TL;DR#
Online medical consultations present unique challenges due to the limited information available to doctors, relying solely on textual patient descriptions and interactions. Existing research largely focuses on improving diagnostic accuracy with sufficient information, neglecting the crucial role of the inquiry process. This paper highlights the need for improved patient simulation models that mirror real-world patient behavior for more effective evaluation of AI-powered doctor models.
To tackle this, the authors developed a novel patient simulator that uses real patient interactions to guide its training. The simulator enables a comprehensive evaluation of the relationship between inquiry and diagnosis. The key finding is that the quality of the inquiry significantly impacts diagnostic accuracy, even with high-performing diagnostic models, following Liebig’s Law. This suggests that improving the inquiry process is crucial for enhancing the effectiveness of online medical consultations. The study also categorizes inquiry strategies into four types, allowing researchers to analyze the inquiry effectiveness of various models.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical gap in online medical consultation research by focusing on the inquiry phase and its impact on diagnosis. It introduces a novel patient simulator that overcomes limitations of existing methods, allowing for more realistic and robust evaluation of doctor-patient interactions. This opens new avenues for developing more effective and human-like AI-powered medical consultation systems and for investigating the complex interplay between doctor inquiries and diagnostic accuracy. The open-sourcing of the patient simulator further enhances its impact and facilitates wider adoption within the research community.
Visual Insights#

🔼 This figure compares two patient simulators used in online medical consultations: a baseline simulator (using prompt engineering on GPT-4) and a new patient simulator developed by the authors. Both simulators engage with the same doctor model and patient records. The consultation is divided into two stages: inquiry and diagnosis. The authors’ model’s dialogue strategies are highlighted in purple, while expressions of emotion or proactive questions are shown in green. In contrast, the baseline model outputs are highlighted in red to emphasize the more extensive symptom information provided in the initial round compared to a typical patient. This visual comparison demonstrates that the authors’ simulator more accurately reflects the behavior of a real patient during an online consultation.
read the caption
Figure 1. Using the same patient records and doctor model, our patient simulator (shown on the right in the figure) is compared to the baseline patient simulator (prompt engineering on GPT-4o, shown on the left in the figure). Online consultation dialogues are divided into inquiry and diagnosis stages, with D representing the doctor and P representing the patient in the figure. Based on the predefined set of dialogue strategies outlined in this paper, the dialogue strategies output by our model are highlighted in purple. The output from our patient simulator may contain emotions or proactive questions, marked in green. In contrast, the baseline tends to provide more comprehensive symptoms in the first round, with additional symptoms and resulting significant differences highlighted in red. These dimensions illustrate that our model better approximates a real patient.
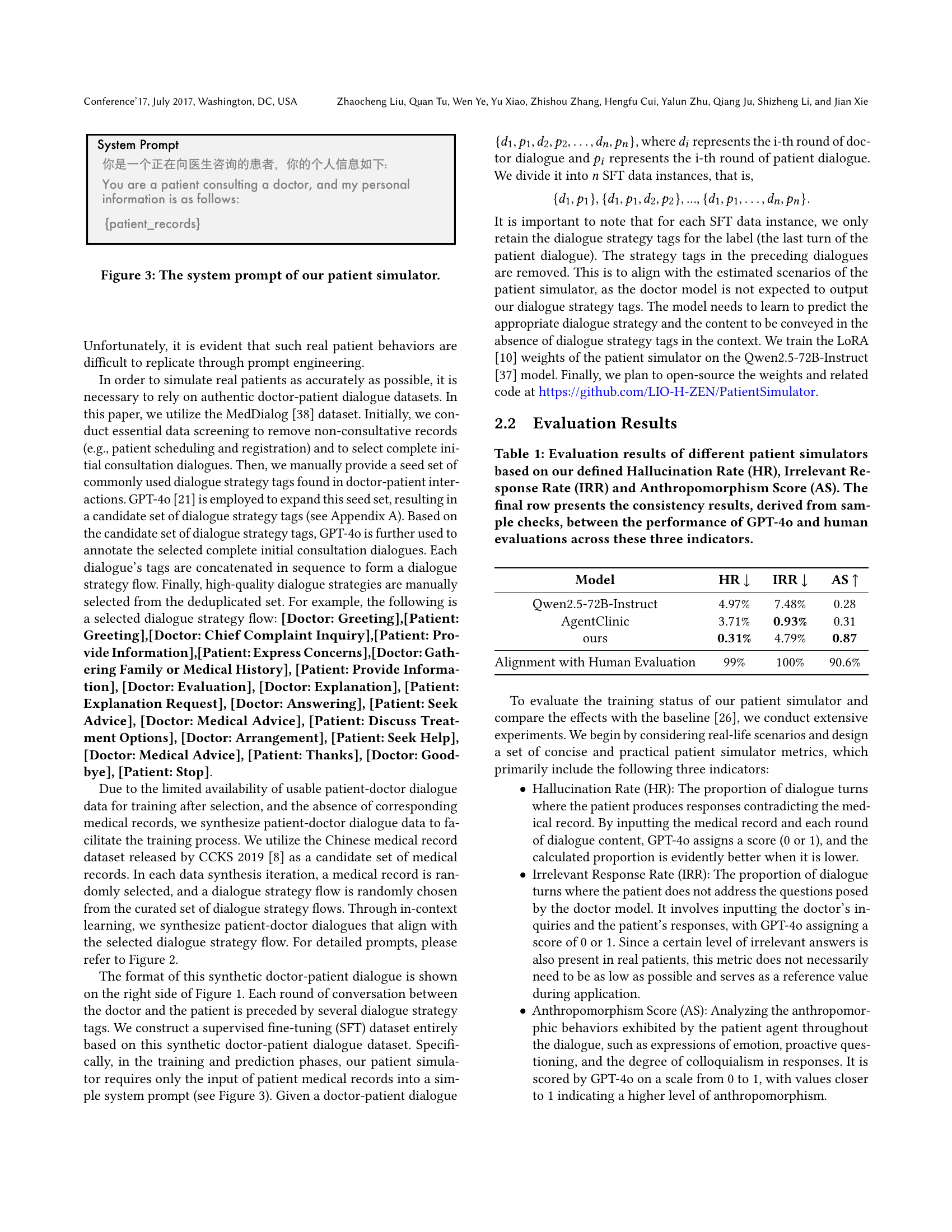
| Model | HR | IRR | AS |
|---|---|---|---|
| Qwen2.5-72B-Instruct | 4.97% | 7.48% | 0.28 |
| AgentClinic | 3.71% | 0.93% | 0.31 |
| ours | 0.31% | 4.79% | 0.87 |
| Alignment with Human Evaluation | 99% | 100% | 90.6% |
🔼 This table presents a comparison of three different patient simulators: Qwen2.5-72B-Instruct, AgentClinic, and the authors’ proposed model. The comparison is based on three key metrics: Hallucination Rate (HR), Irrelevant Response Rate (IRR), and Anthropomorphism Score (AS). HR measures the frequency of simulator responses that contradict the provided medical records. IRR measures the frequency of irrelevant responses from the simulator. AS measures how well the simulator’s responses mimic human-like characteristics, such as emotional expressions and conversational style. The final row shows the level of agreement between evaluations made using GPT-4 and human evaluations. Lower HR and IRR values and a higher AS value generally indicate a better-performing simulator.
read the caption
Table 1. Evaluation results of different patient simulators based on our defined Hallucination Rate (HR), Irrelevant Response Rate (IRR) and Anthropomorphism Score (AS). The final row presents the consistency results, derived from sample checks, between the performance of GPT-4o and human evaluations across these three indicators.
In-depth insights#
Inquiry-Diagnosis Link#
The core of this research revolves around the crucial interplay between the inquiry phase and the diagnostic phase in online medical consultations (OMCs). The paper posits a Liebig’s Law relationship: the quality of inquiry directly limits the effectiveness of even the most sophisticated diagnostic models, and vice-versa. This means that poor-quality questions, regardless of diagnostic capability, will constrain diagnostic accuracy. The study meticulously investigates this link by analyzing real patient interactions, creating a patient simulator, and then testing various doctor models in simulated OMCs. The inquiry process is broken down into four key types, allowing for a more nuanced understanding of how different inquiry strategies influence diagnostic outcomes. The results emphasize the critical need for improved inquiry strategies in OMCs, as this directly impacts the quality and effectiveness of diagnoses, highlighting the often-overlooked importance of the inquiry phase in achieving accurate and timely medical care.
Patient Simulators#
The research paper section on ‘Patient Simulators’ is crucial because it addresses the limitations of existing methods in evaluating medical AI models. Creating a realistic patient simulator is vital for assessing diagnostic accuracy in online medical consultations (OMCs), as current approaches using prompt engineering often fail to capture the nuances of real patient interactions. The paper highlights the need for a patient simulator that mimics real-world behavior, including emotional expression, proactive questioning, and potential refusal to answer repetitive questions. The authors developed a patient simulator trained on real doctor-patient dialogues, addressing the problem of insufficient training data by synthesizing dialogue data using in-context learning. This approach is evaluated through metrics such as hallucination rate, irrelevant response rate, and anthropomorphism score, demonstrating improved performance over existing baselines. The focus on simulating genuine patient responses is key to more accurately evaluating the performance of diagnostic models in OMCs, leading to more robust and reliable assessments of medical AI systems.
Liebig’s Law in OMC#
Liebig’s Law, stating that growth is limited by the scarcest resource, finds a compelling application in online medical consultations (OMC). The paper argues that diagnostic accuracy in OMC is fundamentally constrained by the quality of the physician’s inquiry, regardless of the diagnostic model’s sophistication. Poor inquiry, akin to a limiting nutrient, hampers diagnostic success, even with advanced diagnostic tools. Conversely, a strong inquiry phase enables accurate diagnosis, even with less powerful diagnostic models. This highlights the crucial, often overlooked, role of effective questioning and information gathering in OMC. The study’s experimental design, using a patient simulator trained on real interactions, allows for controlled tests of this hypothesis. By systematically varying inquiry quality and diagnostic model strength, it directly confirms the significant impact of inquiry on overall diagnostic accuracy in OMC, making a strong case for prioritizing and optimizing the inquiry phase of online medical practice.
Inquiry Type Analysis#
The Inquiry Type Analysis section would be crucial for understanding how different AI models approach patient interaction. It would likely categorize the types of questions asked by various models, perhaps into categories like chief complaint, symptom specifics, related symptoms, and medical history. Analyzing the distribution of these question types across models could reveal significant differences in their conversational strategies. A model focusing heavily on chief complaints might be efficient but miss crucial details, whereas a model balancing all categories might be more thorough but less efficient. The analysis could further examine how these different inquiry strategies impact diagnostic accuracy, highlighting the trade-off between depth of inquiry and efficiency. This would likely reveal insights into which inquiry strategies are most effective for accurate diagnosis, ultimately helping improve AI-driven medical consultation systems. Identifying the optimal balance between comprehensive questioning and efficient information gathering is a key takeaway from such analysis. The results could provide valuable guidance for developers in designing more effective AI models for medical consultations.
Future Research#
Future research directions stemming from this inquiry-diagnosis study should prioritize improving the realism of patient simulators. Current methods, relying heavily on prompt engineering, often fall short in capturing the nuances of real patient interactions, including emotional expression and varying levels of cooperation. Therefore, exploring alternative approaches such as incorporating multimodal data (e.g., incorporating audio and visual cues) and leveraging reinforcement learning to refine patient simulator responses will be crucial. Further investigation into the optimal balance between inquiry depth and efficiency is warranted. This includes exploring strategies for dynamically adjusting the inquiry process based on real-time patient responses, thereby maximizing diagnostic accuracy without overwhelming the patient. Finally, broadening the scope to encompass a wider range of medical specialties and diverse patient populations will enhance the generalizability and applicability of the findings. This will require access to significantly larger, more diverse datasets of doctor-patient interactions and potentially involve collaboration with multiple medical institutions.
More visual insights#
More on figures

🔼 This figure displays the system prompts used for synthesizing training dialogues for the patient simulator. The prompts guide the generation of realistic doctor-patient conversations, providing examples of patient records and dialogue strategy flows for the system to follow. This ensures the simulated dialogues accurately reflect real-world interactions, making the patient simulator more effective in training doctor models.
read the caption
Figure 2. Prompts for synthesizing patient simulator training dialogues.

🔼 This figure shows the system prompt used to instruct the patient simulator. The prompt instructs the model to act as a patient providing information to a doctor. The prompt includes a placeholder for the patient’s personal medical records, which are dynamically inserted during each simulation. The key idea is that this prompt is designed to elicit realistic patient responses by providing a clear role and context.
read the caption
Figure 3. The system prompt of our patient simulator.

🔼 This figure illustrates the workflow used to evaluate the diagnostic accuracy of large language models (LLMs) in conversations. It starts with patient records, which are used in a simulated doctor-patient dialogue. The dialogue is then assessed by extracting the diagnosed disease. The extracted diagnosis is then compared to the ground truth diagnosis (the actual disease) and a score is generated representing the accuracy of the LLM’s diagnostic abilities. This workflow helps to quantify the performance of the LLMs in a realistic conversational setting.
read the caption
Figure 4. Workflow for assessing diagnostic accuracy in conversations using LLMs.

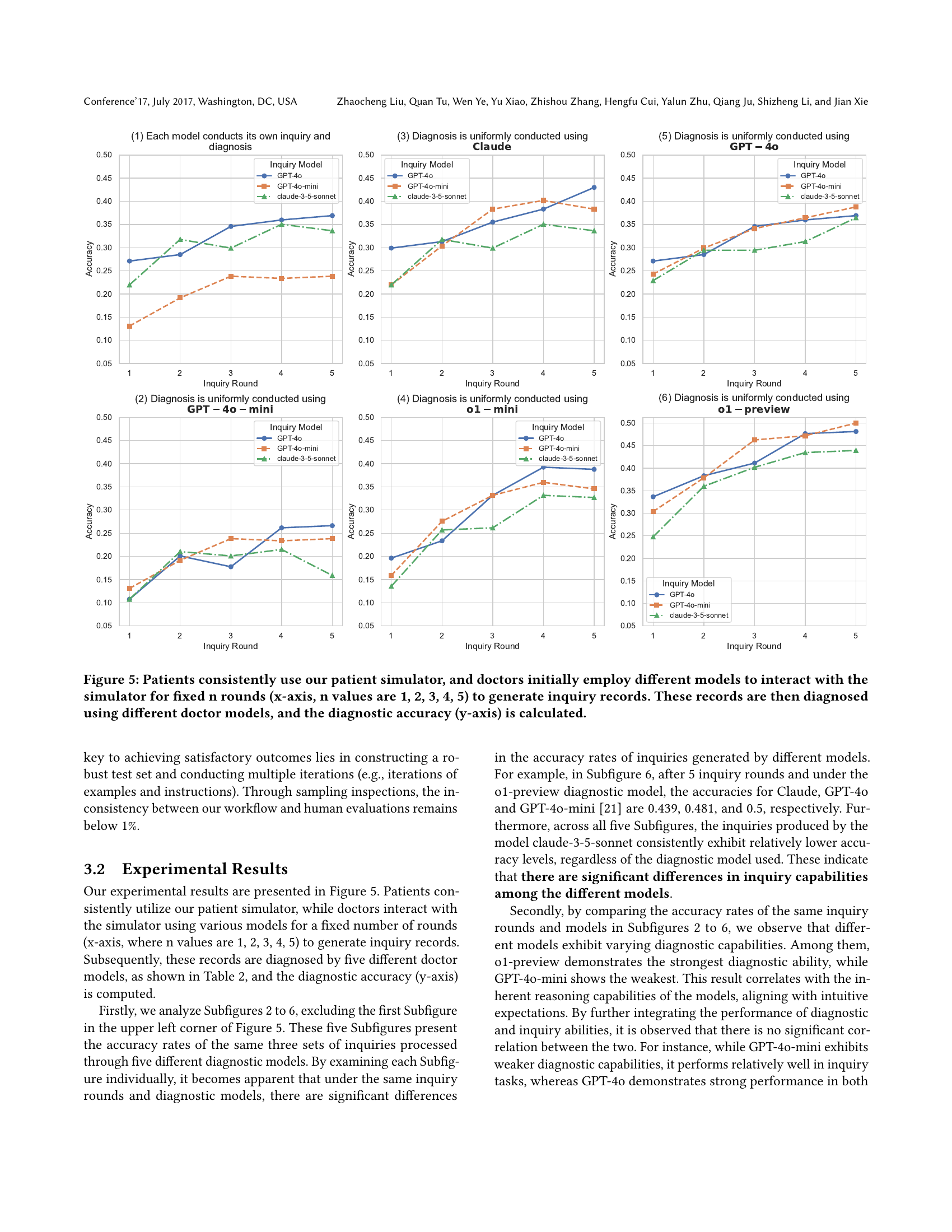
🔼 This figure displays the diagnostic accuracy achieved when using different doctor models to diagnose inquiry records generated through interactions with various inquiry models and the patient simulator. The x-axis represents the number of inquiry rounds (n=1,2,3,4,5), simulating the length of the doctor-patient conversation. The y-axis shows the resulting diagnostic accuracy. The consistent use of the patient simulator ensures consistent patient responses across all tests, isolating the impact of the different inquiry and diagnosis models on accuracy. Each subplot represents a different doctor model used for diagnosis.
read the caption
Figure 5. Patients consistently use our patient simulator, and doctors initially employ different models to interact with the simulator for fixed n rounds (x-axis, n values are 1, 2, 3, 4, 5) to generate inquiry records. These records are then diagnosed using different doctor models, and the diagnostic accuracy (y-axis) is calculated.

🔼 This figure illustrates examples of the four types of inquiries used in online medical consultations. The four types are: Chief Complaint Inquiry (doctor asks about the patient’s main concern), Specification of Known Symptoms (doctor seeks details about symptoms already mentioned), Inquiry about Accompanying Symptoms (doctor inquires about related symptoms), and Gathering Family or Medical History (doctor asks about family medical history). Each type is shown with a short doctor-patient dialogue exchange to exemplify the interaction.
read the caption
Figure 6. Examples of four types of inquiry with D representing the doctor and P representing the patient in the figure.

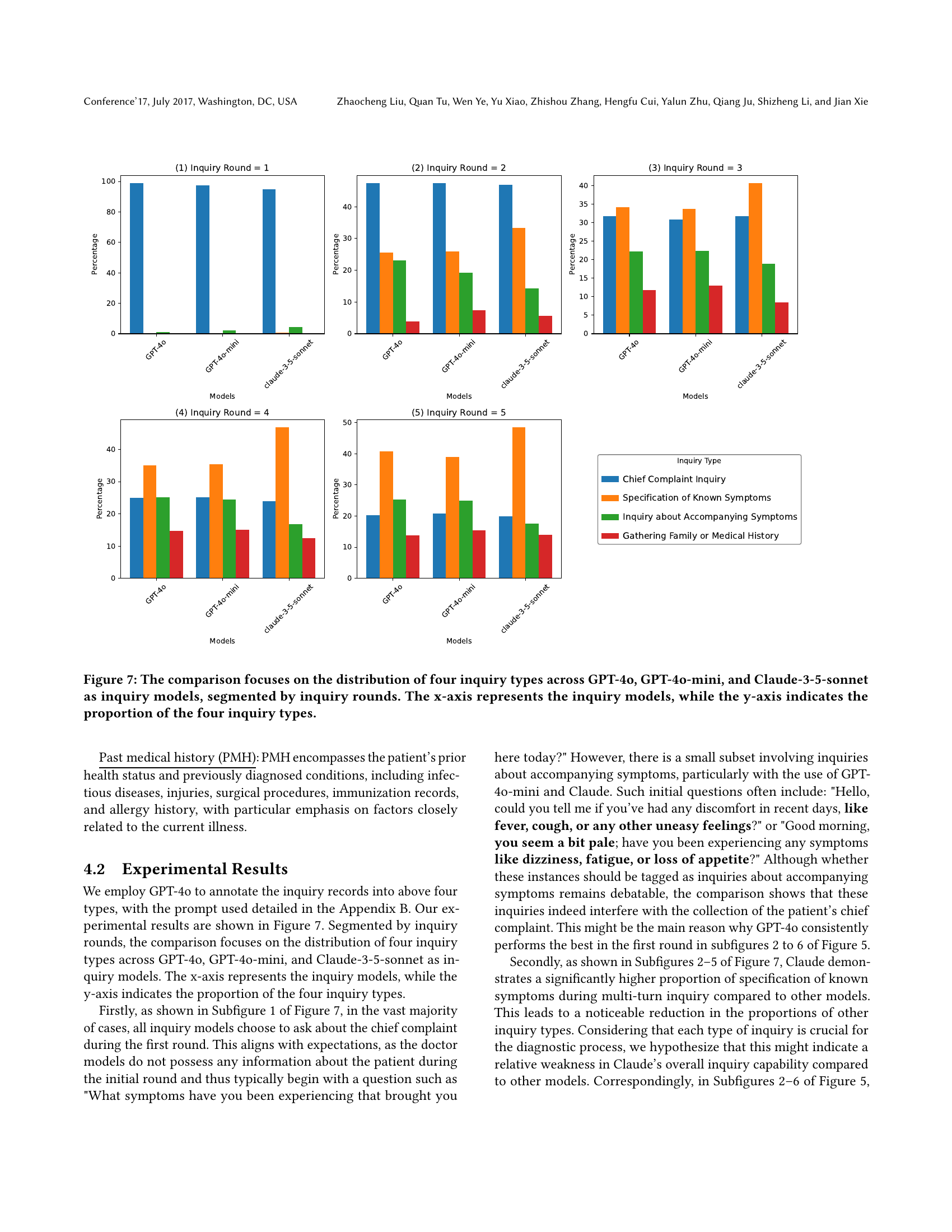
🔼 Figure 7 presents a comparison of the distribution of four inquiry types across three different language models (GPT-40, GPT-40-mini, and Claude-3-5-sonnet) used for generating inquiries in a simulated medical consultation. The models’ inquiries are categorized into four types: Chief Complaint Inquiry, Specification of Known Symptoms, Inquiry about Accompanying Symptoms, and Gathering Family or Medical History. The figure displays this distribution for each model across different numbers of inquiry rounds (turns in the conversation), providing a visual representation of how the models approach the inquiry process in terms of the types of questions asked and the relative frequency of those types. The x-axis identifies the language model, and the y-axis shows the percentage of each inquiry type.
read the caption
Figure 7. The comparison focuses on the distribution of four inquiry types across GPT-4o, GPT-4o-mini, and Claude-3-5-sonnet as inquiry models, segmented by inquiry rounds. The x-axis represents the inquiry models, while the y-axis indicates the proportion of the four inquiry types.

🔼 Figure 8 details the prompt used to annotate the type of inquiries made in doctor-patient dialogues. The prompt instructs annotators to mark whether a doctor’s response contains inquiries about main symptoms, details of already-mentioned symptoms, accompanying symptoms, or family/medical history. It also asks for marking whether the doctor provides medical diagnoses or advice. Specific instructions and output formatting guidelines are also included to ensure consistent annotation.
read the caption
Figure 8. Inquiry Type Annotation Prompt
Full paper#