TL;DR#
Prior research has heavily relied on supervised data to enhance LLMs’ reasoning abilities. However, this approach can be computationally expensive and limits the model’s ability to self-evolve. This paper explores a novel approach using pure reinforcement learning (RL) to develop reasoning capabilities directly in the base model, focusing on self-evolution through the RL process. This method encounters challenges such as poor readability and language mixing.
To overcome these issues, the researchers introduce DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI’s state-of-the-art models on reasoning tasks, and the researchers open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models to support the research community. This strategy showcases that reasoning patterns from larger models are crucial for improving reasoning capabilities in smaller models. This is demonstrated by the success of distilling the reasoning patterns into smaller, efficient models that outperform existing open-source models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to enhance reasoning capabilities in large language models (LLMs) using reinforcement learning. It addresses the limitations of existing methods, offers open-source models for the research community, and opens up new avenues for research on improving reasoning in LLMs. The results significantly advance the state-of-the-art in LLM reasoning, showing impressive performance comparable to top commercial models and setting new benchmarks.
Visual Insights#

🔼 This figure presents a benchmark comparison of the DeepSeek-R1 model’s performance against other models across six different reasoning tasks. The tasks assessed are AIME 2024, Codeforces, GPQA Diamond, MATH-500, MMLU, and SWE-bench Verified. Each bar represents the accuracy or percentile achieved by a specific model on each task. DeepSeek-R1 and its variants (DeepSeek-R1-32B) are compared against OpenAI models (OpenAI-01-1217, OpenAI-01-mini) and DeepSeek-V3. The figure showcases DeepSeek-R1’s competitive performance, particularly on several tasks, highlighting its advanced reasoning capabilities.
read the caption
Figure 1: Benchmark performance of DeepSeek-R1.
| A conversation between User and Assistant. The user asks a question, and the Assistant solves it. |
| The assistant first thinks about the reasoning process in the mind and then provides the user |
| with the answer. The reasoning process and answer are enclosed within <think> </think> and |
| <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> |
| <answer> answer here </answer>. User: prompt. Assistant: |
🔼 This table presents the template used for training the DeepSeek-R1-Zero model. The template structures the input for the model, which consists of a user prompt and the model’s response. The model’s response is formatted with
<think>tags encapsulating the reasoning process and<answer>tags containing the final answer. This standardized format ensures consistent input for reinforcement learning, enabling the model to learn effective reasoning strategies. During training, the placeholder ‘prompt’ is replaced with actual reasoning questions.read the caption
Table 1: Template for DeepSeek-R1-Zero. prompt will be replaced with the specific reasoning question during training.
In-depth insights#
RL Reasoning#
Reinforcement learning (RL) is revolutionizing reasoning capabilities in large language models (LLMs). The core idea is to incentivize reasoning behaviors by rewarding the model for correct and comprehensive responses, driving it to develop sophisticated problem-solving strategies. Unlike supervised fine-tuning, which relies on pre-existing labeled data, RL trains the model through interaction, encouraging self-discovery and the emergence of unexpected reasoning abilities. This approach yields promising results in various tasks, including mathematics, code generation, and commonsense reasoning. However, pure RL faces challenges like poor readability and language mixing. To address this, hybrid approaches using small amounts of supervised data as a “cold start” are used, demonstrating that a combination of RL and supervised learning can significantly improve performance. Distilling these learned reasoning patterns into smaller models is another promising avenue, reducing the computational cost of inference and making advanced reasoning accessible to a wider range of applications. While RL offers powerful tools for enhanced reasoning, further work is needed to optimize efficiency, address biases, and fully unlock the potential of this methodology. The emergence of “aha moments” during RL training showcases the power of self-directed learning and hints at future advancements in achieving artificial general intelligence.
DeepSeek-R1#
DeepSeek-R1 represents a significant advancement in Large Language Model (LLM) reasoning capabilities. Unlike its predecessor, DeepSeek-R1-Zero, which relied solely on reinforcement learning (RL) without supervised fine-tuning, DeepSeek-R1 incorporates a multi-stage training process. This includes a crucial cold-start phase using a small amount of curated data to improve the model’s initial state and enhance the stability and readability of its reasoning process. The introduction of this cold-start data addresses shortcomings observed in DeepSeek-R1-Zero, such as poor readability and language mixing. Furthermore, DeepSeek-R1 employs a refined RL approach focused on reasoning-intensive tasks, incorporating rejection sampling and supervised fine-tuning to further optimize performance. The resulting model achieves performance comparable to OpenAI’s leading models on various reasoning benchmarks, demonstrating the effectiveness of the hybrid approach. Finally, the open-sourcing of DeepSeek-R1 and several distilled smaller dense models (1.5B, 7B, 8B, 14B, 32B, 70B parameters) makes the advancements accessible to the research community, fostering further innovation in the field. This demonstrates a practical approach to bridging the gap between pure RL-trained models and those requiring substantial supervised data.
Distillation#
The research paper section on “Distillation” explores a crucial technique for making large language models (LLMs) more efficient and accessible. The core idea is to transfer the knowledge and reasoning capabilities learned by a large, computationally expensive model (the teacher) to a smaller, more efficient model (the student). This is achieved through a process of knowledge distillation, where the smaller model learns to mimic the behavior of the larger model. This process is particularly important for reasoning tasks, as large models often require significant computational resources. The paper demonstrates that this distillation technique can produce smaller models that perform surprisingly well on various reasoning benchmarks, even outperforming some existing open-source models. This highlights the potential for creating powerful, yet resource-friendly, reasoning LLMs. The researchers also show that directly applying reinforcement learning (RL) to smaller models is less effective than distilling from a larger, RL-trained model, which underscores the importance and efficacy of their distillation approach. This suggests that the intricate reasoning patterns discovered during the training of larger models are essential and are best leveraged through distillation. By releasing distilled models, the research encourages broader community involvement and accelerates the development of more efficient and accessible reasoning LLMs.
Benchmarking#
Benchmarking in this research paper plays a crucial role in evaluating the effectiveness of the proposed DeepSeek-R1 model. The selection of diverse and challenging benchmarks is commendable, covering various aspects like reasoning (AIIME 2024, MATH-500), coding (Codeforces, LiveCodeBench), and knowledge (MMLU, GPQA Diamond). The direct comparison to OpenAI’s o1 models provides a strong baseline, allowing for a clear assessment of DeepSeek-R1’s performance. The inclusion of both closed-source (OpenAI models) and open-source models (QwQ-32B) in the benchmark facilitates a comprehensive evaluation. Moreover, the detailed analysis of results, presented in tables with metrics like pass@1 and cons@64, enhances the transparency of the evaluation. However, a limitation is the heavy reliance on existing benchmarks without introducing completely novel tasks. It would also be valuable to include benchmarks specifically designed to measure the model’s specific strengths, such as its ability to generate lengthy and complex chain-of-thought reasoning. Future work could include creating new, nuanced benchmarks tailored to evaluate the unique characteristics of advanced reasoning models, and the focus on the interpretability of the results to understand both success and failure cases more thoroughly.
Future Work#
The paper’s ‘Future Work’ section suggests several promising avenues for enhancing DeepSeek-R1. Addressing language mixing is crucial, as the current model sometimes blends languages unexpectedly, hindering readability and broader applicability. Improving handling of queries in languages other than English and Chinese is a clear priority. Improving performance on software engineering tasks is another key area, requiring further exploration of efficient RL techniques to overcome the computational limitations. Refinement of the prompting engineering process is vital, as the model’s performance is sensitive to prompt design, and improving zero-shot prompting strategies could significantly broaden its usability. Further investigation into the ‘aha moment’ phenomenon observed during training could reveal valuable insights into the model’s learning process and potentially lead to new training strategies. Finally, scaling the model to even more complex reasoning tasks requiring extensive extended test-time computation is crucial for tackling more sophisticated problems, especially in areas such as function calling and multi-turn conversations.
More visual insights#
More on figures

🔼 This figure shows a graph illustrating the performance of the DeepSeek-R1-Zero model on the AIME 2024 benchmark throughout its reinforcement learning (RL) training. The y-axis represents the model’s accuracy (percentage correct), and the x-axis shows the number of training steps. The graph displays two lines: one for pass@1 accuracy (the percentage of times the top predicted answer was correct) and another for cons@64 (the consensus accuracy across 64 samples). To avoid fluctuations in accuracy, 16 response samples were used for each question and the average accuracy is shown. The plot clearly demonstrates an improvement in accuracy over the course of the RL training, showcasing the model’s learning process and its ability to improve its reasoning capabilities through RL without supervised fine-tuning.
read the caption
Figure 2: AIME accuracy of DeepSeek-R1-Zero during training. For each question, we sample 16 responses and calculate the overall average accuracy to ensure a stable evaluation.

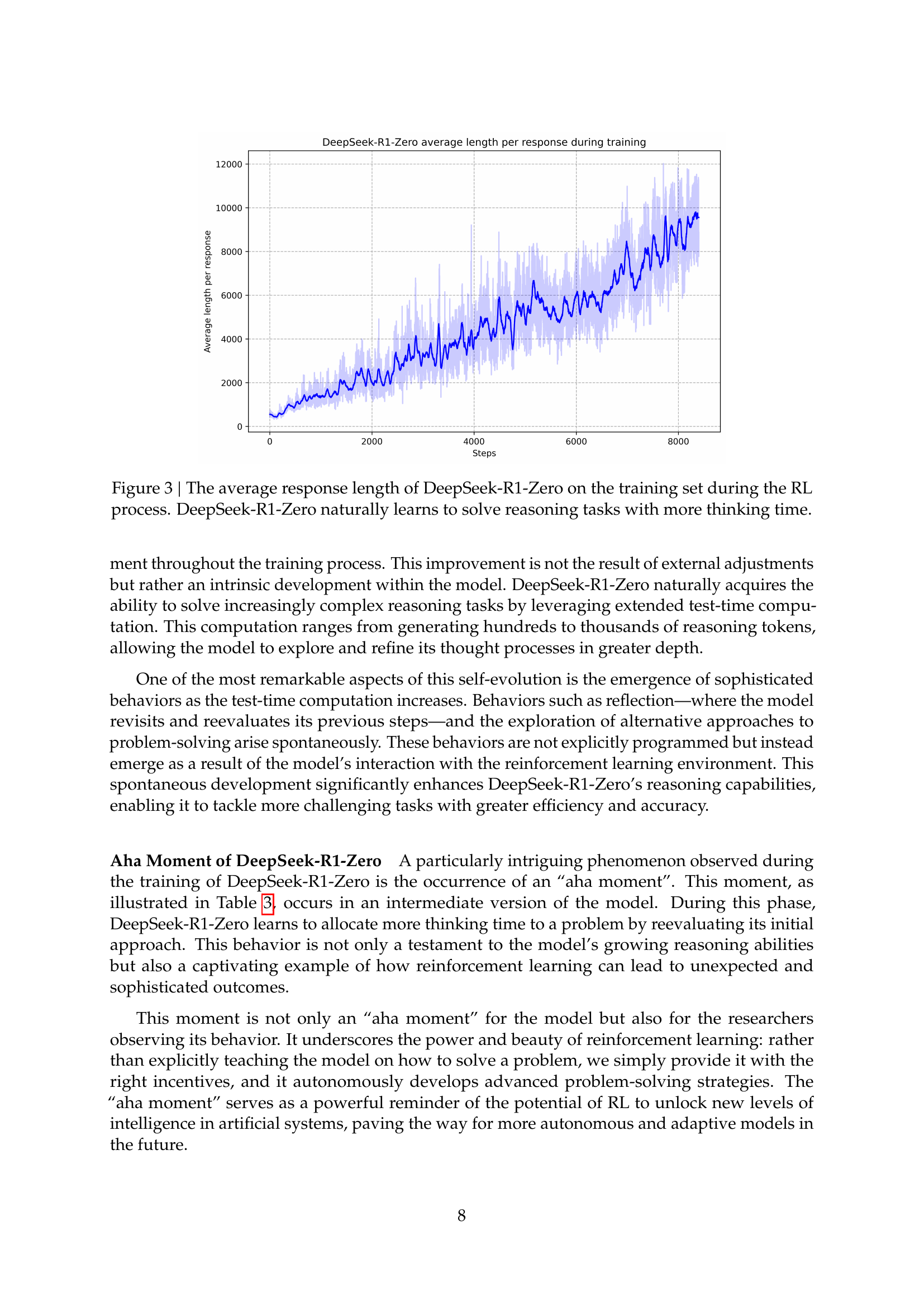
🔼 This figure shows how the average length of DeepSeek-R1-Zero’s responses changed during its reinforcement learning (RL) training. The x-axis represents the training step, and the y-axis represents the average number of tokens in the model’s responses. As training progressed, the model’s responses got progressively longer, indicating that it was taking more time to think through and solve increasingly complex reasoning problems. This increase in response length wasn’t manually enforced but emerged naturally as a consequence of the RL process, showcasing the model’s self-improvement through RL.
read the caption
Figure 3: The average response length of DeepSeek-R1-Zero on the training set during the RL process. DeepSeek-R1-Zero naturally learns to solve reasoning tasks with more thinking time.
More on tables
| Model | AIME 2024 | MATH-500 | GPQA | LiveCode | CodeForces | |
|---|---|---|---|---|---|---|
| Diamond | Bench | |||||
| pass@1 | cons@64 | pass@1 | pass@1 | pass@1 | rating | |
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| OpenAI-o1-0912 | 74.4 | 83.3 | 94.8 | 77.3 | 63.4 | 1843 |
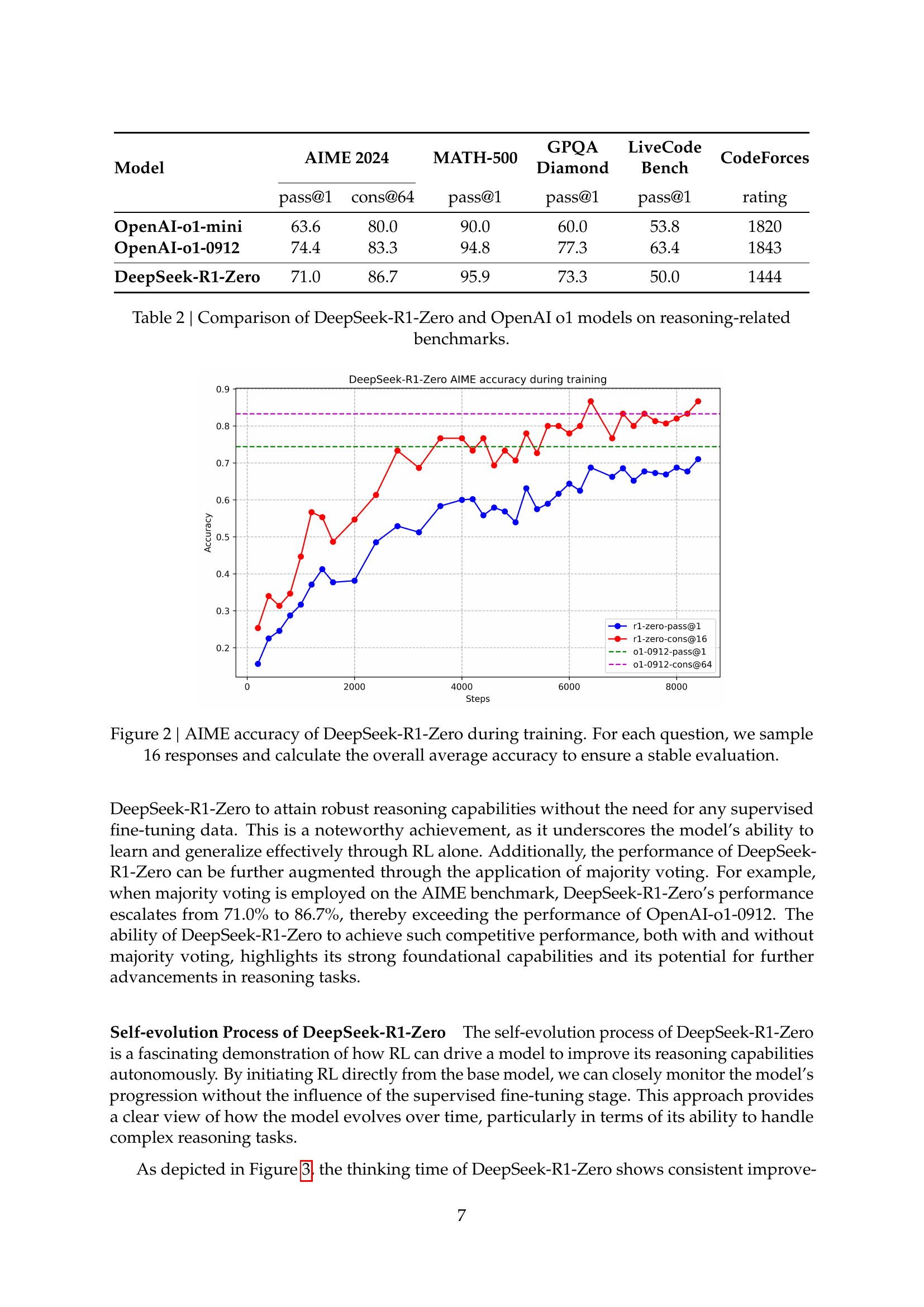
| DeepSeek-R1-Zero | 71.0 | 86.7 | 95.9 | 73.3 | 50.0 | 1444 |
🔼 This table compares the performance of DeepSeek-R1-Zero, a model trained using reinforcement learning without any supervised fine-tuning, against OpenAI’s o1 models on various reasoning benchmarks. It showcases DeepSeek-R1-Zero’s ability to achieve comparable results to OpenAI’s models on tasks such as AIME 2024, MATH-500, and GPQA Diamond, even without relying on any supervised data during training. The comparison highlights DeepSeek-R1-Zero’s performance across multiple reasoning-related benchmarks, providing insight into its strengths and weaknesses relative to established state-of-the-art models.
read the caption
Table 2: Comparison of DeepSeek-R1-Zero and OpenAI o1 models on reasoning-related benchmarks.
| Question: If , then the sum of the real solutions of is equal to |
| Response: <think> |
| To solve the equation , let’s start by squaring both |
| Rearrange to isolate the inner square root term: |
| … |
| Wait, wait. Wait. That’s an aha moment I can flag here. |
| Let’s reevaluate this step-by-step to identify if the correct sum can be |
| We started with the equation: |
| First, let’s square both sides: |
| Next, I could square both sides again, treating the equation: |
| … |
🔼 This table showcases an example from the training of DeepSeek-R1-Zero where the model demonstrates a sudden improvement in its reasoning process, marked by a shift in tone to a more human-like, self-reflective style. The model stops and reevaluates its approach, demonstrating advanced reasoning capabilities. This moment is considered significant not only for the model’s development but also for the researchers observing it, highlighting the unexpected and powerful nature of reinforcement learning in driving autonomous advancements in model reasoning.
read the caption
Table 3: An interesting “aha moment” of an intermediate version of DeepSeek-R1-Zero. The model learns to rethink using an anthropomorphic tone. This is also an aha moment for us, allowing us to witness the power and beauty of reinforcement learning.
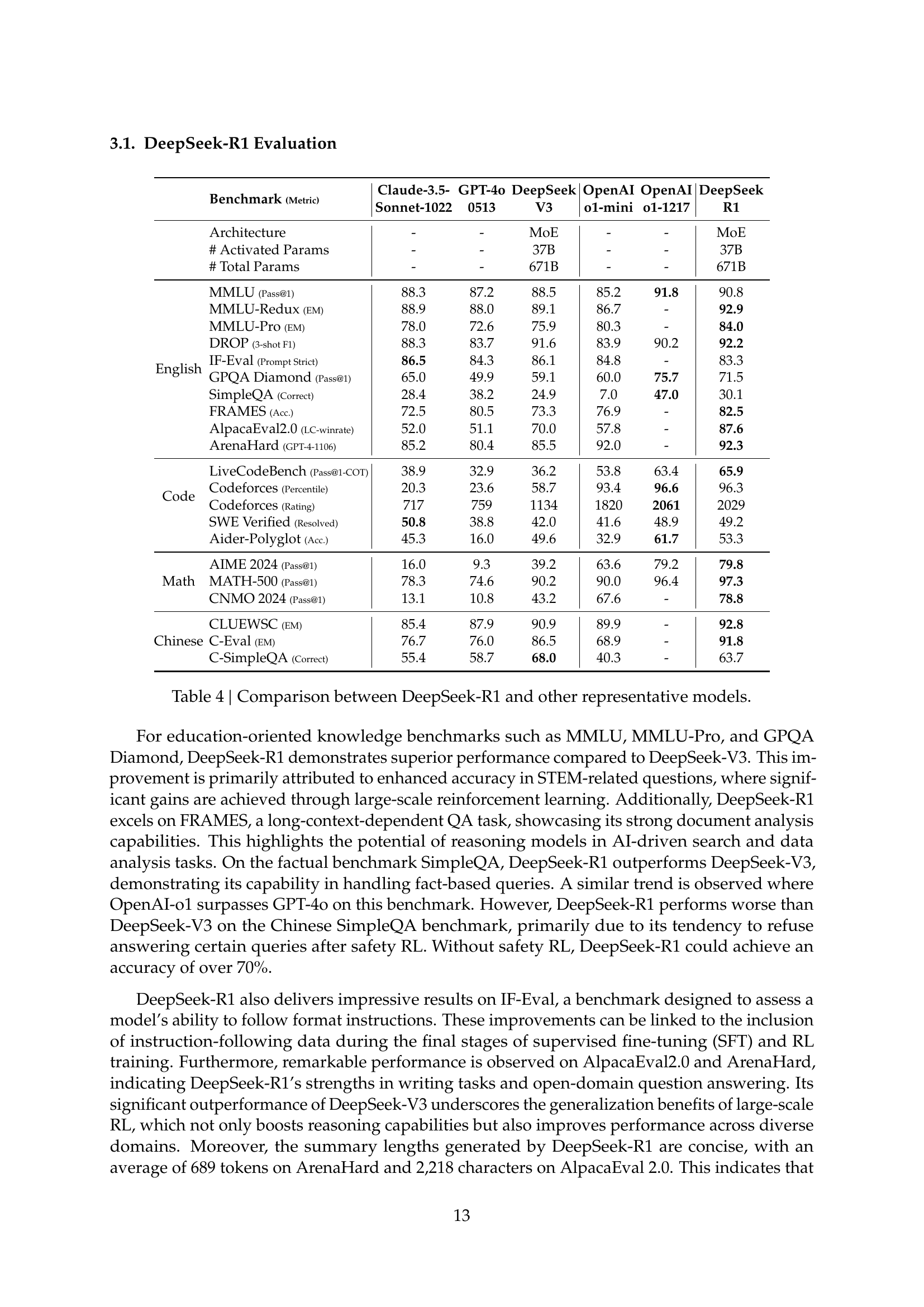
| Benchmark (Metric) | Claude-3.5- | GPT-4o | DeepSeek | OpenAI | OpenAI | DeepSeek | ||
| Sonnet-1022 | 0513 | V3 | o1-mini | o1-1217 | R1 | |||
| Architecture | - | - | MoE | - | - | MoE | ||
| # Activated Params | - | - | 37B | - | - | 37B | ||
| # Total Params | - | - | 671B | - | - | 671B | ||
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 | |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | 92.9 | ||
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | 84.0 | ||
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 | ||
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | - | 83.3 | ||
| GPQA Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 | ||
| SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 | ||
| FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | 82.5 | ||
| AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 | ||
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | ||
| Code | LiveCodeBench (Pass@1-COT) | 38.9 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 | |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | ||
| Codeforces (Rating) | 717 | 759 | 1134 | 1820 | 2061 | 2029 | ||
| SWE Verified (Resolved) | 50.8 | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 | ||
| Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | 61.7 | 53.3 | ||
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 | |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | ||
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | 78.8 | ||
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 | |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | ||
| C-SimpleQA (Correct) | 55.4 | 58.7 | 68.0 | 40.3 | - | 63.7 |
🔼 Table 4 presents a comprehensive comparison of DeepSeek-R1’s performance against several other prominent large language models (LLMs) across a diverse range of benchmark tasks. These benchmarks encompass various domains, including reasoning, coding, knowledge, and general language understanding. The table allows for a direct comparison of DeepSeek-R1’s capabilities with existing models, highlighting its strengths and weaknesses in different areas. The metrics used in the comparison are tailored to the specific nature of each benchmark, providing a nuanced and detailed evaluation of the models’ overall performance.
read the caption
Table 4: Comparison between DeepSeek-R1 and other representative models.
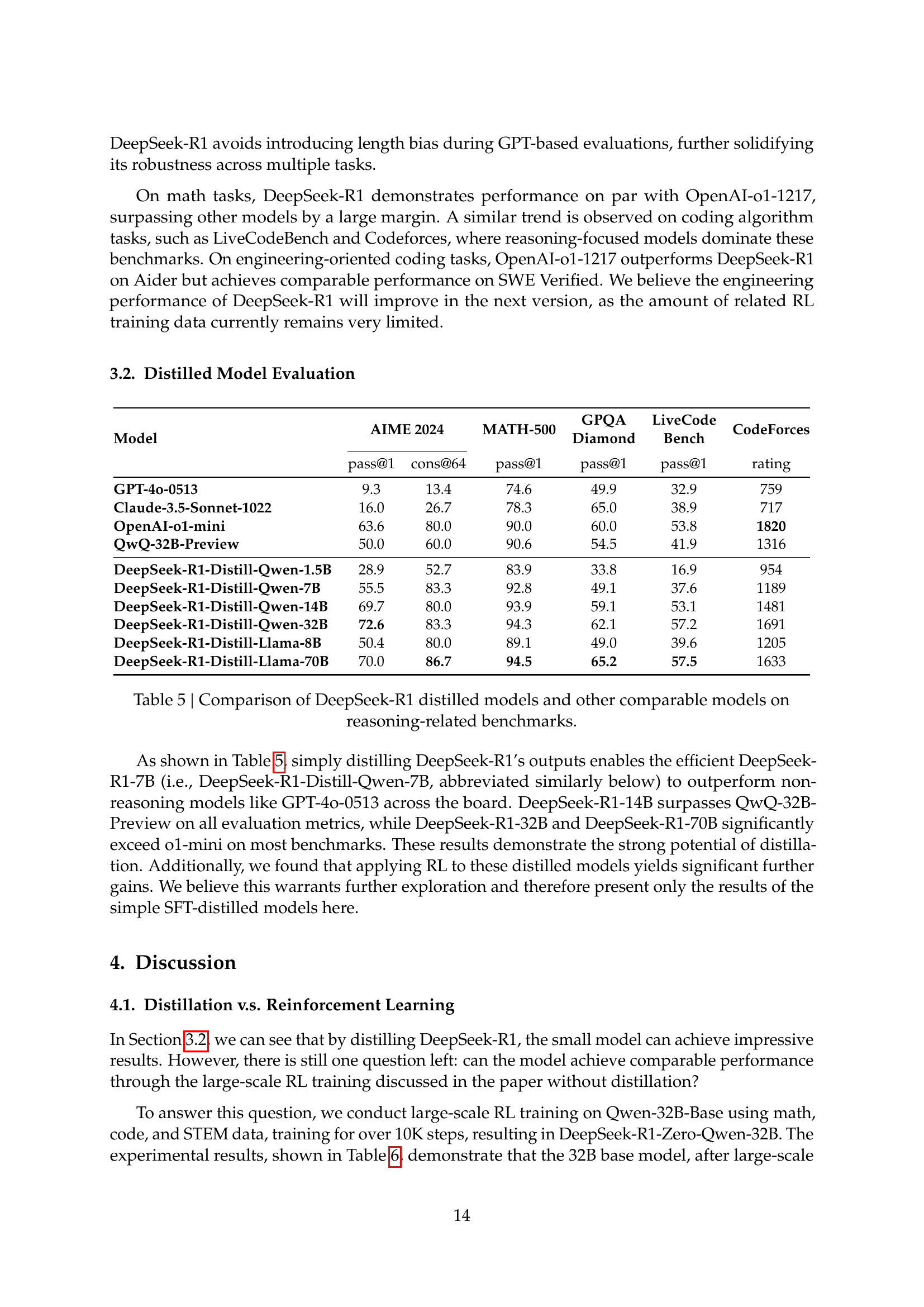
| Model | AIME 2024 | MATH-500 | GPQA | LiveCode | CodeForces | |
| Diamond | Bench | |||||
| pass@1 | cons@64 | pass@1 | pass@1 | pass@1 | rating | |
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 50.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
🔼 This table presents a comparison of the performance of several models, including DeepSeek-R1’s distilled versions (smaller models trained using knowledge from the larger DeepSeek-R1 model) and other comparable models, across multiple reasoning-related benchmarks. The benchmarks assess performance on tasks such as solving math problems, coding challenges, and answering questions requiring reasoning. The results show the pass@1 accuracy (the percentage of times the model gave the correct answer on its first attempt) and other relevant metrics, allowing for a direct comparison of the reasoning capabilities of various models, highlighting the relative effectiveness of knowledge distillation in creating smaller, yet still powerful, reasoning models.
read the caption
Table 5: Comparison of DeepSeek-R1 distilled models and other comparable models on reasoning-related benchmarks.
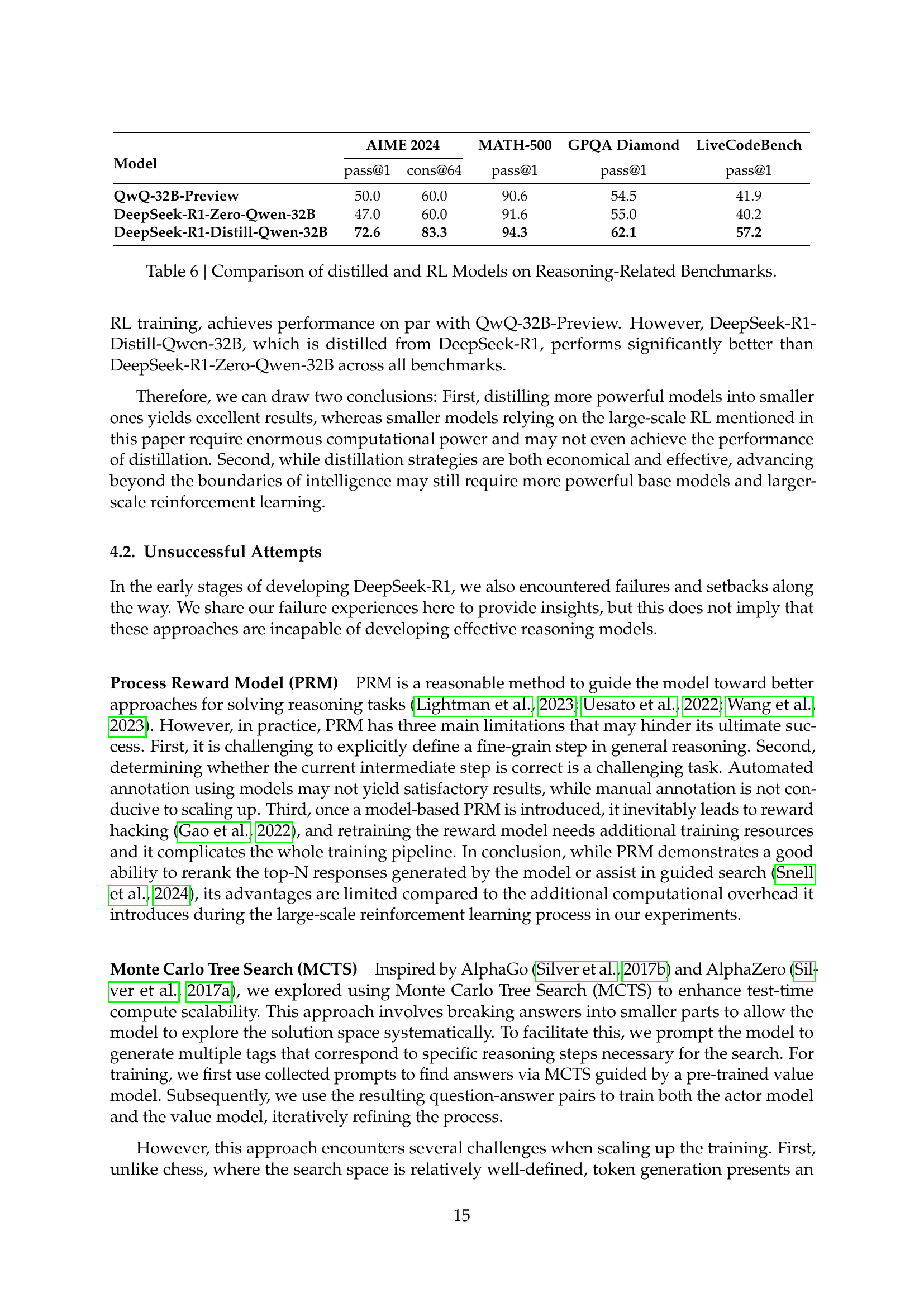
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCodeBench | |
|---|---|---|---|---|---|
| pass@1 | cons@64 | pass@1 | pass@1 | pass@1 | |
| QwQ-32B-Preview | 50.0 | 60.0 | 90.6 | 54.5 | 41.9 |
| DeepSeek-R1-Zero-Qwen-32B | 47.0 | 60.0 | 91.6 | 55.0 | 40.2 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 |
🔼 This table compares the performance of three different model types on several reasoning-related benchmarks. The first is a QwQ-32B-Preview model, which serves as a baseline. The second model is DeepSeek-R1-Zero-Qwen-32B, which was trained using large-scale reinforcement learning (RL) on a 32B parameter Qwen model. The third model, DeepSeek-R1-Distill-Qwen-32B, was created by distilling the knowledge from the larger DeepSeek-R1 model into a smaller 32B Qwen model. The benchmarks assess reasoning capabilities across a variety of tasks, and the results demonstrate that distillation, in this case, outperforms pure reinforcement learning, achieving significantly better results than the model trained exclusively through RL.
read the caption
Table 6: Comparison of distilled and RL Models on Reasoning-Related Benchmarks.
Full paper#