TL;DR#
Current benchmarks for evaluating Large Language Models (LLMs) are insufficient, as state-of-the-art models achieve high accuracy on existing tests. This limits our understanding of true LLM capabilities and the progress towards human-level AI.
Researchers introduce HUMANITY’S LAST EXAM (HLE), a new, globally developed benchmark featuring 3000 challenging questions across many fields. HLE’s multi-modal nature (text and image-based) and rigorous review process ensure high quality and difficulty. Results show even the most advanced LLMs struggle on HLE, highlighting the gap between current AI and human capabilities. The publicly released HLE dataset is intended to drive further LLM research and inform policy discussions.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical need for more challenging benchmarks in evaluating LLMs. Existing benchmarks are quickly saturated, hindering accurate assessment of progress. The new benchmark, along with its open-source nature, enables researchers worldwide to push LLM development towards human-level capabilities. This fosters further research into advanced reasoning and problem-solving capabilities in AI, ultimately shaping the future of AI safety and policy discussions.
Visual Insights#

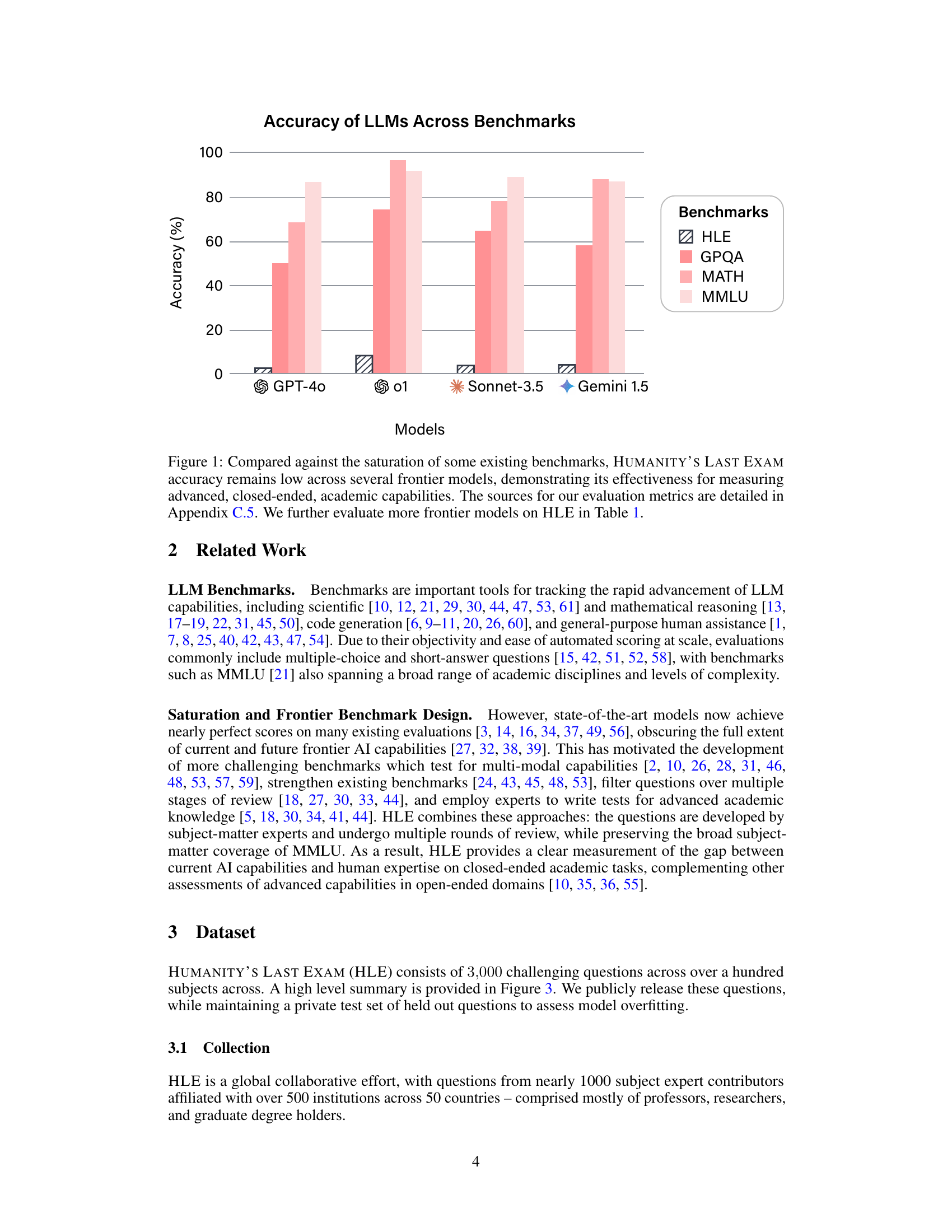
🔼 Humanity’s Last Exam (HLE) is a new benchmark designed to assess the capabilities of large language models (LLMs) on challenging, closed-ended academic questions. This figure compares the accuracy of several state-of-the-art LLMs on HLE against their performance on other established benchmarks like MMLU. The results show that while LLMs achieve near-perfect scores on older benchmarks, their accuracy on HLE remains low. This demonstrates that HLE is indeed a more challenging and effective benchmark for measuring the true capabilities of advanced LLMs in the realm of complex academic reasoning.
read the caption
Figure 1: Compared against the saturation of some existing benchmarks, Humanity’s Last Exam accuracy remains low across several frontier models, demonstrating its effectiveness for measuring advanced, closed-ended, academic capabilities. The sources for our evaluation metrics are detailed in Section C.5. We further evaluate more frontier models on HLE in Table 1.
| Model | Accuracy (%) | Calibration Error (%) |
|---|---|---|
| GPT-4o | ||
| Grok 2 | ||
| Claude 3.5 Sonnet | ||
| Gemini 1.5 Pro | ||
| Gemini 2.0 Flash Thinking | ||
| o1 | ||
| DeepSeek-R1∗ |
🔼 This table presents the performance of various large language models (LLMs) on the HUMANITY’S LAST EXAM (HLE) benchmark. It shows two key metrics: accuracy (the percentage of questions answered correctly) and RMS calibration error (a measure of how well the model’s confidence in its answers matches its actual accuracy). Low accuracy and high calibration error indicate that the models are prone to hallucinating—confidently producing incorrect answers. The table highlights the significant gap between current LLMs and human expert-level performance on complex academic questions. Note that one model (*) is not multi-modal, meaning it cannot process image-based questions; its results are based only on the text-based questions in the benchmark. A more detailed breakdown of the models’ performance on the text-only portion of the HLE is available in a later section of the paper.
read the caption
Table 1: Accuracy and RMS calibration error of different models on HLE, demonstrating low accuracy and high calibration error across all models, indicative of hallucination. ∗Model is not multi-modal, evaluated on text-only subset. We report text-only results on all models in Section C.2.
In-depth insights#
LLM Benchmark Limit#
The limitations of current LLM benchmarks are a significant concern. Existing benchmarks, while useful initially, are quickly saturated as LLMs rapidly improve, hindering accurate assessment of true model capabilities. This saturation masks progress and prevents the identification of genuine advancements at the frontier of AI. A critical need exists for more challenging and diverse benchmarks that push the limits of current LLM abilities, incorporating multi-modal aspects and questions requiring advanced reasoning beyond simple pattern recognition. The development of such benchmarks is crucial to ensure meaningful progress measurement and to inform future research and development efforts in the field.
HLE: Multimodal Test#
A hypothetical “HLE: Multimodal Test” section would likely delve into the design and evaluation of the HUMANITY’S LAST EXAM’s multimodal aspect. This would involve a detailed explanation of how the test incorporates both textual and visual information, highlighting the challenges posed by this dual-modality for large language models (LLMs). The discussion would likely cover the types of questions used (e.g., image-based reasoning, combined text and image interpretation), the rationale for including this multimodal component (e.g., to assess a more comprehensive range of LLM capabilities), and a thorough analysis of the results. Key findings might demonstrate that current LLMs struggle significantly with multimodal reasoning, potentially showcasing a considerable performance gap between human expert-level understanding and the capabilities of these advanced AI models. The section would likely conclude by emphasizing the importance of multimodal benchmarks in the ongoing evaluation of LLM progress, especially in relation to understanding complex real-world scenarios requiring the integration of different sensory inputs.
Expert-Level Questions#
The concept of “Expert-Level Questions” within the context of evaluating large language models (LLMs) is crucial. These questions, designed to be beyond the capabilities of current state-of-the-art LLMs, serve as a benchmark for measuring progress and identifying knowledge gaps. Their creation requires collaboration with domain experts, resulting in problems that demand high-level reasoning skills and specialized knowledge. Successful answers to these questions would represent a significant milestone in AI development, implying a level of understanding that surpasses current models. The difficulty of these questions ensures that simple memorization or internet searching techniques are insufficient. Instead, true understanding and reasoning ability are needed, reflecting a higher order of intelligence. Such rigorous evaluation is vital for assessing the genuine progress in AI and guiding future research efforts.
Model Calibration Gap#
The heading ‘Model Calibration Gap’ suggests an analysis of the discrepancy between a model’s confidence in its predictions and its actual accuracy. A significant gap implies that the model is overconfident in its incorrect answers and underconfident in its correct ones. This is a critical issue, especially in high-stakes applications, as it undermines the trustworthiness and reliability of the model’s output. Investigating this gap may involve analyzing calibration curves, examining confidence scores across different difficulty levels, and possibly exploring different model architectures and training methods to improve calibration performance. Addressing this gap is paramount for building more reliable and trustworthy AI systems.
Future of AI Exams#
The “Future of AI Exams” necessitates a paradigm shift from static benchmarks to dynamic, adaptive assessments. Current evaluations struggle to keep pace with rapid LLM advancements, quickly becoming saturated and failing to expose genuine limitations. Future exams must incorporate multi-modal challenges, require nuanced reasoning, and resist simple internet retrieval to truly gauge advanced capabilities. Furthermore, measuring model calibration and uncertainty, rather than just raw accuracy, is crucial for understanding AI reliability. Ultimately, the goal should be to move beyond closed-ended assessments towards evaluating open-ended problem-solving and complex reasoning, mirroring real-world human intelligence.
More visual insights#
More on figures

🔼 This figure showcases a small sample of the diverse and challenging questions included in the Humanity’s Last Exam benchmark. The questions span a wide range of academic disciplines, including Classics, Ecology, Mathematics, Computer Science, and Chemistry, and vary in their format, including multiple-choice and short-answer questions, some accompanied by images. The questions are designed to assess advanced reasoning capabilities and resist quick solutions found through internet searches.
read the caption
Figure 2: Samples of the diverse and challenging questions submitted to Humanity’s Last Exam.

🔼 Humanity’s Last Exam (HLE) dataset contains 3,000 questions spanning over 100 subjects. The figure displays a high-level breakdown of these subjects categorized into broader groups (e.g., Math, Biology, Humanities). A more detailed list of all subjects is available in Section B.3 of the paper. The visualization helps to show the diversity of topics covered in the HLE benchmark.
read the caption
Figure 3: HLE consists of 3,00030003{,}0003 , 000 exam questions in over a hundred subjects, grouped into high level categories here. We provide a more detailed list of subjects in Section B.3.

🔼 The figure illustrates the multi-stage process of creating the HUMANITY’S LAST EXAM dataset. It begins with a large number of initial question attempts, many of which are filtered out because state-of-the-art LLMs are able to answer them. The remaining questions then undergo iterative refinement through expert review, with both initial feedback rounds and subsequent organizer/expert approval. Finally, the dataset is split into a publicly released set and a private held-out set. The private set is reserved for assessing model overfitting and potential gaming strategies.
read the caption
Figure 4: Dataset creation pipeline. We accept questions that make frontier LLMs fail, then iteratively refine them with the help of expert peer reviewers. Each question is then manually approved by organizers or expert reviewers trained by organizers. A private held-out set is kept in addition to the public set to assess model overfitting and gaming on the public benchmark.

🔼 Figure 5 presents a bar chart comparing the average number of tokens generated by various large language models (LLMs) while answering questions from the HUMANITY’S LAST EXAM (HLE) benchmark. The chart separates models into two categories: reasoning models and non-reasoning models. The token counts include both the tokens used for reasoning (intermediate steps) and those in the final answer. For a more detailed breakdown of token counts for non-reasoning models, refer to Section C.3 of the paper. The chart visually demonstrates the significant difference in computational cost (measured by token usage) between reasoning and non-reasoning LLMs, implying that the reasoning process adds substantial computational overhead.
read the caption
Figure 5: Average completion token counts of reasoning models tested, including both reasoning and output tokens. We also plot average token counts for non-reasoning models in Section C.3.

🔼 This figure displays the average number of tokens generated by several non-reasoning language models across different subject categories within the HUMANITY’S LAST EXAM (HLE) benchmark. The categories shown include Mathematics, Biology/Medicine, Physics, Computer Science/AI, Humanities/Social Sciences, Chemistry, Engineering, and Other. It provides a visual comparison of the computational cost associated with each model’s responses for different subject areas, illustrating variations in complexity and potentially revealing trends in token generation efficiency across various subjects and models.
read the caption
Figure 6: Average output token counts of non-reasoning models.
More on tables
| Score | Scoring Guideline | Description |
| 0 | Discard | The question is out of scope, not original, spam, or otherwise not good enough to be included in the HLE set and should be discarded. |
| 1 | Major Revisions Needed | Major revisions are needed for this question or the question is too easy and simple. |
| 2 | Some Revisions Needed | Difficulty and expertise required to answer the question is borderline. Some revisions are needed for this question. |
| 3 | Okay | The question is sufficiently challenging but the knowledge required is not graduate-level nor complex. Minor revisions may be needed for this question. |
| 4 | Great | The knowledge required is at the graduate level or the question is sufficiently challenging. |
| 5 | Top-Notch | Question is top-notch and perfect. |
| Unsure | - | Reviewer is unsure if the question fits the HLE guidelines, or unsure if the answer is right. |
🔼 This table presents a quantitative evaluation of several large language models (LLMs) on the text-only portion of the HUMANITY’S LAST EXAM (HLE) benchmark. It shows the accuracy and Root Mean Squared (RMS) calibration error for each model. The text-only questions represent 90% of the publicly released HLE dataset. The results demonstrate the performance of state-of-the-art LLMs on challenging, closed-ended academic questions, highlighting the gap between current LLM capabilities and human expertise.
read the caption
Table 2: Accuracy and RMS calibration error of models from Table 1 on the text-only questions of HLE, representing 90% of the public set.
| Score | Scoring Guideline | Description |
|---|---|---|
| 0 | Discard | The question is out of scope, not original, spam, or otherwise not good enough to be included in the HLE set and should be discarded. |
| 1 | Not sure | Major revisions are needed for this question or you’re just unsure about the question. Please put your thoughts in the comment box and an organizer will evaluate this. |
| 2 | Pending | You believe there are still minor revisions that are needed on this question. Please put your thoughts in the comment box and an organizer will evaluate this. |
| 3 | Easy questions models got wrong | These are very basic questions that models got correct or the question was easily found online. Any questions which are artificially difficult (large calculations needing a calculator, requires running/rendering code, etc.) should also belong in this category. The models we evaluate cannot access these tools, hence it creates an artificial difficulty bar. Important: “Found online” means via a simple search online. Research papers/journals/books are fine |
| 4 | Borderline | The question is not interesting OR The question is sufficiently challenging, but 1 or more of the models got the answer correct. |
| 5 | Okay to include in HLE benchmark | Very good questions (usually has score of 3 in the previous review round). You believe it should be included in the HLE Benchmark. |
| 6 | Top question in its category | Great question (usually has a score of 4-5 in the previous review round), at a graduate or research level. Please note that “graduate level” is less strict for Non-STEM questions. For Non-STEM questions and Trivia, they are fine as long as they are challenging and interesting. |
🔼 This table lists the specific versions of the large language models (LLMs) used in the evaluation. It shows the model name and the corresponding version number used in the experiments. The note indicates that when the models allowed for temperature configuration, a temperature of 0 was used for all evaluations. This ensures consistency and reproducibility of the results.
read the caption
Table 3: Evaluated model versions. All models use temperature 0 when configurable.
Full paper#