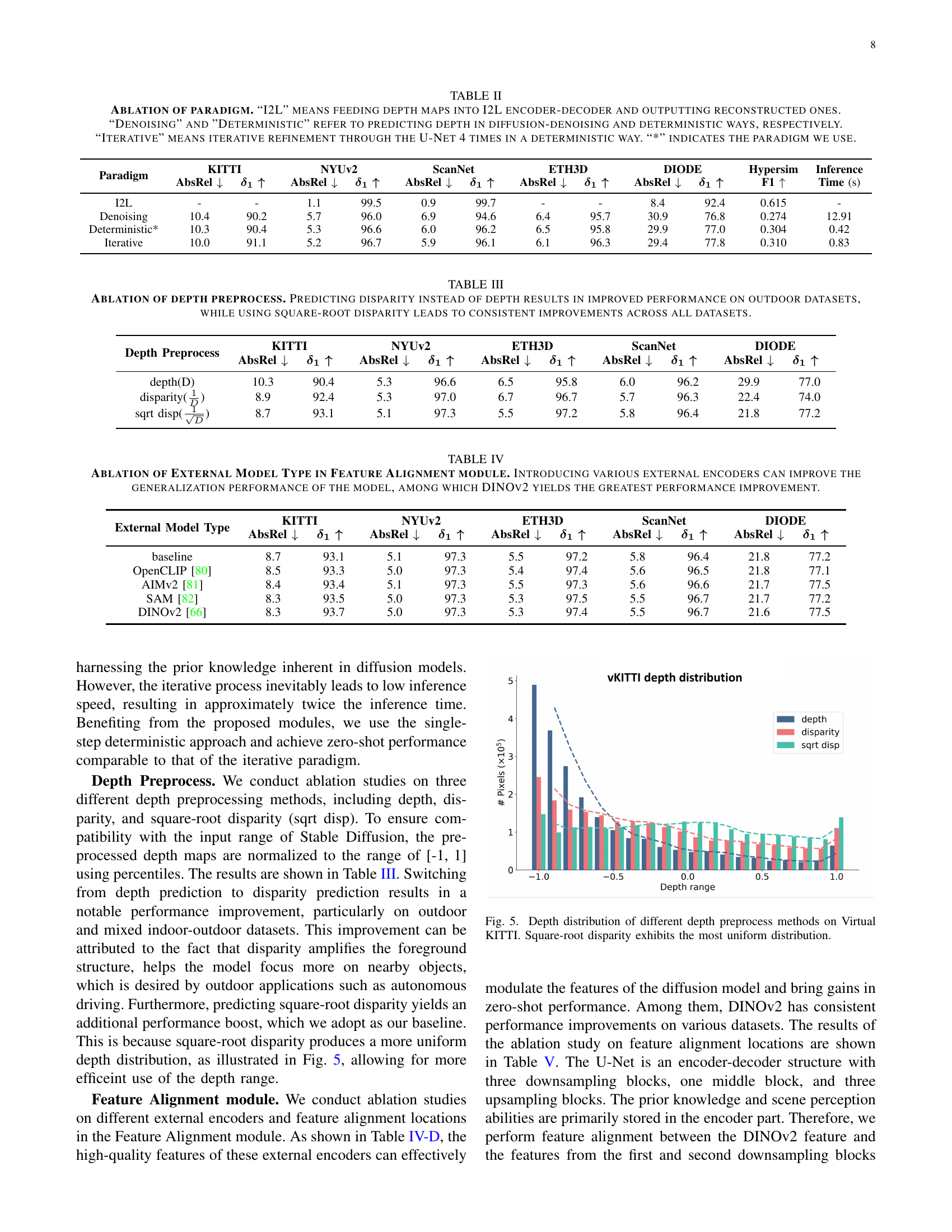
| Paradigm | KITTI AbsRel ↓ | KITTI δ₁ ↑ | NYUv2 AbsRel ↓ | NYUv2 δ₁ ↑ | ScanNet AbsRel ↓ | ScanNet δ₁ ↑ | ETH3D AbsRel ↓ | ETH3D δ₁ ↑ | DIODE AbsRel ↓ | DIODE δ₁ ↑ | Hypersim AbsRel ↓ | Hypersim F1 ↑ | Time (s) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I2L | - | - | 1.1 | 99.5 | 0.9 | 99.7 | - | - | 8.4 | 92.4 | 0.615 | - | ||
| Denoising | 10.4 | 90.2 | 5.7 | 96.0 | 6.9 | 94.6 | 6.4 | 95.7 | 30.9 | 76.8 | 0.274 | 12.91 | ||
| Deterministic* | 10.3 | 90.4 | 5.3 | 96.6 | 6.0 | 96.2 | 6.5 | 95.8 | 29.9 | 77.0 | 0.304 | 0.42 | ||
| Iterative | 10.0 | 91.1 | 5.2 | 96.7 | 5.9 | 96.1 | 6.1 | 96.3 | 29.4 | 77.8 | 0.310 | 0.83 |
🔼 This table presents an ablation study comparing different approaches for depth prediction within the DepthMaster model. It contrasts three main paradigms: 1) Using the I2L (Image-to-Latent) encoder-decoder to reconstruct depth maps, 2) Predicting depth through a diffusion-denoising process, and 3) Directly predicting depth in a deterministic manner. The table also includes a fourth approach which iteratively refines the depth prediction four times using the U-Net in a deterministic manner. The results are shown for various metrics across multiple datasets, indicating which paradigm performed best for the model, marked by an asterisk (*).
read the caption
TABLE II: Ablation of paradigm. “I2L” means feeding depth maps into I2L encoder-decoder and outputting reconstructed ones. “Denoising” and ”Deterministic” refer to predicting depth in diffusion-denoising and deterministic ways, respectively. “Iterative” means iterative refinement through the U-Net 4 times in a deterministic way. “*” indicates the paradigm we use.
| Depth Preprocess | KITTI | NYUv2 | ETH3D | ScanNet | DIODE | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | |
| depth(D) | 10.3 | 90.4 | 5.3 | 96.6 | 6.5 | 95.8 | 6.0 | 96.2 | 29.9 | 77.0 |
| disparity(1/D) | 8.9 | 92.4 | 5.3 | 97.0 | 6.7 | 96.7 | 5.7 | 96.3 | 22.4 | 74.0 |
| sqrt disp(1/√D) | 8.7 | 93.1 | 5.1 | 97.3 | 5.5 | 97.2 | 5.8 | 96.4 | 21.8 | 77.2 |
🔼 This ablation study investigates the impact of different depth representation choices on the model’s performance. It compares using depth values directly, disparity values, and square root disparity. The results show that using disparity improves performance, especially on outdoor scenes. Furthermore, utilizing square root disparity consistently improves performance across all datasets, suggesting it is the best approach.
read the caption
TABLE III: Ablation of depth preprocess. Predicting disparity instead of depth results in improved performance on outdoor datasets, while using square-root disparity leads to consistent improvements across all datasets.
| External Model Type | KITTI | NYUv2 | ETH3D | ScanNet | DIODE | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| AbsRel ↓ | 𝜹₁ ↑ | AbsRel ↓ | 𝜹₁ ↑ | AbsRel ↓ | 𝜹₁ ↑ | AbsRel ↓ | 𝜹₁ ↑ | AbsRel ↓ | 𝜹₁ ↑ | |
| baseline | 8.7 | 93.1 | 5.1 | 97.3 | 5.5 | 97.2 | 5.8 | 96.4 | 21.8 | 77.2 |
| OpenCLIP [80] | 8.5 | 93.3 | 5.0 | 97.3 | 5.4 | 97.4 | 5.6 | 96.5 | 21.8 | 77.1 |
| AIMv2 [81] | 8.4 | 93.4 | 5.1 | 97.3 | 5.5 | 97.3 | 5.6 | 96.6 | 21.7 | 77.5 |
| SAM [82] | 8.3 | 93.5 | 5.0 | 97.3 | 5.3 | 97.5 | 5.5 | 96.7 | 21.7 | 77.2 |
| DINOv2 [66] | 8.3 | 93.7 | 5.0 | 97.3 | 5.3 | 97.4 | 5.5 | 96.7 | 21.6 | 77.5 |
🔼 This table presents the results of ablation studies on different external encoder models used within the Feature Alignment module of the DepthMaster model. The goal is to determine how the choice of external encoder impacts the model’s overall performance, specifically its generalization capabilities. The table compares the performance of the DepthMaster model using various external encoders (OpenCLIP, AIMv2, SAM, and DINOv2) across five different datasets (KITTI, NYU-Depth V2, ETH3D, ScanNet, and DIODE), measuring the absolute relative error (AbsRel) and the accuracy metric δ1. The results indicate that incorporating high-quality external features significantly improves the model’s performance, and DINOv2 provides the best performance improvement among the tested encoders.
read the caption
TABLE IV: Ablation of External Model Type in Feature Alignment module. Introducing various external encoders can improve the generalization performance of the model, among which DINOv2 yields the greatest performance improvement.
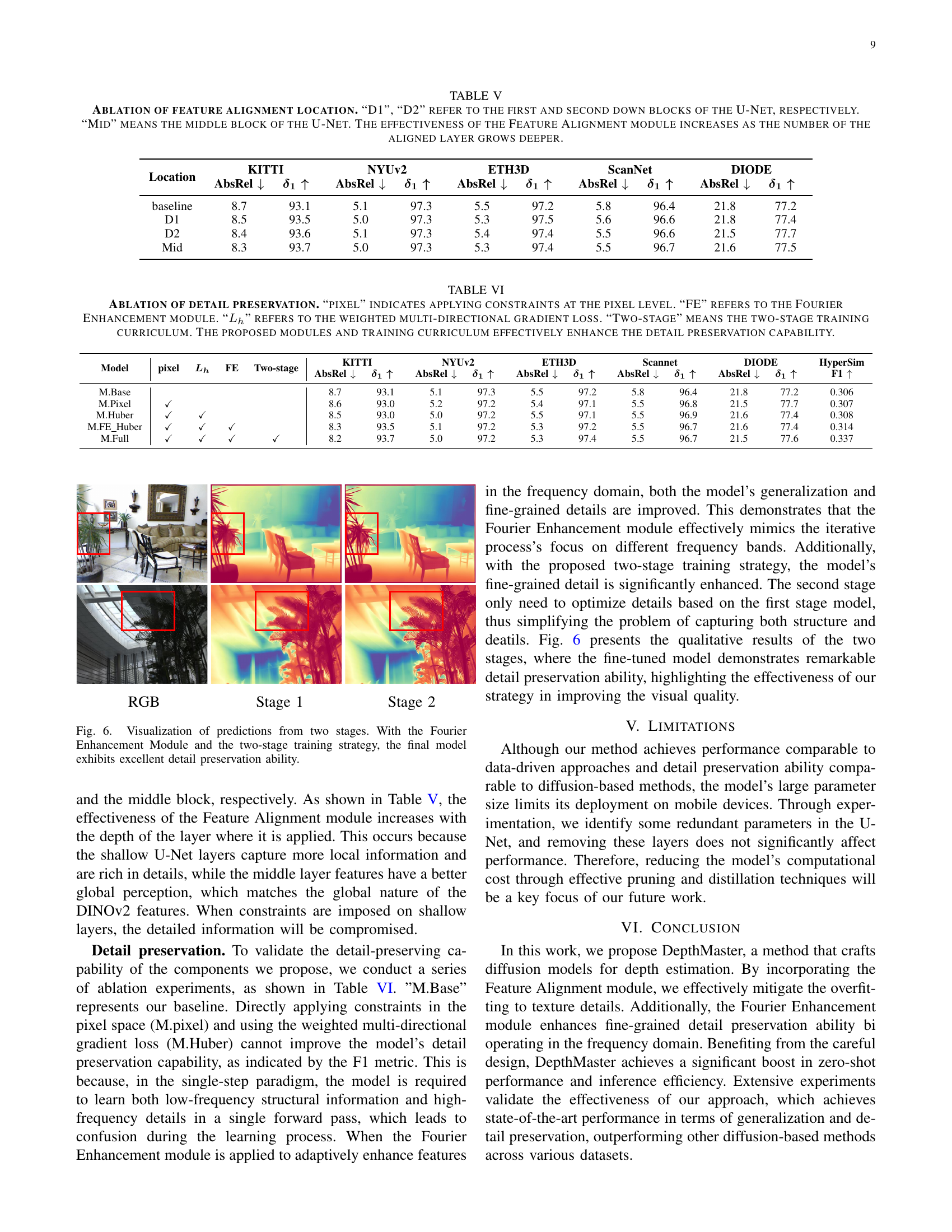
| Location | KITTI | NYUv2 | ETH3D | ScanNet | DIODE | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | AbsRel ↓ | δ₁ ↑ | |
| — | — | — | — | — | — | — | — | — | — | — |
| baseline | 8.7 | 93.1 | 5.1 | 97.3 | 5.5 | 97.2 | 5.8 | 96.4 | 21.8 | 77.2 |
| D1 | 8.5 | 93.5 | 5.0 | 97.3 | 5.3 | 97.5 | 5.6 | 96.6 | 21.8 | 77.4 |
| D2 | 8.4 | 93.6 | 5.1 | 97.3 | 5.4 | 97.4 | 5.5 | 96.6 | 21.5 | 77.7 |
| Mid | 8.3 | 93.7 | 5.0 | 97.3 | 5.3 | 97.4 | 5.5 | 96.7 | 21.6 | 77.5 |
🔼 This table presents an ablation study on the placement of the Feature Alignment module within the U-Net architecture of the DepthMaster model. The Feature Alignment module aligns features from the model with those of an external encoder. The table shows the results of placing this module at different depths within the U-Net: after the first downsampling block (D1), after the second downsampling block (D2), and in the middle block (Mid). The results (AbsRel and δ1 metrics) for different datasets (KITTI, NYU-v2, ETH3D, ScanNet, DIODE) are shown to demonstrate the impact of the module’s location on the model’s performance. The key finding is that deeper placement generally leads to better performance, indicating the importance of higher-level semantic features for alignment.
read the caption
TABLE V: Ablation of feature alignment location. “D1”, “D2” refer to the first and second down blocks of the U-Net, respectively. “Mid” means the middle block of the U-Net. The effectiveness of the Feature Alignment module increases as the number of the aligned layer grows deeper.
| Model | pixel | Lh | FE | Two-stage | KITTI AbsRel ↓ | KITTI δ1 ↑ | NYUv2 AbsRel ↓ | NYUv2 δ1 ↑ | ETH3D AbsRel ↓ | ETH3D δ1 ↑ | Scannet AbsRel ↓ | Scannet δ1 ↑ | DIODE AbsRel ↓ | DIODE δ1 ↑ | HyperSim F1 ↑ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M.Base | 8.7 | 93.1 | 5.1 | 97.3 | 5.5 | 97.2 | 5.8 | 96.4 | 21.8 | 77.2 | 0.306 | |||||
| M.Pixel | ✓ | 8.6 | 93.0 | 5.2 | 97.2 | 5.4 | 97.1 | 5.5 | 96.8 | 21.5 | 77.7 | 0.307 | ||||
| M.Huber | ✓ | ✓ | 8.5 | 93.0 | 5.0 | 97.2 | 5.5 | 97.1 | 5.5 | 96.9 | 21.6 | 77.4 | 0.308 | |||
| M.FE_Huber | ✓ | ✓ | ✓ | 8.3 | 93.5 | 5.1 | 97.2 | 5.3 | 97.2 | 5.5 | 96.7 | 21.6 | 77.4 | 0.314 | ||
| M.Full | ✓ | ✓ | ✓ | ✓ | 8.2 | 93.7 | 5.0 | 97.2 | 5.3 | 97.4 | 5.5 | 96.7 | 21.5 | 77.6 | 0.337 |
🔼 This ablation study analyzes the impact of different components on detail preservation in the DepthMaster model. It compares the baseline model against versions with pixel-level constraints, the Fourier Enhancement module (FE), the weighted multi-directional gradient loss (Lh), and the two-stage training curriculum. The results show how each component contributes to improving the model’s ability to accurately represent fine details in depth estimations.
read the caption
TABLE VI: Ablation of detail preservation. “pixel” indicates applying constraints at the pixel level. “FE” refers to the Fourier Enhancement module. “Lhsubscript𝐿ℎL_{h}italic_L start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT” refers to the weighted multi-directional gradient loss. “Two-stage” means the two-stage training curriculum. The proposed modules and training curriculum effectively enhance the detail preservation capability.
Full paper#