TL;DR#
Current research on generative models focuses on enhancing training-time scaling. However, inference-time scaling, which involves improving model performance with additional compute during inference, is less explored. This paper tackles this gap for diffusion models, a class of generative models known for their flexibility in adjusting inference-time computation via the number of denoising steps. The authors point out that previous research shows the performance gains typically flatten after a few dozen denoising steps, highlighting a need for exploring different avenues to improve inference-time scaling.
This work proposes a search framework aimed at identifying better noises during the diffusion sampling process. The framework involves a search strategy across a design space defined by two axes: the verifiers that provide feedback on noise candidates and the algorithms used to find those candidates. Extensive experiments on various image generation benchmarks (class-conditioned and text-conditioned) demonstrate that increasing inference-time compute through the proposed search leads to significant quality improvements in the generated samples. The authors found that no single configuration is universally optimal; instead, each task requires a specific search setup for optimal performance. This discovery underscores the importance of carefully selecting verifiers and algorithms based on the specific application scenario.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in generative models because it introduces a novel framework for inference-time scaling in diffusion models. This expands the scope of scaling laws beyond training and opens avenues for improving the efficiency and quality of generative models, particularly in computationally expensive tasks. The findings also highlight the need for carefully designed verifiers in different application scenarios and thus provide new directions for future work. The research is relevant to current trends of efficient AI and improving generative model performance.
Visual Insights#

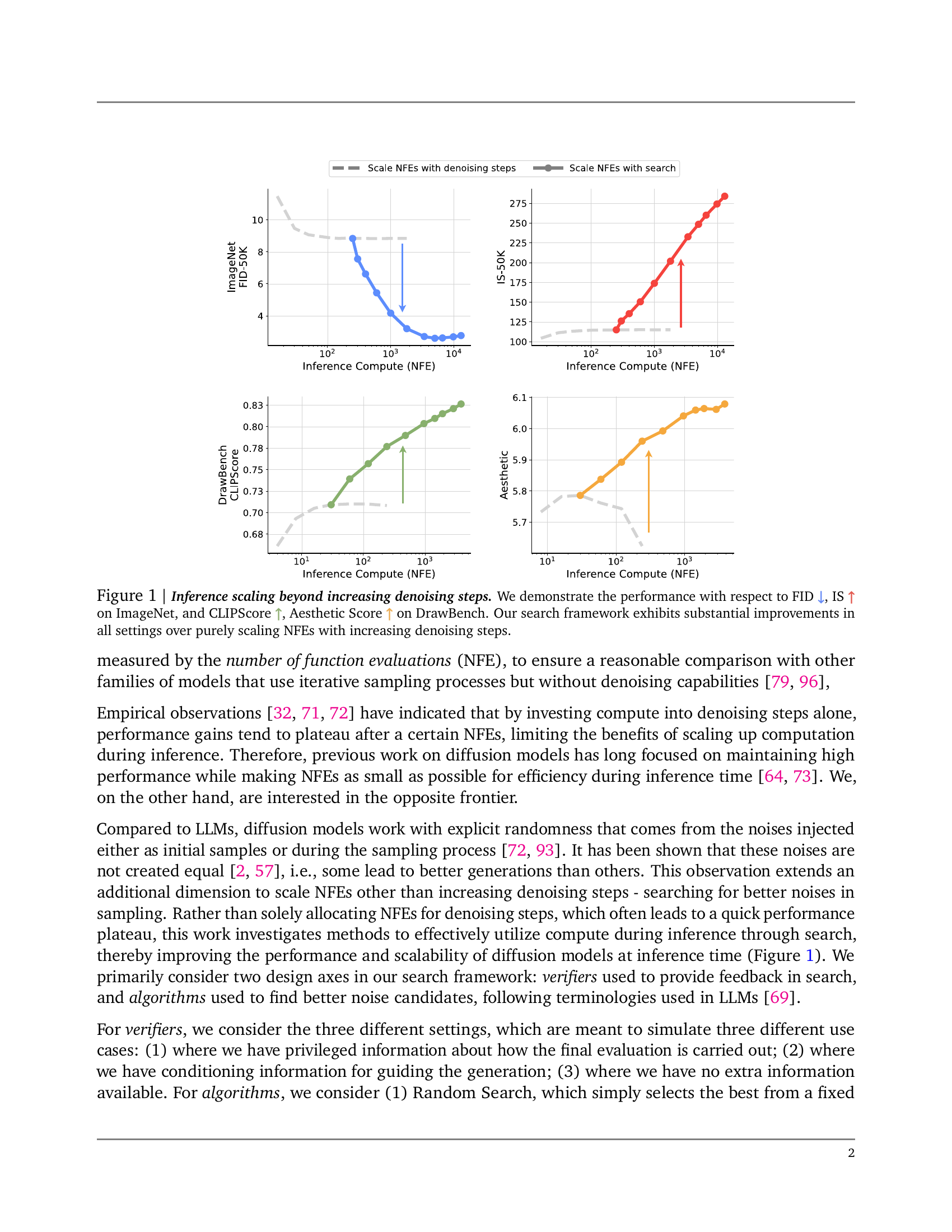
🔼 This figure displays the results of an experiment investigating inference-time scaling in diffusion models. It compares the performance of simply increasing the number of function evaluations (NFEs) via denoising steps against a novel search framework for better noise candidates. Four metrics are used to evaluate performance: Fréchet Inception Distance (FID), Inception Score (IS), CLIPScore, and Aesthetic Score. Lower FID values and higher IS, CLIPScore, and Aesthetic Score values indicate better image generation quality. The results demonstrate that the search framework leads to significant performance improvements compared to simply increasing denoising steps, suggesting that a major source of efficiency lies in efficiently searching for good noise candidates instead of just solely relying on increasing the computational budget via more denoising steps. The improvement is observed on both ImageNet and DrawBench datasets.
read the caption
Figure 1: Inference scaling beyond increasing denoising steps. We demonstrate the performance with respect to FID ↓bold-↓\boldsymbol{\downarrow}bold_↓, IS ↑bold-↑\boldsymbol{\uparrow}bold_↑ on ImageNet, and CLIPScore ↑bold-↑\boldsymbol{\uparrow}bold_↑, Aesthetic Score ↑bold-↑\boldsymbol{\uparrow}bold_↑ on DrawBench. Our search framework exhibits substantial improvements in all settings over purely scaling NFEs with increasing denoising steps.
| Verifier | Color | Shape | Texture | Spatial | Numeracy | Complex |
|---|---|---|---|---|---|---|
| - | 0.7692 | 0.5187 | 0.6287 | 0.2429 | 0.6167 | 0.3600 |
| Aesthetic | 0.7618 | 0.5119 | 0.5826 | 0.2593 | 0.6159 | 0.3472 |
| CLIP | 0.8009 | 0.5722 | 0.7005 | 0.2988 | 0.6457 | 0.3704 |
| ImageReward | 0.8303 | 0.6274 | 0.7364 | 0.3151 | 0.6789 | 0.3810 |
| Ensemble | 0.8204 | 0.5959 | 0.7197 | 0.3043 | 0.6623 | 0.3754 |
🔼 This table presents the results of applying a search algorithm to improve the performance of a text-to-image model (FLUX-1-dev) on the T2I-CompBench benchmark. The search algorithm uses a ‘Verifier Ensemble’ which combines multiple evaluation metrics. The table shows the performance of the model with and without the search algorithm, comparing different aspects of image generation quality such as color, shape, texture, spatial relationships, numeracy, and complex composition. The ’no search’ baseline uses 30 NFEs (Number of Function Evaluations) for denoising, while the search experiments use an additional 1920 NFEs allocated to the search process.
read the caption
Table 1: Performance of search with FLUX.1-dev on T2I-CompBench. We use random search with Verifier Ensemble to obtain the samples; for evaluation, we use the pipeline provided in T2I-CompBench. The first row denotes the performance without search where we fix the denoising budget to be 30303030 NFEs, and for the rest, we fix the search budget to be 1920192019201920 NFEs.
In-depth insights#
Inference-Time Scaling#
Inference-time scaling investigates enhancing model performance not by training longer or with more data, but by allocating additional compute during the inference phase itself. This contrasts with traditional scaling laws which focus on training-time improvements. The paper explores this concept within the context of diffusion models, a class of generative models with inherent flexibility in inference-time computation due to their iterative denoising process. The core idea is that increased computational resources at inference time can lead to better results, going beyond simply increasing the number of denoising steps. The authors propose a framework with two key axes: verifiers (to evaluate sample quality) and search algorithms (to identify optimal noise candidates for the sampling process). Through experiments, they demonstrate that inference-time scaling, particularly using search strategies, significantly improves the quality of generated samples. This improvement is shown across different benchmarks, showcasing the viability and efficiency of this approach. Importantly, the study highlights that the optimal combination of verifiers and algorithms is task-dependent, demanding careful consideration and tailoring for specific applications.
Search Algorithms#
The core of the proposed inference-time scaling framework lies in its innovative search algorithms. Instead of solely relying on increasing denoising steps, these algorithms actively seek out superior noise candidates within the sampling process. Three distinct search algorithms are explored: Random Search (a baseline approach), Zero-Order Search (iteratively refining noise candidates via verifier feedback), and Search over Paths (iteratively refining the entire sampling trajectory). The choice of algorithm significantly impacts performance, with Zero-Order and Search over Paths offering more nuanced control and often superior results compared to Random Search. A key consideration is the algorithm’s ability to effectively leverage verifier feedback without overfitting to verifier biases or causing mode collapse; finding the balance is crucial for optimal performance. The framework’s design highlights the interplay between verifier selection and algorithm choice, underscoring the need for task-specific configurations to maximize efficiency and prevent suboptimal outcomes.
Verifier Analysis#
Verifier analysis in this context would involve a deep dive into the different methods used to assess the quality of generated samples. It would consider not only the quantitative metrics employed, but also the inherent biases and limitations of each approach. Key aspects would include exploring the alignment between verifiers and specific generation tasks, investigating how different verifiers respond to various image attributes, and evaluating the effectiveness of various combinations of verifiers, such as ensembles, to gain a more holistic understanding. A crucial point to analyze is the potential for overfitting or “verifier hacking,” where the generation process becomes excessively optimized for a particular verifier at the expense of overall quality. By systematically examining these factors, a comprehensive analysis can reveal valuable insights into the strengths and weaknesses of different verifiers and inform the design of more robust and effective evaluation strategies.
Scaling Limits#
The concept of “Scaling Limits” in the context of diffusion models refers to the inherent boundaries in improving model performance by simply increasing computational resources, such as the number of denoising steps. While increasing computation initially yields improvements, gains eventually plateau, implying that other strategies are required to surpass this limit. This plateau signifies a critical point beyond which further computational investment provides diminishing returns. The paper likely explores alternative approaches to inference-time scaling, such as refined noise search techniques, which offer a pathway to improved generation quality even with fixed computational budgets. Identifying the optimal balance between increased denoising steps and noise search strategies is crucial for efficient and effective inference-time scaling.
Future Directions#
Future research should explore more sophisticated search algorithms beyond random and zero-order methods, potentially incorporating gradient-based techniques or reinforcement learning for more efficient noise exploration. Developing task-specific verifiers is crucial to overcome the limitations of generic verifiers and address the issue of verifier hacking. Investigating the interplay between training and inference-time scaling is key to unlocking the full potential of diffusion models. Further research should assess the generalizability of inference-time scaling across diverse model architectures and datasets. Finally, a more thorough examination of the computational cost versus quality trade-off is needed for different search strategies and model sizes to optimize for specific application requirements.
More visual insights#
More on figures

🔼 This figure illustrates three different search algorithms used to find better noise candidates during the sampling process of diffusion models. Random Search randomly samples noise candidates and selects the one with the best verifier score. Zero-Order Search iteratively refines noise candidates by sampling from the neighborhood of a ‘pivot’ noise, choosing the best candidate at each step. Search over Paths samples noise at intermediate points in the diffusion process to explore alternative sampling trajectories.
read the caption
Figure 2: Illustration of Search Algorithms. Left: Random Search selects the best sample according to the verifier score and rejects the rest. Center: Zero-Order Search samples N𝑁Nitalic_N candidates in the neighborhood of the pivot noise at each step, and selects the best one according to the verifier to continue the search from. Right: Search over Paths sample noises at intermediate sampling steps to add to current samples to expand the sampling trajectories, and select the best one to continue the search.

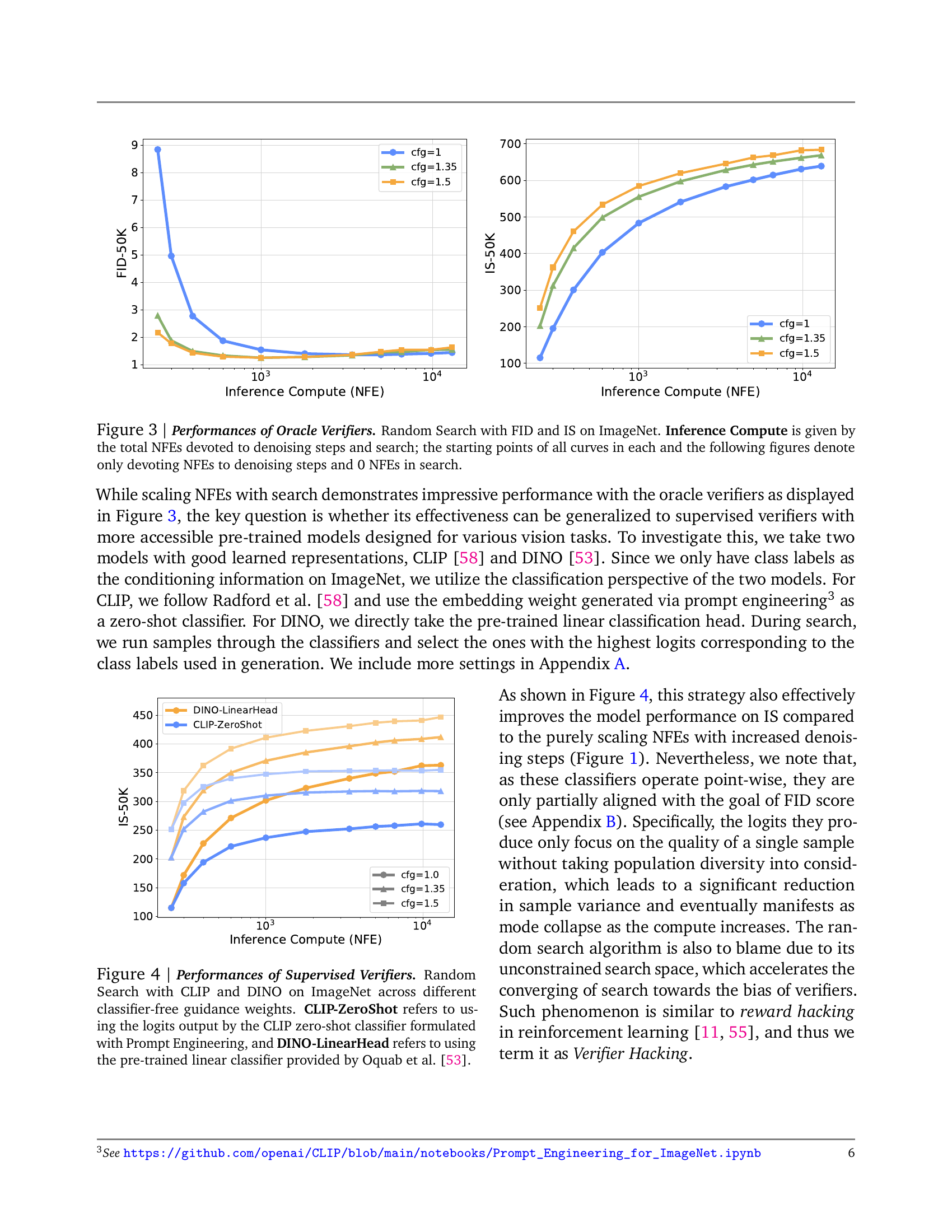
🔼 This figure displays the results of experiments using oracle verifiers (FID and IS) on ImageNet with the Random Search algorithm. The x-axis represents the total number of function evaluations (NFEs), which is the computational budget allocated to both denoising steps and the search process. The y-axis shows the performance metrics (FID and IS). The starting points of each curve indicate the baseline performance achieved by only using the optimal number of NFEs for denoising steps (no NFEs devoted to the search). The curves demonstrate how performance improves as more NFEs are allocated to the search process.
read the caption
Figure 3: Performances of Oracle Verifiers. Random Search with FID and IS on ImageNet. Inference Compute is given by the total NFEs devoted to denoising steps and search; the starting points of all curves in each and the following figures denote only devoting NFEs to denoising steps and 0 NFEs in search.

🔼 This figure displays the performance of using CLIP and DINO as supervised verifiers for a random search method on the ImageNet dataset. The x-axis represents the inference compute (measured in number of function evaluations or NFEs), while the y-axis shows the Inception Score (IS). Different lines represent different classifier-free guidance (CFG) weights (1.0, 1.35, and 1.5). CLIP-ZeroShot uses the logits from CLIP’s zero-shot classifier, created using prompt engineering, while DINO-LinearHead uses a pre-trained linear classifier from the DINO model. The graph showcases how the ImageNet model’s performance improves with increasing inference compute when using supervised verifiers, illustrating inference-time scaling.
read the caption
Figure 4: Performances of Supervised Verifiers. Random Search with CLIP and DINO on ImageNet across different classifier-free guidance weights. CLIP-ZeroShot refers to using the logits output by the CLIP zero-shot classifier formulated with Prompt Engineering, and DINO-LinearHead refers to using the pre-trained linear classifier provided by Oquab et al. [53].

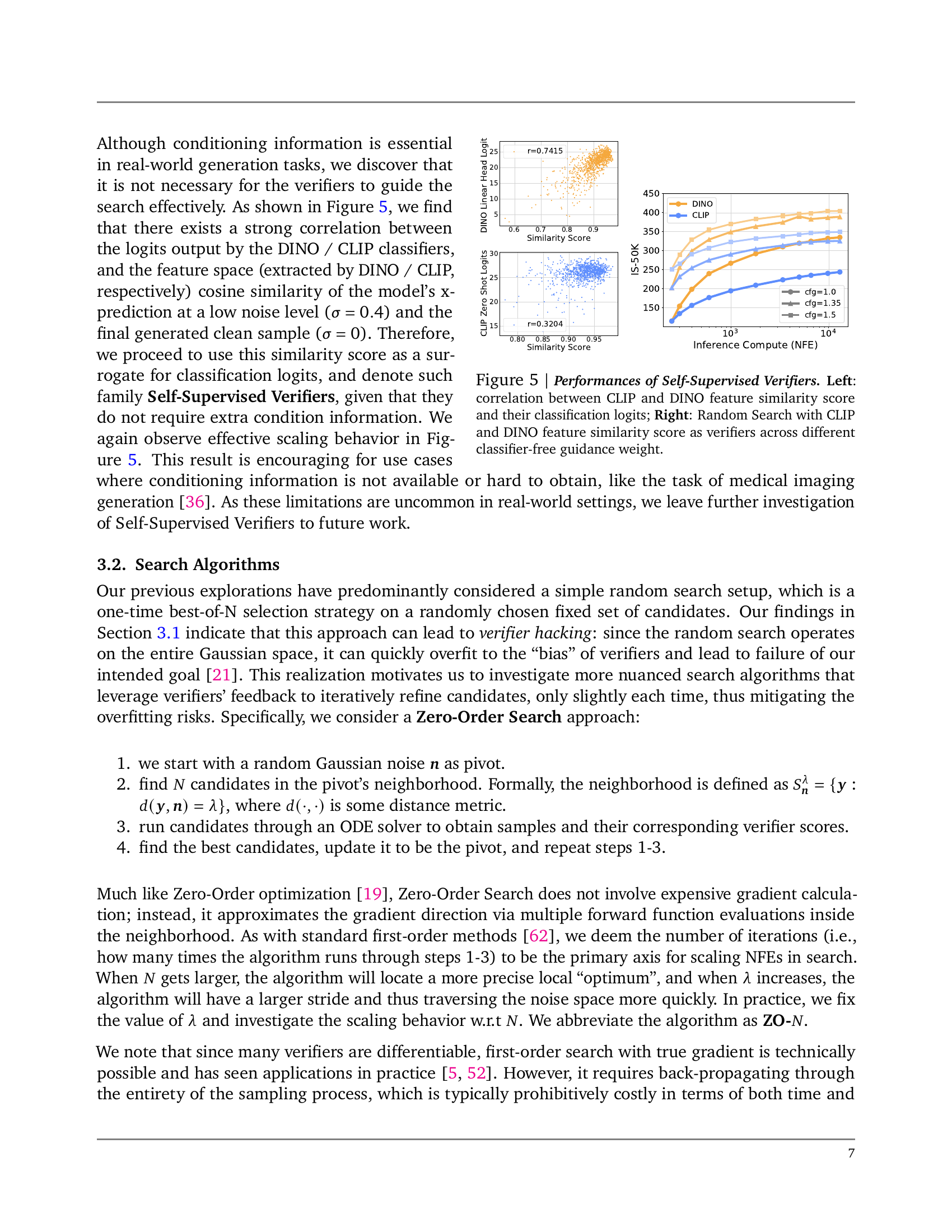
🔼 This figure analyzes the effectiveness of self-supervised verifiers for inference-time scaling in diffusion models. The left panel shows the strong correlation between the cosine similarity of CLIP/DINO features (comparing low-noise and final generated image features) and the classification logits produced by CLIP/DINO classifiers. This correlation justifies using feature similarity as a surrogate for classification logits, avoiding the need for explicit class labels. The right panel demonstrates the performance improvement achieved by using CLIP/DINO feature similarity scores in a Random Search framework across various classifier-free guidance (CFG) weights on an ImageNet classification task. The results highlight the efficacy of self-supervised methods, showing substantial performance gains from scaling inference compute using a search-based approach.
read the caption
Figure 5: Performances of Self-Supervised Verifiers. Left: correlation between CLIP and DINO feature similarity score and their classification logits; Right: Random Search with CLIP and DINO feature similarity score as verifiers across different classifier-free guidance weight.

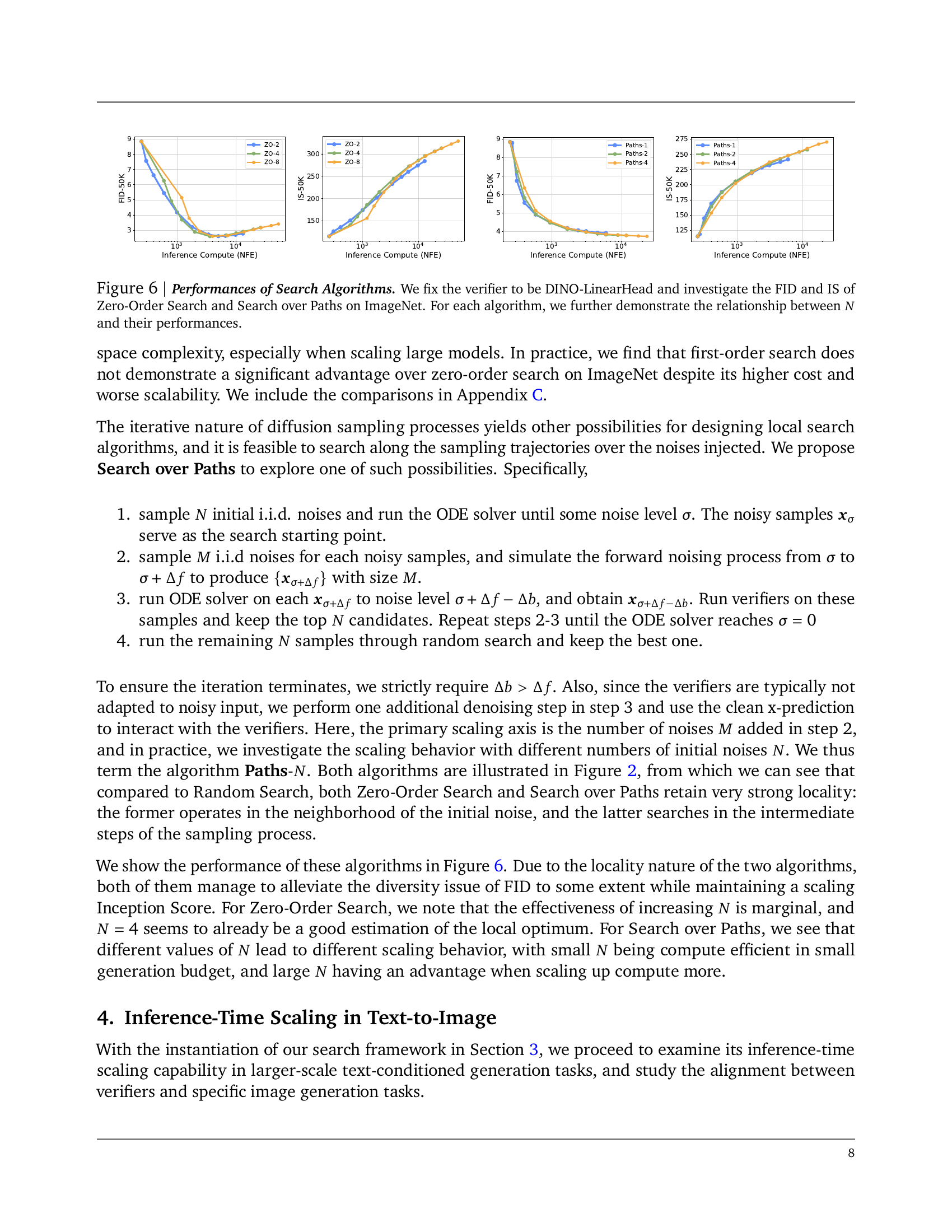
🔼 This figure displays the performance of different search algorithms (Random Search, Zero-Order Search, and Search over Paths) used for improving the inference-time scaling of diffusion models. The experiments were conducted on the ImageNet dataset, using the DINO-LinearHead verifier to evaluate the generated images. The results are shown in terms of Fréchet Inception Distance (FID) and Inception Score (IS). The relationship between the performance of the algorithms and the hyperparameter N (the number of noise candidates or intermediate sampling steps) is investigated. Lower FID values and higher IS values indicate better image quality.
read the caption
Figure 6: Performances of Search Algorithms. We fix the verifier to be DINO-LinearHead and investigate the FID and IS of Zero-Order Search and Search over Paths on ImageNet. For each algorithm, we further demonstrate the relationship between N𝑁Nitalic_N and their performances.

🔼 This figure visualizes the impact of scaling computation on diffusion model generation quality. Each row shows samples generated from a different model (SiT-XL, PixArt-Σ, FLUX-1.dev) using two different strategies: increasing the number of function evaluations (NFEs) in denoising steps (left three images) and increasing the NFEs in search for better noises (right four images). The first two rows use the SiT-XL model with a DINO-LinearHead verifier, while the third row utilizes the PixArt-Σ model with a Verifier Ensemble, and the last two rows use the FLUX-1.dev model with a Verifier Ensemble. This demonstrates how increasing computational budget can improve generation quality in different ways.
read the caption
Figure 7: Visualizations of Scaling Behaviors. Each row is constructed as follows: left three: sampled with increasing NFEs in denoising steps; right four: sampled with increasing NFEs in search. First two rows are sampled from SiT-XL [50] with DINO-LinearHead, third row is sampled from PixArt-ΣΣ\Sigmaroman_Σ [8] with Verifier Ensemble, and last two rows are sampled from FLUX-1.dev [41] with Verifier Ensemble.

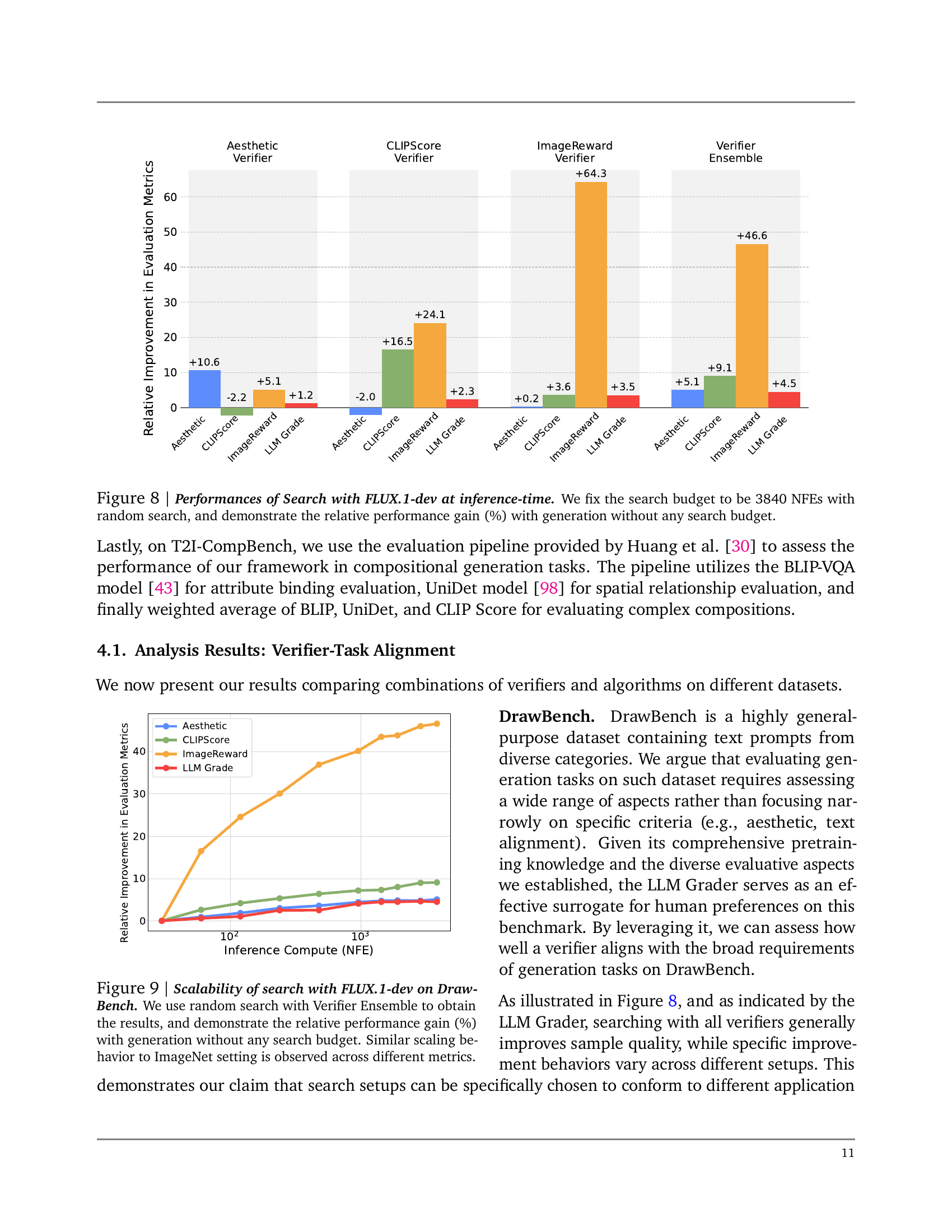
🔼 This figure showcases the performance improvements achieved by incorporating a search process into the inference stage of the FLUX-1-dev model, a cutting-edge text-to-image diffusion model. The experiment uses a fixed search budget of 3840 NFEs (Number of Function Evaluations) with a random search strategy, and compares the results to model generations made without any search at all. The results are presented as percentage improvements across various evaluation metrics, including the aesthetic score, CLIP score, ImageReward score, and a combined Verifier Ensemble score. This provides a comprehensive assessment of how effectively the search method enhances the quality of generated images.
read the caption
Figure 8: Performances of Search with FLUX.1-dev at inference-time. We fix the search budget to be 3840384038403840 NFEs with random search, and demonstrate the relative performance gain (%) with generation without any search budget.

🔼 Figure 9 illustrates the scalability of the proposed inference-time scaling method using the FLUX-1-dev model on the DrawBench dataset. The experiment uses random search with a Verifier Ensemble to evaluate performance. The graph displays the relative improvement in various metrics (Aesthetic, CLIPScore, ImageReward, and LLM Grader) when using the search method compared to generation without any search. The results show that the improvement is consistent across all four metrics, showcasing the scalability and effectiveness of the search method even with a more complex, multi-faceted dataset like DrawBench. The scaling behavior is similar to that observed earlier in experiments using the ImageNet dataset. This demonstrates the generalizability of the inference-time scaling framework across different datasets and metrics.
read the caption
Figure 9: Scalability of search with FLUX.1-dev on DrawBench. We use random search with Verifier Ensemble to obtain the results, and demonstrate the relative performance gain (%) with generation without any search budget. Similar scaling behavior to ImageNet setting is observed across different metrics.

🔼 This figure shows how the number of function evaluations (NFEs) used in a single search iteration affects the performance of the SiT-XL diffusion model on the ImageNet dataset. The denoising budget (the number of NFEs used in the denoising process) is held constant at 250. The plot displays how different allocations of NFEs to the search process affect the model’s final performance. It shows that there are regions of optimal NFEs/iter, with diminishing returns when more NFEs/iter are used. The results show different performance curves for different NFEs/iter values, helping to identify the most computationally efficient way to balance search and denoising.
read the caption
Figure 10: Performance of scaling compute for single search iteration. We use the SiT-XL model, fix the denoising budget to 250250250250 NFE, and demonstrate the performance differences with respect to the NFEs devoted to a single search iteration.

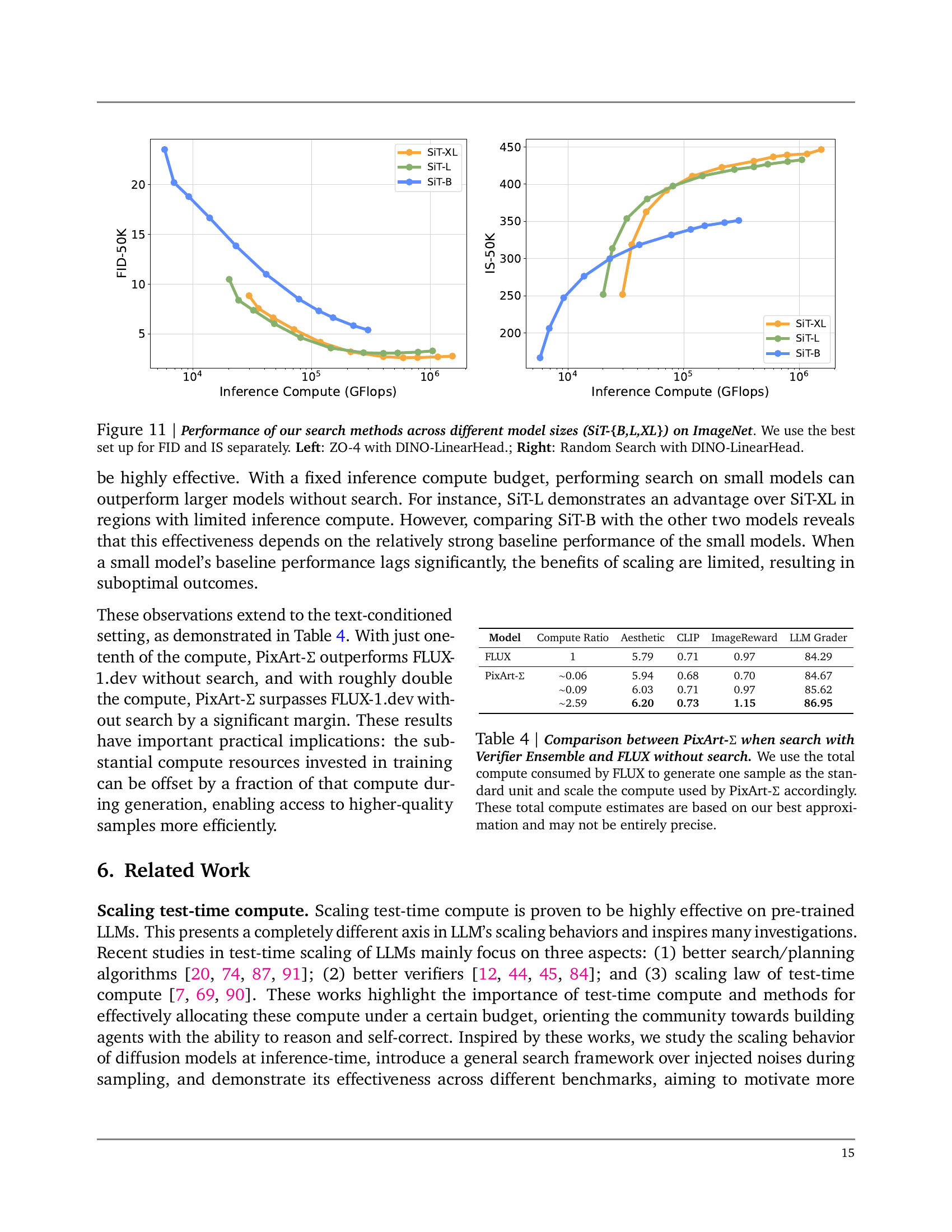
🔼 This figure demonstrates the effectiveness of inference-time scaling for different-sized diffusion models on the ImageNet dataset. It compares the performance of two search methods (Zero-Order Search and Random Search) when applied to three different sizes of the SiT model (SiT-B, SiT-L, and SiT-XL). The performance metric used is the Frechet Inception Distance (FID) and the Inception Score (IS). For each model size, the plot shows how the FID and IS improve as the computation budget (measured in GFLOPs) allocated to the search process increases. The left panel shows the results obtained using Zero-Order Search (ZO-4) with a DINO-LinearHead verifier, and the right panel shows the results of Random Search with a DINO-LinearHead verifier. By comparing the performance across different model sizes and search methods, the figure helps to illustrate how effectively inference-time compute can be used to enhance the quality of images generated by diffusion models, particularly when resources are limited.
read the caption
Figure 11: Performance of our search methods across different model sizes (SiT-{B,L,XL}) on ImageNet. We use the best set up for FID and IS separately. Left: ZO-4 with DINO-LinearHead.; Right: Random Search with DINO-LinearHead.

🔼 This figure demonstrates the effect of tuning two hyperparameters on the performance of two different search algorithms used to improve the quality of samples generated by a diffusion model. The left panel shows the impact of varying step sizes (λ) in the Zero-Order Search algorithm on the FID (Fréchet Inception Distance) and IS (Inception Score) metrics. The right panel illustrates how changing the path lengths (L) in the Search Over Paths algorithm affects these same metrics. Both experiments utilize the SiT-XL model and employ DINO classification logits as the verifier. The results highlight the interplay between hyperparameter tuning, algorithm choice, and overall model performance.
read the caption
Figure 12: Performance of tuning additional parameters for algorithms. Left: Zero-Order Search with step sizes λ𝜆\lambdaitalic_λ; Right: Search Over Paths with lengths L𝐿Litalic_L. We use SiT-XL and fix the verifier to be the classification logits from DINO.

🔼 This figure displays the results of applying random search on ImageNet using the SiT-XL model. The search process was guided by either DINO or CLIP classification logits. The figure presents four key metrics: FID (Fréchet Inception Distance), IS (Inception Score), Precision, and Recall, which are evaluated to assess the quality and diversity of the generated images. The x-axis likely represents increasing computational cost, as more samples are processed during the search, and the y-axis shows the corresponding metric scores. The plots visualize how these metrics change as the amount of computation allocated to the search is increased, showcasing the trade-off between computation cost and image quality.
read the caption
Figure 13: Performance of Random Search on ImageNet against DINO and CLIP classification logits. We use random search on the SiT-XL model and report FID, IS, Precision, and Recall.

🔼 This figure compares the performance of two search algorithms, Zero-Order Search and First-Order Search, used to improve the quality of samples generated by a diffusion model. The SiT-XL model was used with the DINO-LinearHead verifier. Zero-Order Search iteratively refines noise candidates based on verifier feedback, while First-Order Search uses the gradient of the verifier to guide the refinement. The x-axis represents the computational cost (in number of function evaluations), and the y-axis shows the resulting FID and IS scores. The comparison is made at approximately the same computational cost for both algorithms; the cost of the backward pass in First-Order Search is estimated to be roughly three times that of the forward pass.
read the caption
Figure 14: Comparison between Zero-Order and First-Order Search. We use the SiT-XL model and fix the verifier to be the DINO-LinearHead. The Inference Compute is aligned via the rough estimation of cost(backward) ∼similar-to\sim∼ 3×\times×cost(forward).

🔼 Figure 15 presents a correlation analysis between three self-supervised verifiers (CLIP, DINO, and SigLIP) and CLIPScore, a human-evaluated metric for image-text alignment, using samples generated by the FLUX-1-dev model. The figure displays the relationships using scatter plots to show how well the similarity scores calculated by each of the self-supervised verifiers aligns with human judgment (CLIPScore). This analysis helps to understand the biases of each verifier and how well they are aligned with human perception of the quality of generated images.
read the caption
Figure 15: From Left to Right: Correlation of CLIP, DINO, and SigLIP feature similarity score with CLIPScore. All points are generated from FLUX.1-dev.

🔼 This figure shows the detailed prompt used to instruct the large language model (LLM) grader on how to evaluate generated images. The prompt outlines five key aspects to assess: Accuracy to Prompt, Creativity and Originality, Visual Quality and Realism, Consistency and Cohesion, and Emotional or Thematic Resonance. For each aspect, the grader is instructed to provide a score from 0 to 10 and a brief justification. Finally, the grader is asked to provide an overall weighted score reflecting the overall image quality.
read the caption
Figure 16: The detailed prompt for evaluation with the LLM Grader.

🔼 This figure visualizes the impact of increasing inference-time compute on the quality of generated images. The left three images are generated by increasing the number of denoising steps while keeping the inference-time compute constant. The right three images are generated by increasing the inference-time compute through search, while maintaining a constant number of denoising steps. The goal is to show that increasing computation via search can improve image quality beyond simply increasing the number of denoising steps.
read the caption
Figure 17: “loggerhead turtle” (33)

🔼 Figure 18 presents a series of images generated using the SIT-XL model depicting a Sulphur-crested cockatoo. The top row shows images generated by increasing the number of denoising steps in the diffusion process. This demonstrates the model’s improvement in image quality as more computational resources are allocated. The bottom row showcases images generated using the proposed search framework, which iteratively refines noise candidates to enhance image quality with increased computational investment. The improvement shown in the bottom row highlights the effectiveness of the search framework in improving the generation performance beyond simply increasing the number of denoising steps.
read the caption
Figure 18: “Sulphur-crested cockatoo” (89)

🔼 Figure 19 displays six images of Siberian huskies generated using the SiT-XL model. The first three images were generated by increasing the number of denoising steps from 10 to 250, illustrating how the image quality improves with increased computational resources during the denoising process. The last three images were generated using Zero-Order Search with the DINO classification verifier, where the number of NFEs invested were increased from 450 to 6650. This demonstrates the effect of the search process on image quality, highlighting that the quality further improves when increased computational resources are allocated to the noise search process during inference.
read the caption
Figure 19: “Siberian husky” (250)

🔼 This figure visualizes the results of inference-time scaling experiments using the ‘Arctic wolf’ prompt. The images showcase the variations in generated images when increasing the number of function evaluations (NFEs) in the denoising process versus increasing NFEs through a search process for improved noise selection. The left three images are generated by simply increasing denoising steps; the right four images are produced using a search algorithm to find better noises for the sampling process. This comparison highlights the impact of the search method on image quality and diversity.
read the caption
Figure 20: “Arctic wolf” (270)

🔼 This figure shows six different images generated by a text-to-image model when prompted with the word ‘baseball’. The images demonstrate variations in style, perspective, and level of detail, highlighting the model’s ability to generate multiple plausible interpretations of the prompt. Three images on the left are generated by simply increasing the number of denoising steps; and the three images on the right are generated by employing a search algorithm to identify better sampling noises in the diffusion process, demonstrating the effectiveness of the search method in improving the quality of the generated images.
read the caption
Figure 21: “baseball” (429)

🔼 This figure shows six different images generated by the FLUX-1.dev model using the Verifier Ensemble for the prompt ‘hammer’. The left three images show the result of using the standard denoising process with an increasing number of denoising steps (10, 20, and 250). The right three images display the outputs of using the Zero-Order search method with increased inference-time compute (450, 1850, and 6650). This illustrates how increased computation during inference time, through search, can lead to improved image quality in diffusion models.
read the caption
Figure 22: “hammer” (587)

🔼 This figure shows six images generated by a text-to-image model using the prompt ‘volcano’. The left three images demonstrate the visual results as the number of denoising steps increases (10, 20, 250). The right three images illustrate the impact of increasing inference-time compute through search using a zero-order search method with the DINO classifier as a verifier. This visualization demonstrates how the quality and detail of the generated image improve with both increased denoising steps and increased inference computation in the search process.
read the caption
Figure 23: “volcano” (980)
More on tables
| Verifier | Aesthetic | CLIPScore | ImageReward | LLM Grader |
|---|---|---|---|---|
| - | 5.79 | 0.71 | 0.97 | 84.29 |
| Aesthetic + Random | 6.38 | 0.69 | 0.99 | 86.04 |
| + ZO-2 | 6.33 | 0.69 | 0.96 | 85.90 |
| + Paths-2 | 6.31 | 0.70 | 0.95 | 85.86 |
| CLIPScore + Random | 5.68 | 0.82 | 1.22 | 86.15 |
| + ZO-2 | 5.72 | 0.81 | 1.16 | 85.48 |
| + Paths-2 | 5.71 | 0.81 | 1.14 | 85.45 |
| ImageReward + Random | 5.81 | 0.74 | 1.58 | 87.09 |
| + ZO-2 | 5.79 | 0.73 | 1.50 | 86.22 |
| + Paths-2 | 5.76 | 0.74 | 1.49 | 86.33 |
| Ensemble + Random | 6.06 | 0.77 | 1.41 | 88.18 |
| + ZO-2 | 5.99 | 0.77 | 1.38 | 87.25 |
| + Paths-2 | 6.02 | 0.76 | 1.34 | 86.84 |
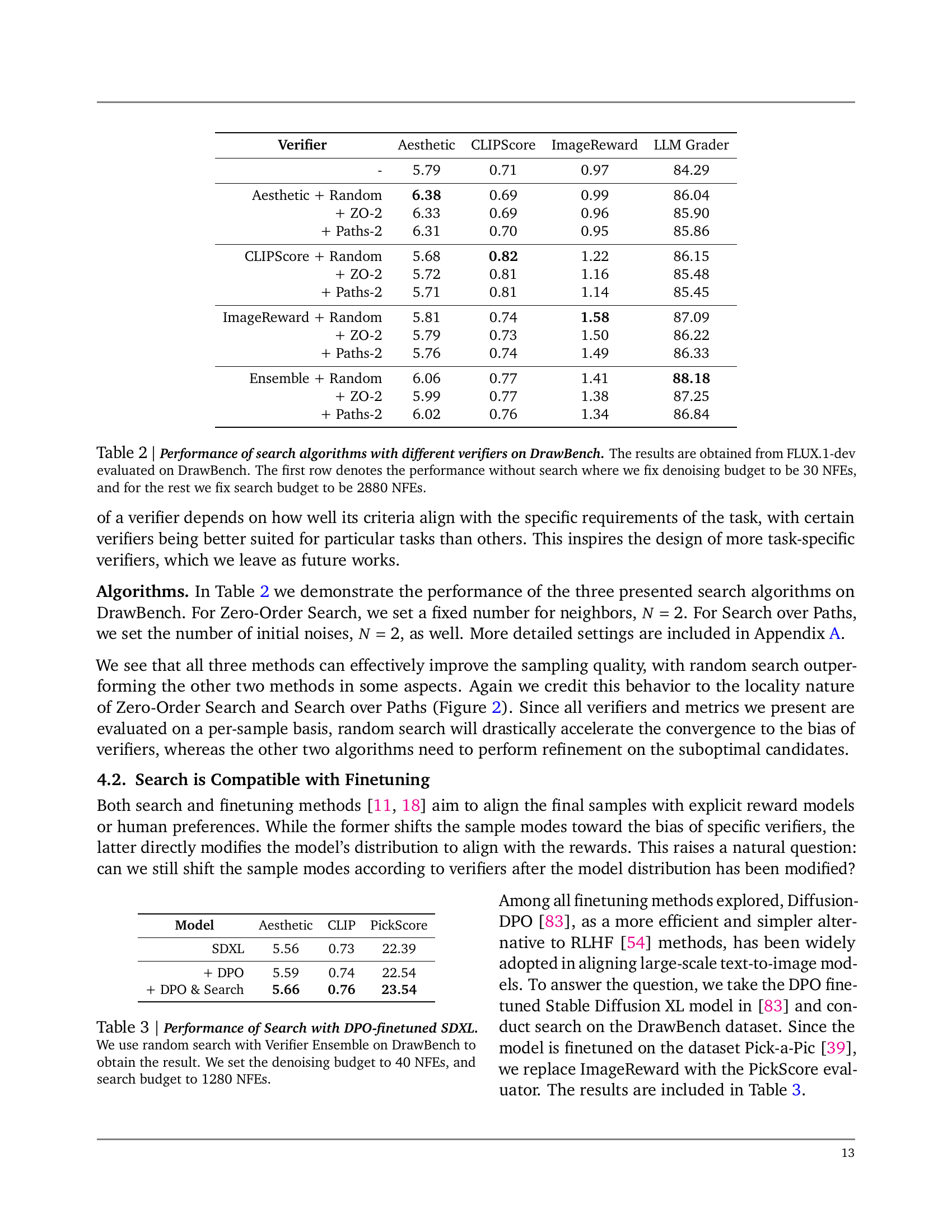
🔼 This table presents a comparison of different search algorithms (Random Search, Zero-Order Search with 2 neighbors, and Search over Paths with 2 paths) combined with various verifiers (Aesthetic, CLIPScore, ImageReward, and a Verifier Ensemble) for text-to-image generation using the FLUX-1-dev model on the DrawBench dataset. The first row shows baseline performance without any search, using 30 NFEs for denoising. The remaining rows show the results of applying the search algorithms, with 2880 NFEs allocated to the search process.
read the caption
Table 2: Performance of search algorithms with different verifiers on DrawBench. The results are obtained from FLUX.1-dev evaluated on DrawBench. The first row denotes the performance without search where we fix denoising budget to be 30303030 NFEs, and for the rest we fix search budget to be 2880288028802880 NFEs.
| Model | Aesthetic | CLIP | PickScore |
|---|---|---|---|
| SDXL | 5.56 | 0.73 | 22.39 |
| + DPO | 5.59 | 0.74 | 22.54 |
| + DPO & Search | 5.66 | 0.76 | 23.54 |
🔼 This table presents the results of applying inference-time scaling to a pre-trained Stable Diffusion XL (SDXL) model that has been fine-tuned using a diffusion-based preference optimization (DPO) technique. The experiment uses the DrawBench dataset, which is designed to assess the ability of models to generate realistic and high-quality images from complex prompts. Random search was employed with the verifier ensemble, ensuring a holistic evaluation across various metrics. The table compares the performance when only denoising steps are used (no search) to various levels of computation investment for the search process. The denoising budget was kept constant at 40 NFEs, while the search budget was varied, indicating how much additional computational power is being used for searching improved noise parameters during the sampling phase, which improves sample quality. The metrics reported are Aesthetic, CLIPScore, and ImageReward, all of which capture different aspects of image quality.
read the caption
Table 3: Performance of Search with DPO-finetuned SDXL. We use random search with Verifier Ensemble on DrawBench to obtain the result. We set the denoising budget to 40404040 NFEs, and search budget to 1280128012801280 NFEs.
| Model | Compute Ratio | Aesthetic | CLIP | ImageReward | LLM Grader |
|---|---|---|---|---|---|
| FLUX | 1 | 5.79 | 0.71 | 0.97 | 84.29 |
| PixArt- | 0.06 | 5.94 | 0.68 | 0.70 | 84.67 |
| 0.09 | 6.03 | 0.71 | 0.97 | 85.62 | |
| 2.59 | 6.20 | 0.73 | 1.15 | 86.95 |
🔼 This table compares the performance of the PixArt-Σ model with and without the proposed inference-time search method. The baseline is the FLUX model without search. The total compute used by the FLUX model to generate a single sample is used as a standard unit, against which the compute used by PixArt-Σ (with varying search intensity) is scaled. Note that the compute estimations provided in the table are approximations.
read the caption
Table 4: Comparison between PixArt-ΣΣ\Sigmaroman_Σ when search with Verifier Ensemble and FLUX without search. We use the total compute consumed by FLUX to generate one sample as the standard unit and scale the compute used by PixArt-ΣΣ\Sigmaroman_Σ accordingly. These total compute estimates are based on our best approximation and may not be entirely precise.
| Configs | Class-conditioned | Text-conditioned | |
|---|---|---|---|
| SiT-XL | FLUX.1-dev | PixArt- | |
| ODE solver | 2 order Heun | Euler | DDIM |
| NFEs/iter | |||
| final denoising steps | |||
| guidance scale | |||
| resolution | |||
🔼 This table lists the default settings used for generating class-conditioned and text-conditioned images using diffusion models. It specifies the ODE solver, number of function evaluations per iteration (NFEs/iter), the number of final denoising steps, the guidance scale, and the image resolution used for different models in the paper’s experiments. Note that some rows contain annotations indicating where in the paper variations of these settings are explored: the NFEs/iter value may differ in the experiments of Figure 10; and the guidance scale may be different in the experiments reported in Figure 4.
read the caption
Table 5: Default sampling settings for Class-conditioned and Text-conditioned generation. ††\dagger† In Figure 10 we report numbers with different NFEs/iter; ‡‡\ddagger‡ In Figure 4 we report results with different guidance scales.
| Hyperparameter | Description | |
|---|---|---|
| initial paths | The number of paths to start the search with. | |
| paths width | The number of noises to sample within each path. | |
| search start | The time to start search. | |
| backward stepsize | The length of time interval to run ODE solver. | |
| forward stepsize | The length of time interval to run noising process. | |
| paths length | The NFEs devoted in each backward step. | |
🔼 This table lists and describes the hyperparameters used in the ‘Search Over Paths’ algorithm, a method for optimizing the noise sampling process within diffusion models. The hyperparameters control aspects of the search, including the initial number of sampling paths explored, the width of each path (number of noise candidates), the starting point of the search in the noise schedule, and the step sizes for forward and backward passes within the sampling process, as well as the computation budget allocated to each backward step.
read the caption
Table 6: Hyperparameters for Search Over Paths.
| Model | Accuracy | Originality | Visual | Consistency | Emotional | Overall | |
|---|---|---|---|---|---|---|---|
| FLUX.1-dev | 89.35 | 67.58 | 93.00 | 97.04 | 73.99 | 84.29 | |
| + 4 search iters | 91.33 | 68.49 | 93.42 | 96.99 | 75.31 | 85.17 | |
| + 16 search iters | 91.95 | 71.52 | 93.76 | 97.24 | 76.30 | 86.42 | |
| + 64 search iters | 93.83 | 75.38 | 93.57 | 97.04 | 79.34 | 88.08 | |
| PixArt- | 84.60 | 73.29 | 91.91 | 95.80 | 76.34 | 84.67 | |
| + 4 search iters | 87.88 | 74.03 | 91.92 | 96.29 | 77.32 | 85.62 | |
| + 16 search iters | 88.15 | 75.39 | 91.72 | 96.04 | 79.17 | 86.27 | |
| + 64 search iters | 89.30 | 77.79 | 92.46 | 96.68 | 80.43 | 87.55 | |
🔼 This table presents a detailed breakdown of the scores assigned by a Large Language Model (LLM) evaluator to images generated by two different text-to-image models: FLUX-1-dev and PixArt-Σ. The LLM assessed each image based on five key aspects: Accuracy to Prompt, Creativity and Originality, Visual Quality and Realism, Consistency and Cohesion, and Emotional or Thematic Resonance. Each aspect received a score from 0 to 10, with higher scores representing better performance. The table shows the average scores for each aspect and an overall average score for images generated with different numbers of search iterations. The results were obtained using random search and a verifier ensemble.
read the caption
Table 7: Break-down scores of LLM Grader for FLUX.1-dev and PixArt-ΣΣ\Sigmaroman_Σ. The evaluation is done on DrawBench with random search and verifier ensemble.
| Verifiers | Aesthetic | CLIPScore | ImageReward |
|---|---|---|---|
| - | 5.79 | 0.71 | 0.97 |
| CLIP-SSL + 4 search iters | 5.76 | 0.71 | 0.99 |
| + 16 search iters | 5.72 | 0.71 | 1.04 |
| DINO-SSL + 4 search iters | 5.79 | 0.71 | 0.99 |
| + 16 search iters | 5.78 | 0.70 | 1.03 |
| SigLIP-SSL + 4 search iters | 5.79 | 0.70 | 1.02 |
| + 16 search iters | 5.75 | 0.70 | 1.02 |
🔼 This table presents the results of experiments evaluating the effectiveness of self-supervised verifiers (CLIP-SSL, DINO-SSL, SigLIP-SSL) in the context of inference-time scaling for diffusion models. The experiments used the FLUX.1-dev model and employed a random search strategy on the DrawBench dataset. The table compares the performance (aesthetic score, CLIP score, ImageReward) of the model when using these self-supervised verifiers with varying amounts of compute allocated to the search process (4 and 16 search iterations). The first row provides a baseline of the model’s performance without any search (i.e., only using the model’s inherent capabilities).
read the caption
Table 8: Performance of self-supervised verifiers on DrawBench. All numbers are from FLUX.1-dev with random search. The first row is the reference performance without search.
Full paper#