TL;DR#
Current AI alignment methods heavily rely on human supervision, but future superhuman AI models may outpace human capabilities, creating safety concerns. This necessitates scalable oversight and weak-to-strong generalization techniques. The existing approaches are typically studied separately, limiting their effectiveness.
The paper proposes a novel approach that combines these techniques. It uses a strong pretrained model to improve the quality of supervision provided by a smaller, weaker model. This is achieved through a debate mechanism where the strong model argues for different answers and a weak model learns from the discussion. The results demonstrate improved alignment on OpenAI’s weak-to-strong NLP benchmarks showing that the combined approach is highly effective.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical challenge of aligning increasingly capable AI models with human values, especially in a future where human oversight may be insufficient. It introduces a novel approach combining scalable oversight and weak-to-strong generalization, demonstrating improved alignment by leveraging debate between strong and weak models. This opens new avenues for research into robust AI alignment techniques that can scale to future superhuman AI systems.
Visual Insights#

🔼 This figure illustrates a three-turn debate between two large language models (LLMs) acting as debaters, Debater A and Debater B. Each turn involves a prompt that presents a science knowledge question and an answer, instructing the debaters to argue for or against the correctness of the answer. Debater A argues for the correctness, while Debater B initially argues against it and then presents a counterargument in response to Debater A’s points. This process simulates how a debate could help extract reliable information from potentially untrustworthy models, forming a crucial step in the weak-to-strong generalization approach described in the paper.
read the caption
Figure 1: Illustration of debate. Illustration of the debate procedure between debater A and debater B.
| Debate Turn | Debater | Prompt |
|---|---|---|
| First | A | There is a science knowledge question, followed by an answer. Debate with another opponent for whether the answer is correct or incorrect. Construct your argument for why the answer is correct. |
| Second | B | There is a science knowledge question, followed by an answer. Debate with another opponent for whether the answer is correct or incorrect. Construct your argument for why the answer is incorrect and list out flaws in your opponent’s argument. |
| Third | A | There is a science knowledge question, followed by an answer. Debate with another opponent for whether the answer is correct or incorrect. Construct the counterargument to opponent’s argument. |
🔼 This table details the prompts used to initiate a debate between two AI models (Debater A and Debater B) on a binary classification problem. The problem originates from the SciQ dataset, where each question has two possible answers: correct and incorrect. Debater A and Debater B are randomly assigned one of these answers. The debate proceeds over three turns, with each debater providing arguments to support their assigned answer and refute the opponent’s claims. Crucially, the transcript of the debate is appended to the prompt for each subsequent turn, making the debate contextually aware.
read the caption
Table 1: Prompts to induce debate on a binary classification problem. The binary classification problem is converted from the SciQ dataset. Two answer choices correct and incorrect are randomly assigned to debater A and B. Debate runs for three turns. We also append the current debate transcript to the prompt.
In-depth insights#
Weak-to-Strong Alignment#
Weak-to-strong alignment in AI focuses on bridging the gap between human-level supervision (weak) and the capabilities of increasingly powerful models (strong). The core challenge lies in the limitation of human ability to effectively evaluate and correct the outputs of advanced AI systems. This necessitates developing methods that enable strong models to learn and generalize effectively from limited, imperfect human feedback. Approaches include techniques like debate, where a strong model argues with another to refine its understanding, thus providing a more robust signal for the weak model to learn from. Furthermore, using ensembles of weak models to aggregate supervision signals can enhance robustness. A key aspect is ensuring that the weak supervision is trustworthy and properly guides the strong model towards desired behavior. The goal is not just performance improvement but ensuring safety and alignment with human values, which is particularly critical as AI systems surpass human capabilities.
Debate’s Role#
The paper explores debate as a mechanism to improve weak-to-strong generalization in AI alignment. Debate forces a strong, potentially unreliable model to justify its reasoning, making its output more transparent and allowing a weaker model to extract more trustworthy information. This process enhances the weaker model’s ability to create more robust supervision signals for the strong model. The paper demonstrates that using an ensemble of weak models, each trained on different debate transcripts, further strengthens this supervision. This approach combines the strengths of scalable oversight (improving human supervision) and weak-to-strong generalization (improving alignment using weak data), offering a novel technique for training safer and more aligned AI systems. The core innovation is leveraging debate, not merely as an evaluation technique, but as a data augmentation and knowledge extraction method for training a more reliable weak model. The experimental results on several NLP tasks show that this debate-based approach significantly outperforms baseline methods, highlighting debate’s effectiveness as a tool in AI alignment.
Ensemble Methods#
The concept of ensemble methods within the context of weak-to-strong generalization in AI alignment is crucial. It addresses the limitations of relying on single weak models to supervise powerful, potentially misaligned strong models. By combining predictions from multiple weak models, an ensemble approach enhances robustness and accuracy. This is particularly important when dealing with noisy or unreliable weak supervision signals, as is often the case with human-provided feedback on complex AI tasks. The authors explore this by creating an ensemble of weak models, each trained with different debate transcripts from a strong model debate. This diversity in training data helps improve the overall reliability of the weak supervision signal and enhances the capabilities of the weak-to-strong generalization process. The choice of ensemble type (debate ensembles versus finetune ensembles) significantly impacts performance, highlighting the need for careful consideration of data diversity in ensemble construction. Overall, the study emphasizes the significant role of ensemble methods in bridging the gap between weak human supervision and the reliable training of strong AI models, leading to more effective and safe AI alignment.
Scalable Oversight#
Scalable oversight addresses the challenge of maintaining effective human supervision as AI models surpass human capabilities. The core problem is the scalability of human evaluation: as models become more complex, manually verifying their behavior becomes increasingly difficult and expensive. Therefore, scalable oversight aims to develop methods that allow humans to more efficiently oversee powerful AI systems. This could involve techniques such as improved evaluation interfaces, automated assistance for human reviewers, or the development of more easily-auditable AI architectures. Ultimately, the goal is to create systems where human oversight can remain relevant and effective even as AI capabilities grow exponentially. Key research areas include improved human-AI collaboration tools, algorithms that highlight potentially problematic model behavior, and new methods for decomposing complex AI systems into more manageable components for evaluation. Success in scalable oversight is critical for ensuring the safety and alignment of advanced AI.
Future Directions#
Future research should prioritize expanding the scope of debate techniques beyond binary classification tasks. Exploring more complex scenarios and diverse question types would allow for a more robust evaluation of the method’s effectiveness and generalizability. Investigating the interplay between debate structure (number of turns, participant roles) and model performance is crucial for optimizing this approach. Furthermore, research should focus on developing more efficient and scalable ensemble methods for weak model training, addressing the computational cost associated with larger ensembles. Addressing the limitations of current pretrained models is key, as the strong model’s trustworthiness significantly affects the quality of weak supervision. Finally, a deeper investigation into the potential of debate in enhancing other alignment methods, such as RLHF, and exploring its applicability to other modalities (e.g., vision) could reveal valuable synergistic effects and broader implications for AI safety.
More visual insights#
More on figures

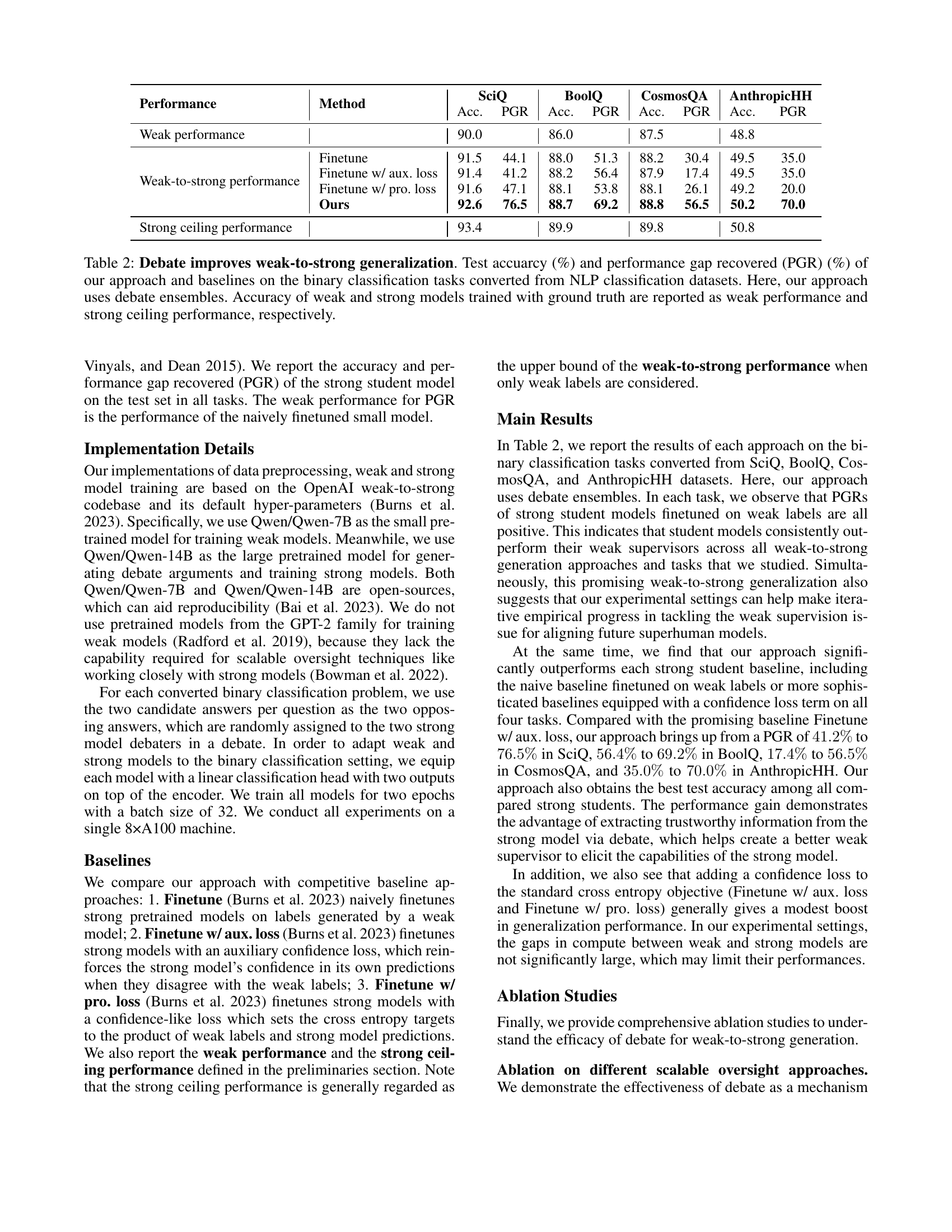
🔼 This figure displays the results of an ablation study investigating the impact of varying the number of weak models within an ensemble on the performance of a weak-to-strong generalization approach. The x-axis represents the number of weak models in the ensemble (cardinality), and the y-axis shows the accuracy achieved. Two datasets, SciQ and AnthropicHH, are shown, illustrating how the optimal ensemble size may vary depending on the dataset. The experiment uses debate ensembles, a specific type of ensemble where the weak models are trained on different debate transcripts. The figure demonstrates the relationship between ensemble size and model performance, showing that beyond a certain cardinality (e.g. 4 models), increasing the number of weak models provides diminishing returns.
read the caption
Figure 2: Ablation study on the cardinality of the ensemble. Here, our approach uses debate ensembles.

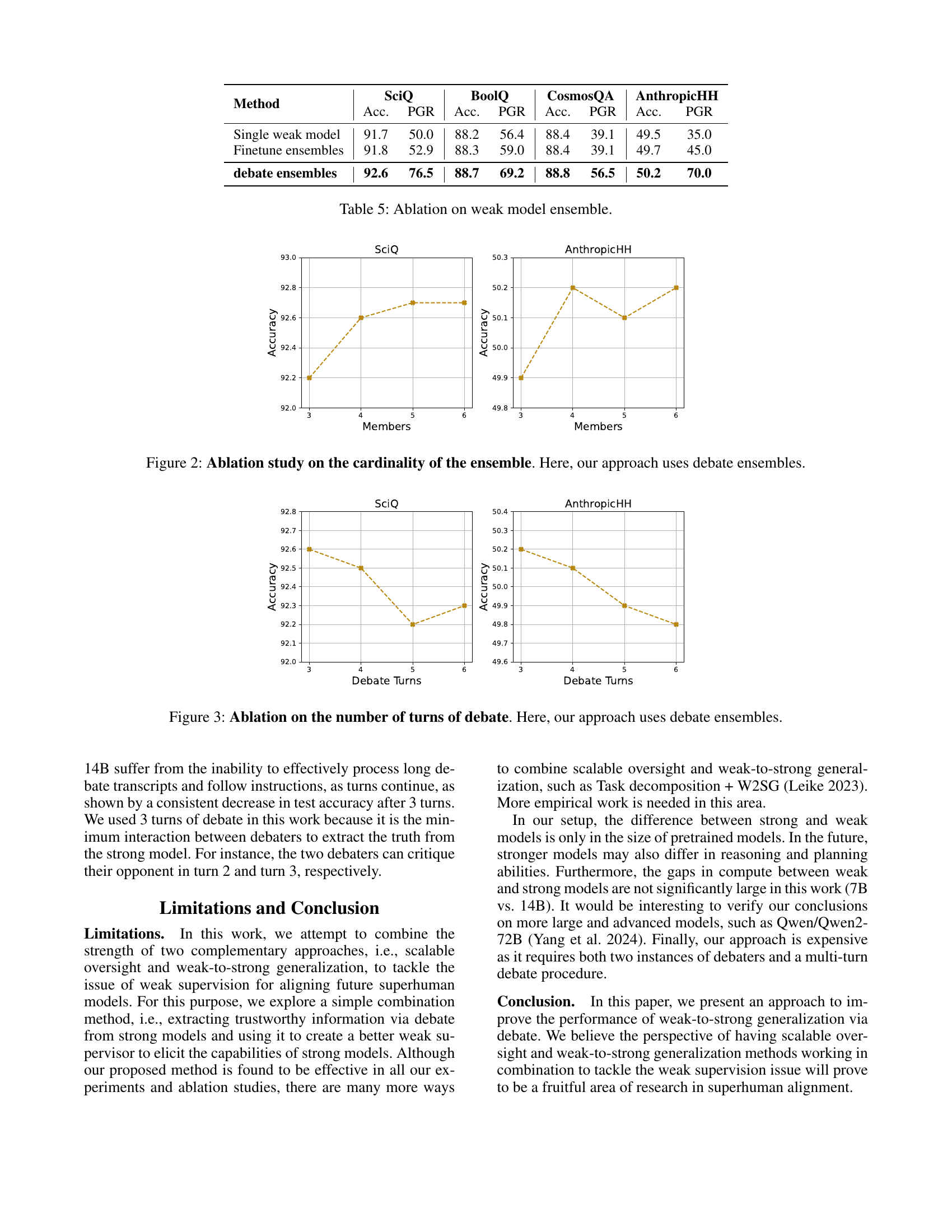
🔼 This ablation study investigates the impact of varying the number of turns in the debate process on the overall performance of the model. Using debate ensembles, the experiment measures accuracy on the SciQ and AnthropicHH datasets while adjusting the number of turns in the debate from 3 to 6. The results illustrate the relationship between debate length and model accuracy, revealing whether extending the debate improves or hinders performance and whether there’s a point of diminishing returns.
read the caption
Figure 3: Ablation on the number of turns of debate. Here, our approach uses debate ensembles.
More on tables
| Performance | Method | SciQ | BoolQ | CosmosQA | AnthropicHH | ||||
|---|---|---|---|---|---|---|---|---|---|
| Acc. | PGR | Acc. | PGR | Acc. | PGR | Acc. | PGR | ||
| Weak performance | 90.0 | 86.0 | 87.5 | 48.8 | |||||
| Weak-to-strong performance | Finetune | 91.5 | 44.1 | 88.0 | 51.3 | 88.2 | 30.4 | 49.5 | 35.0 |
| Finetune w/ aux. loss | 91.4 | 41.2 | 88.2 | 56.4 | 87.9 | 17.4 | 49.5 | 35.0 | |
| Finetune w/ pro. loss | 91.6 | 47.1 | 88.1 | 53.8 | 88.1 | 26.1 | 49.2 | 20.0 | |
| Ours | 92.6 | 76.5 | 88.7 | 69.2 | 88.8 | 56.5 | 50.2 | 70.0 | |
| Strong ceiling performance | 93.4 | 89.9 | 89.8 | 50.8 | |||||
🔼 This table presents the results of an experiment comparing different methods for improving the alignment of AI models. The goal is to enhance the ability of weaker models to learn from, and generalize the knowledge to, stronger models, even with imperfect human supervision. The experiment focuses on binary classification tasks derived from Natural Language Processing (NLP) datasets. The table shows the accuracy and performance gap recovery (PGR) for various approaches. PGR measures how much of the performance gap between a weak model and a strongly trained model the methods can close using only weak supervision. The approaches include finetuning with different loss functions and a novel method using debate between two strong models to generate better training data for the weak model. The weak and strong model performances using ground truth labels are included as baselines.
read the caption
Table 2: Debate improves weak-to-strong generalization. Test accuarcy (%) and performance gap recovered (PGR) (%) of our approach and baselines on the binary classification tasks converted from NLP classification datasets. Here, our approach uses debate ensembles. Accuracy of weak and strong models trained with ground truth are reported as weak performance and strong ceiling performance, respectively.
| Protocol | Prompt |
|---|---|
| Consultancy | There is a science knowledge question, followed by an answer. Construct your argument for why the answer is [random answer]. |
| Market-Making | There is a science knowledge question, followed by an answer. Construct your argument for why the answer is [unselected answer]. |
🔼 This table details the prompts used in the Consultancy and Market-Making experiments. The experiments use a binary classification problem adapted from the SciQ dataset. For each problem, there are two possible answers: correct and incorrect. In the Consultancy prompt, a randomly selected answer is given to the model for which it must construct an argument. In the Market-Making prompt, the model receives the answer not selected by the weak supervisor (a small, initially-trained model) and is tasked with creating a counter-argument. The current transcript is included with each prompt.
read the caption
Table 3: Prompts to induce consultancy and market-making. The binary classification problem is converted from the SciQ dataset. The two answer choices are correct and incorrect. [random answer] is the answer randomly sampled from the two candidate answers. [unselected answer] is the answer that is not selected by the weak supervisor (the naively finetuned small model) based on its prediction. We also append the current transcript to the prompt.
| Method | SciQ | BoolQ | CosmosQA | AnthropicHH | ||||
|---|---|---|---|---|---|---|---|---|
| Acc. | PGR | Acc. | PGR | Acc. | PGR | Acc. | PGR | |
| Consultancy | 91.5 | 44.1 | 87.8 | 46.2 | 88.3 | 34.8 | 49.3 | 25.0 |
| Market-Making | 91.6 | 47.1 | 87.6 | 41.0 | 88.2 | 30.4 | 49.5 | 35.0 |
| Ours | 92.6 | 76.5 | 88.7 | 69.2 | 88.8 | 56.5 | 50.2 | 70.0 |
🔼 This table presents the results of an ablation study comparing the performance of the proposed debate method with two other scalable oversight approaches: Consultancy and Market-Making. The goal is to determine the effectiveness of debate in extracting trustworthy information from a strong model to improve weak supervision. Performance is measured using accuracy and performance gap recovered (PGR) on four binary classification tasks derived from NLP datasets (SciQ, BoolQ, CosmosQA, and AnthropicHH). The table shows that the debate approach consistently outperforms the other methods, highlighting the benefits of debate as a mechanism for improving weak-to-strong generalization.
read the caption
Table 4: Ablation on different scalable oversight approaches. Here, our approach uses debate ensembles.
| Method | SciQ | BoolQ | CosmosQA | AnthropicHH | ||||
|---|---|---|---|---|---|---|---|---|
| Acc. | PGR | Acc. | PGR | Acc. | PGR | Acc. | PGR | |
| Single weak model | 91.7 | 50.0 | 88.2 | 56.4 | 88.4 | 39.1 | 49.5 | 35.0 |
| Finetune ensembles | 91.8 | 52.9 | 88.3 | 59.0 | 88.4 | 39.1 | 49.7 | 45.0 |
| debate ensembles | 92.6 | 76.5 | 88.7 | 69.2 | 88.8 | 56.5 | 50.2 | 70.0 |
🔼 This table presents the results of an ablation study on the impact of using different weak model ensemble methods on the overall performance. It compares three approaches: a single weak model, finetune ensembles (where models share the same debate transcript but have different random seeds during finetuning), and debate ensembles (where each model uses a different debate transcript generated with a different random seed). The table shows the accuracy and performance gap recovered (PGR) for each method across four NLP classification tasks: SciQ, BoolQ, CosmosQA, and AnthropicHH. The data illustrates the effectiveness of using debate ensembles to obtain a more robust supervision estimate.
read the caption
Table 5: Ablation on weak model ensemble.
Full paper#