TL;DR#
Current video generation models struggle with issues like unstable motion, visual quality, and alignment with user prompts. This is mainly due to limited high-quality preference data and the difficulty of adapting existing alignment methods to advanced flow-based models.
This paper tackles these problems by introducing VideoReward, a multi-dimensional reward model trained on a large-scale human preference dataset. It also proposes three novel alignment algorithms that leverage human feedback to improve the quality of flow-based video generation models. Experimental results show that VideoReward and these algorithms significantly outperform existing models, leading to videos with smoother motion, better visual quality, and improved alignment with user prompts.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation because it directly addresses the persistent challenges of unstable motion, misalignment with user prompts, and unsatisfactory visual quality. The proposed method of using human feedback to improve the alignment of video generation models is highly relevant to current research trends focused on improving generative models using human preferences. It introduces novel techniques for flow-based models, pushing the boundaries of what’s possible and opening new avenues for further research.
Visual Insights#

🔼 This figure illustrates the pipeline for aligning video generation models with human preferences. Panel (a) shows the creation of a human preference dataset: 182,000 triplets of video pairs (A and B) generated from prompts, rated by human evaluators across three dimensions: Visual Quality (VQ), Motion Quality (MQ), and Text Alignment (TA). Panel (b) details the training of a Vision-Language Model (VLM) based reward model using the Bradley-Terry model with ties to predict preference scores based on the dataset. Panel (c) outlines the three alignment algorithms applied to flow-based video generation models: Direct Preference Optimization (DPO), Reward Weighted Regression (RWR), and reward guidance, comparing their effectiveness.
read the caption
Figure 1: Overview of Our Video Alignment Paradigm. (a) Human Preference Annotation (Sec. 3.1). We construct a dataset of 182k (prompt, video A, video B) triplets, collecting preference annotations on Visual Quality (VQ), Motion Quality (MQ), and Text Alignment (TA) from human evaluators. (b) Reward Mode Training (Sec. 3.2). We train a VLM-based reward model using the Bradley-Terry-Model-with-Ties formulation. (c) Video Alignment (Sec. 4). We adapt alignment techniques — DPO, RWR, and reward guidance — to flow-based video generation models and provide a comprehensive comparison of their effectiveness.
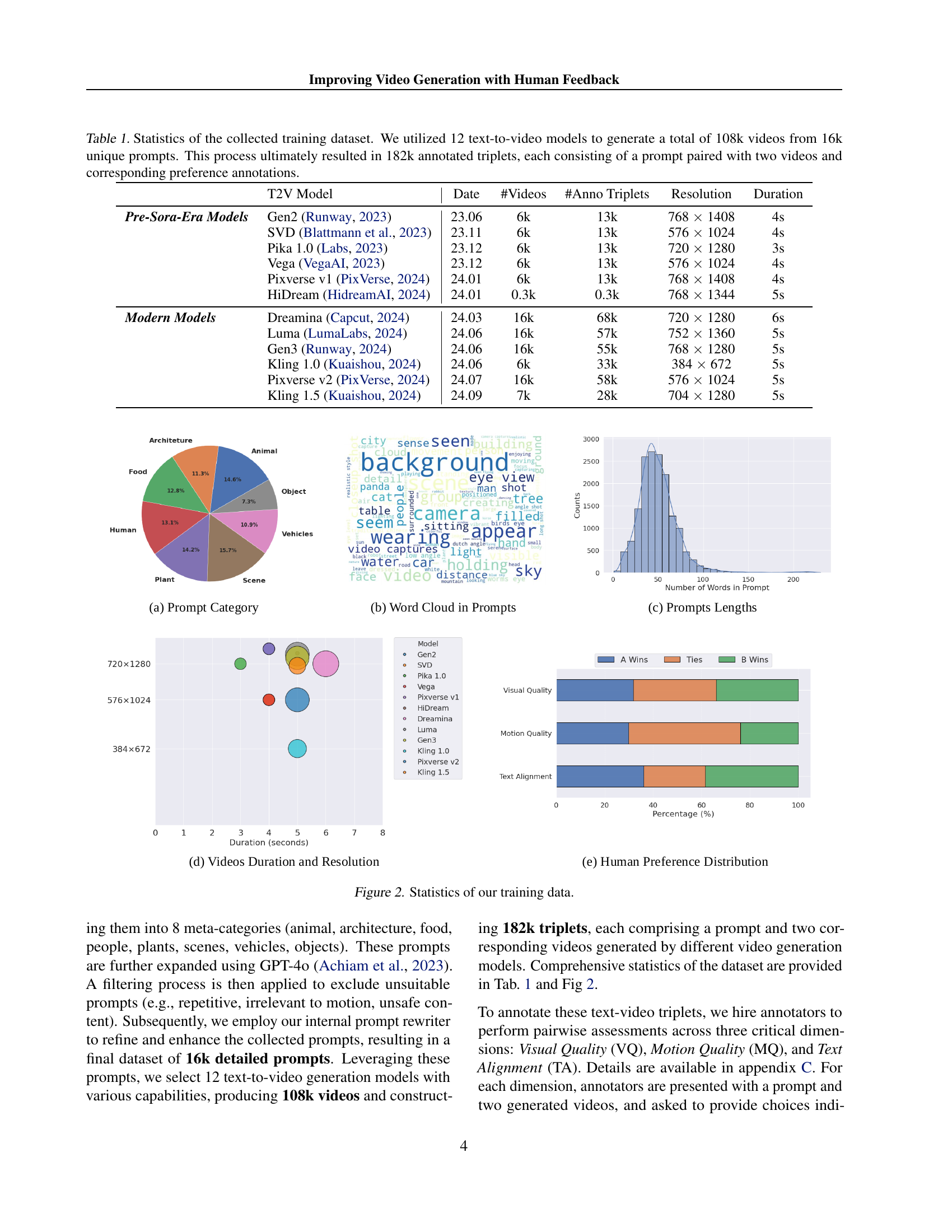
| T2V Model | Date | #Videos | #Anno Triplets | Resolution | Duration | |
| Pre-Sora-Era Models | Gen2 (Runway, 2023) | 23.06 | 6k | 13k | 768 1408 | 4s |
| SVD (Blattmann et al., 2023) | 23.11 | 6k | 13k | 576 1024 | 4s | |
| Pika 1.0 (Labs, 2023) | 23.12 | 6k | 13k | 720 1280 | 3s | |
| Vega (VegaAI, 2023) | 23.12 | 6k | 13k | 576 1024 | 4s | |
| Pixverse v1 (PixVerse, 2024) | 24.01 | 6k | 13k | 768 1408 | 4s | |
| HiDream (HidreamAI, 2024) | 24.01 | 0.3k | 0.3k | 768 1344 | 5s | |
| Modern Models | Dreamina (Capcut, 2024) | 24.03 | 16k | 68k | 720 1280 | 6s |
| Luma (LumaLabs, 2024) | 24.06 | 16k | 57k | 752 1360 | 5s | |
| Gen3 (Runway, 2024) | 24.06 | 16k | 55k | 768 1280 | 5s | |
| Kling 1.0 (Kuaishou, 2024) | 24.06 | 6k | 33k | 384 672 | 5s | |
| Pixverse v2 (PixVerse, 2024) | 24.07 | 16k | 58k | 576 1024 | 5s | |
| Kling 1.5 (Kuaishou, 2024) | 24.09 | 7k | 28k | 704 1280 | 5s |
🔼 This table presents a summary of the dataset used to train the video reward model. It details the number of videos generated, the number of unique prompts used, and the final number of annotated triplets. Each triplet contains a prompt and two videos, with human annotations indicating which video is preferred. The table also specifies the pre- and post-Sora era models used to generate the videos, reflecting the evolution in video generation technology.
read the caption
Table 1: Statistics of the collected training dataset. We utilized 12 text-to-video models to generate a total of 108k videos from 16k unique prompts. This process ultimately resulted in 182k annotated triplets, each consisting of a prompt paired with two videos and corresponding preference annotations.
In-depth insights#
Human Feedback in VideoGen#
Human feedback is crucial for enhancing video generation models. VideoGen models often struggle with issues like unstable motion, misalignment with prompts, and subpar visual quality. Integrating human feedback provides a way to address these shortcomings. This could involve creating large-scale preference datasets where users rate the quality of generated videos along various dimensions, such as visual fidelity, motion coherence, and alignment with the prompt. These datasets can be used to train reward models that quantify video quality. Subsequently, reinforcement learning methods can be employed to align the video generation model with human preferences, as reflected in the reward signals. A key aspect would involve developing sophisticated reward models capable of capturing the multifaceted nature of human preferences, particularly in the context of video, which is more complex than static images. Finally, it’s important to consider how to efficiently incorporate human feedback into the training process, balancing the need for large-scale data with the cost and time involved in human annotation. The focus should be on developing techniques to mitigate reward hacking and ensuring that the alignment process doesn’t negatively impact the model’s capabilities in other aspects.
Multi-Dimensional Reward#
The concept of “Multi-Dimensional Reward” in video generation signifies a shift from simplistic, single-metric evaluations (like FID or CLIP scores) to a more nuanced approach. It acknowledges that human judgment of video quality isn’t solely based on visual fidelity but encompasses multiple facets. The use of multiple dimensions, such as visual quality, motion smoothness, and alignment with textual prompts, offers a more holistic understanding of video generation success. This allows for the creation of reward models that better capture human preferences, leading to more effective reinforcement learning strategies. However, designing and training these multi-dimensional reward models presents challenges. Annotation becomes more complex, requiring careful consideration of how each dimension is weighted and measured. There’s also the risk of dimensionality conflicts, where improving one aspect negatively affects others. Successfully addressing these challenges is crucial to creating truly human-aligned video generation systems that prioritize a balanced and comprehensive measure of quality.
Flow-Based Alignment#
The section on ‘Flow-Based Alignment’ would delve into the challenges of adapting existing alignment techniques from diffusion models to the newer flow-based video generation models. It would likely highlight the differences in how these models generate videos – diffusion models progressively denoise latent representations, whereas flow-based models directly predict velocities. This key difference necessitates the development of novel alignment algorithms specifically tailored to the characteristics of flow-based models. The discussion would likely cover the rationale behind extending the existing training-time (DPO and RWR) and inference-time (NRG) algorithms from diffusion to flow-based models. A critical aspect would be the evaluation and comparison of these three new alignment algorithms. The findings would demonstrate the effectiveness of these algorithms in optimizing flow-based video generation models according to human preferences and potentially highlight the performance differences between the proposed algorithms and traditional supervised fine-tuning approaches. The section likely concludes with a discussion on the trade-offs between training-time and inference-time methods, emphasizing aspects like efficiency and user control over model alignment.
Reward Model Ablation#
A reward model ablation study systematically investigates the impact of design choices on a reward model’s effectiveness in aligning video generation models with human preferences. Different reward model architectures, such as Bradley-Terry and regression models, are compared, revealing the strengths and weaknesses of each approach in capturing human preferences. The study further explores the impact of incorporating tie annotations, demonstrating that accounting for ties in the data improves the model’s ability to capture nuanced preferences. Key design choices, like the use of separate tokens for multi-dimensional rewards, are also examined and shown to significantly influence the reward model’s performance by reducing coupling among reward dimensions. The results highlight the importance of carefully considering both the model architecture and data handling techniques when designing reward models for video generation applications.
Future of Video Alignment#
The future of video alignment hinges on addressing current limitations. Scaling up high-quality human preference datasets is crucial, moving beyond existing datasets limited in size and video quality. Developing more robust reward models that avoid reward hacking, perhaps using techniques that incorporate uncertainty estimates or improved annotation methods, is vital. Exploring alternative alignment algorithms beyond direct preference optimization (DPO) and reward-weighted regression (RWR) might yield improved results and address issues like instability. Research should investigate the use of techniques that better handle multi-modal data and leverage the strengths of large language models (LLMs) for improved alignment. Finally, transfer learning and few-shot learning approaches are promising avenues to reduce the significant computational cost associated with current alignment methods and make the process more accessible.
More visual insights#
More on figures

🔼 Figure 2 presents a comprehensive statistical overview of the training dataset used in the study. It includes visualizations of the distribution of prompts across different categories, a word cloud illustrating the most frequent words used in prompts, a bar chart illustrating prompt lengths, and a distribution of video durations and resolutions.
read the caption
Figure 2: Statistics of our training data.

🔼 This figure compares the performance of two reward model types: Bradley-Terry (BT) and regression models, across different training dataset sizes. The x-axis represents the fraction of the training data used (on a logarithmic scale), and the y-axis shows the resulting accuracy of each model type. The plot demonstrates how the accuracy of both models improves as more training data is available. Notably, the Bradley-Terry model consistently outperforms the regression model, particularly with smaller datasets. This suggests that for limited data, pairwise comparisons (as used in BT) are more effective at capturing relative quality scores than direct regression.
read the caption
Figure 3: Accuracy comparison between the BT and regression reward models across varying training data fractions (log scale).

🔼 This figure compares the distributions of the reward difference (Δr) between two videos for the Bradley-Terry (BT) model and the Bradley-Terry-with-Ties (BTT) model. The BT model struggles to differentiate between videos rated as ties and those clearly preferred or rejected, exhibiting overlap in their Δr values. In contrast, the BTT model shows a clear separation between tied pairs and chosen/rejected pairs. This demonstrates the BTT model’s improved ability to handle tied preferences in reward modeling.
read the caption
Figure 4: Visualization of the ΔrΔ𝑟\Delta rroman_Δ italic_r distribution for the BT reward model (Left) and the BTT reward model (Right). The BTT model effectively distinguishes tie pairs from chosen/rejected pairs.

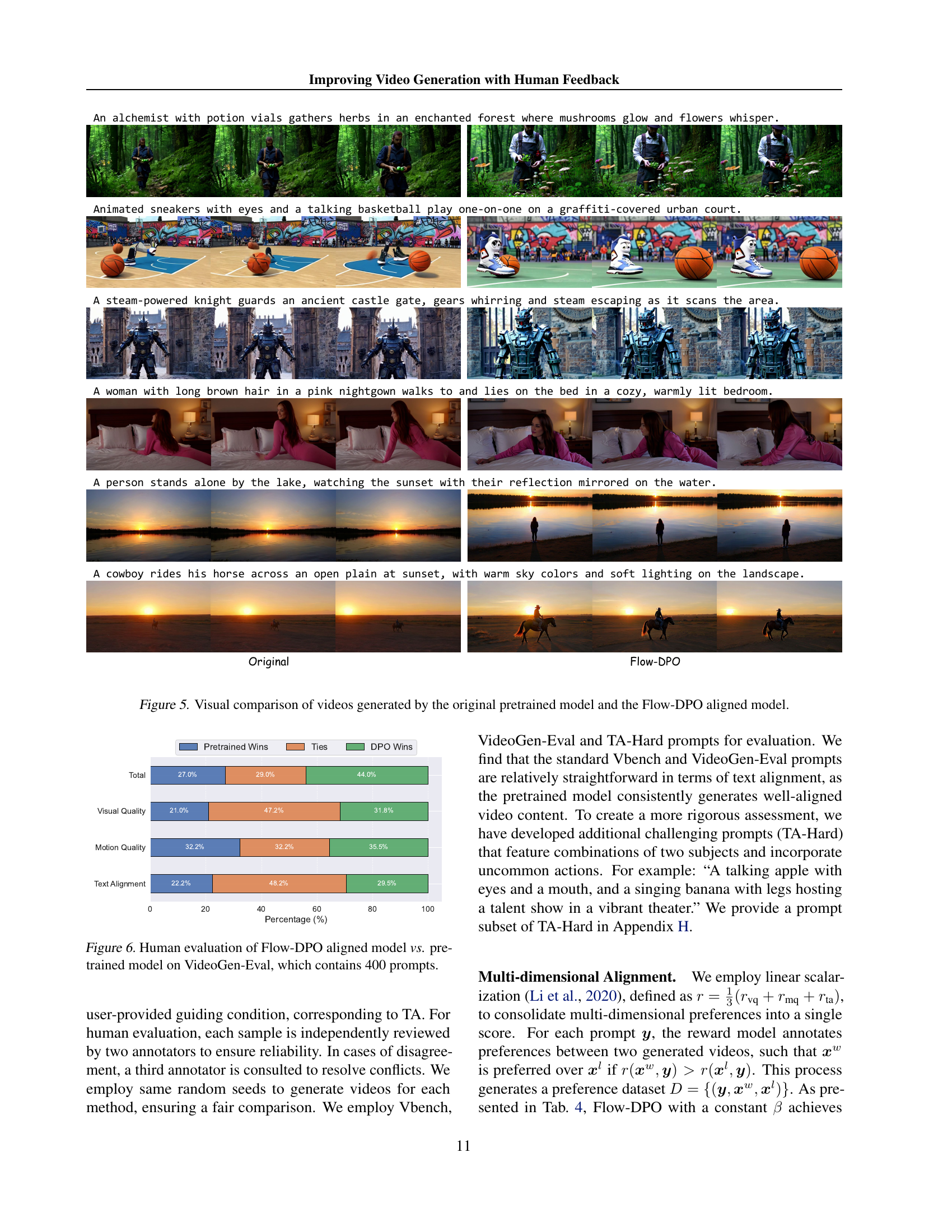
🔼 This figure presents a visual comparison of videos generated using two different methods: (1) a pretrained video generation model and (2) the same model after being aligned using the Flow-DPO algorithm. The figure shows six video examples, each illustrating a scene described by a text prompt. Each example includes a side-by-side comparison of the video generated by the pretrained model and the video generated by the Flow-DPO-aligned model, allowing viewers to visually assess the differences in visual quality, motion, and overall coherence between the two methods.
read the caption
Figure 5: Visual comparison of videos generated by the original pretrained model and the Flow-DPO aligned model.

🔼 This figure presents the results of a human evaluation comparing videos generated by a pretrained video generation model and a Flow-DPO aligned model. The evaluation was conducted on the VideoGen-Eval dataset, which includes 400 prompts. The evaluation metrics used were Visual Quality, Motion Quality, and Text Alignment. The results are presented in a bar chart showing the percentage of wins for each model in each category. The chart displays the number of times videos from either model were preferred in terms of Visual Quality, Motion Quality, and Text Alignment, as well as the frequency of ties.
read the caption
Figure 6: Human evaluation of Flow-DPO aligned model vs. pretrained model on VideoGen-Eval, which contains 400 prompts.

🔼 This figure compares the performance of Flow-DPO, a video generation alignment algorithm, using two different strategies for the KL divergence regularization term (β). The first strategy uses a time-dependent β (βt = β(1-t)²), where β changes throughout the video generation process. The second uses a constant β. The results are shown for Text Alignment (TA) task. The figure shows that Flow-DPO with a constant β consistently outperforms the time-dependent β across various settings. This suggests that a fixed KL divergence regularization strength is more effective for aligning the model than a varying strength.
read the caption
Figure 7: Accuracy of time-dependent βtsubscript𝛽𝑡\beta_{t}italic_β start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT vs. constant β𝛽\betaitalic_β for TA: Flow-DPO with a constant β𝛽\betaitalic_β consistently outperforms the timestep-dependent β𝛽\betaitalic_β across various settings.

🔼 This figure is a comparison of video durations and resolutions present in the GenAI-Bench and VideoGen-RewardBench datasets. The GenAI-Bench dataset contains videos generated by models from before the release of the Sora model, while the VideoGen-RewardBench dataset includes videos from more modern, state-of-the-art models. The chart visually shows the distribution of video durations (in seconds) across different resolutions for both datasets, allowing for a direct comparison of the characteristics of videos included in each benchmark.
read the caption
Figure 8: Video Duration and Resolution in GenAI-Bench and VideoGen-Reward Bench

🔼 Figure 9 is a timeline visualization showing the model coverage of various datasets used in the paper. It illustrates the temporal distribution of different text-to-video (T2V) models used in the training sets of different baselines (VideoScore, VisionReward, GenAI-Bench) and the two evaluation benchmarks (GenAI-Bench and VideoGen-RewardBench). The figure highlights that earlier baselines primarily utilized pre-SoRA era models, while the paper’s training set and newer VideoGen-RewardBench focus on state-of-the-art models. This shows the progression of models over time and the focus of the datasets utilized in the paper.
read the caption
Figure 9: The model coverage across the training sets of different baselines and the two evaluation benchmarks. VideoScore, VisionReward, and GenAI-Bench primarily focus on pre-SoRA-era models, while our training set and VideoGen-RewardBench concentrate on state-of-the-art T2V models.

🔼 This figure presents a human evaluation comparing the performance of the Flow-DPO model (with a constant beta) against the original pretrained model on a set of challenging prompts focusing on Text Alignment (TA-Hard). The results are broken down across three key dimensions: Visual Quality (VQ), Motion Quality (MQ), and Text Alignment (TA). The bar chart shows the percentage of wins for each model in each dimension, as well as the percentage of ties observed. This allows for a detailed assessment of how effectively Flow-DPO improves text alignment in video generation while also considering the potential trade-offs in visual and motion quality.
read the caption
Figure 10: Human evaluation of Flow-DPO on TA-Hard prompt.
More on tables
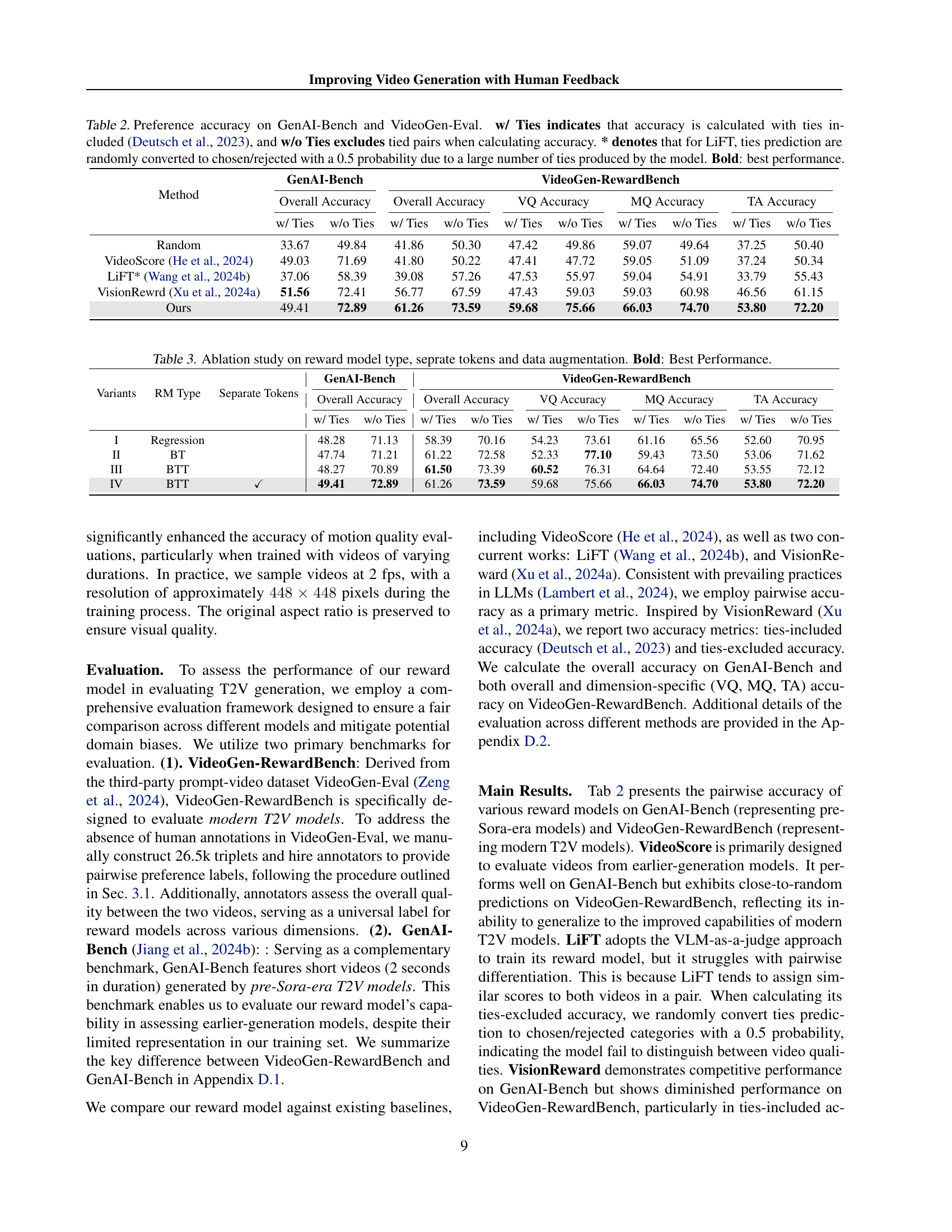
| Method | GenAI-Bench | VideoGen-RewardBench | ||||||||
| Overall Accuracy | Overall Accuracy | VQ Accuracy | MQ Accuracy | TA Accuracy | ||||||
| w/ Ties | w/o Ties | w/ Ties | w/o Ties | w/ Ties | w/o Ties | w/ Ties | w/o Ties | w/ Ties | w/o Ties | |
| Random | 33.67 | 49.84 | 41.86 | 50.30 | 47.42 | 49.86 | 59.07 | 49.64 | 37.25 | 50.40 |
| VideoScore (He et al., 2024) | 49.03 | 71.69 | 41.80 | 50.22 | 47.41 | 47.72 | 59.05 | 51.09 | 37.24 | 50.34 |
| LiFT* (Wang et al., 2024b) | 37.06 | 58.39 | 39.08 | 57.26 | 47.53 | 55.97 | 59.04 | 54.91 | 33.79 | 55.43 |
| VisionRewrd (Xu et al., 2024a) | 51.56 | 72.41 | 56.77 | 67.59 | 47.43 | 59.03 | 59.03 | 60.98 | 46.56 | 61.15 |
| Ours | 49.41 | 72.89 | 61.26 | 73.59 | 59.68 | 75.66 | 66.03 | 74.70 | 53.80 | 72.20 |
🔼 This table presents a comparison of the performance of various reward models on two benchmark datasets: GenAI-Bench and VideoGen-RewardBench. The GenAI-Bench dataset contains videos generated by pre-SOTA models, while the VideoGen-RewardBench dataset contains videos from modern models. The table reports the overall accuracy, as well as the accuracy for three specific dimensions (Visual Quality, Motion Quality, and Text Alignment) on both datasets. Two accuracy metrics are reported: one including ties in the pairwise comparisons and another excluding ties. A special note is made for the LiFT model, as its predictions on ties were randomly converted due to the high number of ties it generated. The model with the best performance in each category is shown in bold.
read the caption
Table 2: Preference accuracy on GenAI-Bench and VideoGen-Eval. w/ Ties indicates that accuracy is calculated with ties included (Deutsch et al., 2023), and w/o Ties excludes tied pairs when calculating accuracy. * denotes that for LiFT, ties prediction are randomly converted to chosen/rejected with a 0.5 probability due to a large number of ties produced by the model. Bold: best performance.
| Variants | RM Type | Separate Tokens | GenAI-Bench | VideoGen-RewardBench | ||||||||
| Overall Accuracy | Overall Accuracy | VQ Accuracy | MQ Accuracy | TA Accuracy | ||||||||
| w/ Ties | w/o Ties | w/ Ties | w/o Ties | w/ Ties | w/o Ties | w/ Ties | w/o Ties | w/ Ties | w/o Ties | |||
| I | Regression | 48.28 | 71.13 | 58.39 | 70.16 | 54.23 | 73.61 | 61.16 | 65.56 | 52.60 | 70.95 | |
| II | BT | 47.74 | 71.21 | 61.22 | 72.58 | 52.33 | 77.10 | 59.43 | 73.50 | 53.06 | 71.62 | |
| III | BTT | 48.27 | 70.89 | 61.50 | 73.39 | 60.52 | 76.31 | 64.64 | 72.40 | 53.55 | 72.12 | |
| IV | BTT | ✓ | 49.41 | 72.89 | 61.26 | 73.59 | 59.68 | 75.66 | 66.03 | 74.70 | 53.80 | 72.20 |
🔼 This ablation study analyzes the impact of different reward model architectures, token separation strategies, and data augmentation techniques on the overall performance of the reward model. It compares the Bradley-Terry (BT), Bradley-Terry-with-Ties (BTT), and regression-based reward models. It also investigates the effect of using separate tokens for multi-dimensional reward modeling. Finally, it examines the influence of data augmentation techniques on the model’s accuracy. The results are presented as overall accuracy and the accuracy for Visual Quality (VQ), Motion Quality (MQ), and Text Alignment (TA) dimensions. The bold values highlight the best-performing configurations.
read the caption
Table 3: Ablation study on reward model type, seprate tokens and data augmentation. Bold: Best Performance.
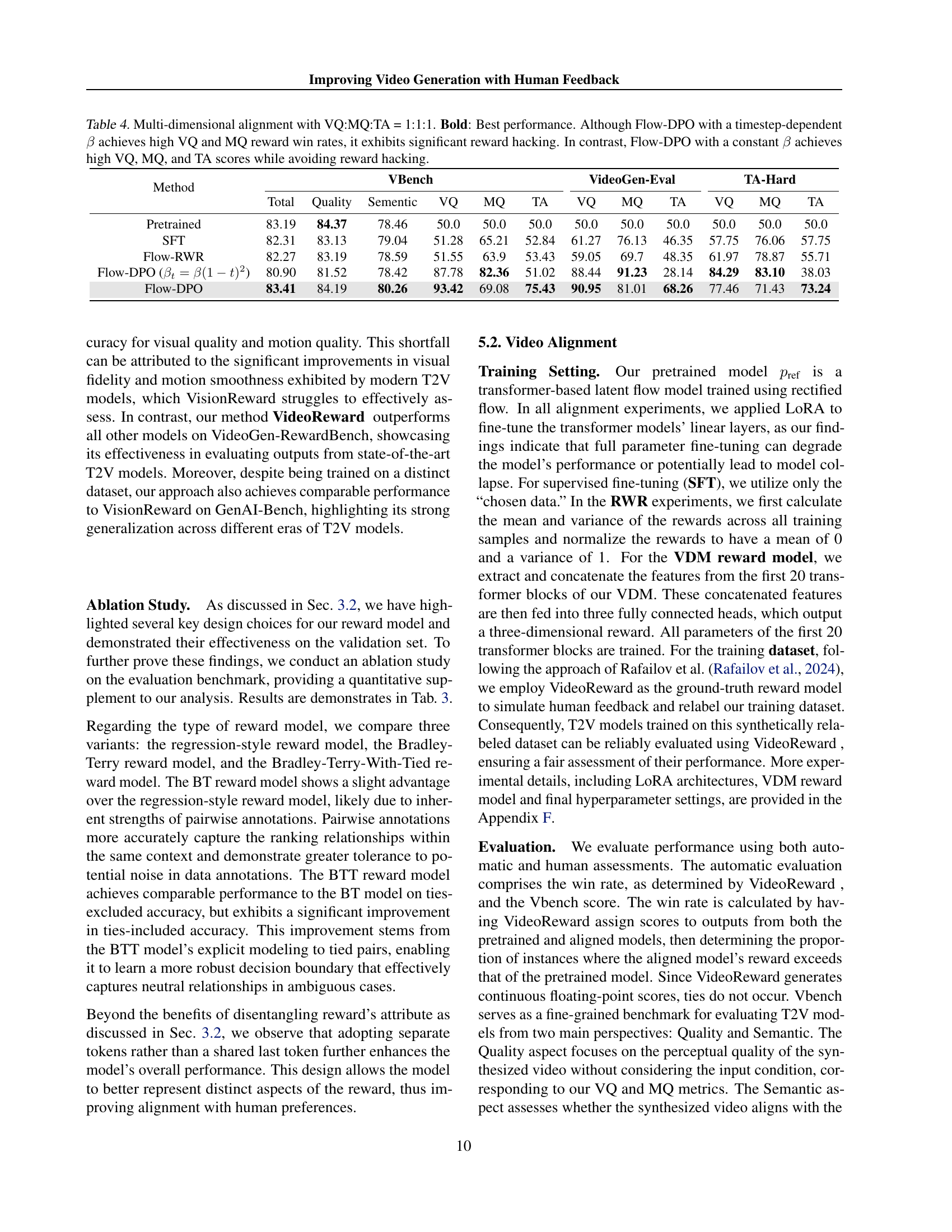
| Method | VBench | VideoGen-Eval | TA-Hard | |||||||||
| Total | Quality | Sementic | VQ | MQ | TA | VQ | MQ | TA | VQ | MQ | TA | |
| Pretrained | 83.19 | 84.37 | 78.46 | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 | 50.0 |
| SFT | 82.31 | 83.13 | 79.04 | 51.28 | 65.21 | 52.84 | 61.27 | 76.13 | 46.35 | 57.75 | 76.06 | 57.75 |
| Flow-RWR | 82.27 | 83.19 | 78.59 | 51.55 | 63.9 | 53.43 | 59.05 | 69.7 | 48.35 | 61.97 | 78.87 | 55.71 |
| Flow-DPO () | 80.90 | 81.52 | 78.42 | 87.78 | 82.36 | 51.02 | 88.44 | 91.23 | 28.14 | 84.29 | 83.10 | 38.03 |
| Flow-DPO | 83.41 | 84.19 | 80.26 | 93.42 | 69.08 | 75.43 | 90.95 | 81.01 | 68.26 | 77.46 | 71.43 | 73.24 |
🔼 This table presents the results of a multi-dimensional video alignment experiment using three different methods: supervised fine-tuning (SFT), reward-weighted regression (Flow-RWR), and direct preference optimization (Flow-DPO). The experiment focuses on aligning a video generation model with human preferences across three dimensions: Visual Quality (VQ), Motion Quality (MQ), and Text Alignment (TA), with equal weighting (1:1:1). The table shows that Flow-DPO with a constant beta (β) significantly outperforms SFT and Flow-RWR, achieving high scores in all three dimensions without exhibiting ‘reward hacking’ (where the model prioritizes high rewards at the expense of overall quality). In contrast, Flow-DPO with a time-dependent beta achieves high VQ and MQ win rates but shows signs of reward hacking.
read the caption
Table 4: Multi-dimensional alignment with VQ:MQ:TA = 1:1:1. Bold: Best performance. Although Flow-DPO with a timestep-dependent β𝛽\betaitalic_β achieves high VQ and MQ reward win rates, it exhibits significant reward hacking. In contrast, Flow-DPO with a constant β𝛽\betaitalic_β achieves high VQ, MQ, and TA scores while avoiding reward hacking.
| Method | VBench | VideoGen-Eval | TA-Hard | |||
| Total | Quality | Semantic | TA | TA | TA | |
| Pretrained | 83.19 | 84.37 | 78.46 | 50.00 | 50.00 | 50.00 |
| SFT | 82.71 | 83.48 | 79.62 | 52.88 | 53.81 | 64.79 |
| Flow-RWR | 82.40 | 83.36 | 78.58 | 59.66 | 49.50 | 66.20 |
| Flow-DPO () | 82.35 | 83.00 | 79.75 | 63.67 | 55.95 | 71.83 |
| Flow-DPO | 83.38 | 84.28 | 79.80 | 69.09 | 65.49 | 84.51 |
🔼 This table presents the results of single-dimensional alignment experiments focusing on Text Alignment (TA). It compares the performance of several methods: Supervised Fine-Tuning (SFT), Reward Weighted Regression for Flow (Flow-RWR), and Direct Preference Optimization for Flow (Flow-DPO) with both a time-dependent and a constant beta parameter (β). The metrics presented likely include overall video quality scores as well as scores specific to TA. The results show that Flow-DPO with a constant beta value is the most effective approach for aligning the model with human preferences on the TA dimension, achieving high performance without exhibiting undesirable side effects (‘reward hacking’).
read the caption
Table 5: Single-dimensional alignment with TA. Bold: Best performance. Flow-DPO with a constant β𝛽\betaitalic_β is the most effective method, achieving best performance without reward hacking.
| VQ:MQ:TA | VQ | MQ | TA |
| 0:0:1 | 60.56 | 46.48 | 70.42 |
| 0.1:0.1:0.8 | 66.50 | 63.73 | 60.86 |
| 0.1:0.1:0.6 | 68.94 | 67.59 | 53.28 |
| 0.5:0.5:0 | 86.43 | 93.23 | 26.65 |
🔼 This table presents results demonstrating the effectiveness of reward guidance in aligning video generation models. The experiment uses VideoGen-Eval prompts and applies different weights to visual quality (VQ), motion quality (MQ), and text alignment (TA) objectives during the inference stage. This allows users to prioritize certain aspects of video quality, such as motion smoothness or text fidelity, leading to personalized video generation.
read the caption
Table 6: Reward guidance using multi-dimensional rewards on VideoGen-Eval prompts. The weighted reward guidence allows users to apply arbitrary weightings to multiple alignment objectives during inference to meet personalized user requirements.
| VQ | MQ | TA | |
| VDM w/o noise | 37.1 | 38.6 | 52.9 |
| VDM w/ noise | 66.2 | 74.6 | 32.4 |
🔼 This table presents an ablation study on the effect of using noisy versus clean latent representations when training a reward model for guiding video generation. The task is text-to-video generation focusing on Text Alignment (TA), a challenging aspect where the goal is to align the video content with the prompt description. The results show that a reward model trained with noisy latent representations (VDM w/ noise) effectively guides the video generation process, resulting in improved performance. Conversely, a model trained on clean latents (VDM w/o noise) fails to effectively guide generation when presented with noisy latents, highlighting the importance of training data that reflects the actual generation process.
read the caption
Table 7: Reward guidance using only MQ rewards on TA-Hard. The reward model trained with noised latents guides the generation effectively, while the model trained on cleaned latents fails to provide meaningful gradient guidance for noised latents.
| Evaluation Dimension | Key Points Summary | |||||||
| Visual Quality |
| |||||||
| Motion Quality |
| |||||||
| Text Alignment |
|
🔼 This table summarizes the key aspects annotators should focus on when evaluating videos based on three dimensions: Visual Quality, Motion Quality, and Text Alignment. For each dimension, it lists several criteria and sub-criteria that annotators should consider, providing detailed guidance for consistent and accurate assessments of video generation quality.
read the caption
Table 8: Key points summary outlined in annotation guidelines for each evaluation dimension.
| Considering the following dimensions introducted by non-dynamic factors: |
| - Image Reasonableness: The image should be objectively reasonable. |
| - Clarity: The image should be clear and visually sharp. |
| - Detail Richness: The level of intricacy in the generation of details. |
| - Aesthetic Creativity: The generated videos should be aesthetically pleasing. |
| - Safety: The generated video should not contain any disturbing or uncomfortable content. |
🔼 This table compares two benchmark datasets used to evaluate video generation models: GenAI-Bench and VideoGen-RewardBench. GenAI-Bench focuses on models from before the release of the Sora model (pre-Sora era), while VideoGen-RewardBench evaluates models released after Sora. The table details the number of samples, prompts, models (categorized as pre-Sora and post-Sora), video durations, and the number of human preference annotations in each dataset. This comparison highlights the differences in the types of models and video characteristics included in each benchmark.
read the caption
Table 9: Comparison between GenAI-Bench and VideoGen-RewardBench. Eariler Models indicates that pre-Sora-era T2V models, and Modern Models indicates that T2V models after Sora.
| Considering the following dimensions in the dynamic process of the video: |
| - Dynamic Stability: The continuity and stability between frames. |
| - Dynamic Reasonableness: The dynamic movement should align with natural physical laws. |
| - Motion Aesthetic Quality: The dynamic elements should be harmonious and not stiff. |
| - Naturalness of Dynamic Fusion: The edges should be clear during the dynamic process. |
| - Motion Clarity: The motion should be easy to identify. |
| - Dynamic Degree: The movement should be clear, avoiding still scenes. |
🔼 This table details the hyperparameters used for three different video alignment algorithms: Supervised Fine-Tuning (SFT), Reward Weighted Regression for Flow (Flow-RWR), and Direct Preference Optimization for Flow (Flow-DPO). It lists the training strategy employed (using Low-Rank Adaptation, or LoRA), the LoRA hyperparameters (alpha, dropout, rank, and target modules), the optimizer used (Adam), the learning rate, the number of epochs, and the batch size. For Flow-DPO, the KL divergence regularization parameter (β) is also specified.
read the caption
Table 10: Hyperparameters for Alignment Algorithms
| Considering the relevance to the input text prompt description. |
| - Subject Relevance Relevance to the described subject characteristics and subject details. |
| - Dynamic Information Relevance: Relevance to actions and postures as described in the text. |
| - Environmental Relevance: Relevance of the environment to the input text. |
| - Style Relevance: Relevance to the style descriptions, if exists. |
| - Camera Movement Relevance: Relevance to the camera descriptions, if exists. |
🔼 This table details the hyperparameters used in training the reward model. It breaks down the settings for both the Vision-Language Model (VLM) and the Video Diffusion Model (VDM) used in the reward model training process. Specific hyperparameters shown include training strategy, use of LoRA (Low-Rank Adaptation), LoRA hyperparameters (alpha, dropout, r, target modules), optimizer, learning rate, number of epochs, batch size, and the number of reward dimensions used.
read the caption
Table 11: Hyperparameters for reward modeling.
Full paper#