↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current video generation models struggle with precise 4D control (e.g., multi-camera shots, dolly zoom). Existing methods require expensive multi-view training data or suffer from poor generalization and artifacts. The lack of efficient 4D control hinders realistic video generation for creative applications.
This paper introduces GS-DiT, a framework that uses pseudo 4D Gaussian fields to generate videos with advanced 4D control. GS-DiT leverages a novel, efficient dense 3D point tracking method (D3D-PT) to build these fields, avoiding the need for multi-view data. The method boasts speed and accuracy improvements over existing sparse methods. Experiments demonstrate GS-DiT’s capabilities in generating videos with complex camera movements and object manipulation, showcasing significant improvements in video quality and control over prior approaches.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances video generation by enabling sophisticated 4D control, previously unachievable. The efficient dense 3D point tracking method (D3D-PT) and the GS-DiT framework offer a novel approach to generating videos with multi-camera effects, dolly zoom, and object motion editing. This is relevant to current trends in high-quality video synthesis and opens avenues for cinematic video production and interactive media applications.
Visual Insights#

🔼 This figure showcases the GS-DiT framework’s ability to generate videos from multiple camera angles. The framework leverages pseudo 4D Gaussian fields, which provide a compact representation of the 4D spatiotemporal information within the video. GS-DiT uses these fields to guide a video diffusion transformer, resulting in the generation of multi-camera videos that maintain visual consistency and dynamic content throughout the different viewpoints.
read the caption
Figure 1: GS-DiT generates multi-camera shooting videos by bringing pseudo 4D Gaussian fields to video diffusion transformers.
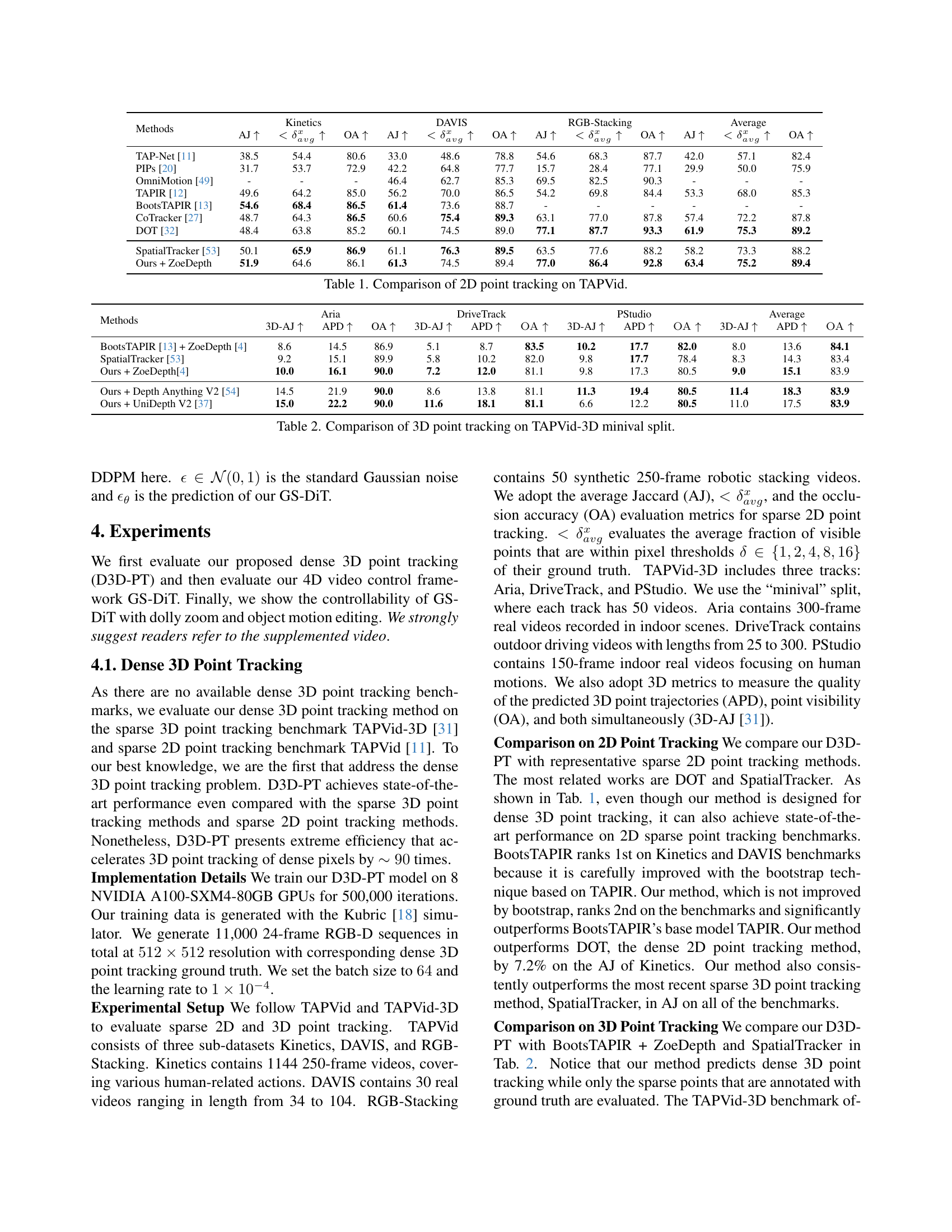
| Methods | Kinetics AJ ↑ | Kinetics <δxavg↑ | Kinetics OA ↑ | DAVIS AJ ↑ | DAVIS <δxavg↑ | DAVIS OA ↑ | RGB-Stacking AJ ↑ | RGB-Stacking <δxavg↑ | RGB-Stacking OA ↑ | Average AJ ↑ | Average <δxavg↑ | Average OA ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TAP-Net [11] | 38.5 | 54.4 | 80.6 | 33.0 | 48.6 | 78.8 | 54.6 | 68.3 | 87.7 | 42.0 | 57.1 | 82.4 |
| PIPs [20] | 31.7 | 53.7 | 72.9 | 42.2 | 64.8 | 77.7 | 15.7 | 28.4 | 77.1 | 29.9 | 50.0 | 75.9 |
| OmniMotion [49] | - | - | - | 46.4 | 62.7 | 85.3 | 69.5 | 82.5 | 90.3 | - | - | - |
| TAPIR [12] | 49.6 | 64.2 | 85.0 | 56.2 | 70.0 | 86.5 | 54.2 | 69.8 | 84.4 | 53.3 | 68.0 | 85.3 |
| BootsTAPIR [13] | 54.6 | 68.4 | 86.5 | 61.4 | 73.6 | 88.7 | - | - | - | - | - | - |
| CoTracker [27] | 48.7 | 64.3 | 86.5 | 60.6 | 75.4 | 89.3 | 63.1 | 77.0 | 87.8 | 57.4 | 72.2 | 87.8 |
| DOT [32] | 48.4 | 63.8 | 85.2 | 60.1 | 74.5 | 89.0 | 77.1 | 87.7 | 93.3 | 61.9 | 75.3 | 89.2 |
| SpatialTracker [53] | 50.1 | 65.9 | 86.9 | 61.1 | 76.3 | 89.5 | 63.5 | 77.6 | 88.2 | 58.2 | 73.3 | 88.2 |
| Ours + ZoeDepth | 51.9 | 64.6 | 86.1 | 61.3 | 74.5 | 89.4 | 77.0 | 86.4 | 92.8 | 63.4 | 75.2 | 89.4 |
🔼 This table presents a comparison of various 2D point tracking methods on the TAPVid benchmark dataset. The TAPVid benchmark consists of three subsets: Kinetics (human-related actions), DAVIS (real-world videos), and RGB-Stacking (synthetic robotic videos). For each method and dataset, the table shows three metrics: Average Jaccard (AJ), which measures the average fraction of visible points within a certain distance of their ground truth positions; the average fraction of visible points within a certain distance of their ground truth positions (< δavg), and Overall Accuracy (OA), representing the overall success rate of point tracking. Higher values for AJ and OA indicate better performance.
read the caption
Table 1: Comparison of 2D point tracking on TAPVid.
In-depth insights#
4D Video Control#
The concept of “4D Video Control” signifies a significant advancement in video generation, moving beyond conventional 2D or 3D manipulation. It emphasizes control over not only spatial aspects (x, y, z) but also the temporal dimension (t), enabling nuanced manipulation of camera position, movement, and object dynamics within a video. This offers unprecedented creative freedom, allowing for effects like multi-camera shooting, dolly zooms, and sophisticated object motion edits, mimicking professional filmmaking techniques. The paper’s approach, using pseudo 4D Gaussian fields and efficient dense 3D point tracking, presents a computationally feasible method to achieve this level of control. The key innovation lies in constructing this field from readily available monocular videos, rather than requiring costly multi-view data. This addresses the limitations of existing methods, which often rely on simulated environments or extensive data collection, enabling a more practical and scalable solution for 4D video generation. The framework effectively bridges the gap between efficient 3D point tracking and the powerful expressivity of diffusion transformers, resulting in a model that learns to generate videos by following guidance extracted from these pseudo 4D fields. This paradigm paves the way for richer, more cinematic video experiences, greatly expanding the possibilities of video synthesis and manipulation.
Gaussian Fields#
The concept of Gaussian fields is central to the paper’s approach for achieving 4D video control. Pseudo 4D Gaussian fields are constructed using efficient dense 3D point tracking, providing a computationally feasible alternative to directly optimizing a full 4D representation. This construction leverages the spatial and temporal information from the input video to represent the dynamic elements within the scene. The Gaussian field then acts as a powerful intermediary representation to render novel views and guide the video diffusion transformer. The use of pseudo 4D Gaussian fields is significant because it allows for flexible and efficient 4D video control, enabling effects like multi-camera shooting and dolly zoom, without the computational cost and limitations associated with traditional methods. Furthermore, the flexibility extends to controlling camera parameters and object motion. The approach highlights a clever trade-off between computational efficiency and 4D control, making it a potentially valuable contribution to the field of video generation.
Dense 3D Tracking#
The concept of ‘Dense 3D Point Tracking’ within the context of video generation is crucial for achieving advanced 4D control. The method presented aims to overcome limitations of existing techniques by efficiently estimating dense 3D point trajectories across video frames. This is achieved through a two-stage process: initial sparse tracking followed by iterative refinement. The innovation lies in its loose coupling to depth estimation, improving generalization to real-world scenarios. Unlike tightly-coupled methods relying on accurate depth maps, this approach uses depth information loosely to refine 3D points, making it more robust. This efficiency is a significant advantage, offering substantial speed improvements compared to state-of-the-art methods like SpatialTracker, making the approach feasible for large-scale video processing and 4D video generation. The performance gains are substantial, with speed increased by orders of magnitude while maintaining accuracy. This advancement greatly facilitates the generation of high-quality videos with diverse cinematic effects. The efficient tracking is, therefore, a key enabler for the overall system’s 4D control capabilities.
GS-DiT Framework#
The GS-DiT framework innovatively uses pseudo 4D Gaussian fields to enhance video generation, addressing limitations in current models. It leverages an efficient Dense 3D Point Tracking (D3D-PT) method for constructing these fields, bypassing computationally expensive optimization techniques. This pseudo 4D representation is used to render videos guiding a pre-trained Diffusion Transformer (DiT). The core advantage lies in enabling 4D control over video generation, encompassing camera parameters (intrinsics and extrinsics), and even object motion, all without requiring expensive multi-view training data. GS-DiT achieves this by finetuning the DiT with rendered videos from the pseudo 4D Gaussian fields. The generated videos are guided by this rendered data, allowing for sophisticated lens techniques like multi-camera shooting and dolly zoom. The D3D-PT is a key component, demonstrating superior accuracy and speed compared to existing methods, enabling efficient pseudo 4D field generation. Overall, GS-DiT offers a novel approach to 4D video generation, opening doors for greater creative control and cinematic effects, all while being trainable on readily available monocular videos.
Future of 4D Video#
The “Future of 4D Video” hinges on efficient and robust 4D representation and manipulation techniques. Current methods, while showing promise, often struggle with computational cost and generalization to real-world scenarios. The paper’s focus on pseudo 4D Gaussian fields offers a potential pathway by leveraging efficient 3D point tracking. Future progress will likely involve improving the accuracy and speed of dense 3D point tracking, exploring alternative 4D representations better suited for complex dynamic scenes, and developing more sophisticated video generation models capable of harnessing richer 4D information. Integrating neural rendering with advanced 4D fields could produce photorealistic novel views while reducing computational burdens. The ability to seamlessly incorporate user-defined controls for camera parameters, object motion, and lighting would revolutionize video generation and editing. Ultimately, the future of 4D video lies in the balance between realistic, controllable content and the efficiency of the underlying algorithms, potentially leading to a new era of immersive and interactive video experiences.
More visual insights#
More on figures

🔼 This figure illustrates the GS-DiT framework. The training process begins with dense 3D point tracking of an input video to construct a pseudo 4D Gaussian field. This field is then rendered into a video, which serves as guidance for a pre-trained video diffusion transformer (DiT) that’s fine-tuned to generate the original input video. During inference, the pseudo 4D Gaussian field can be created using 3D point tracking, depth map lifting, or 4D Gaussian field optimization. Manipulating the Gaussian field parameters (camera intrinsics and extrinsics) allows for cinematic effects like multi-camera shooting and dolly zoom.
read the caption
Figure 2: An overview of GS-DiT. In the training stage, we build a pseudo 4D Gaussian field from an input video via dense 3D point tracking. Our GS-DiT learns to generate the original video guided by the video rendered from the pseudo 4D Gaussian field. In the inference stage, we can build the pseudo 4D Gaussian via dense 3D point tracking, directly lifting the depth map, or optimizing a 4D Gaussian field. Editing and rendering the Gaussian field with scheduled camera intrinsic and extrinsic bring various cinematic effects.

🔼 The figure illustrates the architecture of the GS-DiT model. It shows how a pre-trained video diffusion transformer (DiT) is fine-tuned using videos rendered from a pseudo 4D Gaussian field. The pseudo 4D Gaussian field is constructed using 3D point tracking from the input video. The fine-tuned DiT then generates videos conditioned on this rendered video, allowing for advanced 4D control over the generated video content.
read the caption
Figure 3: The neural network architecture of GS-DiT. GS-DiT generates video conditioned on the video rendered from our pseudo 4D Gaussian field.

🔼 Figure 4 presents a qualitative comparison of three different video generation methods in terms of their ability to generate synchronized videos with camera control. The input video’s first and last frames are shown in (a) and (b). Panel (c) visualizes the camera trajectory used for the generation. The last frames generated by GS-DiT (the authors’ proposed method), GCD, and MonST3R are displayed in (d), (e), and (f) respectively, allowing for a visual comparison of the results of each method.
read the caption
Figure 4: Qualitative comparison of synchronized video generation with camera control. (a)(b) are the first and last frame of the input video. (c) is the camera trajectory visualization. (d)(e)(f) are the last frame of the video generated by our GS-DiT, GCD, and MonST3R.

🔼 This figure demonstrates the capabilities of GS-DiT in controlling video generation with four-dimensional (4D) control. Subfigure (a) shows the effect of a dolly zoom, a cinematic technique that involves simultaneous zooming and camera movement to create a dynamic perspective shift. Subfigure (b) illustrates object manipulation, specifically rotating the blades of a fan, showcasing the model’s ability to modify individual elements within a video scene, all within the 4D control framework of GS-DiT.
read the caption
Figure 5: Video generation with 4D control. (a) presents the dolly zoom effects and (b) rotates the body of the fan.

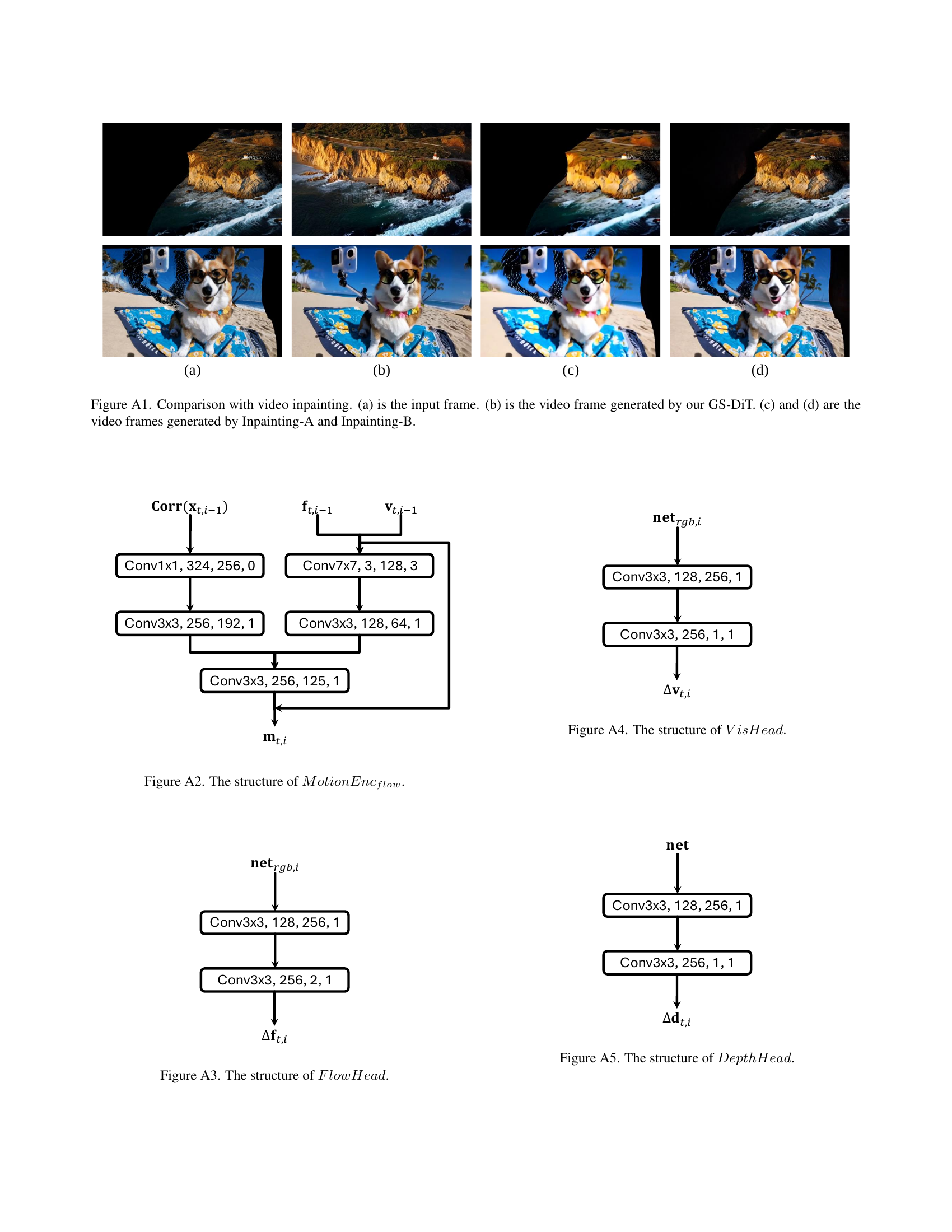
🔼 This figure compares the video inpainting results of GS-DiT against two baseline methods (Inpainting-A and Inpainting-B). It shows how GS-DiT successfully fills in missing parts of the video frame, while the baseline methods struggle to produce coherent results. The input frame (a) is compared with the output of GS-DiT (b), Inpainting-A (c), and Inpainting-B (d), highlighting GS-DiT’s superiority in restoring the integrity of the video.
read the caption
Figure A1: Comparison with video inpainting. (a) is the input frame. (b) is the video frame generated by our GS-DiT. (c) and (d) are the video frames generated by Inpainting-A and Inpainting-B.

🔼 Figure A2 shows the architecture of the MotionEnc_flow module used in the D3D-PT (Dense 3D Point Tracking) method. The input consists of the cropped correlation information from the previous iteration (Corr(x_t,i-1)), the flow from the previous iteration (f_t,i-1), and the visibility from the previous iteration (v_t,i-1). These inputs are processed through a series of convolutional layers (Conv1x1, Conv7x7, Conv3x3) to extract relevant motion features. The output is the motion feature (m_t,i), which is then fed into the ConvGRU_flow module for further processing.
read the caption
Figure A2: The structure of MotionEncflow𝑀𝑜𝑡𝑖𝑜𝑛𝐸𝑛subscript𝑐𝑓𝑙𝑜𝑤{MotionEnc_{flow}}italic_M italic_o italic_t italic_i italic_o italic_n italic_E italic_n italic_c start_POSTSUBSCRIPT italic_f italic_l italic_o italic_w end_POSTSUBSCRIPT.

🔼 Figure A3 illustrates the architecture of the FlowHead component within the D3D-PT (Dense 3D Point Tracking) module. FlowHead takes as input the output of a convolutional recurrent neural network (ConvGRU), processes it through several convolutional layers (Conv3x3), and ultimately outputs a refined flow field (Δft,i), representing the update to the point tracks. The use of convolutional layers allows for spatial context to be considered in refining the flow estimations. The structure depicts a feed-forward network design, enhancing the precision of the point tracking by leveraging spatial information.
read the caption
Figure A3: The structure of FlowHead𝐹𝑙𝑜𝑤𝐻𝑒𝑎𝑑{FlowHead}italic_F italic_l italic_o italic_w italic_H italic_e italic_a italic_d.

🔼 Figure A4 shows the architecture of the VisHead component within the D3D-PT (Dense 3D Point Tracking) module. VisHead predicts the visibility of 3D points, indicating whether they are visible or occluded in a given frame. The figure details the convolutional layers used to process input features and produce the visibility prediction. The network uses several convolutional layers (Conv3x3) of varying filter sizes (e.g., 128, 256) to extract relevant features. The final layer uses a 1x1 convolution to output the visibility prediction. The structure is part of the iterative refinement process where points’ 2D locations, depths, and visibility are progressively refined.
read the caption
Figure A4: The structure of VisHead𝑉𝑖𝑠𝐻𝑒𝑎𝑑{VisHead}italic_V italic_i italic_s italic_H italic_e italic_a italic_d.
More on tables
| Methods | Aria 3D-AJ ↑ | Aria APD ↑ | Aria OA ↑ | DriveTrack 3D-AJ ↑ | DriveTrack APD ↑ | DriveTrack OA ↑ | PStudio 3D-AJ ↑ | PStudio APD ↑ | PStudio OA ↑ | Average 3D-AJ ↑ | Average APD ↑ | Average OA ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BootsTAPIR [13] + ZoeDepth [4] | 8.6 | 14.5 | 86.9 | 5.1 | 8.7 | 83.5 | 10.2 | 17.7 | 82.0 | 8.0 | 13.6 | 84.1 |
| SpatialTracker [53] | 9.2 | 15.1 | 89.9 | 5.8 | 10.2 | 82.0 | 9.8 | 17.7 | 78.4 | 8.3 | 14.3 | 83.4 |
| Ours + ZoeDepth [4] | 10.0 | 16.1 | 90.0 | 7.2 | 12.0 | 81.1 | 9.8 | 17.3 | 80.5 | 9.0 | 15.1 | 83.9 |
| Ours + Depth Anything V2 [54] | 14.5 | 21.9 | 90.0 | 8.6 | 13.8 | 81.1 | 11.3 | 19.4 | 80.5 | 11.4 | 18.3 | 83.9 |
| Ours + UniDepth V2 [37] | 15.0 | 22.2 | 90.0 | 11.6 | 18.1 | 81.1 | 6.6 | 12.2 | 80.5 | 11.0 | 17.5 | 83.9 |
🔼 This table presents a comparison of different 3D point tracking methods on the TAPVid-3D minival dataset split. It shows the performance of each method across three metrics: 3D Average Jaccard Index (3D-AJ), Average Point Depth (APD), and Occlusion Accuracy (OA). The results are presented for three different subsets within the TAPVid-3D dataset: Aria, DriveTrack, and PStudio, offering a comprehensive evaluation across various video types and motion characteristics. The table helps demonstrate the superior performance of the proposed D3D-PT method compared to existing state-of-the-art sparse 3D point tracking techniques.
read the caption
Table 2: Comparison of 3D point tracking on TAPVid-3D minival split.
| Methods | DAVIS PSNR ↑ | DAVIS SSIM ↑ | DAVIS LPIPS ↓ | Sora PSNR ↑ | Sora SSIM ↑ | Sora LPIPS ↓ | Pixabay PSNR ↑ | Pixabay SSIM ↑ | Pixabay LPIPS ↓ |
|---|---|---|---|---|---|---|---|---|---|
| MonST3R | 14.12 | 0.59 | 0.31 | 15.32 | 0.59 | 0.30 | 19.78 | 0.74 | 0.22 |
| GCD | 15.04 | 0.41 | 0.48 | 11.96 | 0.32 | 0.52 | 13.71 | 0.42 | 0.50 |
| Ours | 19.18 | 0.60 | 0.23 | 17.92 | 0.60 | 0.20 | 22.66 | 0.73 | 0.15 |
🔼 This table presents a quantitative comparison of the quality of multi-camera shooting videos generated by different methods. The metrics used are PSNR, SSIM, and LPIPS, calculated for videos generated on three datasets: DAVIS, Sora, and Pixabay. Each dataset represents different characteristics of videos, allowing for a more robust assessment across diverse video content.
read the caption
Table 3: Comparison of the multi-shooting video generation quality.
| Methods | DAVIS | |||
|---|---|---|---|---|
| AJ ↑ | <{ | |||
| δ}^{x}_{avg} | ||||
| ↑ | OA ↑ | |||
| RGB-RAFT (DOT) [32] | 60.1 | 74.5 | 89.0 | |
| RGBD-RAFT | 55.7 | 71.6 | 86.7 | |
| D3D-PT (Ours) | 63.4 | 75.2 | 89.4 |
🔼 This table presents the results of an ablation study conducted on the DAVIS dataset to evaluate the effectiveness of the proposed dense 3D point tracking method. It compares the performance of three different approaches: RGB-RAFT (DOT), which uses the RAFT network for RGB image data; RGBD-RAFT, an extension of the RAFT network that incorporates depth information; and the authors’ proposed D3D-PT method. The comparison is based on three metrics: Average Jaccard (AJ), average number of pixels within a given threshold of ground truth (δΔuv), and Occlusion Accuracy (OA). The results demonstrate the superiority of the proposed D3D-PT method.
read the caption
Table A1: Ablation Study on DAVIS.
Full paper#