TL;DR#
Current methods for evaluating conversational AI systems are inadequate because they often rely on small-scale, manually-curated datasets that fail to capture the complexity of real-world interactions and cannot scale effectively. This leads to limited insights into agent performance and hinders the development of more robust and reliable systems. The lack of a standardized, comprehensive evaluation methodology is a significant obstacle to progress in the field.
IntellAgent is a new, open-source, multi-agent framework designed to overcome these limitations. It uses policy-driven graph modeling to create diverse, synthetic benchmarks, automating the generation of realistic events and interactive user-agent simulations. This innovative approach provides fine-grained diagnostics, enabling researchers to identify critical performance gaps and optimize their agents more effectively. IntellAgent’s modular design also promotes reproducibility and facilitates the integration of new domains and APIs, fostering collaboration and advancing the field as a whole.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces IntellAgent, a novel, open-source framework for comprehensively evaluating conversational AI agents. This addresses a critical gap in the field, as existing methods struggle to capture the complexity of real-world interactions. IntellAgent’s automated generation of diverse, synthetic benchmarks allows for scalable and reproducible evaluation, advancing research and deployment of more reliable conversational AI systems. Its modular design fosters community collaboration and facilitates seamless integration of new domains and APIs.
Visual Insights#

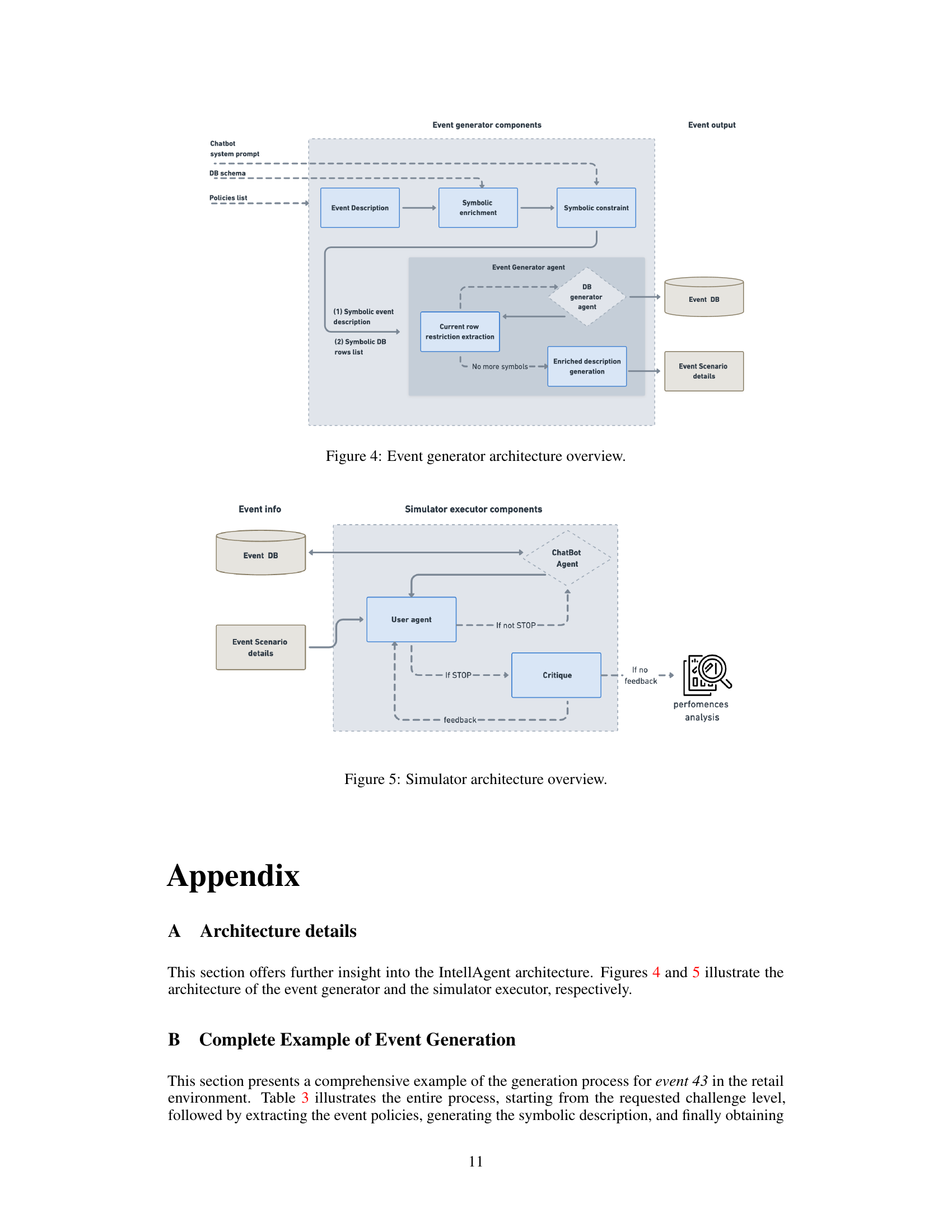
🔼 The IntellAgent system takes as input a chatbot prompt and database schema. It uses this information to generate an event, which simulates a user request and defines the initial state of the system’s database. The event is designed to test a specific subset of predefined policies. Then, a simulated conversation between the user and the chatbot is conducted based on that generated event. Finally, IntellAgent produces a detailed report that analyzes the chatbot’s performance in handling the event, focusing on fine-grained metrics related to policy adherence and overall effectiveness.
read the caption
Figure 1: System diagram. (1) Given a chatbot prompt and a Schema DB, the system generates an event that targets a subset of policies, which includes a user request and a system DB state. (2) For each event the system simulates a conversation between the user and the chatbot. (3) A fine-grained report on the chatbot performances is generated.
| Model | -airline | IntellAgent-airline | -retail | IntellAgent-retail |
| claude-3.5-sonnet | 0.46 | 0.70 | 0.69 | 0.71 |
| gpt-4o | 0.44 | 0.70 | 0.51 | 0.68 |
| gemini-1.5-pro | 0.34 | 0.63 | 0.43 | 0.58 |
| gpt-4o-mini | 0.30 | 0.55 | 0.46 | 0.62 |
| claude-3.5-haiku | 0.28 | 0.53 | 0.44 | 0.56 |
| gemini-1.5-flash | 0.21 | 0.40 | 0.31 | 0.48 |
🔼 This table compares three different random walk sampling strategies for selecting nodes in a policy graph used to generate synthetic data for evaluating conversational AI agents. The strategies are: 1) Uniform sampling, where each neighboring node has an equal chance of being selected; 2) Max sampling, where the node with the highest edge weight is always selected; and 3) IntellAgent weighted sampling, which uses a probability distribution that balances the diversity of the samples with how frequently those node combinations appear in real-world scenarios. The table shows how each strategy would select a sequence of policies (represented as nodes in the graph).
read the caption
Table 1: Comparison of random walk sampling strategies. (Left) Uniform sampling of the next node. (Middle) Selection of the next node based on maximal edge weight. (Right) IntellAgent weighted probability sampling, which balances diversity and alignment with real-world distributions.
In-depth insights#
LLM Evaluation#
LLM evaluation is a complex and rapidly evolving field. Traditional methods often fall short, relying on static benchmarks that don’t reflect the dynamic nature of real-world language interactions. The need for comprehensive, multi-faceted evaluation is paramount, considering aspects beyond simple accuracy, including factors like robustness, fairness, efficiency, and safety. Automated and scalable evaluation frameworks are crucial given the sheer volume and variability of LLM outputs. Focus should shift to simulating diverse real-world scenarios to assess performance in nuanced contexts. Furthermore, the development of fine-grained metrics that capture subtleties in language generation is vital. Ultimately, effective LLM evaluation needs a holistic approach, combining automated and manual methods, and prioritizing rigorous assessment across various relevant dimensions to ensure responsible and beneficial deployment of this powerful technology.
Multi-Agent Design#
A multi-agent design for conversational AI evaluation presents exciting possibilities. The core idea is to move beyond static benchmarks and create dynamic, interactive scenarios where multiple agents (the conversational AI, users, and potentially other entities) interact. This approach allows for a more nuanced and thorough assessment by capturing the complexity of real-world interactions and diverse policy considerations. The framework allows for simulating various levels of complexity, which is crucial for understanding agent performance under pressure. Policy-driven graph modeling becomes a critical component of such a design, representing policy relationships, probabilities, and potential conflicts. By automating scenario generation and providing fine-grained analysis, the multi-agent framework overcomes the limitations of traditional manual evaluations. However, designing a truly effective framework requires careful consideration of several factors including the types of agents involved, the complexity of the policies and their interactions, and the methods for generating comprehensive yet realistic scenarios. Successfully addressing these challenges could significantly enhance the reliability and trustworthiness of conversational AI systems.
Policy Graph#
The concept of a “Policy Graph” in the context of evaluating conversational AI systems is a novel and powerful approach to represent the complex relationships and dependencies between different policies an AI agent must adhere to. Unlike traditional methods that often treat policies in isolation, a policy graph offers a holistic representation, visualizing policies as nodes and their interactions as edges. The weight of these edges can encode the likelihood of co-occurrence or the complexity of the interaction. This enables more sophisticated simulation of real-world scenarios and fine-grained analysis of agent behavior, going beyond simple pass/fail metrics. The graph allows for the automated generation of diverse, realistic scenarios, testing agents’ abilities to navigate intricate policy landscapes. This dynamic approach contrasts sharply with static benchmarks, leading to more insightful evaluation and a deeper understanding of agent capabilities and limitations. Furthermore, the graph structure supports scalability and extensibility, facilitating the integration of new policies and domains, a crucial aspect for advancing conversational AI research and development.
Synthetic Data#
Synthetic data generation is a crucial aspect of evaluating conversational AI models, offering several advantages over real-world datasets. Synthetic datasets provide control over data distribution, enabling researchers to create targeted benchmarks that test specific capabilities. This is in contrast to real-world data, which often suffers from class imbalance, noisy labels, and an uncontrolled variety of interactions. The ability to generate diverse and realistic synthetic interactions is key to thoroughly evaluating model performance under various conditions, including those that are difficult or expensive to obtain in real-world settings. However, the challenge lies in ensuring that synthetic data faithfully reflects the characteristics of real-world conversations; otherwise, model performance on the synthetic data may not generalize to real-world scenarios. This requires careful design and rigorous validation, often involving techniques such as conditional prompting and multi-step generation to balance diversity and faithfulness. Finally, the use of synthetic data promotes reproducibility and reduces reliance on scarce or expensive real-world datasets, which is crucial for open-source research and community collaboration in evaluating conversational AI models.
Future Work#
The “Future Work” section of this research paper presents exciting avenues for enhancing IntellAgent. Integrating real-world interaction data into the policy graph is a crucial next step, as this would allow for more accurate edge weights and node challenge levels, ultimately improving the system’s realism and diagnostic capabilities. Further exploration is needed to refine the event generation process to ensure a more balanced and representative distribution of complexities and policy combinations, potentially leveraging advanced sampling techniques or reinforcement learning. Expanding the range of conversational AI benchmarks beyond T-Bench would demonstrate the framework’s adaptability and provide a broader understanding of its effectiveness. Finally, the authors should investigate incorporating more diverse agents and tools to enrich the testing environment and further assess the robustness and scalability of the IntellAgent framework. This multi-pronged approach would significantly strengthen the framework and further its contributions to the evaluation of conversational AI systems. Investigating bias mitigation techniques would also be invaluable.
More visual insights#
More on figures

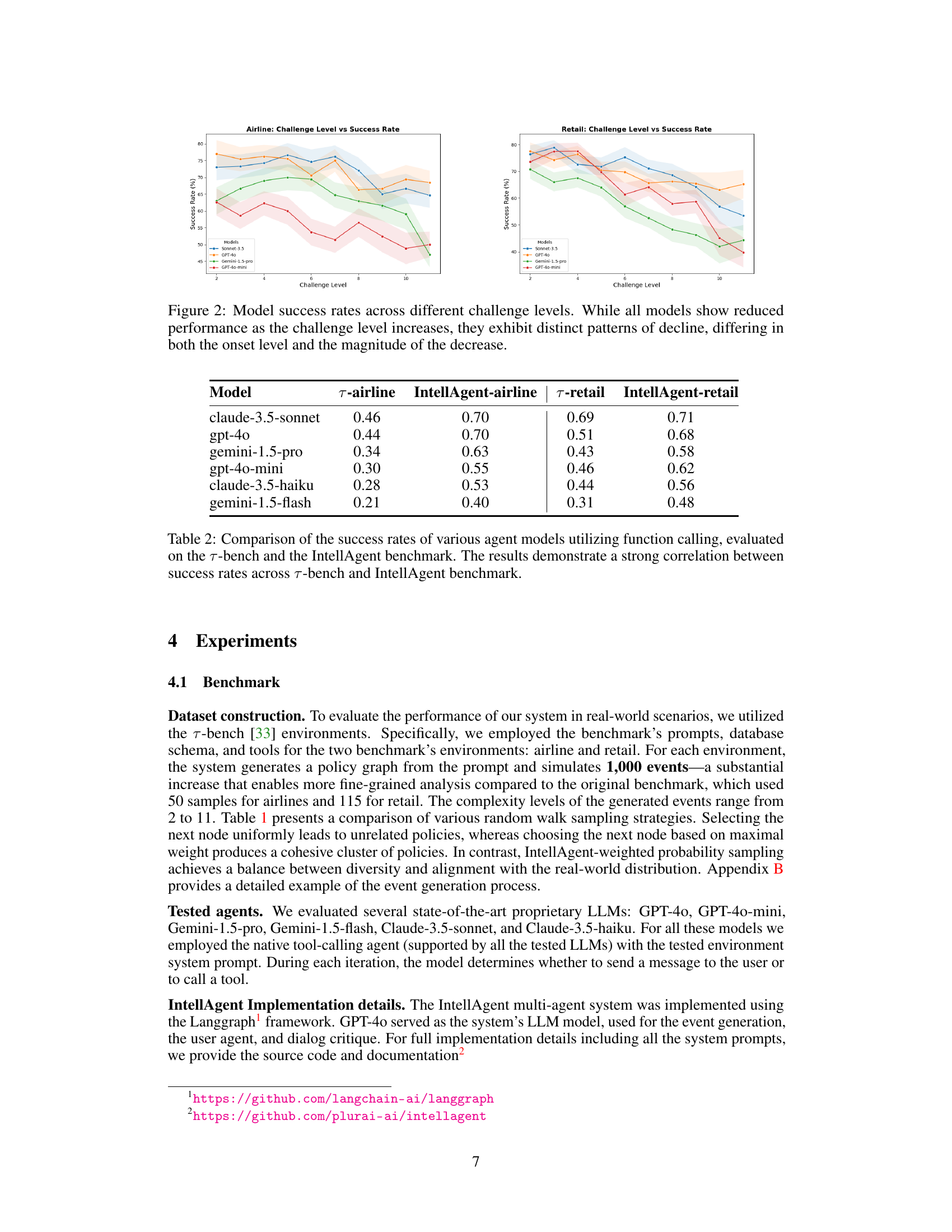
🔼 This figure displays the success rates of several conversational AI models across varying challenge levels. Each model’s performance is plotted against increasing challenge levels. The graph illustrates that, while all models show decreased success rates as challenge levels increase, their decline rates and starting points differ significantly. Some models start showing decreased performance at lower challenge levels compared to others, and some exhibit steeper performance drops as challenge levels escalate than others. This variation highlights the distinct capabilities and limitations of each model in handling complex conversational tasks.
read the caption
Figure 2: Model success rates across different challenge levels. While all models show reduced performance as the challenge level increases, they exhibit distinct patterns of decline, differing in both the onset level and the magnitude of the decrease.

🔼 This figure presents a bar chart comparing the success rates of four top-performing conversational AI models across different policy categories. The x-axis represents various policy categories (e.g., authentication, escalation, payment handling), while the y-axis shows the success rate for each model within each category. The chart highlights that success rates vary significantly across different policy categories, indicating that some categories pose greater challenges than others for these models. Additionally, it shows that the relative performance ranking of the four models is not consistent across all policy categories; a model performing well in one category might perform poorly in another. This demonstrates that different models have different strengths and weaknesses with respect to specific policies, emphasizing the need for comprehensive evaluation across a variety of scenarios.
read the caption
Figure 3: Comparison of the success rates of the top four models across various policy categories, highlighting that some categories are more challenging than others. Additionally, the relative performance order of different models varies across categories.
Full paper#