↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current Automatic Speech Recognition (ASR) systems often rely on transformer-based models, which face challenges in terms of computational efficiency and scalability when dealing with long audio sequences. This is particularly problematic for real-time applications and low-resource settings.
The paper introduces Samba-ASR, a novel ASR model that uses the Mamba architecture, which is based on structured state-space models (SSMs). Unlike transformers, Mamba-based systems exhibit linear complexity, leading to significant improvements in computational efficiency and scalability. The authors demonstrate that Samba-ASR achieves superior accuracy and efficiency compared to existing transformer-based models, setting a new benchmark for the field and providing a more robust solution for diverse ASR tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Samba-ASR, a state-of-the-art speech recognition model that significantly improves efficiency and accuracy. It challenges the dominance of transformer-based models by using a novel state-space model architecture. This opens up new research avenues in efficient and scalable ASR, particularly relevant to low-resource scenarios and real-time applications. Its robust performance and efficient architecture have potential impacts on a variety of speech-related tasks.
Visual Insights#

🔼 Figure 1 provides a detailed illustration of the Samba-ASR model’s architecture. It showcases the model’s key components: the Mamba encoder, responsible for processing raw audio input using Mamba blocks to extract relevant features; the Mamba decoder, which takes the processed audio features and generates text transcriptions; and a crucial Mamba-Cross-Connection bridge facilitating the integration of audio context with text representations for accurate and efficient transcription. The architecture is designed to efficiently handle long-range dependencies in audio and text sequences for high-accuracy automatic speech recognition.
read the caption
Figure 1: Architecture diagram (original) of the Samba-ASR model, illustrating the key components including the Mamba encoder, which processes raw audio features using Mamba blocks, and the Mamba decoder along with the Mamba-Cross-Connection bridge, which generates transcriptions by integrating audio context with text representations. The model’s design focuses on efficient long-range dependency capture for accurate automatic speech recognition.
| Training Parameters | |
|---|---|
| Learning Rate | 1e-4 |
| Optimizer | AdamW |
| Weight Decay | 0.01 |
| Adam eps | 1e-8 |
| Batch Size | 256 |
🔼 This table details the hyperparameters employed during the training phase of the Samba-ASR model. It includes the optimizer used (AdamW), the learning rate, weight decay, Adam epsilon value, and batch size. These parameters were carefully selected to balance model performance, stability and training efficiency.
read the caption
Table 1: Details of Training Parameters used for the training of Samba-ASR
In-depth insights#
Mamba-SSM’s Supremacy#
The claim of “Mamba-SSM’s Supremacy” requires a nuanced examination. While the paper demonstrates Samba-ASR, built on Mamba-SSMs, achieves state-of-the-art results on several benchmarks, surpassing transformer-based models in accuracy and efficiency, it’s crucial to avoid overgeneralization. The supremacy is context-dependent; Mamba excels in handling long sequences efficiently due to its linear complexity, unlike the quadratic scaling of transformers. This efficiency is particularly beneficial for processing long audio files common in speech recognition, leading to faster inference times and reduced computational costs. However, direct comparisons hinge on the specific datasets and evaluation metrics used. Further research is needed to determine if this advantage holds consistently across diverse datasets and acoustic conditions. The paper highlights several advantages, including improved noise robustness and generalization, but more comprehensive testing against a broader range of transformer models under varying conditions is necessary for a definitive assertion of supremacy. Therefore, while the results strongly suggest Mamba-SSMs offer a powerful alternative in specific scenarios, labeling it unequivocally “supreme” requires more extensive validation.
Samba-ASR: Design#
The Samba-ASR system’s design is centered around the Mamba architecture, a novel approach to state-space modeling that offers significant advantages over traditional transformer-based methods. Its core strength lies in the replacement of self-attention mechanisms with efficient state-space dynamics, allowing it to model long-range dependencies more effectively. This design choice leads to linear scaling with sequence length, addressing a critical limitation of transformers which suffer from quadratic complexity. This efficiency is crucial for handling longer audio sequences, common in many real-world ASR tasks. The architecture is further optimized through the use of hardware-aware techniques that minimize memory usage, significantly improving resource utilization, particularly on tasks involving extensive audio sequences. The model’s design employs Mamba blocks in both its encoder (processing raw audio features) and decoder (generating text transcriptions), ensuring consistent and efficient processing throughout. The Mamba-Cross-Connection bridge enhances performance by effectively integrating audio and text representations within the decoding process. The end result is a system promising superior performance and scalability in ASR, particularly relevant when dealing with long-form speech data and resource-constrained environments.
Benchmark Results#
The benchmark results section would be crucial in evaluating Samba-ASR’s performance. It should detail the datasets used (e.g., LibriSpeech, GigaSpeech, SPGISpeech), the metrics employed (primarily WER, but potentially others like accuracy and latency), and a comparison against state-of-the-art (SOTA) systems. A key aspect would be showcasing Samba-ASR’s superiority in terms of WER across diverse datasets, highlighting its robustness. The results should not only present numerical figures but also include insightful analysis. For example, the paper should discuss whether Samba-ASR exhibits better performance on specific audio characteristics (noisy, spontaneous speech, etc.) and analyze the trade-offs between accuracy and efficiency. Visualizations like graphs illustrating WER reduction or a table comparing Samba-ASR against various systems across datasets would be beneficial in conveying the results clearly. Furthermore, an in-depth discussion of statistical significance testing is critical to ensure the reported improvements aren’t due to random chance. The analysis must be thorough, addressing potential limitations and biases inherent in the benchmarks and evaluation metrics. Ultimately, a compelling benchmark results section will firmly establish Samba-ASR’s position as a leading ASR system.
Computational Efficiency#
The research paper highlights the crucial aspect of computational efficiency in Automatic Speech Recognition (ASR). Traditional transformer-based models suffer from quadratic complexity, making them computationally expensive, especially with long audio sequences. The paper introduces Samba-ASR, which leverages the Mamba architecture, a structured state-space model (SSM), to address this limitation. Mamba’s linear complexity is a significant advantage, enabling efficient processing of long sequences. The inherent computational efficiency of Samba-ASR is demonstrated through its superior performance on benchmark datasets. The combination of hardware-aware optimizations, like kernel fusion and parallel scan, further contributes to its efficiency, minimizing memory overhead during both training and inference. This enhanced efficiency allows for real-time applications and scalability which was not easily achievable with transformer-based models. The paper strongly emphasizes that the efficiency of Samba-ASR is not only theoretical but is backed by experimental evidence, showcasing its practical implications in the field of speech recognition.
Future Research#
Future research directions for Samba-ASR should prioritize extending multilingual capabilities and handling diverse, low-resource languages. Improving the model’s robustness to noisy and spontaneous speech is crucial. Exploring different model sizes optimized for varied computational resources (edge devices to large-scale deployments) is essential. Enhancing the pre-training process using larger and more diverse datasets would further boost generalization across accents and speech styles. Integrating real-time processing and on-the-fly language detection would broaden the system’s applicability, moving it toward truly dynamic and interactive use cases. Finally, investigating domain-adaptive fine-tuning for specialized industries is vital to unlock Samba-ASR’s full potential across a broad range of applications.
More visual insights#
More on figures

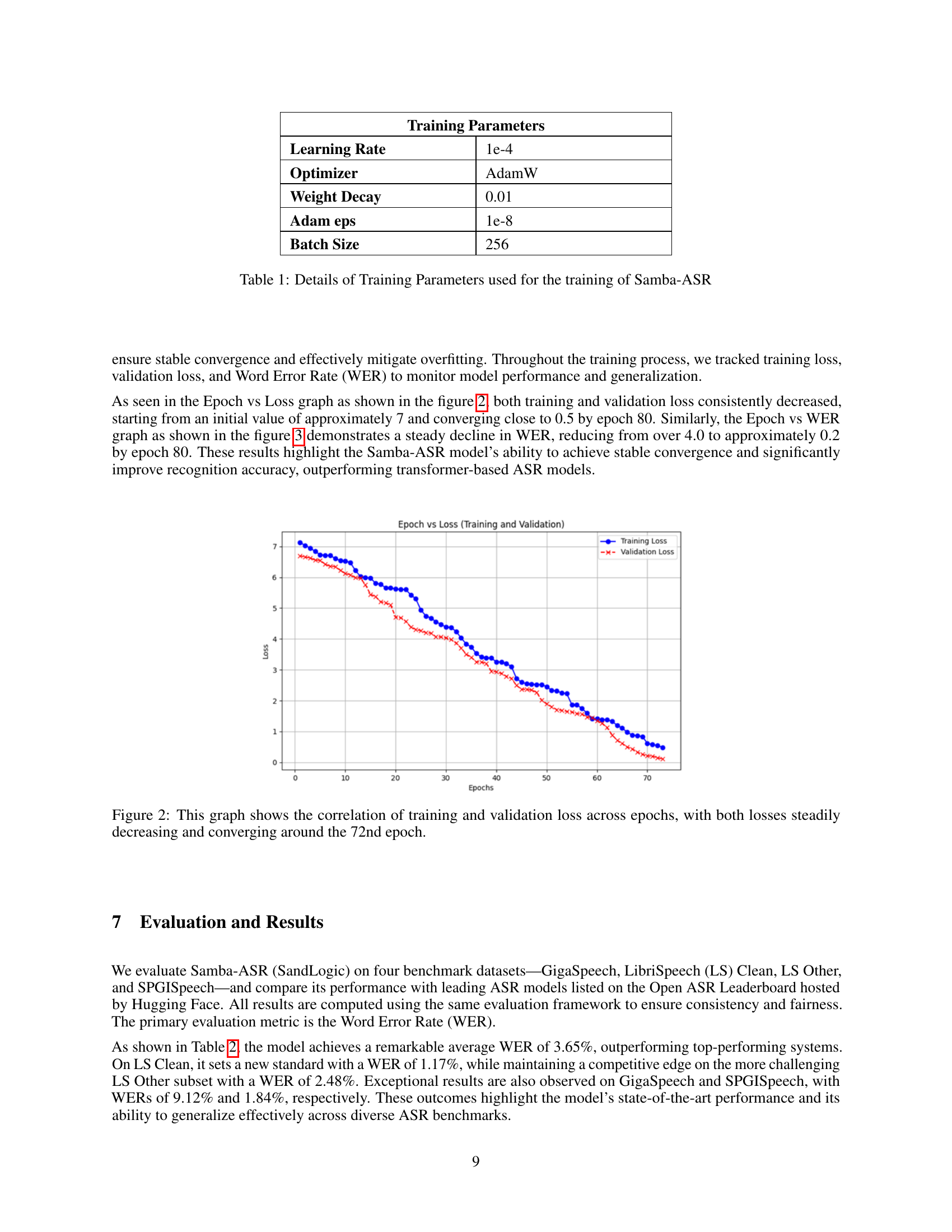
🔼 The figure shows two lines representing training loss and validation loss across training epochs. Both curves steadily decrease, indicating successful model training and a low risk of overfitting. The convergence of both curves around epoch 72 suggests that the model has learned the training data effectively and its performance is generalizing well to unseen data. This visual representation supports the claim that the model training process is stable and effective.
read the caption
Figure 2: This graph shows the correlation of training and validation loss across epochs, with both losses steadily decreasing and converging around the 72nd epoch.

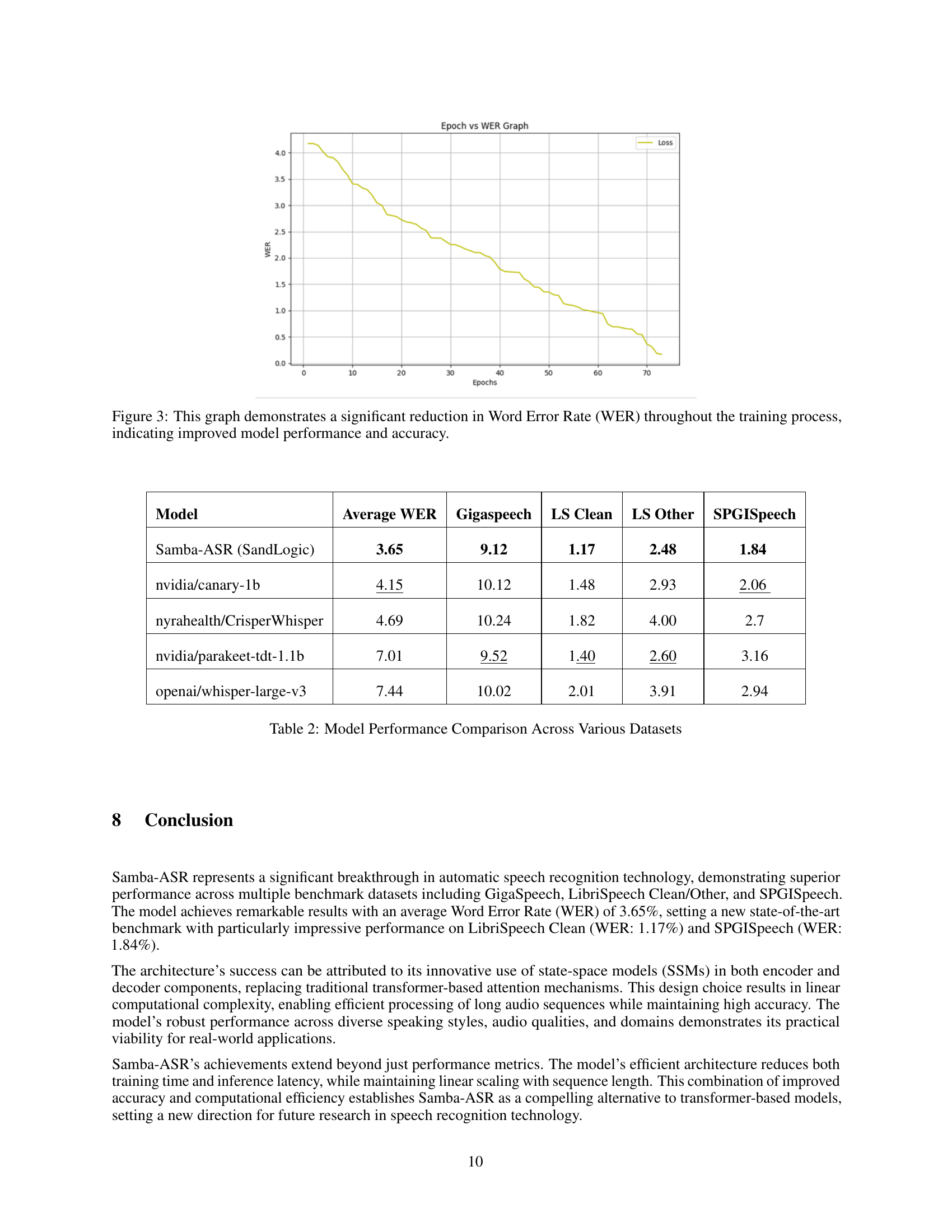
🔼 The graph in Figure 3 visually represents the Word Error Rate (WER) throughout the model’s training. The WER, a key metric in evaluating speech recognition models, shows a significant decrease as the training progresses. This downward trend illustrates the model’s improvement in accuracy and performance during training. The steady decline indicates the effectiveness of the training process and the model’s ability to learn from the training data. The x-axis represents the training epochs and the y-axis represents the WER. A lower WER suggests better speech recognition performance.
read the caption
Figure 3: This graph demonstrates a significant reduction in Word Error Rate (WER) throughout the training process, indicating improved model performance and accuracy.
Full paper#