TL;DR#
Existing identity-preserving video generation (IP2V) methods struggle with artifacts like ‘copy-paste’ and low similarity due to their heavy reliance on low-level facial image information. These limitations often result in rigid facial appearances and irrelevant details. This paper tackles these challenges head-on.
The proposed method, EchoVideo, employs an Identity Image-Text Fusion Module (IITF) that integrates high-level semantic features from text to capture clean facial identity representations while discarding occlusions or lighting issues. It also utilizes a two-stage training strategy that balances the model’s reliance on high-level and low-level features, thus mitigating excessive dependence on shallow information. Extensive experiments demonstrate that EchoVideo significantly outperforms existing methods in generating high-quality, controllable, and identity-preserving videos.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces EchoVideo, a novel approach to identity-preserving video generation that addresses limitations of existing methods. By fusing high-level semantic features from text and images, EchoVideo generates high-quality, controllable videos while avoiding common artifacts like copy-paste. This work is highly relevant to the growing field of text-to-video generation and opens up new avenues for research in multimodal feature fusion and identity preservation.
Visual Insights#

🔼 This figure showcases the capability of the EchoVideo model to generate high-quality, consistent videos while preserving human identity. Panel (a) demonstrates facial feature preservation where the generated video accurately reflects the facial features from the input identity image, even while following a complex prompt. Panel (b) shows that this capability extends to full-body feature preservation. Even with a detailed description, the model correctly generates a video where both facial and body features align with the input image and the prompt’s specifications, demonstrating EchoVideo’s capacity to resolve potential semantic conflicts between the identity and the video prompt. This is a key advantage, as it avoids issues with incoherent or inconsistent video generation that are commonly found in existing identity-preserving video generation models.
read the caption
Figure 1: Sampling results of EchoVideo. (a) Facial feature preservation. (b) Full-body feature preservation. EchoVideo is capable of not only extracting human features but also resolving semantic conflicts between these features and the prompt, thereby generating coherent and consistent videos.
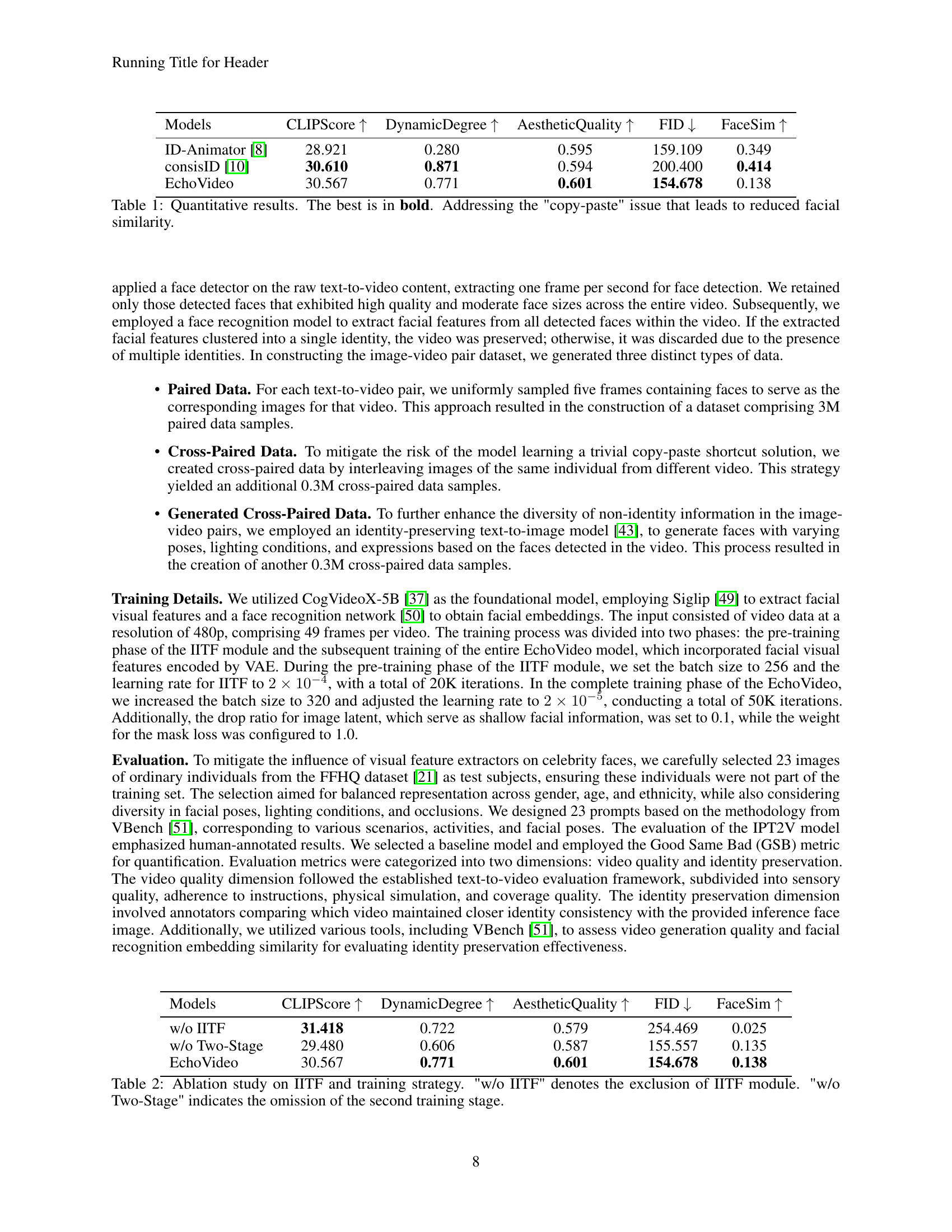
| Models | CLIPScore | DynamicDegree | AestheticQuality | FID | FaceSim |
|---|---|---|---|---|---|
| ID-Animator [8] | 28.921 | 0.280 | 0.595 | 159.109 | 0.349 |
| consisID [10] | 30.610 | 0.871 | 0.594 | 200.400 | 0.414 |
| EchoVideo | 30.567 | 0.771 | 0.601 | 154.678 | 0.138 |
🔼 This table presents a quantitative comparison of EchoVideo’s performance against other state-of-the-art methods in identity-preserving video generation. Metrics include CLIPScore (measuring alignment with text prompts), Dynamic Degree (representing the dynamism of generated videos), Aesthetic Quality (assessing visual appeal), FID (Fréchet Inception Distance, indicating visual fidelity), and FaceSim (measuring facial similarity between generated and real faces). The results highlight EchoVideo’s effectiveness in addressing the ‘copy-paste’ artifacts prevalent in some other models, leading to improved facial similarity, while also demonstrating its competitiveness in terms of overall video quality and adherence to textual descriptions.
read the caption
Table 1: Quantitative results. The best is in bold. Addressing the 'copy-paste' issue that leads to reduced facial similarity.
In-depth insights#
Multimodal Fusion#
The concept of ‘Multimodal Fusion’ in the context of this research paper is crucial for achieving identity-preserving human video generation. The core idea revolves around combining different data modalities, such as textual descriptions and visual features (facial and full-body), to create a more holistic representation of the individual. This approach goes beyond simply using facial images for identity, which can lead to rigid expressions and ‘copy-paste’ artifacts. Instead, the fusion of multimodal data allows the model to learn higher-level semantic information about the subject, leading to more realistic, coherent, and consistent videos. The success of this method hinges on the ability to resolve potential conflicts between these modalities (e.g., a textual description of an adult might conflict with an input image of a child). Therefore, careful design of the fusion module is paramount, likely involving techniques that prioritize high-level semantic features while mitigating the over-reliance on low-level details that could introduce artifacts. Ultimately, the efficacy of the fusion process is critical in determining the quality, consistency, and identity preservation capabilities of the generated videos. Effective fusion is therefore a key differentiator between the proposed method and prior approaches that struggled with low similarity and artifacts.
Identity Preservation#
The concept of “Identity Preservation” in the context of video generation is crucial for creating realistic and believable videos. It focuses on maintaining the visual identity of a person throughout a generated video, preventing inconsistencies or artifacts. The challenges are significant; current methods often suffer from “copy-paste” issues where facial features are rigidly transferred, lacking natural variation, or struggle to match the identity with the textual prompt’s description. Multimodal feature fusion is presented as a key strategy to tackle these issues; by combining text, facial, and full-body features, a more coherent and accurate representation of identity is achieved. This fusion not only helps resolve conflicts between different modalities but also enables the generation of videos exhibiting high-quality, controllable identity and fidelity. The success of this approach hinges on effectively decoupling relevant identity information from extraneous details within the input image, ensuring that only crucial features contribute to identity preservation. Deep learning models play a vital role in achieving this; by training on diverse data and employing appropriate loss functions, the model learns to synthesize video that preserves identity across different poses, expressions, and lighting conditions.
IITF Module#
The Identity Image-Text Fusion (IITF) module is a crucial component of the EchoVideo architecture, designed to resolve semantic conflicts and enhance identity preservation in generated videos. It achieves this by effectively integrating high-level semantic features from text with both overall and detailed facial features from the input image. Unlike prior methods using separate cross-attention mechanisms for text and image, IITF’s pre-fusion integration simplifies the process and allows for more seamless and coherent incorporation of multimodal information. This unified approach is key to generating consistent character traits, avoiding discrepancies between the text prompt and the facial features presented in the generated video. The module employs a learnable mapping to align the feature spaces of the facial features, ensuring compatibility, and further leverages a multi-layer perceptron (MLP) to combine and refine these features before they inform the video generation process. This results in improved video quality, a reduction in artifacts like “copy-paste” issues, and a higher degree of control over the generated character’s identity and overall appearance. The pluggable design of IITF also suggests potential adaptability for use in other video generation models.
Diffusion Model#
The section on “Diffusion Models” would delve into the core technology underpinning the EchoVideo system. It would likely begin by explaining the fundamental principles of diffusion models, highlighting their iterative process of adding noise to data (forward diffusion) and then progressively removing that noise to generate new samples (reverse diffusion). A key aspect would be how these models learn the complex data distributions required for realistic video generation, potentially emphasizing the use of Markov chains and the Gaussian noise process involved. The discussion may also cover different variations of diffusion models, their strengths and limitations in generating high-quality videos, and how the model handles temporal coherence essential for video. The authors might explain modifications or adaptations they made to standard diffusion models to address challenges such as identity preservation, and possibly compare their approach to other existing methods.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a video generation model like EchoVideo, this would involve removing modules like the IITF (Identity Image-Text Fusion) module or altering the training strategy (e.g., removing the two-stage approach). The results reveal the importance of each component; for example, removing the IITF might lead to a significant drop in identity preservation and an increase in semantic inconsistencies, while removing the two-stage training could reduce the quality of generated videos. Analyzing the quantitative metrics (e.g., CLIPScore, FID, FaceSim) after each ablation provides concrete evidence of each component’s impact. Such an analysis would not only validate the design choices made but also offer insights into potential areas for future improvement. By understanding how each element affects the overall performance, researchers can optimize model architecture, refine training procedures, or focus future research on specific problematic areas that ablation reveals.
More visual insights#
More on figures

🔼 Figure 2 illustrates two common problems in identity-preserving video generation. In (a), a semantic conflict occurs: the input image shows a child, but the text prompt describes an adult male. The model struggles to reconcile this mismatch, resulting in inconsistencies in the generated character’s features. In (b), the ‘copy-paste’ issue is shown, where the model over-relies on the input facial image, directly copying its features without proper integration with the textual prompt, leading to unnatural and unrealistic results. This demonstrates the need for a more sophisticated approach that harmoniously integrates textual and visual information.
read the caption
Figure 2: Issues in IP character generation. (a) Semantic conflict. The input image depicts a child’s face, while the prompt specifies an adult male. Insufficient information interaction leads to inconsistent character traits in the model’s output. (b) Copy-paste. During training, the model overly relies on visual information from facial images, directly using the Variational Autoencoder(VAE)-encoded [1] face as the output for the generated face.

🔼 EchoVideo’s architecture centers around a diffusion transformer (DiT) model. It leverages an Identity Image-Text Fusion (IITF) module to combine high-level semantic features from text with facial identity information from an input image. The IITF module is designed to extract clean identity representations and to resolve potential semantic conflicts between text and image information. The system avoids over-reliance on the input image, preventing ‘copy-paste’ artifacts and generating more consistent and coherent characters with multi-view facial coherence across different perspectives. The overall process ensures that generated videos maintain both visual and semantic fidelity.
read the caption
Figure 3: Overall architecture of EchoVideo. By employing a meticulously designed IITF module and mitigating the over-reliance on input images, our model effectively unifies the semantic information between the input facial image and the textual prompt. This integration enables the generation of consistent characters with multi-view facial coherence, ensuring that the synthesized outputs maintain both visual and semantic fidelity across diverse perspectives.

🔼 Figure 4 illustrates two approaches for incorporating facial and textual information into a video generation model. (a) shows a ‘dual branch’ method where facial and textual features are processed independently through cross-attention mechanisms before influencing the video generation process. This approach can lead to inconsistencies because the features are not directly integrated. (b) showcases the Identity Image-Text Fusion (IITF) module, which fuses facial and textual information, ensuring consistent guidance throughout the generation process. This fusion aims to resolve potential conflicts between facial appearance and the text description and produce more coherent and accurate results.
read the caption
Figure 4: Illustration of facial information injection methods. (a) Dual branch. Facial and textual information are independently injected through Cross Attention mechanisms, providing separate guidance for the generation process. (b) IITF. Facial and textual information are fused to ensure consistent guidance throughout the generation process.

🔼 Figure 5 presents a qualitative comparison of video generation results from three different methods: the proposed EchoVideo model, ConsisID [10], and ID-Animator [8]. Each column shows example videos generated using the respective methods. The figure highlights EchoVideo’s ability to effectively avoid common issues such as semantic conflicts (inconsistencies between the text prompt and generated visuals) and the ‘copy-paste’ artifact (where parts of the input image are directly replicated in the output without proper integration). EchoVideo consistently maintains high facial identity preservation (IP).
read the caption
Figure 5: Qualitative results. (a) Ours. (b) ConsisID [10]. (c) ID-Animator [8]. Our model can effectively overcome semantic conflicts and copy-paste phenomena while maintaining the face IP.

🔼 This figure demonstrates the impact of the Identity Image-Text Fusion (IITF) module on video generation. Subfigure (a) shows the results without IITF, illustrating inconsistencies between the generated face and the text prompt. The generated faces often do not match the prompt’s description of the person, demonstrating limitations in semantic understanding and identity preservation. Subfigure (b) shows how IITF addresses these issues by effectively extracting facial semantics from images, resolving conflicts between text and image data. The result is consistent character traits in generated videos that accurately reflect both the facial image and textual description, thus successfully preserving the identity of the person depicted.
read the caption
Figure 6: Effect of the IITF module. (a) Without IITF. (b) With IITF. IITF can effectively extract facial semantic information and resolve conflicts with text information, generating consistent characters while maintaining the face IP.

🔼 This figure demonstrates the impact of incorporating facial visual features, encoded by a Variational Autoencoder (VAE), on the quality of generated videos. Subfigure (a) shows the results when these features are omitted; the generated faces lack detail and appear blurry. Subfigure (b) presents the results when the VAE-encoded facial features are included. The addition of this information significantly enhances the level of facial detail in the generated videos, leading to more realistic and visually appealing results. This highlights the importance of incorporating the additional low-level facial information in order to complement the high-level semantic information for improved video generation.
read the caption
Figure 7: Effect of using facial visual features encoded by VAE. (a) Without face visual features. (b) With face visual features. By using the facial visual information , the facial details in the generated video can be effectively supplemented.
More on tables
| Models | CLIPScore | DynamicDegree | AestheticQuality | FID | FaceSim |
|---|---|---|---|---|---|
| w/o IITF | 31.418 | 0.722 | 0.579 | 254.469 | 0.025 |
| w/o Two-Stage | 29.480 | 0.606 | 0.587 | 155.557 | 0.135 |
| EchoVideo | 30.567 | 0.771 | 0.601 | 154.678 | 0.138 |
🔼 This table presents the results of an ablation study to evaluate the impact of the Identity Image-Text Fusion (IITF) module and the two-stage training strategy on the performance of the EchoVideo model. The study compares the model’s performance with both components included, with only the IITF module removed, with only the second training stage removed and with both components removed. The metrics used for comparison include CLIPScore (measuring adherence to text prompts), Dynamic Degree (representing the dynamism of generated videos), Aesthetic Quality (perceived quality), FID (Fréchet Inception Distance, assessing generated video realism), and FaceSim (measuring facial similarity between generated video and input image). The results illustrate the contribution of each component to overall model effectiveness.
read the caption
Table 2: Ablation study on IITF and training strategy. 'w/o IITF' denotes the exclusion of IITF module. 'w/o Two-Stage' indicates the omission of the second training stage.
| All Gender | Man | Woman | |
| Overall Quality | -11.15% | -9.42% | -13.04% |
🔼 This table presents the results of a user study comparing EchoVideo’s performance to that of a state-of-the-art method (ConsisID [10]). The study involved human evaluation of 529 video pairs, with each pair consisting of a video generated by EchoVideo and a video generated by the comparative method. For each video pair, five annotators independently rated the video quality, assigning scores of ‘good’, ‘same’, or ‘bad’. The table shows the net good rate for all videos as well as a breakdown by gender (male and female) to highlight any potential gender-related biases in the evaluation.
read the caption
Table 3: User study between EchoVideo and state-of-the-art method[10]. Each column displays the net good rate (good%-bad%).
Full paper#