↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for dynamic 3D Gaussian splatting struggle with storage and representing complex real-world motions. Existing techniques, such as those using implicit or explicit deformation or extending to 4D Gaussians, face limitations in handling long durations and complex motion combinations, often resulting in blurry renderings or large model sizes. These methods also frequently require pre-computed information like optical flow, limiting their practical applicability.
To address these issues, the authors propose MoDec-GS, a novel framework that employs a global-to-local motion decomposition. This method efficiently captures dynamic motions through Global Anchor Deformation (GAD) for coarse global movements and Local Gaussian Deformation (LGD) for fine-grained local motions. Furthermore, Temporal Interval Adjustment (TIA) automatically optimizes temporal segments during training, eliminating the need for pre-computed data. MoDec-GS demonstrates significant improvements in memory efficiency (up to 70% reduction) and visual quality compared to state-of-the-art methods, showcasing its effectiveness in handling complex motion scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing dynamic 3D Gaussian splatting methods by improving memory efficiency and handling complex motions. Its novel approach of global-to-local motion decomposition and temporal interval adjustment offers a significant advancement in the field of novel view synthesis, particularly for real-world scenarios with complex movements. This opens new avenues for research in compact and efficient dynamic scene representation.
Visual Insights#

🔼 Figure 1 showcases novel view synthesis results using various methods, including the proposed MoDec-GS, on a dataset of real-world videos with complex motion [45]. MoDec-GS is presented as a new framework that effectively learns compact dynamic 3D Gaussians, overcoming the limitations of existing state-of-the-art (SOTA) techniques [57, 20, 54] in handling complex motion combinations. The comparison highlights MoDec-GS’s superior rendering quality, achieved even with a smaller model size than the other methods. The metrics used for comparison are PSNR (higher is better), LPIPS (lower is better), and storage size (lower is better).
read the caption
Figure 1: Novel view synthesis results on [45]. We introduce MoDec-GS, a novel framework for learning compact dynamic 3D Gaussians from real-world videos with complex motion. While existing SOTA methods [57, 20, 54] have difficulty modeling such complex combination of global and local motions, our approach effectively handles them thanks to GLMD (Sec. 4.1), and outperforms the prior methods in rendering quality even with a compact model size. The metrics under each framework are, PSNR (dB)↑↑\uparrow↑ / LPIPS [59] ↓↓\downarrow↓ / Storage (MB)↓↓\downarrow↓.
| Method | Apple | Block | Paper-windmill | Space-out | ||||
|---|---|---|---|---|---|---|---|---|
| SC-GS [20] | 14.96 / 0.692 / 0.508 | 173.3 | 13.98 / 0.548 / 0.483 | 115.7 | 14.87 / 0.221 / 0.432 | 446.3 | 14.79 / 0.511 / 0.440 | 114.2 |
| Deformable 3DGS [57] | 15.61 / 0.696 / 0.367 | 87.71 | 14.87 / 0.559 / 0.390 | 118.9 | 14.89 / 0.213 / 0.341 | 160.2 | 14.59 / 0.510 / 0.450 | 42.01 |
| 4DGS [54] | 15.41 / 0.691 / 0.524 | 61.52 | 13.89 / 0.550 / 0.539 | 63.52 | 14.44 / 0.201 / 0.445 | 123.9 | 14.29 / 0.515 / 0.473 | 52.02 |
| MoDec-GS (Ours) | 16.48 / 0.699 / 0.402 | 23.78 | 15.57 / 0.590 / 0.478 | 13.65 | 14.92 / 0.220 / 0.377 | 17.08 | 14.65 / 0.522 / 0.467 | 18.24 |
🔼 Table 1 presents a quantitative comparison of different novel view synthesis (NVS) methods on the iPhone dataset [16]. The table evaluates the performance of each method across four metrics: mean Peak Signal-to-Noise Ratio (mPSNR) in decibels (dB), mean Structural Similarity Index (mSSIM), mean Learned Perceptual Image Patch Similarity (mLPIPS), and model storage size in Megabytes (MB). Higher mPSNR and mSSIM values indicate better visual quality, while a lower mLPIPS value signifies higher perceptual similarity to the ground truth. A smaller storage size is also desirable. The best and second-best performing methods for each metric are highlighted in red and blue, respectively. Each row represents a different NVS method, and each column shows the performance of that method on a specific video sequence in the iPhone dataset.
read the caption
Table 1: Quantitative results comparison on iPhone datasets [16]. Red and blue denote the best and second best performances, respectively. Each block element of 5-performance denotes (mPSNR(dB)↑↑\uparrow↑ / mSSIM↑↑\uparrow↑ / mLPIPS↓↓\downarrow↓ Storage(MB)↓↓\downarrow↓).
In-depth insights#
Dynamic 3DGS Limits#
Dynamic 3D Gaussian Splatting (3DGS) methods, while offering impressive speed and quality for static scenes, face limitations when extending to dynamic scenarios. Storage demands dramatically increase as methods attempt to represent temporal changes, often requiring multi-dimensional attributes for numerous Gaussians. Representing complex, real-world motions (combining global and local movements) proves challenging, leading to blurry or incomplete reconstructions. Current approaches often segment videos into static sections or employ implicit/explicit deformation methods, but these solutions either sacrifice quality or efficiency. The temporal aspect presents another significant hurdle: accurately modeling subtle changes over time and dynamically adapting the model to the varying motion complexity across a scene requires substantial computational overhead. Therefore, the focus shifts toward developing more efficient representations and algorithms that address these limitations for creating compact yet effective dynamic 3DGS models.
GLMD Motion Model#
The Global-to-Local Motion Decomposition (GLMD) motion model presented in the paper is a novel approach to handling complex movements in dynamic scenes for efficient 3D Gaussian splatting. It cleverly separates motion into global and local components, addressing the limitations of previous methods that struggled with complex motion combinations. The global component is handled by Global Anchor Deformation (GAD), efficiently capturing large-scale scene motion by directly deforming anchor points in a canonical 3DGS representation. This reduces computational cost compared to deforming individual Gaussians. Local motion is addressed by Local Gaussian Deformation (LGD), which refines the representation with fine-grained adjustments to individual Gaussians, after the global transformation. This two-stage approach is enhanced by Temporal Interval Adjustment (TIA), dynamically optimizing the temporal coverage of each local component to improve both efficiency and accuracy. Overall, GLMD offers a more efficient and effective way to represent complex dynamic scenes, leading to improved rendering quality with significantly reduced storage requirements, especially when dealing with videos containing intricate and diverse movements.
TIA Interval Tuning#
The concept of ‘TIA Interval Tuning’ suggests a dynamic adjustment of temporal segments during the training process of a dynamic scene representation model. This approach aims to optimize the model’s efficiency by allocating more temporal resolution to periods of significant motion and less to static or slowly moving parts of a video. The core idea is to avoid uniform temporal segmentation, which can be wasteful for scenes with varied motion dynamics. By adapting the temporal window for each segment, TIA improves the quality of motion representation without increasing storage significantly. This adaptation enhances the model’s ability to handle both subtle and large motions effectively. Automatic interval adjustment based on gradient analysis also avoids manual intervention, further improving training efficiency. The success of such an approach depends heavily on the effectiveness of the gradient-based adaptation, as a poorly tuned mechanism could lead to artifacts or less effective representation.
Compact Model Design#
The core challenge addressed in the concept of ‘Compact Model Design’ within this research is the inherent tension between achieving high-fidelity dynamic scene representation and maintaining a small model size. Existing methods for dynamic 3D Gaussian splatting often result in large models due to the complexity of representing both global and local motions over time. This paper directly tackles this by introducing a novel framework, MoDec-GS, that employs a global-to-local motion decomposition strategy. This approach decomposes complex movements into global and local components, enabling efficient representation. By using a two-stage deformation process, the global motions are captured effectively, while fine-grained local adjustments are handled through explicit deformation of the individual Gaussian components. This hierarchical approach, coupled with temporal interval adjustment (TIA), allows the system to adapt to varying motion complexity in different video segments, further optimizing the efficiency of model parameters. The result is a significant reduction in model size (up to 70%) without compromising visual quality, a major advance in compact dynamic scene modeling.
Future NVS Research#
Future NVS research should prioritize robustness and generalization across diverse scene complexities and motion types. Current methods struggle with highly detailed or intricate objects, and significant advancements are needed to handle these challenges effectively. This requires exploring innovative representation techniques beyond current Gaussian splatting approaches, perhaps leveraging more sophisticated volumetric models or incorporating techniques from traditional computer graphics. Memory efficiency remains a critical concern, necessitating the development of efficient compression algorithms and model architectures capable of handling long-duration videos. Furthermore, research should focus on improving the handling of complex motions, including the disentanglement of global and local movements for more accurate and realistic reconstruction. This may involve integrating advanced motion estimation or tracking techniques. Finally, future work should address the need for efficient and accurate training methods, potentially incorporating unsupervised or self-supervised learning strategies to alleviate the need for large-scale, labeled datasets.
More visual insights#
More on figures

🔼 MoDec-GS is a novel framework for training compact dynamic 3D Gaussians. It uses a two-stage approach: Global Anchor Deformation (GAD) and Local Gaussian Deformation (LGD). GAD handles global motion by deforming a global canonical scaffold. LGD handles finer local motion by explicitly deforming local canonical scaffolds. Temporal Interval Adjustment (TIA) optimizes the temporal segments for efficient representation of the motion, leading to better quality and compact models. The figure illustrates this process.
read the caption
Figure 2: Overview of our MoDec-GS framework. To effectively train dynamic 3D Gaussians with complex motion, we introduce Global-to-Local Motion Decomposition (GLMD) (Sec 4.1). We first train a Global Canonical Scaffold-GS (Global CS) with entire frames, and apply a Global Anchor Deformation (GAD) to Local Canonical Scaffold-GS (Local CS) dedicated to represent its corresponding temporal segment (Sec 4.2). Next, to finely adjust the remaining local motion, we apply Local Gaussian Deformation (LGD) which explicitly deforms the reconstructed 3D Gaussians with a shared hexplane (Sec 4.3). During the training, Temporal Interval Adjustment (TIA) is performed, optimizing the temporal interval into a non-uniform interval that adopts to the scene’s level of motion (Sec 4.4).

🔼 This figure illustrates the two-stage deformation process in MoDec-GS, designed to efficiently handle complex motions of 3D Gaussians. The first stage, global anchor deformation (GAD), deforms the anchor points themselves to capture large-scale movements across time intervals. This is more efficient than deforming individual Gaussians for global motion. The second stage, local Gaussian deformation (LGD), then refines the representation by explicitly deforming individual Gaussians to model smaller, localized movements within each time interval. This two-stage approach allows for a more compact and efficient representation of complex dynamic scenes compared to methods that only model one type of motion.
read the caption
Figure 3: Concept and effect of 2-stage deformation. For representing a complex motion of 3D Gaussians, a global movement over time intervals can be more efficiently handled through deformation of anchor itself. In contrast, subtle motions of individual 3D Gaussians within a time interval can be effectively addressed by explicit deformation of each Gaussian.

🔼 This figure shows a qualitative comparison of novel view synthesis results from three different datasets (iPhone [16], HyperNeRF [45], and Nvidia [58]). For each dataset, several frames from a scene are shown, comparing the ground truth image to results obtained using four different methods: SC-GS [20], Deformable 3DGS [57], 4DGS [54], and the proposed MoDec-GS method. Yellow boxes highlight specific regions where MoDec-GS shows significant visual improvement compared to other methods. Below each frame, the model storage size in megabytes (MB) is provided, demonstrating the memory efficiency of the proposed approach.
read the caption
Figure 4: Qualitative results comparison on three datasets [16, 45, 58]. The yellow boxes highlight areas where the proposed method achieves notable visual quality improvements, and the storage for the corresponding sequence is displayed below each rendered patch.

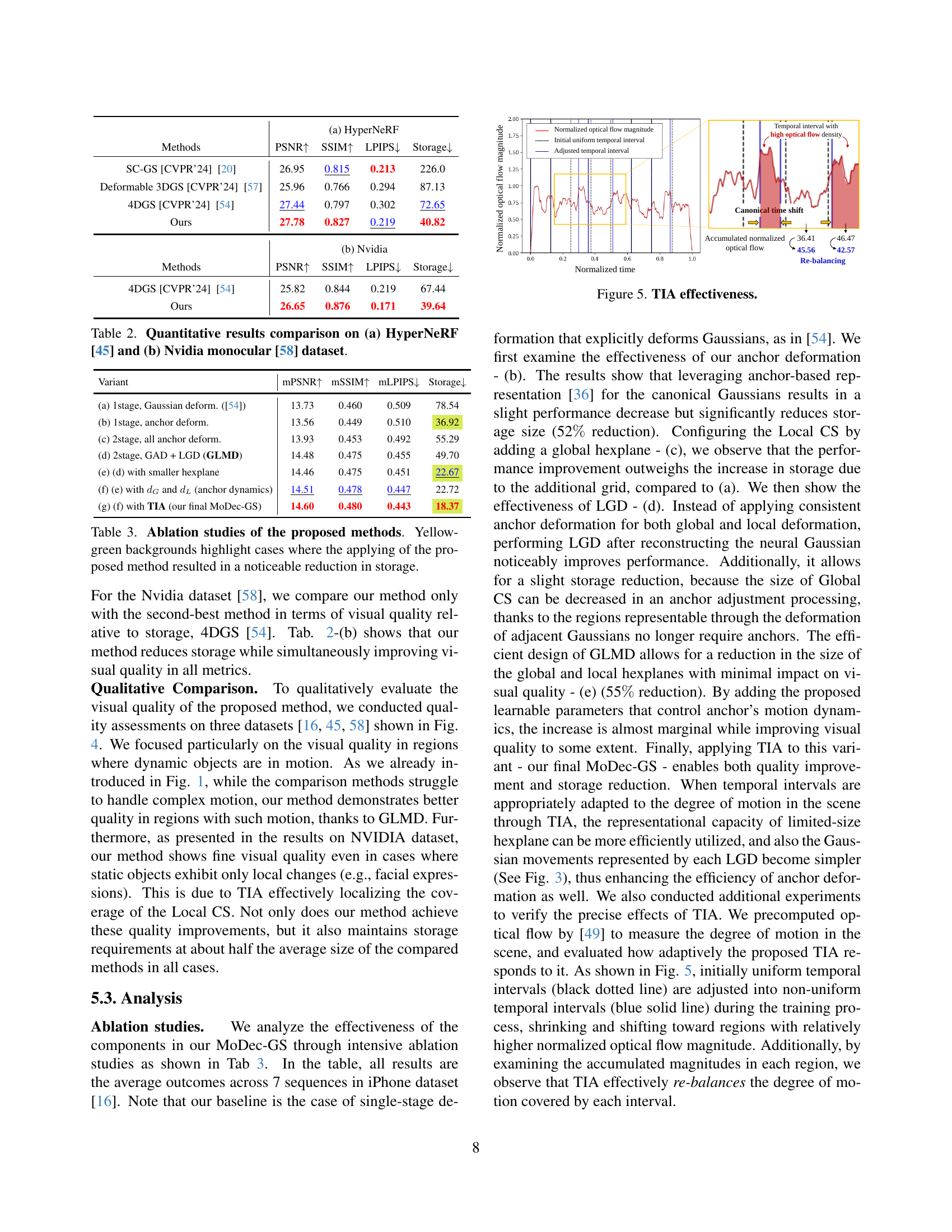
🔼 This figure demonstrates the effectiveness of the Temporal Interval Adjustment (TIA) method. It shows how TIA dynamically adjusts the temporal intervals assigned to local canonical anchors during the training process. The graph plots the normalized magnitude of optical flow against normalized time. The black dotted line represents the initial uniform temporal intervals, while the blue solid line illustrates the adjusted non-uniform intervals. The adjusted intervals are shorter in regions with high optical flow density (i.e., significant motion), reflecting TIA’s ability to focus computational resources on areas with more complex motion.
read the caption
Figure 5: TIA effectiveness.

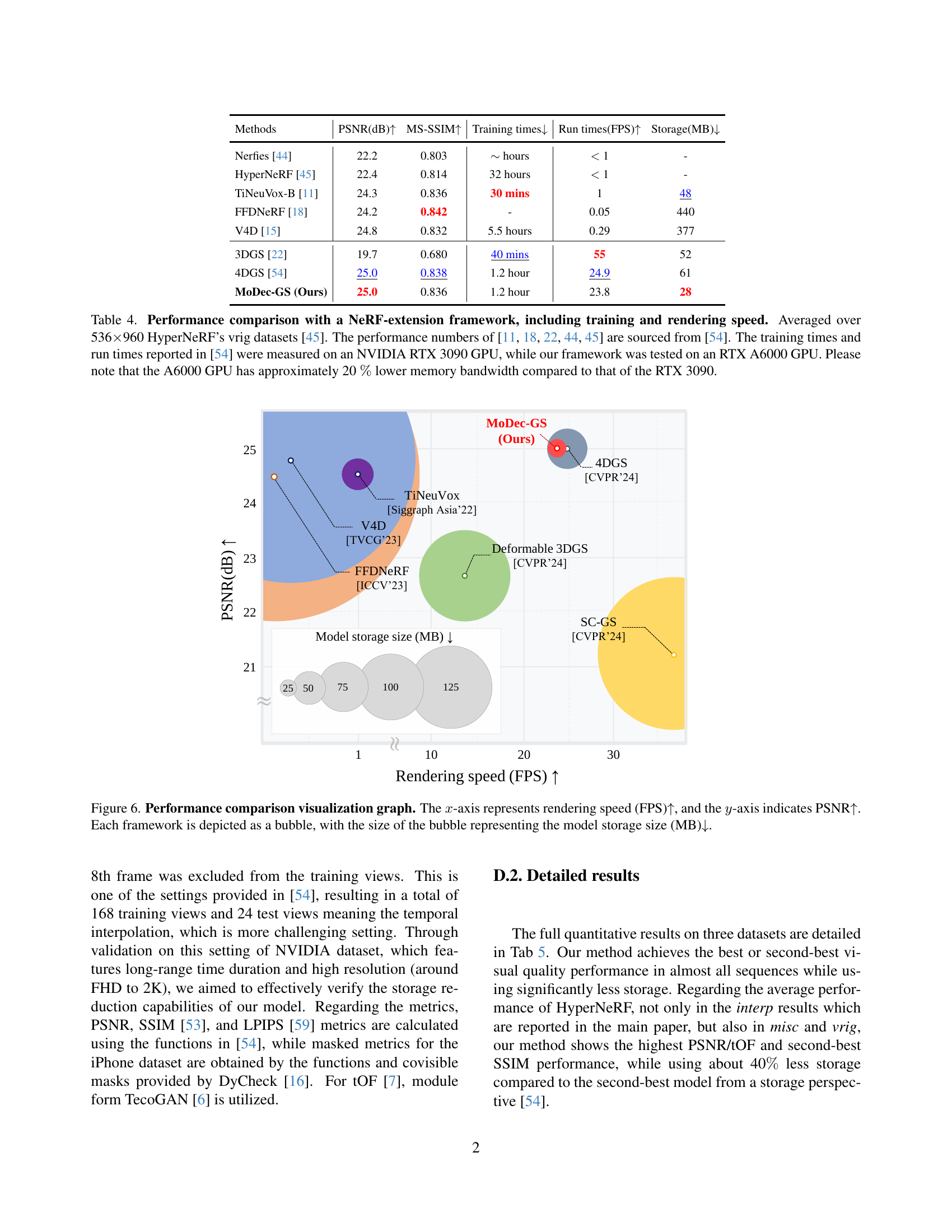
🔼 This figure visualizes the performance of different novel view synthesis (NVS) methods. The x-axis shows rendering speed in frames per second (FPS), and the y-axis represents the peak signal-to-noise ratio (PSNR), a measure of image quality. Each NVS method is represented as a bubble; the bubble’s size corresponds to the model’s storage size in megabytes (MB). This allows for a direct comparison of the trade-off between rendering speed, image quality, and model size for each method.
read the caption
Figure 6: Performance comparison visualization graph. The x𝑥xitalic_x-axis represents rendering speed (FPS)↑↑\uparrow↑, and the y𝑦yitalic_y-axis indicates PSNR↑↑\uparrow↑. Each framework is depicted as a bubble, with the size of the bubble representing the model storage size (MB)↓↓\downarrow↓.

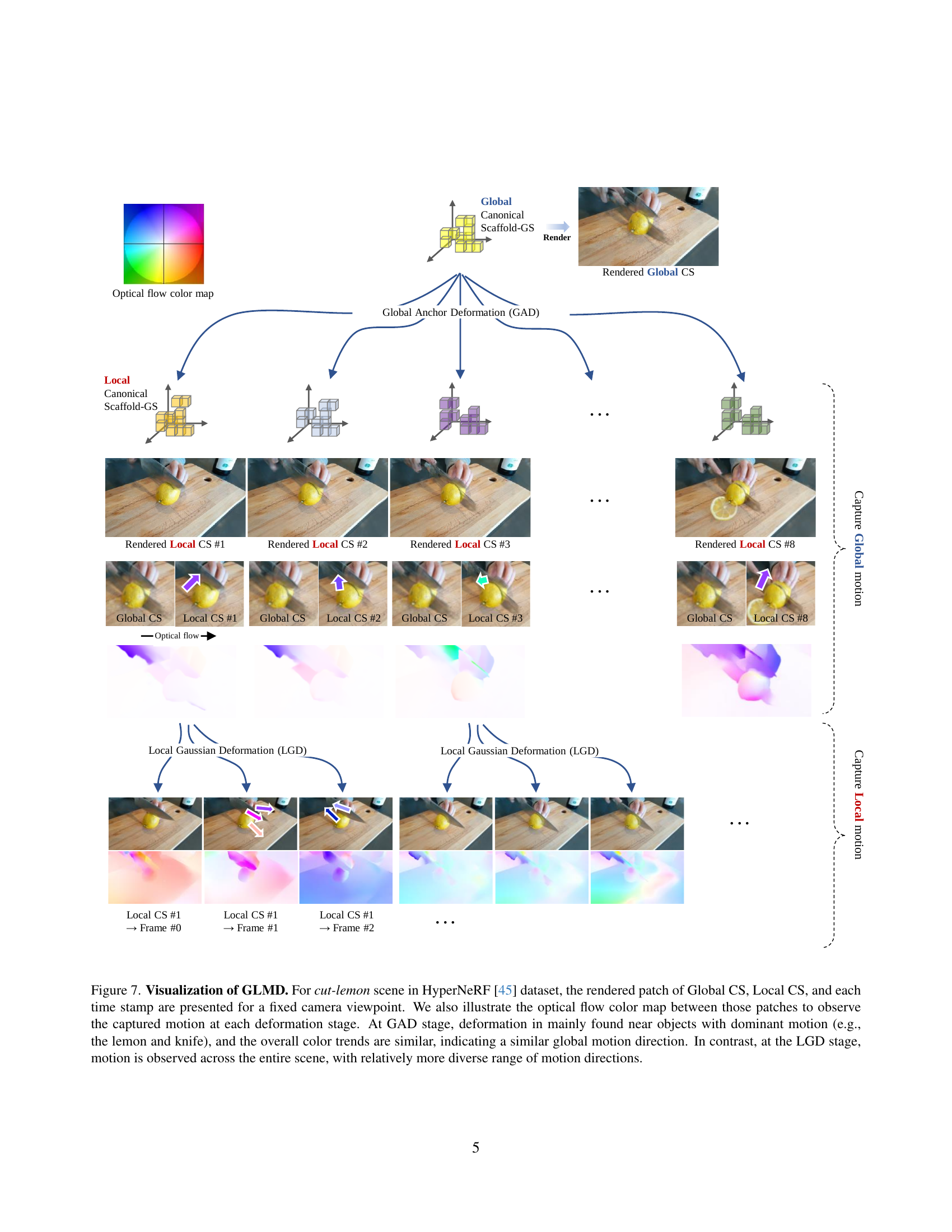
🔼 Figure 7 visualizes the Global-to-Local Motion Decomposition (GLMD) method used in MoDec-GS. It shows the results for the ‘cut-lemon’ scene from the HyperNeRF dataset. For a fixed camera position, it displays the rendered patches from three stages: the Global Canonical Scaffold-GS (Global CS), the Local Canonical Scaffold-GS (Local CS) at multiple timestamps, and the final deformed frame. Optical flow color maps are included between the Global CS and Local CS and between the Local CS and the final frame. The color maps and the rendered patches show that the Global Anchor Deformation (GAD) step primarily deforms the area with significant global motion (lemon and knife), maintaining a similar color trend and flow, while the Local Gaussian Deformation (LGD) step refines the local motions across the whole scene using more diverse color trends and flows.
read the caption
Figure 7: Visualization of GLMD. For cut-lemon scene in HyperNeRF [45] dataset, the rendered patch of Global CS, Local CS, and each time stamp are presented for a fixed camera viewpoint. We also illustrate the optical flow color map between those patches to observe the captured motion at each deformation stage. At GAD stage, deformation in mainly found near objects with dominant motion (e.g., the lemon and knife), and the overall color trends are similar, indicating a similar global motion direction. In contrast, at the LGD stage, motion is observed across the entire scene, with relatively more diverse range of motion directions.
More on tables
| Method | Spin | Teddy | Wheel | Average | ||||
|---|---|---|---|---|---|---|---|---|
| SC-GS [20] | 14.32 / 0.407 / 0.445 | 219.1 | 12.51 / 0.516 / 0.562 | 318.7 | 11.90 / 0.354 / 0.484 | 239.2 | 13.90 / 0.464 / 0.479 | 232.4 |
| Deformable 3DGS [57] | 13.10 / 0.392 / 0.490 | 133.9 | 11.20 / 0.508 / 0.573 | 117.1 | 11.79 / 0.345 / 0.394 | 106.1 | 13.72 / 0.461 / 0.430 | 109.4 |
| 4DGS [54] | 14.89 / 0.413 / 0.441 | 71.80 | 12.31 / 0.509 / 0.605 | 80.44 | 10.83 / 0.339 / 0.538 | 96.50 | 13.72 / 0.460 / 0.509 | 78.54 |
| MoDec-GS (Ours) | 15.53 / 0.433 / 0.366 | 26.84 | 12.56 / 0.521 / 0.598 | 12.28 | 12.44 / 0.374 / 0.413 | 16.68 | 14.60 / 0.480 / 0.443 | 18.37 |
🔼 Table 2 presents a quantitative comparison of the proposed MoDec-GS model against other state-of-the-art methods for dynamic novel view synthesis. It shows the performance on two datasets: (a) HyperNeRF [45], which is a complex dataset known for challenging dynamic scenes, and (b) the Nvidia monocular dataset [58], another widely-used benchmark for evaluating monocular video reconstruction. The metrics used for comparison include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and the model’s storage size in Megabytes (MB). Higher PSNR and SSIM values indicate better visual quality, while a lower LPIPS score signifies that the generated images are perceptually closer to the ground truth. A smaller storage size is preferred as it indicates computational efficiency.
read the caption
Table 2: Quantitative results comparison on (a) HyperNeRF [45] and (b) Nvidia monocular [58] dataset.
| Methods | PSNR ↑ | SSIM ↑ | LPIPS ↓ | Storage ↓ |
|---|---|---|---|---|
| SC-GS [CVPR’24] [20] | 26.95 | 0.815 | 0.213 | 226.0 |
| Deformable 3DGS [CVPR’24] [57] | 25.96 | 0.766 | 0.294 | 87.13 |
| 4DGS [CVPR’24] [54] | 27.44 | 0.797 | 0.302 | 72.65 |
| Ours | 27.78 | 0.827 | 0.219 | 40.82 |
🔼 This table presents the results of ablation studies conducted on the MoDec-GS model. It systematically evaluates the contribution of each component of the model to its overall performance, specifically focusing on storage size reduction. Different model variants are compared, each omitting or modifying a specific component, such as anchor deformation, temporal interval adjustment, or the two-stage deformation process. The table shows the impact of these modifications on key metrics, highlighting the effectiveness of the proposed methods in achieving compact model sizes without sacrificing visual quality. Yellow-green shading indicates where the proposed method resulted in significantly reduced storage.
read the caption
Table 3: Ablation studies of the proposed methods. Yellow-green backgrounds highlight cases where the applying of the proposed method resulted in a noticeable reduction in storage.
| Methods | PSNR ↑ | SSIM ↑ | LPIPS ↓ | Storage ↓ |
|---|---|---|---|---|
| (b) Nvidia | ||||
| 4DGS [CVPR’24] [54] | 25.82 | 0.844 | 0.219 | 67.44 |
| Ours | 26.65 | 0.876 | 0.171 | 39.64 |
🔼 Table 4 presents a performance comparison between MoDec-GS and several other state-of-the-art novel view synthesis (NVS) methods. The comparison specifically focuses on methods that extend NeRFs, evaluating metrics such as PSNR, MS-SSIM, training time, rendering speed (FPS), and model size (storage). The results are averaged across the ‘vrig’ subset of the HyperNeRF dataset [45], using videos with a resolution of 536x960 pixels. It’s important to note that while the performance numbers for the comparison methods were taken from a previous work [54], those results were obtained using an NVIDIA RTX 3090 GPU, whereas MoDec-GS was evaluated on an RTX A6000 GPU. Since the RTX A6000 has approximately 20% lower memory bandwidth, this should be kept in mind when interpreting the results.
read the caption
Table 4: Performance comparison with a NeRF-extension framework, including training and rendering speed. Averaged over 536×\times×960 HyperNeRF’s vrig datasets [45]. The performance numbers of [44, 45, 11, 22, 18] are sourced from [54]. The training times and run times reported in [54] were measured on an NVIDIA RTX 3090 GPU, while our framework was tested on an RTX A6000 GPU. Please note that the A6000 GPU has approximately 20 %percent\%% lower memory bandwidth compared to that of the RTX 3090.
| Variant | mPSNR ↑ | mSSIM ↑ | mLPIPS ↓ | Storage ↓ |
|---|---|---|---|---|
| (a) 1stage, Gaussian deform. ([54]) | 13.73 | 0.460 | 0.509 | 78.54 |
| (b) 1stage, anchor deform. | 13.56 | 0.449 | 0.510 | 36.92 |
| (c) 2stage, all anchor deform. | 13.93 | 0.453 | 0.492 | 55.29 |
| (d) 2stage, GAD + LGD (GLMD) | 14.48 | 0.475 | 0.455 | 49.70 |
| (e) (d) with smaller hexplane | 14.46 | 0.475 | 0.451 | 22.67 |
| (f) (e) with dG and dL (anchor dynamics) | 14.51 | 0.478 | 0.447 | 22.72 |
| (g) (f) with TIA (our final MoDec-GS) | 14.60 | 0.480 | 0.443 | 18.37 |
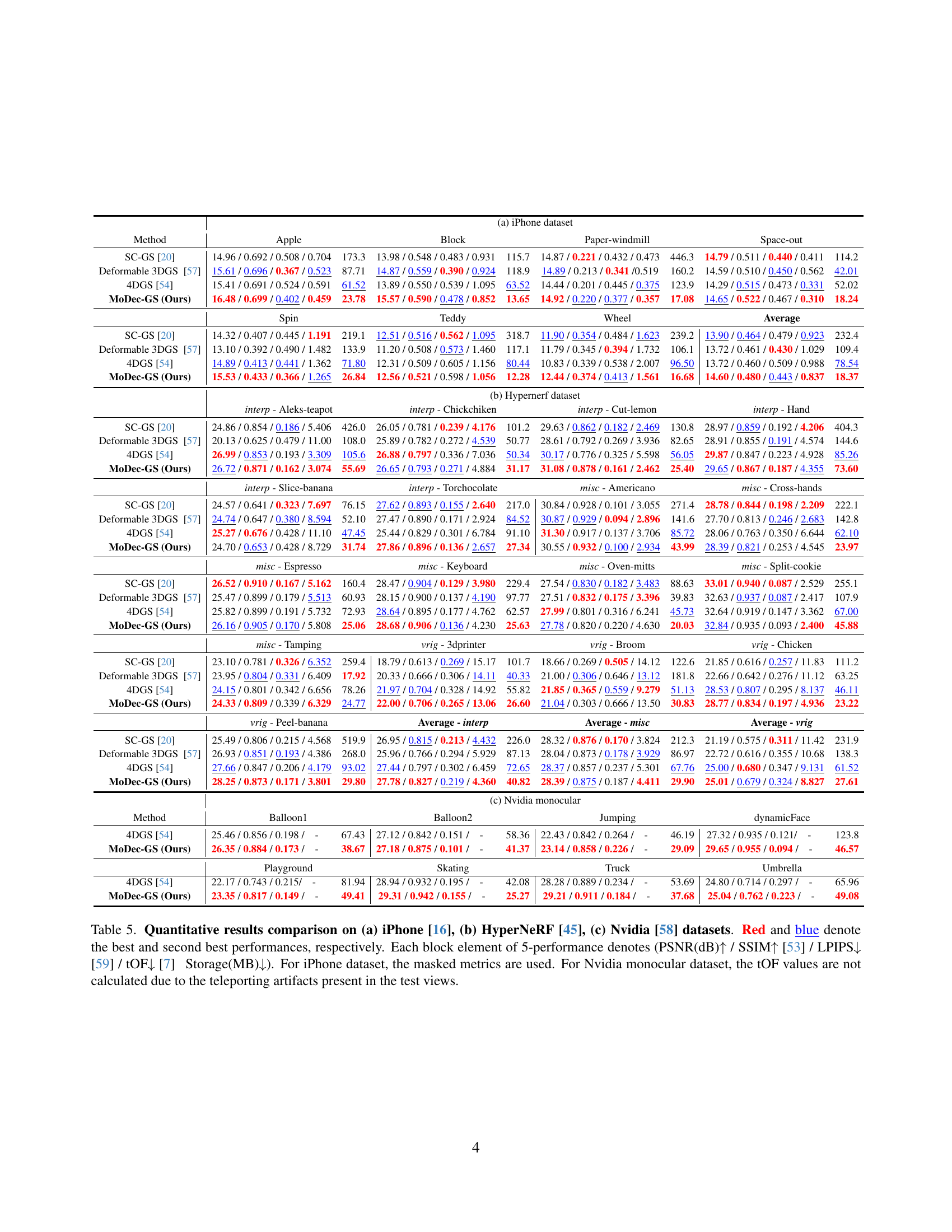
🔼 This table presents a quantitative comparison of different methods for dynamic 3D Gaussian splatting across three datasets: iPhone, HyperNeRF, and Nvidia. The metrics used for comparison include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Temporal Optical Flow (tOF), and model storage size (in MB). The best and second-best performing methods for each metric are highlighted in red and blue, respectively. For the iPhone dataset, masked metrics (considering only co-visible pixels) are reported. Due to the presence of ’teleporting artifacts’ in the Nvidia dataset’s test views, tOF values are not calculated for this dataset.
read the caption
Table 5: Quantitative results comparison on (a) iPhone [16], (b) HyperNeRF [45], (c) Nvidia [58] datasets. Red and blue denote the best and second best performances, respectively. Each block element of 5-performance denotes (PSNR(dB)↑↑\uparrow↑ / SSIM↑↑\uparrow↑ [53] / LPIPS↓↓\downarrow↓ [59] / tOF↓↓\downarrow↓ [7] Storage(MB)↓↓\downarrow↓). For iPhone dataset, the masked metrics are used. For Nvidia monocular dataset, the tOF values are not calculated due to the teleporting artifacts present in the test views.
Full paper#