TL;DR#
Current methods for training robots using vision-language-action (VLA) models struggle with high-frequency actions due to poor action tokenization. These methods typically use simple binning, which fails to capture correlations between consecutive actions, resulting in models that copy previous actions instead of predicting future ones.
The paper introduces FAST, a new tokenization method employing discrete cosine transform to compress and reduce correlations in high-frequency robot actions. This innovative approach enables the training of autoregressive VLAs on high-frequency tasks where previous techniques failed. The authors also developed FAST+, a universal robot action tokenizer, trained on a vast dataset, and demonstrated that VLA models using FAST significantly improve performance and training efficiency compared to prior methods, even achieving similar results to more computationally expensive diffusion-based approaches.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in robotics and AI due to its significant advancements in robot action tokenization. FAST tokenization, introduced here, dramatically improves the training efficiency and performance of autoregressive vision-language-action (VLA) models. This opens up new avenues for scaling VLA models to more complex and higher-frequency tasks, a major limitation in current research. The release of FAST+, a universal tokenizer, further enhances the accessibility and applicability of this work across various robotic platforms and control schemes.
Visual Insights#

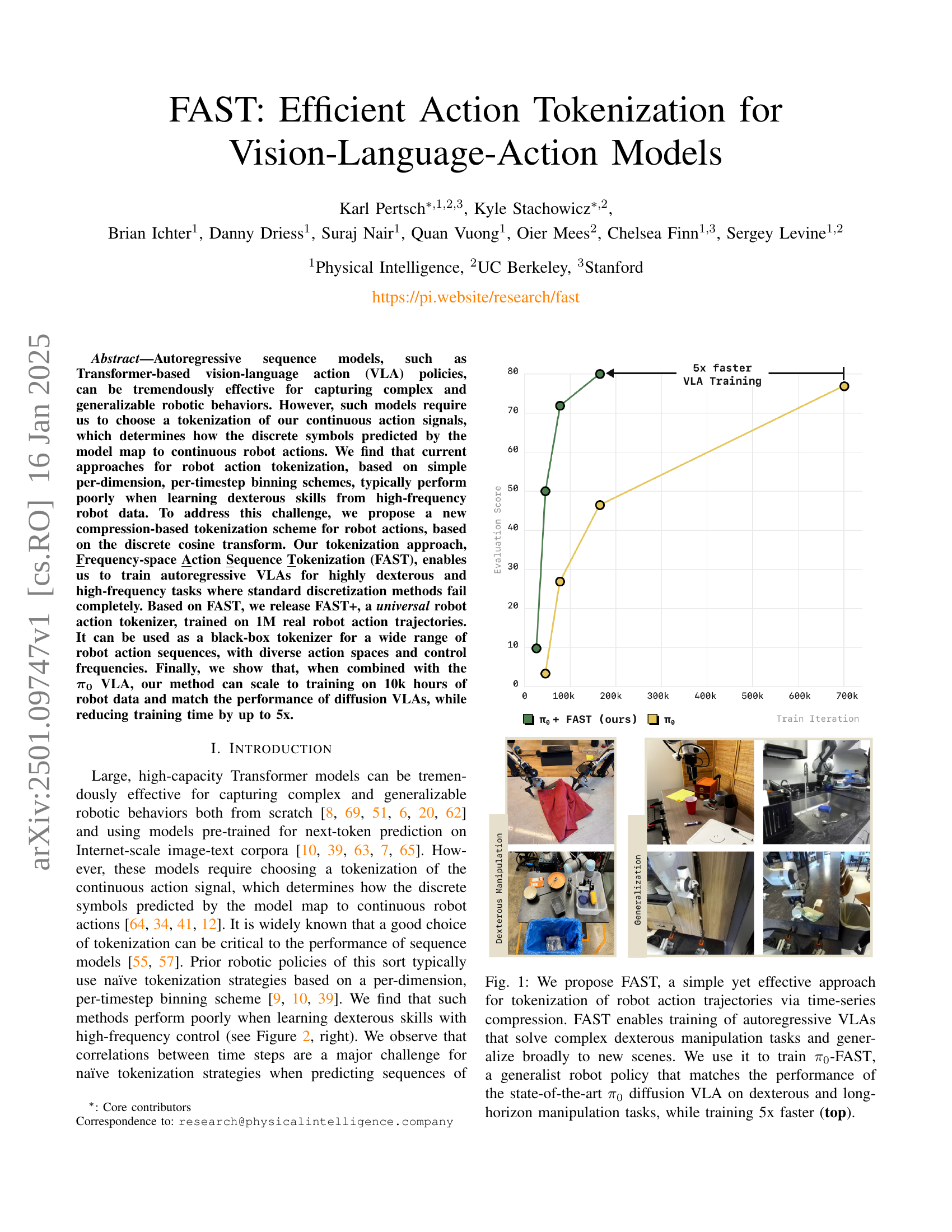
🔼 This figure showcases the effectiveness of FAST, a novel action tokenization method, in training vision-language-action (VLA) models. The top graph compares the training performance of a VLA model using FAST (π₀-FAST) against a state-of-the-art diffusion-based VLA (π₀). The results demonstrate that π₀-FAST achieves comparable performance while training five times faster. The bottom part of the figure presents a series of images illustrating the diverse dexterous manipulation tasks the π₀-FAST model successfully performs.
read the caption
Figure 1: We propose FAST, a simple yet effective approach for tokenization of robot action trajectories via time-series compression. FAST enables training of autoregressive VLAs that solve complex dexterous manipulation tasks and generalize broadly to new scenes. We use it to train π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT-FAST, a generalist robot policy that matches the performance of the state-of-the-art π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT diffusion VLA on dexterous and long-horizon manipulation tasks, while training 5x faster (top).
| Dataset | Action Dimension | Control Frequency | Avg. Token | Compression | |
| Naive | FAST | ||||
| BridgeV2 | 7 | 5 Hz | 35 | 20 | 1.75 |
| DROID | 7 | 15 Hz | 105 | 29 | 3.6 |
| Bussing | 7 | 20 Hz | 140 | 28 | 5.0 |
| Shirt Fold | 14 | 50 Hz | 700 | 53 | 13.2 |
🔼 This table compares the average number of tokens generated per 1-second chunk of robot actions using two different tokenization methods: a naive method and the proposed FAST method. The naive method involves simple per-dimension, per-timestep binning, while FAST uses a discrete cosine transform for compression. The results show that FAST significantly reduces the number of tokens, especially for high-frequency tasks (such as folding a t-shirt), demonstrating its effectiveness in removing redundancy from robot action data.
read the caption
TABLE I: Comparison of the average token count per action chunk for naïve tokenization and FAST. We use 1-second chunks in all datasets. With our method, each chunk requires many fewer tokens, particularly for high-frequency domains such as the T-shirt folding task, indicating that it is more effective at removing redundancy.
In-depth insights#
FAST Tokenization#
The proposed FAST tokenization method offers a significant advancement in handling high-frequency robot action data for vision-language-action (VLA) models. Instead of traditional per-dimension binning, FAST leverages the Discrete Cosine Transform (DCT) for compression. This approach effectively reduces correlations between consecutive tokens, a major issue in prior methods that hindered the learning of dexterous skills. The incorporation of Byte Pair Encoding (BPE) further enhances the compression, leading to a smaller number of high-information tokens. The results demonstrate the effectiveness of FAST, significantly improving the performance and training efficiency of autoregressive VLAs on tasks involving high-frequency control, even outperforming diffusion models in several scenarios. The development of FAST+, a universal tokenizer trained on a vast dataset of robot actions, makes this technique readily applicable and broadly useful. This innovation addresses a crucial limitation in existing VLA frameworks, paving the way for training more effective and generalizable robotic policies.
VLA Training Speedup#
The research demonstrates a significant speedup in Vision-Language-Action (VLA) model training through a novel action tokenization method called FAST. By compressing continuous robot action signals into a smaller number of informative tokens using the Discrete Cosine Transform (DCT) and Byte Pair Encoding (BPE), FAST addresses the limitations of traditional binning methods, which struggle with high-frequency data. This results in faster convergence during training, especially notable for complex, dexterous tasks. The universal tokenizer, FAST+, further enhances efficiency by generalizing across diverse robot types and datasets. The speed improvement is empirically validated by showing that FAST-based models match state-of-the-art diffusion models, while reducing training time by up to 5x. This efficiency gain is crucial for scaling VLA training to large datasets, making it more practical to develop complex and robust robot policies.
High-Freq. Robot Data#
The concept of ‘High-Freq. Robot Data’ in robotics research is crucial because it directly impacts the complexity and fidelity of learned robotic skills. High-frequency data captures the nuances of dexterous manipulation far better than low-frequency data, allowing for a more accurate representation of complex movements. This improved fidelity, however, presents significant challenges. Training models on high-frequency data demands substantially more computational resources and raises concerns about the trade-off between data richness and model training efficiency. Effective action tokenization becomes critical in this context to reduce the dimensionality of the data without sacrificing essential information. The paper suggests that compression-based methods, like the discrete cosine transform, are far superior to naive discretization schemes in managing high-frequency data. They improve training stability, achieve better performance, and allow for scaling to significantly larger datasets than was previously feasible. Furthermore, the ability to process high-frequency data opens avenues for learning more complex, versatile, and truly dexterous skills that were previously intractable with existing methodologies.
Universal Tokenizer#
The concept of a ‘Universal Tokenizer’ in the context of robotic action tokenization is a significant advancement. The goal is to create a single tokenizer capable of handling diverse robot morphologies, control schemes, and action spaces. This addresses a major limitation of previous methods which required task-specific tokenizers, reducing development time and improving generalizability. The paper’s approach uses a Discrete Cosine Transform (DCT) and Byte Pair Encoding (BPE) to achieve efficient compression and effective tokenization for high-frequency data. The resulting tokenizer, FAST+, is trained on a large dataset of 1M real robot trajectories, demonstrating its ability to handle various complexities. Its successful application to diverse robotic scenarios, without dataset-specific adjustments, highlights its true universality and potential to accelerate future advancements in vision-language-action (VLA) model development. The success of FAST+ underscores the power of leveraging general-purpose compression techniques for improved performance and scalability in robotic tasks, making it a significant contribution towards more efficient and robust VLA model training.
Future of VLAs#
The future of Vision-Language-Action (VLA) models is bright, with potential advancements across several key areas. Improved tokenization techniques are crucial; moving beyond simple binning methods to more sophisticated approaches like the proposed FAST, or even learned compression schemes, will unlock the potential of high-frequency data, enabling more complex and dexterous robotic tasks. Enhanced scalability is another critical aspect; the ability to train VLAs on massive datasets of diverse robot experiences is key to generalizability and robustness. Integration with more advanced architectures is vital; combining the strengths of autoregressive and diffusion-based models, alongside exploration of other novel architectures, will lead to policies that are both computationally efficient and demonstrate superior task performance. Finally, addressing the inference speed bottleneck is essential for deploying VLAs in real-world settings; exploring techniques like speculative decoding, quantization and specialized hardware could significantly accelerate the decision-making process. The combination of these advancements would enable truly general-purpose robotic agents capable of efficiently learning and executing complex, nuanced tasks directly from natural language instructions.
More visual insights#
More on figures

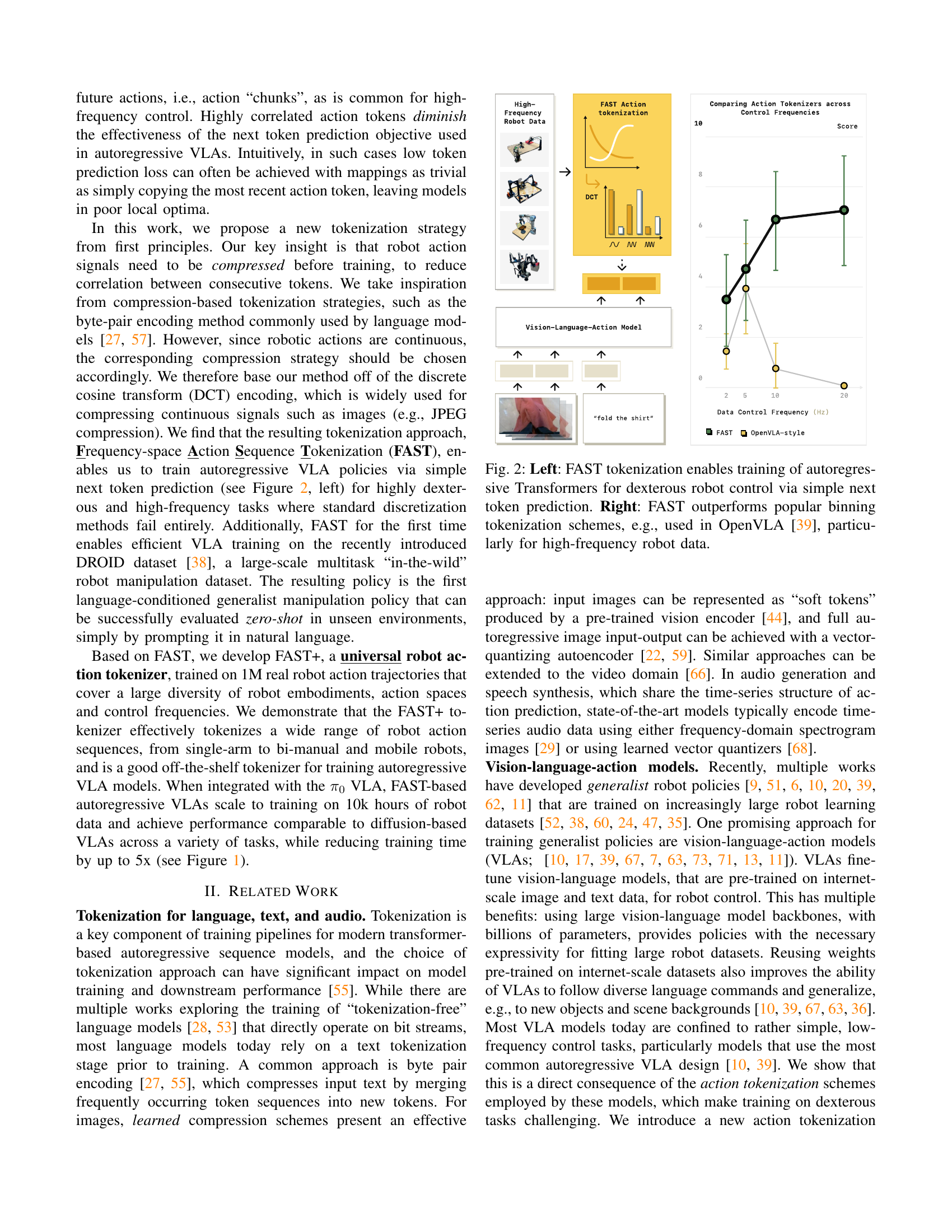
🔼 Figure 2 demonstrates the effectiveness of FAST tokenization in training autoregressive transformer models for robot control. The left panel illustrates how FAST simplifies the training process by compressing robot action sequences into more manageable tokens, allowing the model to predict the next token in the sequence efficiently, even for complex dexterous tasks. The right panel compares FAST’s performance against traditional binning methods commonly used in vision-language-action models like OpenVLA. It shows that FAST significantly outperforms binning, especially when dealing with high-frequency robot data, highlighting its ability to handle the challenges of highly correlated actions and achieving better accuracy in next-token prediction.
read the caption
Figure 2: Left: FAST tokenization enables training of autoregressive Transformers for dexterous robot control via simple next token prediction. Right: FAST outperforms popular binning tokenization schemes, e.g., used in OpenVLA [39], particularly for high-frequency robot data.

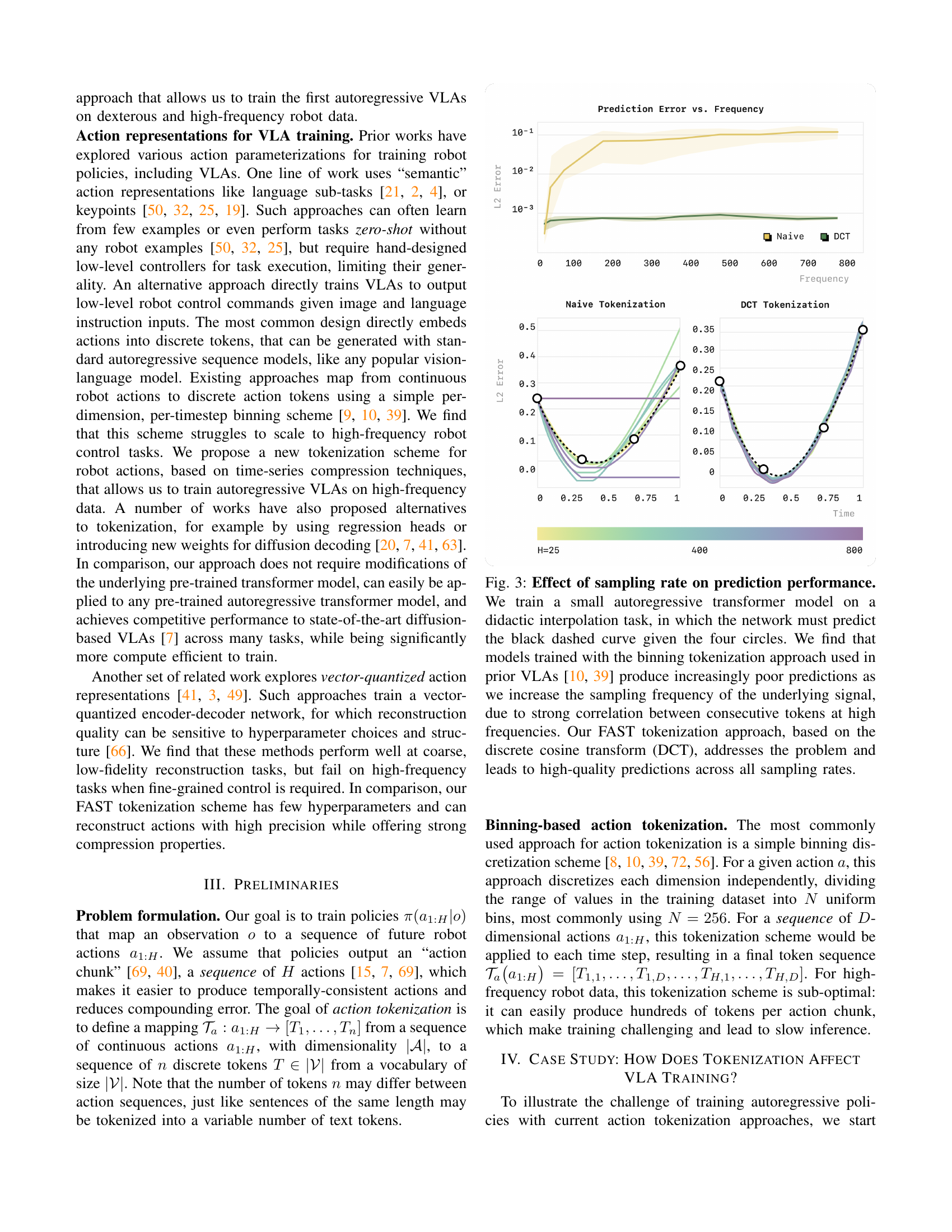
🔼 This figure demonstrates the impact of different action tokenization methods on the performance of autoregressive models for predicting continuous actions from high-frequency data. A simple interpolation task is used, where the model must predict a curve given four data points. Using a standard binning tokenization (as used in previous Vision-Language-Action models), prediction accuracy drastically decreases as the sampling rate (frequency) of the data increases. This is because consecutive tokens become highly correlated at high frequencies, hindering the model’s ability to learn meaningful patterns. In contrast, the proposed FAST tokenization method, based on the Discrete Cosine Transform (DCT), maintains high prediction accuracy across all sampling rates, demonstrating its effectiveness in handling highly correlated action data.
read the caption
Figure 3: Effect of sampling rate on prediction performance. We train a small autoregressive transformer model on a didactic interpolation task, in which the network must predict the black dashed curve given the four circles. We find that models trained with the binning tokenization approach used in prior VLAs [10, 39] produce increasingly poor predictions as we increase the sampling frequency of the underlying signal, due to strong correlation between consecutive tokens at high frequencies. Our FAST tokenization approach, based on the discrete cosine transform (DCT), addresses the problem and leads to high-quality predictions across all sampling rates.

🔼 This figure details the FAST action tokenization pipeline, which efficiently converts continuous robot actions into a compressed sequence of discrete tokens. The process begins with a normalized chunk of robot actions. A Discrete Cosine Transform (DCT) converts these actions into the frequency domain, highlighting the most significant frequency components which represent the important aspects of the actions. These DCT coefficients are then quantized, reducing their precision while preserving crucial information. Finally, Byte-Pair Encoding (BPE) compresses the flattened sequence of quantized coefficients, generating the final, compressed action token sequence. This compressed representation allows for more efficient training of vision-language-action models.
read the caption
Figure 4: Overview of the FAST action tokenization pipeline. Given a normalized chunk of actions, we apply discrete cosine transform (DCT) to convert the signal to the frequency domain. We then quantize the DCT coefficients and use byte-pair encoding (BPE) to compress the flattened sequence of per-dimension DCT coefficients into the final action token sequence. See Section V-B for a detailed description.

🔼 Figure 5 showcases the diverse set of seven environments used to evaluate the performance of the FAST action tokenization method. These environments include six real-world robotic manipulation tasks and one simulated task. The real-world tasks represent a variety of manipulation challenges, ranging from highly dexterous fine motor skills (like folding a t-shirt or arranging groceries) to more complex tasks requiring precise object placement. The inclusion of a simulated task allows for testing generalization capabilities. The ‘DROID’ task is especially notable as it evaluates the ability of the model to perform zero-shot table-top manipulations in entirely unseen environments, demonstrating the robustness and generalizability of the method.
read the caption
Figure 5: Evaluation environments. We test FAST across 7 evaluation environments: 6 real-robot tasks and 1 simulation environment. The tasks are designed to test VLA performance on highly dexterous tasks, like folding cloths from a laundry basket (“Laundry Folding”), and generalization, e.g., zero-shot table-top manipulation in unseen environments (“DROID”).

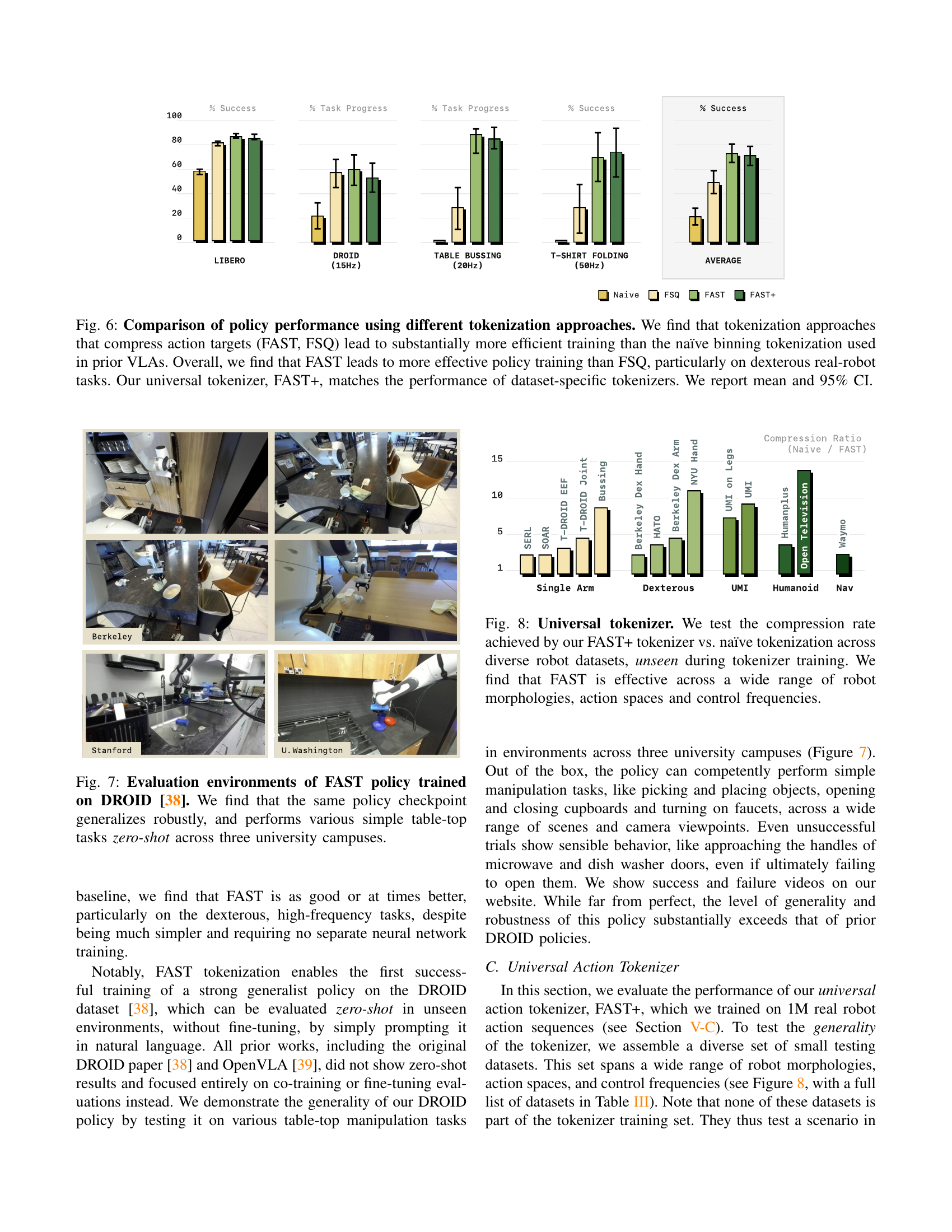
🔼 Figure 6 presents a comparison of the training efficiency and resulting policy performance achieved using different action tokenization methods for vision-language-action (VLA) models. The study compares three approaches: naive binning (a common technique in prior VLA works), frequency-space action sequence tokenization (FAST), and frequency-space quantized (FSQ). The results demonstrate that methods compressing action targets, namely FAST and FSQ, significantly enhance training efficiency compared to the naive binning approach. Further analysis shows that FAST consistently outperforms FSQ, especially in complex, dexterous real-world robotic tasks. The figure also validates the effectiveness of FAST+, a universal tokenizer trained on a large dataset of varied robotic actions, which exhibits performance comparable to tokenizers trained on specific datasets. Mean success rates and 95% confidence intervals are shown for each method and task.
read the caption
Figure 6: Comparison of policy performance using different tokenization approaches. We find that tokenization approaches that compress action targets (FAST, FSQ) lead to substantially more efficient training than the naïve binning tokenization used in prior VLAs. Overall, we find that FAST leads to more effective policy training than FSQ, particularly on dexterous real-robot tasks. Our universal tokenizer, FAST+, matches the performance of dataset-specific tokenizers. We report mean and 95% CI.

🔼 This figure showcases the zero-shot generalization capabilities of a robot policy trained using the FAST action tokenization method on the DROID dataset. The same policy checkpoint, without any further fine-tuning or adaptation, successfully performs various simple tabletop manipulation tasks across three different university campuses. This demonstrates the robustness and generalizability of the FAST-trained policy, highlighting its ability to adapt to new environments and variations in object placement, lighting, and background without retraining.
read the caption
Figure 7: Evaluation environments of FAST policy trained on DROID [38]. We find that the same policy checkpoint generalizes robustly, and performs various simple table-top tasks zero-shot across three university campuses.

🔼 Figure 8 presents a comparison of compression ratios between FAST+, the universal robot action tokenizer, and naive tokenization methods. The comparison is made across multiple robot datasets that were not used during the training of FAST+. This demonstrates the effectiveness and generalizability of FAST+ across diverse robotic setups. The results show that FAST+ consistently achieves significant compression across a wide range of robot morphologies, action spaces, and control frequencies, indicating its robustness and potential for broad applicability in various robotic tasks.
read the caption
Figure 8: Universal tokenizer. We test the compression rate achieved by our FAST+ tokenizer vs. naïve tokenization across diverse robot datasets, unseen during tokenizer training. We find that FAST is effective across a wide range of robot morphologies, action spaces and control frequencies.

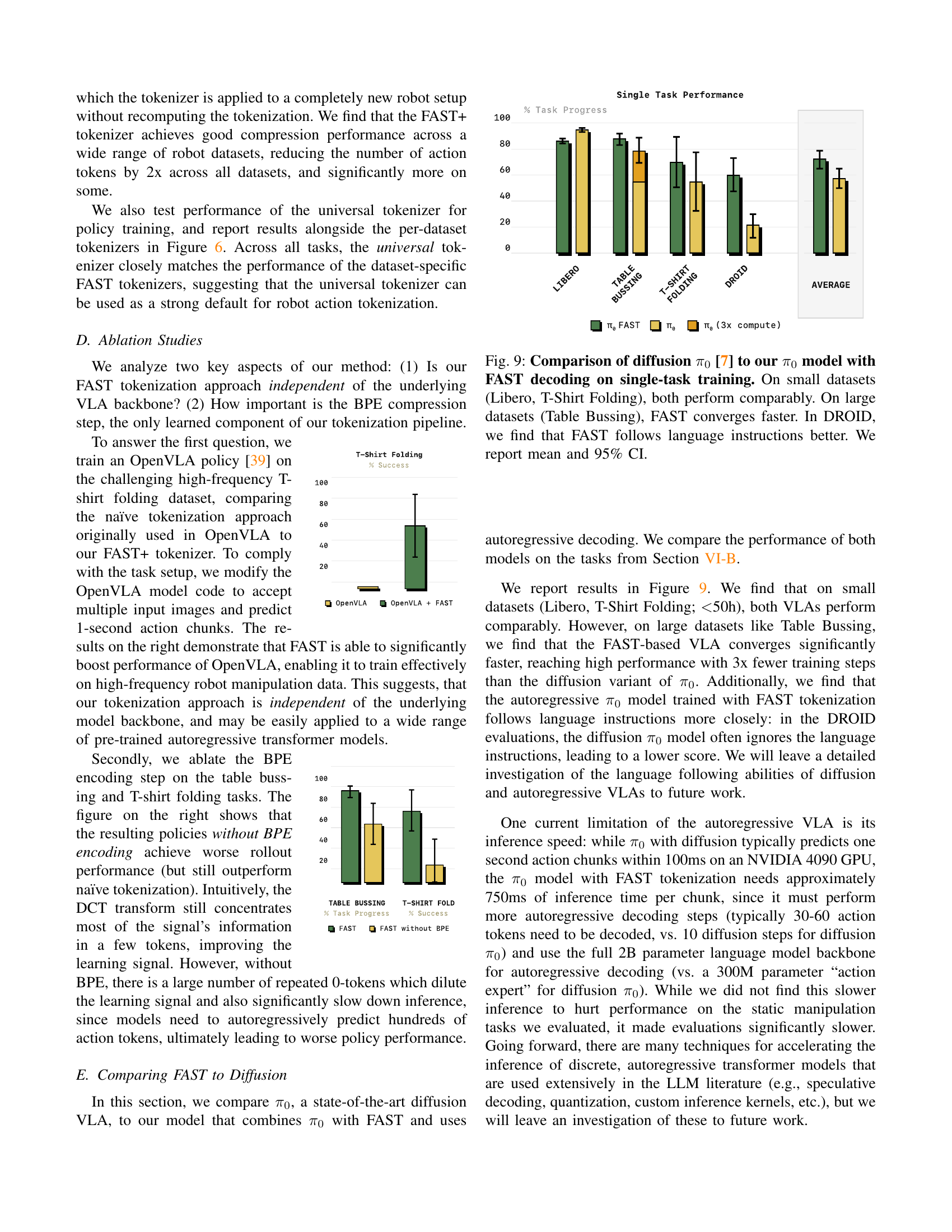
🔼 This figure compares the performance of a state-of-the-art diffusion-based vision-language-action (VLA) model, π0, with a new autoregressive VLA model using FAST action tokenization. The comparison is made across various tasks with different dataset sizes. The results show that on smaller datasets (Libero and T-Shirt Folding), both models perform similarly. However, on larger datasets (Table Bussing), the model with FAST tokenization converges to a solution much faster than the diffusion-based π0 model. Furthermore, when evaluated on the DROID dataset, the FAST model demonstrates superior ability to follow language instructions compared to the diffusion model. The mean and 95% confidence intervals are provided for all results.
read the caption
Figure 9: Comparison of diffusion π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT [7] to our π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT model with FAST decoding on single-task training. On small datasets (Libero, T-Shirt Folding), both perform comparably. On large datasets (Table Bussing), FAST converges faster. In DROID, we find that FAST follows language instructions better. We report mean and 95% CI.

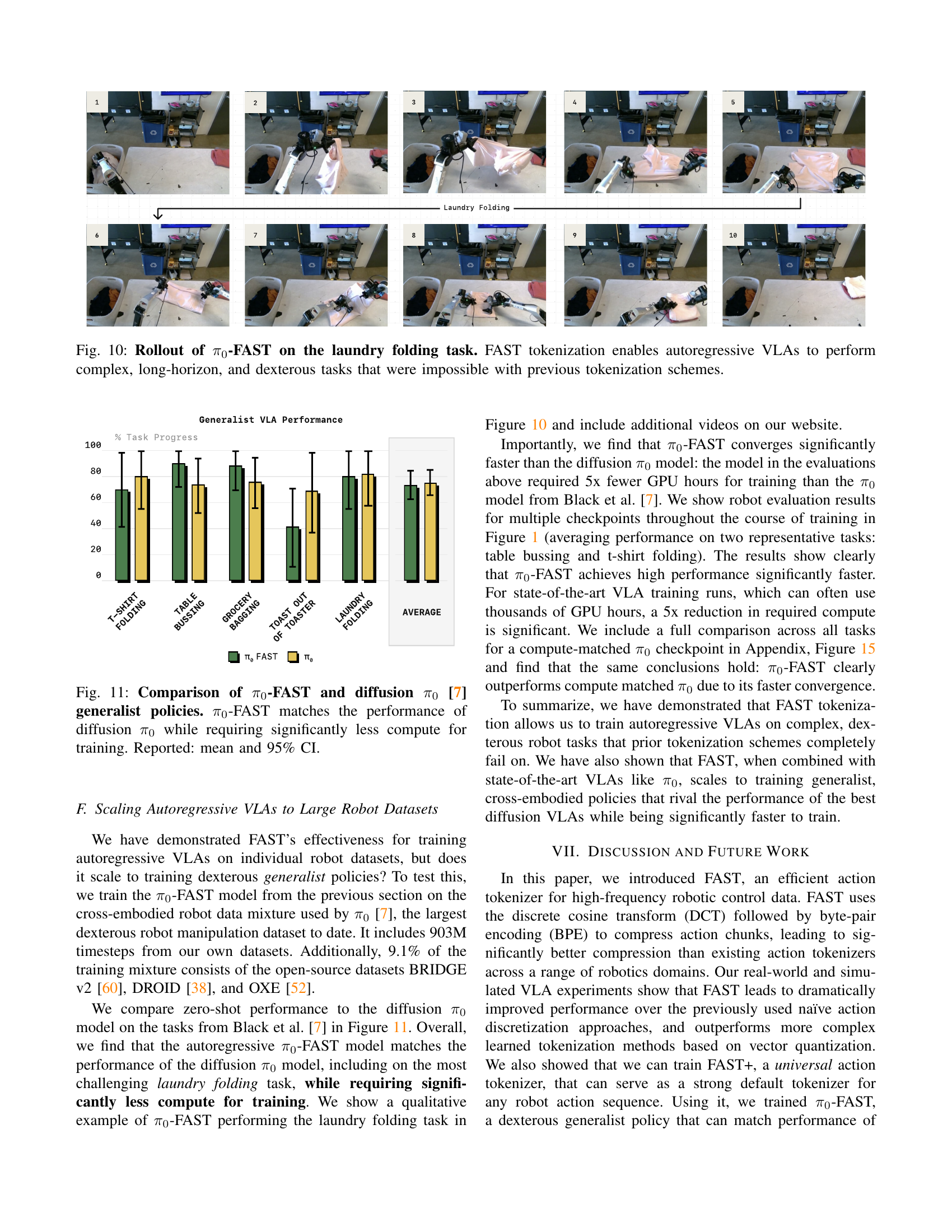
🔼 The figure displays a sequence of images showing the steps involved in a laundry folding task performed by a robot using the π0-FAST (pi-zero-FAST) model. The robot successfully manipulates a shirt, demonstrating complex actions like grasping, unfolding, and folding. This success highlights the effectiveness of the FAST tokenization method in enabling autoregressive Vision-Language-Action (VLA) models to handle intricate, long-duration tasks that previous methods failed to solve. The sequence shows the robot’s progress, emphasizing the dexterity and planning capabilities facilitated by the improved tokenization scheme.
read the caption
Figure 10: Rollout of π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT-FAST on the laundry folding task. FAST tokenization enables autoregressive VLAs to perform complex, long-horizon, and dexterous tasks that were impossible with previous tokenization schemes.

🔼 Figure 11 compares the performance of two generalist robotic policies: π0-FAST (an autoregressive model using the FAST tokenization method) and a diffusion-based π0 model. The results show that π0-FAST achieves comparable performance to the diffusion π0, but with significantly less computational cost during training. The chart displays the success rates and task progress across several complex manipulation tasks, illustrating the efficiency of the π0-FAST approach. Error bars representing the 95% confidence intervals are also included.
read the caption
Figure 11: Comparison of π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT-FAST and diffusion π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT [7] generalist policies. π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT-FAST matches the performance of diffusion π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT while requiring significantly less compute for training. Reported: mean and 95% CI.

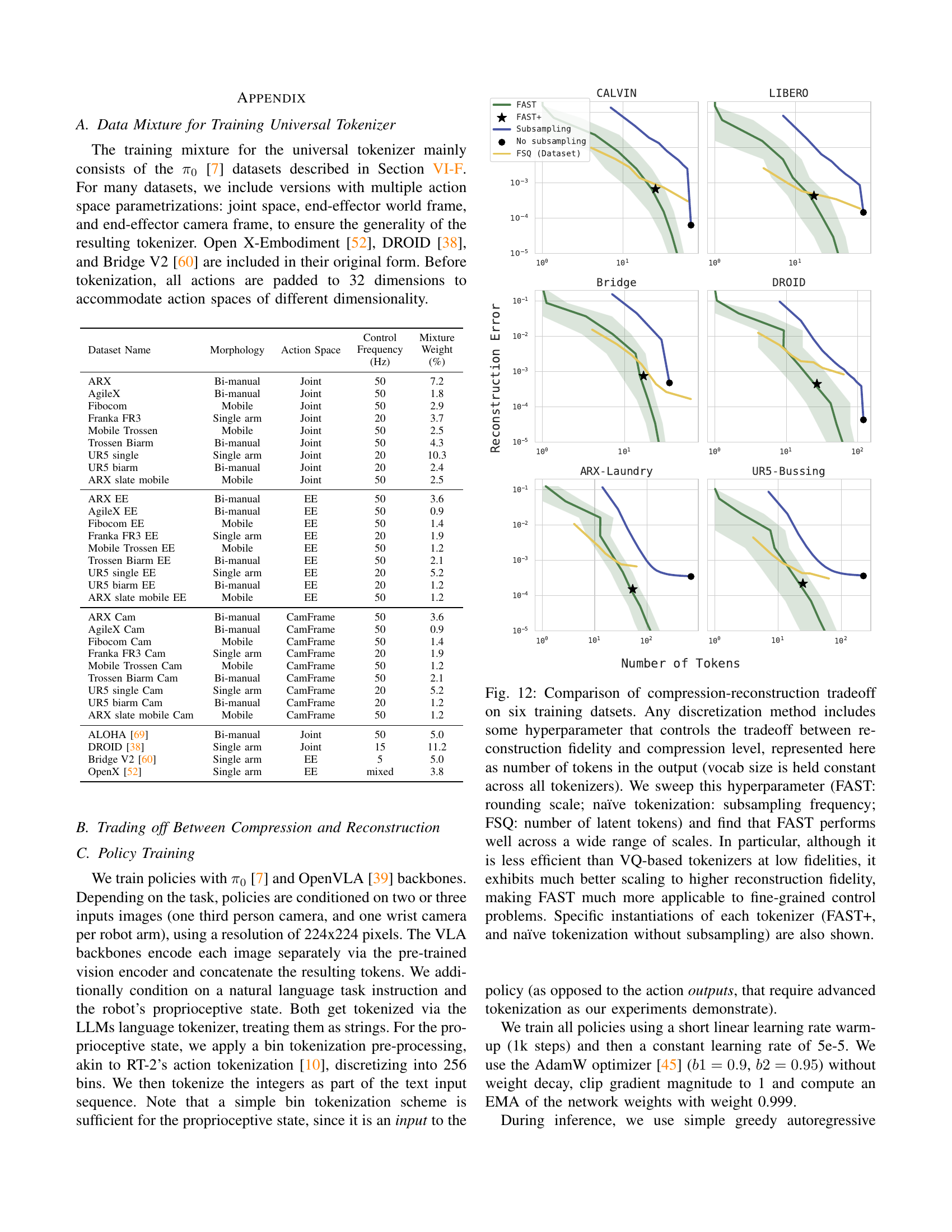
🔼 Figure 12 illustrates the trade-off between compression and reconstruction fidelity for six different robot action tokenization methods. The x-axis represents the number of tokens used (a measure of compression), while the y-axis shows the reconstruction error (a measure of fidelity). Each method has a hyperparameter controlling this trade-off; for FAST, it’s the rounding scale; for naïve tokenization, it’s the subsampling frequency; and for FSQ (Frequency-Space Quantization), it’s the number of latent tokens. The figure demonstrates that FAST achieves good performance across a wide range of compression levels, significantly outperforming VQ-based methods (like FSQ) at higher fidelity levels. This makes FAST particularly suitable for fine-grained control tasks requiring high fidelity reconstruction.
read the caption
Figure 12: Comparison of compression-reconstruction tradeoff on six training datsets. Any discretization method includes some hyperparameter that controls the tradeoff between reconstruction fidelity and compression level, represented here as number of tokens in the output (vocab size is held constant across all tokenizers). We sweep this hyperparameter (FAST: rounding scale; naïve tokenization: subsampling frequency; FSQ: number of latent tokens) and find that FAST performs well across a wide range of scales. In particular, although it is less efficient than VQ-based tokenizers at low fidelities, it exhibits much better scaling to higher reconstruction fidelity, making FAST much more applicable to fine-grained control problems. Specific instantiations of each tokenizer (FAST+, and naïve tokenization without subsampling) are also shown.

🔼 This image shows a single-arm UR5e robot performing the Table Bussing task. The goal is to clear a table by picking up various objects (cups, plates, bowls, cutlery, etc.) and placing them in a trash bin or a plastic container. The task requires precise grasping and manipulation of diverse objects. The scene is designed to be challenging, with utensils intentionally placed on top of trash and objects obstructing each other.
read the caption
(a) Table Bussing

🔼 This image shows the setup for the T-Shirt Folding task. A bimanual ARX robot is used to fold shirts. The training dataset includes approximately 150 shirts of varying sizes, colors, and styles. The evaluation scene shows five shirts in various initial configurations, which are presented one at a time. The success metric is the percentage of successfully folded shirts, as judged by a human evaluator.
read the caption
(b) T-Shirt Folding

🔼 A UR5 single-arm robot needs to pack seven objects from a table into a grocery bag, taking care not to topple or rip the bag in the process. This task requires picking a diverse set of objects and carefully inserting them into the bag.
read the caption
(c) Grocery Bagging

🔼 This task requires a bi-manual Trossen ViperX robot to remove two slices of bread from a toaster and place them onto a plate. The evaluation involves assessing the robot’s ability to successfully grasp and move both slices of bread from the toaster to a plate.
read the caption
(d) Toast out of Toaster

🔼 This image shows the Laundry Folding task, one of the seven tasks used to evaluate the performance of different vision-language-action (VLA) models. The task involves a dual-arm robot that needs to take shirts and shorts from a basket, flatten them on a table, fold them, and stack the folded clothes. This task is particularly challenging because it requires precise grasping, dynamic motions to flatten the clothes, and precise placement of the folded clothes on the existing stack. Success is determined by a human evaluator based on the percentage of clothing items successfully folded and stacked.
read the caption
(e) Laundry Folding

🔼 This figure shows example starting states for several robotic manipulation tasks used to evaluate the performance of different robotic policies. Each subfigure displays a distinct task setup, showcasing the variety of object arrangements and robot configurations used in the experiments. These images help illustrate the complexity of the tasks and the diversity of scenarios considered in assessing the robustness and generalizability of the various robot control methods.
read the caption
Figure 13: Sampled initial configurations of evaluation tasks.

🔼 This figure displays example setups from the quantitative evaluation of the DROID dataset. The DROID dataset is a large-scale, in-the-wild dataset for robot manipulation. The quantitative evaluation tests the robot’s ability to perform various tasks, like putting objects in specific containers, cleaning a table, and interacting with drawers. Each image showcases a different setup, representing the diverse scenarios and objects used to assess the generalizability of the policies. The caption in the paper is short, so this provides more context for the reader.
read the caption
Figure 14: Setups used for quantitative DROID evaluation.

🔼 Figure 15 shows a comparison of the performance of two generalist robot control policies: one is the π0-FAST model (an autoregressive model using the FAST action tokenization method), and the other is a diffusion-based π0 model from a prior work. Both models were trained using the same computational resources. The results demonstrate that π0-FAST significantly outperforms the diffusion π0 model, achieving better task success rates across various tasks. This superior performance is attributed to π0-FAST’s faster convergence during training, a key benefit enabled by the efficient FAST tokenization method. The figure displays the mean task success rates and 95% confidence intervals for each model across several tasks.
read the caption
Figure 15: Comparison of π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT-FAST and compute-matched diffusion π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT [7] generalist policies. π0subscript𝜋0\pi_{0}italic_π start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT-FAST clearly outperforms the diffusion VLA when trained with the same amount of training compute, due to its faster convergence. Reported: mean and 95% CI.
More on tables
| Dataset Name | Morphology | Action Space | Control Frequency (Hz) | Mixture Weight (%) |
| ARX | Bi-manual | Joint | 50 | 7.2 |
| AgileX | Bi-manual | Joint | 50 | 1.8 |
| Fibocom | Mobile | Joint | 50 | 2.9 |
| Franka FR3 | Single arm | Joint | 20 | 3.7 |
| Mobile Trossen | Mobile | Joint | 50 | 2.5 |
| Trossen Biarm | Bi-manual | Joint | 50 | 4.3 |
| UR5 single | Single arm | Joint | 20 | 10.3 |
| UR5 biarm | Bi-manual | Joint | 20 | 2.4 |
| ARX slate mobile | Mobile | Joint | 50 | 2.5 |
| ARX EE | Bi-manual | EE | 50 | 3.6 |
| AgileX EE | Bi-manual | EE | 50 | 0.9 |
| Fibocom EE | Mobile | EE | 50 | 1.4 |
| Franka FR3 EE | Single arm | EE | 20 | 1.9 |
| Mobile Trossen EE | Mobile | EE | 50 | 1.2 |
| Trossen Biarm EE | Bi-manual | EE | 50 | 2.1 |
| UR5 single EE | Single arm | EE | 20 | 5.2 |
| UR5 biarm EE | Bi-manual | EE | 20 | 1.2 |
| ARX slate mobile EE | Mobile | EE | 50 | 1.2 |
| ARX Cam | Bi-manual | CamFrame | 50 | 3.6 |
| AgileX Cam | Bi-manual | CamFrame | 50 | 0.9 |
| Fibocom Cam | Mobile | CamFrame | 50 | 1.4 |
| Franka FR3 Cam | Single arm | CamFrame | 20 | 1.9 |
| Mobile Trossen Cam | Mobile | CamFrame | 50 | 1.2 |
| Trossen Biarm Cam | Bi-manual | CamFrame | 50 | 2.1 |
| UR5 single Cam | Single arm | CamFrame | 20 | 5.2 |
| UR5 biarm Cam | Bi-manual | CamFrame | 20 | 1.2 |
| ARX slate mobile Cam | Mobile | CamFrame | 50 | 1.2 |
| ALOHA [69] | Bi-manual | Joint | 50 | 5.0 |
| DROID [38] | Single arm | Joint | 15 | 11.2 |
| Bridge V2 [60] | Single arm | EE | 5 | 5.0 |
| OpenX [52] | Single arm | EE | mixed | 3.8 |
🔼 This table details the 16 specific tasks used to quantitatively evaluate the performance of robot policies on the DROID dataset. Each task involves a manipulation objective, such as placing an object in a specific location or performing a cleaning action. The number of trials conducted for each task is also listed.
read the caption
TABLE II: DROID evaluation tasks.
| Task | Trials |
| Put the spoon in the dish rack | 4 |
| Put carrot in bowl | 4 |
| Put plate in dish rack | 2 |
| Wipe the table | 2 |
| Put the plate on the table | 2 |
| Clean up the table | 2 |
| Close the drawer | 4 |
| Put the stapler on the notebook | 2 |
| Put stapler in the drawer | 4 |
| Clean the whiteboard | 2 |
| Put the marker in the cup | 4 |
| Put the black sponge in the blue bowl | 2 |
| Put the red bottle in the black bowl | 2 |
| Put the watermelon in the purple bowl | 2 |
| Move the watermelon from the purple bowl to the blue bowl | 2 |
| Put the tape in the purple bowl | 2 |
| Put the water bottle on the left side of the table | 2 |
| Total | 44 |
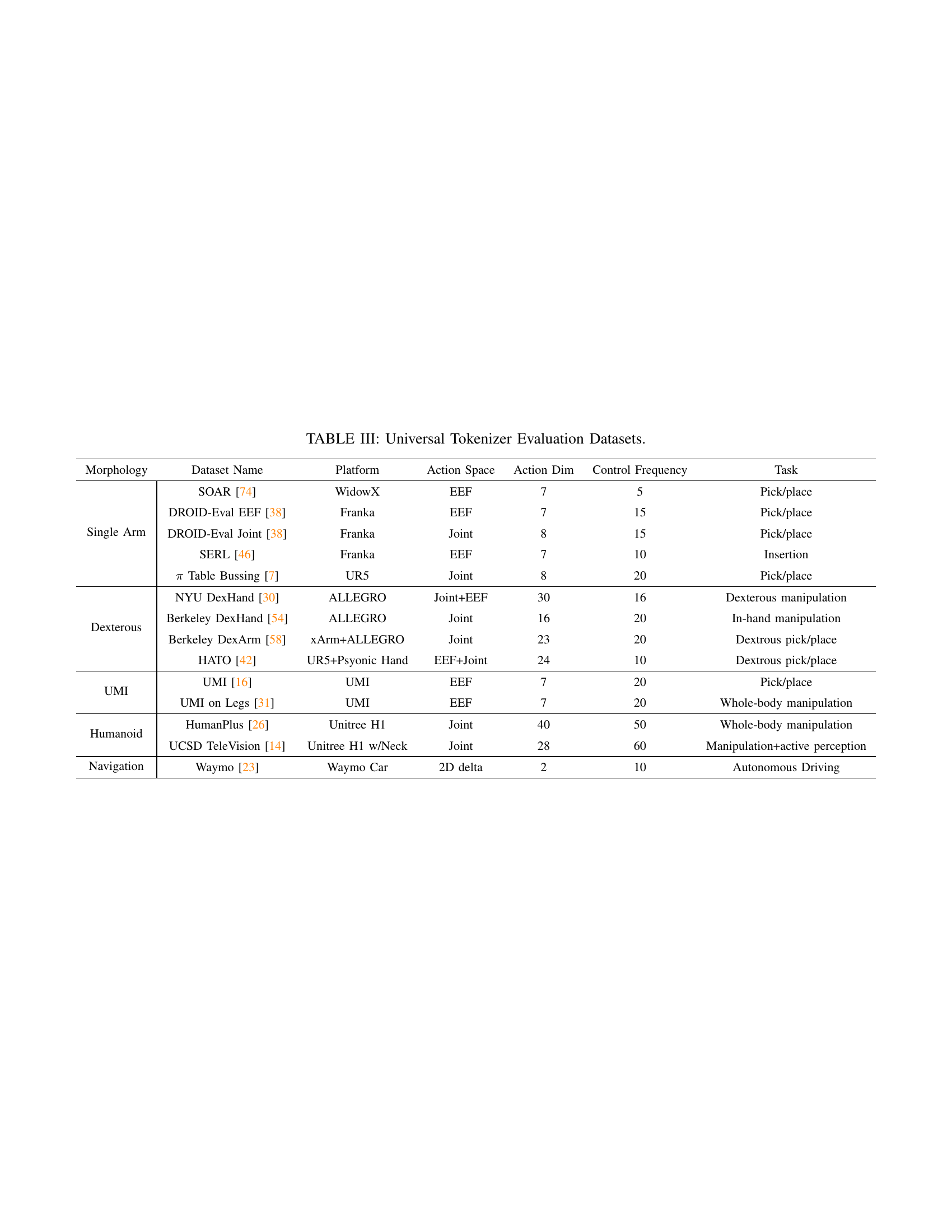
🔼 This table presents a comprehensive list of diverse datasets used to evaluate the performance of the universal robot action tokenizer (FAST+). Each dataset represents a unique robot morphology (single-arm, dual-arm, humanoid, mobile), platform (physical robot, simulator), action space (joint positions, end-effector pose), number of action dimensions, control frequency, and the type of task involved. This variety ensures a robust test of the tokenizer’s ability to generalize across a wide range of robotics scenarios and control schemes.
read the caption
TABLE III: Universal Tokenizer Evaluation Datasets.
Full paper#