↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current document retrieval methods often rely on scalar similarity measures, hindering comprehension and ignoring fine-grained semantic relationships within documents. This limits their ability to effectively address tasks requiring a deep understanding of the text, such as sentence selection or information localization. Long documents pose an additional challenge as identifying the most relevant sections becomes difficult.
GeAR, or Generation Augmented Retrieval, tackles these issues by integrating well-designed fusion and decoding modules. This allows GeAR to generate relevant text snippets from documents, focusing on fine-grained details and improving the understanding of retrieval results. Importantly, GeAR doesn’t increase computational burden compared to existing methods. The introduction of an efficient data synthesis pipeline using LLMs addresses the data scarcity challenge for this novel approach. GeAR’s performance across several datasets and its ability to offer both retrieval and localization capabilities showcases its effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses limitations of existing document retrieval methods by introducing GeAR, a novel approach that combines retrieval and generation capabilities. GeAR enhances fine-grained information localization and improves understanding of retrieval results, opening avenues for more effective information systems. Its data synthesis pipeline and focus on fine-grained semantics are significant contributions.
Visual Insights#
| SQuAD R@5 | SQuAD M@5 | NQ R@5 | NQ M@5 | TriviaQA R@5 | TriviaQA M@5 | PAQ R@5 | PAQ M@5 | RIR R@5 | RIR M@5 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Pre-trained retrieval model | ||||||||||
| SBERT | 0.812 | 0.667 | 0.754 | 0.576 | 0.677 | 0.413 | 0.808 | 0.701 | 0.376 | 0.297 |
| E5 | 0.803 | 0.674 | 0.760 | 0.581 | 0.645 | 0.390 | 0.816 | 0.716 | 0.484 | 0.396 |
| BGE | 0.829 | 0.701 | 0.674 | 0.502 | 0.690 | 0.422 | 0.752 | 0.647 | 0.451 | 0.367 |
| GTE | 0.866 | 0.744 | 0.767 | 0.587 | 0.726 | 0.443 | 0.836 | 0.736 | 0.528 | 0.435 |
| Retrained retrieval model | ||||||||||
| SBERTRT | 0.742 | 0.585 | 0.739 | 0.550 | 0.577 | 0.342 | 0.859 | 0.742 | 0.739 | 0.631 |
| BGERT | 0.841 | 0.701 | 0.751 | 0.553 | 0.640 | 0.384 | 0.901 | 0.802 | 0.953 | 0.881 |
| GeAR | 0.883 | 0.762 | 0.747 | 0.567 | 0.660 | 0.398 | 0.940 | 0.855 | 0.961 | 0.903 |
| GeARw/oℒLM | 0.889 | 0.776 | 0.755 | 0.565 | 0.660 | 0.399 | 0.955 | 0.877 | 0.963 | 0.907 |
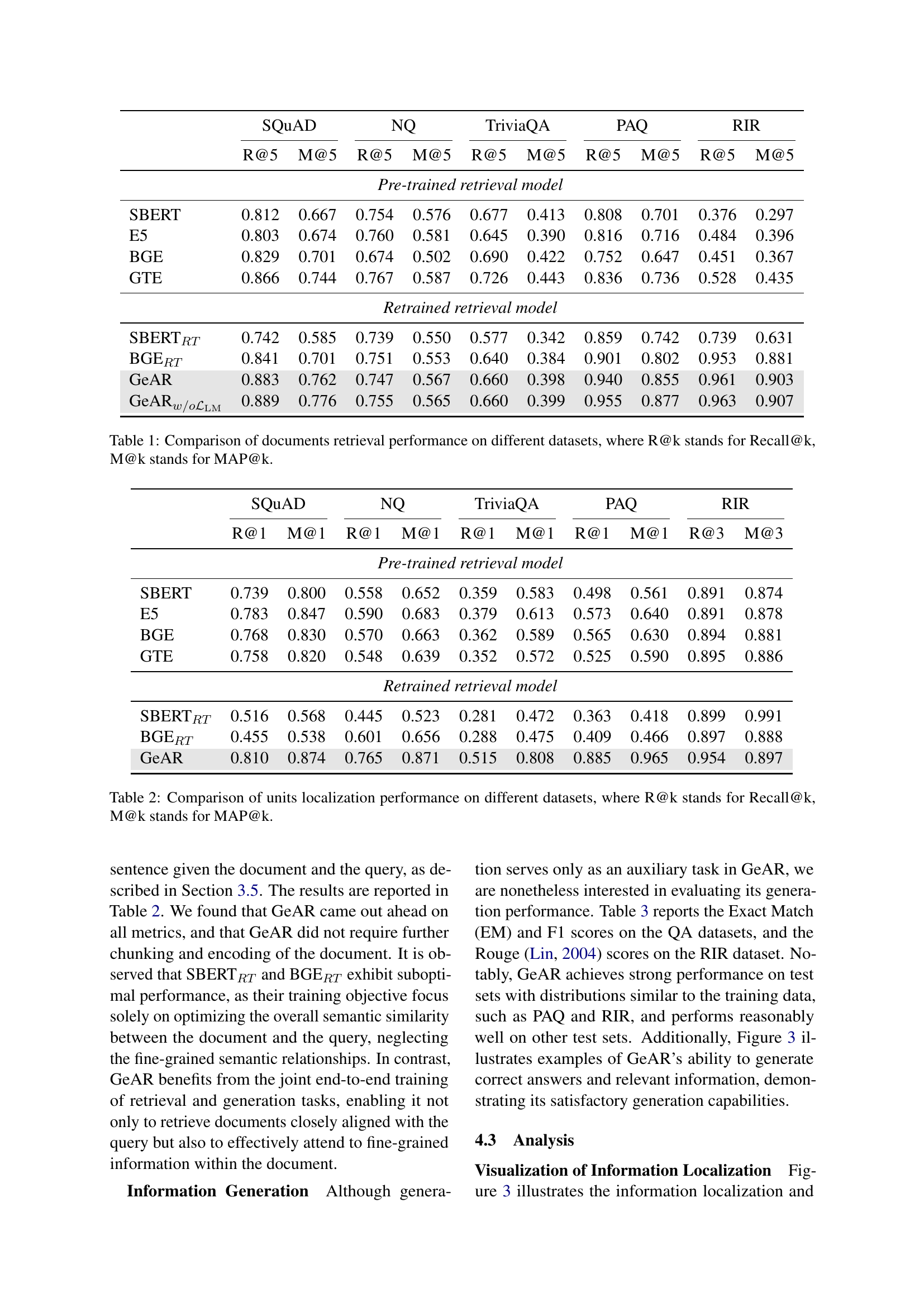
🔼 This table presents a comparison of document retrieval performance across several datasets. The performance is measured using two metrics: Recall@k (R@k) and Mean Average Precision@k (MAP@k). Recall@k indicates the proportion of relevant documents retrieved within the top k results, while MAP@k averages the precision across all ranks. Multiple retrieval models are compared, allowing for a quantitative assessment of their relative effectiveness in retrieving relevant documents from different types of data.
read the caption
Table 1: Comparison of documents retrieval performance on different datasets, where R@k stands for Recall@k, M@k stands for MAP@k.
In-depth insights#
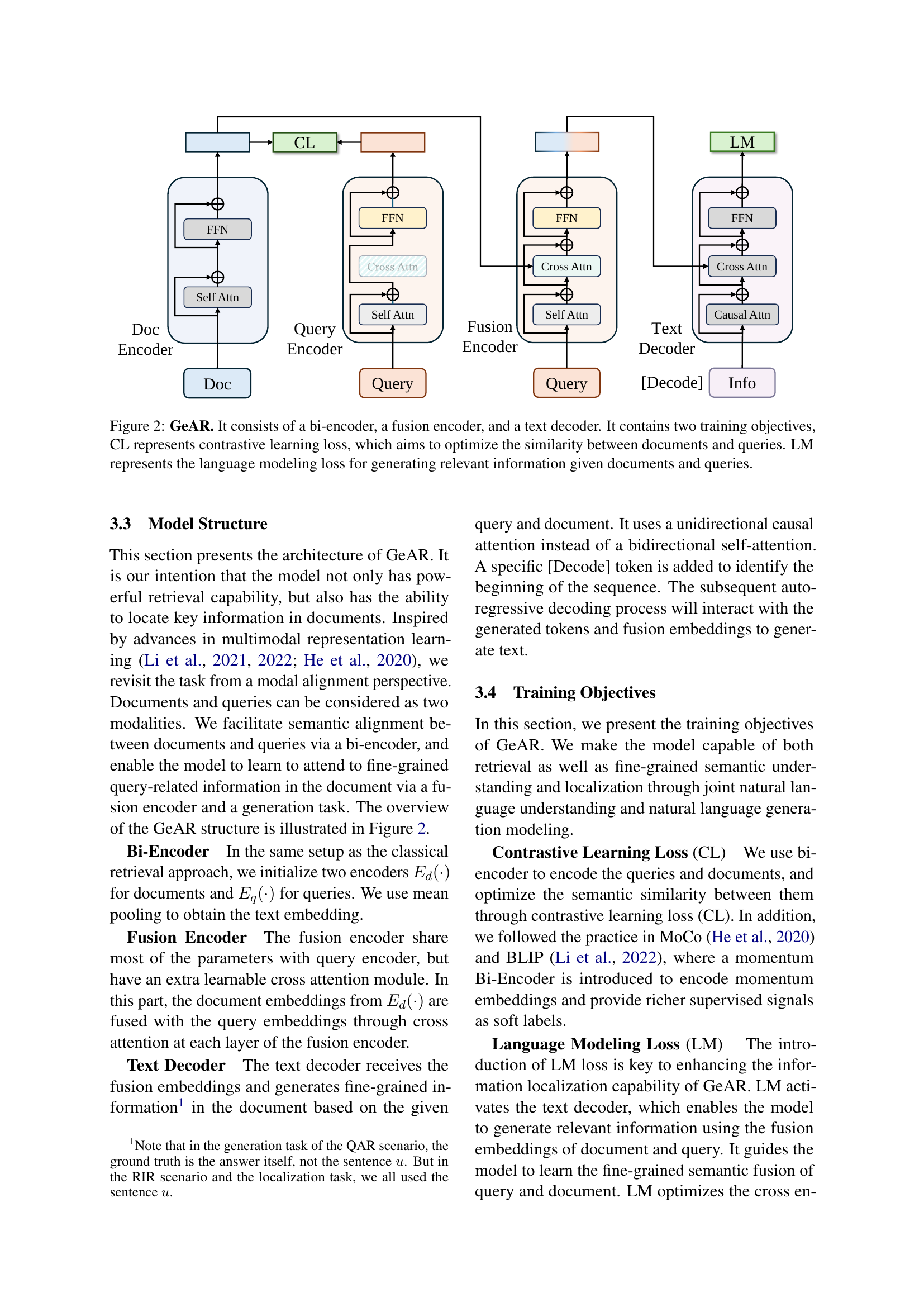
GeAR: A New Retriever#
GeAR, presented as a novel retriever, offers a significant advancement in document retrieval by integrating generation capabilities. This approach directly addresses limitations of traditional bi-encoder models, which often struggle to capture fine-grained semantic relationships and provide limited explanatory power. GeAR’s key innovation lies in its fusion of bi-encoder retrieval with a text generation module. This allows it to not only identify relevant documents but also pinpoint specific sections within those documents that best satisfy the query. The incorporation of a language modeling loss function enhances the model’s ability to precisely locate relevant textual units. Furthermore, the generated text itself acts as a valuable reference, improving the overall transparency and understandability of the retrieval process. Data synthesis, using LLMs, is a crucial aspect of the GeAR methodology, overcoming data scarcity issues commonly associated with fine-grained information localization tasks. Overall, GeAR offers a superior and more explainable retrieval experience compared to traditional methods, making it a valuable contribution to the field.
Fine-Grained Localization#
Fine-grained localization within the context of information retrieval focuses on identifying not just relevant documents, but also the specific, most pertinent segments within those documents. This contrasts with traditional methods that often return an entire document as a single unit of relevance. The advantage lies in providing more precise and nuanced answers, facilitating applications like question answering where only a sentence or phrase might contain the exact answer. Challenges include the need for sophisticated models capable of capturing the intricate semantic relationships between queries and fine-grained text units. Efficient training data generation is also crucial, requiring techniques that accurately annotate these segments and ensure sufficient scale for effective model training. Furthermore, computational efficiency becomes a concern, particularly when dealing with large documents and corpora. Methods involving attention mechanisms, and generation techniques offer promising avenues for addressing these challenges, enabling systems to focus on the granular level of information retrieval.
Data Synthesis Pipeline#
A robust data synthesis pipeline is crucial for training effective retrieval models, especially when dealing with fine-grained information localization. The pipeline’s success hinges on the quality of the base data and the sophistication of the language model (LLM) used for data augmentation. The selection of high-quality Wikipedia articles as a foundation ensures a solid base of factual information. The LLM is tasked with rewriting selected sentences into varied query formulations, mimicking real user search behavior. Careful filtering steps are essential to remove low-quality queries and ensure relevance to the original document. This iterative process of selection, rewriting, and filtering is vital for generating a large, high-quality dataset suitable for training a model that can accurately retrieve and locate relevant information within documents. The efficiency and scalability of the pipeline are also important considerations, requiring careful optimization at each stage to minimize computational costs and maximize data quality.
Model Architecture#
The research paper’s model architecture section would likely detail the design and workings of the GeAR model. It would likely begin by describing the bi-encoder component, which processes both queries and documents to generate initial embeddings. The fusion encoder would then be explained, showing how it combines the query and document embeddings to generate a joint representation. Crucial to the model’s functionality is the text decoder, which uses this joint representation to generate relevant textual snippets from the document, enabling fine-grained information localization. The training objectives, likely encompassing contrastive loss for similarity learning and language modeling loss for text generation, would be fully elucidated. The architecture’s overall design prioritizes balancing retrieval effectiveness with the ability to identify and generate highly specific information within documents. Finally, the model’s modularity, emphasizing the separate yet integrated functions of the bi-encoder, fusion encoder and decoder should be highlighted, showcasing how each component contributes to the overall task of enhanced retrieval with localization.
Future Research#
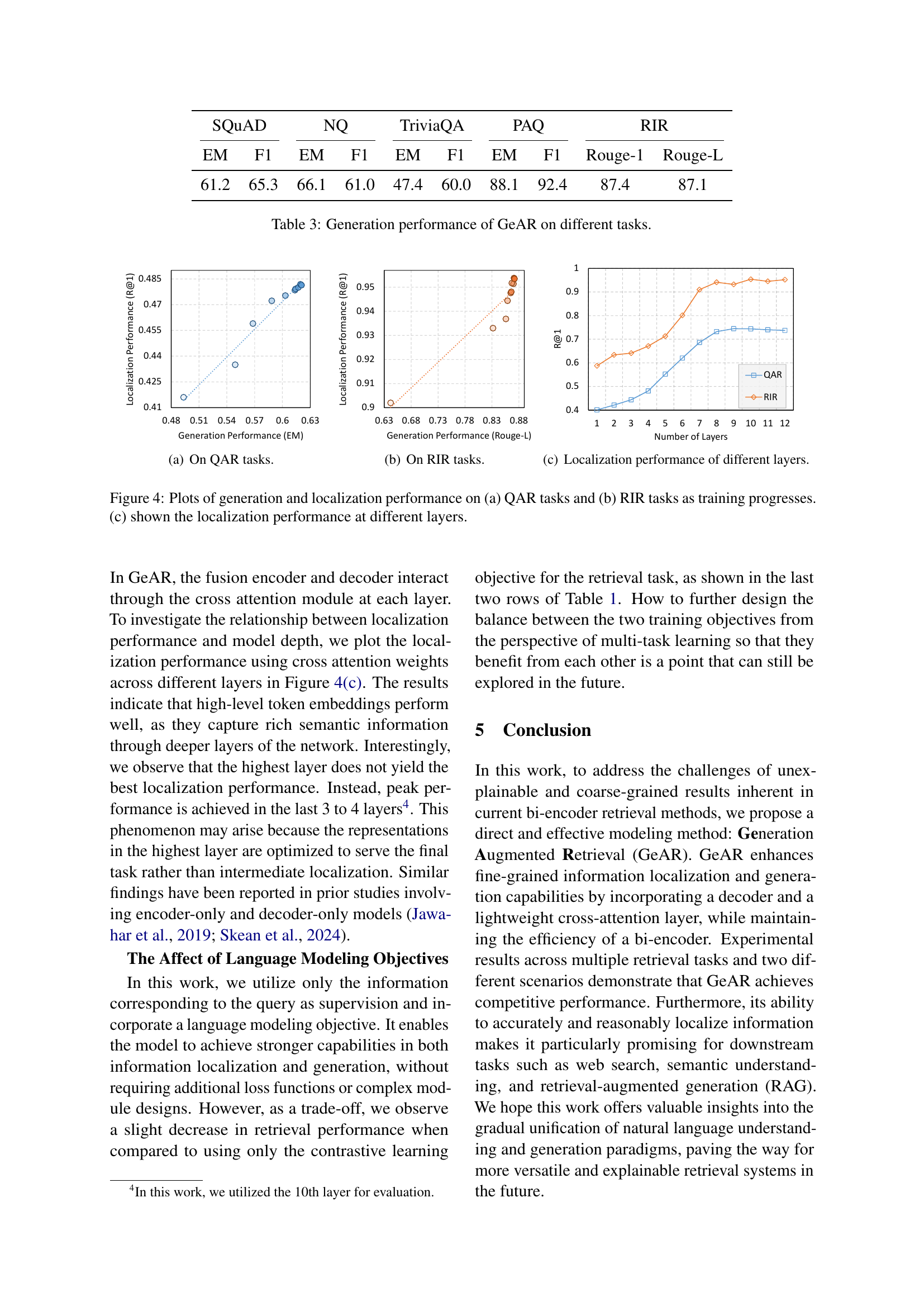
Future research directions for generation-augmented retrieval (GeAR) should prioritize expanding the model’s capabilities to handle longer contexts, addressing the current 512-token limitation. This will involve exploring techniques to efficiently manage and process longer documents, potentially leveraging hierarchical or chunking methods. Another crucial area is improving data synthesis. While the current pipeline using large language models (LLMs) provides high-quality data, further research on data diversity and comprehensiveness would enhance GeAR’s generalizability and robustness across various retrieval tasks. Qualitative analysis of GeAR’s generated explanations is also warranted to explore the model’s reasoning and the interpretability of its results, enhancing user trust and understanding. Finally, investigating the optimal balance between contrastive learning and language modeling objectives during training is essential. Currently, the language modeling loss serves as an auxiliary task, impacting retrieval performance. Future work should aim to optimize both tasks jointly, improving overall performance while preserving the desired localization and generation capabilities.
More visual insights#
More on tables
| SQuAD | NQ | TriviaQA | PAQ | RIR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | M@1 | R@1 | M@1 | R@1 | M@1 | R@1 | M@1 | R@3 | M@3 | |||
| Pre-trained retrieval model | ||||||||||||
| SBERT | 0.739 | 0.800 | 0.558 | 0.652 | 0.359 | 0.583 | 0.498 | 0.561 | 0.891 | 0.874 | ||
| E5 | 0.783 | 0.847 | 0.590 | 0.683 | 0.379 | 0.613 | 0.573 | 0.640 | 0.891 | 0.878 | ||
| BGE | 0.768 | 0.830 | 0.570 | 0.663 | 0.362 | 0.589 | 0.565 | 0.630 | 0.894 | 0.881 | ||
| GTE | 0.758 | 0.820 | 0.548 | 0.639 | 0.352 | 0.572 | 0.525 | 0.590 | 0.895 | 0.886 | ||
| Retrained retrieval model | ||||||||||||
| SBERTRT | 0.516 | 0.568 | 0.445 | 0.523 | 0.281 | 0.472 | 0.363 | 0.418 | 0.899 | 0.991 | ||
| BGERT | 0.455 | 0.538 | 0.601 | 0.656 | 0.288 | 0.475 | 0.409 | 0.466 | 0.897 | 0.888 | ||
| GeAR | 0.810 | 0.874 | 0.765 | 0.871 | 0.515 | 0.808 | 0.885 | 0.965 | 0.954 | 0.897 |
🔼 This table presents a comparison of the performance of different models on the task of units localization. Units localization refers to the ability of a model to identify the specific sections of a document that are most relevant to a given query. The table shows the Recall@k and Mean Average Precision@k (MAP@k) scores for several models across various datasets. Recall@k represents the proportion of relevant units correctly retrieved within the top k results, while MAP@k is a more sophisticated metric that considers both the precision and recall of the retrieved units. Higher scores in both metrics indicate better performance on the units localization task.
read the caption
Table 2: Comparison of units localization performance on different datasets, where R@k stands for Recall@k, M@k stands for MAP@k.
| SQuAD | NQ | TriviaQA | PAQ | RIR | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | Rouge-1 | Rouge-L | |
| 61.2 | 65.3 | 66.1 | 61.0 | 47.4 | 60.0 | 88.1 | 92.4 | 87.4 | 87.1 |
🔼 This table presents a quantitative evaluation of the GeAR model’s text generation capabilities across various tasks. It shows the performance metrics (Exact Match (EM) and F1 scores for question answering tasks, and ROUGE-1 and ROUGE-L scores for relevant information retrieval tasks) achieved by GeAR on different benchmark datasets (SQUAD, NQ, TriviaQA, PAQ, and RIR). This demonstrates the model’s ability to generate high-quality text relevant to the input query across multiple scenarios and datasets.
read the caption
Table 3: Generation performance of GeAR on different tasks.
| Hyperparameter | Assignment |
|---|---|
| Computing Infrastructure | 16 MI200-64GB GPUs |
| Number of epochs | 10 |
| Batch size per GPU | 48 / 16 |
| Maximum sequence length | 512 |
| Optimizer | AdamW |
| AdamW epsilon | 1e-8 |
| AdamW beta weights | 0.9, 0.999 |
| Learning rate scheduler | Cosine lr schedule |
| Initialization learning rate | 1e-5 |
| Minimum learning rate | 1e-6 |
| Weight decay | 0.05 |
| Warmup steps | 1000 |
| Warmup learning rate | 1e-6 |
🔼 This table details the hyperparameters used in training the GeAR model. It lists settings for various aspects of the training process, including the computing infrastructure (number of GPUs and memory), training epochs, batch size, optimizer used (AdamW), learning rate schedule and settings, weight decay, and warmup steps. These settings are crucial for replicating the experiments presented in the paper.
read the caption
Table 4: Hyperparameter settings
| Scenario | Data Number |
|---|---|
| QAR | 30,000,000 |
| RIR | 5,676,877 |
🔼 This table shows the number of data samples used for training the GeAR model in two different retrieval scenarios: Question Answer Retrieval (QAR) and Relevant Information Retrieval (RIR). The QAR scenario used 30,000,000 data samples, while the RIR scenario utilized 5,676,877 samples.
read the caption
Table 5: Training data statistics.
| Scenario | Dataset | Documents Number | Queries Number |
|---|---|---|---|
| QA | Squad | 20,239 | 5,928 |
| NQ | 64,501 | 2,889 | |
| TriviaQA | 104,160 | 14,000 | |
| PAQ | 932,601 | 20,000 | |
| RIR | RIR | 2,315,413 | 145,562 |
🔼 This table presents the evaluation datasets used for the document retrieval task. It shows the number of documents and queries in each dataset used for testing the performance of various document retrieval models. Datasets include SQUAD, NQ, TriviaQA, and PAQ, providing a comprehensive evaluation across different question-answering scenarios.
read the caption
Table 6: The evaluation data statistics for the document retrieval task.
| Scenario | Dataset | Data Number |
|---|---|---|
| QA | Squad | 5,928 |
| NQ | 2,889 | |
| TriviaQA | 14,000 | |
| PAQ | 20,000 | |
| RIR | RIR | 10,000 |
🔼 This table presents the number of data samples used for evaluating the units localization and information generation tasks. It breaks down the counts by dataset (SQUAD, NQ, TriviaQA, PAQ, and RIR) and scenario (QA and RIR). These numbers reflect the size of the test sets used to assess the model’s performance in these specific aspects. The ‘QA’ scenario refers to Question Answering Retrieval and ‘RIR’ denotes Relevant Information Retrieval.
read the caption
Table 7: The evaluation data statistics for the units localization and information generation tasks.
Full paper#