↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Single-image 3D reconstruction is challenging due to limitations of existing methods. Regression-based methods are fast but struggle with occluded regions, while generative methods are accurate but computationally expensive and often misaligned with visible surfaces. The problem is tackled by a new two-stage approach that combines both methods’ strengths.
The proposed method, SPAR3D, first utilizes a lightweight point diffusion model to generate a sparse 3D point cloud quickly. Then, it employs a meshing stage that refines this point cloud using image data to create highly detailed meshes, enabling probabilistic modeling while maintaining efficiency. This design allows for interactive edits, showcasing superior performance on various datasets with a remarkable inference speed of 0.7 seconds.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SPAR3D, a novel and efficient method for 3D object reconstruction from single images. Its two-stage approach, combining point cloud generation with mesh refinement, significantly outperforms existing methods in accuracy and speed. This opens avenues for applications in AR/VR, 3D modeling and other fields needing efficient 3D asset creation.
Visual Insights#

🔼 This figure showcases SPAR3D’s capabilities by presenting six example images. Each example shows the input image, the generated point cloud, and the resulting 3D mesh. This highlights SPAR3D’s ability to create high-quality 3D meshes from single images quickly (0.7 seconds) and allows for interactive user edits. The images demonstrate a variety of objects, illustrating the model’s versatility and robustness.
read the caption
Figure 1: We present SPAR3D, a state-of-the-art 3D reconstructor that reconstructs high-quality 3D meshes from single-view images. SPAR3D enjoys a fast reconstruction speed at 0.7 seconds and supports interactive user edits.
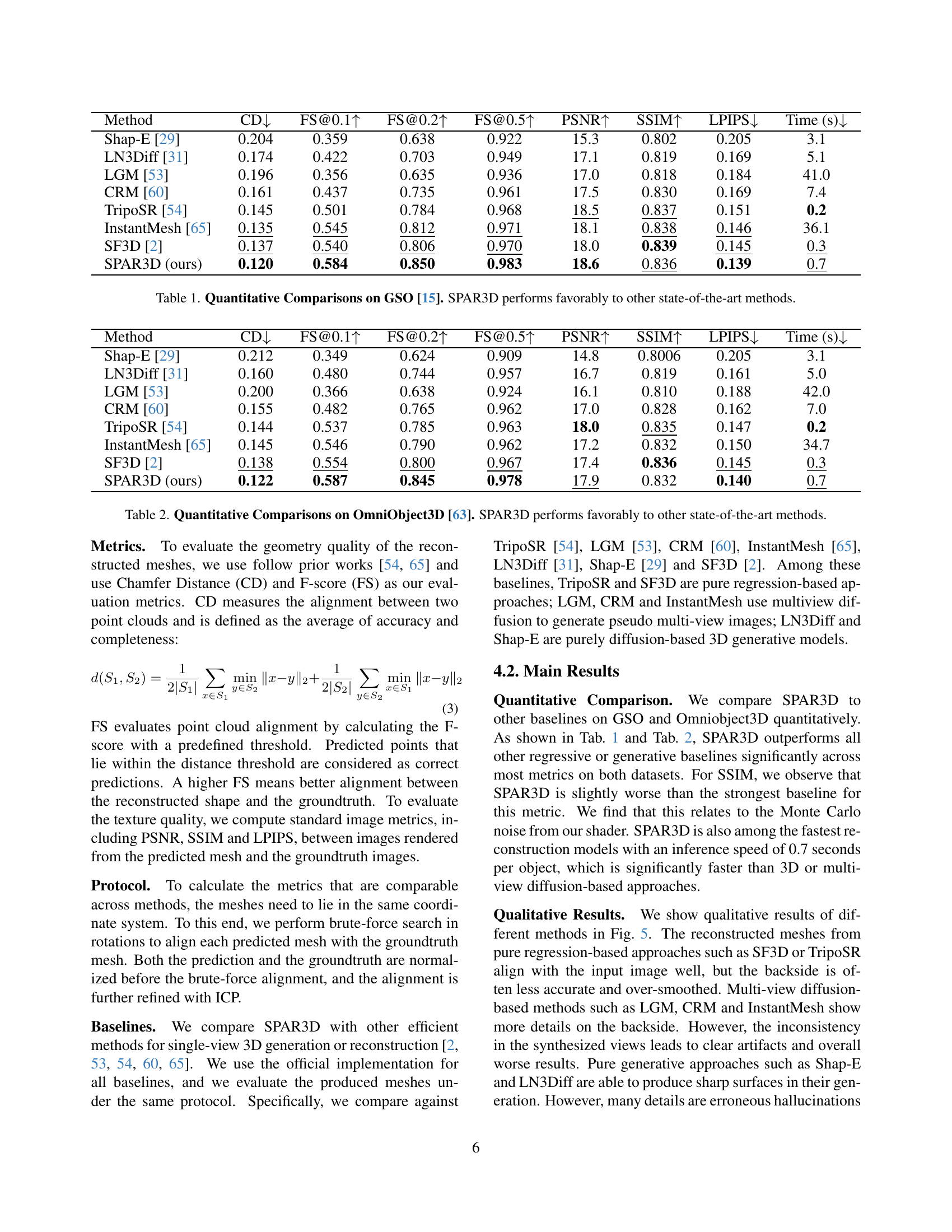
| Method | CD ↓ | FS@0.1 ↑ | FS@0.2 ↑ | FS@0.5 ↑ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | Time (s) ↓ |
|---|---|---|---|---|---|---|---|---|
| Shap-E [29] | 0.204 | 0.359 | 0.638 | 0.922 | 15.3 | 0.802 | 0.205 | 3.1 |
| LN3Diff [31] | 0.174 | 0.422 | 0.703 | 0.949 | 17.1 | 0.819 | 0.169 | 5.1 |
| LGM [53] | 0.196 | 0.356 | 0.635 | 0.936 | 17.0 | 0.818 | 0.184 | 41.0 |
| CRM [60] | 0.161 | 0.437 | 0.735 | 0.961 | 17.5 | 0.830 | 0.169 | 7.4 |
| TripoSR [54] | 0.145 | 0.501 | 0.784 | 0.968 | 18.5 | 0.837 | 0.151 | 0.2 |
| InstantMesh [65] | 0.135 | 0.545 | 0.812 | 0.971 | 18.1 | 0.838 | 0.146 | 36.1 |
| SF3D [2] | 0.137 | 0.540 | 0.806 | 0.970 | 18.0 | 0.839 | 0.145 | 0.3 |
| SPAR3D (ours) | 0.120 | 0.584 | 0.850 | 0.983 | 18.6 | 0.836 | 0.139 | 0.7 |
🔼 Table 1 presents a quantitative comparison of SPAR3D’s performance against other state-of-the-art single-image 3D reconstruction methods on the GSO dataset [15]. The comparison uses several metrics to assess both geometric accuracy (Chamfer Distance, F-score at different thresholds) and visual fidelity (PSNR, SSIM, LPIPS). The inference time for each method is also reported. The results demonstrate that SPAR3D achieves a favorable balance between accuracy, visual quality, and computational efficiency.
read the caption
Table 1: Quantitative Comparisons on GSO [15]. SPAR3D performs favorably to other state-of-the-art methods.
In-depth insights#
Spar3D: 2-Stage Approach#
SPAR3D’s two-stage approach offers a compelling solution to the challenges of single-image 3D reconstruction. The initial stage leverages a lightweight point diffusion model to generate sparse 3D point clouds, efficiently capturing the object’s overall shape and probabilistic uncertainties. This is crucial as it allows for fast sampling, addressing the computational limitations of existing diffusion-based methods. The subsequent meshing stage refines the initial point cloud with high-fidelity details, utilizing the input image and the generated point cloud. This two-pronged approach is highly effective as it combines the speed of regression-based methods with the handling of uncertainty inherent in generative models. The use of point clouds as an intermediary representation is a key innovation, enabling both efficient processing and intuitive user interaction through direct manipulation of the low-resolution point cloud before meshing. This innovative combination of speed and accuracy makes SPAR3D a significant advancement, surpassing the performance of existing methods while maintaining excellent efficiency.
Point Cloud Sampling#
The point cloud sampling stage is a critical component of the proposed SPAR3D framework, focusing on generating sparse 3D point clouds from a single image input. This is achieved using a lightweight point diffusion model, which offers a significant speed advantage over traditional methods. The sparse nature of the point clouds is intentional, enabling faster sampling while still providing sufficient information for the subsequent meshing stage. This design cleverly balances speed and information content, avoiding computationally expensive high-resolution sampling characteristic of some generative approaches. The use of point clouds as an intermediate representation offers another key advantage: interactive user edits. The low resolution makes point cloud manipulation intuitive and efficient. The generated point cloud informs the subsequent meshing stage which enhances detail and accuracy by integrating local image features, resolving ambiguity issues often encountered with other single-image 3D reconstruction methods. This two-stage approach addresses the limitations of purely regression-based or purely generative methods by leveraging the strengths of both. The point diffusion model’s probabilistic nature addresses uncertainty inherent in single-view reconstruction, unlike regression methods which assume a bijective mapping that struggles with occluded regions. Ultimately, the point cloud sampling stage significantly contributes to SPAR3D’s overall efficiency, scalability, and editing capabilities.
Meshing via Triplanes#
Meshing via triplanes offers a novel approach to 3D reconstruction by leveraging the power of image features and sparse point clouds. Triplanes’ inherent structure allows for efficient encoding of high-resolution 3D information, leading to improved mesh quality and reduced computational cost compared to voxel- or point-based methods. By using triplanes, the method achieves high-fidelity detail in the resulting meshes, and the representation facilitates the incorporation of both local image context and global spatial relationships from the point cloud. This dual-pronged approach results in improved accuracy, particularly for complex objects with significant occlusions or challenging viewpoints. The two-stage process (point cloud generation followed by triplane-based mesh refinement) effectively manages uncertainty, enabling high-quality mesh reconstruction while maintaining computational efficiency. The choice of triplanes allows seamless integration with a differentiable renderer, further enhancing the training process and improving the final mesh quality. The architecture’s design suggests a promising direction for efficient and accurate 3D reconstruction from sparse, noisy data.
Interactive Mesh Editing#
The concept of “Interactive Mesh Editing” in the context of single-image 3D reconstruction is a significant advancement. It highlights the practical implications of using a two-stage approach (point cloud generation followed by meshing). The intermediate point cloud representation is crucial; its low resolution enables efficient user interaction, allowing for modifications without the computational overhead of directly manipulating high-resolution meshes. This is particularly valuable for addressing imperfections or inaccuracies in the reconstructed model, especially in occluded regions. The ability to easily add, remove, or reposition points translates directly to intuitive adjustments in the final 3D mesh. Furthermore, the fact that this editing occurs in a rapid timeframe (0.3 seconds) underscores the practical usability of this approach, potentially making the technology accessible for non-expert users. This interactivity is a powerful feature, bridging the gap between automatic 3D reconstruction and the need for manual refinement, and potentially opening up new applications in fields like augmented reality, 3D modeling, and animation. The ability to edit point clouds enables users to refine models in real-time, improving accuracy and making the system more user-friendly.
Future Research#
Future research directions stemming from this work on single-image 3D reconstruction could explore several promising avenues. Improving the robustness and quality of the point cloud generation is crucial, perhaps by exploring alternative diffusion models or incorporating additional cues from the input image. Addressing the ambiguity inherent in inverse rendering during material decomposition, potentially through semi-supervised learning or incorporating physically-based priors, would also significantly enhance the realism of the generated meshes. Investigating more sophisticated and efficient meshing strategies, such as adaptive mesh refinement, is another key area. Finally, exploring novel interaction paradigms that leverage the point cloud representation for more intuitive and powerful user editing capabilities presents a fascinating opportunity. Extending the approach to handle more complex scenes and object categories is another goal. The development of a benchmark dataset specifically designed for evaluating the various aspects of single-image 3D reconstruction, such as geometry, texture, and material accuracy, would be highly valuable to the research community.
More visual insights#
More on figures

🔼 SPAR3D is a two-stage method. First, a point diffusion model processes the input image to generate a sparse point cloud. Second, a triplane transformer uses this point cloud and image features to create high-resolution triplane features. These features are then used to reconstruct the 3D object’s geometry, texture, and illumination.
read the caption
Figure 2: SPAR3D Overview. Conditioned on the input image, SPAR3D first leverages a point diffusion model to generate a sparse point cloud. The triplane transformer then uses the sampled point cloud and image features to produce high-resolution triplane features. The triplane features are then queried to reconstruct the geometry, texture, and illumination of the object in the image.

🔼 This figure details the differentiable renderer used in the SPAR3D model. The process begins by estimating geometry, albedo, lighting, and normal maps using the triplane features and metallic/roughness values derived from the input image. These estimations are then rasterized and interpolated before being fed into a custom shader (based on Disney’s BRDF). The shader uses Monte Carlo integration for improved accuracy and includes visibility testing to enhance shadow modeling. Finally, the rendered image is compared against a ground truth image to calculate a rendering loss that is minimized during training, ensuring the model’s output aligns with reality.
read the caption
Figure 3: Our Differentiable Renderer. We estimate geometry, albedo, lighting, and normal maps from the triplane and metallic/roughness values from the image. We rasterize and interpolate these values as input to our shader (omitted here for simplicity). Our shader uses the Disney BRDF [3] and performs Monte Carlo integration. We further perform visibility testing to improve shadow modeling. Finally, we compare the rendered image with the GT image and minimize the rendering loss.

🔼 This figure illustrates the shadow modeling technique used in the SPAR3D model. A ray is cast from the camera through each pixel. The depth of each point along the ray is compared to the depth stored in the depth map, which represents the distances to the closest visible surface. If the ray intersects a point whose depth is greater than the depth in the depth map, it implies that the point is occluded, and thus shadowed. This visibility test is performed in screen space, making it computationally efficient.
read the caption
Figure 4: Shadow Modeling. We perform visibility testing in screen-space by marching along sampled rays. If any point along the ray has a ray depth which is farther away than the depth map, we consider the entire ray as shadowed.

🔼 Figure 5 presents a visual comparison of 3D reconstruction results from SPAR3D and several state-of-the-art methods. Each row shows the input image followed by the 3D mesh reconstruction from different methods. The comparison highlights that SPAR3D not only accurately reconstructs the visible parts of objects, as shown in the input images, but also produces superior quality geometry and textures, especially for the portions of the objects that are not directly visible in the image.
read the caption
Figure 5: Qualitative Comparison. We compare SPAR3D to other state-of-the-art methods visually. SPAR3D not only aligns better with the visible surfaces from images, but also generates higher-quality geometries and textures for the occluded surfaces.

🔼 Figure 6 presents a qualitative evaluation of SPAR3D’s generalization capabilities. The top two rows showcase 3D reconstructions from images generated by 2D generative models, illustrating how well SPAR3D handles diverse and complex input styles beyond the controlled datasets used for training. The bottom two rows demonstrate reconstructions from ImageNet images, further expanding the range of tested image types. In all cases, the generated 3D meshes accurately reflect the objects’ geometric details and textures, even for occluded parts not directly visible in the 2D input. This successful reconstruction across a wide variety of image sources highlights SPAR3D’s robustness and strong generalization performance.
read the caption
Figure 6: Generalization Results. We show qualitative results of SPAR3D on in-the-wild images from 2D generative models (top 2 rows) and ImageNet (bottom 2 rows). The reconstructed meshes exhibit accurate geometric structures with great textures, demonstrating a strong generalization performance of SPAR3D.

🔼 This figure showcases the interactive editing capabilities of SPAR3D. The left side demonstrates adding features (a handle to a mug, a tail to an elephant) by duplicating existing points in the sparse point cloud. The right side shows how imperfections are fixed and fine details are improved by manipulating points (moving or deleting them). The entire editing process, done in Blender, takes under a minute.
read the caption
Figure 7: Editing Results. We show qualitative examples of interactive editing with SPAR3D. On the left two examples, we add a handle to the mug and a tail to the elephant doll by duplicating existing points. On the right two examples, we move or delete points to fix imperfections and to improve local details on the mesh. All the edits are performed in Blender within a minute.

🔼 This figure demonstrates the robustness of the SPAR3D model when presented with conflicting information from the input image and the point cloud. The input consists of an image of a squirrel and a point cloud of a horse. The resulting 3D mesh generated by SPAR3D prioritizes the image data for the visible surface, accurately representing the squirrel. However, the back surface, which is not visible in the image, is generated using information from the horse point cloud. This highlights the model’s ability to integrate cues selectively from multiple sources to create a coherent and accurate 3D reconstruction, even when those cues are contradictory. The resulting mesh shows a squirrel from the front, but the back side appears more horse-like.
read the caption
Figure 8: Generated Mesh with Conflicting Cues. Under conflicting cues from images and point clouds, our model reconstructs the visible surface based on the image, while generating the backside surface based on the point cloud.

🔼 Figure 9 presents a comparison of albedo and relighting results between SPAR3D and SF3D. The comparison highlights that SPAR3D produces albedo estimations with less baked-in lighting than SF3D. This leads to more realistic and improved relighting outcomes when using SPAR3D’s albedo estimations.
read the caption
Figure 9: Decomposition and Relighting Results. We show decomposed albedo and relighting results of SPAR3D in comparison with SF3D. The albedo estimated by SPAR3D has less baked-in lighting compared with SF3D and results in better relighting outcomes.
More on tables
| Method | CD ↓ | FS@0.1 ↑ | FS@0.2 ↑ | FS@0.5 ↑ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | Time (s) ↓ |
|---|---|---|---|---|---|---|---|---|
| Shap-E [29] | 0.212 | 0.349 | 0.624 | 0.909 | 14.8 | 0.8006 | 0.205 | 3.1 |
| LN3Diff [31] | 0.160 | 0.480 | 0.744 | 0.957 | 16.7 | 0.819 | 0.161 | 5.0 |
| LGM [53] | 0.200 | 0.366 | 0.638 | 0.924 | 16.1 | 0.810 | 0.188 | 42.0 |
| CRM [60] | 0.155 | 0.482 | 0.765 | 0.962 | 17.0 | 0.828 | 0.162 | 7.0 |
| TripoSR [54] | 0.144 | 0.537 | 0.785 | 0.963 | 18.0 | 0.835 | 0.147 | 0.2 |
| InstantMesh [65] | 0.145 | 0.546 | 0.790 | 0.962 | 17.2 | 0.832 | 0.150 | 34.7 |
| SF3D [2] | 0.138 | 0.554 | 0.800 | 0.967 | 17.4 | 0.836 | 0.145 | 0.3 |
| SPAR3D (ours) | 0.122 | 0.587 | 0.845 | 0.978 | 17.9 | 0.832 | 0.140 | 0.7 |
🔼 Table 2 presents a quantitative comparison of SPAR3D’s performance against other state-of-the-art methods on the OmniObject3D dataset [63]. The comparison uses several metrics to evaluate the quality of 3D mesh reconstruction, including Chamfer Distance (CD), F-score (FS) at different thresholds (0.1, 0.2, 0.5), Peak Signal-to-Noise Ratio (PSNR), Structural SIMilarity index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and inference time. Lower CD and LPIPS values are better, while higher values for the rest indicate superior performance. The results demonstrate that SPAR3D achieves favorable performance compared to other methods across most metrics, indicating its effectiveness in generating high-quality 3D mesh reconstructions.
read the caption
Table 2: Quantitative Comparisons on OmniObject3D [63]. SPAR3D performs favorably to other state-of-the-art methods.
| Method | CD ↓ | FS@0.1 ↑ | PSNR ↑ | LPIPS ↓ |
|---|---|---|---|---|
| SPAR3D w/o Point | 0.136 | 0.506 | 18.5 | 0.146 |
| SPAR3D | 0.120 | 0.584 | 18.6 | 0.139 |
| SPAR3D w/o Point | 0.140 | 0.509 | 17.8 | 0.146 |
| SPAR3D | 0.122 | 0.587 | 17.9 | 0.140 |
🔼 This ablation study investigates the impact of removing the point sampling stage from the SPAR3D model. The table presents quantitative results on the GSO and OmniObject3D datasets, measuring Chamfer Distance (CD), F-score (FS@0.1, FS@0.2, FS@0.5), Peak Signal-to-Noise Ratio (PSNR), and Learned Perceptual Image Patch Similarity (LPIPS). By comparing the performance of the complete SPAR3D model with a variant lacking the point sampling stage, the study demonstrates the significant contribution of this stage to the model’s overall accuracy and efficiency.
read the caption
Table 3: Ablation Study on GSO (top 2 rows) and Omniobject3D (bottom 2 rows). Removing the point sampling stage leads to significant performance drop.
Full paper#