TL;DR#
Multi-agent systems struggle with effective coordination, especially in decentralized settings with limited communication. Many existing approaches rely on explicit communication protocols or centralized control, which can be inefficient and limit scalability. This often leads to deadlocks or suboptimal solutions in complex scenarios.
This paper proposes SRMT (Shared Recurrent Memory Transformer), a novel approach that addresses these issues. SRMT uses a shared memory space to enable implicit communication between agents. Each agent maintains its own working memory and updates the shared space, allowing for indirect information exchange and improved coordination. Experiments demonstrate SRMT’s effectiveness in a challenging multi-agent pathfinding task, outperforming traditional methods and showing strong generalization to unseen environments and scalability to larger problems.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to multi-agent coordination using shared memory and transformers, addressing a critical challenge in multi-agent reinforcement learning. The findings offer valuable insights into improving decentralized decision-making and show significant performance gains in complex scenarios. This work opens new avenues for researchers to explore more effective coordination mechanisms in distributed AI systems, pushing the boundaries of MARL applications.
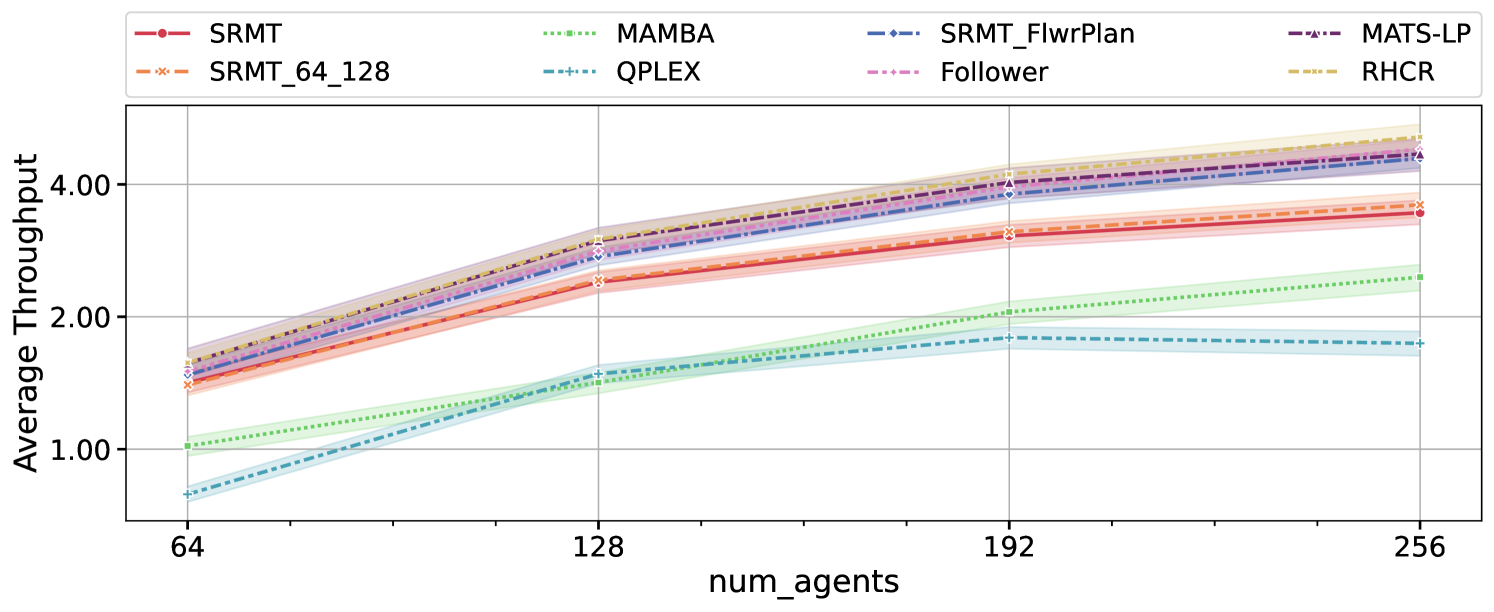
Visual Insights#

🔼 The figure illustrates the architecture of the Shared Recurrent Memory Transformer (SRMT). The core of SRMT is composed of three key components: the memory head, which updates individual agent memories; a cross-attention mechanism, which enables agents to access a shared memory containing the pooled recurrent memories of all agents; and an action decoder, which produces the agents’ actions. Each agent’s input consists of its own recurrent memory, a history of its past observations, and its current observation. This input undergoes self-attention processing before being passed to the cross-attention mechanism, allowing information exchange between agents through the shared memory. The updated agent memories are then fed back into the memory head and the action decoder to generate the next actions.
read the caption
Figure 1: Shared Recurrent Memory Transformer architecture. SRMT pools recurrent memories memi,t𝑚𝑒subscript𝑚𝑖𝑡mem_{i,t}italic_m italic_e italic_m start_POSTSUBSCRIPT italic_i , italic_t end_POSTSUBSCRIPT of individual agents at a moment t𝑡titalic_t and provides global access to them via cross-attention.
| Parameter | MAPF (all models) | SRMT LMAPF |
|---|---|---|
| Optimizer | Adam | Adam |
| Learning rate | ||
| LR Scheduler | Adaptive KL | Constant |
| (discount factor) | ||
| Recurrence rollout | - | |
| Clip ratio | ||
| Batch size | ||
| Optimization epochs | ||
| Entropy coefficient | ||
| Value loss coefficient | ||
| GAEλ | ||
| MLP hidden size | ||
| ResNet residual blocks | ||
| ResNet filters | ||
| Attention hidden size | ||
| Attention heads | ||
| GRU hidden size | - | |
| Activation function | ReLU | ReLU |
| Network Initialization | orthogonal | orthogonal |
| Rollout workers | ||
| Envs per worker | ||
| Training steps | ||
| Episode length | ||
| Observation patch | ||
| Number of agents |
🔼 This table details the configurations and hyperparameters used during the training of various models for multi-agent pathfinding tasks, including the Shared Recurrent Memory Transformer (SRMT) and several baseline models. It provides a comprehensive overview of the settings employed for both MAPF (Multi-Agent Pathfinding) and LMAPF (Lifelong Multi-Agent Pathfinding) experiments, covering aspects such as the optimizer, learning rate, discount factor, recurrent rollout length, batch size, and various network architecture parameters. These details are crucial for understanding and replicating the experimental results presented in the paper.
read the caption
Table 1: Models configuration and training hyperparameters.
In-depth insights#
Shared Memory MARL#
Shared memory in multi-agent reinforcement learning (MARL) offers a compelling approach to enhance coordination and cooperation among agents. By establishing a shared memory space, agents can implicitly communicate, reducing the reliance on explicit communication mechanisms which can be complex and prone to failure. This indirect communication allows agents to access information about the global state and the actions of other agents, enabling better decision-making and improved performance, particularly in challenging partially observable environments. However, efficient management of the shared memory is crucial. The size and structure of the shared memory directly impact performance; an overly large space can lead to decreased efficiency, while an insufficiently sized one restricts information access. Furthermore, the mechanisms for updating and accessing the shared memory need careful consideration. Effective strategies ensure that the information is both relevant and readily available to all agents. Successfully addressing these design challenges unlocks the potential of shared memory MARL to achieve significantly improved results in complex cooperative scenarios.
SRMT Architecture#
The SRMT architecture is a novel approach to multi-agent reinforcement learning that leverages a shared recurrent memory transformer. Its core innovation lies in the integration of individual agent memories into a globally accessible shared memory space. This allows agents to implicitly communicate and coordinate their actions without explicit communication channels, thereby mitigating the complexities of traditional MARL communication protocols. The system’s design is decentralized, with each agent maintaining its own recurrent memory and updating it based on local observations and the shared memory content. The use of a transformer architecture allows for efficient parallel processing of information from both individual and shared memories, leading to effective coordination and improved performance, especially in challenging scenarios with sparse rewards or long horizons. The ability to implicitly share information via the shared memory is particularly beneficial in scenarios where explicit communication is difficult or costly. This shared memory mechanism significantly enhances coordination and avoids deadlocks by allowing agents to learn effective implicit communication strategies. The architecture demonstrates successful application to decentralized multi-agent pathfinding, showcasing its capacity for handling complex and dynamic environments.
Bottleneck Experiments#
The Bottleneck Experiments section would likely detail a series of controlled tests designed to evaluate the performance of the Shared Recurrent Memory Transformer (SRMT) in scenarios requiring high levels of inter-agent coordination. The core concept of a bottleneck—a narrow passage that forces agents into close proximity—introduces a crucial challenge: efficient coordination to avoid deadlocks and collisions. This setup allows researchers to isolate the impact of SRMT’s shared memory mechanism on collision avoidance and overall task completion success rate. The experiments would probably involve varying the bottleneck’s length or complexity to assess the model’s scalability and generalization capabilities. Performance metrics such as success rate (all agents reach their goals), individual success rate, and the total number of steps taken would be crucial. The results would be compared against baselines such as traditional multi-agent reinforcement learning approaches lacking a shared memory. A key finding might show SRMT’s superior performance, especially in scenarios with sparse rewards or longer, more challenging bottlenecks, highlighting the effectiveness of shared memory in enabling implicit communication and coordination amongst agents.
LMAPF Generalization#
Analyzing lifelong multi-agent pathfinding (LMAPF) generalization reveals crucial aspects of algorithm robustness and real-world applicability. Successful generalization implies an agent’s ability to adapt to unseen map layouts and agent numbers, showcasing its learning capabilities beyond the training data. A strong LMAPF algorithm should exhibit consistent performance across diverse map complexities (e.g., mazes, random, warehouse layouts), demonstrating its adaptability to different spatial challenges. Evaluating generalization often involves testing on maps larger or structurally different from those encountered during training; this reveals the algorithm’s ability to extrapolate learned strategies to novel scenarios. Furthermore, evaluating performance with varying numbers of agents assesses the algorithm’s scalability and its ability to maintain efficiency and effectiveness in increasingly complex multi-agent environments. The presence of unseen obstacles or dynamic elements during testing would provide a more rigorous evaluation of true generalization. Ultimately, strong LMAPF generalization is vital for deploying these algorithms in dynamic, unpredictable environments where perfect prior knowledge is unrealistic.
Future of SRMT#
The future of SRMT (Shared Recurrent Memory Transformer) appears bright, given its demonstrated success in multi-agent pathfinding. Further research could explore its application in more complex and dynamic environments, beyond the relatively simple scenarios tested in the paper. Scaling SRMT to handle a significantly larger number of agents is crucial for real-world applications. This might involve investigating more efficient memory sharing mechanisms and potentially exploring distributed architectures. Integrating SRMT with other advanced techniques such as hierarchical reinforcement learning or model-predictive control could lead to even more robust and effective multi-agent systems. Investigating the impact of different reward functions and training methods on SRMT’s performance is also warranted. Finally, a deeper understanding of the internal workings of the shared memory and how it facilitates coordination among agents could lead to significant improvements and new theoretical insights. Addressing the limitations regarding perfect localization and action execution is crucial to make SRMT applicable to real-world robotic systems.
More visual insights#
More on figures

🔼 This figure shows a simple two-agent coordination task, a bottleneck, where agents must navigate through a narrow passage. The environment consists of two rooms connected by a one-cell-wide corridor. Each agent has a 5x5 field of view and starts in one room, with their goal located in the opposite room. This setup requires both agents to pass through the corridor, making it a test of coordination.
read the caption
(a) Bottleneck

🔼 This image displays a sample maze environment from the POGEMA benchmark used in the experiments. It shows a complex arrangement of walls and pathways, where agents must navigate to their respective goals while avoiding collisions. The complexity of the maze highlights the challenging nature of the multi-agent pathfinding task.
read the caption
(b) Maze

🔼 The image displays a sample environment from the POGEMA benchmark, specifically showcasing a ‘Random’ map used for testing multi-agent pathfinding algorithms. The map is a grid-based representation, likely featuring randomly placed obstacles and open spaces that agents must navigate. The agents’ starting points and goals are typically represented by colored shapes, demonstrating the complexity of pathfinding in unstructured environments. This visualization helps illustrate the challenges in coordinating multiple agents through randomly generated obstacles, as opposed to more structured environments such as mazes.
read the caption
(c) Random

🔼 This subfigure shows an example of a ‘Puzzle’ environment from the POGEMA benchmark. The image displays a grid-based map with obstacles (grey squares) and two agents (colored circles) attempting to reach their respective goals (empty circles of the same color). The layout of the obstacles presents a complex pathfinding challenge, requiring agents to navigate around them and potentially coordinate their movements to avoid collisions and reach their goals efficiently.
read the caption
(d) Puzzle

🔼 This image displays a warehouse environment map used in multi-agent pathfinding experiments. The map shows a complex layout with multiple obstacles and narrow corridors representing a challenging scenario for agents to navigate. The agents need to efficiently plan their routes to reach their respective goals without colliding with each other or the obstacles. This complex layout makes the task more difficult compared to simpler environments, offering a significant challenge for testing multi-agent coordination and pathfinding algorithms.
read the caption
(e) Warehouse

🔼 The figure shows a sample map from the MovingAI dataset used in the experiments. MovingAI is a dataset containing diverse and complex maps that are commonly used for evaluating multi-agent pathfinding algorithms. The map is characterized by its intricate layout of obstacles and narrow passages, demanding precise coordination and efficient navigation strategies from the agents.
read the caption
(f) MovingAI

🔼 Figure 2 showcases example environments used to evaluate multi-agent pathfinding algorithms. (a) presents a simplified ‘Bottleneck’ scenario: two agents must navigate a narrow passage to reach their respective goals in opposite rooms, highlighting the need for coordination. This illustrates a simple, controlled test of coordination abilities. (b) through (f) depict more complex maps from the POGEMA benchmark (Skrynnik et al., 2024a), offering diverse layouts and sizes to assess algorithm generalization and performance across various scenarios. These include mazes, random arrangements, and more structured warehouse and MovingAI maps, evaluating the ability of the tested algorithms to solve pathfinding problems in diverse and more realistic settings.
read the caption
Figure 2: Examples of environments. (a) Bottleneck task. This is a toy task on coordination. Two agents start in rooms opposite their goals and should coordinate passing the corridor. Agents are shown as solid-colored circles, their goals are empty circles with the same border color. (b)-(f) Maps from POGEMA benchmark (images for POGEMA maps are from (Skrynnik et al., 2024a)). POGEMA allows testing the planning methods’ generalization across different maps and problem sizes.

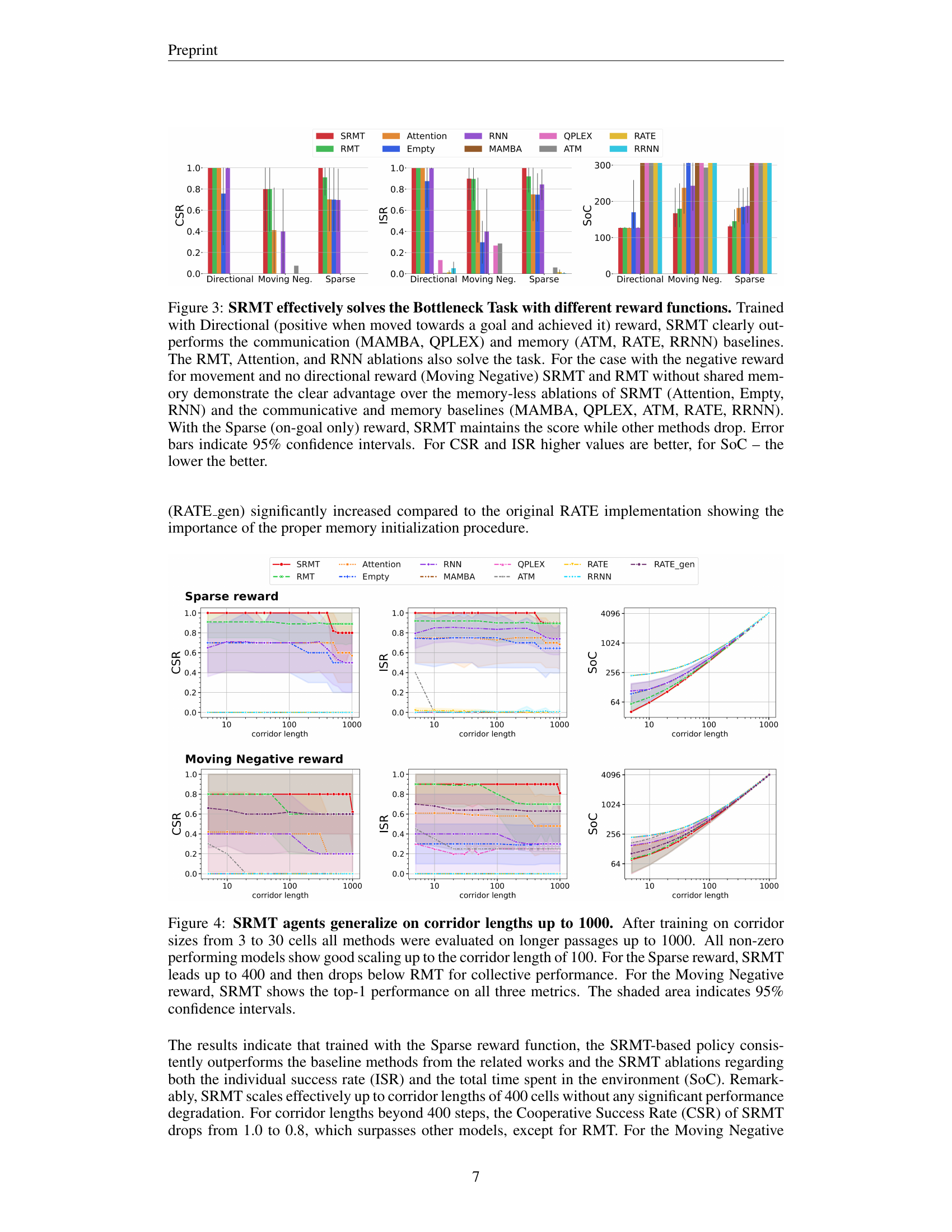
🔼 This figure displays the performance comparison of different multi-agent reinforcement learning (MARL) algorithms on a bottleneck navigation task. The algorithms are evaluated across three reward scenarios: Directional, Moving Negative, and Sparse. The results show that the Shared Recurrent Memory Transformer (SRMT) significantly outperforms other models, especially in scenarios with sparse rewards or negative rewards for movement. SRMT’s superior performance is particularly evident compared to communication-based models (MAMBA, QPLEX) and memory-based models (ATM, RATE, RRNN). Ablation studies using variations of the SRMT (RMT, Attention, Empty, RNN) further highlight the importance of the shared memory mechanism. The metrics used for evaluation include Cooperative Success Rate (CSR), Individual Success Rate (ISR), and Sum-of-Costs (SoC). Higher CSR and ISR values are preferred, while a lower SoC value is desired.
read the caption
Figure 3: SRMT effectively solves the Bottleneck Task with different reward functions. Trained with Directional (positive when moved towards a goal and achieved it) reward, SRMT clearly outperforms the communication (MAMBA, QPLEX) and memory (ATM, RATE, RRNN) baselines. The RMT, Attention, and RNN ablations also solve the task. For the case with the negative reward for movement and no directional reward (Moving Negative) SRMT and RMT without shared memory demonstrate the clear advantage over the memory-less ablations of SRMT (Attention, Empty, RNN) and the communicative and memory baselines (MAMBA, QPLEX, ATM, RATE, RRNN). With the Sparse (on-goal only) reward, SRMT maintains the score while other methods drop. Error bars indicate 95% confidence intervals. For CSR and ISR higher values are better, for SoC – the lower the better.

🔼 This figure displays the results of testing the generalization capabilities of different multi-agent pathfinding models on longer corridors than those used during training. The models were initially trained on corridors ranging from 3 to 30 cells in length and then evaluated on corridors up to 1000 cells. The results show that most models maintain good performance up to a corridor length of 100 cells. However, the performance of the SRMT model (Shared Recurrent Memory Transformer), while initially leading for the Sparse reward condition, drops below that of the RMT model (Recurrent Memory Transformer) when the corridor reaches 400 cells. In contrast, for the Moving Negative reward scenario, SRMT consistently displays the best performance across all three metrics (Cooperative Success Rate, Individual Success Rate, and Sum of Costs). The shaded area represents the 95% confidence interval.
read the caption
Figure 4: SRMT agents generalize on corridor lengths up to 1000. After training on corridor sizes from 3 to 30 cells all methods were evaluated on longer passages up to 1000. All non-zero performing models show good scaling up to the corridor length of 100. For the Sparse reward, SRMT leads up to 400 and then drops below RMT for collective performance. For the Moving Negative reward, SRMT shows the top-1 performance on all three metrics. The shaded area indicates 95% confidence intervals.

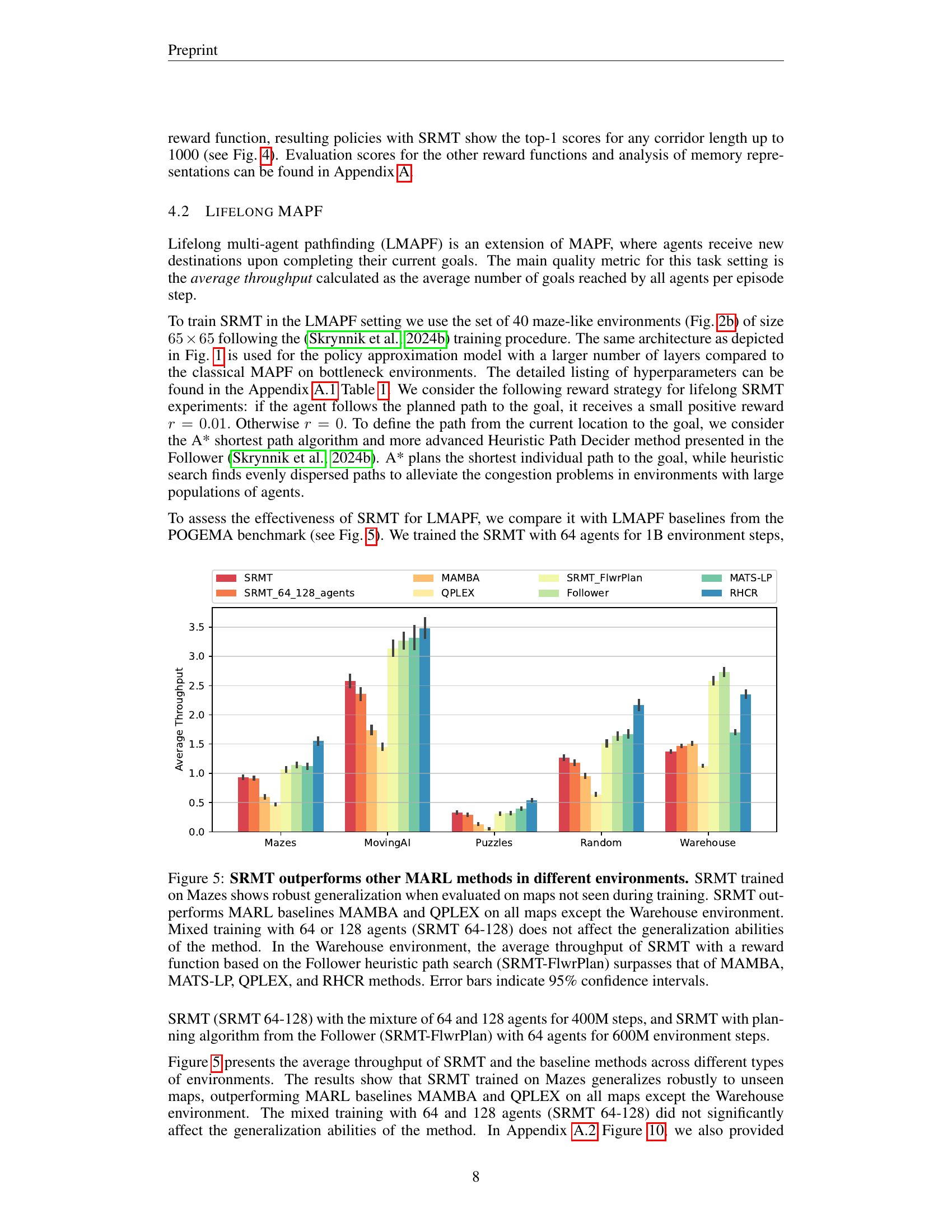
🔼 Figure 5 presents a comparison of the SRMT algorithm’s performance against several other multi-agent reinforcement learning (MARL) methods across six different environments. The figure shows that SRMT, trained on maze-like environments, exhibits strong generalization capabilities when tested on unseen maps. Notably, SRMT outperforms the MAMBA and QPLEX baselines in most environments, with the exception of the Warehouse environment. Even in the Warehouse environment (known for its challenging narrow corridors and high congestion), SRMT demonstrates competitiveness. Specifically, when SRMT incorporates a heuristic path-planning approach (SRMT-FlwrPlan), it surpasses other methods in average throughput, including MAMBA, MATS-LP, QPLEX, and RHCR (a centralized planning-based algorithm). The results show that training SRMT with a mixture of 64 or 128 agents does not negatively impact its generalization ability. Error bars in the graph represent 95% confidence intervals, providing a measure of uncertainty in the results.
read the caption
Figure 5: SRMT outperforms other MARL methods in different environments. SRMT trained on Mazes shows robust generalization when evaluated on maps not seen during training. SRMT outperforms MARL baselines MAMBA and QPLEX on all maps except the Warehouse environment. Mixed training with 64 or 128 agents (SRMT 64-128) does not affect the generalization abilities of the method. In the Warehouse environment, the average throughput of SRMT with a reward function based on the Follower heuristic path search (SRMT-FlwrPlan) surpasses that of MAMBA, MATS-LP, QPLEX, and RHCR methods. Error bars indicate 95% confidence intervals.

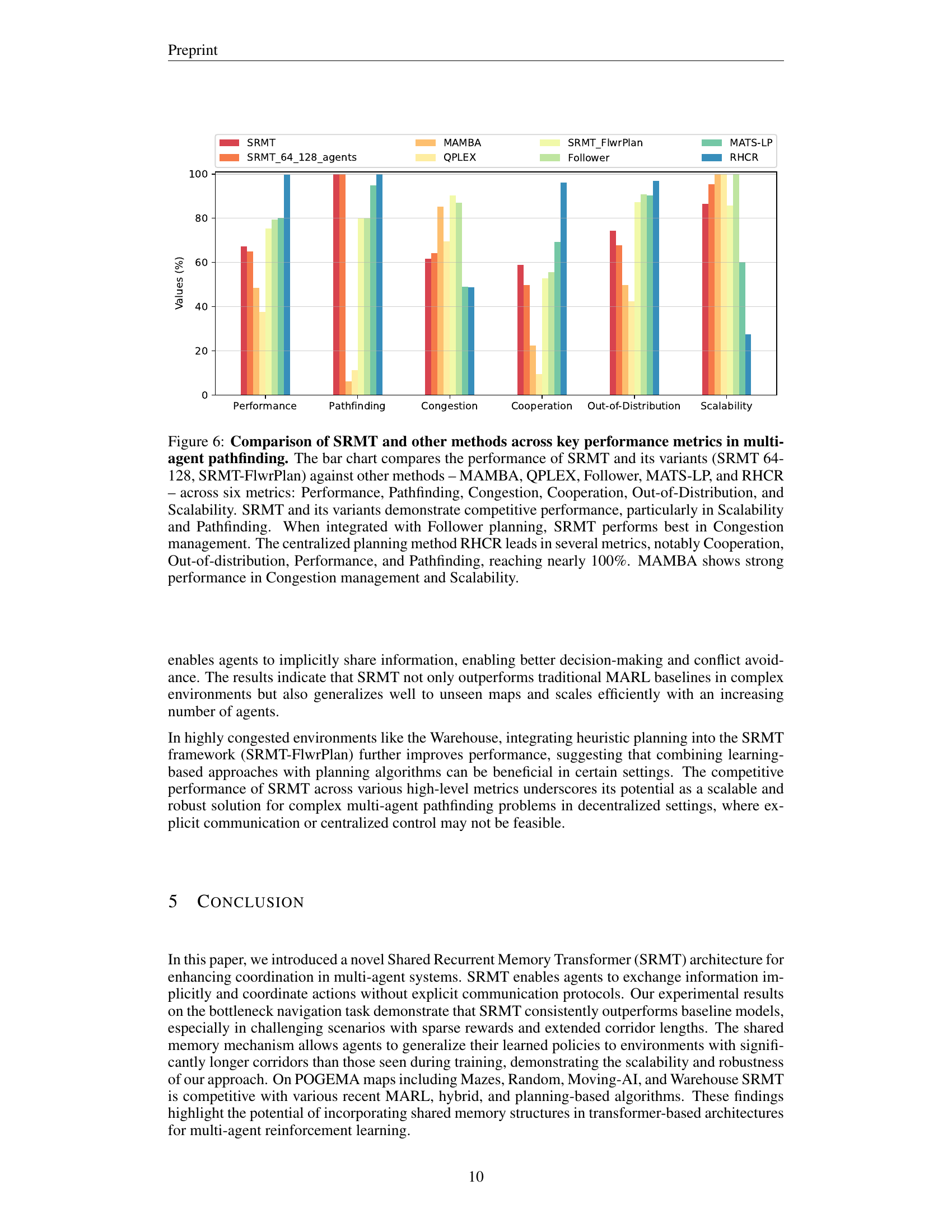
🔼 Figure 6 presents a bar chart comparing the performance of different multi-agent pathfinding (MAPF) algorithms across six key metrics: Performance (average throughput), Pathfinding (optimality of individual agent paths), Congestion (agent density), Cooperation (ability to resolve complex scenarios), Out-of-Distribution (generalization to unseen maps), and Scalability (runtime scaling with increasing agent numbers). The algorithms compared are SRMT (the proposed method), two SRMT variants (SRMT 64-128, using a mixture of 64 and 128 agents during training; and SRMT-FlwrPlan, integrating Follower planning), and several other state-of-the-art methods: MAMBA, QPLEX, Follower, MATS-LP, and RHCR. The results show that SRMT and its variants perform competitively, especially excelling in Scalability and Pathfinding. Notably, integrating Follower planning into SRMT significantly improves performance in Congestion management. The centralized planning method RHCR generally exhibits the best performance across multiple metrics, but SRMT and MAMBA are competitive in certain aspects, especially Scalability and Congestion.
read the caption
Figure 6: Comparison of SRMT and other methods across key performance metrics in multi-agent pathfinding. The bar chart compares the performance of SRMT and its variants (SRMT 64-128, SRMT-FlwrPlan) against other methods – MAMBA, QPLEX, Follower, MATS-LP, and RHCR – across six metrics: Performance, Pathfinding, Congestion, Cooperation, Out-of-Distribution, and Scalability. SRMT and its variants demonstrate competitive performance, particularly in Scalability and Pathfinding. When integrated with Follower planning, SRMT performs best in Congestion management. The centralized planning method RHCR leads in several metrics, notably Cooperation, Out-of-distribution, Performance, and Pathfinding, reaching nearly 100%. MAMBA shows strong performance in Congestion management and Scalability.

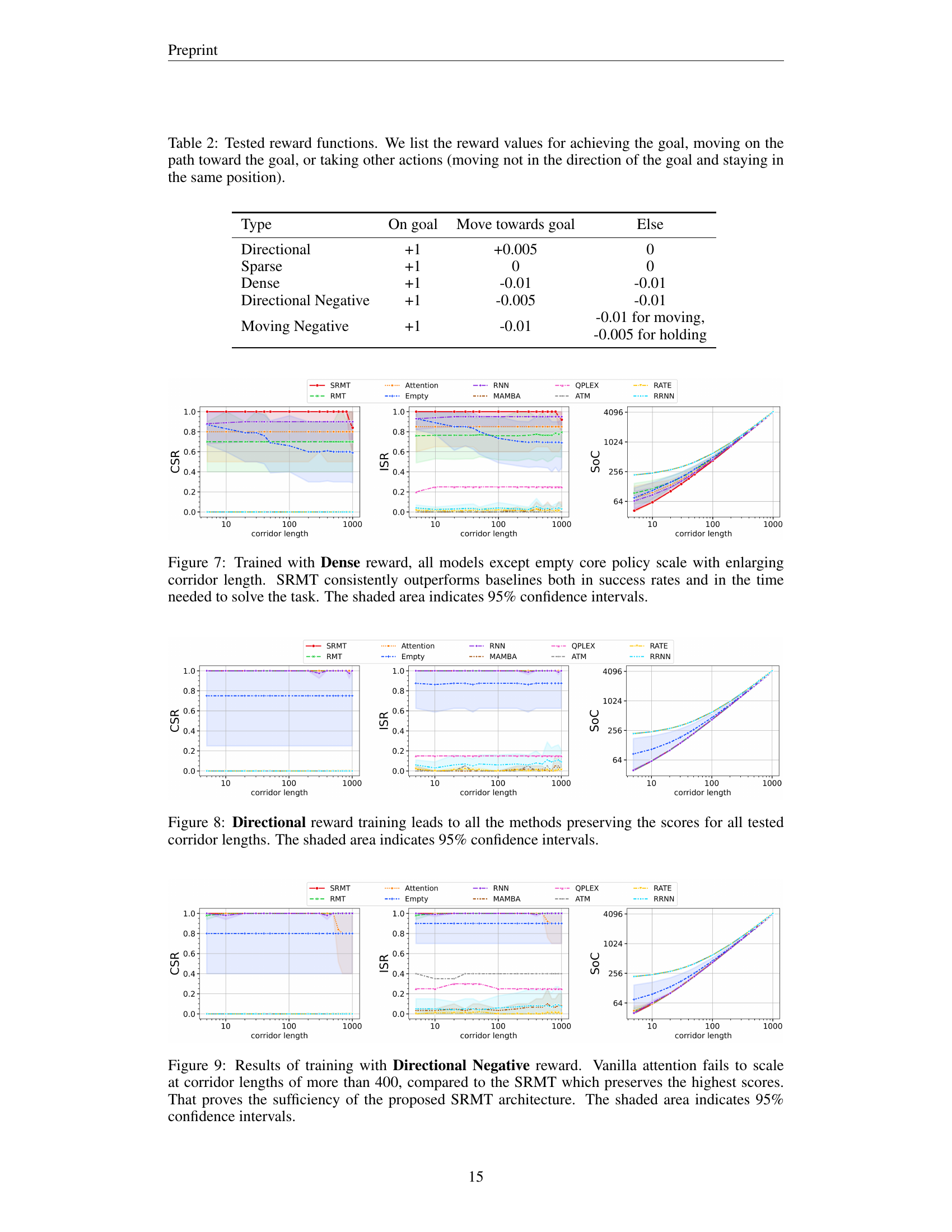
🔼 This figure displays the performance of various multi-agent pathfinding models trained with a dense reward function on a bottleneck task. The x-axis represents the corridor length, while the y-axis shows the success rate (CSR), individual success rate (ISR), and sum-of-costs (SoC). The results demonstrate that SRMT consistently outperforms other methods, such as MAMBA, QPLEX, ATM, RATE, RRNN, RMT, Attention, Empty, and RNN, across all three metrics, even as the corridor length increases. The shaded regions represent the 95% confidence intervals, indicating the statistical significance of the results. The empty core model, which lacks key components of the others, notably struggles at longer corridor lengths.
read the caption
Figure 7: Trained with Dense reward, all models except empty core policy scale with enlarging corridor length. SRMT consistently outperforms baselines both in success rates and in the time needed to solve the task. The shaded area indicates 95% confidence intervals.

🔼 Figure 8 displays the results of an experiment comparing different multi-agent reinforcement learning methods on a bottleneck navigation task. The x-axis represents the length of the corridor, a key factor in the difficulty of the task. The y-axis shows various performance metrics for each model (Cooperative Success Rate (CSR), Individual Success Rate (ISR), and Sum of Costs (SoC)). The Directional reward function was used, which rewards the agents for progressing toward their goals. The plot shows that, under the Directional reward scheme, all the tested models maintain relatively consistent performance across various corridor lengths. The shaded regions represent 95% confidence intervals, indicating the uncertainty associated with each model’s performance.
read the caption
Figure 8: Directional reward training leads to all the methods preserving the scores for all tested corridor lengths. The shaded area indicates 95% confidence intervals.
🔼 Figure 9 presents a comparison of the performance of different models on a multi-agent pathfinding task with a ‘Directional Negative’ reward function. The x-axis represents the length of the corridor the agents need to navigate through, which acts as a measure of task difficulty. The y-axis displays three metrics: Cooperative Success Rate (CSR), Individual Success Rate (ISR), and Sum-of-Costs (SoC). The figure shows that models incorporating a shared recurrent memory mechanism (SRMT) significantly outperform models using vanilla attention mechanisms, particularly as corridor length increases. This difference is evident across all three performance metrics, with the SRMT achieving the highest scores even for longer corridors. The vanilla attention models struggle to maintain performance as the task difficulty increases, highlighting the effectiveness of SRMT’s shared memory in enabling agents to coordinate and solve complex pathfinding challenges. The shaded regions represent the 95% confidence intervals, showing the variability in the results. Overall, this figure demonstrates the superiority of the proposed SRMT architecture, particularly for more challenging multi-agent scenarios.
read the caption
Figure 9: Results of training with Directional Negative reward. Vanilla attention fails to scale at corridor lengths of more than 400, compared to the SRMT which preserves the highest scores. That proves the sufficiency of the proposed SRMT architecture. The shaded area indicates 95% confidence intervals.

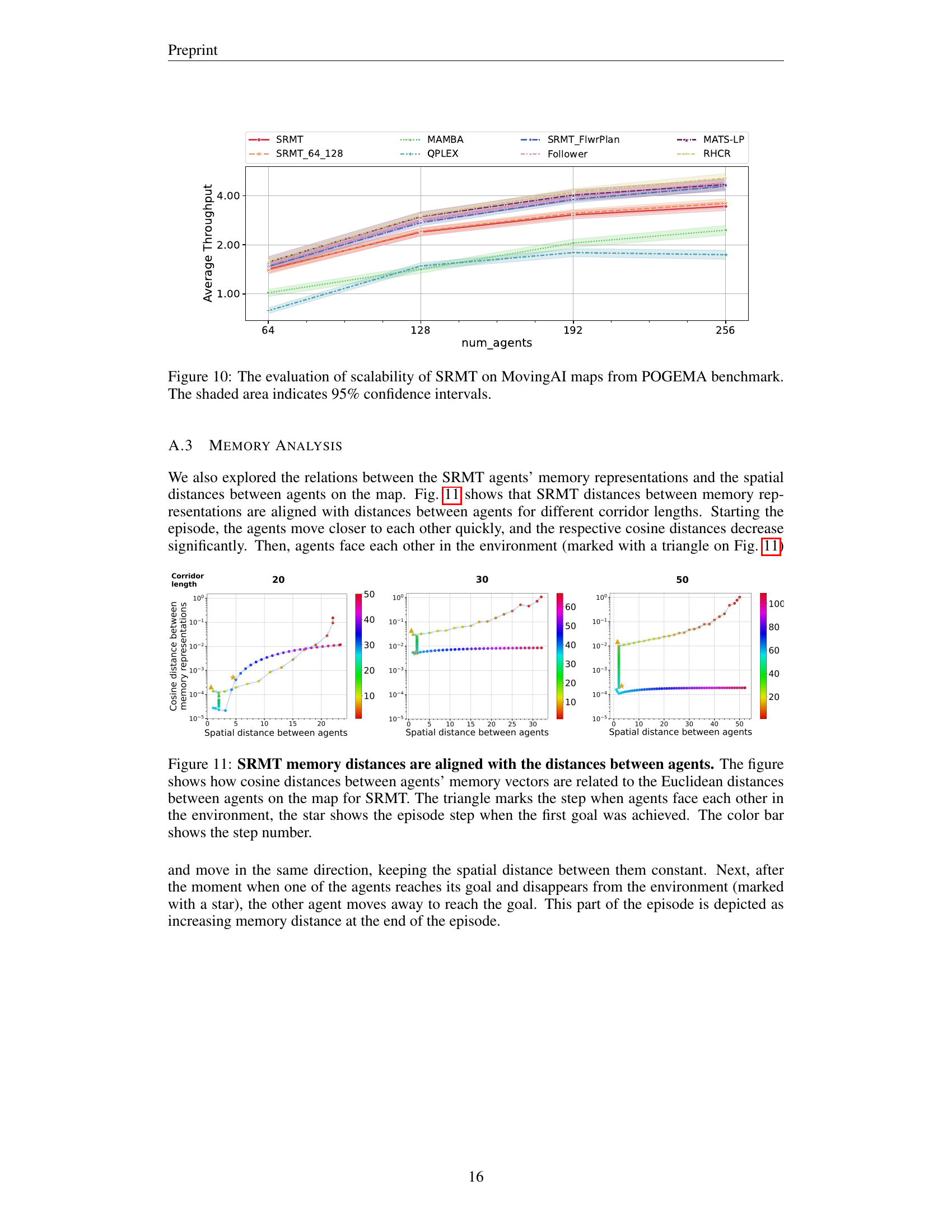
🔼 This figure displays the results of an experiment evaluating the scalability of the Shared Recurrent Memory Transformer (SRMT) algorithm. The experiment used MovingAI maps from the POGEMA benchmark. The x-axis represents the number of agents, and the y-axis shows the average throughput achieved. Different lines represent different algorithms being compared to SRMT. The shaded regions around the lines illustrate the 95% confidence intervals, providing a measure of uncertainty or variability in the results.
read the caption
Figure 10: The evaluation of scalability of SRMT on MovingAI maps from POGEMA benchmark. The shaded area indicates 95% confidence intervals.
Full paper#