↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Existing video LLMs struggle with real-time interaction due to the inherent limitations of autoregressive decoding and the conflict between continuous perception and response generation. This leads to delayed responses and reduced responsiveness, particularly problematic in long video streams. This paper addresses these issues by proposing an alternative architecture.
Dispider, the proposed system, tackles this challenge with a disentangled design. It uses separate, parallel modules for perception (continuous video analysis), decision (determining interaction trigger points), and reaction (generating responses). This asynchronous approach ensures timely, contextually accurate responses without interrupting the continuous video processing. Experiments show that Dispider significantly outperforms existing models in real-time interactive scenarios, highlighting the effectiveness of its architecture and its improvements in both temporal reasoning and response generation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to video question answering, enabling real-time interaction with video LLMs. Its disentangled architecture addresses the limitations of existing online video LLMs, paving the way for more engaging and responsive human-computer interaction systems in the rapidly evolving field of video understanding and large language models. This research has the potential to significantly impact the development of interactive multimedia applications and real-time video analysis tools. Further research could explore improved scene segmentation techniques and the optimization of asynchronous interaction modules for various tasks.
Visual Insights#

🔼 Figure 1 illustrates the architectural differences between Dispider and VideoLLM-online in handling real-time video interactions. Dispider uses a disentangled approach with separate, parallel modules for perception (continuous video monitoring), decision (determining interaction trigger points), and reaction (asynchronous response generation). This allows for simultaneous perception and reaction, unlike VideoLLM-online, which uses a single LLM, resulting in sequential processing and hindering real-time responsiveness. Dispider’s lightweight perception module efficiently processes the video stream, identifying optimal moments for interaction. The decision module integrates interaction history and visual information to trigger the asynchronous interaction module for generating detailed responses, ensuring timely and contextually accurate interactions.
read the caption
Figure 1: Schematic comparison between Dispider and VideoLLM-online [5]. Our Dispider introduces a disentangled paradigm for active real-time interaction with streaming video. It features a lightweight perception module for continuous monitoring, a decision module to determine when to trigger system interactions, and an asynchronous reaction module for generating detailed responses. In contrast, VideoLLM-online is unable to simultaneously perform streaming perception and response generation because it relies on a single LLM to handle both functions.
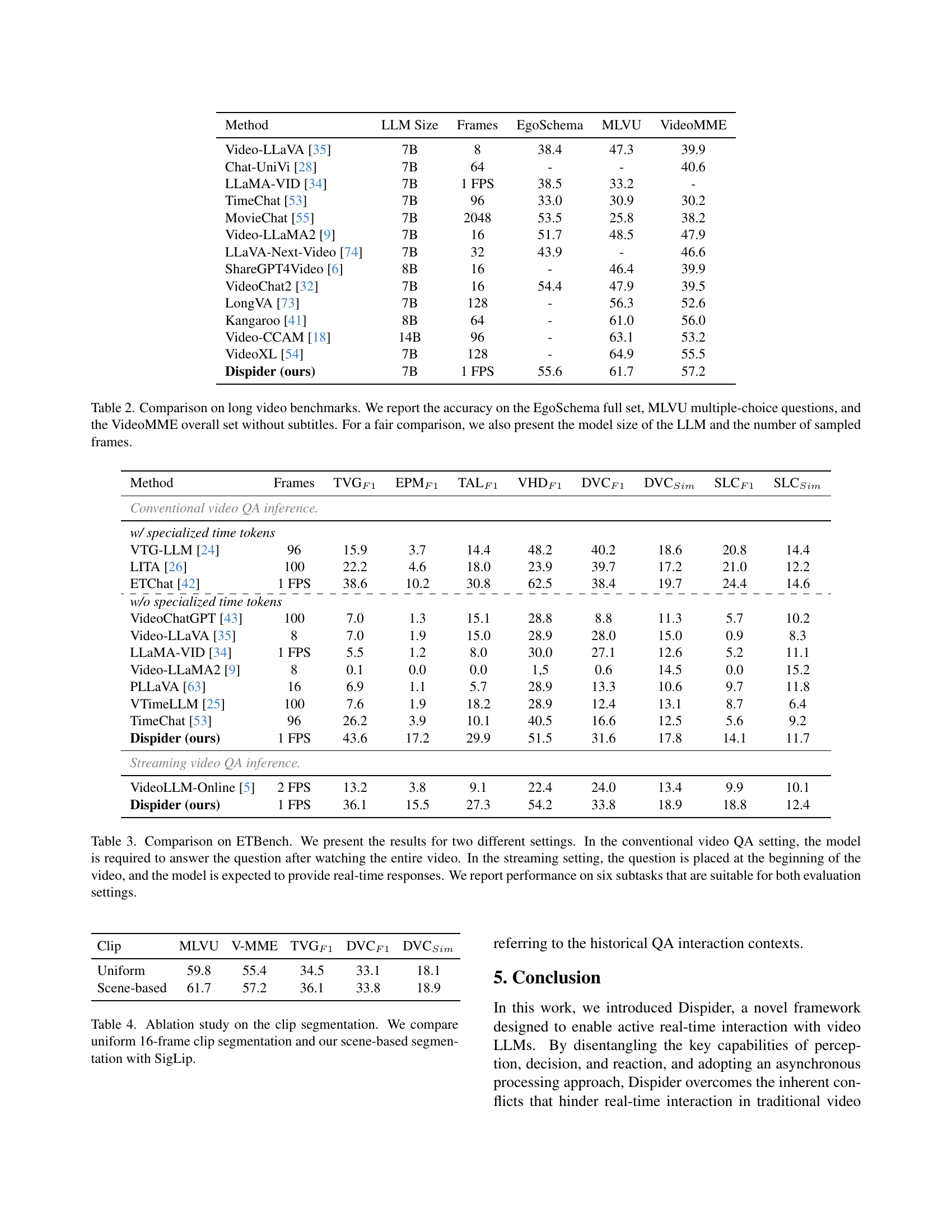
| Method | LLM Size | Frames | EgoSchema | MLVU | VideoMME |
|---|---|---|---|---|---|
| Video-LLaVA [35] | 7B | 8 | 38.4 | 47.3 | 39.9 |
| Chat-UniVi [28] | 7B | 64 | - | - | 40.6 |
| LLaMA-VID [34] | 7B | 1 FPS | 38.5 | 33.2 | - |
| TimeChat [53] | 7B | 96 | 33.0 | 30.9 | 30.2 |
| MovieChat [55] | 7B | 2048 | 53.5 | 25.8 | 38.2 |
| Video-LLaMA2 [9] | 7B | 16 | 51.7 | 48.5 | 47.9 |
| LLaVA-Next-Video [74] | 7B | 32 | 43.9 | - | 46.6 |
| ShareGPT4Video [6] | 8B | 16 | - | 46.4 | 39.9 |
| VideoChat2 [32] | 7B | 16 | 54.4 | 47.9 | 39.5 |
| LongVA [73] | 7B | 128 | - | 56.3 | 52.6 |
| Kangaroo [41] | 8B | 64 | - | 61.0 | 56.0 |
| Video-CCAM [18] | 14B | 96 | - | 63.1 | 53.2 |
| VideoXL [54] | 7B | 128 | - | 64.9 | 55.5 |
| Dispider (ours) | 7B | 1 FPS | 55.6 | 61.7 | 57.2 |
🔼 Table 1 presents a comprehensive comparison of various models’ performance on the StreamingBench benchmark, which evaluates three key aspects of video understanding: Omni-source Understanding (evaluating the model’s ability to understand various aspects of the video content, including emotion, scene, source, and multimodal alignment), Contextual Understanding (testing the model’s capability in understanding misleading and anomalous contexts, sequential questions, and proactive outputs), and Real-Time Visual Understanding (assessing the model’s proficiency in perceiving objects, causal reasoning, summarizing clips, and understanding attributes, events, text, spatial relationships, actions, and counting). The models are categorized into three groups (Human, Proprietary LLMs, Open-Source LLMs) for a complete and fair comparison.
read the caption
Table 1: Performance comparison on StreamingBench on Omni-source Understanding, Contextual Understanding, and Real-Time Visual Understanding. Omni-source Understanding includes Emotion Recognition (ER), Scene Understanding (SCU), Source Discrimination (SD), and Multimodal Alignment (MA). Contextual Understanding includes Misleading Context Understanding (MCU), Anomaly Context Understanding (ACU), Sequential Question Answering (SQA) and Proactive Output (PO). Real-Time Visual Understanding includes Object Perception (OP), Causal Reasoning (CR), Clips Summarization (CS), Attribute Perception (ATP), Event Understanding (EU), Text-Rich Understanding (TR), Prospective Reasoning (PR), Spatial Understanding (SU), Action Perception (ACP), and Counting (CT). Results are categorized into Human, Proprietary MLLMs, and Open-Source MLLMs for a comprehensive evaluation.
In-depth insights#
Dispider: Active Video LLMs#
The concept of “Dispider: Active Video LLMs” introduces a novel approach to video understanding by enabling real-time interaction with Large Language Models (LLMs). Dispider’s core innovation lies in disentangling the perception, decision, and reaction processes, overcoming limitations of prior models that handle these tasks sequentially. This allows for simultaneous video processing and response generation, crucial for truly real-time interaction. The system uses a lightweight perception module for continuous video monitoring, a decision module to identify optimal interaction moments, and an asynchronous reaction module for generating responses. This asynchronous design ensures timely and accurate responses without hindering real-time processing. Dispider’s scene-based perception further enhances efficiency by segmenting the video into meaningful clips. The model’s architecture, therefore, fosters efficient long-duration video understanding, significantly surpassing previous online and offline video LLMs in both accuracy and responsiveness. The implications of such a system are far-reaching, suggesting a more intuitive and dynamic human-computer interaction paradigm, particularly beneficial for applications like real-time video summarization, question answering, and interactive video editing.
Disentangled Architecture#
The core concept of a disentangled architecture in the context of video LLMs centers on separating the distinct processes of perception, decision, and reaction into independent modules that operate concurrently. This contrasts with monolithic approaches that utilize a single large language model (LLM) to handle all three. The advantages are threefold. First, parallel processing allows for continuous video monitoring while simultaneously generating responses. Second, this design avoids the blocking problem inherent in autoregressive LLMs where generating a response necessitates pausing video processing. Third, it offers the potential for greater efficiency by using specialized, potentially lighter-weight, models for specific tasks. This design principle may lead to improved response speed and reduced latency, thereby enabling more natural and engaging real-time interactions with streaming video. Asynchronous operation between modules allows for a dynamic balance between continuous perception and more resource-intensive response generation, improving overall system performance.
Scene-Based Perception#
The concept of ‘Scene-Based Perception’ in the context of real-time video understanding is crucial for efficient processing. Instead of uniformly processing video frames, it suggests segmenting the video into meaningful chunks based on scene changes. This approach reduces redundancy and allows the model to focus on informative parts. The choice of scene boundary detection method is vital, impacting accuracy and efficiency. Methods like using pre-trained models to extract features and calculate cosine similarities between frames offer a good balance between computational cost and accuracy. The system’s ability to accurately determine scene boundaries directly influences the quality of downstream tasks, such as response generation and question answering. The effectiveness of this approach hinges on the robustness of the scene change detection, particularly in handling subtle changes or noisy video streams. Further, integrating this scene segmentation with a decision module for optimal response timing is key. This ensures that the model only responds when sufficient information within a scene has been observed, maximizing response efficiency and timeliness, while avoiding unnecessary computation and delaying interaction.
Asynchronous Interaction#
The concept of “Asynchronous Interaction” in the context of a real-time video processing system is crucial for efficiency and responsiveness. It addresses the inherent conflict between continuous video perception and the time-consuming nature of generating detailed responses using large language models (LLMs). By decoupling the response generation from the video processing pipeline, the system can maintain uninterrupted video monitoring and analysis while simultaneously preparing detailed and context-aware responses. This asynchronous design prevents response generation from blocking the perception module, ensuring that the system remains responsive to new visual information and user interactions. The asynchronous interaction module handles the task of generating detailed answers independently, allowing the main video processing to proceed concurrently and seamlessly. This approach is essential for dealing with long-duration video streams where continuous interaction is expected, as it ensures that the system can deliver timely, relevant feedback without sacrificing real-time processing capabilities. The disentanglement of processes ensures contextually accurate responses. The system’s ability to generate these responses in the background, without impacting real-time visual monitoring, is a significant improvement over traditional approaches.
StreamingBench Results#
The StreamingBench results section would be crucial for evaluating Dispider’s performance in real-time video understanding. It would likely present quantitative results across StreamingBench’s three core aspects: Real-time Visual Understanding, Omni-source Understanding, and Contextual Understanding. High scores across these categories would strongly validate Dispider’s effectiveness in processing and responding to streaming videos promptly and accurately. A detailed breakdown by task within each category, showcasing Dispider’s strengths and weaknesses compared to baseline models, especially concerning response latency and accuracy, would be particularly informative. Comparison to VideoLLM-online is key here, as Dispider aims to outperform it by addressing limitations in simultaneous perception and response generation. The analysis should also consider the impact of various parameters, like video length and complexity, on Dispider’s performance to demonstrate its robustness and scalability in real-world scenarios. Finally, error analysis showcasing common failure modes of Dispider and potential areas for future improvements would contribute significantly to the section’s value.
More visual insights#
More on figures

🔼 The Response Decision Module within Dispider dynamically determines the optimal moments for generating responses to user queries during live video streaming. It achieves this by first segmenting the continuous video stream into variable-length clips based on scene changes. This ensures that each clip contains meaningful visual information without unnecessary redundancy. The module then leverages a historical memory that incorporates past interactions and visual cues from previously processed video segments. This memory, combined with features extracted from the current video clip, the user’s question, and special tokens (⟨TODO⟩ and ⟨ANS⟩ indicating the need for a decision and the presence of an answer, respectively), informs the model’s decision regarding whether to produce a response or wait for additional information.
read the caption
Figure 2: Illustration of the Response Decision Module in a proactive streaming video processing system. The module dynamically determines when to respond during video streaming by segmenting the video into non-uniform clips and utilizing historical memory to capture context. The module then combines memory features, clip features, question text, and special tokens, ⟨TODO⟩ and ⟨ANS⟩, to decide on response timing.

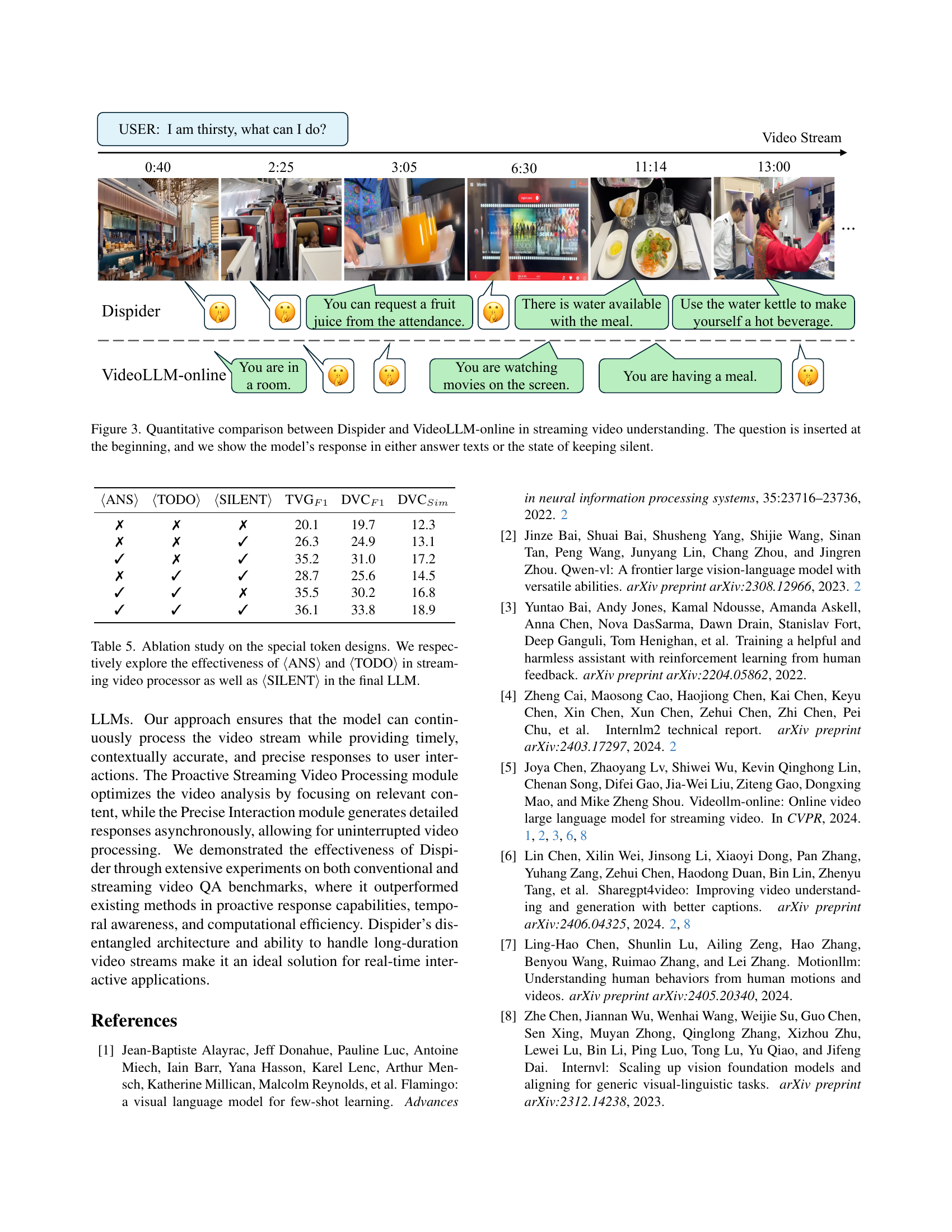
🔼 Figure 3 presents a comparative analysis of Dispider and VideoLLM-online, focusing on their performance in real-time video understanding tasks. A question is asked at the very beginning of a video stream. The figure then shows a timeline of the video, highlighting key moments where either model responded with an answer (text displayed), or remained silent (indicated by silence). The goal is to demonstrate the capabilities of Dispider to provide timely and relevant responses as the video progresses, in contrast to VideoLLM-online.
read the caption
Figure 3: Quantitative comparison between Dispider and VideoLLM-online in streaming video understanding. The question is inserted at the beginning, and we show the model’s response in either answer texts or the state of keeping silent.
More on tables
| Method | Frames | TVGF1 | EPMF1 | TALF1 | VHDF1 | DVCF1 | DVCSim | SLCF1 | SLCSim |
|---|---|---|---|---|---|---|---|---|---|
| Conventional video QA inference. | |||||||||
| w/ specialized time tokens | |||||||||
| VTG-LLM [24] | 96 | 15.9 | 3.7 | 14.4 | 48.2 | 40.2 | 18.6 | 20.8 | 14.4 |
| LITA [26] | 100 | 22.2 | 4.6 | 18.0 | 23.9 | 39.7 | 17.2 | 21.0 | 12.2 |
| ETChat [42] | 1 FPS | 38.6 | 10.2 | 30.8 | 62.5 | 38.4 | 19.7 | 24.4 | 14.6 |
| \hdashline w/o specialized time tokens | |||||||||
| VideoChatGPT [43] | 100 | 7.0 | 1.3 | 15.1 | 28.8 | 8.8 | 11.3 | 5.7 | 10.2 |
| Video-LLaVA [35] | 8 | 7.0 | 1.9 | 15.0 | 28.9 | 28.0 | 15.0 | 0.9 | 8.3 |
| LLaMA-VID [34] | 1 FPS | 5.5 | 1.2 | 8.0 | 30.0 | 27.1 | 12.6 | 5.2 | 11.1 |
| Video-LLaMA2 [9] | 8 | 0.1 | 0.0 | 0.0 | 1,5 | 0.6 | 14.5 | 0.0 | 15.2 |
| PLLaVA [63] | 16 | 6.9 | 1.1 | 5.7 | 28.9 | 13.3 | 10.6 | 9.7 | 11.8 |
| VTimeLLM [25] | 100 | 7.6 | 1.9 | 18.2 | 28.9 | 12.4 | 13.1 | 8.7 | 6.4 |
| TimeChat [53] | 96 | 26.2 | 3.9 | 10.1 | 40.5 | 16.6 | 12.5 | 5.6 | 9.2 |
| Dispider (ours) | 1 FPS | 43.6 | 17.2 | 29.9 | 51.5 | 31.6 | 17.8 | 14.1 | 11.7 |
| Streaming video QA inference. | |||||||||
| VideoLLM-Online [5] | 2 FPS | 13.2 | 3.8 | 9.1 | 22.4 | 24.0 | 13.4 | 9.9 | 10.1 |
| Dispider (ours) | 1 FPS | 36.1 | 15.5 | 27.3 | 54.2 | 33.8 | 18.9 | 18.8 | 12.4 |
🔼 This table presents a comparison of different video LLMs on three established long-video question answering benchmarks: EgoSchema, MLVU, and VideoMME. The accuracy of each model is reported on the full EgoSchema dataset, MLVU’s multiple-choice questions, and the overall VideoMME dataset (without subtitles). To ensure a fair comparison across models with varying architectures and scales, the table also includes the size of the Large Language Model (LLM) used by each model and the number of video frames sampled for processing.
read the caption
Table 2: Comparison on long video benchmarks. We report the accuracy on the EgoSchema full set, MLVU multiple-choice questions, and the VideoMME overall set without subtitles. For a fair comparison, we also present the model size of the LLM and the number of sampled frames.
| Clip | MLVU | V-MME | TVGF1 | DVCF1 | DVCSim |
|---|---|---|---|---|---|
| Uniform | 59.8 | 55.4 | 34.5 | 33.1 | 18.1 |
| Scene-based | 61.7 | 57.2 | 36.1 | 33.8 | 18.9 |
🔼 Table 3 presents a comparison of the model’s performance on the ETBench benchmark under two different scenarios: conventional video QA and streaming video QA. In the conventional setting, the model processes the entire video before answering a question posed at the end. In contrast, the streaming setting simulates a real-time interaction where the question is presented at the start, demanding timely and accurate responses throughout the video. The table details the model’s performance across six subtasks (TVG, EPM, TAL, VHD, DVC, SLC) that assess various aspects of temporal understanding and visual reasoning, suitable for both settings. The results showcase the model’s ability to handle both offline and real-time video understanding tasks effectively.
read the caption
Table 3: Comparison on ETBench. We present the results for two different settings. In the conventional video QA setting, the model is required to answer the question after watching the entire video. In the streaming setting, the question is placed at the beginning of the video, and the model is expected to provide real-time responses. We report performance on six subtasks that are suitable for both evaluation settings.
| ⟨ANS⟩ | ⟨TODO⟩ | ⟨SILENT⟩ | TVGF1 | DVCF1 | DVCSim |
|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | 20.1 | 19.7 | 12.3 |
| ✗ | ✗ | ✓ | 26.3 | 24.9 | 13.1 |
| ✓ | ✗ | ✓ | 35.2 | 31.0 | 17.2 |
| ✗ | ✓ | ✓ | 28.7 | 25.6 | 14.5 |
| ✓ | ✓ | ✗ | 35.5 | 30.2 | 16.8 |
| ✓ | ✓ | ✓ | 36.1 | 33.8 | 18.9 |
🔼 This table presents an ablation study on different clip segmentation methods used in the Dispider model. It compares the performance of a uniform clip segmentation approach (dividing the video into fixed-length clips of 16 frames each) against the model’s proposed scene-based segmentation (dynamically segmenting the video based on scene changes detected using SigLip). The comparison is done using metrics from conventional QA tasks on the MLVU and VideoMME datasets as well as streaming metrics (temporal grounding and dense video captioning) on the ETBench dataset. This helps analyze how the choice of segmentation strategy affects the model’s accuracy in different video understanding tasks.
read the caption
Table 4: Ablation study on the clip segmentation. We compare uniform 16-frame clip segmentation and our scene-based segmentation with SigLip.
Full paper#