↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Large multimodal models (LMMs) are powerful but computationally expensive, especially when handling images and videos. Existing efficient LMMs focus on model downsizing, neglecting the crucial issue of excessive vision tokens. This often leads to performance degradation. This limits real-time applications.
LLaVA-Mini tackles this by analyzing how LMMs process visual information, discovering that vision tokens are crucial in early layers. It introduces modality pre-fusion to fuse visual information into text tokens beforehand, allowing extreme compression to just one vision token. This leads to a 77% reduction in FLOPs and 2.9x faster inference speed, while matching state-of-the-art performance on various benchmarks. LLaVA-Mini handles high-resolution images and long videos efficiently, paving the way for low-latency multimodal interactions.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical need for efficient large multimodal models (LMMs), a key challenge in the field of AI. By achieving significant improvements in efficiency and speed, while maintaining comparable performance, LLaVA-Mini opens new avenues for real-time multimodal applications and provides valuable insights into the design of efficient LMMs. The work is particularly relevant given the computational costs associated with existing LMMs. It demonstrates a novel approach to compressing visual information that deserves attention from other researchers developing LMMs.
Visual Insights#

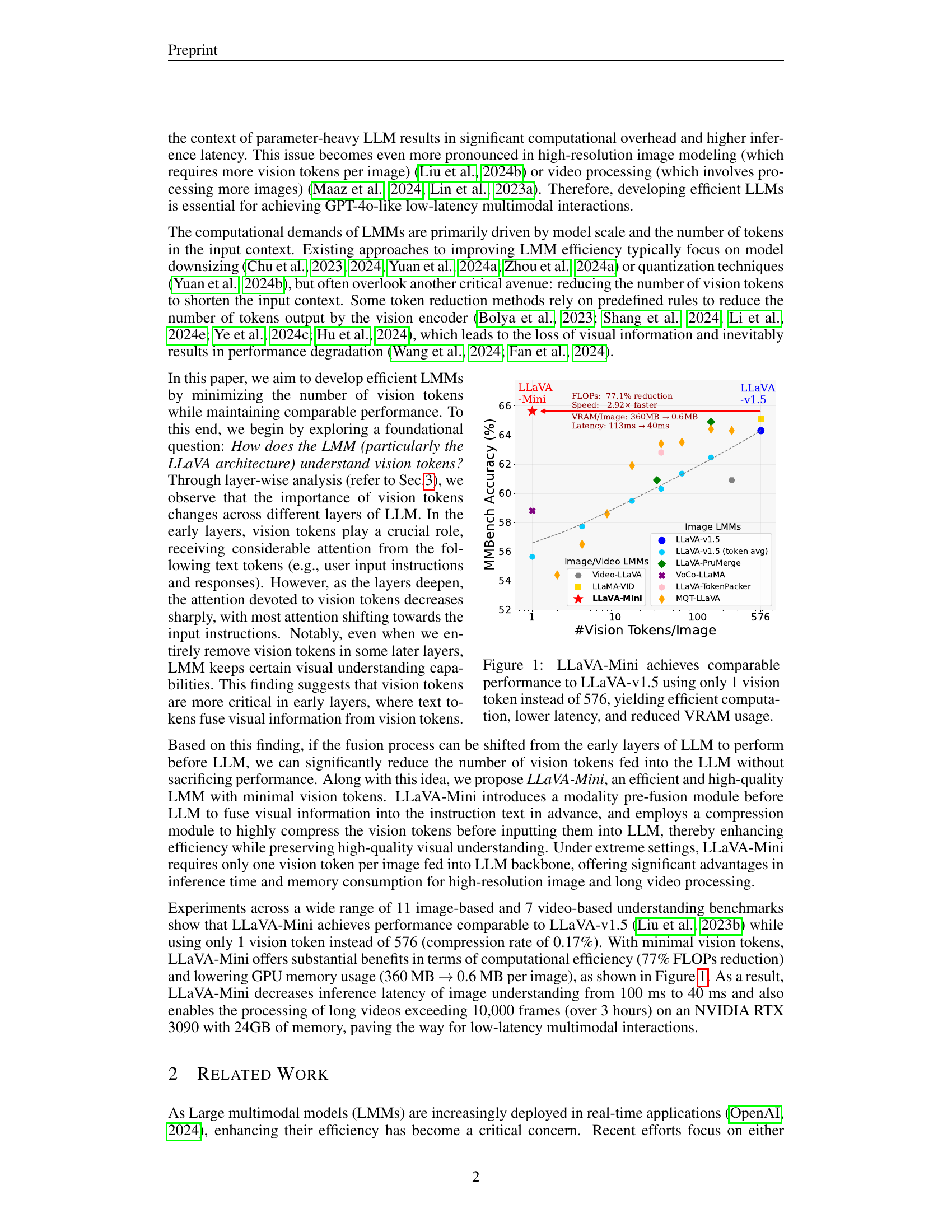
🔼 LLaVA-Mini, a new large multimodal model, achieves performance on par with the existing LLaVA-v1.5 model. The key improvement is its efficiency: LLaVA-Mini uses only one vision token to represent an image, compared to 576 tokens in LLaVA-v1.5. This significant reduction in tokens leads to substantially lower computational costs, faster inference times (lower latency), and reduced memory usage (VRAM). The graph visually depicts this efficiency gain by comparing the performance of LLaVA-Mini against LLaVA-v1.5 across various benchmarks, showing comparable accuracy with drastically reduced resource requirements.
read the caption
Figure 1: LLaVA-Mini achieves comparable performance to LLaVA-v1.5 using only 1 vision token instead of 576, yielding efficient computation, lower latency, and reduced VRAM usage.
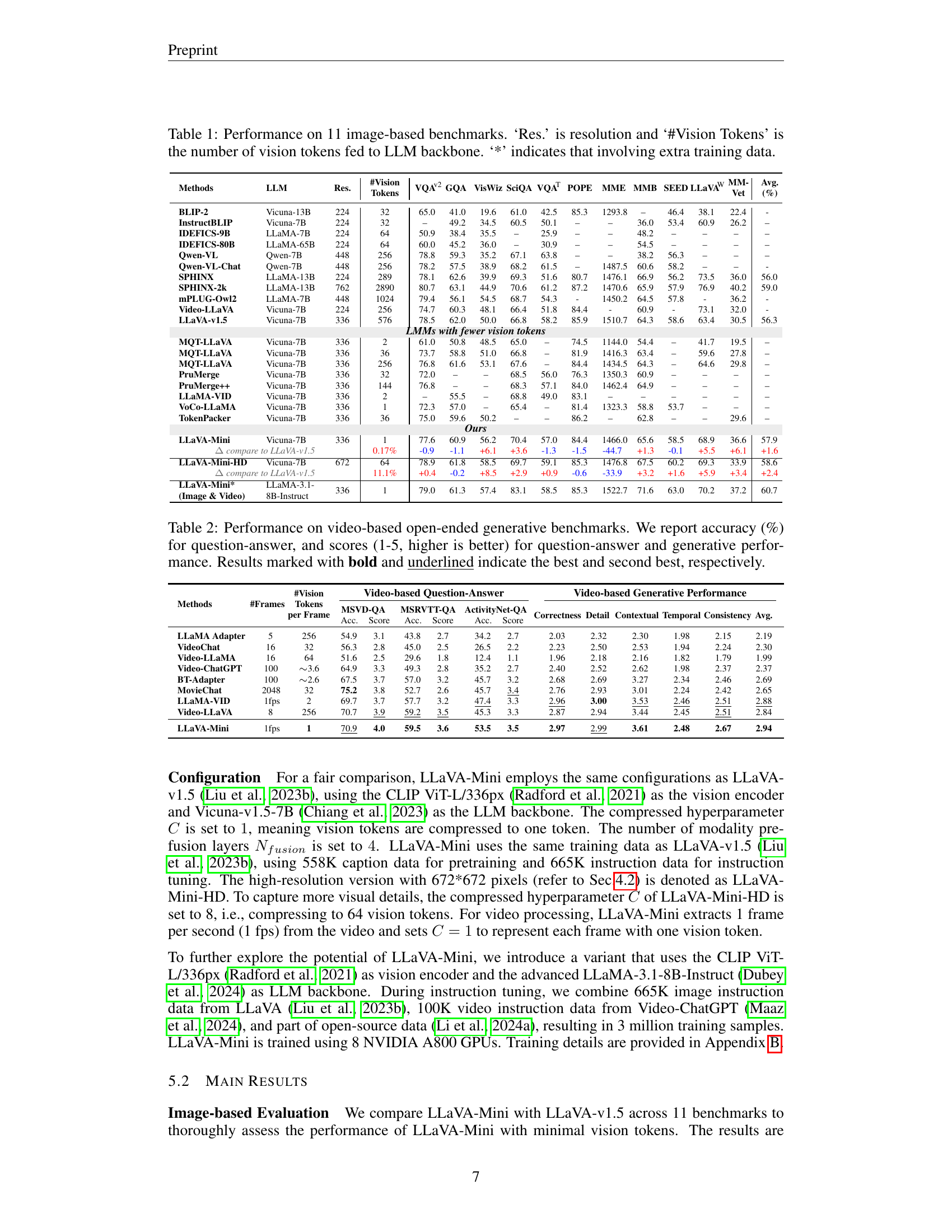
| Methods | LLM | Res. | #Vision | Tokens | VQAv2 | GQA | VisWiz | SciQA | VQAT | POPE | MME | MMB | SEED | LLaVAW | MM-Vet | Avg. (%) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BLIP-2 | Vicuna-13B | 224 | 32 | 65.0 | 41.0 | 19.6 | 61.0 | 42.5 | 85.3 | 1293.8 | - | 46.4 | 38.1 | 22.4 | - | ||
| InstructBLIP | Vicuna-7B | 224 | 32 | - | 49.2 | 34.5 | 60.5 | 50.1 | - | - | 36.0 | 53.4 | 60.9 | 26.2 | - | ||
| IDEFICS-9B | LLaMA-7B | 224 | 64 | 50.9 | 38.4 | 35.5 | - | 25.9 | - | - | - | 48.2 | - | - | - | ||
| IDEFICS-80B | LLaMA-65B | 224 | 64 | 60.0 | 45.2 | 36.0 | - | 30.9 | - | - | - | 54.5 | - | - | - | ||
| Qwen-VL | Qwen-7B | 448 | 256 | 78.8 | 59.3 | 35.2 | 67.1 | 63.8 | - | - | - | 38.2 | 56.3 | - | - | ||
| Qwen-VL-Chat | Qwen-7B | 448 | 256 | 78.2 | 57.5 | 38.9 | 68.2 | 61.5 | - | 1487.5 | 60.6 | 58.2 | - | - | - | ||
| SPHINX | LLaMA-13B | 224 | 289 | 78.1 | 62.6 | 39.9 | 69.3 | 51.6 | 80.7 | 1476.1 | 66.9 | 56.2 | 73.5 | 36.0 | 56.0 | ||
| SPHINX-2k | LLaMA-13B | 762 | 2890 | 80.7 | 63.1 | 44.9 | 70.6 | 61.2 | 87.2 | 1470.6 | 65.9 | 57.9 | 76.9 | 40.2 | 59.0 | ||
| mPLUG-Owl2 | LLaMA-7B | 448 | 1024 | 79.4 | 56.1 | 54.5 | 68.7 | 54.3 | - | 1450.2 | 64.5 | 57.8 | - | 36.2 | - | ||
| Video-LLaVA | Vicuna-7B | 224 | 256 | 74.7 | 60.3 | 48.1 | 66.4 | 51.8 | 84.4 | - | 60.9 | - | 73.1 | 32.0 | - | ||
| LLaVA-v1.5 | Vicuna-7B | 336 | 576 | 78.5 | 62.0 | 50.0 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 | 58.6 | 63.4 | 30.5 | 56.3 | ||
| LMMs with fewer vision tokens | |||||||||||||||||
| MQT-LLaVA | Vicuna-7B | 336 | 2 | 61.0 | 50.8 | 48.5 | 65.0 | - | 74.5 | 1144.0 | 54.4 | - | 41.7 | 19.5 | - | ||
| MQT-LLaVA | Vicuna-7B | 336 | 36 | 73.7 | 58.8 | 51.0 | 66.8 | - | 81.9 | 1416.3 | 63.4 | - | 59.6 | 27.8 | - | ||
| MQT-LLaVA | Vicuna-7B | 336 | 256 | 76.8 | 61.6 | 53.1 | 67.6 | - | 84.4 | 1434.5 | 64.3 | - | 64.6 | 29.8 | - | ||
| PruMerge | Vicuna-7B | 336 | 32 | 72.0 | - | - | 68.5 | 56.0 | 76.3 | 1350.3 | 60.9 | - | - | - | - | ||
| PruMerge++ | Vicuna-7B | 336 | 144 | 76.8 | - | - | 68.3 | 57.1 | 84.0 | 1462.4 | 64.9 | - | - | - | - | ||
| LLaMA-VID | Vicuna-7B | 336 | 2 | - | 55.5 | - | 68.8 | 49.0 | 83.1 | - | - | - | - | - | - | ||
| VoCo-LLaMA | Vicuna-7B | 336 | 1 | 72.3 | 57.0 | - | 65.4 | - | 81.4 | 1323.3 | 58.8 | 53.7 | - | - | - | ||
| TokenPacker | Vicuna-7B | 336 | 36 | 75.0 | 59.6 | 50.2 | - | - | 86.2 | - | 62.8 | - | - | 29.6 | - | ||
| Ours | |||||||||||||||||
| LLaVA-Mini | Vicuna-7B | 336 | 1 | 77.6 | 60.9 | 56.2 | 70.4 | 57.0 | 84.4 | 1466.0 | 65.6 | 58.5 | 68.9 | 36.6 | 57.9 | ||
| Δ compare to LLaVA-v1.5 | 0.17% | -0.9 | -1.1 | +6.1 | +3.6 | -1.3 | -1.5 | -44.7 | +1.3 | -0.1 | +5.5 | +6.1 | +1.6 | ||||
| LLaVA-Mini-HD | Vicuna-7B | 672 | 64 | 78.9 | 61.8 | 58.5 | 69.7 | 59.1 | 85.3 | 1476.8 | 67.5 | 60.2 | 69.3 | 33.9 | 58.6 | ||
| Δ compare to LLaVA-v1.5 | 11.1% | +0.4 | -0.2 | +8.5 | +2.9 | +0.9 | -0.6 | -33.9 | +3.2 | +1.6 | +5.9 | +3.4 | +2.4 | ||||
| LLaVA-Mini* (Image & Video) | LLaMA-3.1-8B-Instruct | 336 | 1 | 79.0 | 61.3 | 57.4 | 83.1 | 58.5 | 85.3 | 1522.7 | 71.6 | 63.0 | 70.2 | 37.2 | 60.7 |
🔼 This table presents a comparison of different large multimodal models (LMMs) on eleven image-based benchmarks. The benchmarks evaluate various aspects of visual understanding. Key metrics include the model’s accuracy on each benchmark, the resolution of images used (‘Res.’), and the number of vision tokens processed by the large language model (LLM) backbone (’#Vision Tokens’). The asterisk (*) indicates that additional training data was used for that specific model. The table allows for an assessment of the trade-off between model performance and computational efficiency in the context of different LLM architectures.
read the caption
Table 1: Performance on 11 image-based benchmarks. ‘Res.’ is resolution and ‘#Vision Tokens’ is the number of vision tokens fed to LLM backbone. ‘*’ indicates that involving extra training data.
In-depth insights#
Vision Token Compression#
Vision token compression, a crucial aspect of efficient large multimodal models (LMMs), seeks to reduce the computational burden associated with processing numerous visual tokens. The core idea revolves around minimizing the number of tokens representing visual information while preserving crucial visual details. This is challenging because a simple reduction in token count can lead to significant information loss and degraded model performance. Effective compression strategies must strike a balance between achieving high compression ratios and maintaining visual understanding capabilities. One approach, as seen in the paper, uses a query-based compression module. This module employs learnable compression queries that selectively extract essential visual information, resulting in a significantly smaller number of compressed tokens. Another key aspect, mentioned in the paper, is modality pre-fusion. This technique fuses visual information with textual information before the compressed tokens are fed into the large language model (LLM). This pre-fusion step is critical as it helps prevent information loss during the compression process. Together, compression and pre-fusion enable LMMs to maintain robust visual understanding with drastically fewer visual tokens, resulting in improved efficiency and faster inference times, making real-time multimodal interactions more feasible. The trade-off between compression ratio and performance is a critical design consideration. Further research should explore optimizing compression algorithms to achieve even higher compression ratios while minimizing performance degradation.
Modality Pre-fusion#
The concept of “Modality Pre-fusion” presented in the research paper is a significant contribution to efficient large multimodal models (LMMs). It directly addresses the computational bottleneck caused by the numerous vision tokens typically fed into the language model. Instead of compressing vision tokens after they’ve been processed by a vision encoder, modality pre-fusion fuses visual information with text tokens before the LLM receives them. This pre-fusion step allows for extreme compression of the vision tokens, significantly reducing the computational overhead associated with LMMs. The key insight here is the observation that vision tokens are most important in early layers of the LLM, where visual and textual information are initially fused. By shifting this fusion process to occur beforehand, the research effectively minimizes the number of vision tokens needed for maintaining strong performance. This is a paradigm shift from traditional methods that focused on compressing tokens after vision encoding and provides strong efficiency gains. The method’s effectiveness is demonstrated by achieving comparable performance to existing models with significantly fewer visual tokens and substantial reductions in FLOPs and latency. The success of modality pre-fusion highlights the importance of understanding the internal workings of LLMs and exploiting architectural features to enhance efficiency without compromising accuracy.
Efficiency Gains#
The research paper highlights significant efficiency gains achieved through the proposed method. Reducing the number of vision tokens dramatically lowers computational overhead, a major bottleneck in large multimodal models. The use of a single vision token is a bold demonstration of extreme compression, exceeding previous efforts. This efficiency isn’t solely due to token reduction; a modality pre-fusion module intelligently integrates visual information into text tokens beforehand, further optimizing the LLM’s processing. The combined effect leads to substantial reductions in FLOPs and inference latency, enabling real-time performance on resource-constrained hardware. Furthermore, memory usage is significantly decreased, allowing for the processing of exceptionally long videos. The results showcase a trade-off between efficiency and performance, demonstrating that comparable accuracy can be maintained while achieving substantial efficiency gains. This suggests a viable path toward deploying advanced multimodal models in resource-limited environments.
High-Res & Video#
The section on “High-Res & Video” would delve into the paper’s approach to handling high-resolution images and video data, a crucial aspect of efficient large multimodal models (LMMs). It would likely discuss the challenges posed by the increased computational cost and memory requirements associated with processing high-resolution inputs. The authors probably address this by proposing techniques to compress visual information effectively, perhaps employing efficient encoding schemes or selective attention mechanisms. A key aspect would be how these methods maintain accuracy while reducing resource usage. Specifically, the approach for video processing is likely outlined, perhaps involving techniques like frame sampling or temporal feature aggregation to mitigate the computational burden of processing lengthy video sequences. The effectiveness of these methods should be evaluated against established benchmarks in image and video understanding, highlighting the model’s capability to achieve high performance with significantly improved efficiency compared to existing LMMs. Benchmark results and efficiency gains in terms of speed, FLOPs, and memory usage are key elements to assess the impact of the proposed techniques.
Future Works#
Future work could explore several promising directions. Improving the efficiency of the modality pre-fusion module is crucial; while effective, it adds computational overhead. Investigating alternative fusion methods, or optimizing the existing one, could significantly boost performance and reduce latency. Extending LLaVA-Mini to handle more complex modalities beyond image and video, such as audio or 3D point clouds, is another valuable area. This would broaden the applications and capabilities of the model. Further exploration of different LLM backbones is warranted to determine the optimal architecture for LLaVA-Mini and how backbone choice affects its performance and efficiency. A thorough analysis of the model’s limitations needs to be undertaken. Identifying specific scenarios or datasets where the model performs suboptimally will guide the development of improved techniques and data augmentation strategies. Finally, investigating different quantization methods and other model compression techniques will be important for deploying LLaVA-Mini on resource-constrained devices. This would open up its use to mobile and edge applications, expanding its practical impact considerably.
More visual insights#
More on figures

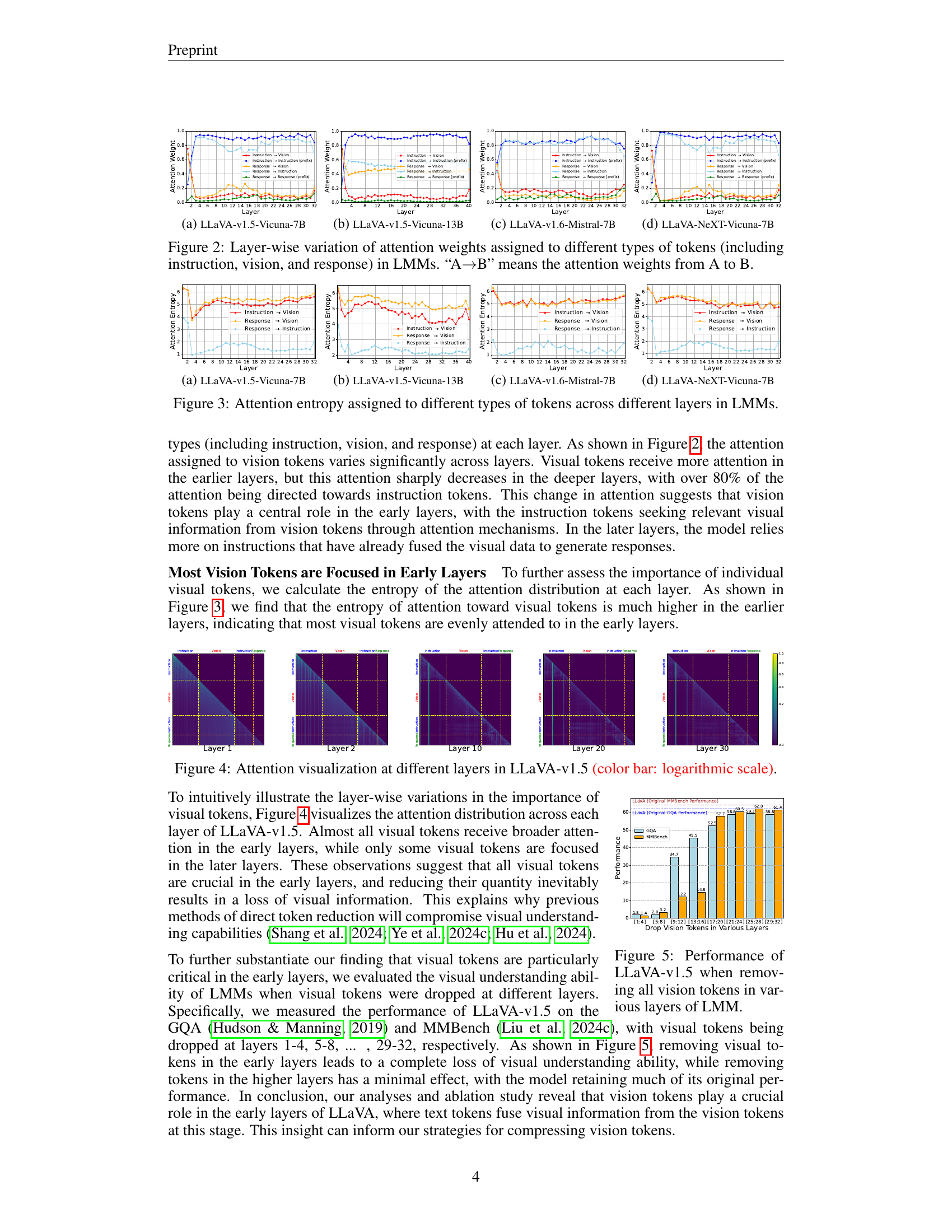
🔼 Figure 2(a) displays the layer-wise attention weights assigned to different token types (instruction, vision, and response) in the LLaVA-v1.5-Vicuna-7B model. The attention weight from one token type to another is shown, revealing how the model’s focus shifts between these token types as the layers progress. The visualization shows that vision tokens receive significant attention in earlier layers, where visual information is integrated into text tokens. However, the attention given to vision tokens decreases as the layers deepen.
read the caption
(a) LLaVA-v1.5-Vicuna-7B

🔼 Figure 3(b) presents a graph illustrating the attention entropy across different layers in the LLaMA-13B language model within the LLaVA-v1.5 architecture. Attention entropy, a measure of attention distribution, is plotted for three token types: instructions, vision tokens, and responses. The graph shows how the attention weight given to vision tokens decreases significantly as the model processes information through deeper layers, while attention to instruction tokens increases. This visualization helps to understand the role of vision tokens at different stages of language model processing within a multimodal architecture.
read the caption
(b) LLaVA-v1.5-Vicuna-13B

🔼 Figure 3(c) presents a graph illustrating the attention entropy assigned to different token types (instruction, vision, and response) across various layers within the LLaMA-v1.6-Mistral-7B large language model. Attention entropy measures the distribution of attention weights, providing insights into which token type is most crucial at different processing stages. The graph allows for a layer-wise comparison of the importance of visual information relative to textual instructions and responses, highlighting the dynamic shift in attention weights during the processing of multimodal information.
read the caption
(c) LLaVA-v1.6-Mistral-7B

🔼 Figure 3(d) presents the attention entropy assigned to different token types across various layers within the LLaVA-NeXT-Vicuna-7B model. Attention entropy measures the uncertainty or randomness in the attention distribution. High entropy indicates that attention is spread more evenly across different tokens, while low entropy indicates that attention is concentrated on a smaller subset of tokens. The plot shows how the entropy of attention weights for instruction, vision, and response tokens changes across different layers of the LLM. This visualization helps understand how the model processes and integrates visual and textual information at different stages of its reasoning process.
read the caption
(d) LLaVA-NeXT-Vicuna-7B

🔼 This figure visualizes how the attention mechanism in Large Multimodal Models (LMMs) distributes attention across different token types (instruction, vision, and response) at various layers of the model. The graphs show that vision tokens receive considerably more attention in the early layers of the LMM, indicating their crucial role in the initial stages of visual information processing. As the model progresses through deeper layers, the attention shifts towards instruction tokens and then response tokens, reflecting the flow of information processing within the LMM. Different line styles and colors represent different LMM configurations.
read the caption
Figure 2: Layer-wise variation of attention weights assigned to different types of tokens (including instruction, vision, and response) in LMMs. “A→→\rightarrow→B” means the attention weights from A to B.

🔼 Figure 3(a) presents a detailed layer-wise analysis of attention weights in the LLaVA-v1.5-Vicuna-7B multimodal model. It illustrates the distribution of attention across different token types (instruction, vision, and response) at various layers of the LLM. This visualization helps understand how the model’s reliance on visual information changes as processing progresses through the layers. The figure shows that vision tokens are heavily attended to in the early layers where visual information is initially fused with textual information. However, their importance decreases significantly in later layers, indicating that the crucial role of vision tokens is primarily in the initial integration process.
read the caption
(a) LLaVA-v1.5-Vicuna-7B

🔼 Figure 3(b) shows the attention entropy assigned to different types of tokens (instruction, vision, and response) across various layers in the LLaVA-v1.5-Vicuna-13B model. Attention entropy measures the distribution of attention weights across different tokens within each layer. A higher entropy indicates more even distribution of attention across tokens, while a lower entropy means attention is concentrated on a few tokens. This figure helps to visualize how the importance of vision tokens changes across layers of the LLM, showing that vision tokens are more important in earlier layers and less crucial in later layers, implying that the fusion of vision and text information happens predominantly in the initial layers.
read the caption
(b) LLaVA-v1.5-Vicuna-13B

🔼 Figure 3(c) presents a detailed visualization of attention entropy across different layers of the LLaVA-v1.6-Mistral-7B model. Attention entropy, a measure of attention distribution across different tokens, illustrates the importance of various tokens (instructions, vision tokens, and responses) at different processing stages. The figure allows for insights into the role of vision tokens in the LLM’s understanding process across various layers. It indicates the relative weighting and focus on the different token types in different layers of the model.
read the caption
(c) LLaVA-v1.6-Mistral-7B

🔼 This figure shows the layer-wise attention weight distribution across different token types (instruction, vision, and response) in the LLaVA-NeXT-Vicuna-7B model. The attention weights illustrate how the model’s focus on visual information changes across different layers of the LLM. It visualizes the relative importance of vision tokens at different processing stages during the understanding of image and text inputs.
read the caption
(d) LLaVA-NeXT-Vicuna-7B

🔼 This figure visualizes the entropy of attention weights assigned to different token types (instruction, vision, and response) across various layers of four different Large Multimodal Models (LMMs). Attention entropy measures the distribution of attention across tokens within each layer. A high entropy indicates that attention is distributed relatively evenly across all tokens of that type, while a low entropy indicates that attention is focused on only a few tokens. The graphs show that the attention entropy for vision tokens is much higher in the earlier layers, indicating vision tokens are more evenly attended to in early layers. As the layer number increases, the attention weight shifts to instruction tokens. This suggests vision tokens play a crucial role in fusing visual information with text in the early layers of the LLM.
read the caption
Figure 3: Attention entropy assigned to different types of tokens across different layers in LMMs.

🔼 This figure visualizes the attention weights assigned to different vision tokens across various layers of the LLaVA-v1.5 model. The color intensity in each heatmap represents the attention weight (logarithmic scale), showing how much attention each layer gives to individual vision tokens. It demonstrates that in the early layers, almost all vision tokens receive a high level of attention, whereas in later layers, attention focuses on fewer, specific tokens. This visualization helps to explain why removing vision tokens has a more significant impact in the initial layers.
read the caption
Figure 4: Attention visualization at different layers in LLaVA-v1.5 (color bar: logarithmic scale).

🔼 This figure displays the performance of the LLaVA-v1.5 model on the GQA and MMBench datasets when vision tokens are removed from different layers of the large language model (LLM). It demonstrates how the importance of vision tokens varies across different layers of the LLM. Removing tokens from early layers results in a significant drop in performance, indicating that vision tokens are more critical in those initial layers for fusing visual information into textual representations.
read the caption
Figure 5: Performance of LLaVA-v1.5 when removing all vision tokens in various layers of LMM.

🔼 LLaVA-Mini is an efficient large multimodal model that uses only one vision token to represent each image. The figure’s left side shows a high-level overview of this architecture. The right side provides a detailed breakdown of the proposed query-based compression module and the modality pre-fusion module. The compression module reduces the number of vision tokens, while the pre-fusion module integrates visual information into text tokens before they reach the LLM backbone, which significantly enhances the model’s efficiency without sacrificing performance.
read the caption
Figure 6: Architecture of LLaVA-Mini. Left: LLaVA-Mini represents each image with one vision token. Right: Detailed view of the proposed query-based compression and modality pre-fusion.

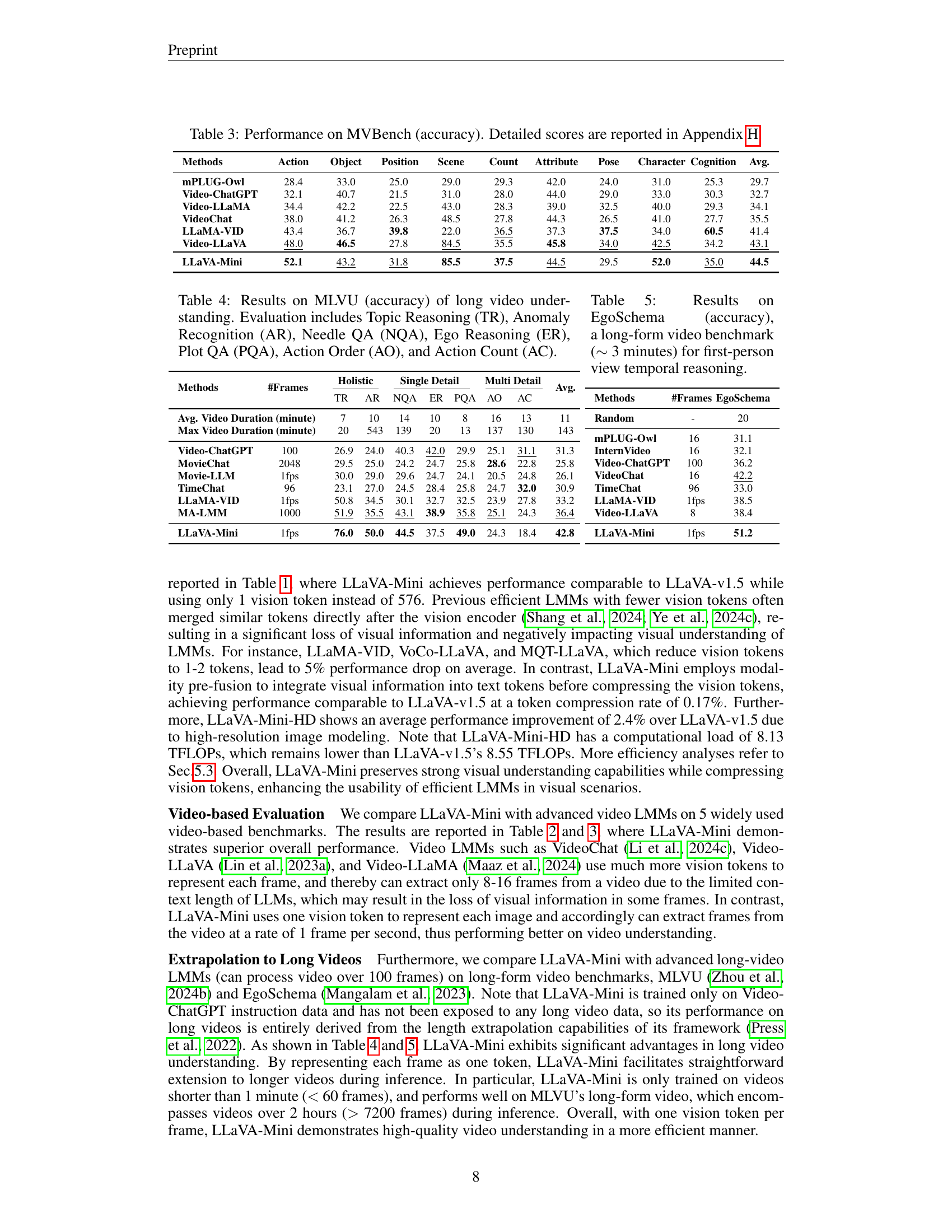
🔼 This table presents the performance of different models on the MLVU benchmark for long video understanding. MLVU assesses various aspects of video comprehension, including the ability to reason about topics (TR), identify anomalies (AR), answer questions requiring detailed information (Needle QA, NQA), understand first-person perspectives (Ego Reasoning, ER), comprehend plot details (Plot QA, PQA), determine the order of events (Action Order, AO), and count actions (Action Count, AC). The results show the accuracy achieved by each model on these distinct subtasks. Higher scores indicate better performance in understanding the nuances of long videos.
read the caption
Table 4: Results on MLVU (accuracy) of long video understanding. Evaluation includes Topic Reasoning (TR), Anomaly Recognition (AR), Needle QA (NQA), Ego Reasoning (ER), Plot QA (PQA), Action Order (AO), and Action Count (AC).

🔼 Table 5 presents the performance evaluation results of various models on the EgoSchema benchmark. EgoSchema is a challenging dataset designed for evaluating long-form video understanding, specifically focusing on temporal reasoning within first-person perspective videos (approximately 3 minutes long). The table shows the accuracy of different models in performing this task, highlighting the relative strengths and weaknesses of each model in understanding and reasoning about the temporal aspects of first-person videos. The performance is measured as accuracy, indicating the proportion of correctly answered questions.
read the caption
Table 5: Results on EgoSchema (accuracy), a long-form video benchmark (∼similar-to\sim∼ 3 minutes) for first-person view temporal reasoning.

🔼 This figure shows the computational efficiency and speed improvements of LLaVA-Mini compared to LLaVA-v1.5. It displays a significant reduction in FLOPs (floating-point operations) and a substantial decrease in inference latency (response time) for LLaVA-Mini, highlighting its efficiency in processing images.
read the caption
Figure 7: FLOPs and latency of LLaVA-Mini.

🔼 This figure shows the computational efficiency of LLaVA-Mini-HD, a variant of LLaVA-Mini designed for high-resolution images. It presents a comparison of FLOPs (floating-point operations) and inference latency (the time it takes to get a result) between LLaVA-Mini-HD and LLaVA-v1.5, a previous model. The x-axis likely represents different numbers of vision tokens, while the y-axis shows both FLOPs and latency, demonstrating how LLaVA-Mini-HD achieves significantly fewer FLOPs and lower latency, especially as the number of vision tokens increases. This highlights the efficiency gains achieved through the model’s unique design.
read the caption
Figure 8: FLOPs and latency of LLaVA-Mini-HD.

🔼 This figure compares the GPU memory usage of LLaVA-Mini against several other video LLMs when processing a 3-hour long video. It demonstrates LLaVA-Mini’s significant memory efficiency. While other models struggle with memory constraints, even on high-end GPUs with 40GB of VRAM, LLaVA-Mini efficiently processes the video on a 24GB GPU thanks to its minimal vision token usage, showcasing its suitability for real-time applications with long videos.
read the caption
Figure 9: VRAM usage (3-hour video) of LLaVA-Mini.

🔼 This table presents the results of experiments conducted to evaluate the impact of varying the number of modality pre-fusion layers in the LLaVA-Mini model. The modality pre-fusion module is a key component of LLaVA-Mini, designed to integrate visual and textual information effectively before feeding it into the main language model. The table shows how changes in the number of pre-fusion layers affect model performance across different metrics (e.g., VQAv2, GQA, and MMB). This allows researchers to determine the optimal number of layers to balance performance and computational cost.
read the caption
Table 6: Performance of LLaVA-Mini with different numbers of modality pre-fusion layers Nfusionsubscript𝑁𝑓𝑢𝑠𝑖𝑜𝑛N_{fusion}italic_N start_POSTSUBSCRIPT italic_f italic_u italic_s italic_i italic_o italic_n end_POSTSUBSCRIPT.

🔼 This table presents a comparison of LLaVA-Mini’s performance using different numbers of vision tokens. It shows how varying the number of vision tokens affects the model’s accuracy on three benchmark tasks (VQAV2, GQA, and MMB). This allows for an analysis of the trade-off between efficiency (fewer tokens) and performance.
read the caption
Table 7: Performance of LLaVA-Mini with various vision tokens.
More on tables
| #Vision | |
|---|---|
| Tokens |
🔼 This table presents the performance of various large multimodal models (LMMs) on video-based open-ended generative benchmarks. It evaluates both question-answering accuracy (percentage) and a 1-5 rating for both question-answering quality and overall generative performance. The best and second-best results for each metric are highlighted in bold and underlined.
read the caption
Table 2: Performance on video-based open-ended generative benchmarks. We report accuracy (%) for question-answer, and scores (1-5, higher is better) for question-answer and generative performance. Results marked with bold and underlined indicate the best and second best, respectively.
| Methods | #Frames | #VisionTokensper Frame | Video-based Question-Answer | Video-based Question-Answer | Video-based Question-Answer | Video-based Generative Performance | Video-based Generative Performance | Video-based Generative Performance | Video-based Generative Performance | Video-based Generative Performance | Avg. | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA Adapter | 5 | 256 | 54.9 | 3.1 | 43.8 | 2.7 | 34.2 | 2.7 | 2.03 | 2.32 | 2.30 | 1.98 | 2.15 | 2.19 | ||
| VideoChat | 16 | 32 | 56.3 | 2.8 | 45.0 | 2.5 | 26.5 | 2.2 | 2.23 | 2.50 | 2.53 | 1.94 | 2.24 | 2.30 | ||
| Video-LLaMA | 16 | 64 | 51.6 | 2.5 | 29.6 | 1.8 | 12.4 | 1.1 | 1.96 | 2.18 | 2.16 | 1.82 | 1.79 | 1.99 | ||
| Video-ChatGPT | 100 | ~3.6 | 64.9 | 3.3 | 49.3 | 2.8 | 35.2 | 2.7 | 2.40 | 2.52 | 2.62 | 1.98 | 2.37 | 2.37 | ||
| BT-Adapter | 100 | ~2.6 | 67.5 | 3.7 | 57.0 | 3.2 | 45.7 | 3.2 | 2.68 | 2.69 | 3.27 | 2.34 | 2.46 | 2.69 | ||
| MovieChat | 2048 | 32 | 75.2 | 3.8 | 52.7 | 2.6 | 45.7 | 3.4 | 2.76 | 2.93 | 3.01 | 2.24 | 2.42 | 2.65 | ||
| LLaMA-VID | 1fps | 2 | 69.7 | 3.7 | 57.7 | 3.2 | 47.4 | 3.3 | 2.96 | 3.00 | 3.53 | 2.46 | 2.51 | 2.88 | ||
| Video-LLaVA | 8 | 256 | 70.7 | 3.9 | 59.2 | 3.5 | 45.3 | 3.3 | 2.87 | 2.94 | 3.44 | 2.45 | 2.51 | 2.84 | ||
| LLaVA-Mini | 1fps | 1 | 70.9 | 4.0 | 59.5 | 3.6 | 53.5 | 3.5 | 2.97 | 2.99 | 3.61 | 2.48 | 2.67 | 2.94 |
🔼 This table presents the performance of different large multimodal models (LLMs) on the MVBench benchmark, which evaluates various aspects of video understanding capabilities. The accuracy of each model is shown across 20 sub-tasks of MVBench, including action recognition, object detection, scene understanding, and others. The table helps compare the overall performance of the models on video understanding and analyze their strengths and weaknesses in different sub-tasks. Detailed scores are provided in Appendix H of the paper.
read the caption
Table 3: Performance on MVBench (accuracy). Detailed scores are reported in Appendix H.
| Methods | Action | Object | Position | Scene | Count | Attribute | Pose | Character | Cognition | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| mPLUG-Owl | 28.4 | 33.0 | 25.0 | 29.0 | 29.3 | 42.0 | 24.0 | 31.0 | 25.3 | 29.7 |
| Video-ChatGPT | 32.1 | 40.7 | 21.5 | 31.0 | 28.0 | 44.0 | 29.0 | 33.0 | 30.3 | 32.7 |
| Video-LLaMA | 34.4 | 42.2 | 22.5 | 43.0 | 28.3 | 39.0 | 32.5 | 40.0 | 29.3 | 34.1 |
| VideoChat | 38.0 | 41.2 | 26.3 | 48.5 | 27.8 | 44.3 | 26.5 | 41.0 | 27.7 | 35.5 |
| LLaMA-VID | 43.4 | 36.7 | 39.8 | 22.0 | 36.5 | 37.3 | 37.5 | 34.0 | 60.5 | 41.4 |
| Video-LLaVA | 48.0 | 46.5 | 27.8 | 84.5 | 35.5 | 45.8 | 34.0 | 42.5 | 34.2 | 43.1 |
| LLaVA-Mini | 52.1 | 43.2 | 31.8 | 85.5 | 37.5 | 44.5 | 29.5 | 52.0 | 35.0 | 44.5 |
🔼 This table compares the performance of LLaVA-Mini using query-based compression against average pooling for compressing vision tokens. It shows the impact of different compression methods on visual question answering tasks using the VQA, GQA, and MMBench datasets. The results highlight the effectiveness of query-based compression in balancing performance and computational cost.
read the caption
Table 8: Effect of query-based compression.
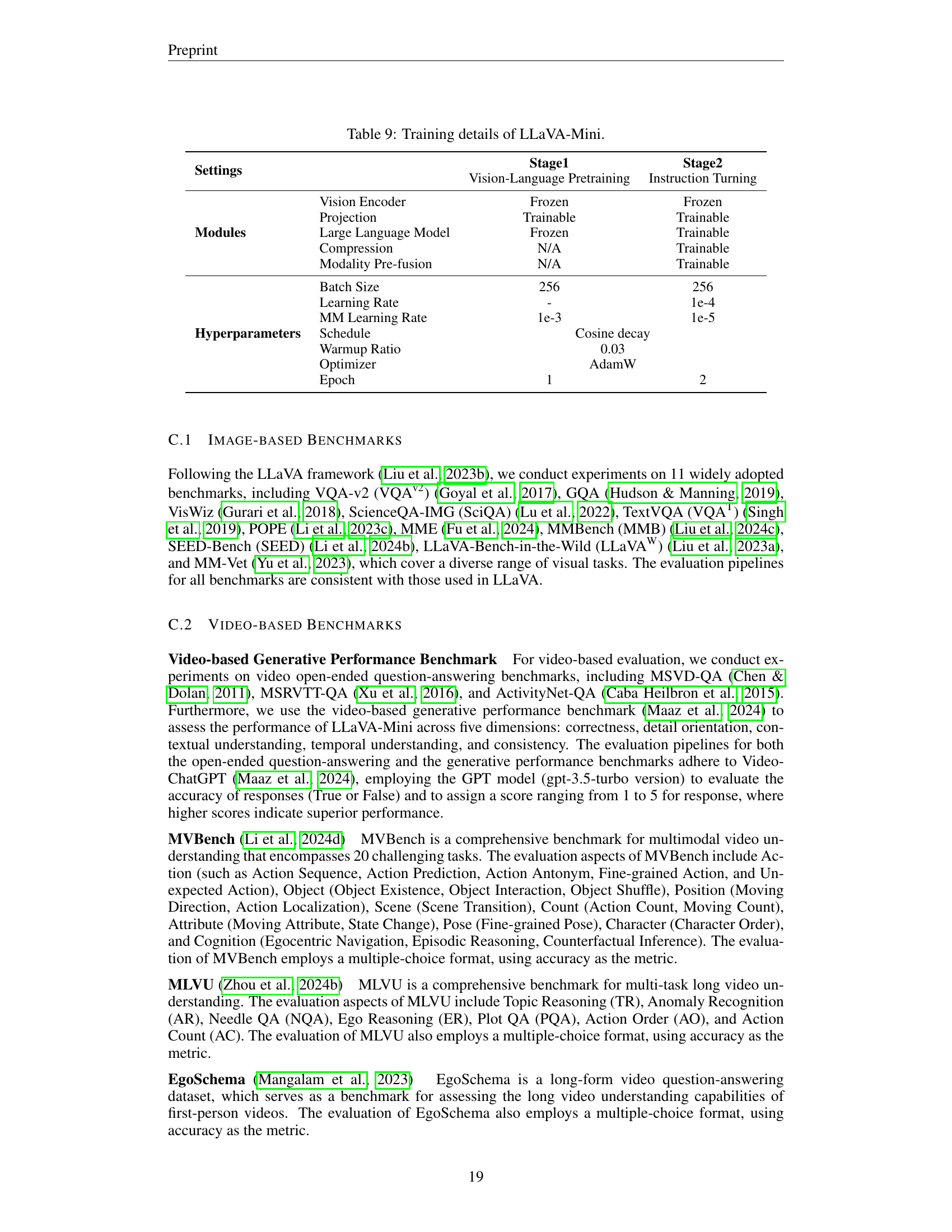
🔼 This table details the training hyperparameters and settings used in two stages of training the LLaVA-Mini model. Stage 1 focuses on vision-language pretraining, while Stage 2 involves instruction tuning. The table specifies which modules (vision encoder, projection, large language model, compression, and modality pre-fusion) were trained or frozen during each stage, along with details like batch size, learning rate, and the optimizer used. It provides a comprehensive overview of the training configuration for LLaVA-Mini.
read the caption
Table 9: Training details of LLaVA-Mini.
| Methods | #Frames | EgoSchema |
|---|---|---|
| Random | - | 20 |
| mPLUG-Owl | 16 | 31.1 |
| InternVideo | 16 | 32.1 |
| Video-ChatGPT | 100 | 36.2 |
| VideoChat | 16 | 42.2 |
| TimeChat | 96 | 33.0 |
| LLaMA-VID | 1fps | 38.5 |
| Video-LLaVA | 8 | 38.4 |
| LLaVA-Mini | 1fps | 51.2 |
🔼 This table compares the performance of LLaVA-Mini against other methods that also reduce the number of vision tokens used in LLMs. It shows the performance of several models (including variations of MQT-LLaVA and PruMerge) on three benchmark metrics (VQAV2, GQA, and MMB), each using a different number of vision tokens. The goal is to demonstrate LLaVA-Mini’s effectiveness at achieving strong performance even with a drastically reduced number of vision tokens.
read the caption
Table 10: Comparison of LLaVA-Mini with previous token merging methods.
| Methods | Pre-fusion#Layers | #VisionTokens | FLOPs(T) | VQAv2 | GQA | MMB |
|---|---|---|---|---|---|---|
| LLaVA-v1.5 | - | 576 | 8.55 | 78.5 | 62.0 | 64.3 |
| LLaVA-Mini (w/o pre-fusion) | 0 | 1 | 0.96 | 72.4 | 54.2 | 57.7 |
| 0 | 16 | 1.16 | 74.1 | 55.4 | 59.2 | |
| 0 | 64 | 1.79 | 75.3 | 56.7 | 62.1 | |
| 0 | 144 | 2.85 | 76.9 | 58.9 | 64.9 | |
| LLaVA-Mini (w/ pre-fusion) | 1 | 1 | 1.21 | 74.8 | 55.5 | 60.4 |
| 2 | 1 | 1.46 | 76.0 | 57.6 | 63.1 | |
| 3 | 1 | 1.81 | 76.9 | 59.1 | 64.9 | |
| 4 | 1 | 1.96 | 77.6 | 60.9 | 65.6 |
🔼 This table presents a comparison of the performance of LLaVA-Mini with and without its compression module, while keeping the pre-fusion module. The performance metrics used are VQA-v2, GQA, and MMB accuracy, and the number of vision tokens used is specified. This demonstrates the impact of the pre-fusion module on the model’s performance.
read the caption
Table 11: Performance of LLaVA-Mini when using only pre-fusion module without compression.
| Methods | Res. | #Vision Tokens | VQAv2 | GQA | MMB |
|---|---|---|---|---|---|
| LLaVA-v1.5 | 336 | 576 | 78.5 | 62.0 | 64.3 |
| LLaVA-Mini | 336 | 1 | 77.6 | 60.9 | 65.6 |
| 336 | 4 | 77.7 | 60.9 | 66.7 | |
| 336 | 16 | 78.1 | 61.3 | 66.6 | |
| 336 | 64 | 78.5 | 61.6 | 67.5 | |
| 672 | 16 | 78.5 | 61.5 | 67.4 | |
| 672 | 64 | 78.9 | 61.8 | 67.5 | |
| 672 | 144 | 79.3 | 62.3 | 67.9 | |
| 672 | 576 | 80.0 | 62.9 | 68.1 |
🔼 This table compares the performance of LLaVA-Mini when the compression and modality pre-fusion modules are placed outside the LLM backbone versus inside. It shows that placing these modules outside the LLM yields better results (higher performance in VQAv2, GQA, and MMB) with a comparable FLOPs count. This highlights the advantage of the LLaVA-Mini architecture for efficiency and performance.
read the caption
Table 12: Comparison of performing compression and pre-fusion outside or within LLM backbone.
| Compression | #VisionTokens | FLOPs | VQAv2 | GQA | MMB |
|---|---|---|---|---|---|
| Average Pooling | 1 | 1.96T | 76.1 | 59.8 | 64.0 |
| Query-based | +2.42G | 77.6 | 60.9 | 65.6 | |
| Average Pooling | 4 | 2.01T | 76.9 | 60.3 | 65.1 |
| Query-based | +2.44G | 77.7 | 60.9 | 66.7 |
🔼 This table presents a comparison of inference latency (in milliseconds) for the LLaVA-Mini model across three different hardware platforms: RTX 3090 (with 24GB of memory), A100 (with 40GB of memory), and A800 (with 80GB of memory). The latency is measured for varying numbers of vision tokens used in the model (1, 4, 16, and 64). This allows for an assessment of the model’s efficiency and scalability across different hardware configurations and varying model complexities. The comparison also includes latency for the LLaVA-v1.5 model (using 576 vision tokens) as a baseline for evaluating the performance gains of LLaVA-Mini.
read the caption
Table 13: Inference latency (millisecond) of LLaVA-Mini on various hardware platforms.
| Settings | Stage1 | Stage2 |
|---|---|---|
| Vision-Language Pretraining | Vision-Language Pretraining | Instruction Turning |
| Modules | ||
| Vision Encoder | Frozen | Frozen |
| Projection | Trainable | Trainable |
| Large Language Model | Frozen | Trainable |
| Compression | N/A | Trainable |
| Modality Pre-fusion | N/A | Trainable |
| Hyperparameters | ||
| Batch Size | 256 | 256 |
| Learning Rate | - | 1e-4 |
| MM Learning Rate | 1e-3 | 1e-5 |
| Schedule | Cosine decay | Cosine decay |
| Warmup Ratio | 0.03 | 0.03 |
| Optimizer | AdamW | AdamW |
| Epoch | 1 | 2 |
🔼 This table breaks down the computational cost (measured in FLOPs) for each component of the LLaVA-Mini model. It compares LLaVA-Mini’s computational efficiency against the original LLaVA-v1.5 model at two different resolutions (336x336 and 672x672 pixels). The components analyzed include the Vision Encoder, Projection, Compression, Pre-fusion, and LLM. The total FLOPs for each model at each resolution is also shown, highlighting the significant reduction in computational cost achieved by LLaVA-Mini.
read the caption
Table 14: Computational overhead (FLOPs) of each component in LLaVA-Mini.
| Methods | #Vision Tokens | VQAv2 | GQA | MMB |
|---|---|---|---|---|
| MQT-LLaVA | 2 | 61.0 | 50.8 | 54.4 |
| MQT-LLaVA | 36 | 73.7 | 58.8 | 63.4 |
| MQT-LLaVA | 256 | 76.8 | 61.6 | 64.3 |
| PruMerge | 32 | 72.0 | - | 60.9 |
| PruMerge++ | 144 | 76.8 | - | 64.9 |
| LLaVA-Mini | 1 | 72.4 | 54.2 | 57.7 |
| LLaVA-Mini | 16 | 74.1 | 55.4 | 59.2 |
| LLaVA-Mini | 64 | 75.3 | 56.7 | 62.1 |
| LLaVA-Mini | 144 | 76.9 | 58.9 | 64.9 |
🔼 This table presents a detailed breakdown of the performance results for LLaVA-Mini on the MVBench benchmark. MVBench is a comprehensive evaluation benchmark for multimodal video understanding, consisting of 20 challenging tasks across different aspects of video understanding, including action, object, position, scene, count, attribute, pose, character, and cognition. The table shows LLaVA-Mini’s performance on each of these 20 individual sub-tasks, allowing for a granular analysis of its strengths and weaknesses in various video understanding capabilities. The results are presented in terms of accuracy for each sub-task, providing a precise and comprehensive view of LLaVA-Mini’s overall performance on the benchmark.
read the caption
Table 15: Detailed results on 20 subsets of MVBench.
Full paper#