TL;DR#
Scaling reinforcement learning (RL) with large language models (LLMs) is crucial for continued AI progress but has been challenging. Previous methods haven’t produced competitive results. This paper introduces Kimi K1.5, a novel multi-modal LLM trained using RL. The core issue is that scaling RL with LLMs is hampered by limited training data and lack of effective training techniques.
The researchers address these challenges using a new simplistic RL framework, long context scaling (128k context window), and improved policy optimization. They avoid complex methods such as Monte Carlo tree search and value functions. Kimi K1.5 achieves state-of-the-art performance on various benchmarks, demonstrating the effectiveness of their approach. The team also introduces long2short methods, leveraging long-CoT techniques to improve short-CoT model results, showing significant improvements over existing models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to scaling reinforcement learning with large language models (LLMs), a significant challenge in AI. The successful application of RL to LLMs opens new avenues for continued AI improvement, beyond the limitations of solely relying on pre-trained data. The findings are relevant to researchers working on improving LLM reasoning abilities and developing more efficient RL training methods, especially for multi-modal models. The proposed techniques and results could significantly advance the state-of-the-art in various AI applications.
Visual Insights#
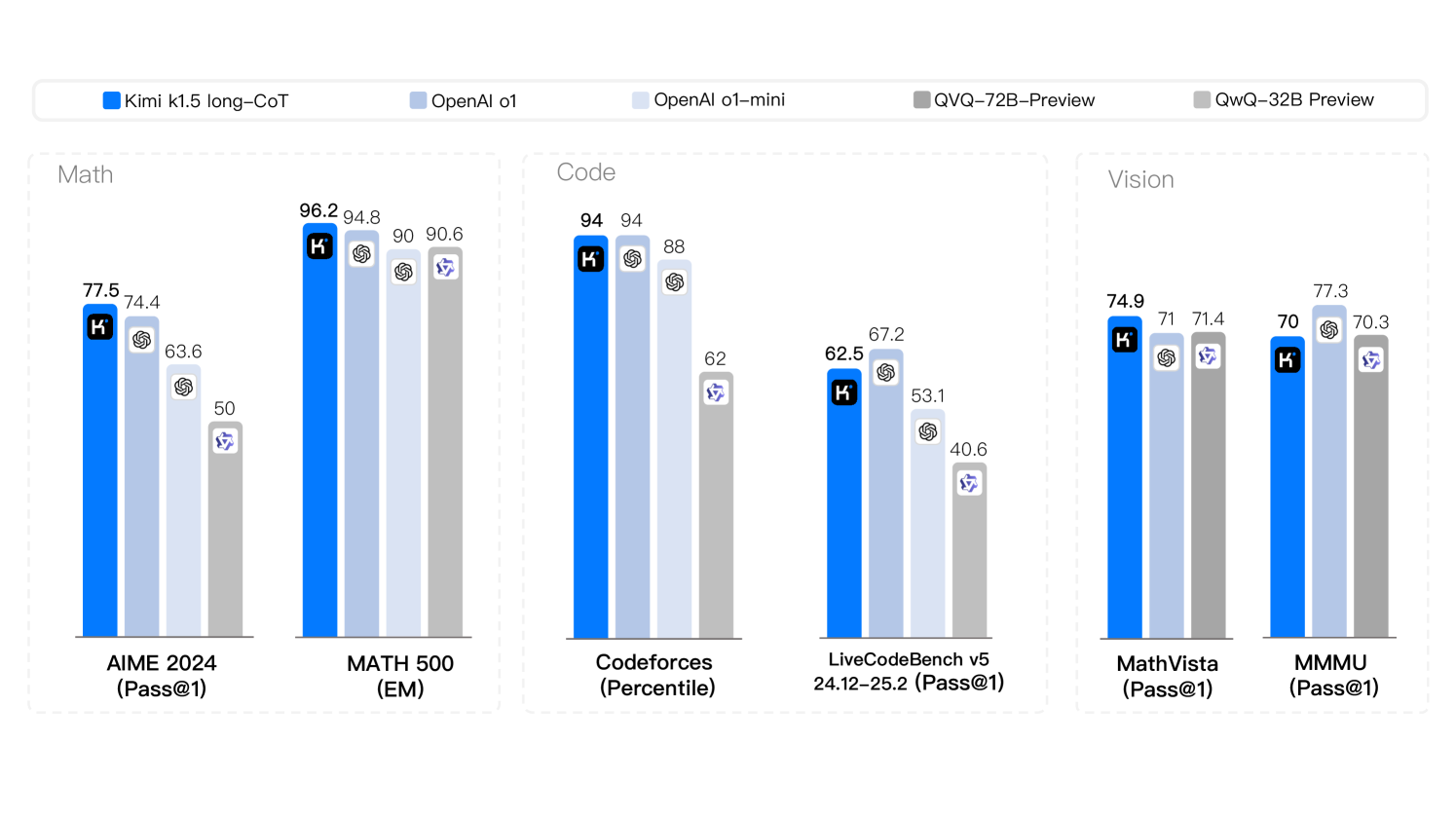
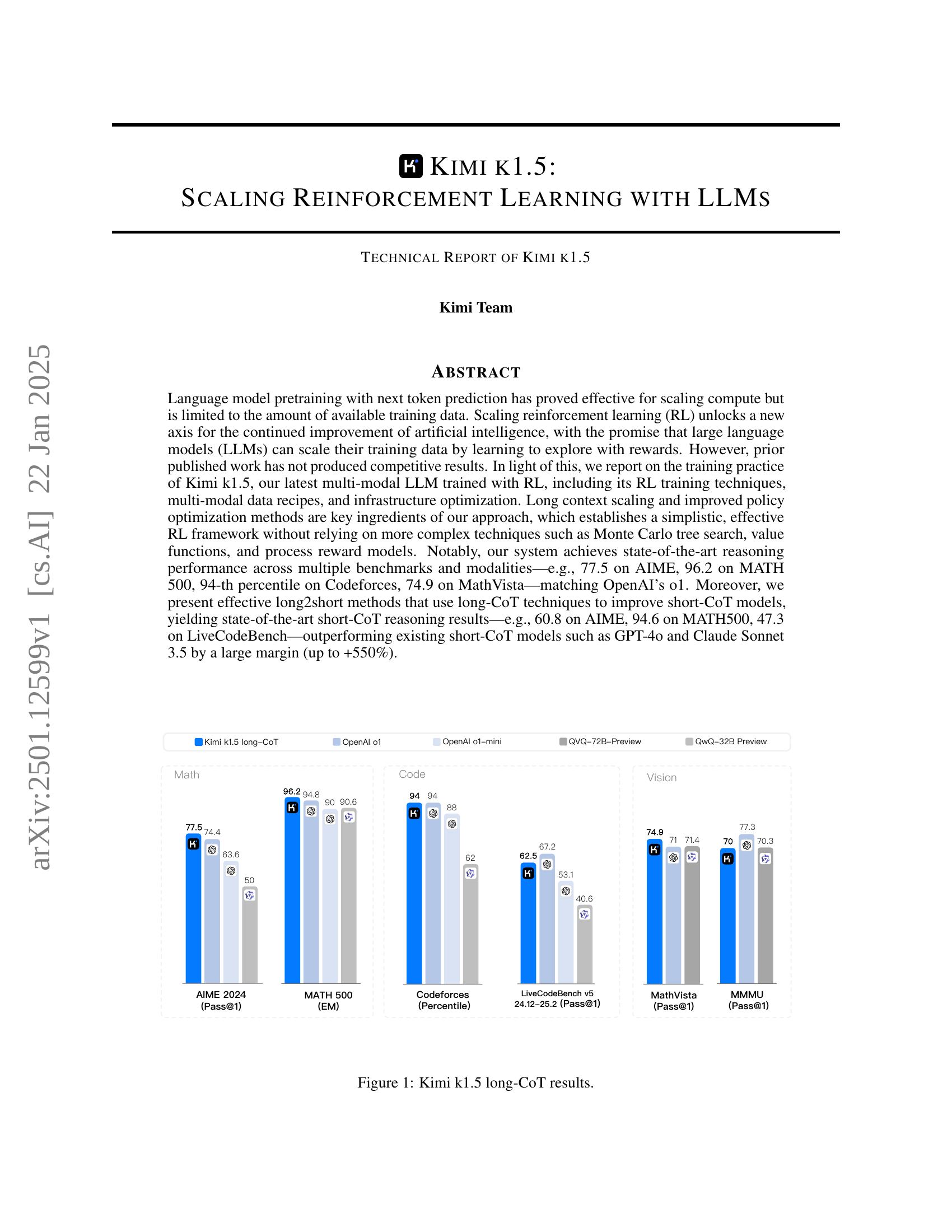
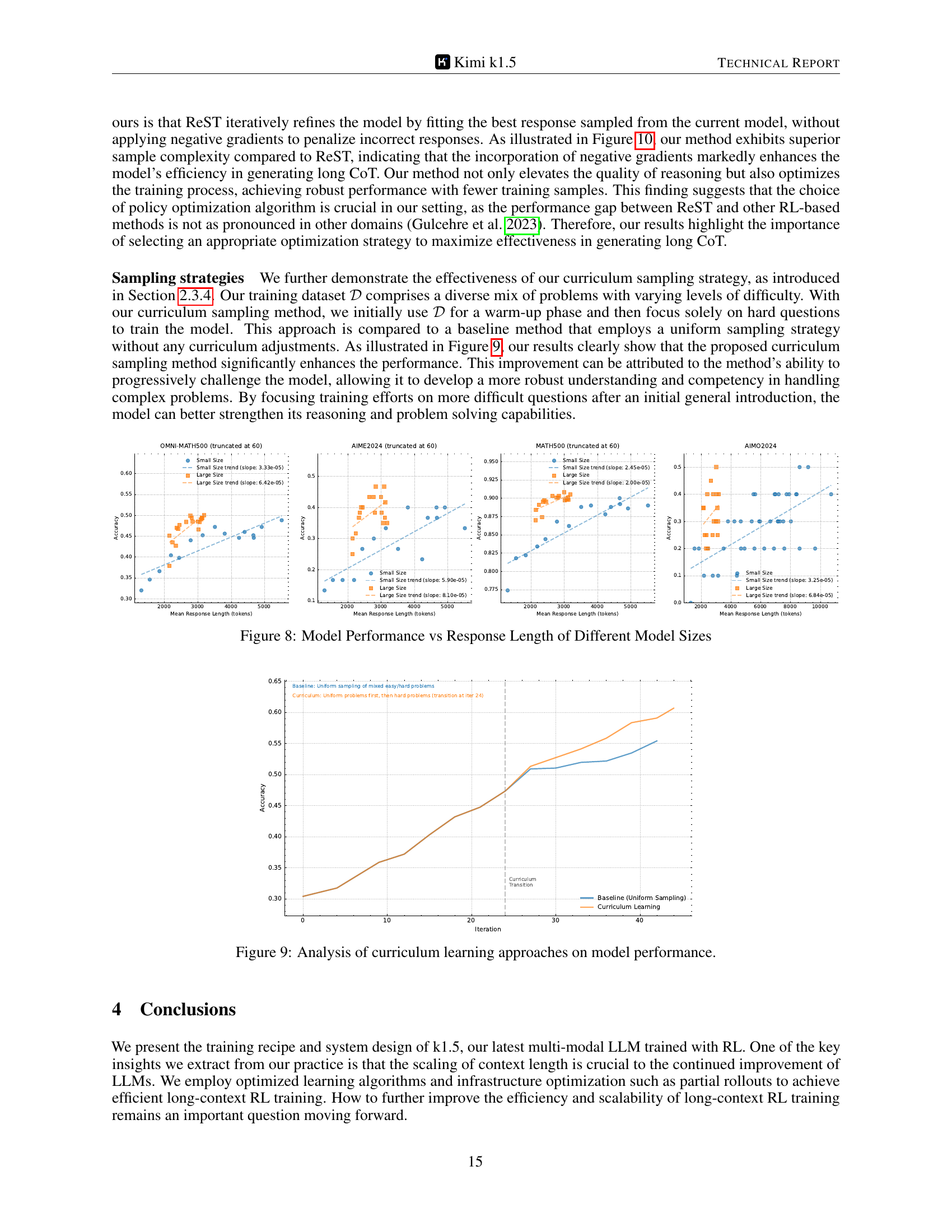
🔼 This figure presents a comparison of the Kimi K1.5 model’s performance on various reasoning benchmarks against other leading language models, both open-source and proprietary. The benchmarks cover different domains and modalities including mathematics (AIME 2024, MATH 500), code (Codeforces, LiveCodeBench), and vision-language tasks (MathVista). The bar chart visually displays the superior performance of Kimi K1.5 in achieving state-of-the-art results across most tasks.
read the caption
Figure 1: Kimi k1.5 long-CoT results.
In-depth insights#
RL Scaling with LLMs#
Reinforcement learning (RL) presents a powerful mechanism to enhance the capabilities of large language models (LLMs), particularly in complex reasoning tasks. Scaling RL with LLMs unlocks a new dimension in AI advancement, moving beyond the limitations of solely relying on pre-existing training data. By incorporating rewards, LLMs can learn to explore and generate more sophisticated solutions. However, achieving competitive results through RL-based LLM training has proven challenging, necessitating innovative training practices, multi-modal data integration, and infrastructure optimization. Key strategies include enhancing policy optimization through techniques such as online mirror descent, and leveraging long-context scaling to boost the model’s capacity for complex reasoning. The simplistic framework employed, avoiding complex methods like Monte Carlo Tree Search, highlights the potential for efficient RL scaling with LLMs. Moreover, bridging the gap between long and short chain-of-thought models presents a critical area of further research, with techniques such as model merging, rejection sampling, and reinforcement learning showing promise for improving efficiency and performance.
Long-Context RL#
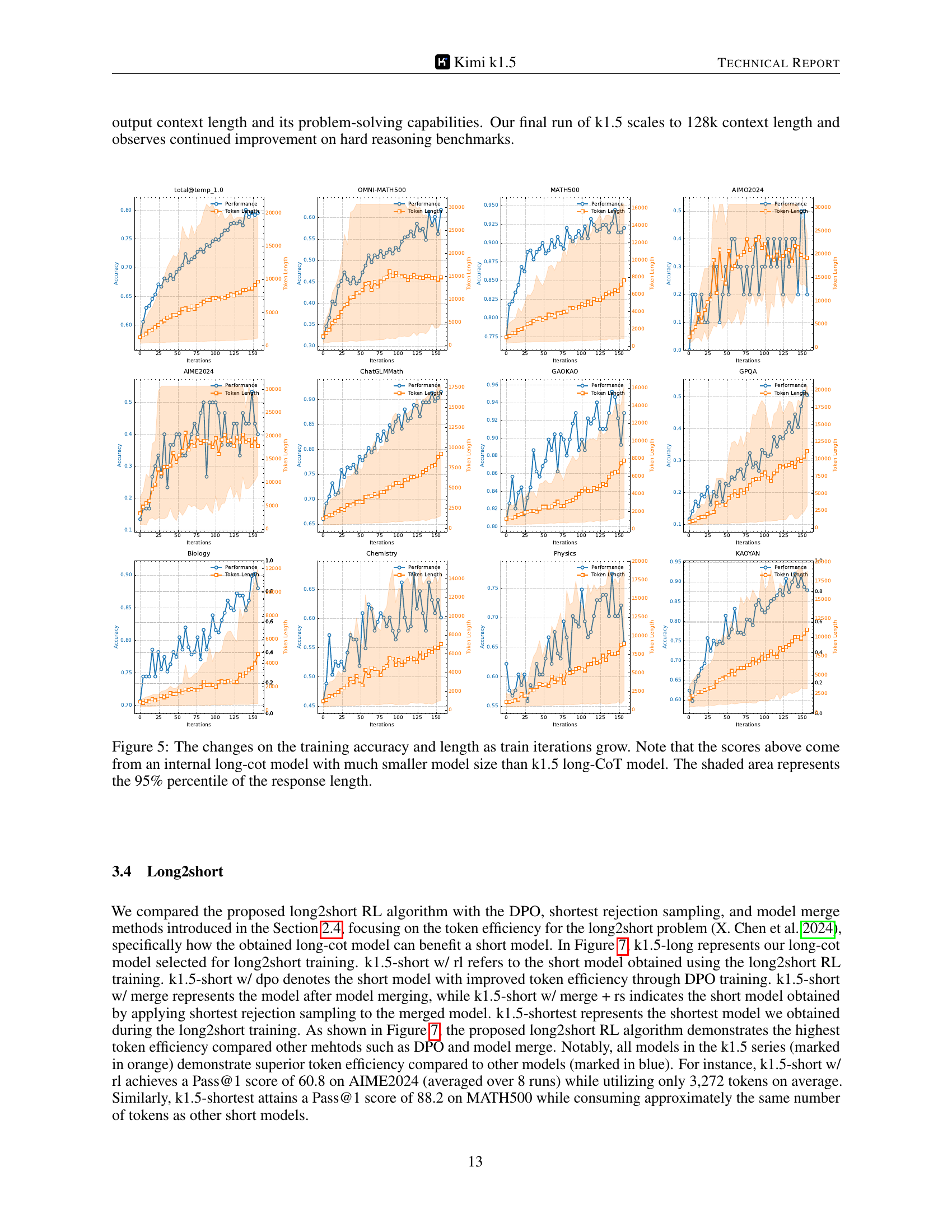
Long-context Reinforcement Learning (RL) represents a significant advancement in training large language models (LLMs). By dramatically increasing the context window, often to tens or hundreds of thousands of tokens, this approach allows LLMs to consider significantly more information when making decisions. This is crucial because it enables the model to engage in more complex reasoning tasks, essentially allowing for more ’thinking steps’ within a single inference. The increased context length also facilitates better handling of long chain-of-thought (CoT) reasoning, which is essential for tackling difficult problems that require multiple steps of logical deduction. However, long-context RL faces challenges in terms of computational cost and efficiency. The paper explores techniques like partial rollouts to mitigate these issues, enabling the training of sophisticated models without excessive resource consumption. This exploration of longer context windows opens new avenues for enhancing LLM capabilities, pushing the boundaries of their reasoning abilities and potentially leading to more human-like problem-solving.
Multimodal Reasoning#
Multimodal reasoning, the capacity of AI systems to understand and reason using information from multiple modalities like text, images, and audio, is a rapidly evolving field. Current research emphasizes the fusion of different data sources to produce more robust and comprehensive representations. This contrasts with unimodal approaches which often struggle with incomplete or ambiguous information. The benefits are significant: enhanced reasoning capabilities, improved accuracy in complex tasks, and the potential to handle real-world scenarios more effectively. However, challenges remain. Creating high-quality multimodal datasets is time-consuming and expensive, requiring careful annotation and curation. Developing effective fusion mechanisms is also complex, necessitating advanced techniques to integrate diverse data types seamlessly and avoid information loss. Future research should focus on creating larger, more diverse datasets and developing innovative fusion algorithms that can handle the nuances of multimodal information processing. A deeper understanding of how humans integrate multimodal information is also crucial for guiding model development.
Long2Short Methods#
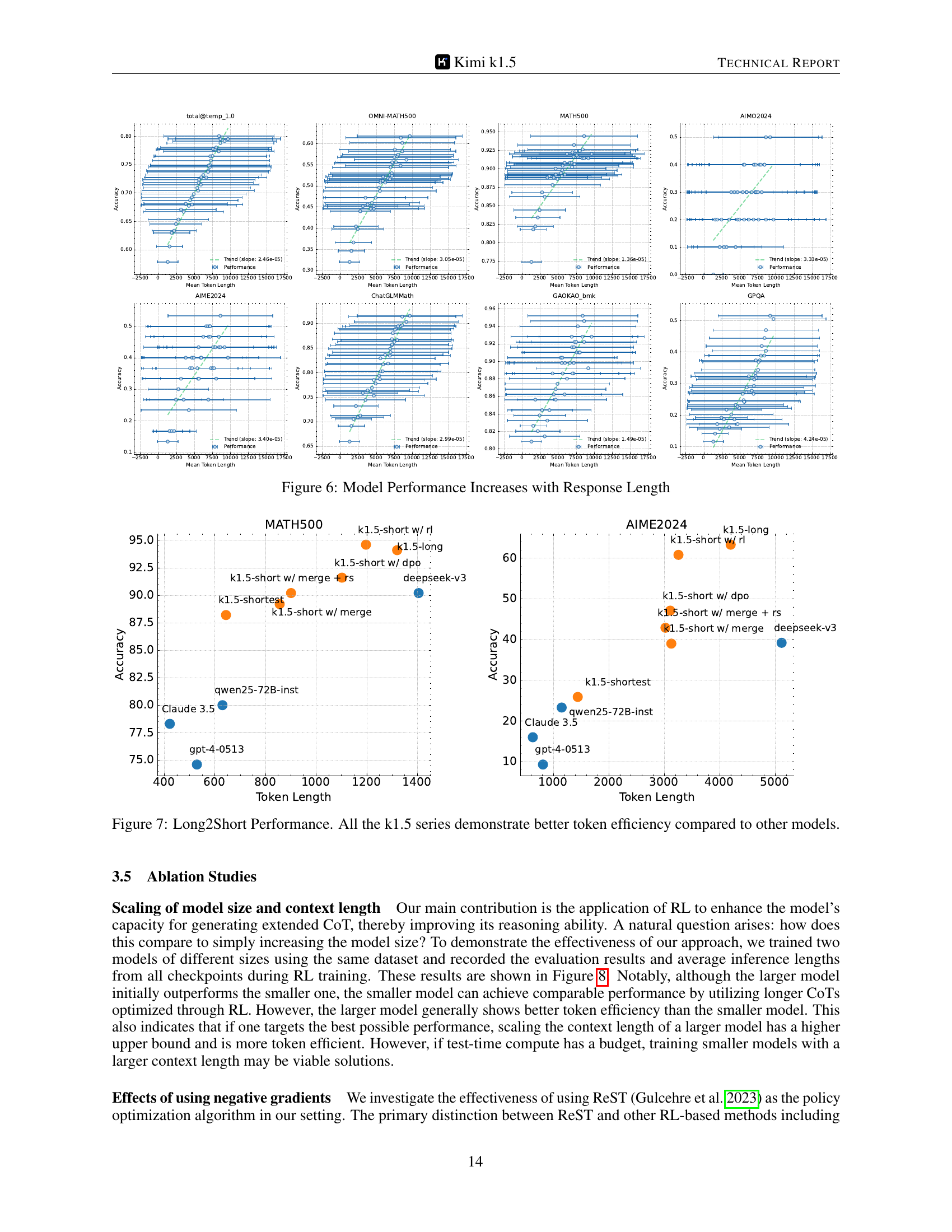
The concept of “Long2Short Methods” in the context of large language models (LLMs) addresses the efficiency challenge posed by long chain-of-thought (CoT) reasoning. Long CoT methods, while powerful, can be computationally expensive, requiring significant inference time and resources. Long2Short techniques aim to transfer the reasoning capabilities learned from lengthy CoT processes to shorter, more efficient models. This involves bridging the performance gap between computationally intensive long CoT and the speed and efficiency of short CoT, while preserving accuracy. Several strategies are explored, including model merging, where weights from long and short CoT models are combined. Another approach uses shortest rejection sampling, selecting the most concise correct response from multiple samples. Reinforcement learning (RL) also plays a crucial role, training models to generate short but effective reasoning sequences. The core goal is to create models that achieve high performance on reasoning benchmarks while minimizing the computational cost at inference time, making these methods essential for the practical deployment of LLMs in resource-constrained environments.
RL Training Practices#
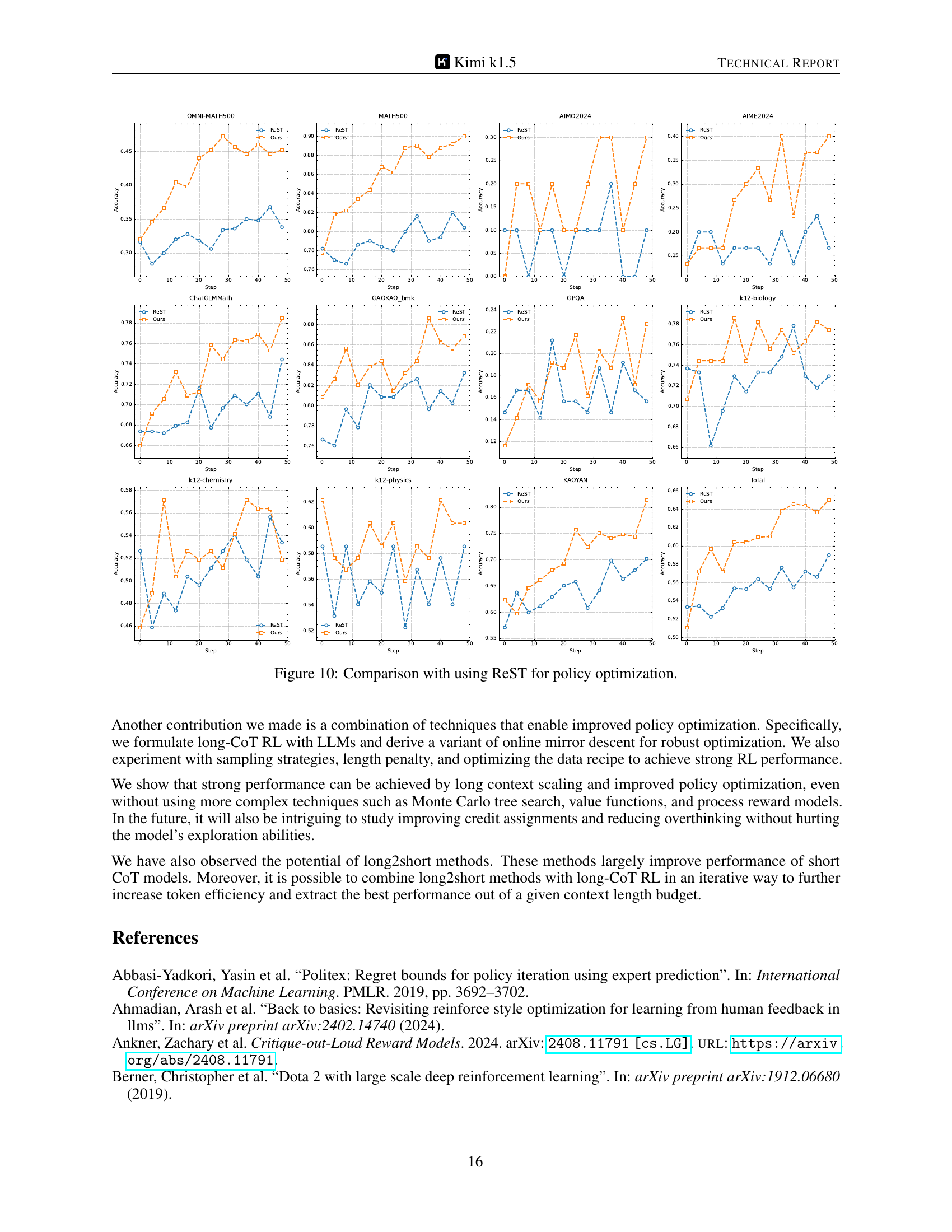
Reinforcement learning (RL) training practices for large language models (LLMs) are crucial for achieving strong reasoning abilities. Key ingredients include long context scaling, enabling the model to leverage extensive information; improved policy optimization, employing techniques like online mirror descent for robust training; and a simplistic RL framework that avoids complex methods like Monte Carlo tree search, focusing instead on efficient direct policy optimization. The choice of reward model is also critical; the paper highlights success with chain-of-thought based rewards for more accurate evaluation. Furthermore, effective sampling strategies like curriculum and prioritized sampling are vital for efficient training. The paper details mitigation of reward hacking via prompt set curation, carefully selecting questions for diverse coverage, balanced difficulty, and accurate evaluability. Finally, the incorporation of length penalties to address the issue of overthinking, promoting efficient model responses, is noteworthy.
More visual insights#
More on figures

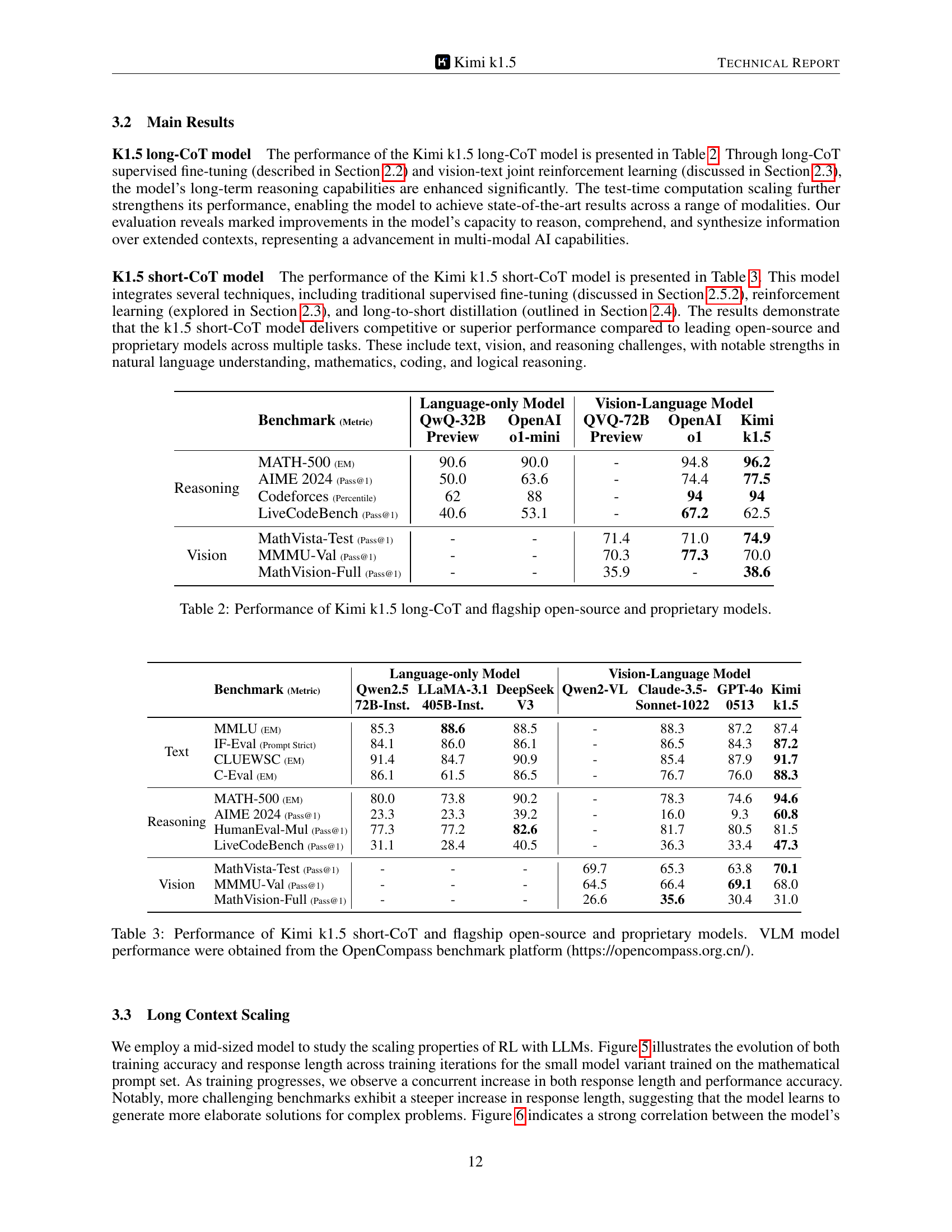
🔼 This figure presents a comparison of Kimi K1.5’s performance on various short-Chain of Thought (short-CoT) reasoning tasks against other leading language models, both open-source and proprietary. It showcases Kimi K1.5’s performance across multiple benchmarks and modalities (Math, Code, Vision), highlighting its state-of-the-art results and significant improvements over existing models.
read the caption
Figure 2: Kimi k1.5 short-CoT results.

🔼 This figure provides a high-level overview of the large-scale reinforcement learning training system used for the LLM. It illustrates the interactions between various components, including rollout workers, trainer workers, a central master, reward models, and a replay buffer. The rollout workers generate rollout trajectories by interacting with the model, while the trainer workers update model weights based on the experiences stored in the replay buffer. The central master coordinates these processes, ensuring efficient data processing. Reward models evaluate the quality of model outputs, and the replay buffer enables diverse and unbiased data for training.
read the caption
(a) System overview

🔼 This figure illustrates the partial rollout mechanism used in the large-scale reinforcement learning system for LLMs. Partial rollouts optimize the handling of complex reasoning trajectories by managing rollouts of both long and short trajectories. If a trajectory exceeds a token limit, the unfinished portion is saved and continued in the next iteration. This ensures that no single lengthy trajectory monopolizes resources, and that shorter rollouts can be processed while longer ones are underway, maximizing efficiency. The diagram shows how segments of long responses are stored in a replay buffer and used across iterations, reducing computational overhead.
read the caption
(b) Partial Rollout
Full paper#