TL;DR#
Current multimodal large language models (MLLMs) struggle with video understanding due to the complexity of temporal dynamics and scarcity of high-quality video-text datasets. Many existing models focus on directly handling video data, often resulting in lower efficiency and performance. The high cost and difficulty of creating large, high-quality video datasets also hinder progress. This paper introduces a novel solution by prioritizing high-quality image data during training. By leveraging the strong foundation of image understanding, VideoLLaMA3 successfully extends its capabilities to video, overcoming many challenges associated with direct video processing.
The researchers developed VideoLLaMA3, a novel multimodal foundation model, using a vision-centric training paradigm and framework. This involved four stages: Vision Encoder Adaptation, Vision-Language Pretraining, Multi-task Fine-tuning, and Video-centric Fine-tuning. Key techniques include Any-resolution Vision Tokenization (AVT) and Differential Frame Pruner (DiffFP) to efficiently handle varied video resolutions and compress redundant frames. The model achieved state-of-the-art results on various benchmarks, showing strong performance in image, video, and document understanding.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents VideoLLaMA3, a significant advancement in multimodal foundation models. Its vision-centric approach offers a novel training paradigm and framework design, leading to state-of-the-art performance on various image and video understanding benchmarks. This work is relevant to current research trends in large language models and opens avenues for improving video understanding and developing more efficient and powerful multimodal AI systems.
Visual Insights#

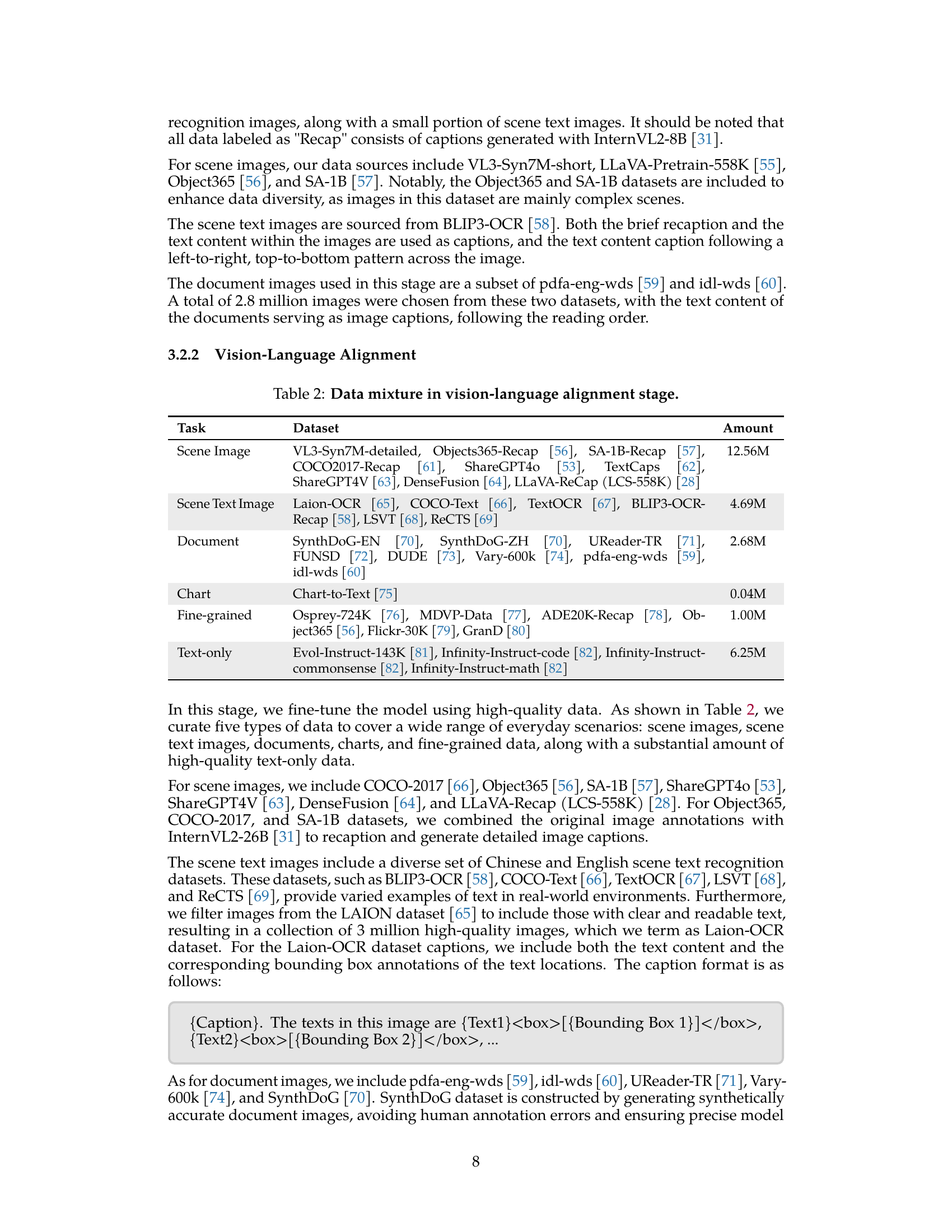
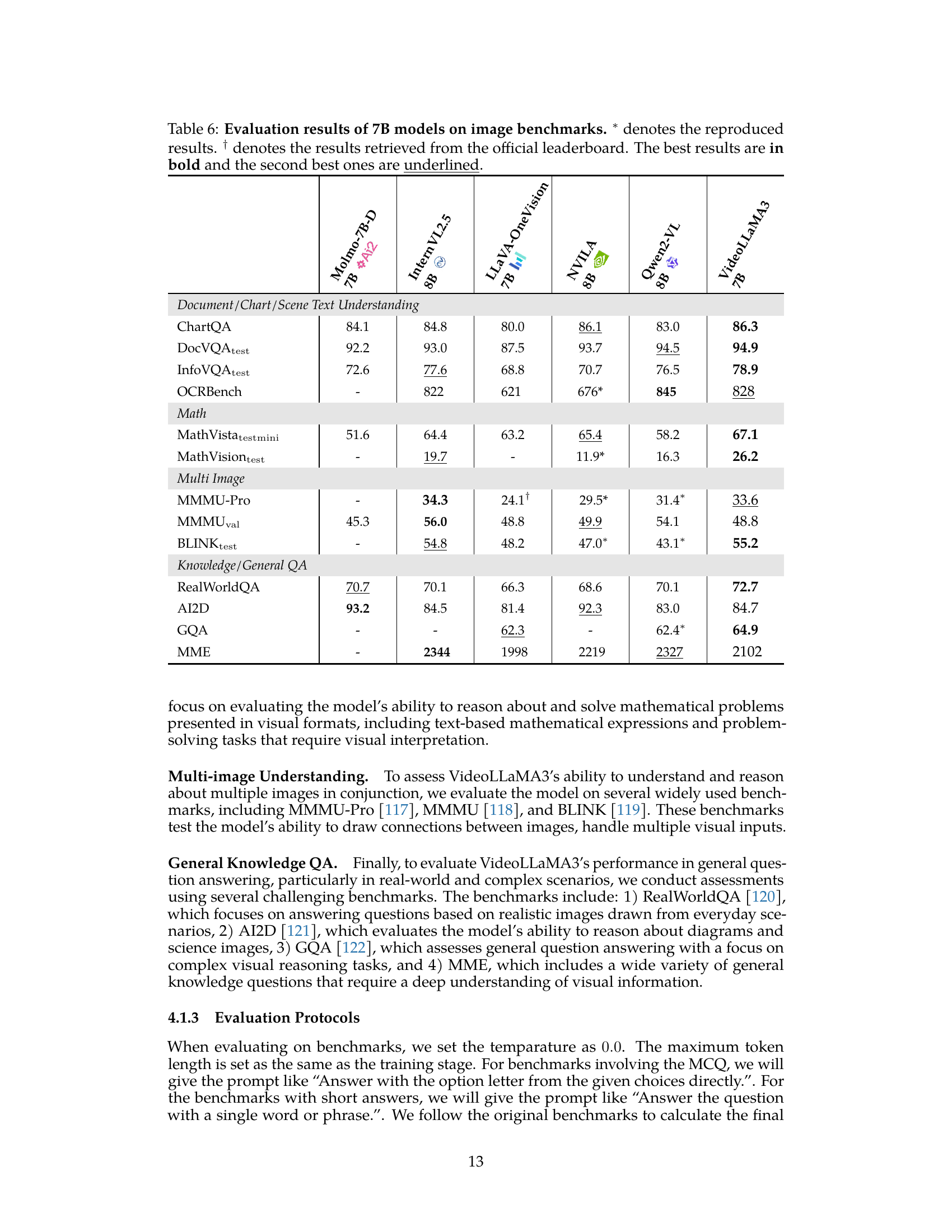
🔼 This figure compares the performance of VideoLLaMA3 against other state-of-the-art image and video Multimodal Large Language Models (MLLMs) across a variety of benchmark datasets. These benchmarks test different capabilities, including general video understanding (VideoMME, PerceptionTest, MLVU), document comprehension (DocVQA), and mathematical reasoning (MathVista). The results show that VideoLLaMA3 achieves highly competitive performance across all categories. Importantly, the figure notes that two specific models, LLaVA-OneVision and LLaVA-Video, were only used for evaluating image and video benchmarks, respectively, due to their specialized nature.
read the caption
Figure 1: Performance Comparison of VideoLLaMA3 with the previous advanced image/video MLLM on various representative benchmarks. As shown in the figure, VideoLLaMA3 has achieved very competitive results on various benchmarks. Specifically, VideoLLaMA3 not only demonstrates strong video understanding capabilities (VideoMME, PerceptionTest, MLVU) but also maintains excellent document comprehension abilities (DocVQA) and multimodal mathematical reasoning skills (MathVista). Note that LLaVA-OneVision is only used for evaluating image benchmarks, while LLaVA-Video is only used for evaluating video benchmarks.
| Task | Dataset | Amount |
| Scene Image | VL3-Syn7M-short, LLaVA-Pretrain-558k (liu2023improvedllava, ), Objects365-Recap (Objects365, ), SA-1B-Recap (kirillov2023segment, ) | 11.84M |
| Scene Text Image | BLIP3-OCR-Recap (Xue2024xGenMMA, ) | 0.93M |
| Document | pdfa-eng-wds (pdfa, ), idl-wds idlwds | 2.80M |
🔼 Table 1 details the composition of the training dataset used in the Vision Encoder Adaptation stage of the VideoLLaMA3 model training. It shows the different types of data used (Scene Image, Scene Text Image, and Document), their respective sources (datasets), and the total amount of data samples for each category. This stage focuses on adapting the vision encoder to handle images of varying resolutions, aligning the visual feature space with the language model.
read the caption
Table 1: Data mixture in vision encoder adaptation stage.
In-depth insights#
Vision-Centric Paradigm#
A vision-centric paradigm in multimodal learning prioritizes high-quality image-text data for foundational model training. This contrasts with approaches that directly leverage often-noisy video-text data, which is more challenging to collect and annotate. By focusing initially on robust image understanding, the model acquires strong visual representation capabilities that are then efficiently adapted for video processing. This staged approach simplifies training, improves data efficiency, and potentially leads to superior video understanding compared to methods that tackle both image and video jointly from the start. The core idea hinges on the observation that video is essentially a sequence of correlated images, making strong image representation a crucial prerequisite for effective video understanding. A successful vision-centric model demonstrates excellence in both image and video understanding benchmarks, validating the strategy’s efficacy. The vision-centric framework also often includes architectural adaptations, such as dynamic resolution handling for images and temporal compression for videos, maximizing both performance and data efficiency.
Multi-Stage Training#
Multi-stage training in large language models (LLMs) offers a structured approach to learning, enhancing performance and capabilities incrementally. Each stage often focuses on a specific aspect of the model’s development, such as vision encoder adaptation, vision-language alignment, and multi-task fine-tuning, each utilizing specific datasets and optimization strategies. This allows for gradual refinement and avoids the potential pitfalls of overwhelming the model with too much complexity at once. Vision-centric training paradigms, prioritizing high-quality image-text data, have proven beneficial for boosting both image and video understanding. By focusing on a strong foundation in image understanding, the model’s subsequent performance on video tasks improves significantly. The model’s architecture could be gradually enhanced by incorporating different types of vision and language data in different stages. This iterative process facilitates improved generalization and adaptability. The inclusion of a video compressor reduces computational demands and improves the efficiency and precision of video representation, improving performance in video understanding tasks. The multi-stage approach allows for flexibility and the possibility of adapting to various types of multimodal datasets.
AVT & DiffFP#
The proposed AVT (Any-resolution Vision Tokenization) and DiffFP (Differential Frame Pruner) are crucial for efficient and effective multimodal processing in VideoLLaMA3. AVT addresses the limitations of fixed-resolution tokenization by dynamically adapting to various image and video resolutions, ensuring detailed visual information capture regardless of input size. This adaptability significantly improves the model’s flexibility and reduces information loss compared to traditional methods. DiffFP enhances video processing efficiency by compressing videos through frame pruning, removing redundant information between temporally adjacent frames. By focusing on significant changes, it optimizes computational resources and makes processing long videos more manageable. The synergy of AVT and DiffFP is key to VideoLLaMA3’s superior performance, enabling it to handle diverse visual inputs and complex temporal dynamics more effectively. This vision-centric design contributes to reduced model size and improved efficiency while retaining high accuracy in both image and video understanding tasks.
High-Quality Dataset#
Creating a high-quality dataset is crucial for training robust and effective multimodal models. The quality of the data directly impacts the model’s performance and ability to generalize. High-resolution images and precise annotations are essential. The dataset should also be diverse, representing a wide range of scenarios and visual concepts. Data cleaning and filtering are vital steps to eliminate noise and inaccuracies which could hinder the model’s learning process. Careful selection of data sources is another critical aspect; reliable sources are necessary to minimize biases. The size of the dataset is important, but high quality trumps quantity; it is preferable to have a smaller, cleaner dataset than a large one with significant noise. Finally, the design of the dataset needs to match the training paradigm, ensuring that the data is well-suited to the chosen model architecture and learning method for optimal effectiveness.
Future Research#
The paper’s ‘Future Research’ section would ideally address several key limitations. Improving video data quality and diversity is paramount, necessitating a focus on larger, higher-quality datasets with richer annotations. This would likely involve exploring new data acquisition and annotation methods, potentially leveraging automated techniques and crowdsourcing. Addressing the computational cost of real-time video processing is crucial for practical applications. This requires exploring efficient model architectures and optimized inference strategies, perhaps drawing upon techniques like model quantization and pruning. Extending the model’s capabilities to handle unseen modalities, such as audio and speech, would greatly enhance its versatility and real-world applicability. A focus on efficient multi-modal fusion techniques is key here. Finally, developing advanced post-training techniques is essential to further refine the model’s performance and align it with human preferences, potentially through reinforcement learning and human-in-the-loop approaches.
More visual insights#
More on figures

🔼 This figure illustrates the four-stage training pipeline of the VideoLLaMA3 model. Stage 1, Vision Encoder Adaptation, focuses on aligning the vision encoder with the language model using various image data to handle different resolutions. Stage 2, Vision-Language Alignment, jointly tunes the vision encoder, projector, and language model using large-scale image-text data. Stage 3, Multi-task Fine-tuning, incorporates data for downstream tasks and video-text data to establish a foundation for video understanding. Finally, Stage 4, Video-centric Fine-tuning, further improves the model’s video understanding capabilities by including more video data.
read the caption
Figure 2: Training paradigm of VideoLLaMA3. The training of VideoLLaMA3 has four stages: (1) Vision Encoder Adaptation, (2) Vision-Language Alignment, (3) Multi-task Fine-tuning, and (4) Video-centric Fine-tuning.

🔼 VideoLLaMA3 processes image and video inputs using a two-stage pipeline. First, Any-Resolution Vision Tokenization (AVT) converts images/videos of any resolution into 1D token sequences, which allows for flexible input sizes. Then, the Differential Frame Pruner (DiffFP) acts as a video compressor, removing redundant frames in videos to improve efficiency, particularly for long videos. This process ultimately feeds the information into a large language model for multimodal understanding.
read the caption
Figure 3: The overall pipeline of our VideoLLaMA3. There are two key technical points: ❶ Any-resolution Vision Tokenization (AVT): AVT converts images or videos of any resolution into a set of 1-D token sequences, enabling compatibility with varying amounts of input images and videos of different resolutions, thereby supporting more flexible vision input; ❷ Differential Frame Pruner (DiffFP): Serving as a video compressor, DiffFP eliminates video content with minimal differences between adjacent frames. This approach enhances video processing efficiency, particularly for long-form videos.

🔼 The figure illustrates the process of Differential Frame Pruning (DiffFP), a video compression technique. DiffFP analyzes video frames by comparing patches (small regions) between consecutive frames. The distance between these patches in pixel space is calculated (using 1-norm distance). Patches with small distances, representing high similarity and minimal changes between frames, are pruned (removed). This reduces the number of tokens used to represent the video, making video processing more efficient, especially for long videos with lots of redundant information. The output is a more compact and efficient representation of the video.
read the caption
Figure 4: The calculation flow of our DiffFP. We prune video tokens based on patch similarities in pixel space, removing patches with smaller distances to the previous frame.

🔼 Figure 5 illustrates how different data types (image sequences, video sequences, and streaming video sequences) are formatted for input into the VideoLLaMA3 model. Different symbols are used to delineate various aspects of the data. For image sequences, a newline character (’\n’) separates tokens representing different images. Video sequences use ‘Time: xxs’ to mark timestamps for each frame, commas (’,’) to separate frames, and newlines (’\n’) to distinguish between videos. Lastly, streaming video sequences organize video and text tokens in an interleaved structure.
read the caption
Figure 5: Data formats for different data types. ❶ For image sequence, we use '\n' to separate image tokens from different image; ❷ For video sequence, we use 'Time: xxs' to indicate timestamps of each frame, ',' to separate different frames, and '\n' to separate tokens from different videos; ❸ For streaming video sequence, videos and texts are organized in an interleaved format.

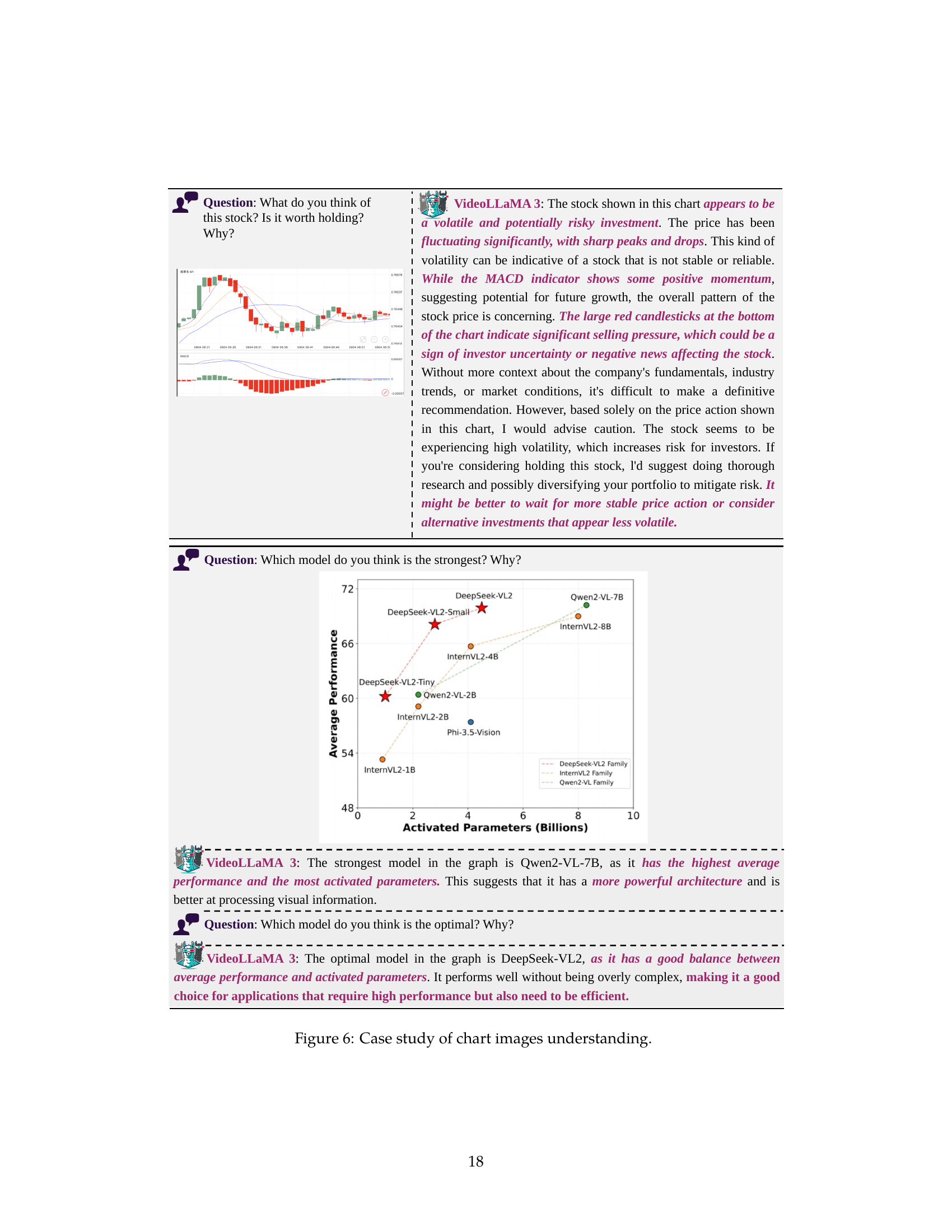
🔼 This figure showcases two examples of VideoLLaMA3’s chart image understanding capabilities. The first example demonstrates the model’s ability to analyze stock trends and provide investment advice based on the visual information presented in a stock chart. The second example shows VideoLLaMA3 comparing the performance of different large language models (LLMs) based on a chart displaying their average performance and number of parameters. This highlights the model’s ability to extract and interpret quantitative information from chart visualizations.
read the caption
Figure 6: Case study of chart images understanding.

🔼 This figure showcases two examples demonstrating VideoLLaMA 3’s capabilities in Optical Character Recognition (OCR) and understanding document images. The first example shows the model successfully extracting and interpreting text from a design image, offering suggestions for improvement. The second example demonstrates the model’s ability to accurately perform OCR on a more complex, dense document image.
read the caption
Figure 7: Case study of OCR and document images.

🔼 This figure showcases VideoLLaMA3’s capacity for multi-image understanding through three distinct examples. The first demonstrates the model’s ability to differentiate between two bird species based on visual features. The second example highlights the model’s comprehension of complex visual and textual information within a document, surpassing basic OCR capabilities by extracting answers from a document containing multiple images. The final example illustrates VideoLLaMA3’s understanding of narratives presented in a comic strip format, demonstrating the model’s capacity for storytelling and contextual comprehension.
read the caption
Figure 8: Case study of multi-image understanding.

🔼 This figure showcases three examples where the VideoLLaMA3 model demonstrates its ability to understand images within the context of general knowledge. The first example involves a basketball free throw, illustrating the model’s grasp of sports imagery and terminology. The second shows the Mona Lisa, highlighting its understanding of art history and cultural significance. The last displays a space-themed video with puppies in astronaut suits, and shows how the model can describe the video. Each example demonstrates VideoLLaMA3’s comprehensive understanding beyond simple image recognition and its capacity to connect images to broader contextual information.
read the caption
Figure 9: Case study of images with general knowledge.

🔼 Figure 10 presents several case studies showcasing VideoLLaMA3’s video understanding capabilities. Each case study demonstrates the model’s ability to handle various tasks including identifying objects within a video and their positions, recognizing the last key to disappear on a keyboard, identifying unusual aspects (like bears eating sushi), detailing video contents, and understanding video competitions.
read the caption
Figure 10: Case study of video understanding.

🔼 Figure 11 showcases VideoLLaMA 3’s capabilities in handling complex video understanding tasks. It presents three examples demonstrating the model’s proficiency in long video understanding, temporal grounding, and video-image joint understanding. The first example involves describing a long video; the second shows temporal grounding by identifying specific timestamps within a video when an action occurs; and the third example demonstrates joint understanding by connecting a video clip with a separate image.
read the caption
Figure 11: Case study of long video understanding, temporal grounding, and video-image joint understanding.
More on tables
| Task | Dataset | Amount |
| Scene Image | VL3-Syn7M-detailed, Objects365-Recap (Objects365, ), SA-1B-Recap (kirillov2023segment, ), COCO2017-Recap (lin2014microsoft, ), ShareGPT4o (Chen2024HowFA, ), TextCaps (sidorov2020textcaps, ), ShareGPT4V (chen2023sharegpt4v, ), DenseFusion (li2024densefusion, ), LLaVA-ReCap (LCS-558K) (li2024llavaonevision, ) | 12.56M |
| Scene Text Image | Laion-OCR (schuhmann2022laion, ), COCO-Text (veit2016coco, ), TextOCR (singh2021textocr, ), BLIP3-OCR-Recap (Xue2024xGenMMA, ), LSVT (Sun2019ICDAR2C, ), ReCTS (liu2019icdar, ) | 4.69M |
| Document | SynthDoG-EN (kim2022ocr, ), SynthDoG-ZH (kim2022ocr, ), UReader-TR (Ye2023UReaderUO, ), FUNSD (funsd, ), DUDE (van2023icdar, ), Vary-600k (wei2023vary, ), pdfa-eng-wds (pdfa, ), idl-wds (idlwds, ) | 2.68M |
| Chart | Chart-to-Text (2022Chart, ) | 0.04M |
| Fine-grained | Osprey-724K (yuan2024osprey, ), MDVP-Data (lin2024draw, ), ADE20K-Recap (zhou2019semantic, ), Object365 (Objects365, ), Flickr-30K (young2014image, ), GranD (rasheed2024glamm, ) | 1.00M |
| Text-only | Evol-Instruct-143K (chen2024allava, ), Infinity-Instruct-code (InfinityInstruct2024, ), Infinity-Instruct-commonsense InfinityInstruct2024 , Infinity-Instruct-math (InfinityInstruct2024, ) | 6.25M |
🔼 This table details the composition of the training dataset used in the Vision-Language Alignment stage of the VideoLLaMA3 model training. It breaks down the dataset by the type of data included (Scene Image, Scene Text Image, Document, Chart, Fine-grained, and Text-only) and the amount of data for each type. This breakdown helps to understand the balance of different data modalities used to train the model to effectively link visual and linguistic information.
read the caption
Table 2: Data mixture in vision-language alignment stage.
| Task | Dataset | Amount |
| Image & Text Data | ||
| General | LLaVA-SFT-665K (li2024llava, ), LLaVA-OV-SI (li2024llavaonevision, ), Cambrian-cleaned (tong2024cambrian, ), Pixmo (docs, cap, points, cap-qa, ask-model-anything) (molmo2024, ) | 9.87M |
| Document | DocVQA (mathew2021docvqadatasetvqadocument, ), Docmatix (laurençon2024building, ) | 1.31M |
| Chart/Figure | ChartQA (masry2022chartqa, ), MMC_Instruction (liu2023mmc, ), DVQA (kafle2018dvqa, ), LRV_Instruction (liu2023aligning, ), ChartGemma (masry2024chartgemmavisualinstructiontuningchart, ), InfoVQA (mathew2022infographicvqa, ), PlotQA (methani2020plotqa, ) | 1.00M |
| OCR | MultiUI (liu2024harnessingwebpageuistextrich, ), in-house data | 0.83M |
| Grounding | RefCoco (kazemzadeh2014referitgame, ), VCR (zellers2019vcr, ), in-house data | 0.50M |
| Multi-Image | Demon-Full (li2024fine, ), Contrastive_Caption (jiang2024mantisinterleavedmultiimageinstruction, ) | 0.41M |
| Text-only | Magpie (xu2024magpie, ), Magpie-Pro (xu2024magpie, ), Synthia (Synthia-70B-v1.2, ), Infinity-Instruct-subjective (InfinityInstruct2024, ), NuminaMath (li2024numinamath, ) | 2.21M |
| Video Data | ||
| General | LLaVA-Video-178K (zhang2024video, ), ShareGPT4o-Video (chen2024sharegpt4video, ), FineVideo (Farré2024FineVideo, ), CinePile (rawal2024cinepile, ), ShareGemini-k400 (sharegemini, ), ShareGemini-WebVID (sharegemini, ), VCG-Human (Maaz2024VideoGPT+, ), VCG-Plus (Maaz2024VideoGPT+, ), VideoLLaMA2 in-house data, Temporal Grounding in-house data | 2.92M |
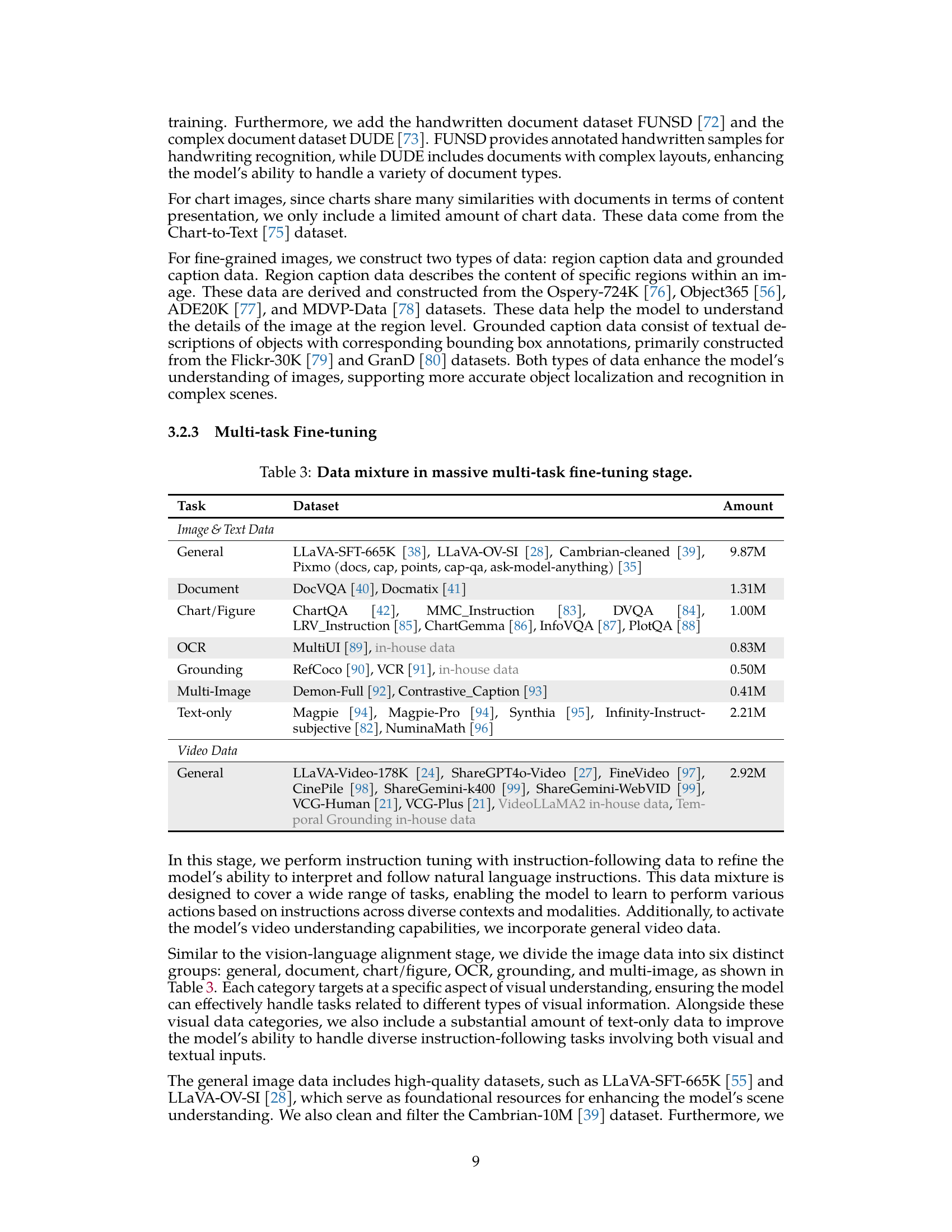
🔼 This table details the composition of the training data used in the Multi-task Fine-tuning stage of the VideoLLaMA3 model. It breaks down the dataset into categories (General, Document, Chart/Figure, OCR, Grounding, Multi-Image, and Text-only), listing the specific datasets used within each category and the amount of data in each. This stage focuses on preparing the model for downstream tasks by exposing it to a wide variety of image and text-based tasks.
read the caption
Table 3: Data mixture in massive multi-task fine-tuning stage.
| Task | Dataset | Amount |
| General Video | LLaVA-Video-178K (zhang2024video, ), ShareGPT4o-Video (chen2024sharegpt4video, ), FineVideo (Farré2024FineVideo, ), CinePile (rawal2024cinepile, ), ShareGemini-k400 (sharegemini, ), ShareGemini-WebVID (sharegemini, ), VCG-Human (Maaz2024VideoGPT+, ), VCG-Plus (Maaz2024VideoGPT+, ), VideoRefer (yuan2024videorefer, ), VideoLLaMA2 in-house data, In-house synthetic data | 3.03M |
| Streaming Video | ActivityNet (krishna2017dense, ), YouCook2 (zhou2018towards, ), Ego4D-narration (grauman2022ego4d, ), Ego4D-livechat (chen2024videollm, ) | 36.2K |
| Temporal Grounding | ActivityNet (krishna2017dense, ), YouCook2 (zhou2018towards, ), ViTT (huang2020multimodal, ), QuerYD (oncescu2021queryd, ), HiREST (zala2023hierarchical, ), Charades-STA (gao2017tall, ), Moment-10M (qian2024momentor, ), COIN (tang2019coin, ) | 0.21M |
| Image-only | LLaVA-SFT-665K (li2024llava, ), LLaVA-OV-SI (li2024llavaonevision, ) | 0.88M |
| Text-only | Magpie (xu2024magpie, ), Tulu 3 (lambert2024tulu3, ) | 1.56M |
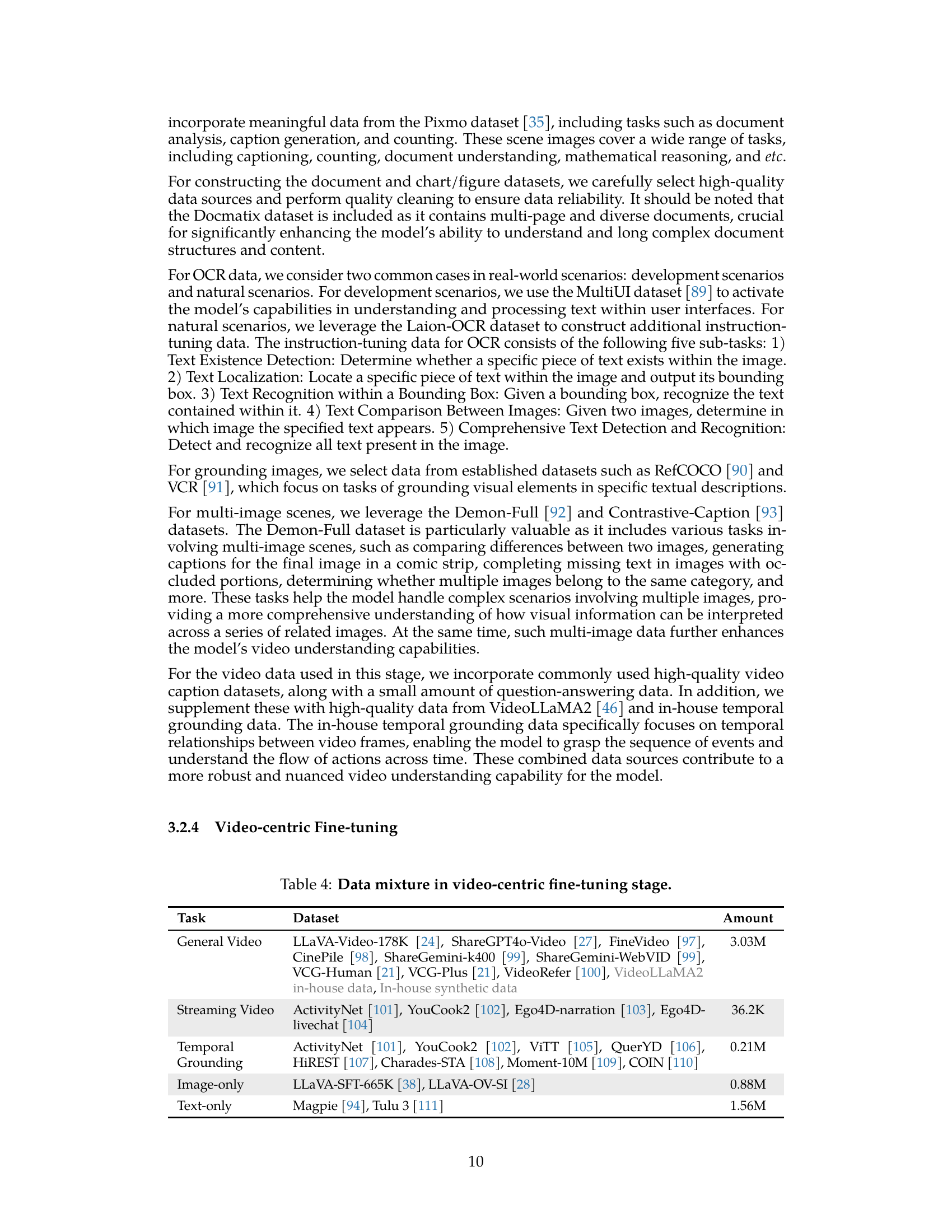
🔼 This table details the composition of the training dataset used in the Video-centric Fine-tuning stage of the VideoLLaMA3 model training. It breaks down the data by task type (General Video, Streaming Video, Temporal Grounding, Image-only, Text-only) and lists the specific datasets used for each. This stage focuses on enhancing video understanding capabilities, and the data mixture reflects this emphasis.
read the caption
Table 4: Data mixture in video-centric fine-tuning stage.
| | | | VideoLLaMA3 2B | |
| Document/Chart/Scene Text Understanding | ||||
| ChartQA | 65.3* | 79.2 | 73.5 | 79.8 |
| DocVQAtest | 81.6 | 88.7 | 90.1 | 91.9 |
| InfoVQAtest | - | 60.9 | 65.5 | 69.4 |
| OCRBench | 622* | 804 | 767∗ | 779 |
| Math | ||||
| MathVistatestmini | 44.6 | 51.3 | 43.0 | 59.2 |
| MathVisiontest | 6.5* | 14.7 | 12.4 | 15.5 |
| Multi Image | ||||
| MMMU-Pro | 17.1* | 23.7 | 26.0 | 28.6 |
| MMMUval | 38.8 | 43.6 | 41.1 | 45.3 |
| BLINKtest | 42.3* | 44.0 | 43.1∗ | 44.2 |
| Knowledge/General QA | ||||
| RealWorldQA | 48.8* | 60.1 | 62.9 | 67.3 |
| AI2D | 62.1* | 74.9 | 69.9 | 78.2 |
| GQA | 49.2* | 59.5* | 59.8∗ | 62.7 |
| MME | 1600* | 2005∗ | 1872 | 1901 |
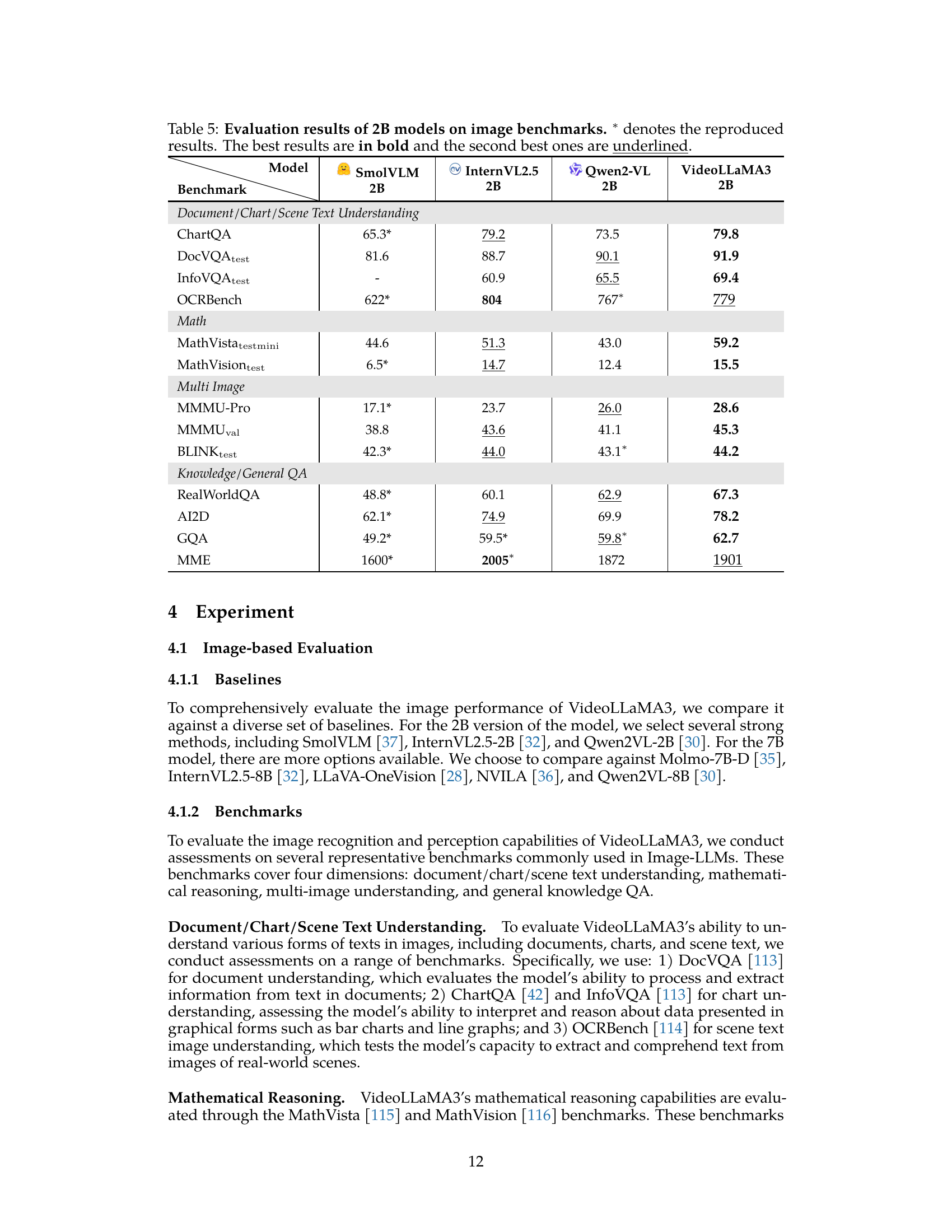
🔼 This table presents a comparison of the performance of several 2-billion parameter image LLMs on a variety of image understanding benchmarks. The models compared are SmolVLM, InternVL 2.5, Qwen2-VL, and VideoLLaMA3. The benchmarks cover document and chart understanding, mathematical reasoning, multi-image understanding, and general knowledge question answering. Results are presented as percentages, with the best result for each benchmark shown in bold and the second-best result underlined. Results marked with an asterisk (*) indicate that they were reproduced by the authors, rather than taken directly from the original benchmark’s leaderboard. This allows for a more consistent and fair comparison across models.
read the caption
Table 5: Evaluation results of 2B models on image benchmarks. ∗ denotes the reproduced results. The best results are in bold and the second best ones are underlined.
Molmo-7B-D
7B |
InternVL2.5
8B |
LLaVA-OneVision
7B |
NVILA
8B |
Qwen2-VL
8B | VideoLLaMA3 7B | |
| Document/Chart/Scene Text Understanding | ||||||
| ChartQA | 84.1 | 84.8 | 80.0 | 86.1 | 83.0 | 86.3 |
| DocVQAtest | 92.2 | 93.0 | 87.5 | 93.7 | 94.5 | 94.9 |
| InfoVQAtest | 72.6 | 77.6 | 68.8 | 70.7 | 76.5 | 78.9 |
| OCRBench | - | 822 | 621 | 676* | 845 | 828 |
| Math | ||||||
| MathVistatestmini | 51.6 | 64.4 | 63.2 | 65.4 | 58.2 | 67.1 |
| MathVisiontest | - | 19.7 | - | 11.9* | 16.3 | 26.2 |
| Multi Image | ||||||
| MMMU-Pro | - | 34.3 | 24.1† | 29.5* | 31.4∗ | 33.6 |
| MMMUval | 45.3 | 56.0 | 48.8 | 49.9 | 54.1 | 48.8 |
| BLINKtest | - | 54.8 | 48.2 | 47.0∗ | 43.1∗ | 55.2 |
| Knowledge/General QA | ||||||
| RealWorldQA | 70.7 | 70.1 | 66.3 | 68.6 | 70.1 | 72.7 |
| AI2D | 93.2 | 84.5 | 81.4 | 92.3 | 83.0 | 84.7 |
| GQA | - | - | 62.3 | - | 62.4∗ | 64.9 |
| MME | - | 2344 | 1998 | 2219 | 2327 | 2102 |
🔼 This table presents a comparison of the performance of several 7B parameter large language models (LLMs) on a variety of image-based benchmarks. The benchmarks assess capabilities in document/chart/scene text understanding, mathematical reasoning, multi-image understanding, and general knowledge question answering. Results are shown as percentages and are categorized by benchmark type. The table highlights the top-performing model for each task, indicating the best and second-best results using bold and underline formatting respectively. Some results denoted by ∗ are reproduced from other sources and some results denoted by † are from the official leaderboard. This allows readers to easily compare VideoLLaMA3’s performance against other state-of-the-art models in image understanding.
read the caption
Table 6: Evaluation results of 7B models on image benchmarks. ∗ denotes the reproduced results. † denotes the results retrieved from the official leaderboard. The best results are in bold and the second best ones are underlined.
| | | | VideoLLaMA3 2B | |
| General Video Understanding | ||||
| VideoMME w/o sub | 53.0 | 51.9 | 55.6 | 59.6 |
| VideoMME w/ sub | 54.6 | 54.1 | 60.4 | 63.4 |
| MMVUval | - | 33.6∗ | 36.5† | 39.9 |
| MVBench | - | 68.8 | 63.2 | 65.5 |
| EgoSchematest | - | 58.1∗ | 54.9 | 58.5 |
| PerceptionTesttest | 61.0 | 66.3∗ | 53.9 | 68.0 |
| ActivityNet-QA | - | 54.1∗ | 53.3∗ | 58.2 |
| Long Video Understanding | ||||
| MLVUdev | 63.3 | 58.9∗ | 62.7∗ | 65.4 |
| LongVideoBenchval | - | 52.0 | 48.7∗ | 57.1 |
| LVBench | - | 37.3∗ | 38.0∗ | 40.4 |
| Temporal Reasoning | ||||
| TempCompass | 60.8 | 57.7∗ | 62.2∗ | 63.4 |
| NextQA | - | 75.6∗ | 77.2∗ | 81.1 |
| Charades-STA | - | - | - | 55.5 |
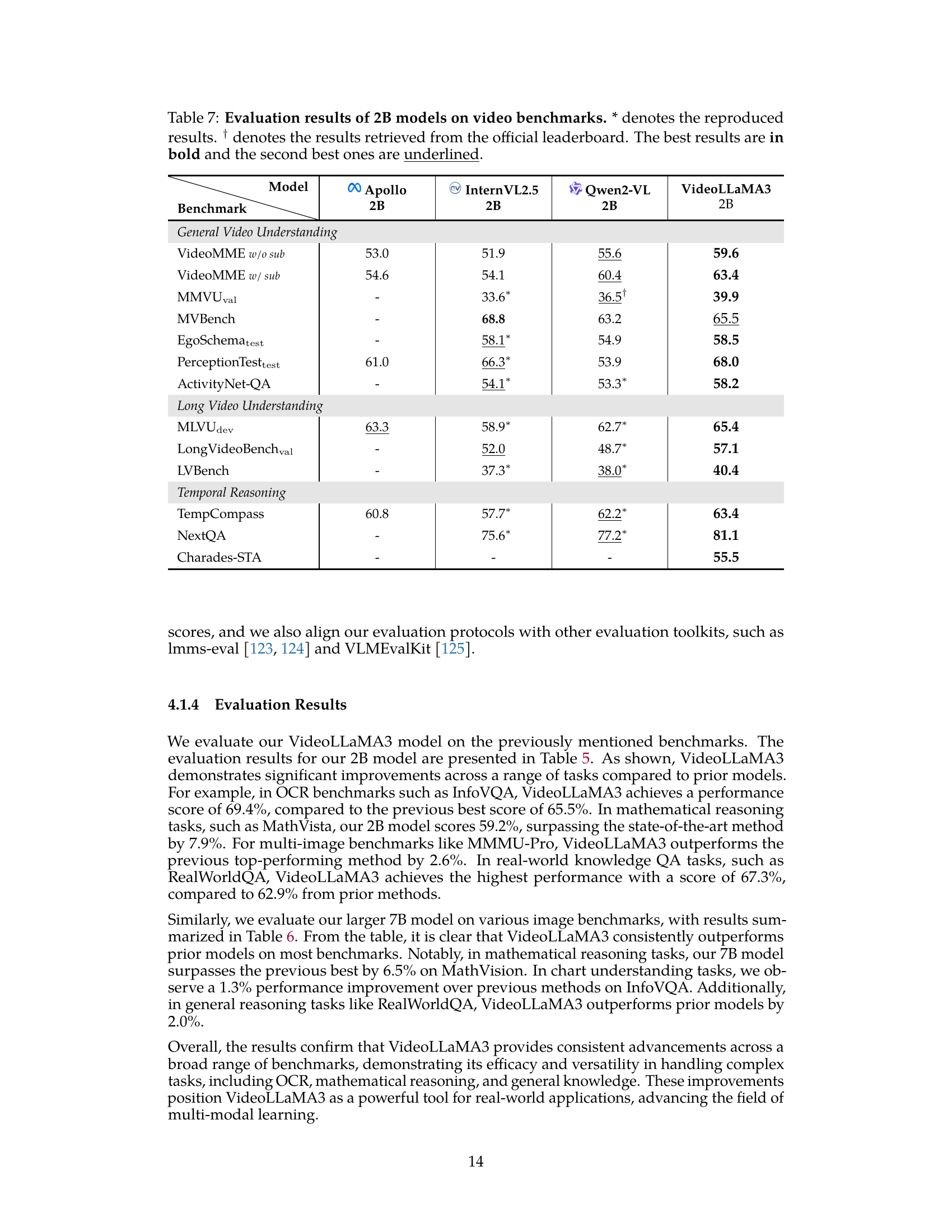
🔼 Table 7 presents a comparison of the performance of four different 2-billion parameter models on a range of video understanding benchmarks. The models are compared across various video understanding tasks, categorized into general video understanding, long video understanding, and temporal reasoning. For each task and model, the table shows the performance score, indicating the model’s accuracy or effectiveness. Results marked with ‘*’ represent reproduced results from existing studies, and those marked with ‘†’ were retrieved directly from the official leaderboard for the specific benchmark. The highest score for each task is highlighted in bold, and the second-highest score is underlined, providing clear visual indicators of the best-performing models and offering a clear ranking system for comparison across models and tasks. This allows for a direct and easy comparison of the different models’ capabilities across diverse video understanding scenarios.
read the caption
Table 7: Evaluation results of 2B models on video benchmarks. * denotes the reproduced results. † denotes the results retrieved from the official leaderboard. The best results are in bold and the second best ones are underlined.
Qwen2-VL
7B |
InternVL2.5
8B |
LLaVA-Video
7B |
NVILA
8B |
Apollo
7B | VideoLLaMA 2.1-7B | VideoLLaMA 3-7B | |
| General Video Understanding | |||||||
| VideoMME w/o sub | 63.3 | 64.2 | 63.3 | 64.2 | 61.3 | 54.9 | 66.2 |
| VideoMME w/ sub | 69.0 | 66.9 | 69.7 | 70.0 | 63.3 | 56.4 | 70.3 |
| MMVUval | 42.1† | 41.1† | 42.4∗ | 43.7∗ | - | 39.5† | 44.1 |
| MVBench | 67.0 | 72.0 | 58.6 | 68.1 | - | 57.3 | 69.7 |
| EgoSchematest | 66.7 | 66.2∗ | 57.3 | 54.3∗ | - | 53.1 | 63.3 |
| PerceptionTesttest | 62.3 | 68.9∗ | 67.9∗ | 65.4∗ | - | 54.9 | 72.8 |
| ActivityNet-QA | 57.4∗ | 58.9∗ | 56.5 | 60.9 | - | 53.0 | 61.3 |
| Long Video Understanding | |||||||
| MLVUdev | 69.8∗ | 69.0∗ | 70.8∗ | 70.6∗ | 70.9 | 57.4 | 73.0 |
| LongVideoBenchval | 55.6† | 60.0 | 58.2 | 57.7 | 58.5 | - | 59.8 |
| LVBench | 44.2∗ | 41.5∗ | 40.3∗ | 42.6∗ | - | 36.3 | 43.7 |
| Temporal Reasoning | |||||||
| TempCompass | 67.9† | 68.3∗ | 65.4 | 69.7∗ | 64.9 | 56.8 | 68.1 |
| NextQA | 81.2∗ | 85.0∗ | 83.2 | 82.2 | - | 75.6 | 84.5 |
| Charades-STA | - | - | - | - | - | - | 60.7 |
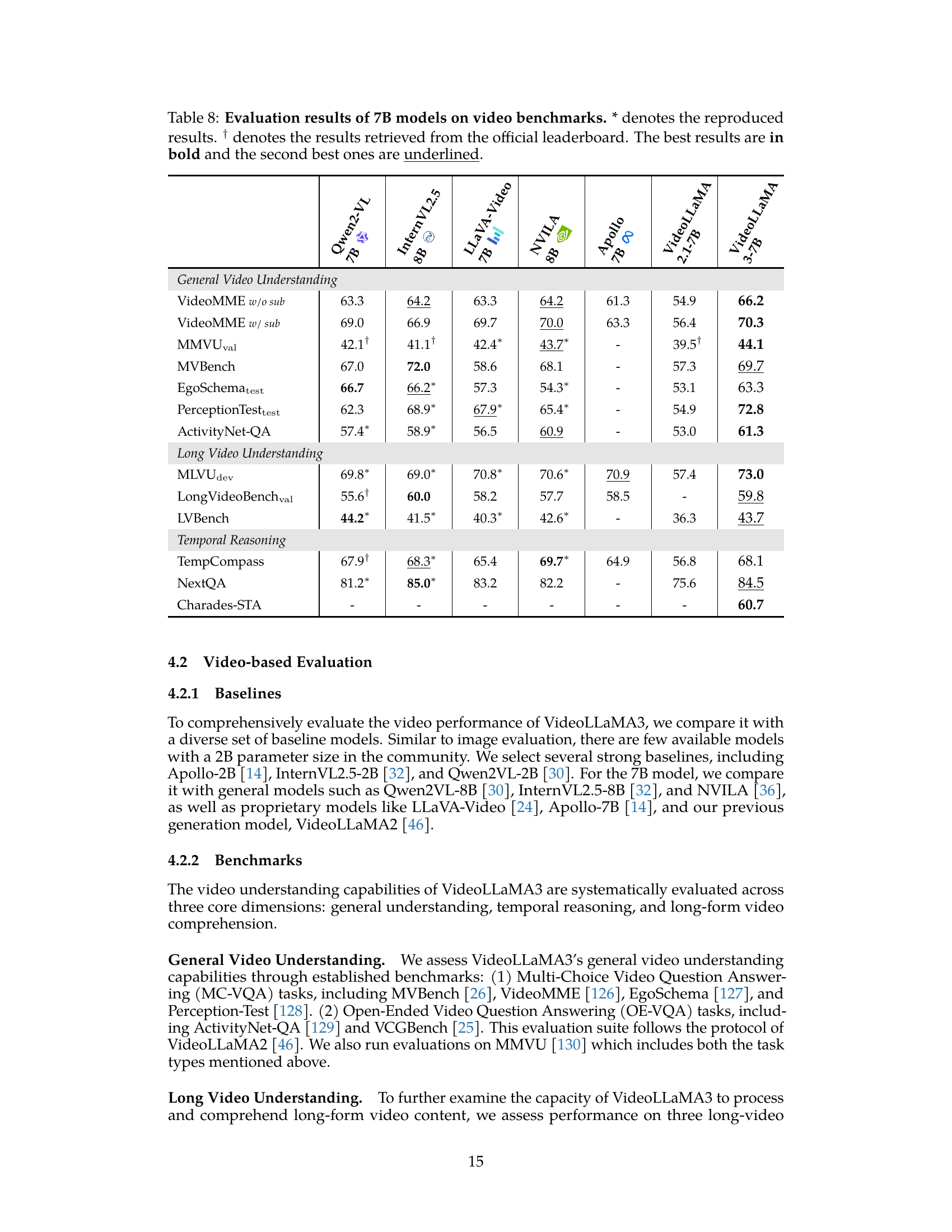
🔼 Table 8 presents a comparison of the performance of several 7B parameter multimodal large language models (MLLMs) on various video understanding benchmarks. The benchmarks are categorized into three key areas: general video understanding, long video understanding, and temporal reasoning. The table displays the scores achieved by each model on each benchmark. The scores reflect the models’ abilities to understand and respond to various tasks involving video data, including question answering, caption generation, and temporal reasoning. Reproduced results are marked with an asterisk (*), while results from official leaderboards are indicated with a dagger (†). The highest score for each benchmark is shown in bold, with the second-highest score underlined. This allows for a direct comparison of the different models’ capabilities in processing and understanding video content, providing a comprehensive overview of their relative strengths and weaknesses.
read the caption
Table 8: Evaluation results of 7B models on video benchmarks. * denotes the reproduced results. † denotes the results retrieved from the official leaderboard. The best results are in bold and the second best ones are underlined.
| Model | GQA | AI2D | ChartQA | DocVQAval | MME |
| clip-vit-large-patch14-336 radford2021learning | 61.50 | 56.28 | 18.32 | 24.86 | 1668.41 |
| dfn5B-clip-vit-h-14-378 fang2023data | 62.70 | 56.87 | 16.40 | 23.09 | 1665.35 |
| siglip-so400m-patch14-384 Zhai2023SigmoidLF | 62.92 | 57.12 | 22.44 | 31.32 | 1667.92 |
🔼 This table presents the ablation study conducted on different vision encoders used in the VideoLLaMA3 model. It compares the performance of three different pre-trained vision encoders (CLIP, DFN, and SigLIP) across various downstream tasks. The goal is to determine the impact of the choice of vision encoder on the model’s overall performance on image understanding benchmarks including GQA, AI2D, ChartQA, DocVQA, and MME. The results help to justify the selection of SigLIP as the base vision encoder for VideoLLaMA3.
read the caption
Table 9: Ablation Study on Vision Encoders.
Full paper#