↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Current GUI agents struggle with multi-step reasoning and rely heavily on textual annotations, limiting their effectiveness in complex tasks. These agents often lack the ability to reflect on past experiences and adapt to changing situations, leading to errors and inconsistencies. They also tend to rely on additional GUI information, which can lead to information loss or redundancy.
To address these shortcomings, the researchers developed InfiGUIAgent, a multimodal GUI agent trained using a two-stage supervised fine-tuning method. The first stage focuses on enhancing fundamental skills, while the second stage integrates advanced reasoning skills using synthesized data to enable the agent to learn from past experiences and make better decisions. InfiGUIAgent demonstrates competitive performance on standard GUI benchmarks, proving the effectiveness of the proposed method. The modular design allows for flexibility and better adaptation across various platforms.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing GUI agents by introducing InfiGUIAgent, which uses a two-stage training process to improve reasoning abilities. This work is relevant to the current trend of using large language models for automating tasks and opens up new avenues for research in hierarchical and reflective reasoning for GUI interaction. The modular action space design is also significant, improving adaptability and deployment across platforms.
Visual Insights#

🔼 InfiGUIAgent uses a two-stage training process. Stage 1 focuses on fundamental skills like GUI understanding, question answering, and instruction grounding using diverse datasets. Stage 2 introduces advanced reasoning capabilities (hierarchical and expectation-reflection reasoning). During inference, the agent iteratively performs reflection (comparing results to expectations), hierarchical reasoning (strategic and tactical planning), actions, and expectation setting (predicting the next outcome). Each step uses the overall task, past interactions, and current context as input.
read the caption
Figure 1: InfiGUIAgent is trained in two stages. Stage 1 cultivates fundamental abilities using diverse datasets covering GUI understanding (element recognition and layout comprehension), question answering, instruction grounding, general knowledge, and tool usage. Stage 2 introduces native advanced reasoning, employed during both training and inference. This stage follows a cyclical process at each step, consisting of Reflection, Hierarchical Reasoning (strategic and tactical layers), Action, and Expectation. Each step receives the overall task, the history of previous screenshots and reasoning, and the current environment as input. Reflection assesses the previous action’s outcome against its expectation, while Expectation predicts the outcome of the current action for subsequent reflection.
🔼 This table lists the datasets used in Stage 1 of the InfiGUIAgent training process. It details the platform (Webpage, Mobile, or both) each dataset was collected from, the category of the data (GUI Understanding, Grounding, Question Answering, General Knowledge, or Tool Usage), and the number of samples available in each dataset. The datasets cover various aspects of GUI interaction, including visual understanding, task execution, and general knowledge.
read the caption
Table 1: Training datasets used in stage 1 of supervised fine-tuning.
In-depth insights#
GUI Agent Advances#
GUI agent advances are significantly impacting task automation on computing devices. Multimodal large language models (MLLMs) have proven powerful for visual understanding and reasoning within GUIs, enabling complex operations. However, challenges remain. Multi-step reasoning and reliance on textual annotations hinder current agents’ effectiveness. Hierarchical and expectation-reflection reasoning are crucial capabilities for overcoming these limitations, allowing for robust, adaptive, and error-correcting interactions. Future advances will likely focus on refining these reasoning skills through improved training methodologies and dataset design, potentially utilizing techniques such as two-stage supervised fine-tuning and synthesizing data to enhance native reasoning abilities. Addressing the inherent visual nature of GUIs more directly, beyond textual representations, is also key for improved performance and generalization across diverse platforms. Ultimately, the goal is to create more robust, flexible, and human-like GUI agents capable of completing a wider range of tasks with greater efficiency and accuracy.
Two-Stage SFT#
A two-stage supervised fine-tuning (SFT) approach for training a multimodal GUI agent offers a structured way to enhance both fundamental skills and advanced reasoning capabilities. The initial stage focuses on building foundational skills: robust GUI understanding and grounding. This involves training the model on diverse datasets encompassing visual-language understanding, GUI-specific QA, and tool use. The second stage aims to cultivate native advanced reasoning. This is achieved by introducing hierarchical and expectation-reflection reasoning skills. These are integrated into the training data through synthesis, allowing the agent to plan strategically and reflect on previous actions, improving the consistency and effectiveness of complex task execution. This two-stage method avoids the reliance on additional, potentially inconsistent GUI information, like accessibility trees, and allows for more robust generalization. The separation of skill development into distinct stages facilitates a more efficient and targeted training process, ultimately improving the performance and adaptability of the GUI agent.
Reasoning Enhancements#
Reasoning enhancements in AI agents, particularly those interacting with graphical user interfaces (GUIs), are crucial for advancing task automation capabilities. Effective reasoning goes beyond simple, single-step operations; it necessitates multi-step, hierarchical reasoning where an agent breaks down complex tasks into smaller, manageable subtasks. This hierarchical approach allows for strategic planning, enabling the agent to anticipate necessary steps and to adjust its actions based on previous outcomes. Another critical aspect is expectation-reflection reasoning, where the AI agent can predict expected outcomes and reflect on whether the actual results match its expectations. This self-corrective mechanism is essential for robust and reliable performance, as it enables the agent to learn from its mistakes and improve its decision-making. Synthesizing data to incorporate these reasoning skills during training is vital. Creating datasets that include hierarchical plans and expectation-reflection cycles ensures the AI model internalizes these capabilities natively, rather than relying on external prompts or annotations. The challenge lies in generating realistic and representative training data that accurately reflects the complexities of real-world GUI interactions. The success of such enhancements significantly impacts the effectiveness and robustness of AI agents in navigating and automating GUI-based tasks.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would offer a crucial evaluation of the proposed method. It should present a rigorous comparison against existing state-of-the-art techniques on established benchmarks. Ideally, it would include quantitative metrics, like accuracy, precision, recall, and F1-score, clearly demonstrating performance improvements or parity. Statistical significance testing (e.g., t-tests, ANOVA) should be applied to confirm the validity of observed differences. The results should be presented in tables and/or charts for easy readability and comprehension. Furthermore, an insightful discussion of the results is paramount, explaining any unexpected outcomes or limitations. A discussion of the benchmarks’ strengths and weaknesses, and their relevance to the problem at hand, is equally important. Crucially, the paper should provide a detailed analysis of where the proposed method excels and where it falls short compared to existing approaches. This holistic approach gives a comprehensive understanding of the practical impact and limitations of the proposed solution. The discussion must be nuanced, emphasizing both the positive outcomes and potential shortcomings, rather than simply stating the results.
Future Work#
Future work for InfiGUIAgent should prioritize enhancing its robustness and adaptability. Improving the model’s generalization capabilities across diverse GUI platforms and designs is crucial. This includes handling variations in visual styles, layouts, and resolutions, as well as supporting different operating systems and applications. Addressing the limitations in complex reasoning could involve exploring more advanced reasoning techniques such as symbolic reasoning or integrating external knowledge bases. Further investigation into the trade-offs between efficiency and accuracy is needed, potentially through model compression or more efficient training methodologies. Expanding the agent’s capabilities to include broader task domains beyond GUI interactions (e.g., integrating with other modalities like speech or natural language processing) would enhance its versatility. Finally, rigorous testing and evaluation on large-scale, real-world datasets will be necessary to validate the effectiveness and reliability of these improvements.
More visual insights#
More on figures

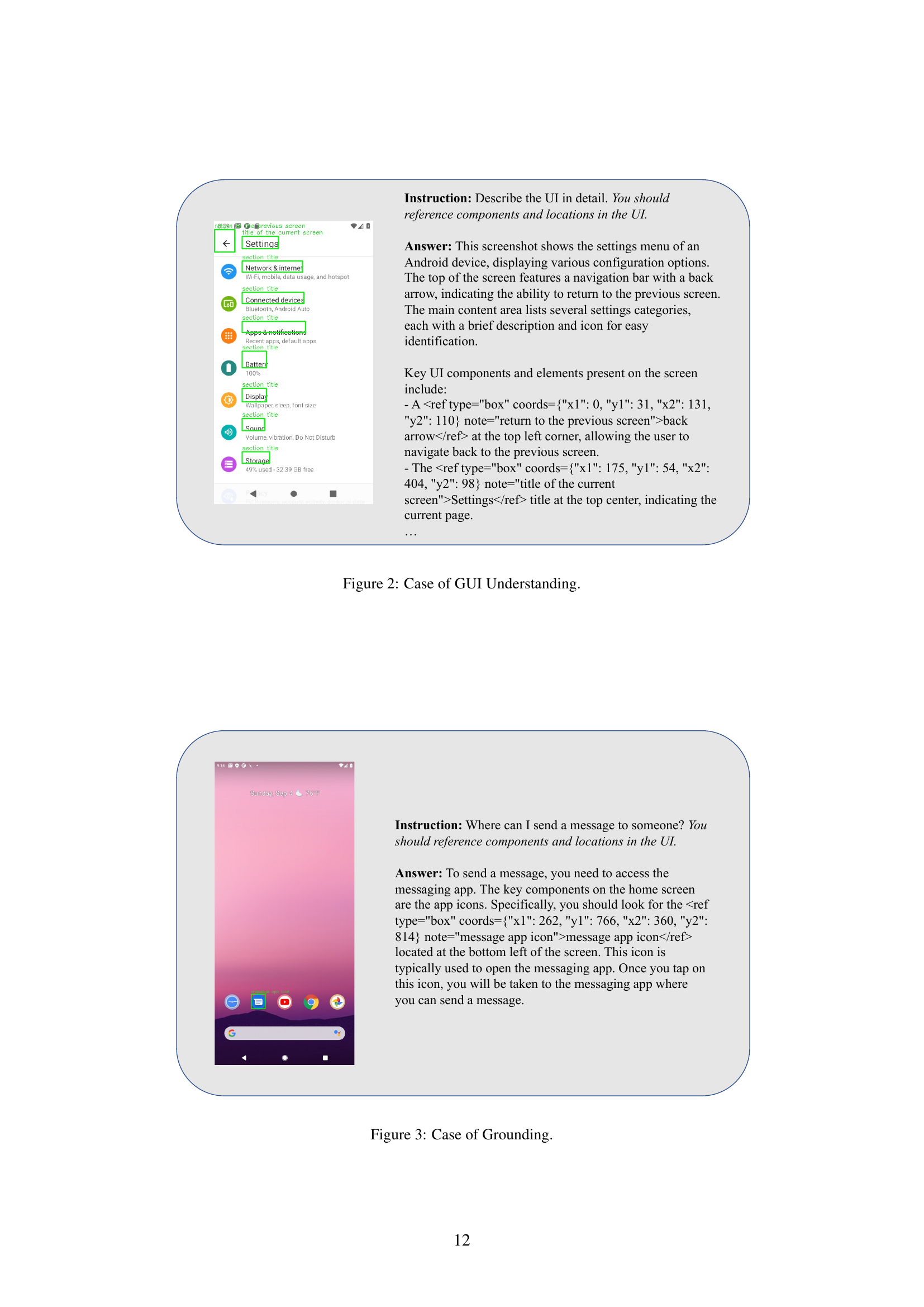
🔼 This figure showcases the InfiGUIAgent’s ability to understand a GUI. The screenshot displays the settings menu of an Android device, and the caption details key UI components and their locations, demonstrating the agent’s capacity to accurately interpret and describe the interface elements.
read the caption
Figure 2: Case of GUI Understanding.

🔼 The figure demonstrates the agent’s ability to ground actions within a GUI. The instruction asks the agent to identify where to send a message. The agent correctly identifies the messaging app icon at the bottom-left of the home screen and explains its function in relation to sending messages.
read the caption
Figure 3: Case of Grounding.

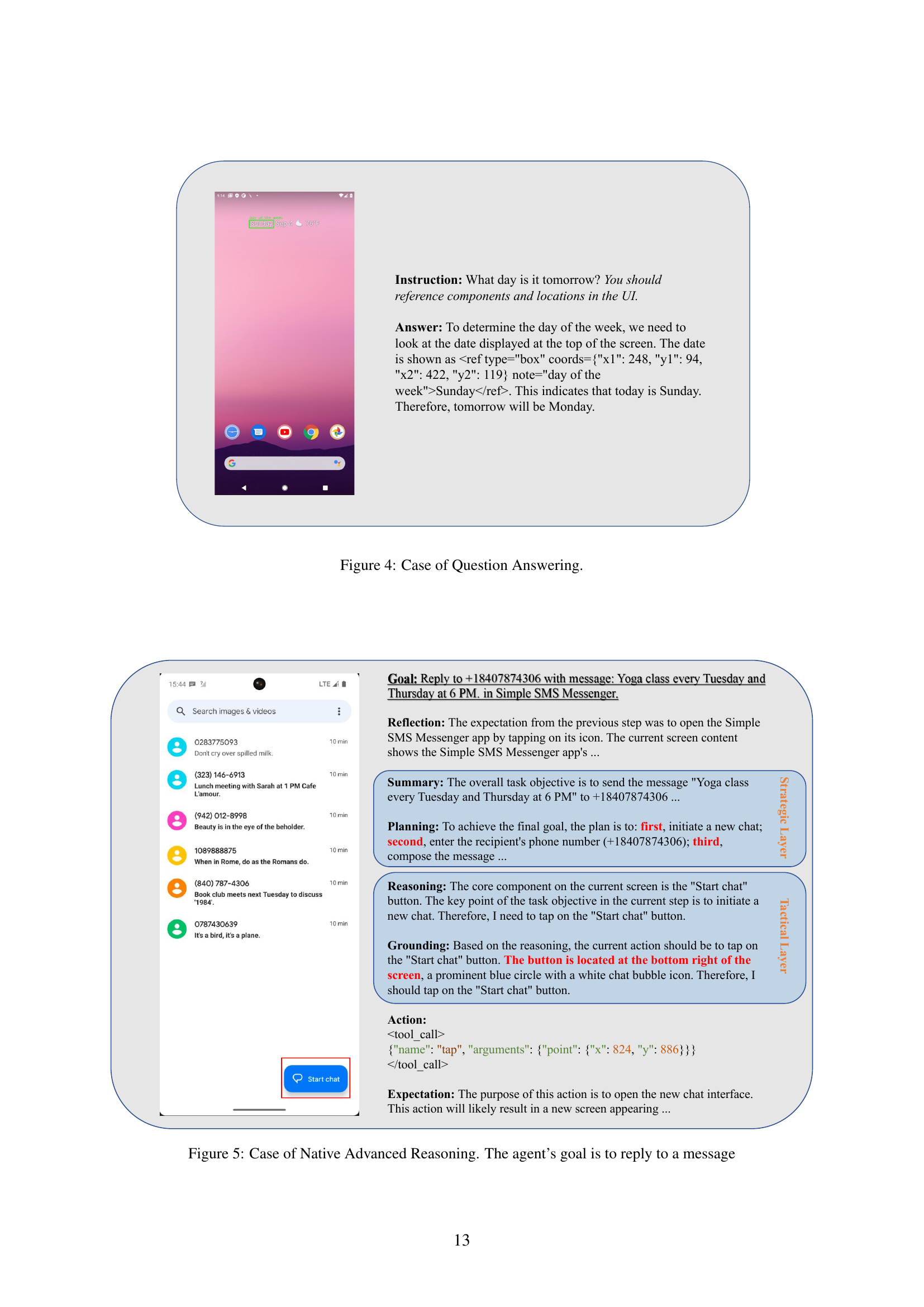
🔼 This figure showcases the InfiGUIAgent’s ability to answer questions based on the visual information provided in a screenshot. The screenshot shows a portion of an Android phone’s home screen displaying the time and date. The question posed is ‘What day is it tomorrow?’, and the model correctly identifies the current day (Sunday) from the screen and answers ‘Monday’. The answer highlights the InfiGUIAgent’s ability to extract relevant information from the visual UI and perform simple reasoning tasks.
read the caption
Figure 4: Case of Question Answering.

🔼 This figure demonstrates the InfiGUIAgent’s advanced reasoning capabilities in a messaging app scenario. The agent must identify the relevant UI element (the ‘Start chat’ button) and perform the correct action (tapping the button) to initiate a reply. The figure displays the agent’s reasoning process, detailing the steps involved: reflection on the previous action, hierarchical reasoning to determine the next steps, and expectation of the outcome. This illustrates the agent’s ability to understand context, plan actions, and adapt its behavior to achieve the goal of replying to a message.
read the caption
Figure 5: Case of Native Advanced Reasoning. The agent’s goal is to reply to a message

🔼 This figure illustrates an example of InfiGUIAgent performing advanced reasoning to achieve the goal of creating a new contact. It shows the agent’s reasoning process, broken down into strategic and tactical layers, as it navigates the phone app’s interface to locate and tap the ‘Contacts’ tab, and subsequently initiates the ‘Create new contact’ process. The steps highlight how the agent uses hierarchical reasoning to decompose the task and combines this with grounding, referencing specific visual elements to perform actions.
read the caption
Figure 6: Case of Native Advanced Reasoning. The agent’s goal is to create a new contact.

🔼 This figure shows a screenshot of a smartphone screen, illustrating the step-by-step process of creating a new contact using InfiGUIAgent. The agent first successfully navigated to the ‘Contacts’ section, and in this specific step (K+1), it proceeds to initiate the process by tapping the ‘Create new contact’ button. This illustrates the agent’s hierarchical reasoning and grounding capabilities by showing the action and its expected outcome within the broader context of creating a contact. Details like the reasoning process, the grounding details of the button’s location and visual features, and the action itself as a JSON formatted instruction, are all displayed in the caption.
read the caption
Figure 7: Case of Native Advanced Reasoning. The agent’s goal is to create a new contact.
More on tables
| Dataset | Platform | Category | # of Samples |
|---|---|---|---|
| GUI-related Datasets | |||
| GUIEnv (Chen et al., 2024) | Webpage | Grounding | 150,000 |
| RICO Semantic Annotation (Sunkara et al., 2022) | Mobile | Grounding | 150,000 |
| SeeClick-Web (Cheng et al., 2024) | Webpage | Grounding | 100,000 |
| RICO SCA (Li et al., 2020a) | Mobile | Grounding | 100,000 |
| Widget Caption (Li et al., 2020b) | Mobile | Grounding | 70,000 |
| GUIChat (Chen et al., 2024) | Webpage | QA | 40,000 |
| ScreenQA (Hsiao et al., 2022) | Mobile | QA | 17,000 |
| UIBert Reference Expression (Bai et al., 2021) | Mobile & Mobile | Grounding | 16,000 |
| Screen2Words (Wang et al., 2021) | Mobile | Understanding | 12,000 |
| Complex QA (Yin et al., 2023) | Mobile | QA | 11,000 |
| Screen Annotation (Baechler et al., 2024) | Mobile | Understanding | 5,400 |
| OmniAct-Single Click (Kapoor et al., 2024) | Webpage & Desktop | Grounding | 4,800 |
| Non-GUI Datasets | |||
| LLaVA-OneVision (Li et al., 2024a) | - | General | 250,000 |
| PixMo (MDeitke et al., 2024) | - | General | 68,800 |
| Glaive-function-calling (Glaive AI, 2024) | - | Tool Usage | 5,000 |
🔼 This table lists the datasets used in Stage 2 of the InfiGUIAgent training process, focusing on enhancing advanced reasoning capabilities. The datasets provide examples of hierarchical and expectation-reflection reasoning, crucial for effective GUI interaction. Each dataset includes information on the platform (Webpage or Mobile) and the number of samples provided, contributing to the agent’s ability to perform complex multi-step tasks.
read the caption
Table 2: UI action reasoning datasets used in the training process
| Dataset | Platform | # of Samples |
|---|---|---|
| GUIAct (Chen et al., 2024) | Webpage & Mobile | 10,000 |
| AMEX (Chai et al., 2024) | Mobile | 3,000 |
| Android in the Zoo (Zhang et al., 2024a) | Mobile | 2,000 |
| Composition: Stage 1-aligned | - | 30,000 |
🔼 This table categorizes the different types of actions that an agent can take within the GUI environment. It breaks down actions into six categories based on their characteristics: single-point operations (e.g., tap, click), two-point operations (e.g., swipe, select text), directional operations (e.g., scroll), text input operations, parameterless operations (e.g., remember, enter), and state settings (e.g., set task status). Each category lists specific examples of actions it includes. This provides a structured understanding of the action space available to the GUI agent, showing how various interactions are classified and what parameters they may take.
read the caption
Table 3: Categorization of actions in the action space.
| Category | Operations |
|---|---|
| Single-point operations | tap, click, hover, select |
| Two-point operations | swipe, select_text |
| Directional operations | scroll |
| Text input | input, point_input |
| Parameterless operations | remember, enter, home, back |
| State settings | set_task_status |
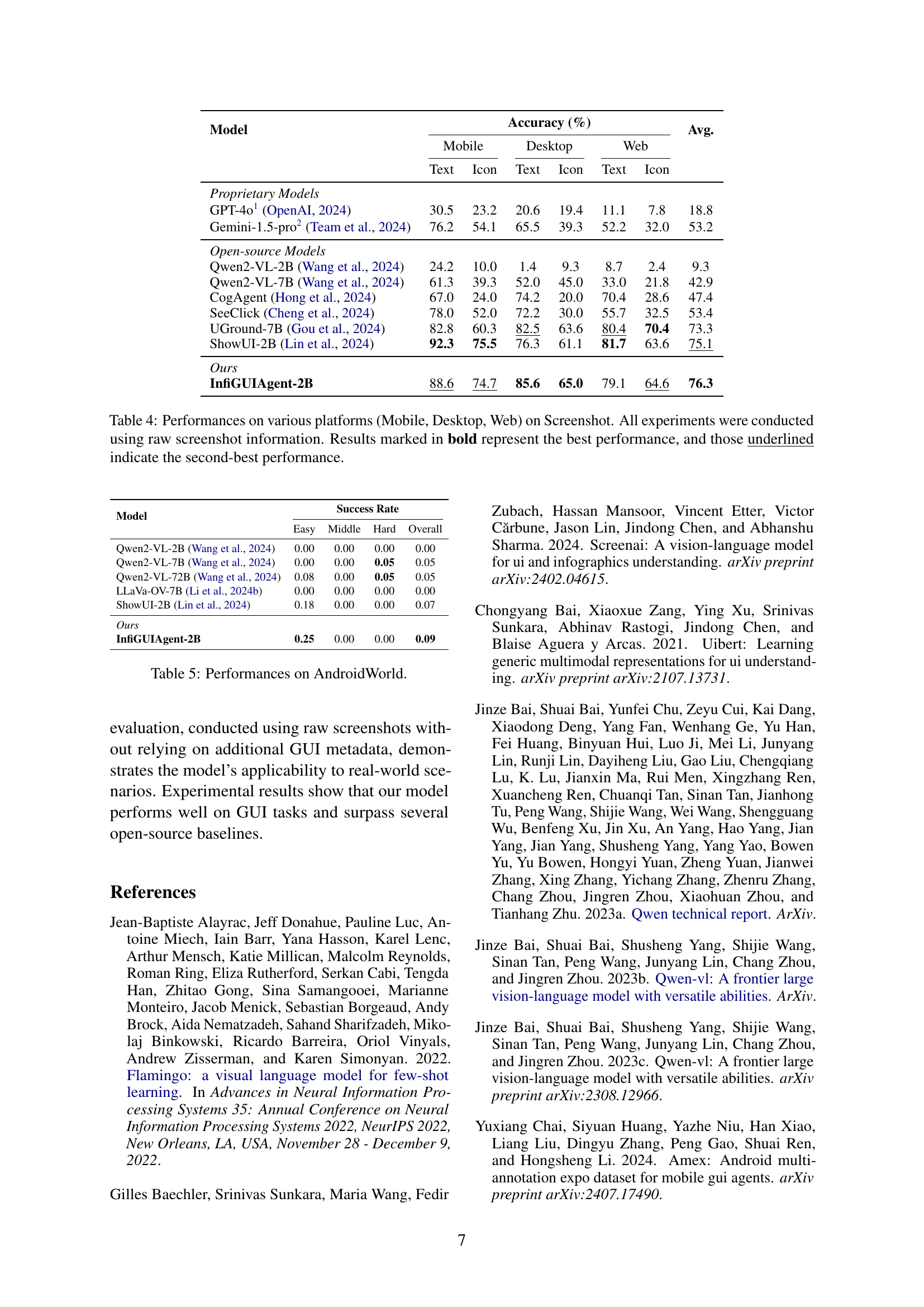
🔼 This table presents a comparison of the performance of different models on the ScreenSpot benchmark across various platforms (Mobile, Desktop, and Web) and for different element types (Text and Icon). The accuracy of each model is evaluated using raw screenshot information, without any additional metadata or augmentations. The best performing model for each category is highlighted in bold, while the second-best is underlined. This highlights the effectiveness of the models in understanding and interacting with graphical user interfaces on different device types.
read the caption
Table 4: Performances on various platforms (Mobile, Desktop, Web) on Screenshot. All experiments were conducted using raw screenshot information. Results marked in bold represent the best performance, and those underlined indicate the second-best performance.
| Model | Mobile Text | Mobile Icon | Desktop Text | Desktop Icon | Web Text | Web Icon | Avg. |
|---|---|---|---|---|---|---|---|
| Proprietary Models | |||||||
| GPT-4o1 (OpenAI, 2024) | 30.5 | 23.2 | 20.6 | 19.4 | 11.1 | 7.8 | 18.8 |
| Gemini-1.5-pro2 (Team et al., 2024) | 76.2 | 54.1 | 65.5 | 39.3 | 52.2 | 32.0 | 53.2 |
| Open-source Models | |||||||
| Qwen2-VL-2B (Wang et al., 2024) | 24.2 | 10.0 | 1.4 | 9.3 | 8.7 | 2.4 | 9.3 |
| Qwen2-VL-7B (Wang et al., 2024) | 61.3 | 39.3 | 52.0 | 45.0 | 33.0 | 21.8 | 42.9 |
| CogAgent (Hong et al., 2024) | 67.0 | 24.0 | 74.2 | 20.0 | 70.4 | 28.6 | 47.4 |
| SeeClick (Cheng et al., 2024) | 78.0 | 52.0 | 72.2 | 30.0 | 55.7 | 32.5 | 53.4 |
| UGround-7B (Gou et al., 2024) | 82.8 | 60.3 | 82.5 | 63.6 | 80.4 | 70.4 | 73.3 |
| ShowUI-2B (Lin et al., 2024) | 92.3 | 75.5 | 76.3 | 61.1 | 81.7 | 63.6 | 75.1 |
| Ours | |||||||
| InfiGUIAgent-2B | 88.6 | 74.7 | 85.6 | 65.0 | 79.1 | 64.6 | 76.3 |
🔼 This table presents a comparison of the success rates achieved by different models on the AndroidWorld benchmark. The benchmark consists of 116 programmatic tasks across 20 real-world Android applications. The table shows the success rates broken down by task difficulty level (Easy, Middle, Hard) for several models including InfiGUIAgent, as well as several open-source baselines. The overall success rate is also shown for each model. Note that the experiments were conducted using raw screenshots without any additional GUI metadata.
read the caption
Table 5: Performances on AndroidWorld.
Full paper#