TL;DR#
Current large-scale generative models struggle with creating high-fidelity personalized images, especially those with multiple subjects. Existing methods often suffer from subject fidelity issues, blending problems, or limitations in handling diverse object categories. These limitations hinder the creation of complex and visually rich images tailored to specific subjects and scenarios.
AnyStory overcomes these limitations with a novel “encode-then-route” approach. It uses an enhanced encoder combining ReferenceNet and CLIP to robustly represent subjects. A decoupled instance-aware router accurately guides subject condition injection in the latent space, minimizing blending and maximizing control. This results in high-quality, personalized images, even with multiple subjects, demonstrating the approach’s effectiveness across diverse scenarios and subject types.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AnyStory, a novel approach that significantly advances personalized image generation. It addresses the limitations of existing methods by achieving high-fidelity personalization for both single and multiple subjects, a significant challenge in the field. The unified approach and innovative techniques (enhanced subject representation encoder and decoupled instance-aware subject router) open new avenues for research in multi-subject generation and visual storytelling. Researchers can leverage AnyStory’s framework to develop more sophisticated and flexible image generation models for various applications.
Visual Insights#

🔼 AnyStory, a unified framework for single and multi-subject personalization in text-to-image generation, is illustrated. The framework uses a two-stage process: First, it encodes the subject using a simplified ReferenceNet and CLIP vision encoder. Second, it uses a decoupled instance-aware subject router to inject subject conditions into the image generation process, guiding the placement and characteristics of subjects within the image. The training involves separate training of the subject encoder and the router.
read the caption
Figure 1: Overview of AnyStory framework. AnyStory follows the “encode-then-route” conditional generation paradigm. It first utilizes a simplified ReferenceNet combined with a CLIP vision encoder to encode the subject (Sec. 3.2), and then employs a decoupled instance-aware subject router to guide the subject condition injection (Sec. 3.3). The training process is divided into two stages: the subject encoder training stage and the router training stage (Sec. 3.4). For brevity, we omit the text conditional branch here.
| Architecture | #Params (B) | Speed (ms/img) |
| Original ReferenceNet [28] | 2.57 | 62.0 |
| Simplified ReferenceNet | 2.02 | 53.2 |
🔼 This table presents a comparison of the original ReferenceNet architecture from the paper [28] and a simplified version used in AnyStory. It shows the number of parameters (in billions) and the inference speed (in milliseconds per image) for each architecture. The measurements were obtained using an NVIDIA A100 GPU, a batch size of 1, and an input resolution of 64x64 in the latent space. The simplified version reduces computational cost without significant performance loss.
read the caption
Table 1: Statistics of the simplified ReferenceNet. The speed is measured on an A100 GPU with a batch size of 1 and an input (latent) resolution of 64×64646464\times 6464 × 64.
In-depth insights#
Unified Personalization#
The concept of “Unified Personalization” in text-to-image generation suggests a system capable of handling both single and multiple subjects seamlessly. This implies overcoming the challenges of subject blending and fidelity loss often seen when multiple subjects interact within a single image. A unified approach would likely involve a sophisticated encoding and routing mechanism that accurately perceives and predicts the spatial location of each subject, preventing overlap and ensuring individual subject details are preserved. This requires moving beyond simple subject masking techniques towards more intelligent methods that understand the complex relationships between subjects and their surroundings. A successful unified personalization system should also offer fine-grained control over individual subject attributes such as pose, expression, and style, while maintaining consistency and coherence across the entire image. Achieving this would represent a significant advance in the field, enabling the creation of highly personalized and detailed scenes that accurately reflect the user’s intent, regardless of the number of subjects involved. Key aspects to consider include the subject encoding method, routing algorithm, and loss function employed for training and ensuring high-fidelity generation.
Subject Encoding#
Subject encoding in text-to-image generation aims to create effective representations of specific subjects for personalized image synthesis. High-fidelity encoding is crucial as it directly impacts the quality and accuracy of the generated images. A challenge lies in balancing detail preservation with the ability to generalize across variations in pose, background, and viewpoint. Methods often involve using powerful image encoders like ReferenceNet, possibly combined with CLIP, to capture both visual details and semantic concepts. The choice of encoder is a critical design decision, impacting computational efficiency and the capacity to handle diverse subjects. Simplifications to the encoder architecture, such as removing cross-attention layers, can improve efficiency while potentially reducing the richness of the subject representation. The effectiveness of subject encoding significantly influences the downstream tasks of subject routing and the final image generation process. Careful consideration must be given to the trade-off between detailed encoding for high-fidelity and generalized encoding enabling flexibility.
Instance-Aware Routing#
Instance-aware routing, in the context of image generation, is a crucial mechanism for handling multiple subjects or objects within a single scene. It addresses the challenge of preventing unwanted blending or interference between subjects by carefully controlling how their individual features are integrated into the image generation process. The core idea is to dynamically assign influence regions or weights to each subject’s representation, ensuring that each contributes to the final image in a spatially defined manner. This approach moves beyond simpler methods that may rely on fixed masks or uniform blending, offering more flexible and precise control over the final output. Effective instance-aware routing requires a system capable of accurately perceiving and predicting the locations of the subjects, often through an intermediate segmentation-like step, which guides the injection of subject-specific conditions within a generative model. By decoupling subject features from background or global context, instance-aware routing also enables fine-grained control over individual subject attributes and relative positioning within the overall scene.
Experimental Results#
A dedicated ‘Experimental Results’ section in a research paper would ideally present a rigorous evaluation of the proposed AnyStory model. This would involve a multifaceted assessment, likely including quantitative metrics such as FID (Fréchet Inception Distance) and IS (Inception Score) to measure image quality and diversity. The results should demonstrate AnyStory’s superior performance compared to existing single and multi-subject personalization methods. Furthermore, ablation studies should be included, systematically removing key components (e.g., ReferenceNet encoder, decoupled router) to isolate their individual contributions. Crucially, the results should visually showcase AnyStory’s effectiveness in generating high-fidelity images with correctly identified and distinct subjects, even under complex multi-subject scenarios. Success would be demonstrated by the absence of subject blending and the accurate reflection of text prompts within the generated images. Finally, the discussion should analyze the model’s limitations, highlighting areas for future work and improvement, and exploring any unexpected or counterintuitive results.
Future of AnyStory#
The future of AnyStory hinges on addressing its current limitations and expanding its capabilities. Improving background control is crucial; currently, AnyStory struggles to consistently personalize backgrounds, a key aspect of visual storytelling. Future work should focus on integrating more sophisticated background generation techniques or allowing user-specified background input. Enhanced subject fidelity and control is another area ripe for development; while AnyStory excels at detailed subject representation, refining its ability to handle complex interactions, occlusions, and diverse subject types would improve the quality and variety of generated images. Expanding the range of supported subject types beyond current examples is also important. Exploring more diverse datasets and potentially incorporating 3D modeling techniques could address this. Finally, investigating the potential for improved efficiency is vital. The ’encode-then-route’ approach, while effective, may be computationally expensive. Optimizing model architecture or employing more efficient algorithms could make AnyStory more accessible for wider use. Addressing these areas will solidify AnyStory’s position as a leading personalized text-to-image generation model.
More visual insights#
More on figures

🔼 This figure demonstrates the impact of using a ReferenceNet encoder in AnyStory. The left image shows the output when only a CLIP vision encoder is used, showing loss of fine details. The right image shows how incorporating ReferenceNet into the subject representation enhances the preservation of subject details and fidelity in the generated image.
read the caption
Figure 2: Effect of ReferenceNet encoding. The ReferenceNet encoder enhances the preservation of subject details.

🔼 This figure demonstrates the AnyStory model’s ability to avoid blending of subject characteristics when generating images with multiple subjects. The router module, a key component of AnyStory, limits the influence of each subject’s conditions to specific areas of the image. By confining these influences, the model produces cleaner, higher-quality images where subjects are distinct and well-defined, without unwanted blending or mixing of features.
read the caption
Figure 3: The effectiveness of the router. The router restricts the influence areas of the subject conditions, thereby avoiding the blending of characteristics between multiple subjects and improving the quality of the generated images.

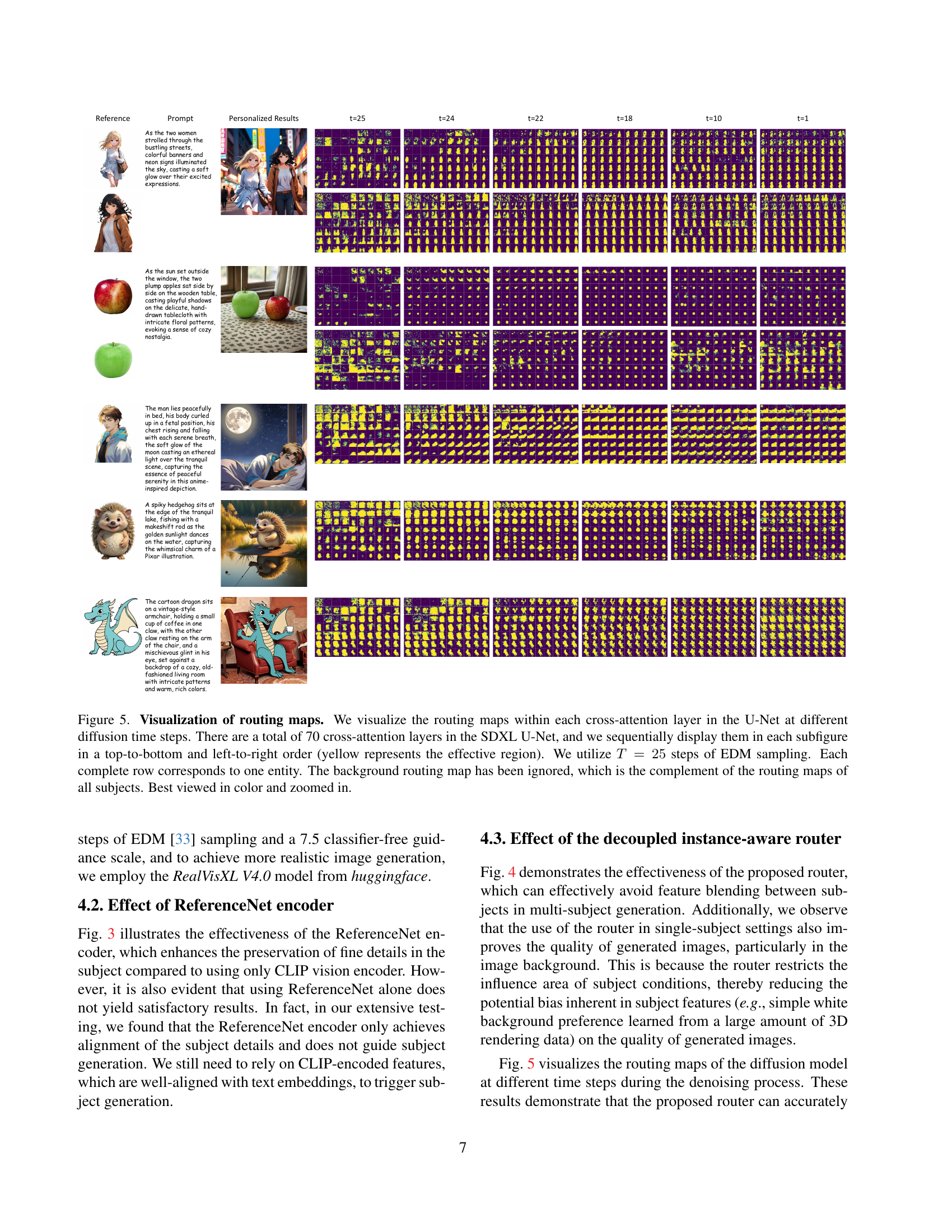
🔼 This figure visualizes the attention maps generated by the model’s routing module at various stages of the diffusion process. Each row represents a different subject or entity in the image, showing how the model focuses on specific areas to condition generation. The maps illustrate the attention weights across the 70 cross-attention layers within the U-Net, revealing how the model progressively refines subject placement and boundaries during image generation. Yellow highlights indicate the areas where the model focuses most strongly. The background map is omitted for clarity; it’s essentially the inverse of the combined subject maps.
read the caption
Figure 4: Visualization of routing maps. We visualize the routing maps within each cross-attention layer in the U-Net at different diffusion time steps. There are a total of 70 cross-attention layers in the SDXL U-Net, and we sequentially display them in each subfigure in a top-to-bottom and left-to-right order (yellow represents the effective region). We utilize T=25𝑇25T=25italic_T = 25 steps of EDM sampling. Each complete row corresponds to one entity. The background routing map has been ignored, which is the complement of the routing maps of all subjects. Best viewed in color and zoomed in.

🔼 Figure 5 demonstrates the effectiveness of AnyStory’s decoupled instance-aware subject router in controlling the influence area of subject conditions during image generation. The figure shows coarse and refined routing maps at different diffusion time steps (t) for various subjects. Each row corresponds to a subject. The yellow regions in the maps highlight where the subject’s features are injected into the image. The refined routing maps, generated by masked cross-attention, provide more precise localization of subject features compared to the coarse maps. This precise control prevents the blending of features from different subjects and leads to higher-quality image generation, especially in multi-subject scenarios.
read the caption
Figure 5: Effectiveness of the proposed router structure. For the meaning of each illustration, please refer to Fig. 4.

🔼 This figure showcases example image generation results from the AnyStory model. It demonstrates the model’s ability to generate diverse and high-quality images based on text prompts, showcasing a range of art styles, subjects, and compositions. The images highlight AnyStory’s capacity for personalization, including the generation of single or multiple subjects with varying levels of detail and complexity.
read the caption
Figure 6: Example generations II from AnyStory.
More on tables
🔼 This figure visualizes the routing maps at different diffusion time steps during the denoising process. Each row corresponds to a single entity, showing how the routing maps evolve over time. The visualization uses yellow to represent the effective region of each subject’s condition. The figure helps demonstrate the effectiveness of the proposed router in accurately perceiving and locating the effect regions of each subject during the image generation process.
read the caption
((a)) Coarse routing maps
![[Uncaptioned image]](extracted/6135755/figures/appendix/ai-generated-dwarf-story-fantasy-8697130.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/girl-coat-night-night-city-8836068.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/man-warrior-art-character-cartoon-9093563.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/mario-figure-game-nintendo-super-1558068.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/panda-cartoon-2d-art-character-7918136.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/avocado-food-fruit-6931344.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/guy-anime-cartoon-chibi-character-7330732.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/guy-anime-cartoon-chibi-character-7330788.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/young-male-man-japanese-anime-3815077.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/young-male-man-japanese-anime-3816557.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/shark-jaws-fish-animal-marine-life-2317422.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/white-egg-with-face-illustration-WtolM5hsj14.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/alligator-crocodile-suit-cartoon-576481.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/snowman-winter-christmas-time-snow-7583640.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/monster-cartoon-funny-creature-8534186.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/a-cartoon-character-wearing-a-face-mask-and-running-6-adg66qleM.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/car-vehicle-drive-transportation-8316057.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/camel-desert-two-humped-animal-7751098.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/cartoon-samurai-characters-4790355.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/caveman-prehistoric-character-9211043.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/boy-walk-nature-anime-smile-8350034.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/fish-jaw-angry-cartoon-parrot-fish-1402423.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/fish-telescope-fish-cartoon-1450768.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/cat-pet-animal-kitty-kitten-cute-6484941.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/child-costume-bee-character-8320341.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/guy-anime-cartoon-chibi-character-7330758.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/girl-anime-chibi-cartoon-character-7346667.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/white-and-blue-cat-figurine-u3ZUSIH_eis.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/sock-monkey-plush-toy-on-brown-panel-5INN0oj12u4.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/karate-fighter-cartoon-character-8537724.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/ai-generated-giraffe-doctor-8647702.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/ai-generated-skull-character-8124354.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/a-red-robot-is-standing-on-a-pink-background-unt3066GV-E.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/cartoon-dinosaur-dragon-animal-8539364.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/man-book-read-hanfu-chinese-hanfu-7364886.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/muslim-hijab-child-cartoon-doodle-7747745.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/tambourine-musician-woman-character-9073083.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/ai-generated-man-agent-character-9050849.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/ai-generated-superhero-hero-heroine-7977051.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/a-woman-in-a-tan-jacket-and-tan-pants-QVyAUDUOlMw.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/a-woman-in-a-yellow-shirt-and-black-pants-rdHrrFA1KKg.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/fashion-boy-cartoon-spring-summer-8515751.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/woman-girl-fashion-model-female-8859569.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/woman-cartoon-character-anime-8926994.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/apple-red-delicious-fruit-vitamins-256268.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/apple-food-fresh-fruit-green-1239300.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/fox-animal-wildlife-wild-mammal-9267914.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/christmas-deer-animal-rudolph-8380345.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/ai-generated-man-portrait-7953120.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/created-by-ai-hedgehog-cartoon-8635844.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/dragon-creature-baby-dragon-8480029.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/boy-cartoon-fashion-chibi-kawaii-8515729.png)
![[Uncaptioned image]](extracted/6135755/figures/appendix/blonde-boy-cartoon-character-comic-1300066.png)
🔼 This table visualizes the refined routing maps generated by the AnyStory model during the image generation process. Each row represents a subject, and the columns display the routing maps at different stages of the diffusion process (different time steps). The maps show the areas where the model focuses on injecting subject-specific information. The visualization helps illustrate the effectiveness of the model’s instance-aware routing in controlling the impact of each subject’s condition in the final generated image, thus preventing subject blending.
read the caption
((b)) Refined routing maps
Full paper#