↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current methods for 3D object generation either lack intricate details or simply mimic existing objects, falling short in generating truly creative and fine-grained 3D assets. Existing approaches often struggle with generating high-fidelity 3D models from 2D data, especially for complex objects like birds, hindering progress in fields like virtual and augmented reality, and 3D asset creation. This paper presents the challenges of existing methods, and the limitations faced in fine-grained 3D generation.
This research introduces Chirpy3D, a novel framework that addresses these challenges. Chirpy3D leverages multi-view diffusion models to integrate fine-grained 2D image understanding into 3D space. It models parts using continuous latent distributions, allowing for the generation of entirely new, yet plausible parts. A self-supervised loss further enhances the visual coherency of generated objects. The result is a system that produces high-quality 3D models that surpass the limitations of previous methods, offering unprecedented levels of creative control and intricate detail.
Key Takeaways#
Why does it matter?#
This paper is important because it bridges the gap between 2D and 3D fine-grained object generation, a significant challenge in computer vision. By enabling the creation of novel 3D objects with intricate details and creative control, it opens new avenues for research in 3D asset creation, virtual and augmented reality, and other applications requiring high-quality 3D models. Its novel approach to part-level manipulation and self-supervised learning provides valuable insights for researchers working on generative models.
Visual Insights#
🔼 This figure showcases the capabilities of Chirpy3D, a novel approach for generating 3D bird models. The top row displays examples of 3D birds representing existing species, accurately reflecting real-world bird anatomy and features. The bottom row demonstrates Chirpy3D’s ability to create entirely new, never-before-seen bird species by manipulating a learned ‘part latent space’. This space allows for creative combinations and variations of bird parts, leading to the generation of diverse and plausible novel bird designs that exhibit realistic details and species-specific features.
read the caption
Figure 1: Generated chirpy 3D birds composed of diverse parts. Our Chirpy3D learns a part latent space from raw 2D images and can generate high-quality creative 3D birds by exploring the part latent space. (Top) Existing species. (Bottom) Novel species.
| Dl | 4 | 16 | 32 | 64 |
|---|---|---|---|---|
| H | 4.81 | 4.68 | 4.67 | 4.33 |
| eH | 123.2 | 108.1 | 106.7 | 76.3 |
🔼 This table presents a quantitative comparison of three different models’ performance in generating multi-view images of birds. The metrics used are DINO and CLIP similarity scores, and FID and FID-CLIP scores. Higher DINO and CLIP scores indicate better subject fidelity, while lower FID and FID-CLIP scores indicate better image quality and lower divergence from real images. The models compared are Textual Inversion, PartCraft, and Chirpy3D (the authors’ model).
read the caption
Table 1: Subject fidelity metrics.
In-depth insights#
Fine-grained 3D#
The concept of “Fine-grained 3D” in the context of 3D asset generation points towards a significant advancement in the field. It highlights the need to move beyond coarse 3D models lacking intricate details and towards high-fidelity representations capturing minute features. This requires tackling the challenges of efficiently representing and generating highly detailed textures, geometries, and structures, pushing the boundaries of existing methods. A key challenge lies in acquiring sufficient high-quality, fine-grained 3D data for training, as such data is often expensive and difficult to obtain. Therefore, the focus shifts towards leveraging readily available 2D data and employing techniques like multi-view diffusion or techniques that transfer knowledge from 2D to 3D to address the data scarcity. The success of “Fine-grained 3D” rests on achieving a balance between detail and computational efficiency, making it vital to explore efficient model architectures and training strategies. Furthermore, the ability to generate creative and novel 3D objects, rather than just mimicking existing ones, is critical. This calls for incorporating mechanisms for manipulating parts of objects, enabling part-level creativity and the generation of entirely new, plausible objects that would not exist in the real world. Ultimately, “Fine-grained 3D” represents a quest for realistic and highly detailed 3D assets, driving progress towards richer, more nuanced virtual environments and digital content creation.
Part-Aware Latents#
The concept of ‘Part-Aware Latents’ in the context of 3D object generation represents a significant advancement. It suggests a model capable of disentangling an object into constituent parts and encoding their properties into a latent space. This allows for unprecedented creative control, enabling not only manipulation of existing parts but also generation of entirely novel parts via interpolation and sampling. The continuous nature of this latent space is crucial, facilitating seamless transitions between different part variations and promoting the emergence of plausible novel combinations. The success hinges on the model’s ability to capture species-specific details and incorporate this understanding into the part latents, thereby bridging the gap between fine-grained 2D image understanding and sophisticated 3D object creation. Self-supervised methods, likely crucial for ensuring consistency and preventing artifacts in newly generated parts, would also play an essential role in this system. Overall, ‘Part-Aware Latents’ signifies a shift towards truly creative 3D generation, moving beyond mere mimicry to the production of unique and intricate objects.
Novel 3D Objects#
The concept of “Novel 3D Objects” in the context of this research paper centers on the creation of entirely new, three-dimensional objects that do not exist in the real world. This goes beyond simply mimicking or modifying existing objects; it represents a significant leap in generative AI. The paper achieves this novelty through several key innovations. Firstly, by creating a continuous part-level latent space, the model allows for seamless interpolation and sampling, generating plausible parts that transcend the training data. This opens the door for generating truly unique objects. Secondly, self-supervised learning methods ensure that the generated parts remain coherent, even those that are completely new and haven’t been previously observed. Lastly, by using multi-view diffusion models, the approach ensures consistency and accuracy across multiple viewpoints of the 3D object. The resulting ability to generate novel 3D objects with fine-grained detail and creative freedom is a significant step forward, opening up a vast potential for diverse applications in various fields.
MVDream Fine-tune#
Fine-tuning MVDream, a multi-view diffusion model, is a critical step in the Chirpy3D framework. Instead of training from scratch, leveraging a pre-trained model allows the researchers to efficiently transfer the knowledge of multi-view consistency to the 3D bird generation task. This is particularly important for generating high-quality, fine-grained 3D models where maintaining consistency across multiple views is crucial. The fine-tuning process likely involves optimizing the model with 2D bird images, enabling it to effectively capture the fine-grained details present in the 2D data. This approach is significantly more efficient than training from scratch. The method allows fine-grained details from 2D images to be transferred into 3D, bridging the gap between 2D and 3D domains. Careful consideration is given to the selection of the loss function and other hyperparameters to effectively transfer the knowledge while avoiding overfitting to the limited training dataset. The success of MVDream fine-tuning significantly contributes to the overall capability of the Chirpy3D system in generating high-quality, novel, and creative 3D bird models.
Creative Generation#
The concept of “Creative Generation” in the context of AI research papers signifies the ability of an algorithm to produce novel and original outputs, moving beyond mere imitation or reproduction. This often involves techniques that go beyond simple data interpolation or extrapolation. A crucial aspect is the generation of outputs that transcend the training dataset, exhibiting originality and creativity rather than simply recombining existing elements. The level of control offered is another important criterion, with truly creative generation systems allowing for precise manipulation of various generative parameters, leading to a wider range of creative possibilities. The evaluation of creative generation presents a unique challenge, as quantitative metrics alone may be insufficient. Subjective assessment, user studies, and qualitative analysis of generated outputs are often needed to truly capture the degree of creativity achieved. The ability to generate outputs with intricate detail and high fidelity is also a defining characteristic, ensuring the plausibility and aesthetic appeal of the results. Ultimately, creative generation in AI aims to push the boundaries of what is possible, blurring the lines between human and machine creativity. The underlying framework of many creative generation models often involves a combination of deep learning architectures, probabilistic models, and novel loss functions. This multi-faceted approach allows for flexible control over the generative process, producing diverse and surprising outputs.
More visual insights#
More on figures

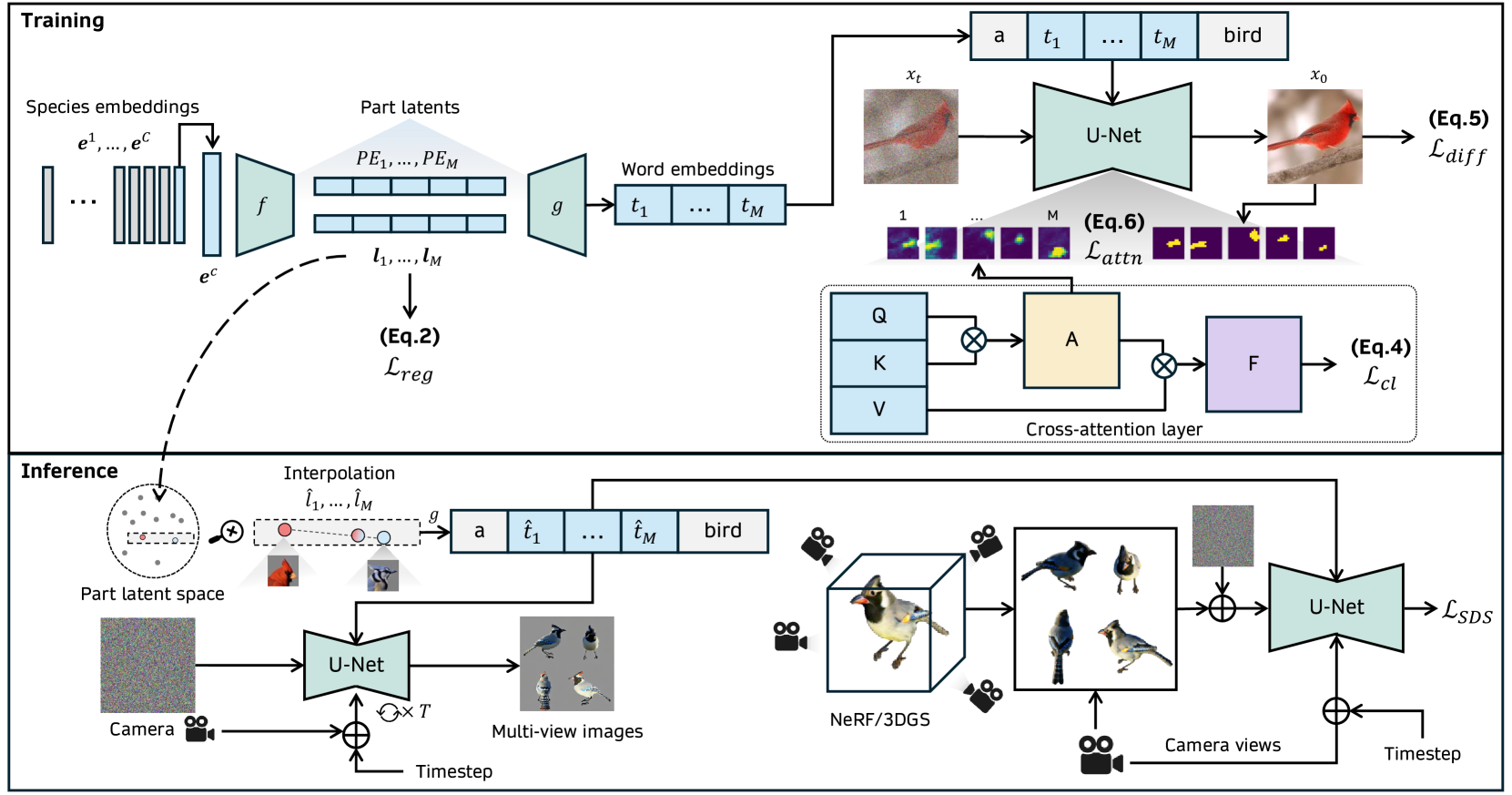
🔼 This figure illustrates the architecture of Chirpy3D, a system for creative 3D bird generation. The top half shows the training process. Chirpy3D fine-tunes a pre-trained text-to-multi-view diffusion model (like MVDream) using 2D bird images. It learns a continuous part-aware latent space by mapping species embeddings to part latents, then decoding these into word embeddings that condition the diffusion model’s text prompt. Multiple loss functions are used during training: a diffusion loss, a regularization loss to ensure part latents follow a Gaussian distribution, an attention loss for part disentanglement, and a novel feature consistency loss to improve visual coherence. The bottom half demonstrates the inference process. Users select desired part latents to preview multi-view images, which can then be converted into 3D representations (e.g., using NeRF) via an SDS loss.
read the caption
Figure 2: Overall architecture of our Chirpy3D. (Top) During training, we fine-tune a text-to-multi-view diffusion model (e.g., MVDream) with only 2D images of birds. We aim to learn the underlying part information by modeling a continuous part-aware latent space. This is achieved by learning a set of species embeddings 𝒆𝒆\bm{e}bold_italic_e, project them into part latents 𝒍𝒍\bm{l}bold_italic_l through learnable f𝑓fitalic_f, decode into word embeddings 𝒕𝒕\bm{t}bold_italic_t through learnable g𝑔gitalic_g and insert into text prompt. We train the diffusion model with diffusion loss (Eq. 5) and multiple loss objectives – ℒregsubscriptℒreg\mathcal{L}_{\text{reg}}caligraphic_L start_POSTSUBSCRIPT reg end_POSTSUBSCRIPT (Eq. 2) to model part latents as Gaussian distribution, ℒattnsubscriptℒattn\mathcal{L}_{\text{attn}}caligraphic_L start_POSTSUBSCRIPT attn end_POSTSUBSCRIPT (Eq. 6) for part disentanglement, and our proposed ℒclsubscriptℒcl\mathcal{L}_{\text{cl}}caligraphic_L start_POSTSUBSCRIPT cl end_POSTSUBSCRIPT (Eq. 4) to enhance visual coherency. f𝑓fitalic_f and g𝑔gitalic_g are trainable modules. For efficient training, we added LoRA layers into cross-attention layers of the U-Net. (Bottom) During inference, we can first preview multi-view images by selecting desired part latents as condition before turning them into 3D representations (e.g., NeRF) through SDS loss ℒSDSsubscriptℒSDS\mathcal{L}_{\text{SDS}}caligraphic_L start_POSTSUBSCRIPT SDS end_POSTSUBSCRIPT.

🔼 This figure illustrates a self-supervised approach to ensure the generation of visually coherent, unseen parts. Since there are no images of unseen part latents available for training, the method uses real natural images as a proxy. By extracting cross-attention feature maps from two noised latents, the model is trained to minimize the discrepancy between these feature maps. This indirect approach encourages the model to generate similar feature maps for any given part latents, regardless of whether the latent represents a seen or unseen part. This ultimately stabilizes the denoising process for unseen parts, leading to more visually coherent novel object generation.
read the caption
Figure 3: As we do not have images of unseen part latents, we use real natural images as our proxy. We extract cross-attention feature maps F𝐹Fitalic_F of two noised latents, then minimize the discrepancy between the two feature maps. This will encourage the model to compute similar feature maps for any given part latents, which indirectly stabilizes the denoising process for unseen latents.

🔼 Figure 4 illustrates three different methods for generating bird images using the Chirpy3D model. (a) shows seen part selection, where existing parts from known bird species are combined to create new images. (b) demonstrates unseen part synthesis through novel sampling, generating entirely new bird parts not seen during training. This is achieved by sampling from a learned continuous latent space representing bird parts. (c) shows unseen part synthesis via interpolation, creating novel bird parts by smoothly blending existing parts from the latent space. This allows for generating hybrid bird species.
read the caption
Figure 4: (a) Seen part selection generation. Unseen part synthesis via (b) novel sampling and (c) interpolation.

🔼 This figure shows the results of generating multi-view images of birds using the Textual Inversion method. Textual Inversion is a baseline method that directly uses word embeddings without explicitly modeling part-aware latent space. The images demonstrate the model’s ability to generate birds, but they tend to lack the fine-grained detail and visual consistency observed in other methods presented in the paper.
read the caption
(a) Textual Inversion

🔼 PartCraft is a method for generating images by replacing parts of existing images with corresponding parts from other images. The figure shows the result of this method applied to the task of bird image generation. Specifically, it demonstrates the linear interpolation of parts between two different bird species, illustrating the system’s ability to generate novel combinations of existing parts.
read the caption
(b) PartCraft

🔼 This figure shows 3D bird models generated by the Chirpy3D model. The models showcase the model’s ability to generate high-quality, detailed birds with species-specific features. The birds shown represent a variety of species, both existing and novel, demonstrating the model’s capacity for both realistic and creative generation.
read the caption
(c) Chirpy3D (Ours)

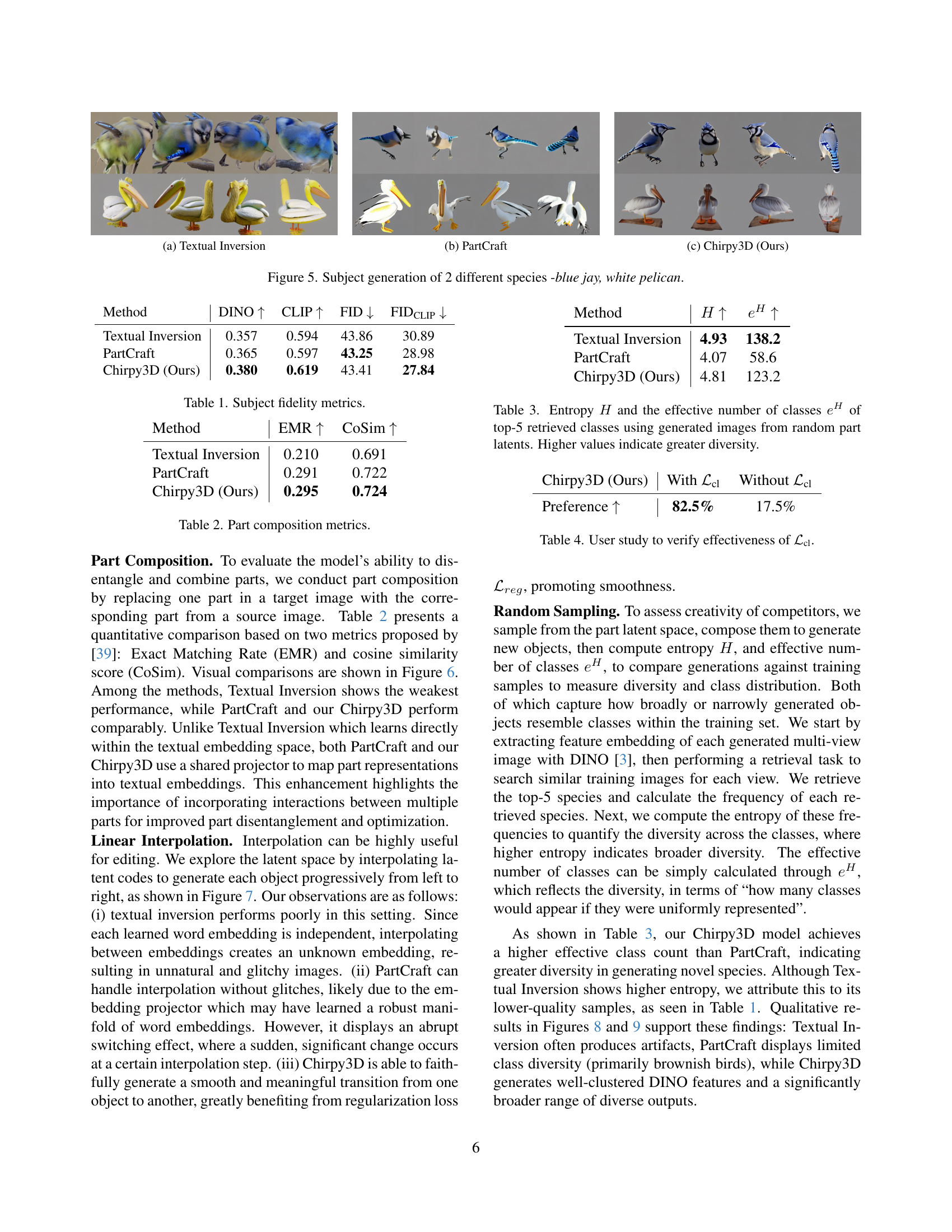
🔼 This figure showcases the model’s ability to generate images of different bird species. Two species are highlighted here: the Blue Jay and the White Pelican. The images demonstrate the model’s capacity to generate realistic and detailed depictions of these birds, capturing fine-grained features such as plumage patterns and beak shapes. This highlights the effectiveness of the model in generating high-quality, species-specific images from a diverse range of birds.
read the caption
Figure 5: Subject generation of 2 different species -blue jay, white pelican.

🔼 This figure displays a visual comparison of part composition using six bird species: cardinal, Wilson warbler, least auklet, California gull, horned lark, and song sparrow. Each row shows a target image where one part (head, body, or wings) has been replaced with a corresponding part from a different source bird species. All images, both source and target, in each row share the same random seed to highlight how the model generates and recombines components. Red circles clearly mark the parts that have been swapped.
read the caption
Figure 6: Visual comparison of part composition. A,B,C,D,E,F𝐴𝐵𝐶𝐷𝐸𝐹A,B,C,D,E,Fitalic_A , italic_B , italic_C , italic_D , italic_E , italic_F represent cardinal, wilson warbler, least auklet, california gull, horned lark, and song sparrow respectively. Red circles indicate changed parts. All generated (including sources & targets) by the same seed.

🔼 This figure shows the results of multi-view image generation using the Textual Inversion method. It displays several generated images of birds, showcasing the method’s ability (or inability) to generate images from text prompts. Differences in image quality, realism, and adherence to the prompt can be observed. The purpose is to provide a visual comparison of this method’s performance compared to other methods discussed in the paper (PartCraft and Chirpy3D).
read the caption
(a) Textual Inversion

🔼 The figure shows linear interpolation results between two bird species using PartCraft. PartCraft, unlike Chirpy3D, exhibits an abrupt switch in the generated images after a certain interpolation step, resulting in less smooth transitions between the two bird species.
read the caption
(b) PartCraft

🔼 This figure shows 3D bird models generated by the Chirpy3D model. The images demonstrate the model’s ability to generate high-quality, novel 3D bird models with diverse parts, illustrating its capacity for creative 3D object generation. The birds depicted showcase intricate details and a range of species, highlighting the model’s capability in fine-grained 3D generation.
read the caption
(c) Chirpy3D (Ours)

🔼 This figure shows a comparison of linear interpolation results between two bird species (blue jay and cardinal) using three different methods: Textual Inversion, PartCraft, and Chirpy3D. The x-axis implicitly represents the interpolation parameter, smoothly transitioning from one bird species to the other. The y-axis represents the visual features of the generated bird. Chirpy3D demonstrates a smooth, continuous transition between the two species’ features throughout the interpolation range. In contrast, PartCraft’s interpolation shows an abrupt, discontinuous change in bird features at a specific point in the interpolation, indicated by a red box in the figure. This highlights Chirpy3D’s ability to generate a more natural and continuous transition between species’ features due to its modeling of continuous part latents.
read the caption
Figure 7: Linear interpolation of all part latents between two different species – blue jay and cardinal. Only one view is shown. Our Chirpy3D achieves much smoother interpolation, unlike PartCraft exhibits an abrupt switch phenomenon after a certain step (red box).

🔼 Figure 5(a) shows the results of generating images of two bird species (blue jay and white pelican) using the Textual Inversion method. The Textual Inversion method directly uses text embeddings to generate images, without incorporating a mechanism to represent and manipulate individual parts of the bird. This may result in less control over the fine-grained details of the bird’s features and less ability to generate novel variations.
read the caption
(a) Textual Inversion

🔼 Figure 7(b) shows the results of linear interpolation of part latents between two bird species using PartCraft. PartCraft, unlike Chirpy3D, exhibits an abrupt, non-smooth transition between the two species during the interpolation, as indicated by the red box.
read the caption
(b) PartCraft

🔼 Chirpy3D generates high-quality 3D bird images with diverse parts by exploring a continuous part latent space. The images show novel bird species created through interpolation and sampling of the part latents, demonstrating the system’s ability to generate creative and plausible 3D bird models.
read the caption
(c) Chirpy3D (Ours)

🔼 This figure visualizes the results of t-SNE dimensionality reduction applied to DINO (DETR-like image-level representations) features extracted from generated images. The images were generated using the Chirpy3D model, a method for creative 3D bird generation described in the paper. Points colored blue represent images generated from known bird species (subject reconstruction), while those colored orange represent images of novel bird species created by the model (novel generation). The plot shows how these images cluster together based on their visual similarity as captured by the DINO features. Clustering patterns provide insight into the model’s ability to generate both realistic representations of known bird species and creative novel variations.
read the caption
Figure 8: t-SNE embeddings of DINO features of generated images. Blue represents images of subject reconstruction; Orange represents images of novel generation.

🔼 This figure displays the results of 3D object generation using the Textual Inversion method. It showcases the limitations of the Textual Inversion method in terms of generating high-quality, detailed, and visually consistent 3D objects, particularly when dealing with fine-grained details and novel object creation. The generated objects lack the fidelity and coherence seen in other methods, highlighting the challenges of translating 2D fine-grained understanding to the 3D domain.
read the caption
(a) Textual Inversion

🔼 This figure shows the results of part composition using the PartCraft method. Part composition involves replacing one part of a target bird image (e.g., the head) with the corresponding part from a different bird image. The results demonstrate the model’s ability to combine parts from different bird species to create novel bird images. The figure likely shows multiple examples of these part-swapped bird images, illustrating the accuracy and visual quality of the resulting creations compared to the source birds and the target bird.
read the caption
(b) PartCraft

🔼 This figure shows the results of 3D bird generation using the Chirpy3D method. It showcases the model’s ability to generate high-quality, multi-view images of birds, including both existing and novel species. The birds are shown from various angles and exhibit realistic details and textures. The results highlight Chirpy3D’s capacity for generating diverse and creative outputs.
read the caption
(c) Chirpy3D (Ours)

🔼 Figure 9 displays the results of generating images using random samples from the latent spaces of three different models: Textual Inversion, PartCraft, and Chirpy3D. Textual Inversion, due to its method of directly interpolating word embeddings, frequently produces images with noticeable artifacts. PartCraft generates images with fewer artifacts, but the resulting images lack overall consistency. In contrast, Chirpy3D consistently produces novel and diverse images, demonstrating its superior ability in generating creative and high-quality outputs.
read the caption
Figure 9: Generated images with random sampled latents/embeddings. Textual Inversion often produces images with artifacts due to the direct interpolation of word embeddings. PartCraft can generate images with fewer artifacts but lacks consistency. In contrast, our Chirpy3D generates novel images with greater diversity.

🔼 This figure showcases 3D renderings of birds generated using NeRF (Neural Radiance Fields). It demonstrates the capability of the Chirpy3D model to generate high-quality, detailed 3D models of birds from various angles. The images showcase both existing bird species and novel, synthetic birds created through the model’s creative capabilities. The diversity of generated bird poses and appearances highlights the model’s effectiveness in 3D object generation.
read the caption
Figure 10: NeRF rendering of learned 3D objects.

🔼 This figure displays a comparison of 3D bird generation results obtained with and without the feature consistency loss (ℒcl). The left column shows generations without the feature consistency loss, exhibiting a lack of visual coherence and various artifacts. The right column shows results obtained with the feature consistency loss, demonstrating significantly improved visual coherence and a reduction in artifacts, thereby emphasizing the importance of this loss term in producing high-quality, consistent 3D bird models.
read the caption
(a) Ours without ℒclsubscriptℒcl\mathcal{L}_{\text{cl}}caligraphic_L start_POSTSUBSCRIPT cl end_POSTSUBSCRIPT

🔼 This figure shows a qualitative comparison of visual coherency before and after applying feature consistency loss (ℒcl). The left column (a) displays bird images generated before applying the loss, while the right column (b) shows the results after applying the loss. The results demonstrate that the feature consistency loss improves visual coherency and reduces artifacts.
read the caption
(b) Ours with ℒclsubscriptℒcl\mathcal{L}_{\text{cl}}caligraphic_L start_POSTSUBSCRIPT cl end_POSTSUBSCRIPT

🔼 This figure demonstrates the effect of the feature consistency loss (ℒcl) on the visual consistency of generated images. Two sets of images are shown, each generated with the same camera pose but different random seeds. The images in (a) were generated without the ℒcl loss, resulting in inconsistencies such as artifacts and variations in visual features between the images. The images in (b) were generated with the ℒcl loss, showcasing improved visual consistency and reduced artifacts.
read the caption
Figure 11: All images are generated with the same camera pose but with different seeds on unseen latent. (a) Without our feature consistency loss ℒclsubscriptℒcl\mathcal{L}_{\text{cl}}caligraphic_L start_POSTSUBSCRIPT cl end_POSTSUBSCRIPT, the generated images lack consistency (e.g., less artifact, and inconsistent visual feature) compared to (b).

🔼 This figure demonstrates the capability of the model to generate novel animal breeds by interpolating between existing breeds. The image shows a hybrid dog (center) that blends features of a Siberian Husky (left) and a Papillon (right). The model was trained on the Stanford Dogs dataset, indicating its ability to learn and creatively combine fine-grained characteristics of different dog breeds to produce plausible novel variations.
read the caption
Figure 12: A hybrid (middle) between siberian husky (left) and papillon (right), trained with Stanford Dogs [27].

🔼 This figure displays the results of 3D object generation using two different methods: NeRF (Neural Radiance Fields) and 3DGS (a method for generating 3D shapes using Gaussian Splatting). It showcases examples of generated 3D bird models, highlighting the quality and detail achievable with these optimization-based approaches. The figure shows multiple views of the generated 3D birds from various angles, enabling a full 3D understanding of the model’s capabilities.
read the caption
Figure 13: Optimization-based 3D generation with NeRF or 3DGS.

🔼 This figure demonstrates the image-to-3D generation pipeline using InstantMesh. The input is a single front view image of a bird, which is then processed to generate a 3D model of the bird. InstantMesh employs an intermediate step of generating multiple views (in this case, a side view is also shown). The final output is a 3D mesh representation ready for rendering or further manipulation.
read the caption
Figure 14: Image-to-3D using front view and side view of generated object.

🔼 This figure shows examples of dog breed hybrids generated by the model. The top row shows a mix between a Chow Chow and a Golden Retriever, and a Pomeranian and a Pug. These images demonstrate the model’s ability to generate plausible combinations of existing dog breeds, showcasing fine-grained control over the generation process.
read the caption
(a) Mixing chow with golden retriever, pomeranian with pug.

🔼 This figure shows examples of novel animal generation from the Chirpy3D model. The images depict the results of combining features from disparate animals. Specifically, it shows three hybrid creatures: a hamster-cat hybrid, a hamster-horse hybrid, and an elephant-horse hybrid. These novel combinations showcase the model’s ability to generate plausible and creative combinations of animal features beyond those seen during training.
read the caption
(b) Hamster-cat, Hamster-horse, Elephant-horse

🔼 Figure 15 showcases the model’s ability to generate images beyond birds. (a) demonstrates the generation of various dog breeds and hybrids, highlighting the model’s capacity for creating novel variations within a specific species. (b) shows the generation of diverse animal combinations, indicating that the model’s framework is applicable to a broader range of animal categories.
read the caption
Figure 15: (a) Dog generation. (b) Animal generation.

🔼 This figure shows the results of generating 3D bird models from the text prompt ‘a bird, 3d asset’. The image showcases multiple generated bird models, each rendered from a slightly different viewpoint to illustrate the multi-view capability of the model. The variation in the generated birds demonstrates the model’s ability to produce diverse outputs even with a simple prompt.
read the caption
(a) a bird, 3d asset.

🔼 This figure shows a multi-view rendering of a 3D model of a cardinal generated using the Chirpy3D method. Multiple views are presented to demonstrate the quality and realism of the generated 3D bird model. The fine-grained details are visible, highlighting the model’s ability to capture intricate features. The background is plain, focusing attention on the 3D bird model itself.
read the caption
(b) a cardinal, 3d asset.

🔼 This figure shows the results of multi-view generation using the MVDream model with different text prompts. The guidance scale was set to 7.5. Subfigure (a) uses the general prompt ‘bird’, resulting in varied outputs from different random seeds, demonstrating the model’s ability to generate diverse bird-like forms. Subfigure (b) employs the more specific prompt ‘cardinal’, leading to consistently similar outputs across different seeds. This consistency with the specific prompt allows for a lower guidance scale during 3D generation using the Score Distillation Sampling (SDS) loss, preventing oversaturation of details and producing higher-quality 3D models.
read the caption
Figure 16: Multi-view generation with text prompt through MVDream [52]. The guidance scale is 7.5. Each row is a different seed. (a) The generation varies for different seeds for the token “bird”. (b) The generation with a fine-grained token “cardinal”. As highly similar objects are generated for each seed, we can use a lower guidance scale for SDS loss and enable 3D generation without oversaturated effect.

🔼 Figure 5(a) shows the results of multi-view generation using the Textual Inversion method. Textual Inversion, unlike other methods described in the paper (PartCraft and Chirpy3D), directly uses word embeddings for image generation. This is a baseline method compared against more sophisticated approaches that employ part-level manipulation for greater creative control. The image showcases a variety of bird species, highlighting the method’s ability to generate different bird types, but potentially at the cost of less detailed rendering and consistency compared to PartCraft or Chirpy3D.
read the caption
(a) Textual Inversion

🔼 Figure 7 shows the results of linear interpolation between two bird species (blue jay and cardinal) using three different methods: Textual Inversion, PartCraft, and Chirpy3D. The x-axis represents the interpolation step, ranging from one species to the other. The y-axis implicitly represents the generated image. Textual Inversion produces noisy and discontinuous transitions between the bird species. PartCraft shows an abrupt shift in the generated image at a certain point during interpolation. In contrast, Chirpy3D produces smooth and coherent transitions, showcasing a more natural and seamless morphing process between the two species.
read the caption
(b) PartCraft

🔼 This figure displays multi-view generation results from the Chirpy3D model on novel bird species created through interpolation. The images showcase a smooth transition between different bird species, highlighting the model’s capacity to generate plausible and visually coherent novel bird variations.
read the caption
(c) Chirpy3D (Ours)

🔼 This figure shows multi-view generation results on existing bird species. The three columns represent the outputs from Textual Inversion, PartCraft, and Chirpy3D respectively. Each row displays a different bird species, illustrating the models’ ability to generate multi-view images of known bird types. The goal is to compare the visual fidelity and consistency of the generated images across different methods. Note that (d) shows one of the actual training images for comparison. Chirpy3D shows improved visual quality and consistency compared to the baseline methods.
read the caption
(d)

🔼 Figure 17 presents a comparison of multi-view bird image generation results from three different methods: Textual Inversion, PartCraft, and the authors’ proposed Chirpy3D. Each column (a, b, c) displays images generated by each method for several existing bird species. Column (d) shows an example of a real training image for reference. The figure highlights that Chirpy3D produces images with superior multi-view consistency and cleaner backgrounds compared to the baseline methods.
read the caption
Figure 17: Multi-view generation on existing species, trained with respective methods (a, b, c). (d) One of the training images of the species. Not only our Chirpy3D (c) can reconstruct well in multi-view perspective comparing to Textual Inversion (a) and PartCraft (b), but our generated images are also consistent in terms of orientation and cleaner background.

🔼 This figure shows the results of generating multi-view images of birds using the Textual Inversion method. It highlights that this method struggles to generate high-quality and consistent multi-view images of birds, likely due to limitations in representing and manipulating the intricate visual details of bird species. The images appear less realistic and lack the fine-grained detail achievable by other more advanced methods like Chirpy3D. The figure serves as a visual comparison to highlight the differences between Textual Inversion and other approaches in generating high-quality, detailed bird images.
read the caption
(a) Textual Inversion

🔼 PartCraft is a method for creative 3D object generation that uses a part-aware approach. This image shows the results of PartCraft’s object generation, specifically focusing on its ability to compose and recombine existing parts to create novel objects. The visual comparison allows assessment of the quality and creativity of the generated objects, showcasing the method’s strengths and limitations in generating fine-grained details and plausible combinations.
read the caption
(b) PartCraft

🔼 This figure shows multi-view generation results on novel bird species created using interpolation by Chirpy3D. Chirpy3D generates smooth transitions between bird species by blending latent representations of different bird parts. Compared to methods like Textual Inversion and PartCraft, Chirpy3D produces more visually coherent and natural-looking results, demonstrating the effectiveness of its continuous part-aware latent space in creating novel, plausible bird variations.
read the caption
(c) Chirpy3D (Ours)

🔼 This figure compares the results of generating novel bird species using three different methods: Textual Inversion, PartCraft, and Chirpy3D. Each method used the same random seed, but with different randomly sampled part latents. Textual Inversion resulted in incomprehensible images because it directly samples from the word embedding space, which is not sufficient for generating novel species. PartCraft, while generating comprehensible birds, lacked diversity due to its discrete part representation. In contrast, Chirpy3D successfully generated a variety of novel bird species with consistent poses and consistent quality, showcasing the benefits of its continuous part latent space.
read the caption
Figure 18: Multi-view generation on novel species (random sampling), trained with respective methods. All were generated with the same seed but with different sampled part latents. (a) Trained with Textual Inversion, the generated images are often incomprehensible, indicating that direct sampling from word embedding space is insufficient to generate novel species. (b) PartCraft has a non-linear projector to project word embeddings, while able to generate comprehensible objects, but lacking diversity since it is not trained to have a continuous distribution of part latents. (c) Our Chirpy3D not only can generate images of diverse species, also stable in terms of bird pose.

🔼 This figure shows the results of multi-view generation using the Textual Inversion method. The method directly uses textual embeddings without leveraging a continuous latent space. The images generated demonstrate the limitations of this approach, producing images with noticeable artifacts and a lack of diversity compared to other methods.
read the caption
(a) Textual Inversion
Full paper#