↗ arXiv ↗ Hugging Face ↗ Papers with Code
TL;DR#
Research in computational linguistics has predominantly focused on high-resource languages, neglecting historically significant yet under-resourced languages such as historical Turkish. This has led to a scarcity of annotated datasets and trained models essential for various natural language processing (NLP) tasks. This severely limits the application of advanced NLP techniques to historical Turkish texts.
This paper addresses this gap by introducing the first NER dataset (HisTR), the first Universal Dependencies treebank (OTA-BOUN), and a clean corpus (OTC) of historical Turkish texts, alongside transformer-based models trained on these new resources for NER, dependency parsing, and POS tagging. The study demonstrates significant improvements in the computational analysis of historical Turkish, offering valuable benchmarks and resources for the NLP community while highlighting challenges such as domain adaptation and language variations across time periods. All resources and models are publicly available.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical lack of resources for processing historical Turkish, a language with limited digital resources. It provides valuable datasets and models, opening new avenues for research on low-resource historical language processing and impacting related fields like digital humanities and computational linguistics.
Visual Insights#

🔼 This figure shows a sample of text from the Servet-i Funun journal, a historical Turkish magazine published between 1896 and 1901. The text is presented in two forms: the original Perso-Arabic script and a transliteration using the modern Turkish alphabet. This demonstrates the challenges involved in processing historical Turkish texts due to the use of a different script and significant differences between the historical and modern forms of the language.
read the caption
Figure 1: Transcription of an excerpt from the original document which is written with the Perso-Arabic script.
| Partition | # of Sentences | PERSON Counts | LOCATION Counts |
|---|---|---|---|
| Training set | 462 | 264 | 584 |
| Development set | 200 | 122 | 210 |
| Ruznamçe test set | 150 | 265 | 216 |
| Total | 812 | 651 | 1,010 |
🔼 This table presents the distribution of sentences in the HisTR (Historical Turkish Named Entity Recognition) dataset across different partitions: training set, development set, and two test sets (one for general evaluation and another specifically designed to test robustness on a more challenging historical text type). For each partition, it shows the total number of sentences and the counts of sentences containing PERSON and LOCATION entities. This breakdown allows readers to assess the size and composition of the dataset used for training and evaluating the named entity recognition models.
read the caption
Table 1: Partitions in the HisTR dataset
In-depth insights#
HisTR NER Dataset#
The HisTR NER dataset represents a significant contribution to the field of historical Turkish natural language processing (NLP). Its creation addresses a critical gap in available resources for this under-resourced language. Manually annotated, HisTR provides a high-quality dataset for training and evaluating named entity recognition (NER) models specifically designed for historical Turkish. The dataset’s focus on the Ottoman era, coupled with its inclusion of diverse text types, contributes to its potential for robust model development. However, its relatively small size compared to modern NER datasets could limit the performance of more complex, data-hungry models. Furthermore, the annotation process itself, which involves manually tagging entities such as persons and locations, is labor-intensive and prone to biases. These challenges highlight the need for future research to expand upon HisTR, perhaps with the incorporation of more data or the application of techniques like active learning and data augmentation to maximize its utility for future NLP endeavors.
OTA-BOUN Treebank#
The creation of the OTA-BOUN treebank represents a significant contribution to the field of historical Turkish NLP. Manually annotated, it offers a crucial resource for syntactic analysis, enabling deeper investigation into historical linguistic structures. The treebank’s inclusion of sentences in both Latin-based and Perso-Arabic scripts adds valuable linguistic diversity. However, its relatively small size presents limitations, highlighting the need for more extensive annotation efforts. The annotation process itself faced challenges due to inconsistencies in historical spelling and the use of archaic terminology, demonstrating the complexity of working with such texts. The challenges underscore the need for ongoing development and expansion of the treebank to enhance its value as a benchmark for future NLP research and development in historical Turkish. The availability of this dataset, along with analysis tools and insights into the challenges of annotation, is vital for the advancement of the field. Its use in benchmarking and training new models is a clear testament to its importance.
Historical Turkish NLP#
The field of Historical Turkish NLP presents unique challenges due to the significant linguistic and orthographic changes the language underwent over centuries. Unlike modern standardized languages, historical Turkish exhibits substantial variations in vocabulary, grammar, and script (Arabic vs. Latin), making it difficult for standard NLP models to process effectively. Existing resources are extremely scarce, and the available data is often noisy and incomplete due to the challenges in digitizing and transcribing historical documents. The research highlights the crucial need for creating specialized datasets and models, focusing on areas like named entity recognition (NER), dependency parsing, and part-of-speech tagging for historical Turkish texts. This work makes a substantial contribution by introducing novel resources (HisTR, OTA-BOUN, OTC), establishing the baseline for future advancements and providing open-source tools to facilitate this development.
Model Fine-tuning#
Model fine-tuning in this research paper is a crucial aspect that deserves in-depth analysis. The authors intelligently leverage pre-trained language models, acknowledging the limitations of training from scratch with limited data. The choice to fine-tune existing models is a pragmatic and efficient approach, allowing them to build upon the substantial knowledge embedded within those models. The fine-tuning process, applied to various tasks like NER and dependency parsing, showcases the models’ adaptability to the nuances of historical Turkish. However, the results reveal the challenges of achieving optimal performance with limited historical data. While the models demonstrate strong capabilities, the discrepancy between in-domain and out-of-domain performance underscores the need for more extensive data to improve the generalization of these models. The investigation into the impact of varying training data sizes and combinations highlights the importance of balancing data quantity and quality in fine-tuning. This research effectively showcases both the potential and limitations of fine-tuning pre-trained models in a low-resource language setting, offering valuable insights for future work in this field.
Future Directions#
Future research should prioritize expanding the datasets used in this study. Larger, more diverse datasets spanning broader time periods and genres of historical Turkish texts are crucial for improving the accuracy and robustness of NLP models. Further investigation into the impact of different pre-training strategies, including multilingual and domain-specific approaches, is needed to optimize model performance for historical Turkish. The development of novel techniques to address the specific challenges presented by historical texts, such as noisy OCR data and varying linguistic features, is another key area of focus. Finally, there’s a significant opportunity to explore the integration of historical Turkish NLP with other digital humanities tools and resources to facilitate more comprehensive historical research. This interdisciplinary approach could uncover valuable insights into various fields of study, such as history, literature, and linguistics, broadening the reach and impact of this research significantly.
More visual insights#
More on figures

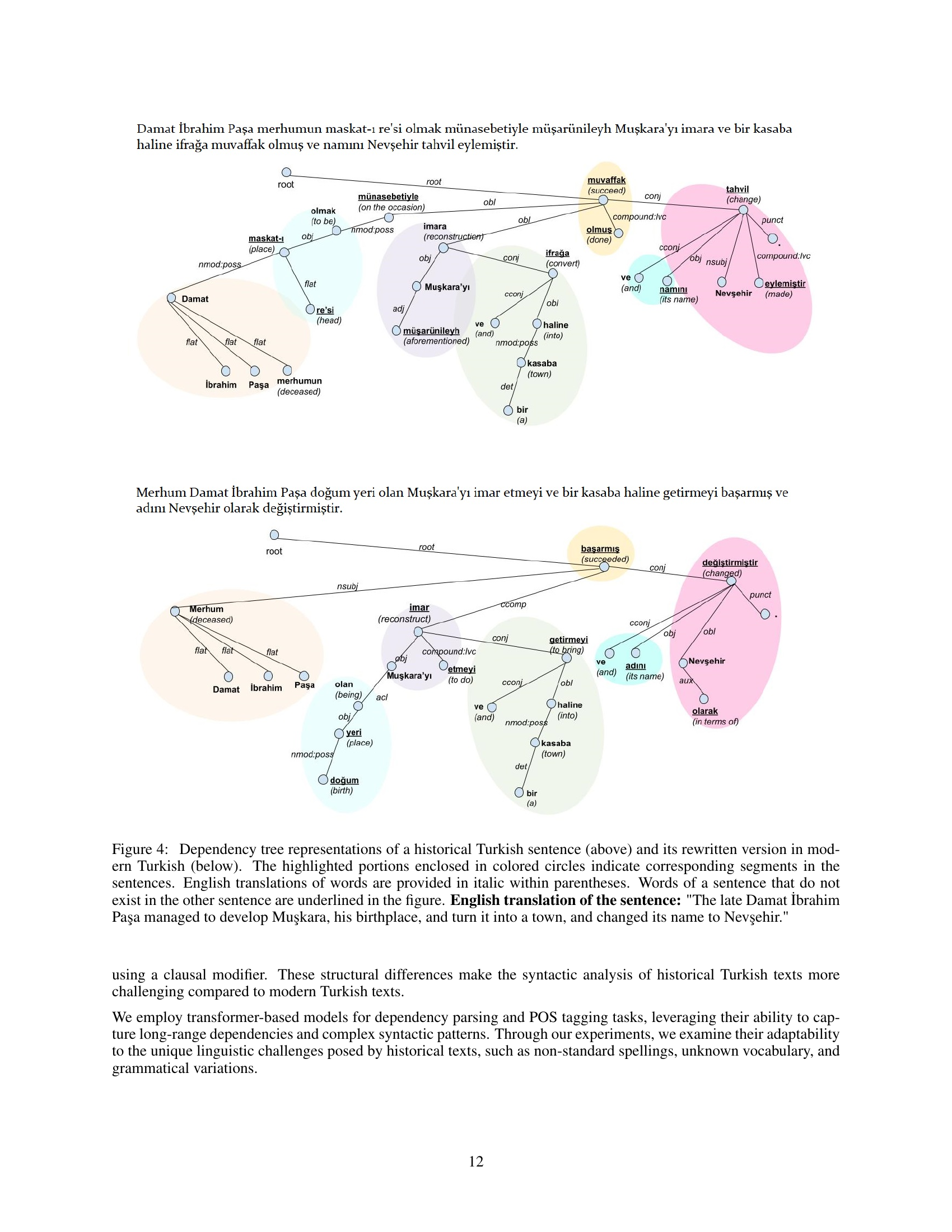
🔼 This figure displays a sample sentence from the OTA-BOUN historical Turkish treebank in the CoNLL-U format. CoNLL-U (CoNLL Universal) is a standard format for representing linguistic annotations, particularly dependency parsing. The table shows each word (token) of the sentence, its part-of-speech tag (POS), its morphological features, and its dependency relation to other words in the sentence. The first column is the index of the word in the sentence. The second column provides the word itself written in the Latin alphabet (a transliteration of the original historical Turkish). The third column shows its part-of-speech tag and morphological features. The last column presents the word in the original Perso-Arabic script used in historical Turkish. The dependency relations are shown via the ‘HEAD’ column, where the index of the head word each word depends on is specified. This detailed annotation makes this figure a useful example of the rigorous annotation process involved in creating the treebank, illustrating the complexity and detail captured in the historical Turkish dataset.
read the caption
Figure 2: CoNLL-U Representation of an example sentence from our OTA-BOUN historical Turkish treebank.

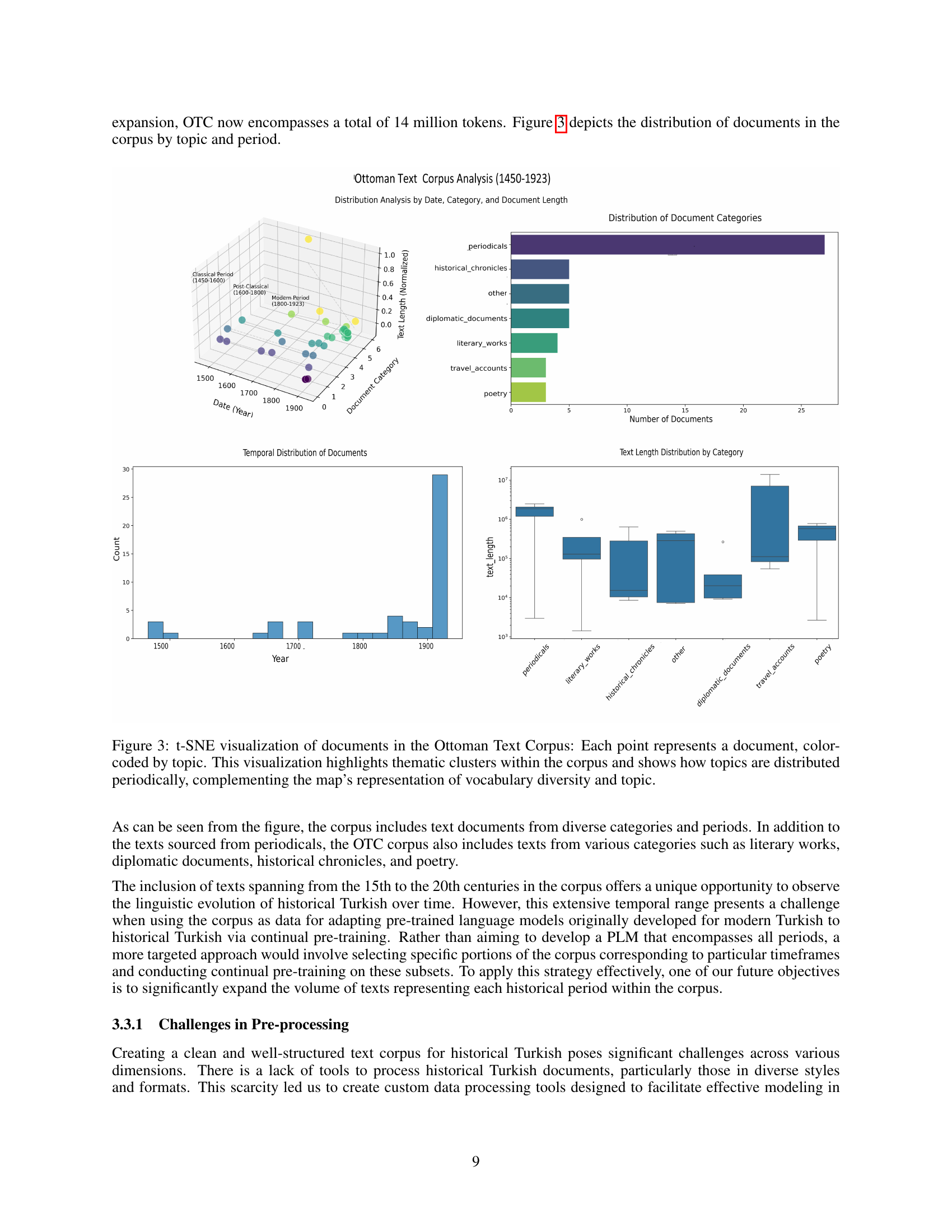
🔼 This figure uses t-SNE (t-distributed Stochastic Neighbor Embedding) to visualize the relationships between documents in the Ottoman Text Corpus. Each point represents a single document, and the color of each point indicates its topic. The clustering of points reveals thematic groups within the corpus. The distribution of these clusters across time (as shown in the accompanying bar charts) demonstrates how topic prevalence varies across different historical periods. This visualization therefore effectively displays both the topical and temporal diversity of the Ottoman Text Corpus.
read the caption
Figure 3: t-SNE visualization of documents in the Ottoman Text Corpus: Each point represents a document, color-coded by topic. This visualization highlights thematic clusters within the corpus and shows how topics are distributed periodically, complementing the map’s representation of vocabulary diversity and topic.
More on tables
| Features | The OTA-BOUN Treebank |
|---|---|
| Num. of Sentences | 514 |
| Num. of Tokens | 8,794 |
| Avg. Token Count Per Sentence | 17.10 |
| Num. of Unique POS Tags | 16 |
| Num. of Unique Morphological Features | 52 |
| Num. of Unique Dependencies | 40 |
🔼 Table 2 presents a detailed statistical overview of the Ottoman Turkish-Boğaziçi University (OTA-BOUN) historical treebank, a valuable linguistic resource for researchers working with historical Turkish. The table summarizes key features of the treebank, providing insights into the nature and characteristics of the data. Specifically, it provides the total number of sentences, tokens, and the average token count per sentence, giving a sense of the corpus size and sentence length distribution. It also presents the number of unique parts-of-speech (POS) tags and unique morphological features, offering insights into the richness and complexity of the language represented in the treebank. Finally, it includes the number of unique dependency relations, which are crucial for understanding the grammatical structures captured within the treebank.
read the caption
Table 2: Some statistics of the OTA-BOUN historical Turkish treebank
| Relation Type | Count | % | Relation Type | Count | % |
|---|---|---|---|---|---|
| acl | 348 | 3.95 | dislocated | 5 | 0.06 |
| advcl | 197 | 2.24 | fixed | 6 | 0.07 |
| advmod | 396 | 4.49 | flat | 87 | 0.99 |
| advmod:emph | 87 | 0.99 | goeswith | 5 | 0.06 |
| amod | 620 | 7.04 | iobj | 26 | 0.30 |
| appos | 2 | 0.02 | mark | 27 | 0.31 |
| aux | 39 | 0.44 | nmod | 137 | 1.55 |
| case | 257 | 2.92 | nmod:poss | 746 | 8.47 |
| cc | 228 | 2.59 | nsubj | 507 | 5.75 |
| cc:preconj | 12 | 0.14 | nsubj:pass | 22 | 0.25 |
| ccomp | 120 | 1.36 | nummod | 57 | 0.65 |
| compound | 76 | 0.86 | obj | 557 | 6.32 |
| compound:lvc | 246 | 2.79 | obl | 873 | 9.91 |
| compound:redup | 33 | 0.37 | obl:agent | 4 | 0.05 |
| conj | 607 | 6.89 | orphan | 4 | 0.05 |
| cop | 48 | 0.54 | parataxis | 10 | 0.11 |
| csubj | 42 | 0.48 | punct | 1207 | 13.70 |
| dep | 14 | 0.16 | root | 514 | 5.83 |
| det | 508 | 5.76 | vocative | 7 | 0.08 |
| discourse | 82 | 0.93 | xcomp | 49 | 0.56 |
🔼 This table presents a detailed breakdown of the dependency relations found within the Ottoman Turkish Universal Dependencies (OTA-BOUN) treebank. It lists each dependency relation type, its frequency count, and its percentage relative to the total number of dependency relations in the treebank. This provides valuable insights into the syntactic structures characteristic of historical Turkish, such as the prevalence of particular types of relationships between words in sentences.
read the caption
Table 3: Counts and percentages of dependency relation types in the OTA-BOUN treebank
| TR-BOUN | IMST-UD | OTA-BOUN | |
|---|---|---|---|
| Avg. token count per sentence | 12.41 | 10.01 | 17.10 |
| conj (%) | 5.66 | 4.96 | 6.89 |
| compound:lvc (%) | 1.0 | 0.90 | 2.79 |
| acl (%) | 2.78 | 2.64 | 3.95 |
🔼 Table 4 presents a quantitative comparison of the OTA-BOUN historical Turkish treebank with two widely used modern Turkish treebanks (TR-BOUN and IMST-UD). The comparison focuses on key metrics related to token and dependency features, offering insights into the structural differences between historical and modern Turkish. Metrics include the average number of tokens per sentence, the percentage of conjunct (conj) dependency relations, and the percentage of light verb compound (compound:lvc) dependency relations and adnominal clause (acl) relations. These metrics provide valuable insights into the syntactic and stylistic characteristics of each treebank, highlighting how historical Turkish differs from modern Turkish in terms of sentence structure and grammatical constructions.
read the caption
Table 4: Comparison of historical Turkish treebank with the two most frequently used modern Turkish treebanks in terms of token and dependency metrics
| Expected Text | Extracted Text | Error Analysis |
|---|---|---|
| Dilberün her handesi bin can bağışlar e aşuya | Dil-beruñ her òandesi biñ cÀn baàışlar èÀşıúa | Diacritical Encoding Error: Unicode normalization failure in historical Turkish diacritics and characters. The system incorrectly encodes special characters ’ñ’ and ’À’, resulting in ambiguity. Technical cause: Non-standardized Unicode point mapping for Ottoman-specific diacritics. |
| Bu mutabakatla beraber, keşf edilen eski yazıldığı veçhile Türkçe karşılığı lafzıdır. | Bu mutabakatle beraber, keşf edilen eski ya WU J. ıS i J e Ha Tı Ye Kef Lam Mim Nun te de yazıldığı veçhile Türkçe karşılığı lafzıdır. | Script Conversion Error: Critical failure in Arabic-Latin script conversion pipeline. OCR system’s inability to properly map Arabic script ligatures to Latin characters due to contextual shape variations. Root cause: Inadequate handling of Unicode ranges U+0600-U+06FF. |
| GÜRİZ yahut GÜRİZGAH: | G Ü R ÎZ : , yâhut G Ü R İZ G Â H : | Word Segmentation Error: Tokenization algorithm failure in word recognition. Improper word boundary detection caused by missing morphological analysis support. Technical impact: Loss of semantic unity in words. |
| HİSÂB-ı CÜMEL: Ebced hisâbının diğer adıdır | HtSÂB-t C Ü M EL: Ebced hi-sâbının diğer adıdır | Character Substitution Error: Systematic misclassification of Turkish ’İ’ character as ’t’. Error stems from inadequate training data representation of Turkish-specific uppercase dotted ’İ’. Technical cause: Unicode point confusion between U+0130 and U+0074. |
| İran şâirlerinden: Şevket Ferâhî’nin | İran şâirlerinden: J i j Z j S ’ C j | Mixed Script Error: Complete text fragmentation due to script detection failure. System’s inability to maintain consistent character encoding across different writing systems. Root cause: Inadequate handling of bi-directional text rendering. |
🔼 This table presents examples of text extraction errors encountered during the digital conversion of historical Turkish documents. It showcases the types of errors, their causes (e.g., diacritical encoding, script conversion, word segmentation, character substitution, mixed script issues), and analysis of why these errors occurred during the digitization process. Each row details a specific instance with the original (expected) text, the extracted text containing errors, and a breakdown explaining the nature and source of the error, including references to Unicode issues and challenges related to processing historical Turkish script variations.
read the caption
Table 5: Analysis of sample text extraction errors in digital conversion of historical Turkish documents
| Model Descriptions | ||||||
|---|---|---|---|---|---|---|
BERTurk+MilliyetNER | BERTurk fine-tuned only using MilliyetNER, | |||||
a large NER dataset for modern Turkish. | ||||||
BERTurk+MilliyetNER+HisTR | BERTurk+MilliyetNER further fine-tuned using | |||||
HisTR, the small dataset for historical Turkish. | ||||||
BERTurk+HisTR | BERTurk fine-tuned only using HisTR. | |||||
mBERT+WikiANN+HisTR | mBERT fine-tuned on WikiANN, a large multilingual | |||||
NER dataset, and further fine-tuned using HisTR. | ||||||
mBERT+HisTR | mBERT fine-tuned only using HisTR. | |||||
TURNA+MilliyetNER+HisTR | TURNA fine-tuned on MilliyetNER and further | |||||
fine-tuned using HisTR. | ||||||
| Model Performance | ||||||
| — | — | — | — | — | — | — |
| HisTR Development Set | Ruznamçe Test Set | |||||
| Name | Prec. | Recall | F1 | Prec. | Recall | F1 |
BERTurk+MilliyetNER | 75.39 | 71.99 | 73.65 | 53.84 | 61.95 | 57.58 |
BERTurk+MilliyetNER+HisTR | 90.26 | 92.17 | 91.21 | 59.92 | 64.03 | 61.91 |
BERTurk+HisTR | 88.63 | 91.57 | 90.07 | 54.49 | 61.75 | 57.89 |
mBERT+WikiANN+HisTR | 80.73 | 87.05 | 83.77 | 41.17 | 41.93 | 41.49 |
mBERT+HisTR | 83.95 | 88.25 | 86.05 | 43.19 | 42.20 | 42.69 |
TURNA+MilliyetNER+HisTR | 77.62 | 80.26 | 78.92 | 57.61 | 41.58 | 48.30 |
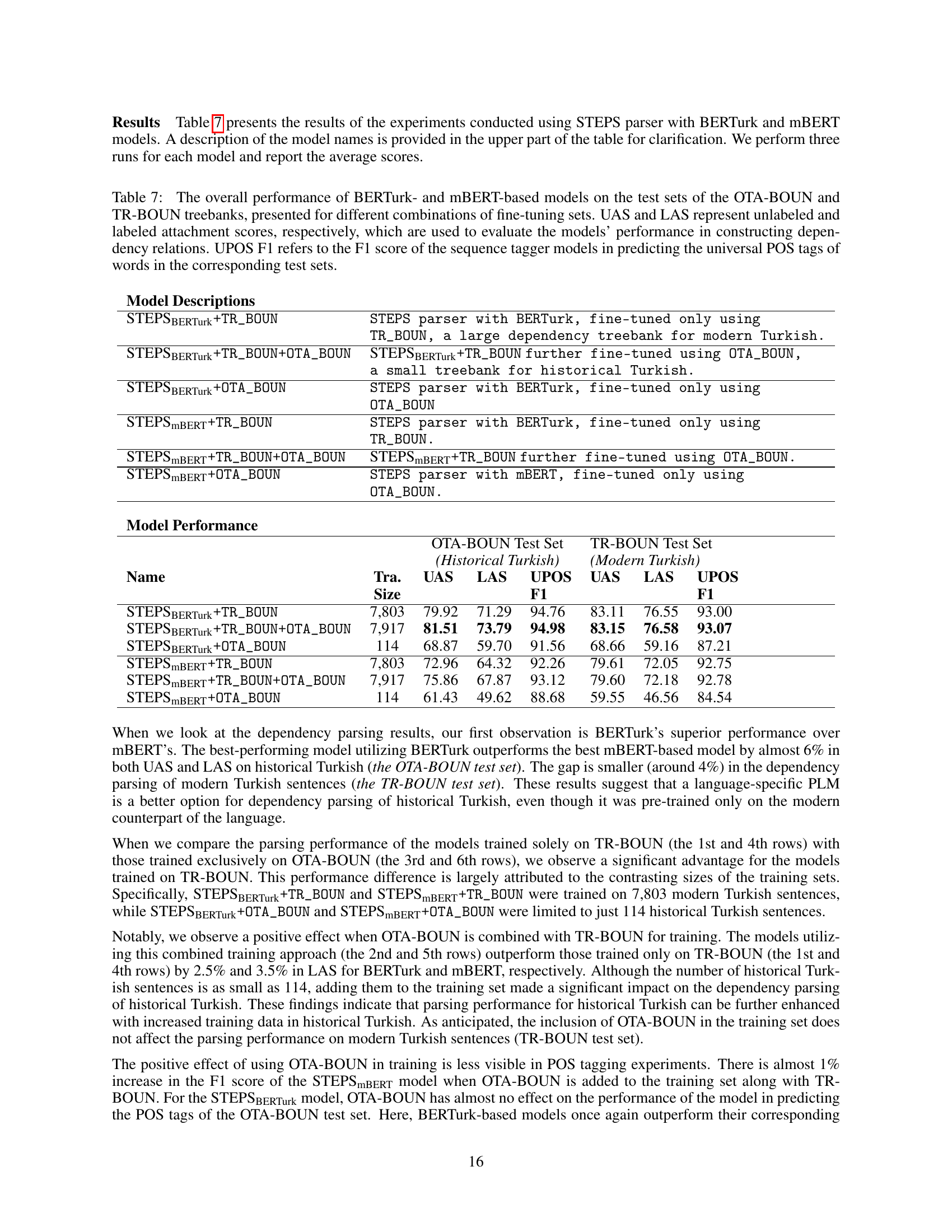
🔼 Table 6 presents the performance of three different pre-trained Named Entity Recognition (NER) models (BERTurk, mBERT, and TURNA) on the HisTR dataset. The HisTR dataset is specifically designed for historical Turkish texts, posing unique challenges not encountered in modern Turkish NER. The table shows the performance of the models on both an in-domain development set and an out-of-domain test set. The in-domain data consists of similar texts to those in the training data, while the out-of-domain data has different characteristics. Multiple experiments were conducted for each model using various combinations of training data. The results are reported using the precision, recall, and F1-score for each setting, offering insights into how well each model generalizes to the different datasets.
read the caption
Table 6: The overall performance of BERTurk, mBERT, and TURNA NER models on the in-domain development and out-of-domain test sets of the HisTR dataset when using different combinations of fine-tuning sets
| Model Descriptions | OTA-BOUN Test Set (Historical Turkish) | TR-BOUN Test Set (Modern Turkish) | ||
|---|---|---|---|---|
| STEPSBERTurk+TR_BOUN | STEPS parser with BERTurk, fine-tuned only using TR_BOUN, a large dependency treebank for modern Turkish. | |||
| STEPSBERTurk+TR_BOUN+OTA_BOUN | STEPSBERTurk+TR_BOUN further fine-tuned using OTA_BOUN, a small treebank for historical Turkish. | |||
| STEPSBERTurk+OTA_BOUN | STEPS parser with BERTurk, fine-tuned only using OTA_BOUN | |||
| STEPSmBERT+TR_BOUN | STEPS parser with BERTurk, fine-tuned only using TR_BOUN. | |||
| STEPSmBERT+TR_BOUN+OTA_BOUN | STEPSmBERT+TR_BOUN further fine-tuned using OTA_BOUN. | |||
| STEPSmBERT+OTA_BOUN | STEPS parser with mBERT, fine-tuned only using OTA_BOUN. | |||
| Model Performance | ||||
| — | — | — | — | — |
| OTA-BOUN Test Set | TR-BOUN Test Set | |||
| (Historical Turkish) | (Modern Turkish) | |||
| Name | Tra. Size | UAS | LAS | UPOS F1 |
| STEPSBERTurk+TR_BOUN | 7,803 | 79.92 | 71.29 | 94.76 |
| STEPSBERTurk+TR_BOUN+OTA_BOUN | 7,917 | 81.51 | 73.79 | 94.98 |
| STEPSBERTurk+OTA_BOUN | 114 | 68.87 | 59.70 | 91.56 |
| STEPSmBERT+TR_BOUN | 7,803 | 72.96 | 64.32 | 92.26 |
| STEPSmBERT+TR_BOUN+OTA_BOUN | 7,917 | 75.86 | 67.87 | 93.12 |
| STEPSmBERT+OTA_BOUN | 114 | 61.43 | 49.62 | 88.68 |
🔼 Table 7 presents the results of dependency parsing and POS tagging experiments using the STEPS parser with BERTurk and mBERT models. It shows the performance of different model configurations (fine-tuned on various combinations of the OTA-BOUN and TR-BOUN treebanks) on both historical (OTA-BOUN) and modern (TR-BOUN) Turkish datasets. The table includes metrics such as unlabeled attachment score (UAS), labeled attachment score (LAS), and Universal Part-of-Speech (UPOS) F1-score, providing a comprehensive evaluation of the models’ ability to accurately identify dependency relations and POS tags in both historical and modern Turkish text.
read the caption
Table 7: The overall performance of BERTurk- and mBERT-based models on the test sets of the OTA-BOUN and TR-BOUN treebanks, presented for different combinations of fine-tuning sets. UAS and LAS represent unlabeled and labeled attachment scores, respectively, which are used to evaluate the models’ performance in constructing dependency relations. UPOS F1 refers to the F1 score of the sequence tagger models in predicting the universal POS tags of words in the corresponding test sets.
Full paper#