TL;DR#
Current video inpainting methods struggle with large masked regions, often resulting in blurry textures and temporal inconsistencies. These methods typically combine flow-based pixel propagation with transformer-based generation, but struggle to generate detailed and temporally consistent results when dealing with large areas of missing data.
DiffuEraser tackles these challenges using a stable diffusion model. By incorporating prior information to help guide the generation process (injected priors) and enhancing temporal consistency through improved temporal receptive fields and leveraging the temporal smoothing property of video diffusion models, DiffuEraser produces significantly better results in both texture detail and temporal coherence. Experimental results show that it outperforms state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DiffuEraser, a novel video inpainting model that significantly outperforms existing methods. Its use of stable diffusion and injected priors addresses limitations in current techniques, achieving superior results in both texture quality and temporal consistency. This work opens new avenues for research in video editing and generation, particularly for long sequences.
Visual Insights#

🔼 DiffuEraser, a video inpainting model, uses a stable diffusion architecture. The core is a denoising U-Net that processes noisy latent representations to generate the final inpainted video frames. A secondary branch, BrushNet, processes masked image regions, extracting features that are integrated into the U-Net via zero-convolution blocks, improving the model’s understanding of the masked areas. To maintain temporal coherence across frames, the architecture incorporates a temporal attention mechanism following the self- and cross-attention layers.
read the caption
Figure 1: Overview of the proposed video inpainting model DiffuEraser, based on stable diffusion. The main denoising UNet performs the denoising process to generate the final output. The BrushNet branch extracts features from masked images, which are added to the main denoising UNet layer by layer after a zero convolution block. Temporal attention is incorporated after self-attention and cross-attention to improve temporal consistency.
In-depth insights#
Diffusion Video Inpaint#
Diffusion models have shown remarkable success in image generation and inpainting tasks. Extending these capabilities to video presents unique challenges, primarily in maintaining temporal consistency across frames. A hypothetical ‘Diffusion Video Inpaint’ system would leverage the strengths of diffusion models – powerful generative abilities and handling of complex details – while addressing the temporal coherence issue. This likely involves incorporating temporal information, such as optical flow or frame-to-frame motion vectors, directly into the diffusion process. This could be achieved through conditioning the diffusion model on both the current frame’s masked regions and the predicted motion from preceding and subsequent frames. A key challenge is balancing the model’s generative capacity with its ability to adhere to the temporal constraints and prevent blurry, inconsistent results, especially with larger masks and long-sequence videos. Another crucial aspect would be the choice of prior information. Incorporating a pre-trained model for initial pixel propagation or using predicted frames could significantly help guide the diffusion process, reducing noise and hallucinations while improving efficiency. Careful consideration of the model architecture is essential, potentially requiring modifications to standard diffusion architectures to effectively handle the spatio-temporal nature of the video data. Ultimately, a successful Diffusion Video Inpaint method would achieve high-fidelity video inpainting results while maintaining seamless temporal consistency, even in challenging scenarios.
Prior-Guided Diffusion#
Prior-guided diffusion models represent a significant advancement in generative modeling by leveraging prior information to enhance the quality and efficiency of the diffusion process. Instead of relying solely on the inherent capabilities of the diffusion model, these approaches integrate pre-trained models or external knowledge to guide the generation process. This guidance can take several forms, such as using the output of a pre-trained image inpainting model as a prior to initialize the diffusion process, thereby reducing noise and improving the generation of detailed structures. Incorporating priors can mitigate noisy artifacts and hallucinations, common issues in diffusion models, leading to cleaner, more coherent results. Furthermore, priors can serve as a weak form of conditioning, providing contextual information that shapes the generation, such as object shapes or textures. By effectively utilizing prior knowledge, prior-guided diffusion models achieve greater control, accuracy, and efficiency in generating high-quality samples while mitigating common pitfalls of standard diffusion models. The success of this approach highlights the potential of integrating diverse sources of information into generative models for enhancing both performance and interpretability.
Temporal Consistency#
Maintaining temporal consistency is crucial in video inpainting, as it ensures that the inpainted content seamlessly blends with the original video across frames. The paper highlights the challenges in achieving this, particularly when dealing with long sequences or large masked regions. Traditional methods, relying on optical flow or transformer-based approaches, often fail to preserve temporal coherence, resulting in noticeable discrepancies and inconsistencies between frames. The authors address this by incorporating a motion module and employing the temporal smoothing property of the Video Diffusion Model. This dual approach leverages both local and global temporal information to maintain temporal consistency throughout the video, including at clip transitions. Furthermore, the expansion of the temporal receptive field helps improve the propagation of known pixels and the generation of unknown pixels, thereby enhancing overall temporal coherence. The paper demonstrates that these improvements effectively overcome the limitations of previous methods, leading to superior temporal consistency in the completed video.
Long-Seq Inference#
The concept of “Long-Seq Inference” in video inpainting addresses the challenge of maintaining temporal consistency when processing long sequences. Standard approaches often struggle to maintain coherence across numerous frames, leading to noticeable inconsistencies and artifacts at clip boundaries. The core problem is that the temporal receptive field of most models is limited, meaning they only consider a relatively short window of past and future frames. To overcome this, strategies often involve enhancing temporal consistency mechanisms, such as incorporating sophisticated motion models or expanding the temporal context of the processing. Methods like leveraging the temporal smoothing property of video diffusion models or employing a pre-inference step to process longer clips as a whole are examples of solutions proposed in the literature. This pre-processing allows the model to develop a more holistic understanding of the temporal dynamics before generating the final output. Ultimately, successful “Long-Seq Inference” requires a careful balance between computational efficiency and the need for a sufficiently long temporal receptive field to generate temporally consistent results. The quality of long-range temporal coherence heavily influences the realism and usability of the inpainted video.
Future Enhancements#
Future enhancements for DiffuEraser could focus on several key areas. Improving the handling of complex motions is crucial; the current model might struggle with scenes involving rapid or intricate movements. Expanding the range of temporal consistency is another important direction; while the paper addresses this to some degree, further improvements could yield more seamless results across extended video sequences. Exploring different prior models beyond ProPainter could lead to improved performance and perhaps more efficient processing. Investigating alternative diffusion model architectures might unlock greater generative capabilities, potentially reducing artifacts or improving detail preservation. Finally, rigorous testing on a wider variety of video datasets is necessary to assess the model’s robustness and identify any limitations or biases, paving the way for a more generally applicable and robust solution. Incorporating user interaction or feedback could also enhance the system’s utility and make it more versatile.
More visual insights#
More on figures

🔼 This figure shows an example of the noisy artifacts that can be generated by the model when inpainting videos. In particular, it focuses on a scenario where the masked region is above the sea level. The model fails to correctly reconstruct this area, resulting in a noisy output that closely resembles random noise instead of the expected coherent sea level. This highlights the limitation of the model in handling some scenarios and the need for further improvements in its generative capabilities.
read the caption
Figure 2: Example of noisy artifacts generated by the model. The masked region above the sea level is not completed correctly and resembles random noise.

🔼 This figure illustrates how prior information is incorporated into the DiffuEraser model during the inference stage to improve the quality of video inpainting. The process begins with the output of a pre-trained prior model (in this case, ProPainter). DDIM (Denoising Diffusion Implicit Models) inversion is applied to this output to transform it into a more suitable format for integration with the noisy latent representation of the current frame. This inverted prior is then added to the noisy latent, effectively providing a strong initialization and weak conditioning. This helps to guide the generation process within the diffusion model, reducing noisy artifacts and promoting the generation of coherent and meaningful inpainted content. The addition of priors serves as a form of weak supervision, making the generation process more stable and less prone to hallucinating unrealistic details.
read the caption
Figure 3: Incorporation of priors. We introduce priors during inference by performing DDIM inversion on the outputs of the prior model and adding them to the noisy latent.

🔼 This figure demonstrates the impact of incorporating prior information into the diffusion model. The left side shows inpainting results with only the diffusion model, resulting in noisy artifacts and inconsistencies within the masked regions. The right side shows how adding prior information significantly improves the inpainting quality by producing more coherent and realistic results with fewer artifacts. This highlights the effectiveness of using priors to initialize and guide the diffusion model, mitigating the generation of unwanted objects.
read the caption
Figure 4: Comparison of inpainting results before and after incorporating priors.

🔼 This figure illustrates how the temporal smoothing property inherent in Video Diffusion Models (VDMs) is leveraged to maintain consistency at the boundaries where video clips are joined. The even-numbered timesteps are generated from the beginning of a clip, while odd-numbered timesteps are generated from the midpoint. This staggered approach uses the VDM’s inherent temporal smoothing effect to produce smooth transitions between clips, enhancing the temporal consistency across the entire sequence.
read the caption
Figure 5: Utilizing the temporal smoothing property of the Video Diffusion Model (VDM) to enhance consistency at the intersections of clips.

🔼 This figure illustrates how the temporal consistency of video inpainting is optimized for long sequences. The issue addressed is that while individual short video clips (e.g., 22 frames) maintain temporal consistency, transitions between clips often exhibit inconsistencies. The optimization uses the temporal smoothing property of the Video Diffusion Model (VDM). By employing a staggered approach to denoising during inference (even-numbered timesteps from the clip start, odd-numbered from the midpoint), the method blends frames at clip boundaries seamlessly, enhancing overall consistency.
read the caption
Figure 6: Temporal consistency optimization for long-sequence inference.

🔼 This figure illustrates the method used to expand the temporal receptive field of the model. To improve temporal consistency, especially across long sequences, the model performs a pre-processing step before the main frame-by-frame inference. The pre-processing involves either pre-propagation (a) or pre-inference (b). Pre-propagation focuses on extending the influence of known pixels across the whole sequence to improve their consistency. In contrast, pre-inference processes the whole sequence as a single unit, using the temporal context of the entire sequence to guide the generation of unknown pixels (new regions that haven’t been seen in the video). This combined approach addresses the issue of consistency across segments.
read the caption
Figure 7: Perform pre-propagation or pre-inference to expand the temporal receptive field of model.

🔼 This figure illustrates how pre-propagation and pre-inference improve temporal consistency in long video sequences. The left side (a) shows pre-propagation, where a portion of the video is processed in advance to establish a strong baseline for consistency. This baseline guides the frame-by-frame processing shown on the right side (b), ensuring that consistency is maintained throughout the entire video. The process is repeated for consecutive video clips.
read the caption
Figure 8: The temporal consistency obtained from pre-propagation or pre-inference is maintained throughout all remaining frames.

🔼 This figure showcases a comparison of texture quality between the proposed DiffuEraser model and the existing Propainter model. It provides several examples of video frames with masked regions, displaying the inpainting results from both methods side-by-side. This allows for a visual assessment of how each model handles texture detail, clarity, and overall realism in the inpainted areas.
read the caption
Figure 9: Texture quality comparison between DiffuEraser and Propainter.

🔼 This figure presents a qualitative comparison of texture quality between DiffuEraser (the proposed model) and Propainter (a state-of-the-art transformer-based model) for video inpainting. It shows several examples of video frames with masked regions, alongside the inpainting results produced by each model. The visual comparison highlights that DiffuEraser generates more detailed and refined textures than Propainter, demonstrating its superior generative capabilities, particularly in handling complex textures and object details. The masked regions are indicated in green.
read the caption
Figure 10: Texture quality comparison between DiffuEraser and Propainter.

🔼 This figure shows a comparison of the temporal consistency achieved by DiffuEraser and Propainter on several video sequences. Each row displays a sequence of frames with a masked region. The leftmost column (‘Masked Frames’) shows the original frames with the masked area. The middle column shows the results obtained by Propainter, and the rightmost column shows the results generated by DiffuEraser. The comparison highlights how DiffuEraser provides better consistency in the inpainted content across consecutive frames, especially apparent in the sequences with larger masked regions or more complex movement.
read the caption
Figure 11: Temporal consistency comparison between DiffuEraser and Propainter.

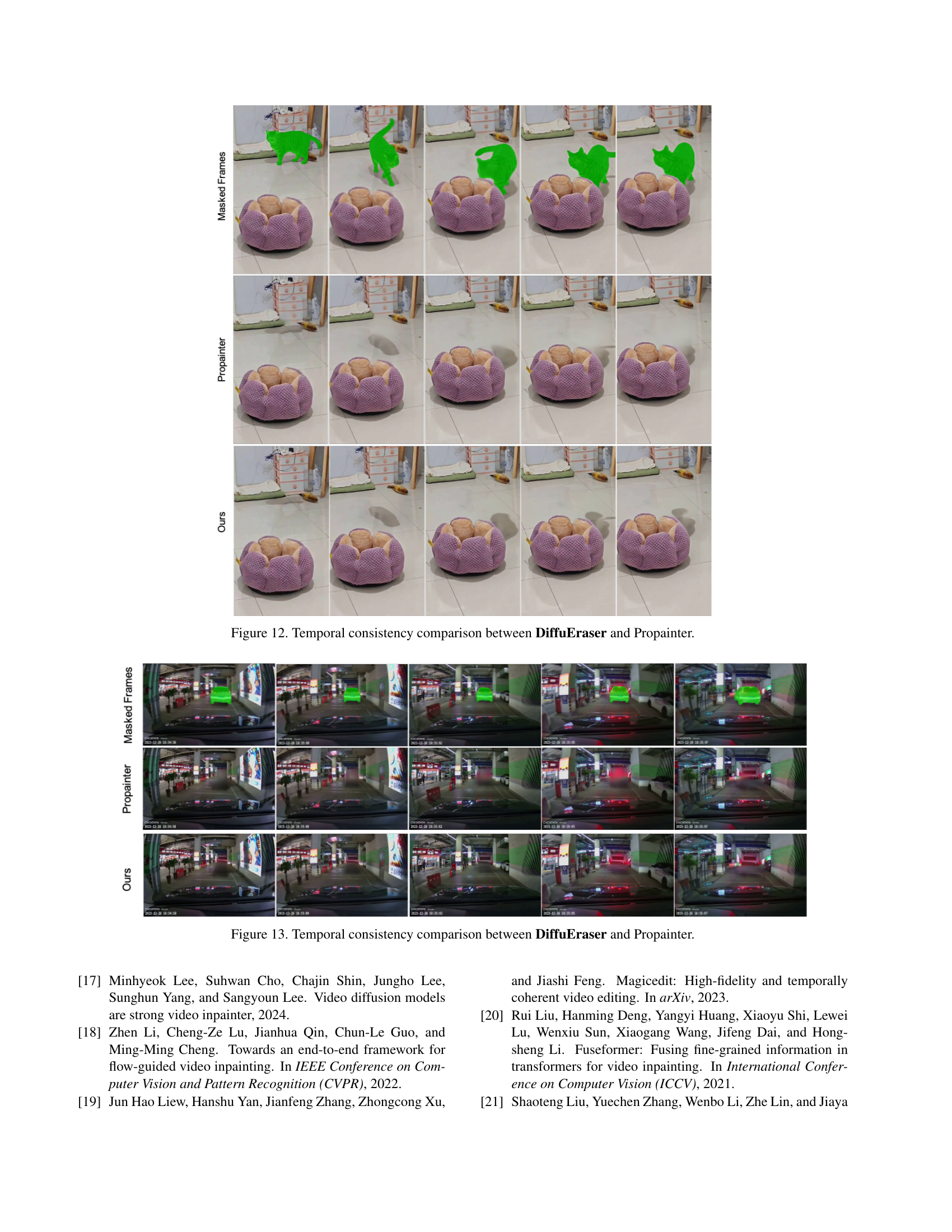
🔼 This figure compares the temporal consistency of video inpainting results between DiffuEraser and ProPainter. It visually demonstrates how well each model maintains consistent visual content across consecutive frames of a video after inpainting. Differences in the consistency of textures and objects across frames highlight the relative strengths and weaknesses of the two models in preserving temporal coherence. The effectiveness of each model in handling temporal consistency is crucial for producing realistic and natural-looking inpainted videos.
read the caption
Figure 12: Temporal consistency comparison between DiffuEraser and Propainter.
Full paper#