TL;DR#
Current research on Large Language Models (LLMs) faces a significant challenge: enhancing their reasoning abilities. While LLMs excel at many tasks, complex reasoning requires more advanced techniques than simple autoregressive text generation. Existing methods heavily rely on expensive human annotation for training data, limiting scalability. Moreover, test-time reasoning accuracy often remains unsatisfactory.
This paper offers a comprehensive overview of recent LLM reasoning advancements, focusing on approaches that tackle these limitations. It explores the use of reinforcement learning to create high-quality reasoning datasets automatically, reducing human annotation needs. The paper also examines test-time scaling techniques such as chain-of-thought and tree-of-thought prompting, and the utilization of Process Reward Models (PRMs) for guiding LLMs’ reasoning process. Finally, it reviews the groundbreaking OpenAI o1 series and several open-source projects working on similar large reasoning models, offering valuable insights into this rapidly evolving research area.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers because it systematically reviews the latest advancements in Large Language Model (LLM) reasoning, highlighting the shift from human annotation to automated data construction using LLMs. It also introduces the concept of large reasoning models and explores key technical components like reinforcement learning and test-time scaling, opening avenues for developing more advanced reasoning models and prompting new research directions. Its comprehensive nature makes it a valuable resource for both experts and those new to the field.
Visual Insights#

🔼 This figure contrasts two main approaches for creating training datasets for LLMs focused on reasoning: human annotation and automated LLM-based annotation. Human annotation, while producing high-quality data, is expensive and difficult to scale. In contrast, automated methods using LLMs are more cost-effective, but the quality of the resulting data can be less reliable, especially for complex, multi-step reasoning tasks. The figure visually illustrates the process of each annotation method, highlighting their respective costs and scalability.
read the caption
Figure 1: Illustrating different paradigms for annotating LLM reasoning data.
| Method | Label | Paper | Year | Task | Brief Description | |||
| Human Annotation | Outcome | [98] | 2024 |
| Voting annotation | |||
| [104] | 2022 | Preference Alignment | Preference ranking | |||||
| Process | [75] | 2023 | Mathematical reasoning | Stepwise annotation | ||||
| Human-LLM Collaboration | Outcome | [42] | 2023 | Semantic analysis | Human correction | |||
| [152] | 2024 | Text classification | Human correction | |||||
| [74] | 2023 |
|
| |||||
| LLM Automation | Outcome | [106] | 2020 | Commonsense reasoning | Text extraction | |||
| [120] | 2024 | Tool use | Trial and error | |||||
| [65] | 2024 | Embodied tasks | Synthetic augmentation | |||||
| [109] | 2024 |
| Multi-agent collaboration | |||||
| Process | [84] | 2023 | Mathematical reasoning | Stronger LLM | ||||
| [148] | 2024 | Mathematical reasoning | Monte Carlo simulation | |||||
| [156] | 2024 |
| Monte Carlo simulation | |||||
| [85] | 2024 | Mathematical reasoning | MCTS simulation | |||||
| LLM Automation with feedback | Outcome | [70] | 2024 |
| Self-refining | |||
| [135] | 2024 |
| Contrastive learning | |||||
| Process | [183] | 2024 |
|
|
🔼 This table provides a detailed overview of various methods used for constructing training datasets to enhance the reasoning capabilities of Large Language Models (LLMs). It categorizes the methods into three main approaches: Human Annotation, Human-LLM Collaboration, and LLM Automation. For each approach, it lists specific papers, their publication years, the type of data generated (Outcome or Process), the task the data is used for, and a brief description of the annotation method. This table highlights the shift from expensive and time-consuming human annotation to more cost-effective LLM-driven automated methods for dataset creation.
read the caption
Table 1: Training data construction for LLM reasoning.
In-depth insights#
LLM Reasoning Rise#
The rise of LLM reasoning signifies a paradigm shift in AI, moving beyond simple text generation towards complex problem-solving. Early methods relied heavily on prompting techniques like chain-of-thought, coaxing LLMs into step-by-step reasoning. However, these methods were limited by their reliance on human-crafted prompts and their inability to scale effectively. The field has since advanced significantly with the integration of reinforcement learning. This allows for automated generation of high-quality reasoning trajectories and efficient fine-tuning, leading to more robust and accurate LLM reasoning capabilities. This is especially critical in tasks requiring multi-step reasoning, where process reward models are crucial for providing nuanced feedback. Test-time scaling has emerged as another key area, demonstrating that significant performance gains can be achieved simply by increasing compute resources during inference. Open-source initiatives are further accelerating this progress, making powerful reasoning tools more widely accessible and fostering broader research and development.
RL-Driven Scaling#
Reinforcement learning (RL) offers a powerful mechanism to overcome limitations of supervised fine-tuning in large language models (LLMs) for reasoning. RL-driven scaling leverages RL to automatically generate high-quality reasoning trajectories, circumventing the expensive and laborious process of human annotation. This is achieved through trial-and-error search algorithms, where the LLM iteratively refines its reasoning process based on feedback signals. The use of process reward models (PRMs), providing dense, step-wise rewards, further enhances the learning efficiency. This approach is particularly effective in handling complex tasks that involve multiple steps and intermediate decisions, enabling the scaling of LLM reasoning capabilities with increased train-time compute and ultimately contributing to the development of large reasoning models. Combining RL-driven train-time scaling with search-based test-time scaling unlocks a synergistic effect, demonstrating that increased compute during both training and inference can significantly boost reasoning accuracy. This paradigm shift marks a crucial milestone in the advancement of LLMs, paving the way for more sophisticated and powerful reasoning AI.
PRM’s Role#
Process Reward Models (PRMs) play a pivotal role in enhancing Large Language Model (LLM) reasoning capabilities. Unlike traditional outcome-based reward models, PRMs provide feedback at each step of a reasoning process, enabling more effective learning and fine-grained control. This step-wise reward mechanism is particularly beneficial for complex tasks requiring multiple reasoning steps, such as mathematical problem-solving or logical inference. By rewarding correct intermediate steps, PRMs guide the LLM towards generating higher-quality reasoning trajectories. Furthermore, PRMs are instrumental in reducing reliance on expensive human annotation, as they allow for the automatic generation of high-quality training data through trial-and-error search algorithms. In test-time settings, PRMs can further enhance LLM performance by guiding search algorithms, like Monte Carlo Tree Search (MCTS), towards finding optimal solutions. The integration of PRMs represents a crucial advancement in the development of large reasoning models, paving the way for more sophisticated and robust reasoning capabilities in LLMs.
Test-Time Boost#
Test-time boost techniques significantly enhance Large Language Model (LLM) reasoning capabilities without modifying the model’s parameters or retraining. These methods focus on optimizing the inference process itself, often through clever prompting strategies or by employing search algorithms guided by process reward models (PRMs). Chain-of-Thought (CoT) prompting, for example, guides the LLM through explicit reasoning steps, dramatically improving accuracy. Furthermore, techniques like Tree-of-Thoughts (ToT) explore multiple reasoning paths concurrently, leading to more robust and reliable conclusions. PRM-guided search algorithms, such as Monte Carlo Tree Search (MCTS), leverage the PRM’s feedback to intelligently navigate the search space, identifying high-quality reasoning trajectories. The effectiveness of these approaches hinges on the ability to elicit deliberate, step-by-step reasoning from the model during test time, thereby circumventing the limitations of solely relying on pre-training and fine-tuning to enhance reasoning abilities. Test-time scaling laws suggest that increased compute during inference correlates with improved reasoning performance, creating a new avenue for enhancing LLMs by increasing test-time resources.
Future of Reasoning#
The future of reasoning in large language models (LLMs) is bright, but multifaceted. Progress hinges on overcoming challenges in data acquisition, shifting from expensive human annotation to more scalable, automated methods using LLMs themselves. Reinforcement learning techniques, particularly those employing process reward models (PRMs), are crucial for efficiently guiding LLMs towards more robust and human-like reasoning. Test-time scaling, which leverages increased compute during inference to improve accuracy, is another key area of development. The integration of these advancements, alongside further research into prompt engineering and agentic workflows, promises to unlock significant emergent reasoning capabilities in LLMs. Ultimately, the goal is to create truly general-purpose reasoning models that can handle complex, real-world problems, extending beyond current benchmarks and pushing the boundaries of artificial intelligence.
More visual insights#
More on figures

🔼 This figure illustrates three different reward model approaches used in train-time reinforcement learning for enhancing LLM reasoning capabilities. (a) shows a direct reinforcement learning setup where rewards are given immediately after an action. (b) demonstrates multi-step reinforcement learning incorporating an outcome reward model (ORM), where a reward is assigned based on the final outcome. (c) displays a more refined multi-step reinforcement learning approach using a process reward model (PRM), providing step-wise rewards to guide the LLM’s reasoning process during intermediate steps.
read the caption
Figure 2: Reward models for Train-time Reinforcement of LLM Reasoning.

🔼 This figure illustrates four different search algorithms used to enhance reasoning capabilities during the inference phase of large language models (LLMs). Each algorithm explores different solution paths in a search space, aiming to find the optimal answer given a limited budget of compute during inference. The diagrams visually represent the search process, showcasing how each algorithm navigates through various reasoning paths to reach a final decision. The algorithms shown are: Majority Vote, Tree Search, Beam Search, and Lookahead Search. These algorithms vary in their exploration strategy and computational cost.
read the caption
Figure 3: Diagrams of Different Search Algorithms for Test-time Reasoning Enhancement.

🔼 Figure 4 illustrates three test-time methods for enhancing Large Language Model (LLM) reasoning without additional training. These methods leverage the inherent capabilities of LLMs and do not require further fine-tuning or retraining. Verbal Reinforcement Search (VRS) uses iterative feedback and interaction to refine solutions. Memory-based Reinforcement leverages past experiences stored in an external memory module to inform the next reasoning step. Agentic System Search uses LLMs to search and optimize the structure and parameters of an agentic system, which consists of modules for planning, reasoning, tool usage, and memory.
read the caption
Figure 4: Typical training-free test-time enhancing methods: verbal reinforcement search, memory-based reinforcement, and agentic system search.

🔼 This figure presents a taxonomy of benchmarks used to evaluate the reasoning capabilities of Large Language Models (LLMs). It categorizes benchmarks into five main problem types: Math Problems, Logic Problems, Commonsense Problems, Coding Problems, and Agent Problems. Each category is further divided into subcategories based on the specific aspects of reasoning being assessed. For example, Math Problems include subcategories like Math Word Problems, Advanced Mathematical Reasoning, Geometric Reasoning, and Cross-Modal Mathematical Reasoning. The taxonomy visually displays the hierarchical relationships among different benchmark types and sub-types, offering a comprehensive overview of the evaluation landscape for LLM reasoning.
read the caption
Figure 5: A Taxonomy for LLM Reasoning Benchmarks.
More on tables
| Text classification |
| Semantic analysis |
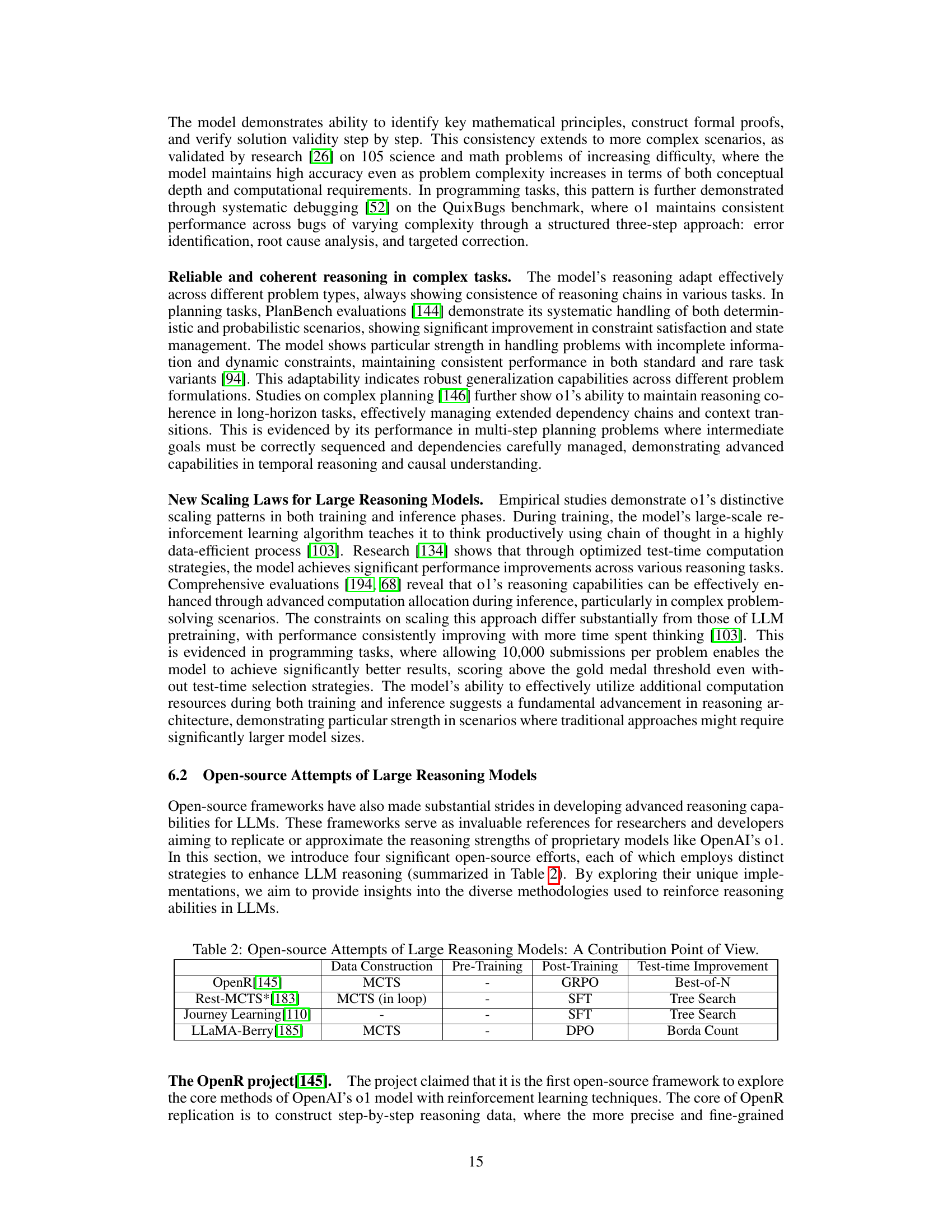
🔼 This table compares four open-source projects that aim to replicate or improve upon the reasoning capabilities of OpenAI’s o1 series models. For each project, it details the data construction methods (pre-training and post-training), test-time improvement techniques, and the overall approach or contribution perspective.
read the caption
Table 2: Open-source Attempts of Large Reasoning Models: A Contribution Point of View.
| Text classification |
| Semantic analysis |
🔼 This table lists representative research papers that explore test-time reasoning enhancement techniques for Large Language Models (LLMs) without requiring additional training. The methods are categorized into three approaches: Verbal Reinforcement Search (VRS), Memory-based Reinforcement, and Agentic System Search. Each category contains various sub-approaches and example works that demonstrate how to improve the reasoning abilities of LLMs at test time, solely by modifying the input prompt or search strategy.
read the caption
Table 3: A list of representative works of training-free test-time reinforcing.
Full paper#