↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current image-to-video (I2V) models struggle to generate videos with accurate and consistent object motion, especially when multiple objects are involved. This often results in unrealistic or jarring movements. This paper tackles this problem by proposing a new approach.
The proposed method, Through-The-Mask, uses a two-stage process. First, it generates an intermediate representation of object motion using mask-based trajectories. This representation captures both the semantic meaning (what objects are) and the motion (how they move). Then, a second stage uses this representation to generate a video sequence. This approach significantly improves the accuracy and realism of object motion, leading to more natural and believable videos, even in challenging multi-object scenarios. The effectiveness is shown via evaluations on existing and a new benchmark dataset.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and video generation. It addresses the limitations of current image-to-video models in handling complex object motion, particularly in multi-object scenarios, by introducing a novel two-stage framework. This opens avenues for creating more realistic and consistent videos with accurate object interactions, which is highly relevant to the rapidly advancing field of AI video generation. The new benchmark dataset further enhances the field.
Visual Insights#

🔼 This figure demonstrates the THROUGH-THE-MASK model’s ability to generate videos from a single input image and a text caption. The top rows show the input image and its segmentation mask, illustrating the mask-based motion trajectories used by the model. The bottom rows display the generated video, showcasing the model’s capacity to accurately animate multiple objects in the scene based on the provided text prompt. The results highlight the method’s success in creating realistic and consistent object motion within the generated video.
read the caption
Figure 1: Through-The-Mask is an Image-to-Video method that animates an input image based on a provided text caption. The generated video (rows 2 and 4) leverages mask-based motion trajectories (rows 1 and 3), enabling accurate animation of multiple objects.
| Method | Single-Object FVD↓ | Single-Object CF↑ | Single-Object ViCLIP-T↑ | Single-Object ViCLIP-V↑ | Single-Object AD | Single-Object Text | Single-Object Motion | Single-Object Quality | Multi-Object FVD↓ | Multi-Object CF↑ | Multi-Object ViCLIP-T↑ | Multi-Object ViCLIP-V↑ | Multi-Object AD | Multi-Object Text | Multi-Object Motion | Multi-Object Quality |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| align. | consist. | align. | consist. | |||||||||||||
| VideoCrafter [10] | 1484.18 | 0.966 | 0.209 | 0.796 | 2.93 | 84.3 | 84.3 | 81.2 | 1413.83 | 0.966 | 0.208 | 0.802 | 3.75 | 84.3 | 87.5 | 92.1 |
| DynamiCrafter [54] | 1442.48 | 0.942 | 0.214 | 0.817 | 8.94 | 75.0 | 81.2 | 82.8 | 1300.07 | 0.947 | 0.211 | 0.834 | 7.56 | 75.0 | 73.4 | 76.5 |
| Motion-I2V [43] | 1195.08 | 0.937 | 0.220 | 0.822 | 6.28 | 75.0 | 89.0 | 93.7 | 1162.06 | 0.935 | 0.219 | 0.821 | 6.97 | 81.0 | 89.0 | 95.3 |
| ConsistI2V [41] | 1206.61 | 0.951 | 0.218 | 0.839 | 5.21 | 65.6 | 78.1 | 81.2 | 1186.10 | 0.935 | 0.217 | 0.850 | 7.25 | 81.2 | 82.8 | 84.3 |
| TI2V (UNet) | 1285.99 | 0.942 | 0.219 | 0.877 | 5.90 | 53.1 | 59.3 | 70.3 | 1410.68 | 0.942 | 0.218 | 0.883 | 7.93 | 62.5 | 64.0 | 60.0 |
| Ours (UNet) | 925.39 | 0.969 | 0.220 | 0.888 | 4.70 | - | - | - | 1089.86 | 0.966 | 0.220 | 0.896 | 5.59 | - | - | - |
| TI2V (DiT) | 1232.89 | 0.924 | 0.223 | 0.797 | 10.87 | 65.6 | 73.4 | 68.7 | 1156.82 | 0.917 | 0.221 | 0.805 | 10.52 | 64.0 | 59.3 | 64.0 |
| Ours (DiT) | 1216.83 | 0.945 | 0.226 | 0.860 | 7.22 | - | - | - | 1134.71 | 0.948 | 0.225 | 0.863 | 7.48 | - | - | - |
🔼 This table presents a quantitative comparison of different image-to-video generation models on the SA-V-128 benchmark dataset. The benchmark consists of videos with single and multiple objects, allowing for a thorough evaluation of the models’ ability to handle complex motion scenarios. The models are evaluated using several metrics: Fréchet Video Distance (FVD) measures the overall visual quality; CLIPFrame (CF) assesses the temporal consistency of video frames; ViCLIP-T and ViCLIP-V evaluate the alignment between the generated videos and text and image input respectively; Average Displacement (AD) quantifies the realism of the motion in generated videos. In addition to these objective metrics, human ratings are included, providing a subjective evaluation of the video quality. Specifically, the human evaluation shows the percentage of evaluators who prefer the results of the Through-The-Mask model over other models for each video.
read the caption
Table 1: Results for single-object and multi-object settings on the SA-V-128 Benchmark. We report FVD, CLIPFrame (CF), ViCLIP-T, ViCLIP-V, and Average Displacement (AD), along with human ratings. Human evaluation shows the percentage of raters that prefer the results of Through-The-Mask.
In-depth insights#
Mask-based Motion#
The concept of ‘Mask-based Motion’ in image-to-video generation offers a novel approach to animating objects within a scene. Instead of relying on pixel-level motion estimation (like optical flow), it leverages semantic segmentation masks to define object boundaries. This allows the model to reason about object motion at a higher, more abstract level, focusing on consistent movement of individual objects rather than pixel displacements. This is advantageous because it inherently handles object interactions and occlusions more robustly. The mask-based approach creates a more compact and semantically rich representation of motion, improving training efficiency and enabling more accurate and realistic animation, especially in complex, multi-object scenarios. However, the effectiveness of this method depends heavily on the accuracy of the initial segmentation masks; errors in object boundaries will directly translate to errors in motion prediction. Future research could explore more sophisticated mask refinement techniques or incorporate uncertainty estimation to mitigate these issues and enhance the robustness of mask-based motion models for image-to-video generation.
Two-Stage I2V#
A two-stage Image-to-Video (I2V) approach offers a powerful way to tackle the complexities of video generation. The first stage focuses on creating an intermediate representation that captures both semantic information (what objects are present) and motion information (how the objects move), thereby disentangling the generation process. This representation, such as mask-based motion trajectories, avoids issues inherent in single-stage approaches, where the model must reason about both aspects simultaneously. A second stage then uses this refined representation to generate the final video, greatly improving generation quality, especially for complex scenes with multiple objects interacting. The two-stage design allows for more precise control over the output, addressing limitations of single-stage methods that struggle with accurate and consistent object movement. By separating semantic and motion understanding, each stage can be specialized and optimized to improve efficiency and quality. This ultimately leads to more realistic and coherent videos, a major advancement in I2V technology.
Attention Blocks#
The concept of ‘Attention Blocks’ in the context of image-to-video generation is crucial for effectively integrating contextual information. These blocks, likely implemented as neural network layers, would selectively focus on different parts of the input data. Masked cross-attention allows the model to selectively attend to relevant parts of the input image and corresponding textual descriptions, improving the accuracy of object representation and action prediction. Masked self-attention helps maintain consistency in the movement of individual objects over time, preventing conflicts and ensuring smooth motion. This two-pronged approach is vital for handling complex, multi-object scenarios, where standard attention mechanisms might struggle with the inherent ambiguity. By carefully controlling which parts of the input influence the output at each stage, these ‘Attention Blocks’ refine the generated video and enhance both the realism and coherence of the final output. The design incorporates object-level attention, enabling the model to learn object-specific motion patterns rather than relying on a pixel-by-pixel approach.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, it would involve removing elements like the masked attention mechanisms (both cross and self-attention) to understand how these impact the overall performance. Removing the mask entirely could show if the model’s success depends on focusing attention on specific object regions. Analyzing results with only cross-attention or self-attention would highlight the unique roles each plays in ensuring temporal consistency and semantic integration of objects’ motion. By comparing these results to the full model, we can quantify the contribution of each component to factors such as motion realism, temporal coherence, and text faithfulness. This analysis is crucial for validating the core design choices of the model and identifying potential avenues for future improvement. The degree of performance degradation when ablating specific components will directly correlate with their relative importance within the overall architecture.
Future I2V#
Future Image-to-Video (I2V) research will likely focus on addressing current limitations. Improved temporal consistency and object motion fidelity, particularly in complex scenes with multiple interacting objects, remains a key challenge. This necessitates more sophisticated methods for modeling object interactions and temporal dynamics. Enhanced controllability over the generation process through more nuanced text prompts and/or other modalities (e.g., sketches) will be crucial. Furthermore, scalability to higher resolutions and longer video sequences is a priority. Finally, addressing issues of efficiency is vital, with a focus on reduced computational cost and faster generation times, making I2V technology more accessible and practical for broader applications.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage Image-to-Video (I2V) framework. Stage 1, Image-to-Motion, takes an input image (x^(0)), its segmentation mask (s^(0)), and a motion-specific text prompt (c_motion) to generate mask-based motion trajectories (s^). Stage 2, Motion-to-Video, uses the input image (x^(0)), the generated trajectories (s^), a global text prompt (c), and object-specific prompts (c_local) to produce the final video output (x^). The framework uses a pre-trained LLM to extract the prompts.
read the caption
Figure 2: Overview of our I2V framework, transforming a reference image x(0)superscript𝑥0x^{(0)}italic_x start_POSTSUPERSCRIPT ( 0 ) end_POSTSUPERSCRIPT and text prompt c𝑐citalic_c into a coherent video sequence x^^𝑥\hat{x}over^ start_ARG italic_x end_ARG. A pre-trained LLM is used to derive the motion-specific prompt cmotionsubscript𝑐𝑚𝑜𝑡𝑖𝑜𝑛c_{motion}italic_c start_POSTSUBSCRIPT italic_m italic_o italic_t italic_i italic_o italic_n end_POSTSUBSCRIPT and object-specific prompts clocal={clocal(1),…,clocal(L)}subscript𝑐𝑙𝑜𝑐𝑎𝑙superscriptsubscript𝑐𝑙𝑜𝑐𝑎𝑙1…superscriptsubscript𝑐𝑙𝑜𝑐𝑎𝑙𝐿c_{local}=\{c_{local}^{(1)},\dots,c_{local}^{(L)}\}italic_c start_POSTSUBSCRIPT italic_l italic_o italic_c italic_a italic_l end_POSTSUBSCRIPT = { italic_c start_POSTSUBSCRIPT italic_l italic_o italic_c italic_a italic_l end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( 1 ) end_POSTSUPERSCRIPT , … , italic_c start_POSTSUBSCRIPT italic_l italic_o italic_c italic_a italic_l end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_L ) end_POSTSUPERSCRIPT }, capturing each object’s intended motion. We generate an initial segmentation mask s(0)superscript𝑠0s^{(0)}italic_s start_POSTSUPERSCRIPT ( 0 ) end_POSTSUPERSCRIPT from x(0)superscript𝑥0x^{(0)}italic_x start_POSTSUPERSCRIPT ( 0 ) end_POSTSUPERSCRIPT using SAM2. In Stage 1, the Image-to-Motion utilizes x(0)superscript𝑥0x^{(0)}italic_x start_POSTSUPERSCRIPT ( 0 ) end_POSTSUPERSCRIPT, s(0)superscript𝑠0s^{(0)}italic_s start_POSTSUPERSCRIPT ( 0 ) end_POSTSUPERSCRIPT, and cmotionsubscript𝑐𝑚𝑜𝑡𝑖𝑜𝑛c_{motion}italic_c start_POSTSUBSCRIPT italic_m italic_o italic_t italic_i italic_o italic_n end_POSTSUBSCRIPT to generate mask-based motion trajectories s^^𝑠\hat{s}over^ start_ARG italic_s end_ARG that represent object-specific movement paths. In Stage 2, the Motion-to-Video takes as input x(0)superscript𝑥0x^{(0)}italic_x start_POSTSUPERSCRIPT ( 0 ) end_POSTSUPERSCRIPT, the generated trajectories s^^𝑠\hat{s}over^ start_ARG italic_s end_ARG, the text prompt c𝑐citalic_c as a global condition, and object-specific prompts clocalsubscript𝑐𝑙𝑜𝑐𝑎𝑙c_{local}italic_c start_POSTSUBSCRIPT italic_l italic_o italic_c italic_a italic_l end_POSTSUBSCRIPT through a masked attention blocks (Section 3.3), producing the final video x^^𝑥\hat{x}over^ start_ARG italic_x end_ARG.

🔼 Figure 3 illustrates the architecture of the masked attention block, a key component of the proposed Image-to-Video generation model. The figure depicts how the model processes video latent patches (represented as squares, color-coded to identify individual objects within the video frame), and how these patches interact with different types of prompts. Global prompts (gray triangles) provide general information about the scene, while object-specific prompts (color-coded triangles) offer detailed instructions for each object. The illustration highlights the use of four distinct attention mechanisms: standard self-attention (considering all patches), masked self-attention (restricting attention to a single object), standard cross-attention (integrating global prompts), and masked cross-attention (aligning object-specific prompts). This combination of attention mechanisms enables the model to generate accurate and consistent object motion, even in complex, multi-object scenarios.
read the caption
Figure 3: Illustration of the masked attention block. Squares represent video latent patches, color-coded to indicate objects (e.g., cat or dog). Triangles denote prompt tokens: gray for global prompts and object-specific colors for local prompts. The pipeline features self-attention for all patches, masked self-attention restricted to each object, cross-attention integrating global prompts, and masked cross-attention aligning object-specific prompts.

🔼 This figure showcases a qualitative comparison of video generation results. It presents visual examples from the SA-V-128 benchmark dataset, directly comparing videos generated by the proposed ‘Through-The-Mask’ method and a baseline TI2V (Text-to-Image-to-Video) approach. The comparison highlights the differences in the realism and accuracy of the generated videos, particularly in terms of object motion and interaction.
read the caption
Figure 4: Qualitative comparison: Visual examples of generated videos for Through-The-Mask compared to the TI2V baseline on examples from the SA-V-128 benchmark.

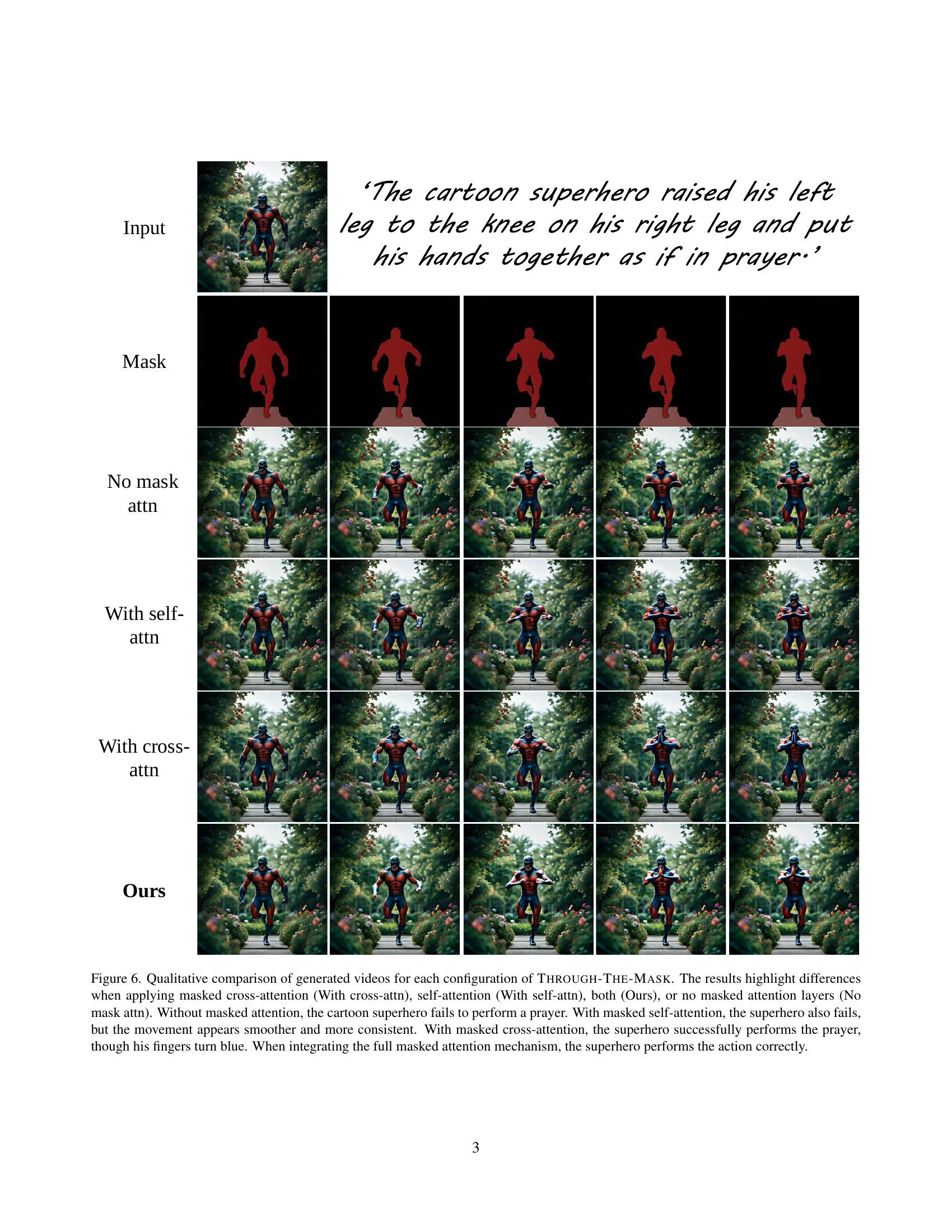
🔼 This figure compares the performance of using segmentation masks versus optical flow as intermediate representations for generating videos from images. The top row displays the input image and the text prompt used to guide the animation. The second row shows the segmentation masks generated by the model. These masks highlight the different objects and their respective boundaries in the image. The third row shows the optical flow generated by the model. Optical flow indicates the direction and magnitude of motion between consecutive frames. The fourth row displays the final generated videos using the segmentation masks as the intermediate representation. The fifth row displays the final generated videos using the optical flow as the intermediate representation. By comparing the generated videos from these two different methods, we can understand the strengths and weaknesses of each approach.
read the caption
Figure 5: Qualitative comparison of generated videos using segmentation masks vs optical flow as an intermediate motion representation. The first row shows the input image and text, the second row displays the generated masks, and the third row presents the generated optical flow. The fourth and fifth rows show the generated videos, with the fourth row using our mask-based model and the fifth using our flow-based model.

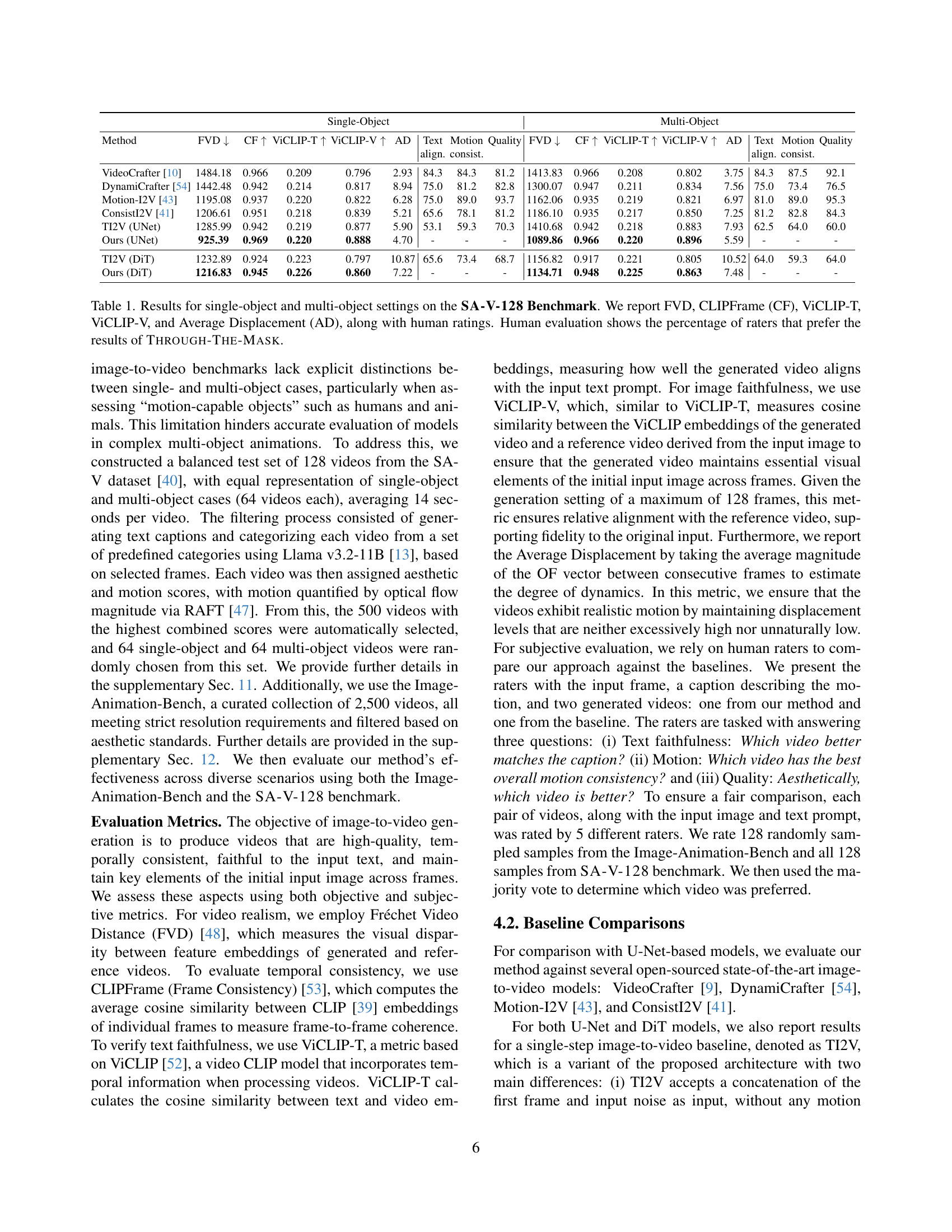
🔼 This figure shows a qualitative comparison of videos generated using different configurations of the Through-The-Mask model. Four versions are shown: one without any masked attention layers, one with only masked self-attention, one with only masked cross-attention, and one with both (the ‘Ours’ version, representing the full model). The videos all depict a cartoon superhero attempting to perform a prayer pose. The results illustrate how the different attention mechanisms affect the accuracy and smoothness of the superhero’s movements and the overall quality of the generated video. Without masked attention, the pose is incorrect. Self-attention improves smoothness but the pose is still not accurate. Cross-attention yields a correct pose but introduces an artifact (blue fingers). The complete model produces both an accurate and smooth result.
read the caption
Figure 6: Qualitative comparison of generated videos for each configuration of Through-The-Mask. The results highlight differences when applying masked cross-attention (With cross-attn), self-attention (With self-attn), both (Ours), or no masked attention layers (No mask attn). Without masked attention, the cartoon superhero fails to perform a prayer. With masked self-attention, the superhero also fails, but the movement appears smoother and more consistent. With masked cross-attention, the superhero successfully performs the prayer, though his fingers turn blue. When integrating the full masked attention mechanism, the superhero performs the action correctly.

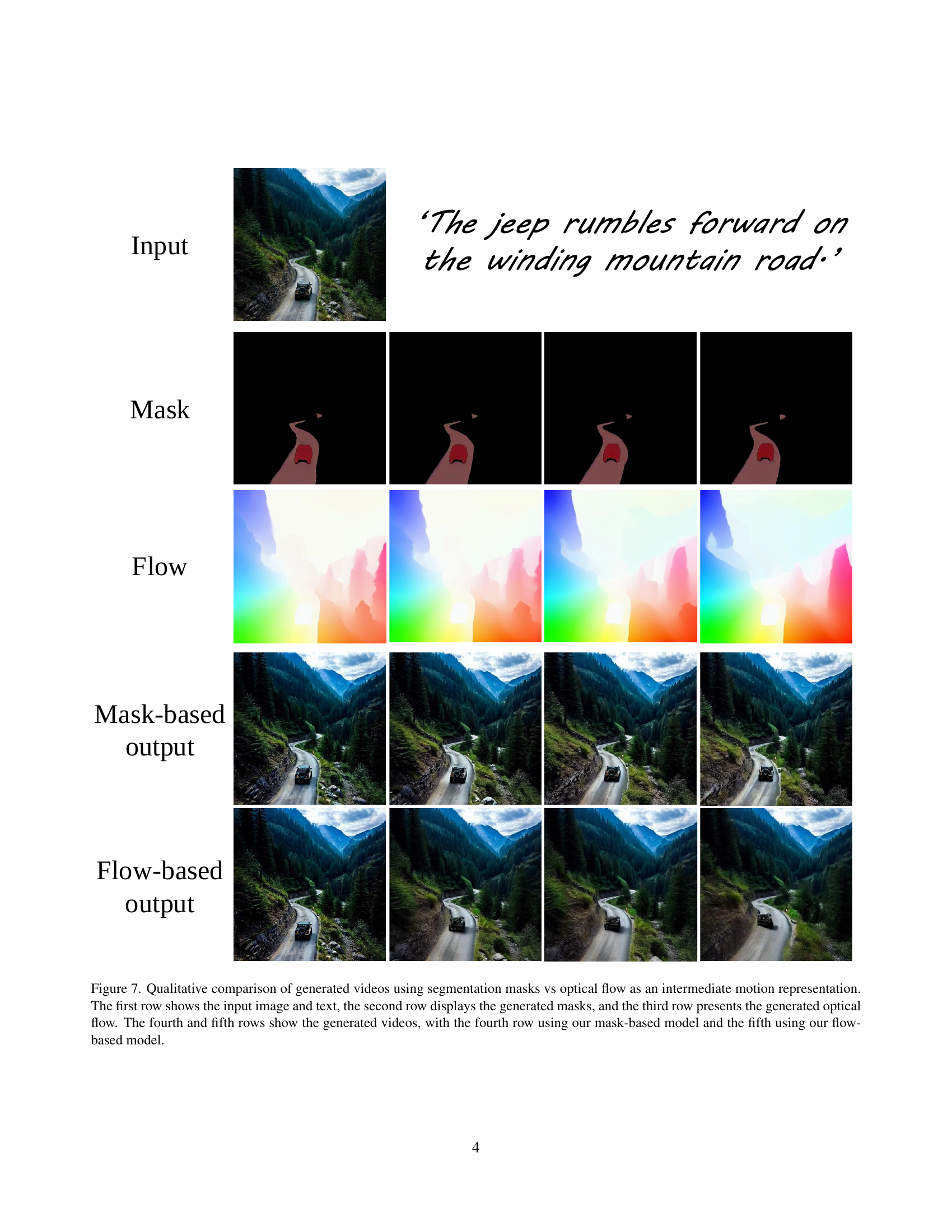
🔼 This figure compares the performance of using segmentation masks versus optical flow as intermediate representations for image-to-video generation. The top row shows the input image and text prompt. The second row displays the segmentation masks generated for each object within the image. The third row shows the optical flow fields that were predicted from the input video. The bottom two rows show the generated videos: the fourth row uses a model that leverages the generated masks, while the fifth row uses a model that leverages the predicted optical flow. The comparison highlights the relative strengths and weaknesses of each intermediate representation in driving the generation process.
read the caption
Figure 7: Qualitative comparison of generated videos using segmentation masks vs optical flow as an intermediate motion representation. The first row shows the input image and text, the second row displays the generated masks, and the third row presents the generated optical flow. The fourth and fifth rows show the generated videos, with the fourth row using our mask-based model and the fifth using our flow-based model.

🔼 This figure shows a qualitative comparison of videos generated using two different methods: Through-The-Mask (TTM) and TI2V. Both methods use the DiT architecture. Each row represents a different video generation task, with the input image and text prompt displayed at the top. The videos generated by TTM are displayed next, followed by the videos generated by the TI2V baseline. This allows for a direct visual comparison of the two methods’ capabilities in generating realistic and coherent videos from a given image and textual description, highlighting Through-The-Mask’s superior performance in generating more accurate and natural-looking results.
read the caption
Figure 8: Qualitative comparison of video generations produced by Through-The-Mask (DiT-based) and the TI2V baseline (DiT-based).
More on tables
| Method | FVD ↓ | CF ↑ | ViCLIP-T ↑ | ViCLIP-V ↑ | AD | Text | Motion | Quality |
|---|---|---|---|---|---|---|---|---|
| VideoCrafter [10] | 266.83 | 0.961 | 0.195 | 0.810 | 4.87 | 78.9 | 78.1 | 80.4 |
| DynamiCrafter [54] | 217.40 | 0.946 | 0.200 | 0.840 | 8.28 | 55.4 | 53.9 | 53.9 |
| Motion-I2V [43] | 286.42 | 0.928 | 0.209 | 0.746 | 7.46 | 81.2 | 82.8 | 83.5 |
| ConsistI2V [41] | 283.59 | 0.938 | 0.202 | 0.838 | 6.38 | 57.0 | 67.1 | 65.6 |
| TI2V (UNet) | 242.18 | 0.954 | 0.203 | 0.858 | 5.99 | 49.2 | 57.8 | 66.4 |
| Ours (UNet) | 196.23 | 0.962 | 0.210 | 0.865 | 5.69 | - | - | - |
| TI2V (DiT) | 212.23 | 0.937 | 0.206 | 0.789 | 9.00 | 61.7 | 63.2 | 67.1 |
| Ours (DiT) | 192.45 | 0.948 | 0.215 | 0.847 | 7.42 | - | - | - |
🔼 Table 2 presents a quantitative evaluation of different image-to-video generation models on the Image-Animation-Bench dataset. The metrics used are Fréchet Video Distance (FVD), which measures the visual similarity between generated and ground truth videos; CLIPFrame (CF), which assesses temporal consistency across frames; ViCLIP-T, measuring text-video alignment; ViCLIP-V, evaluating image-video fidelity; and Average Displacement (AD), indicating the level of motion in generated videos. Human evaluation scores, representing the percentage of raters who preferred the results of Through-The-Mask over other methods, are also included for a comprehensive comparison.
read the caption
Table 2: Image-Animation-Bench results. We report FVD, CLIPFrame (CF), ViCLIP-T, ViCLIP-V, and Average Displacement (AD), along with human ratings. Human evaluation shows the percentage of raters that prefer the results of Through-The-Mask.
| Config. | FVD↓ | CF↑ | ViCLIP-T↑ | ViCLIP-V↑ | AD |
|---|---|---|---|---|---|
| TI2V (UNet) | 974.07 | 0.942 | 0.218 | 0.880 | 6.91 |
| no mask attn (UNet) | 972.25 | 0.962 | 0.214 | 0.880 | 4.99 |
| w. cross-attn (UNet) | 670.92 | 0.965 | 0.220 | 0.890 | 5.25 |
| w. self-attn (UNet) | 658.92 | 0.968 | 0.218 | 0.892 | 5.00 |
| Ours (UNet) | 648.59 | 0.968 | 0.220 | 0.892 | 5.15 |
| TI2V (DiT) | 1199.86 | 0.921 | 0.222 | 0.802 | 10.70 |
| no mask attn (DiT) | 1182.49 | 0.943 | 0.223 | 0.851 | 6.78 |
| w. cross-attn (DiT) | 1105.91 | 0.945 | 0.226 | 0.859 | 7.23 |
| w. self-attn (DiT) | 1152.38 | 0.946 | 0.223 | 0.855 | 7.01 |
| Ours (DiT) | 1082.23 | 0.947 | 0.226 | 0.861 | 7.35 |
🔼 This table presents the results of an ablation study conducted on the SA-V-128 benchmark dataset. The study investigates the impact of different attention mechanisms (masked cross-attention, masked self-attention, both, and neither) within both U-Net and DiT-based image-to-video generation models. The table compares various metrics across different attention configurations to assess the contribution of each mechanism to the overall performance of the model.
read the caption
Table 3: Ablation study results on the SA-V-128 benchmark comparing the performance of different attention configurations, in both U-Net and DiT-based models.
| Configuration | FVD ↓ | CF ↑ | ViCLIP-T ↑ | ViCLIP-V ↑ | AD |
|---|---|---|---|---|---|
| w. OF | 1014.72 | 0.934 | 0.219 | 0.879 | 7.04 |
| w. Seg. | 648.59 | 0.968 | 0.220 | 0.892 | 5.15 |
🔼 This table presents the results of an ablation study that compares the performance of using segmentation masks versus optical flow as the intermediate motion representation in a two-stage image-to-video generation model. The study evaluates four different model configurations. The first is the baseline model using optical flow. The second and third models utilize segmentation masks, one using only masked cross-attention and the other using both masked cross-attention and masked self-attention. The fourth model is the full THROUGH-THE-MASK model. The metrics compared across the configurations are Fréchet Video Distance (FVD), CLIPFrame (CF), ViCLIP-T, ViCLIP-V, and Average Displacement (AD). Lower FVD indicates higher video quality, while higher values in other metrics usually indicate better performance.
read the caption
Table 4: Ablation study comparing segmentation masks and optical flow as motion trajectory representation. w. Seg refers to models with segmentation-based motion trajectories, while w. OF denotes models with optical flow-based motion trajectories.
Full paper#