↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Aligning large language models (LLMs) with human preferences is crucial, but existing Reinforcement Learning from Human Feedback (RLHF) methods like Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) often face challenges in terms of computational cost and training stability. These methods introduce complexity, require extensive computing resources and can be prone to instability during training, hindering large-scale applications. Newer methods address some issues but may create other problems.
This paper introduces REINFORCE++, a novel method that enhances the classic REINFORCE algorithm. REINFORCE++ addresses these issues by integrating key optimization techniques from PPO, but without the need for a critic network. This simplification leads to improved training stability and reduced computational overhead. Empirical evaluations demonstrate REINFORCE++’s superior stability compared to GRPO and greater computational efficiency than PPO while maintaining comparable performance. The open-source availability further enhances its accessibility and use.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a simpler and more efficient approach to aligning large language models (LLMs) with human preferences. It directly addresses the computational challenges associated with existing RLHF methods, making it a practical solution for researchers working with LLMs. The open-source implementation further enhances its accessibility and potential impact on the field.
Visual Insights#

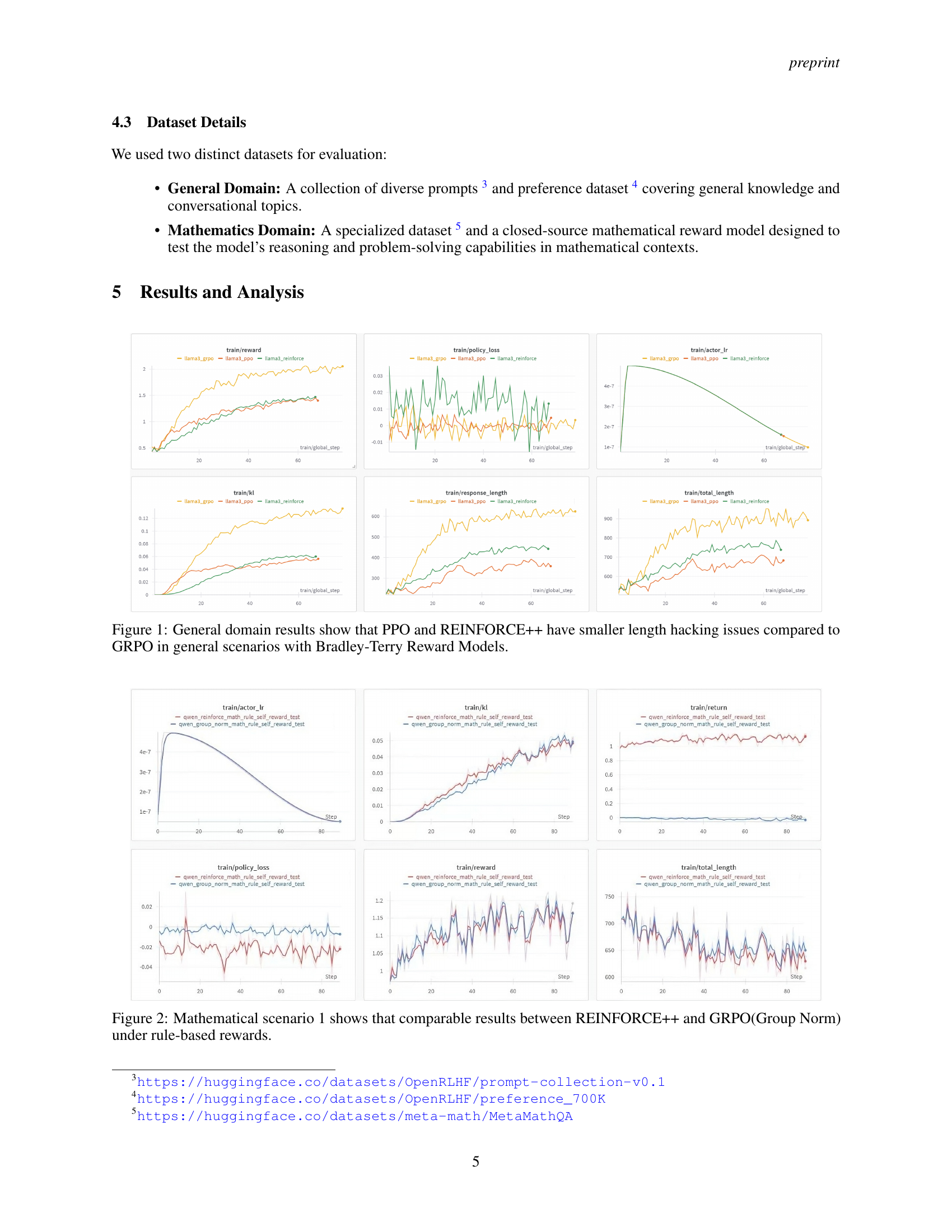
🔼 The figure displays the training curves for three reinforcement learning algorithms (PPO, REINFORCE++, and GRPO) on a general domain dataset using the Bradley-Terry reward model. It compares their performance across several metrics, including reward, KL divergence, policy loss, response length, actor learning rate, and total sequence length. The key observation is that PPO and REINFORCE++ exhibit less severe ’length hacking’ (where the model generates excessively long outputs to maximize reward) than GRPO.
read the caption
Figure 1: General domain results show that PPO and REINFORCE++ have smaller length hacking issues compared to GRPO in general scenarios with Bradley-Terry Reward Models.
| Parameter | Value |
|---|---|
| KL Penalty Coefficient (β) | 0.01 (General), 0.001 (Mathematics) |
| Maximum Samples | 25,000 |
| Samples per Prompt | 4 |
| Rollout Batch Size | 256 |
| Training Batch Size | 128 |
| Actor Learning Rate | 5 × 10⁻⁷ |
| Critic Learning Rate | 9 × 10⁻⁶ |
| Discount Factor (γ) | 1.0 |
| Clip ϵ | 0.2 |
🔼 This table details the hyperparameters used in the REINFORCE++ algorithm, including the KL penalty coefficient, the number of samples per prompt, batch sizes, learning rates, discount factor, and the clipping parameter epsilon. These settings influence the training efficiency and model performance, showcasing the specific configurations used in the experiments.
read the caption
Table 1: Hyper-Parameter Configuration for REINFORCE++
In-depth insights#
RLHF Algorithm Advance#
Reinforcement Learning from Human Feedback (RLHF) has seen significant algorithmic advancements. Early methods like REINFORCE suffered from high variance in gradient estimates, limiting scalability. Proximal Policy Optimization (PPO) improved stability by incorporating a critic network and clipping mechanisms, but introduced computational overhead. Newer approaches like Direct Preference Optimization (DPO) and REINFORCE Leave-One-Out (RLOO) aim to address specific limitations, but might introduce complexities. Group Relative Policy Optimization (GRPO) focuses on improving efficiency, but stability can still be a concern. The evolution reflects a trade-off between simplicity, stability, computational efficiency, and alignment performance. Future research likely focuses on methods which balance these considerations more effectively, potentially leveraging techniques beyond gradient-based policy optimization.
PPO-inspired Enhancements#
The heading ‘PPO-inspired Enhancements’ suggests a crucial aspect of the research paper focusing on improving the REINFORCE algorithm. It implies that the authors are borrowing effective components from Proximal Policy Optimization (PPO), a widely used and powerful reinforcement learning method known for its stability, to enhance the REINFORCE algorithm’s performance. Key enhancements likely include techniques to constrain policy updates, such as clipping mechanisms, to prevent drastic changes in the policy and improve training stability. This is crucial, as REINFORCE often suffers from high variance in gradient estimates. The integration of these PPO elements aims to mitigate REINFORCE’s instability while retaining its simplicity. By strategically combining the best features of both algorithms, the researchers aim to create a more efficient and robust RLHF framework. This approach is expected to deliver improved training stability and computational efficiency for aligning Large Language Models with human preferences, potentially outperforming existing methods like GRPO while maintaining a straightforward implementation.
Stability and Efficiency#
The research paper emphasizes achieving both stability and efficiency in training large language models (LLMs). Stability is crucial because unstable training can lead to unpredictable and unreliable model performance. The paper addresses instability by integrating techniques like token-level KL penalties and PPO-clip loss. These mechanisms help constrain policy updates, preventing drastic changes that could disrupt training dynamics. Efficiency is equally important, as training LLMs is computationally expensive. The paper highlights the efficiency gains from eliminating the critic network, reducing computational overhead compared to methods like PPO. The use of mini-batch updates further enhances efficiency by allowing for parallel processing and improved convergence rates. The combination of these stability-enhancing and efficiency-boosting techniques results in a training process that is both robust and resource-conscious, paving the way for more effective and scalable LLM development. The balanced approach to stability and efficiency is a key contribution of the paper, allowing for improved performance without sacrificing practicality.
Empirical Evaluation#
A robust empirical evaluation section is crucial for validating the claims of any research paper. For this paper on REINFORCE++, a strong empirical evaluation would involve a multifaceted approach. It should begin by clearly defining the metrics used to assess performance, such as alignment with human preferences, computational efficiency, and training stability. Benchmark datasets, including both general and domain-specific ones (like mathematical reasoning), are needed for a comprehensive evaluation. Comparisons against established baselines, such as PPO and GRPO, are essential. The results should be presented clearly, likely using tables and graphs, showcasing the superior performance of REINFORCE++. A detailed analysis of the results, including error bars and statistical significance tests, is necessary to strengthen the claims. Finally, ablation studies investigating the impact of individual components of the REINFORCE++ algorithm would further solidify the findings and demonstrate its effectiveness. The inclusion of open-source code and data would allow for reproducibility, a cornerstone of strong empirical research.
Future Work Directions#
Future research should prioritize scaling REINFORCE++ to larger datasets and more complex alignment scenarios, rigorously evaluating its performance against state-of-the-art methods under diverse conditions. Investigating the impact of different reward model architectures and hyperparameter tuning strategies is crucial. Exploring the integration of REINFORCE++ with other RLHF techniques, such as reward shaping or curriculum learning, could further enhance its efficiency and effectiveness. A key area of exploration is analyzing the robustness of REINFORCE++ to adversarial attacks and developing techniques to mitigate such vulnerabilities. Finally, theoretical analysis of REINFORCE++’s convergence properties and sample complexity is needed to provide a deeper understanding of its strengths and limitations. Understanding its behavior with different LLMs and prompt styles warrants detailed investigation.
More visual insights#
More on figures

🔼 Figure 2 presents a comparison of REINFORCE++ and GRPO (Group Norm) performance on a mathematical task using rule-based rewards. The graphs illustrate key metrics such as reward, KL divergence, policy loss, actor learning rate, and total length (likely of generated text) across training steps. The main takeaway is that both algorithms achieve comparable performance in this specific scenario, demonstrating REINFORCE++’s competitiveness with a more established method.
read the caption
Figure 2: Mathematical scenario 1 shows that comparable results between REINFORCE++ and GRPO(Group Norm) under rule-based rewards.

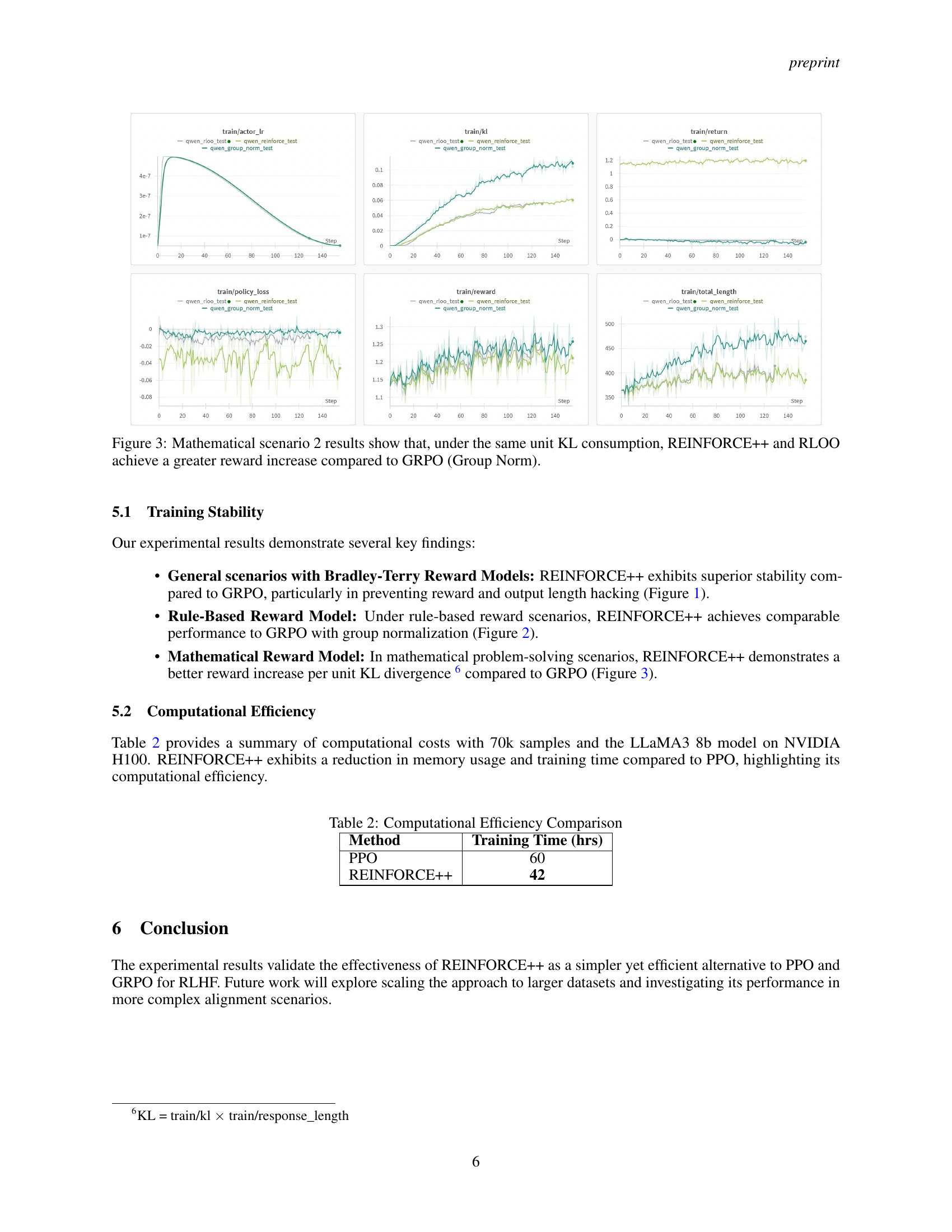
🔼 Figure 3 presents a comparison of the performance of REINFORCE++, RLOO, and GRPO (Group Norm) in a mathematical scenario. The key finding is that, when consuming the same amount of KL divergence (a measure of the difference between the model’s updated policy and its previous policy), both REINFORCE++ and RLOO achieve a significantly larger increase in reward than GRPO. This highlights that REINFORCE++ and RLOO are more efficient at improving model performance in this specific context compared to the Group Norm variant of GRPO.
read the caption
Figure 3: Mathematical scenario 2 results show that, under the same unit KL consumption, REINFORCE++ and RLOO achieve a greater reward increase compared to GRPO (Group Norm).
Full paper#