TL;DR#
Current video-LLMs often struggle with temporal grounding in long-form videos, mainly due to the limitations of the existing two-stage training paradigm and weakly aligned training signals. These models heavily rely on meticulous and expensive curated instruction-tuning datasets, and they often fail to grasp subtle temporal relationships present in long videos, resulting in suboptimal performance on tasks demanding fine-grained or long-context temporal grounding.
To tackle this, the authors present Temporal Preference Optimization (TPO). TPO is a novel post-training framework that enhances the temporal grounding abilities of video-LLMs using preference learning. It leverages curated preference datasets at two levels: localized and comprehensive temporal grounding, which allow the model to distinguish between well-grounded and less accurate temporal responses. By training on these preference datasets, TPO substantially improves temporal understanding and reduces reliance on manual annotations. Experiments show that TPO significantly improves the performance across various long-form video benchmarks, establishing the leading 7B model on Video-MME.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel post-training framework, Temporal Preference Optimization (TPO), to significantly improve the temporal grounding capabilities of large video-multimodal models. This addresses a critical challenge in long-form video understanding, where current models struggle to accurately identify and utilize temporal information. TPO’s self-training approach reduces reliance on manually annotated data, making it a scalable and efficient solution. The findings open avenues for advancing temporal reasoning in long-form video analysis and other related domains.
Visual Insights#

🔼 This figure illustrates the Temporal Preference Optimization (TPO) framework, a self-improvement method enhancing video-LMMs’ understanding. It operates at two levels: localized TPO, focusing on short video segments and contrasting responses that either include or exclude the target segment; and comprehensive TPO, using full versus downsampled videos to contrast responses to high-level queries. The resulting preference data, after filtering, trains the video-LMM to favor temporally accurate responses.
read the caption
Figure 1: Temporal Preference Optimization (TPO) is a self-improvement preference optimization technique designed to enhance video comprehension in video-LMMs by modeling temporal preferences at two granular levels: localized and comprehensive TPO. In localized TPO (upper-left), we generate queries focused on short segments, with contrastive responses that retain or exclude the target segment. For comprehensive TPO (lower-left), queries are designed for high-level understanding, using intact video versus sparse downsampled video for contrasting responses. After post-filtering, the contrast response pairs are serving as the preference dataset to train a video-LMM, guiding the model to prioritize preferred responses for improved video understanding.
| Model | LongVideoBench | MLVU (M-avg) | Video-MME | |||
|---|---|---|---|---|---|---|
| Short | Medium | Long | Average | |||
| LongVA-7B [63] | 51.3 | 58.8 | 61.1/61.6 | 50.4/53.6 | 46.2/47.6 | 52.6/54.3 |
| + SFT | 52.7 | 58.9 | 62.6/67.7 | 52.4/52.7 | 46.8/47.4 | 53.9/55.9 |
| + SFT | 53.1 | 59.9 | 63.7/64.9 | 52.6/54.3 | 46.3/47.9 | 54.2/55.7 |
| + Hound-DPO [64, 63] | 52.8 | 59.1 | 62.2/65.8 | 52.4/54.8 | 46.1/46.3 | 53.6/55.6 |
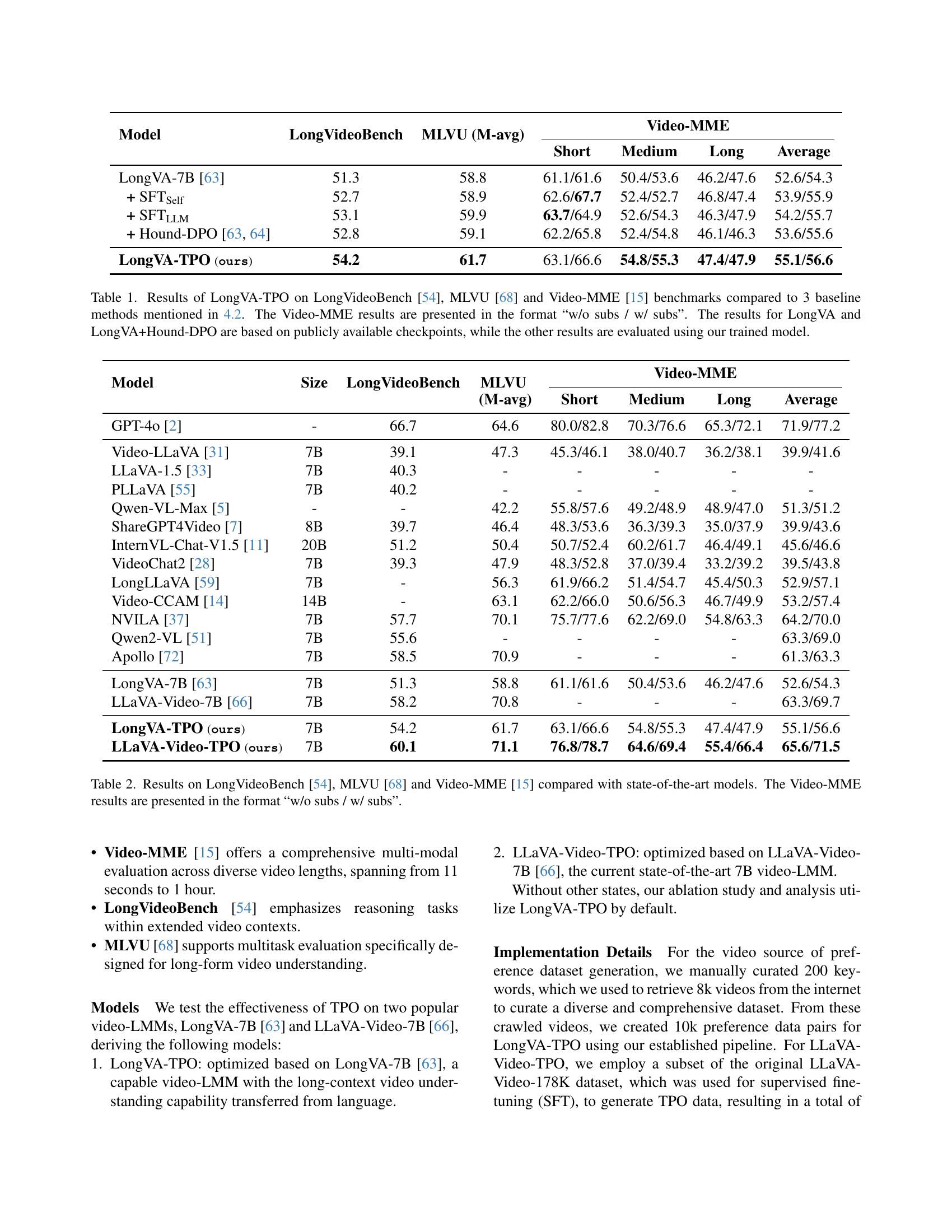
| LongVA-TPO (ours) | 54.2 | 61.7 | 63.1/66.6 | 54.8/55.3 | 47.4/47.9 | 55.1/56.6 |
🔼 This table presents a comparison of the performance of the proposed Temporal Preference Optimization (TPO) method against three baseline methods on three video understanding benchmarks: LongVideoBench, MLVU, and Video-MME. For each benchmark, the table shows the performance scores (presumably accuracy or a similar metric) for each method. The Video-MME benchmark results are further broken down into scores with and without subtitles (‘w/o subs / w/ subs’). Importantly, the results for the LongVA and LongVA+Hound-DPO methods are based on pre-trained, publicly available model weights, whereas the results for the other methods (including TPO) were obtained using models trained by the authors of the paper.
read the caption
Table 1: Results of LongVA-TPO on LongVideoBench [54], MLVU [68] and Video-MME [15] benchmarks compared to 3 baseline methods mentioned in 4.2. The Video-MME results are presented in the format “w/o subs / w/ subs”. The results for LongVA and LongVA+Hound-DPO are based on publicly available checkpoints, while the other results are evaluated using our trained model.
In-depth insights#
Temporal Grounding#
Temporal grounding in video understanding is a significant challenge, focusing on precisely locating events and actions within a video’s temporal dimension. Current methods often struggle with long-form videos, where complex temporal relationships and extended dependencies make accurate grounding difficult. This necessitates advanced techniques beyond simple frame-by-frame analysis. Preference learning emerges as a powerful technique, enabling models to learn nuanced temporal relationships by comparing preferred and dis-preferred responses. This approach is particularly valuable as it reduces reliance on expensive and time-consuming manual annotations. By incorporating various granularities of temporal preference data, from localized segments to comprehensive sequences, models can learn to prioritize temporally coherent responses. This improved grounding significantly enhances the model’s capacity to accurately answer questions requiring detailed temporal understanding, advancing the state-of-the-art in long-form video analysis.
Preference Learning#
Preference learning, a machine learning paradigm, focuses on learning from user preferences rather than explicit labels This is particularly valuable in scenarios where obtaining precise labels is difficult or expensive. In the context of video-LLMs, preference learning is a powerful technique for aligning model behavior with human expectations regarding temporal understanding. By training models on paired examples of preferred and less-preferred responses, often generated from variations in video segments or queries, the system learns to prioritize outputs consistent with human judgment on temporal grounding. This approach is especially effective when dealing with long-form videos, where sophisticated temporal reasoning is crucial but data annotation is expensive. Direct preference optimization (DPO) and other preference learning methods directly integrate user preference data into model training, offering a flexible and efficient alternative to traditional supervised approaches. This allows the model to learn nuanced temporal relationships and generate temporally grounded responses more effectively, thereby improving long-form video understanding capabilities. The choice of preference data granularity, either focused on specific video segments or encompassing the whole sequence, greatly influences the performance. Choosing a data strategy carefully enhances the effectiveness of preference learning for temporal reasoning in video-LLMs.
TPO Framework#
The Temporal Preference Optimization (TPO) framework is a novel post-training approach designed to enhance the temporal grounding capabilities of video-LLMs. Its core innovation lies in leveraging preference learning, moving beyond traditional supervised fine-tuning. TPO uses curated preference datasets at two granularities: localized temporal grounding (focusing on specific video segments) and comprehensive temporal grounding (capturing extended temporal dependencies). By contrasting preferred and dis-preferred responses, the model learns to prioritize temporally accurate and well-grounded answers. This self-training approach reduces reliance on manually annotated data, making it a more scalable and efficient solution for improving video understanding, especially for long-form videos. The framework shows promising results across multiple benchmarks, demonstrating its effectiveness in enhancing temporal reasoning and its potential to improve state-of-the-art video-LLMs.
Benchmark Results#
Benchmark results in a research paper are crucial for evaluating the proposed method’s performance and comparing it against existing state-of-the-art approaches. A thoughtful analysis would consider various aspects. Firstly, the choice of benchmarks is vital; selecting relevant and widely-used datasets demonstrates the method’s generalizability and impact. Secondly, a thorough comparison should be provided, not just raw scores, but a detailed analysis of the results on each benchmark, including any significant differences or trends. Thirdly, the analysis must address potential limitations. Were there any specific scenarios where the method underperformed? Did the metrics fully capture the nuances of the task? Finally, the discussion should highlight the method’s advantages and disadvantages in relation to the benchmarks, offering insights into its strengths and weaknesses. The overall goal is not just to present numbers but to provide a comprehensive, nuanced evaluation that clearly demonstrates the paper’s contribution to the field.
Future of TPO#
The future of Temporal Preference Optimization (TPO) looks promising. Scalability is key; as larger video datasets become available, TPO’s self-training nature will prove beneficial, reducing the reliance on expensive, manually annotated data. Expanding TPO’s application beyond the current benchmarks is another key area. Exploring its effectiveness in diverse video tasks, such as complex event detection or detailed activity recognition, will be crucial. Integration with other video understanding techniques could also boost performance. For example, combining TPO with advanced temporal modeling methods could yield more accurate and robust temporal grounding. Addressing limitations such as potential bias in generated preferences and sensitivity to specific video-LMM architectures will necessitate further research. Finally, investigating TPO in different modalities, such as audio or multi-modal contexts, could offer exciting new avenues for temporal reasoning.
More visual insights#
More on figures

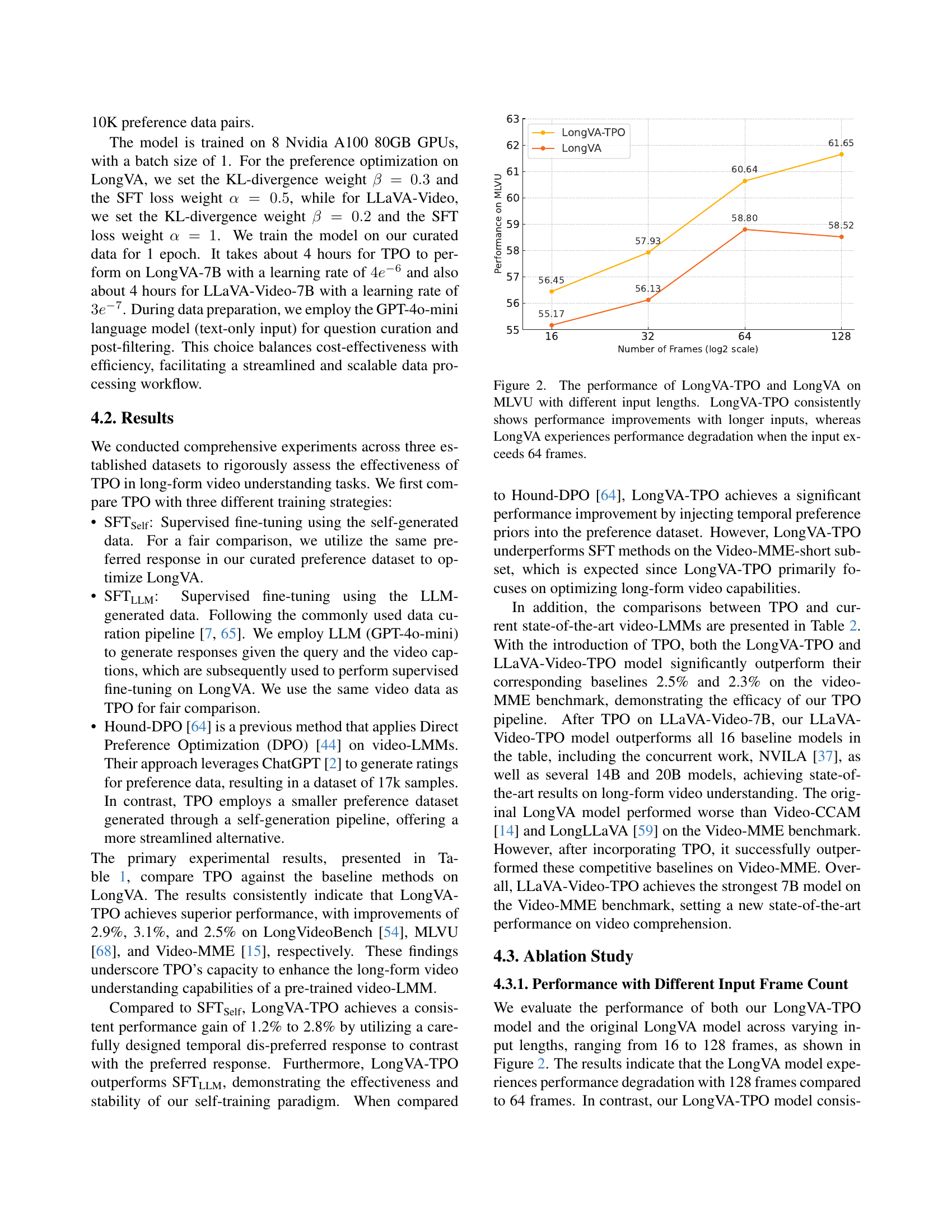
🔼 This figure displays a comparison of the performance of the LongVA and LongVA-TPO models on the MLVU benchmark across various video lengths. The x-axis represents the input video length (number of frames) on a logarithmic scale, and the y-axis shows the performance score of each model. The results reveal that LongVA-TPO consistently demonstrates improved performance as input video length increases, showcasing better handling of longer contexts. Conversely, the performance of the LongVA model plateaus and even degrades when the input exceeds 64 frames, indicating limitations in processing extended temporal information.
read the caption
Figure 2: The performance of LongVA-TPO and LongVA on MLVU with different input lengths. LongVA-TPO consistently shows performance improvements with longer inputs, whereas LongVA experiences performance degradation when the input exceeds 64 frames.

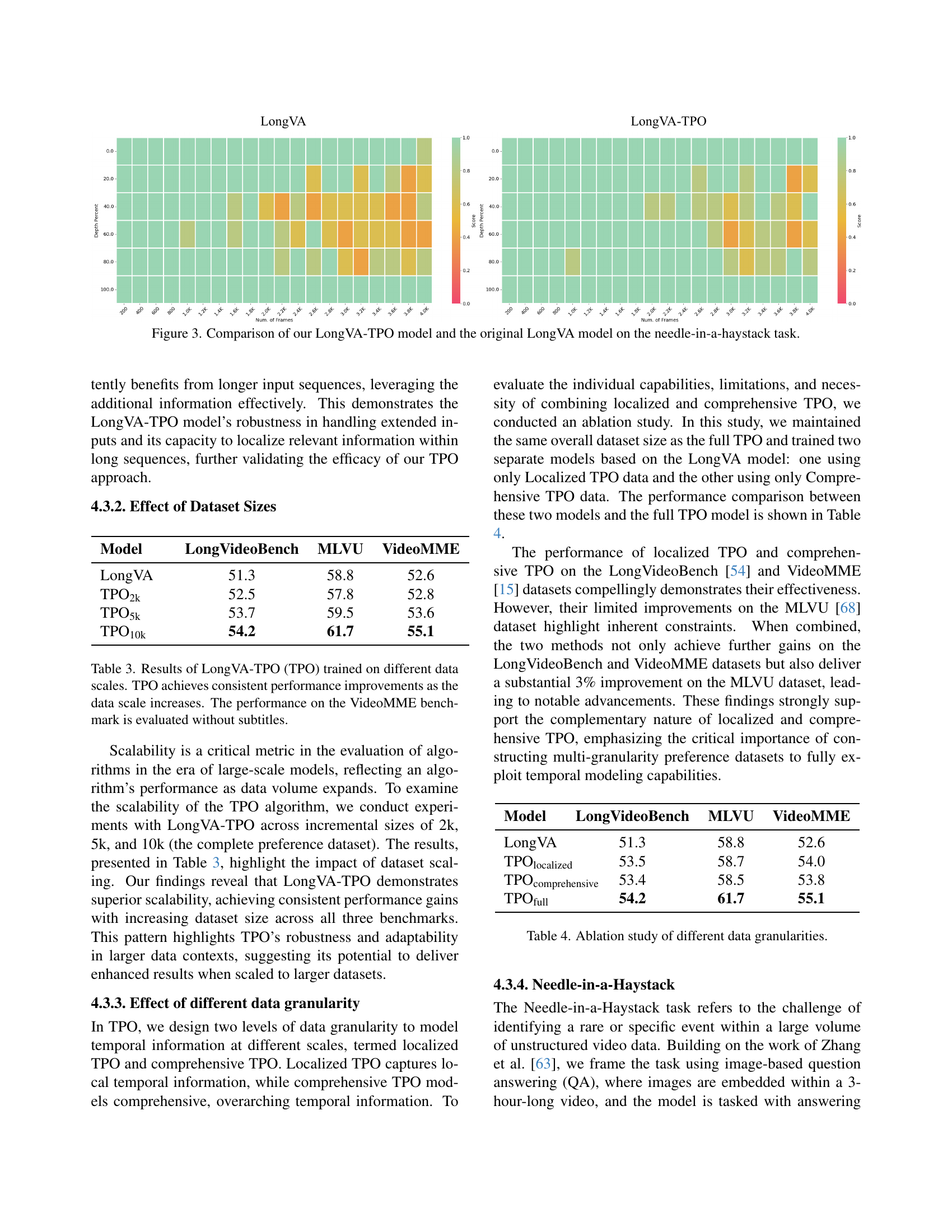
🔼 Figure 3 presents a visual comparison of the LongVA-TPO model’s performance against the original LongVA model on the ’needle-in-a-haystack’ task. This task tests the ability of the models to locate a specific, rare event within a lengthy video. The figure uses heatmaps to represent model performance at different video lengths, showing the percentage of correct responses across varying video durations. The heatmaps highlight how the LongVA-TPO model maintains consistently better performance compared to the original LongVA, especially as the video length increases.
read the caption
Figure 3: Comparison of our LongVA-TPO model and the original LongVA model on the needle-in-a-haystack task.

🔼 This figure showcases a qualitative comparison of the LongVA and LongVA-TPO models’ performance on two videos sourced from the VideoMME benchmark dataset. The comparison focuses on the quality of generated responses to both comprehensive (high-level understanding) and localized (specific segment) questions. The results illustrate that the LongVA-TPO model consistently produces superior response quality, demonstrating the effectiveness of the Temporal Preference Optimization (TPO) framework in enhancing the temporal grounding capabilities of video-LMMs.
read the caption
Figure 4: Qualitative comparison between LongVA-TPO model and LongVA on two videos from VideoMME benchmark. Our LongVA-TPO model demonstrates superior generation quality on both comprehensive and localized questions.

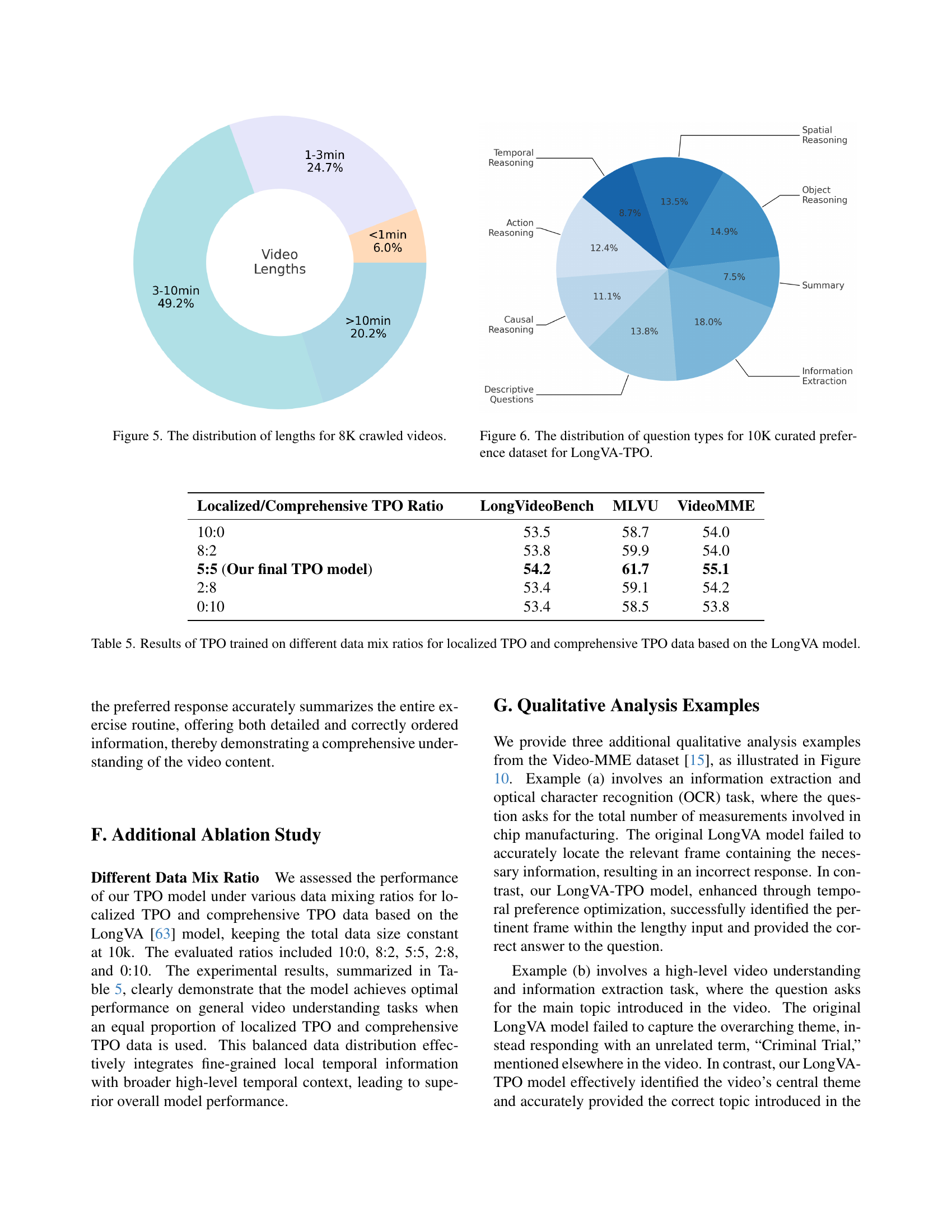
🔼 This figure shows a pie chart illustrating the distribution of video lengths within a dataset of 8,000 videos used for training. The dataset is comprised of videos with durations categorized into four ranges: less than 1 minute, 1 to 3 minutes, 3 to 10 minutes, and more than 10 minutes. The chart visually represents the proportion of videos falling into each of these duration categories, offering insight into the temporal characteristics of the video data used in the study.
read the caption
Figure 5: The distribution of lengths for 8K crawled videos.

🔼 This figure shows a pie chart visualizing the distribution of various question types within a curated dataset of 10,000 question-answer pairs. This dataset was specifically created for training the LongVA-TPO model, a model focused on enhancing temporal understanding in videos. Each slice of the pie chart represents a different question type, indicating the relative frequency of each type in the dataset. The categories included are: Temporal Reasoning, Action Reasoning, Causal Reasoning, Information Extraction, Descriptive Questions, Summarization, Object Reasoning, and Spatial Reasoning. The sizes of the slices visually represent the proportion of each question type within the dataset.
read the caption
Figure 6: The distribution of question types for 10K curated preference dataset for LongVA-TPO.
More on tables
| Model | Size | LongVideoBench | MLVU | Video-MME | |||
|---|---|---|---|---|---|---|---|
| (M-avg) | Short | Medium | Long | Average | |||
| GPT-4o [2] | - | 66.7 | 64.6 | 80.0/82.8 | 70.3/76.6 | 65.3/72.1 | 71.9/77.2 |
| Video-LLaVA [31] | 7B | 39.1 | 47.3 | 45.3/46.1 | 38.0/40.7 | 36.2/38.1 | 39.9/41.6 |
| LLaVA-1.5 [33] | 7B | 40.3 | - | - | - | - | - |
| PLLaVA [55] | 7B | 40.2 | - | - | - | - | - |
| Qwen-VL-Max [5] | - | - | 42.2 | 55.8/57.6 | 49.2/48.9 | 48.9/47.0 | 51.3/51.2 |
| ShareGPT4Video [7] | 8B | 39.7 | 46.4 | 48.3/53.6 | 36.3/39.3 | 35.0/37.9 | 39.9/43.6 |
| InternVL-Chat-V1.5 [11] | 20B | 51.2 | 50.4 | 50.7/52.4 | 60.2/61.7 | 46.4/49.1 | 45.6/46.6 |
| VideoChat2 [28] | 7B | 39.3 | 47.9 | 48.3/52.8 | 37.0/39.4 | 33.2/39.2 | 39.5/43.8 |
| LongLLaVA [59] | 7B | - | 56.3 | 61.9/66.2 | 51.4/54.7 | 45.4/50.3 | 52.9/57.1 |
| Video-CCAM [14] | 14B | - | 63.1 | 62.2/66.0 | 50.6/56.3 | 46.7/49.9 | 53.2/57.4 |
| NVILA [37] | 7B | 57.7 | 70.1 | 75.7/77.6 | 62.2/69.0 | 54.8/63.3 | 64.2/70.0 |
| Qwen2-VL [51] | 7B | 55.6 | - | - | - | - | 63.3/69.0 |
| Apollo [72] | 7B | 58.5 | 70.9 | - | - | - | 61.3/63.3 |
| LongVA-7B [63] | 7B | 51.3 | 58.8 | 61.1/61.6 | 50.4/53.6 | 46.2/47.6 | 52.6/54.3 |
| LLaVA-Video-7B [66] | 7B | 58.2 | 70.8 | - | - | - | 63.3/69.7 |
| LongVA-TPO (ours) | 7B | 54.2 | 61.7 | 63.1/66.6 | 54.8/55.3 | 47.4/47.9 | 55.1/56.6 |
| LLaVA-Video-TPO (ours) | 7B | 60.1 | 71.1 | 76.8/78.7 | 64.6/69.4 | 55.4/66.4 | 65.6/71.5 |
🔼 Table 2 presents a comprehensive comparison of the performance of various video large multimodal models (video-LMMs) on three benchmark datasets: LongVideoBench, MLVU, and Video-MME. It shows the strengths and weaknesses of different models in handling long-form video understanding tasks. The Video-MME results are presented as two scores; the first (before the ‘/’) reflects performance without subtitles, and the second (after the ‘/’) shows performance with subtitles. This allows for a nuanced understanding of model capabilities, revealing how much reliance they have on textual information versus inherent visual and temporal cues within the video itself. The table helps to establish the effectiveness of the Temporal Preference Optimization (TPO) method by comparing its results to state-of-the-art models.
read the caption
Table 2: Results on LongVideoBench [54], MLVU [68] and Video-MME [15] compared with state-of-the-art models. The Video-MME results are presented in the format “w/o subs / w/ subs”.
| Model | LongVideoBench | MLVU | VideoMME |
|---|---|---|---|
| LongVA | 51.3 | 58.8 | 52.6 |
| TPO | 52.5 | 57.8 | 52.8 |
| TPO | 53.7 | 59.5 | 53.6 |
| TPO | 54.2 | 61.7 | 55.1 |
🔼 This table presents the results of the Temporal Preference Optimization (TPO) method on the LongVideoBench, MLVU, and Video-MME benchmarks, using different sizes of the training dataset. It demonstrates how the model’s performance improves as the amount of training data increases. Note that the Video-MME results presented here are without subtitles.
read the caption
Table 3: Results of LongVA-TPO (TPO) trained on different data scales. TPO achieves consistent performance improvements as the data scale increases. The performance on the VideoMME benchmark is evaluated without subtitles.
| Model | LongVideoBench | MLVU | VideoMME |
|---|---|---|---|
| LongVA | 51.3 | 58.8 | 52.6 |
| TPO | 53.5 | 58.7 | 54.0 |
| TPO | 53.4 | 58.5 | 53.8 |
| TPO | 54.2 | 61.7 | 55.1 |
🔼 This ablation study analyzes the impact of using different granularities of data in the Temporal Preference Optimization (TPO) framework. It compares the performance of models trained using only localized temporal preference data, only comprehensive temporal preference data, and a combination of both. The results are presented for three long-form video understanding benchmarks: LongVideoBench, MLVU, and Video-MME, showing the relative contribution of each data type and the synergistic benefit of combining them.
read the caption
Table 4: Ablation study of different data granularities.
| Localized/Comprehensive TPO Ratio | LongVideoBench | MLVU | VideoMME |
|---|---|---|---|
| 10:0 | 53.5 | 58.7 | 54.0 |
| 8:2 | 53.8 | 59.9 | 54.0 |
| 5:5 (Our final TPO model) | 54.2 | 61.7 | 55.1 |
| 2:8 | 53.4 | 59.1 | 54.2 |
| 0:10 | 53.4 | 58.5 | 53.8 |
🔼 This table presents the performance of the Temporal Preference Optimization (TPO) model trained on various combinations of localized and comprehensive temporal preference data. The LongVA model was used as the base model. Different ratios of localized to comprehensive data were used during training (10:0, 8:2, 5:5, 2:8, 0:10), representing the proportion of localized and comprehensive data. The results show the performance on three different video understanding benchmarks: LongVideoBench, MLVU, and Video-MME. This allows for an analysis of how the balance between localized and comprehensive training data impacts overall performance.
read the caption
Table 5: Results of TPO trained on different data mix ratios for localized TPO and comprehensive TPO data based on the LongVA model.
Full paper#