TL;DR#
Current Retrieval-Augmented Generation (RAG) models often struggle with complex queries due to limitations in their single retrieval step before answer generation. This leads to inaccurate or incomplete answers, especially in scenarios requiring multi-hop reasoning where information needs to be gathered from multiple sources. This problem is further exacerbated by the inherent difficulty in accurately training these models due to the lack of intermediate reasoning steps in available datasets.
CoRAG solves these problems with a novel chain-of-retrieval approach. It dynamically refines queries based on evolving context, allowing for more accurate retrieval and multi-hop reasoning. This approach, combined with a rejection sampling technique for data augmentation and various test-time decoding strategies, significantly improves the model’s accuracy and efficiency. The method is validated on multiple benchmarks, surpassing existing state-of-the-art models particularly in multi-hop question answering tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly advances the field of Retrieval-Augmented Generation (RAG) by introducing a novel training approach and decoding strategies. It offers a practical solution to the limitations of current RAG systems, particularly for complex, multi-hop questions. The work opens exciting new avenues of research, particularly in developing efficient and robust RAG models that address real-world challenges.
Visual Insights#

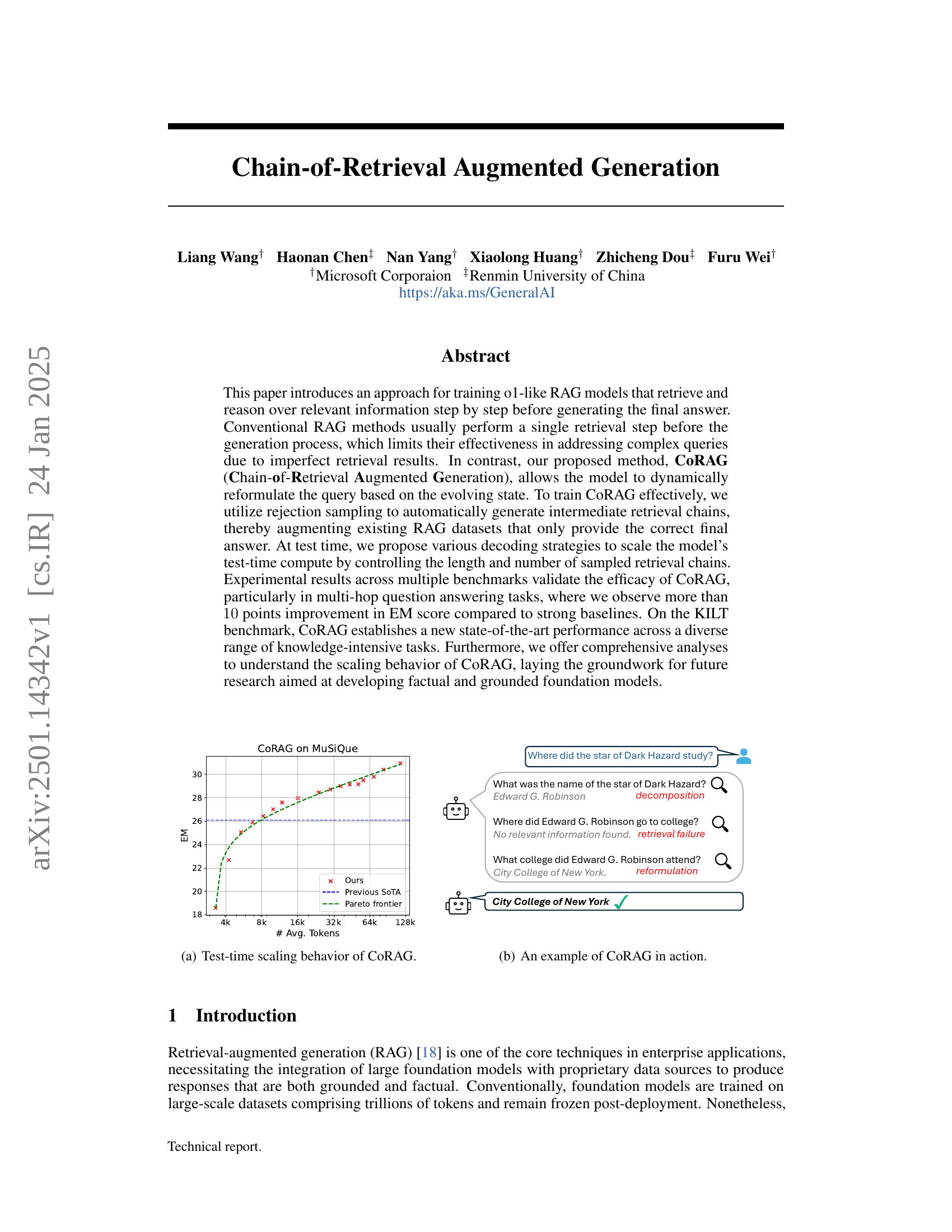
🔼 This figure shows how the performance of the CoRAG model scales with the increase of the average number of tokens consumed during testing. The x-axis represents the average number of tokens consumed per test instance, which sums both prompt and generated tokens. The y-axis shows the exact match (EM) score, a common metric for evaluating the accuracy of question-answering models. The curve shows that increasing token consumption initially leads to significant improvement in the EM score, indicating better performance by allowing for more extensive reasoning steps. However, the gains gradually diminish as the token consumption increases beyond a certain point.
read the caption
(a) Test-time scaling behavior of CoRAG.
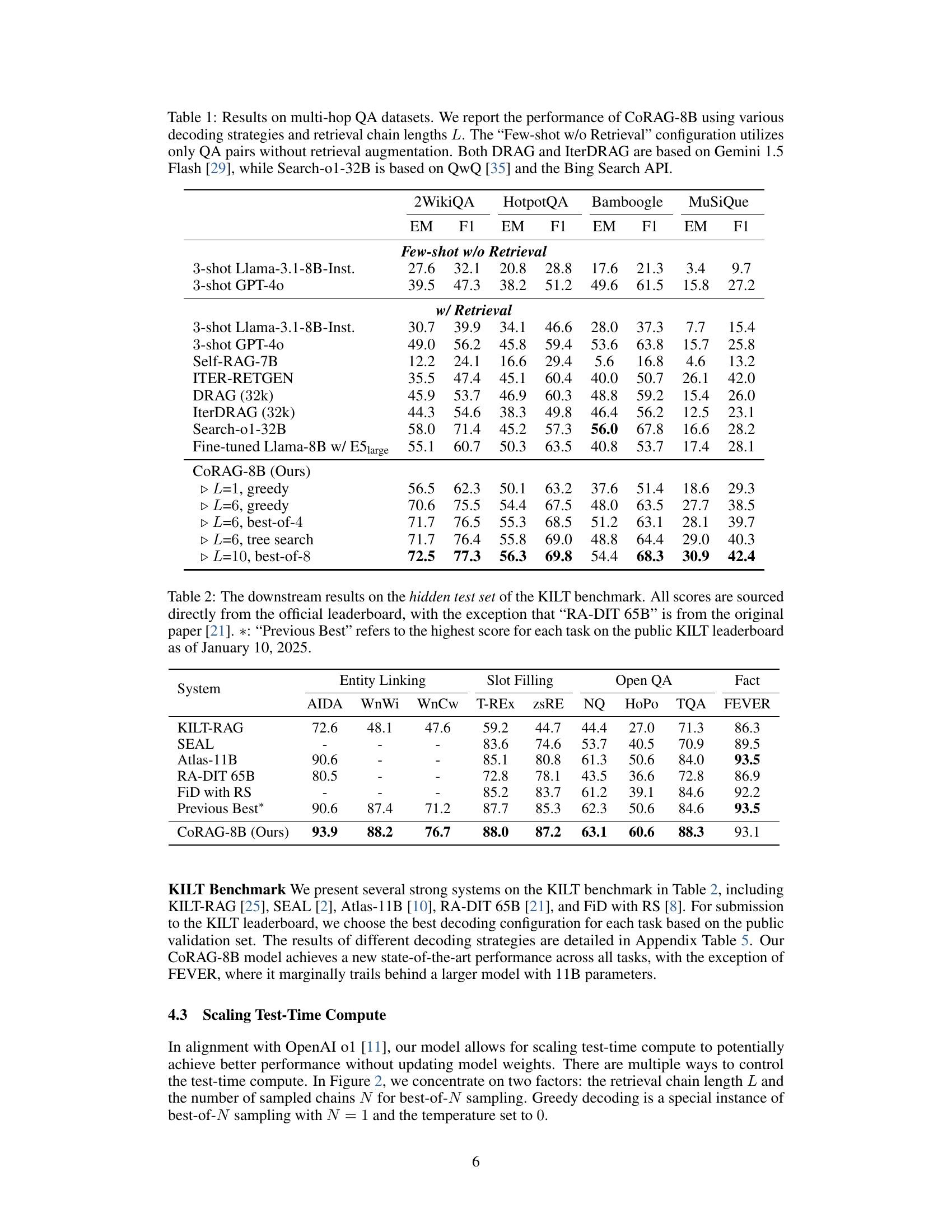
| 2WikiQA | HotpotQA | Bamboogle | MuSiQue | |||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | |
| Few-shot w/o Retrieval | ||||||||
| -shot Llama-3.1-8B-Inst. | 27.6 | 32.1 | 20.8 | 28.8 | 17.6 | 21.3 | 3.4 | 9.7 |
| -shot GPT-4o | 39.5 | 47.3 | 38.2 | 51.2 | 49.6 | 61.5 | 15.8 | 27.2 |
| w/ Retrieval | ||||||||
| -shot Llama-3.1-8B-Inst. | 30.7 | 39.9 | 34.1 | 46.6 | 28.0 | 37.3 | 7.7 | 15.4 |
| -shot GPT-4o | 49.0 | 56.2 | 45.8 | 59.4 | 53.6 | 63.8 | 15.7 | 25.8 |
| Self-RAG-7B | 12.2 | 24.1 | 16.6 | 29.4 | 5.6 | 16.8 | 4.6 | 13.2 |
| ITER-RETGEN | 35.5 | 47.4 | 45.1 | 60.4 | 40.0 | 50.7 | 26.1 | 42.0 |
| DRAG (k) | 45.9 | 53.7 | 46.9 | 60.3 | 48.8 | 59.2 | 15.4 | 26.0 |
| IterDRAG (k) | 44.3 | 54.6 | 38.3 | 49.8 | 46.4 | 56.2 | 12.5 | 23.1 |
| Search-o1-32B | 58.0 | 71.4 | 45.2 | 57.3 | 56.0 | 67.8 | 16.6 | 28.2 |
| Fine-tuned Llama-8B w/ E5 | 55.1 | 60.7 | 50.3 | 63.5 | 40.8 | 53.7 | 17.4 | 28.1 |
| CoRAG-8B (Ours) | ||||||||
| =, greedy | 56.5 | 62.3 | 50.1 | 63.2 | 37.6 | 51.4 | 18.6 | 29.3 |
| =, greedy | 70.6 | 75.5 | 54.4 | 67.5 | 48.0 | 63.5 | 27.7 | 38.5 |
| =, best-of- | 71.7 | 76.5 | 55.3 | 68.5 | 51.2 | 63.1 | 28.1 | 39.7 |
| =, tree search | 71.7 | 76.4 | 55.8 | 69.0 | 48.8 | 64.4 | 29.0 | 40.3 |
| =, best-of- | 72.5 | 77.3 | 56.3 | 69.8 | 54.4 | 68.3 | 30.9 | 42.4 |
🔼 Table 1 presents a comprehensive comparison of the CoRAG-8B model’s performance on several multi-hop question answering (QA) datasets against various state-of-the-art baselines. It showcases the impact of different decoding strategies (greedy, best-of-N sampling, tree search) and varying retrieval chain lengths on the model’s accuracy, measured by Exact Match (EM) and F1 scores. The table also includes results for a few-shot setting without retrieval augmentation for comparison, highlighting the effectiveness of the CoRAG approach. Note that certain baseline models (DRAG, IterDRAG, and Search-01-32B) leverage specific underlying models and retrieval methods which are explicitly noted in the caption for transparency.
read the caption
Table 1: Results on multi-hop QA datasets. We report the performance of CoRAG-8B using various decoding strategies and retrieval chain lengths L𝐿Litalic_L. The “Few-shot w/o Retrieval” configuration utilizes only QA pairs without retrieval augmentation. Both DRAG and IterDRAG are based on Gemini 1.5 Flash [29], while Search-o1-32B is based on QwQ [35] and the Bing Search API.
In-depth insights#
CoRAG: Chain-of-Retrieval#
CoRAG, or Chain-of-Retrieval Augmented Generation, presents a novel approach to enhance Retrieval Augmented Generation (RAG) models. Unlike traditional RAG which performs a single retrieval step before generation, CoRAG iteratively retrieves and reasons over information, dynamically refining queries based on the evolving context. This multi-step process allows CoRAG to effectively handle complex queries that might stump single-step methods due to imperfect initial retrieval. A key innovation is the use of rejection sampling to augment existing datasets with intermediate retrieval chains, enabling effective model training. The paper also introduces various decoding strategies at test time to control computational cost by managing retrieval chain length and sampling. Empirical results showcase significant improvements over strong baselines, particularly in multi-hop question answering, demonstrating the efficacy of CoRAG’s iterative approach and establishing new state-of-the-art results. The scalability analysis offers valuable insights into the trade-off between computational cost and performance. The technique holds promise for building more robust and factual foundation models by mitigating limitations inherent in traditional RAG methods.
Rejection Sampling#
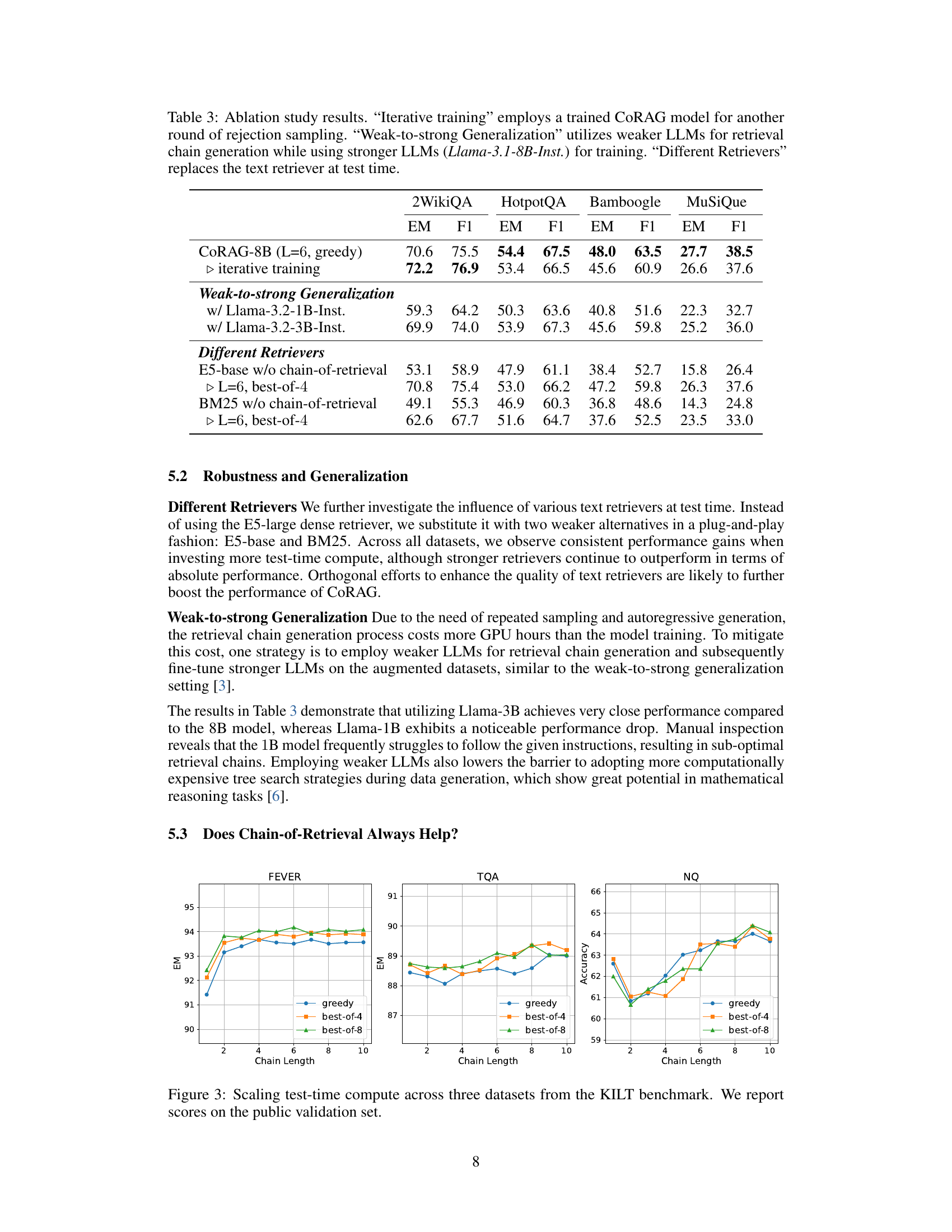
Rejection sampling, in the context of the research paper, is a crucial technique for augmenting existing datasets by generating synthetic retrieval chains. Its primary function is to address the scarcity of intermediate retrieval steps in typical RAG (Retrieval-Augmented Generation) datasets. This data augmentation is vital for effectively training models to reason and retrieve information dynamically, a core feature of the CoRAG system. The process involves sampling chains of sub-queries and sub-answers, evaluating them based on the probability of arriving at the correct final answer, and rejecting those that fall below a certain threshold. This iterative refinement improves the model’s ability to learn complex multi-hop reasoning, going beyond the limitations of single-step retrieval. The effectiveness and efficiency of this method are significant, enabling the creation of diverse and high-quality training data without manual annotation, a major bottleneck in the development of advanced RAG models. The strategic use of rejection sampling ultimately enhances the generalization capabilities and improves the overall performance of CoRAG in tasks requiring multi-step reasoning.
Decoding Strategies#
The effectiveness of retrieval-augmented generation (RAG) models hinges significantly on the decoding strategies employed during inference. The choice of decoding strategy directly impacts the trade-off between computational cost and model performance. The paper explores various strategies, including greedy decoding, best-of-N sampling, and tree search. Greedy decoding is computationally efficient but may not explore the full potential of the model. Best-of-N sampling balances efficiency with improved accuracy by generating multiple candidate answers. Tree search, while most comprehensive, incurs the highest computational overhead. The optimal strategy is context-dependent and varies across datasets and tasks, demonstrating the crucial need for adaptive decoding mechanisms that dynamically adjust to the complexity of the query and the quality of the retriever. Further research should investigate more sophisticated strategies and explore the potential of reinforcement learning to optimize the selection of decoding strategies during inference.
Test-Time Scaling#
The concept of ‘Test-Time Scaling’ in the context of Retrieval Augmented Generation (RAG) models is crucial for practical applications. It addresses the trade-off between model performance and computational cost during inference. The paper explores various decoding strategies—greedy decoding, best-of-N sampling, and tree search—to control this trade-off. Greedy decoding is the fastest but may not be optimal, while best-of-N sampling offers a balance between speed and accuracy by exploring multiple retrieval chains. Tree search, though potentially most effective, is computationally expensive. The empirical evaluation reveals a relationship between total tokens consumed and model performance, often following a log-linear trend. This finding suggests that dynamically allocating computational resources based on query complexity and retriever performance is beneficial. The results highlight the importance of test-time optimization in RAG models to achieve efficient and high-quality responses in real-world scenarios, particularly for complex or resource-constrained environments.
Future of RAG#
The future of Retrieval Augmented Generation (RAG) is bright, with several key areas ripe for advancement. Improved retrieval methods, moving beyond simple keyword matching to incorporate semantic understanding and contextual awareness, are crucial. This includes exploring more sophisticated techniques like dense passage retrieval and advanced query reformulation strategies to handle complex, multi-hop queries more effectively. Enhanced model architectures are also needed to better integrate retrieval and generation processes, potentially via more seamless integration of LLMs and retrieval systems. Furthermore, research into efficient test-time scaling is paramount, enabling RAG to handle increasingly large datasets and complex reasoning tasks without compromising speed and efficiency. Finally, addressing hallucination issues remains a top priority, improving the accuracy and reliability of RAG-generated responses, perhaps through better methods for evaluating the trustworthiness of retrieved information and incorporating uncertainty quantification into the generation process. These combined efforts will enable RAG systems to become more accurate, robust, efficient, and reliable, unlocking their full potential across a wider range of applications.
More visual insights#
More on figures

🔼 The figure shows an example of a multi-hop question answering process using the Chain-of-Retrieval Augmented Generation (CoRAG) model. The user asks a question, ‘Where did the star of Dark Hazard study?’, and the system uses multiple retrieval steps to find the answer. First, it retrieves the star’s name, ‘Edward G. Robinson’. Then, it reformulates the query to ‘What college did Edward G. Robinson attend?’ and retrieves the answer, ‘City College of New York’. This illustrates the dynamic reformulation of queries and the step-by-step retrieval process of CoRAG, highlighting its capability in addressing complex questions requiring multiple hops of reasoning.
read the caption
(b) An example of CoRAG in action.

🔼 CoRAG (Chain-of-Retrieval Augmented Generation) is a novel approach for training RAG models that retrieve and reason over relevant information step by step before generating the final answer. The figure illustrates the CoRAG framework. It begins with rejection sampling to augment standard QA datasets by creating retrieval chains. Each chain starts with the original query and iteratively generates sub-queries and corresponding sub-answers. These chains are used to train an open-source large language model (LLM) to predict the next action (sub-query or sub-answer) based on the current state of the chain. During the inference stage (when generating answers to new questions), multiple decoding strategies are employed to control the computational cost and balance it with the desired accuracy.
read the caption
Figure 1: Overview of CoRAG. Rejection sampling is utilized to augment QA-only datasets with retrieval chains. Each chain starts with the original query, followed by a sequence of sub-queries and sub-answers. An open-source LLM is then fine-tuned to predict the next action based on the current state. During inference, multiple decoding strategies are available to control the test-time compute.

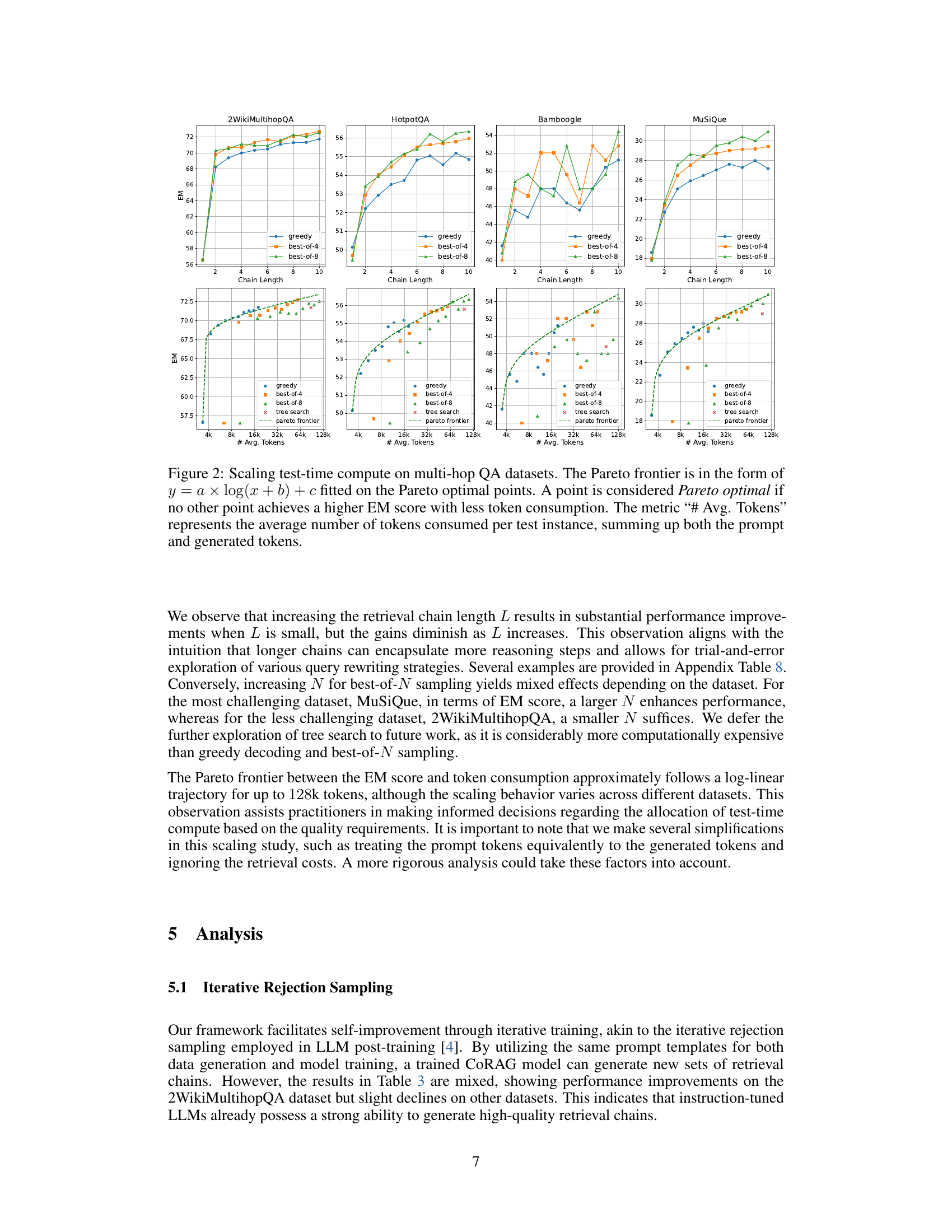
🔼 This figure examines the trade-off between model performance (measured by Exact Match score) and computational cost (measured by the average number of tokens used per query) in multi-hop question answering. It shows how different decoding strategies (greedy, best-of-N sampling, tree search) and retrieval chain lengths affect this trade-off. The Pareto frontier is visualized, illustrating the optimal balance between performance and cost for each strategy. Points on the Pareto frontier represent situations where no other strategy could achieve a higher EM score with fewer tokens. The relationship between tokens and EM score is modeled by a logarithmic function, y = a × log(x + b) + c, where y represents EM and x represents average tokens.
read the caption
Figure 2: Scaling test-time compute on multi-hop QA datasets. The Pareto frontier is in the form of y=a×log(x+b)+c𝑦𝑎𝑥𝑏𝑐y=a\times\log(x+b)+citalic_y = italic_a × roman_log ( italic_x + italic_b ) + italic_c fitted on the Pareto optimal points. A point is considered Pareto optimal if no other point achieves a higher EM score with less token consumption. The metric “# Avg. Tokens” represents the average number of tokens consumed per test instance, summing up both the prompt and generated tokens.

🔼 This figure shows how varying the retrieval chain length impacts the performance and computational cost of the CoRAG model on three different tasks from the KILT benchmark. The x-axis represents the length of the retrieval chain (number of retrieval steps), and the y-axis represents the performance (accuracy or exact match) achieved on the tasks. Different lines represent various decoding strategies employed by the model. The figure highlights the trade-off between achieving higher accuracy and managing computational cost by adjusting the retrieval chain length. The scores are those achieved on the public validation set of the KILT benchmark.
read the caption
Figure 3: Scaling test-time compute across three datasets from the KILT benchmark. We report scores on the public validation set.

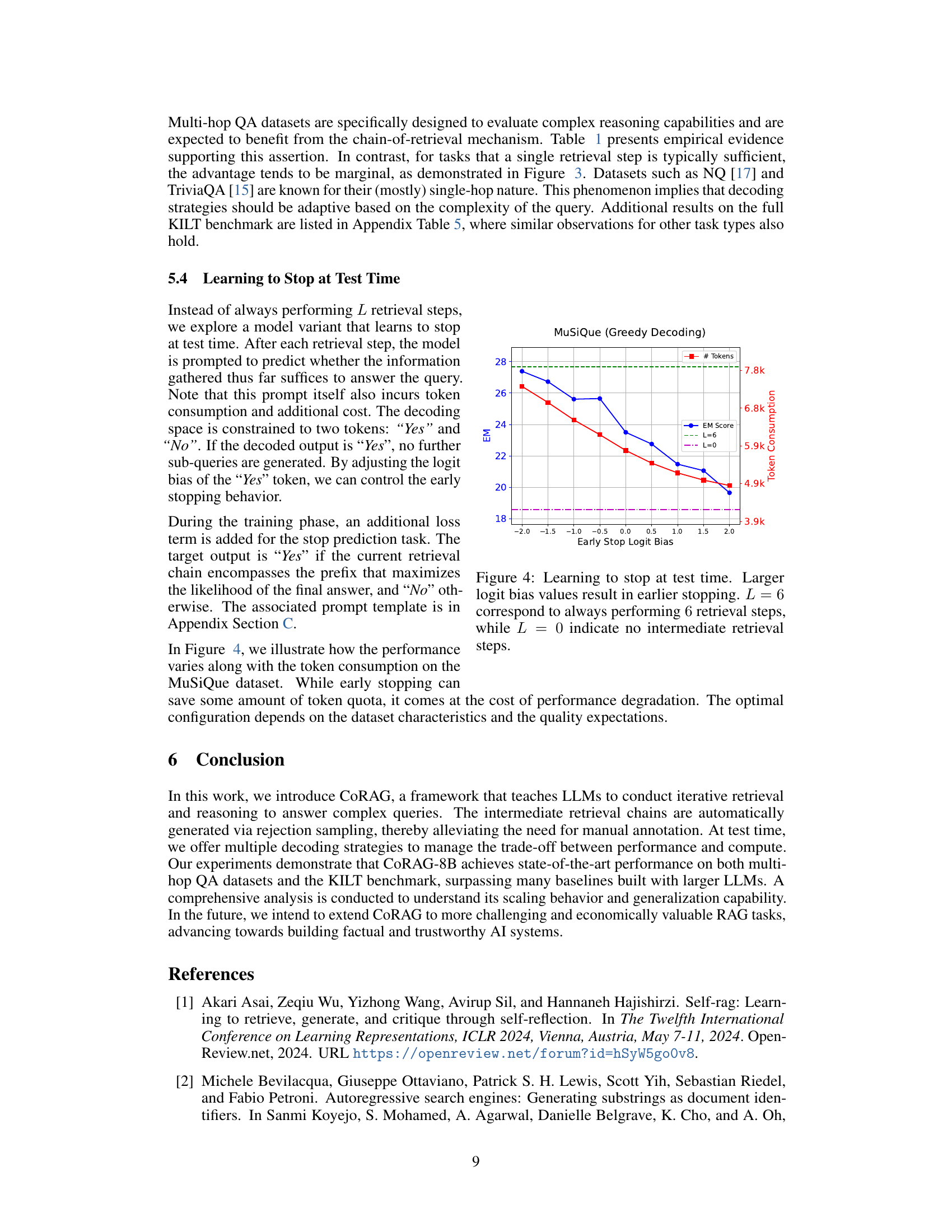
🔼 This figure illustrates the effect of a learnable ‘stop’ mechanism that determines when to halt the iterative retrieval process within the Chain-of-Retrieval Augmented Generation (CoRAG) model. The experiment varies the logit bias associated with the ‘stop’ prediction. A higher logit bias incentivizes the model to stop earlier, reducing the number of retrieval steps. The results show the trade-off between the model’s performance (measured by Exact Match score) and the number of tokens consumed for different stopping strategies. The x-axis represents the logit bias of the stop decision, and the y-axis depicts the Exact Match score and token consumption. The different colored lines represent different numbers of retrieval steps: L=6 (always using 6 retrieval steps) and L=0 (no intermediate retrieval steps). This allows for examination of how a learnable stopping mechanism affects efficiency without sacrificing accuracy.
read the caption
Figure 4: Learning to stop at test time. Larger logit bias values result in earlier stopping. L=6𝐿6L=6italic_L = 6 correspond to always performing 6666 retrieval steps, while L=0𝐿0L=0italic_L = 0 indicate no intermediate retrieval steps.

🔼 This figure illustrates the impact of varying the number of retrieval chains sampled during the rejection sampling process on the performance of the model. The experiment systematically varies the number of sampled chains, increasing it from 4 to 16, while keeping all other hyperparameters constant. The x-axis represents the number of sampled chains, and the y-axis displays the resulting EM (Exact Match) score on four different multi-hop question answering datasets. The purpose is to investigate the effect of the quantity of training data generated through rejection sampling on model performance.
read the caption
Figure 5: Scaling rejection sampling compute for training data generation. We vary the number of sampled chains from 4444 to 16161616 while maintaining all other hyperparameters fixed.

🔼 This figure displays the impact of different sampling temperatures on the performance of the CoRAG model across four multi-hop question answering datasets (2WikiMultihopQA, HotpotQA, Bamboogle, and MuSiQue). Each dataset has a separate subplot showing the Exact Match (EM) score on the y-axis and the sampling temperature on the x-axis. Different lines represent different decoding strategies (greedy, best-of-4, best-of-8). The plots reveal how the choice of sampling temperature influences the balance between diversity and quality in the retrieval chains generated during training, which in turn affects the final model’s performance on these datasets. The results suggest that there is no universally optimal sampling temperature, and its effectiveness can vary based on the dataset.
read the caption
Figure 6: Effects of varying the sampling temperature on multi-hop QA datasets.
More on tables
| System | Entity Linking | Slot Filling | Open QA | Fact | |||||
|---|---|---|---|---|---|---|---|---|---|
| AIDA | WnWi | WnCw | T-REx | zsRE | NQ | HoPo | TQA | FEVER | |
| KILT-RAG | 72.6 | 48.1 | 47.6 | 59.2 | 44.7 | 44.4 | 27.0 | 71.3 | 86.3 |
| SEAL | - | - | - | 83.6 | 74.6 | 53.7 | 40.5 | 70.9 | 89.5 |
| Atlas-11B | 90.6 | - | - | 85.1 | 80.8 | 61.3 | 50.6 | 84.0 | 93.5 |
| RA-DIT 65B | 80.5 | - | - | 72.8 | 78.1 | 43.5 | 36.6 | 72.8 | 86.9 |
| FiD with RS | - | - | - | 85.2 | 83.7 | 61.2 | 39.1 | 84.6 | 92.2 |
| Previous Best∗ | 90.6 | 87.4 | 71.2 | 87.7 | 85.3 | 62.3 | 50.6 | 84.6 | 93.5 |
| CoRAG-8B (Ours) | 93.9 | 88.2 | 76.7 | 88.0 | 87.2 | 63.1 | 60.6 | 88.3 | 93.1 |
🔼 Table 2 presents the results of the KILT benchmark, a comprehensive evaluation suite for knowledge-intensive language tasks. The table compares the performance of the proposed CoRAG model against several state-of-the-art models across various subtasks within KILT. These subtasks cover diverse areas like entity linking, slot filling, and open question answering. The scores are sourced directly from the official KILT leaderboard, providing an objective comparison. One exception is the RA-DIT 65B model, where the score is taken from its original publication (reference [21]), as opposed to the leaderboard. The ‘Previous Best’ column indicates the top score achieved for each task on the public leaderboard up to January 10, 2025.
read the caption
Table 2: The downstream results on the hidden test set of the KILT benchmark. All scores are sourced directly from the official leaderboard, with the exception that “RA-DIT 65B” is from the original paper [21]. ∗*∗: “Previous Best” refers to the highest score for each task on the public KILT leaderboard as of January 10, 2025.
| 2WikiQA | HotpotQA | Bamboogle | MuSiQue | |||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | |
| CoRAG-8B (L=, greedy) | 70.6 | 75.5 | 54.4 | 67.5 | 48.0 | 63.5 | 27.7 | 38.5 |
| iterative training | 72.2 | 76.9 | 53.4 | 66.5 | 45.6 | 60.9 | 26.6 | 37.6 |
| Weak-to-strong Generalization | ||||||||
| w/ Llama-3.2-1B-Inst. | 59.3 | 64.2 | 50.3 | 63.6 | 40.8 | 51.6 | 22.3 | 32.7 |
| w/ Llama-3.2-3B-Inst. | 69.9 | 74.0 | 53.9 | 67.3 | 45.6 | 59.8 | 25.2 | 36.0 |
| Different Retrievers | ||||||||
| E5-base w/o chain-of-retrieval | 53.1 | 58.9 | 47.9 | 61.1 | 38.4 | 52.7 | 15.8 | 26.4 |
| L=, best-of- | 70.8 | 75.4 | 53.0 | 66.2 | 47.2 | 59.8 | 26.3 | 37.6 |
| BM25 w/o chain-of-retrieval | 49.1 | 55.3 | 46.9 | 60.3 | 36.8 | 48.6 | 14.3 | 24.8 |
| L=, best-of- | 62.6 | 67.7 | 51.6 | 64.7 | 37.6 | 52.5 | 23.5 | 33.0 |
🔼 This table presents the results of an ablation study conducted to analyze the impact of various components and training strategies on the CoRAG model’s performance. Three main variations were tested: 1) Iterative Training, where a trained CoRAG model was used to generate additional retrieval chains via rejection sampling; 2) Weak-to-Strong Generalization, which explored using weaker LLMs to generate retrieval chains while retaining a stronger LLM (Llama-3.1-8B-Inst.) for the main training; and 3) Different Retrievers, where alternative text retrieval methods were substituted during the testing phase. The table shows the performance (EM and F1 scores) across multiple multi-hop QA datasets (2WikiQA, HotpotQA, Bamboogle, MuSiQue) for each of these variations, allowing for a detailed comparison and analysis of each component’s contribution to the overall model effectiveness.
read the caption
Table 3: Ablation study results. “Iterative training” employs a trained CoRAG model for another round of rejection sampling. “Weak-to-strong Generalization” utilizes weaker LLMs for retrieval chain generation while using stronger LLMs (Llama-3.1-8B-Inst.) for training. “Different Retrievers” replaces the text retriever at test time.
| Multi-hop QA | KILT Benchmark | |
|---|---|---|
| Initialization | Llama-3.1-8B-Instruct | |
| Learning rate | ||
| Batch size | ||
| Epoch | ||
| Warmup steps | ||
| # Training samples | ||
| # Retrieved passages | ||
| Max sequence length | ||
🔼 This table lists the hyperparameters used during the training of the Chain-of-Retrieval Augmented Generation (CoRAG) model. It shows the different settings for two sets of experiments: one for multi-hop question answering (QA) tasks and another for the KILT benchmark, a diverse set of knowledge-intensive tasks. For each experiment, it specifies the model initialization, learning rate, batch size, number of training epochs, number of warmup steps, and the total number of training samples and retrieved passages used. The maximum sequence length for each experiment is also specified.
read the caption
Table 4: Hyperparameters for training CoRAG.
| System | Entity Linking | Slot Filling | Open QA | Fact | |||||
|---|---|---|---|---|---|---|---|---|---|
| AIDA | WnWi | WnCw | T-REx | zsRE | NQ | HoPo | TQA | FEVER | |
| CoRAG-8B (Ours) | |||||||||
| =, greedy | 90.4 | 86.0 | 76.8 | 87.0 | 82.1 | 62.5 | 56.4 | 88.4 | 91.4 |
| =, greedy | 92.7 | 87.4 | 75.8 | 86.6 | 83.8 | 63.2 | 59.1 | 88.6 | 93.8 |
| =, best-of- | 92.5 | 87.4 | 75.8 | 86.3 | 83.5 | 62.6 | 59.6 | 88.7 | 93.9 |
| =, tree search | 91.8 | 86.8 | 75.5 | 86.4 | 83.0 | 62.4 | 59.9 | 88.9 | 93.9 |
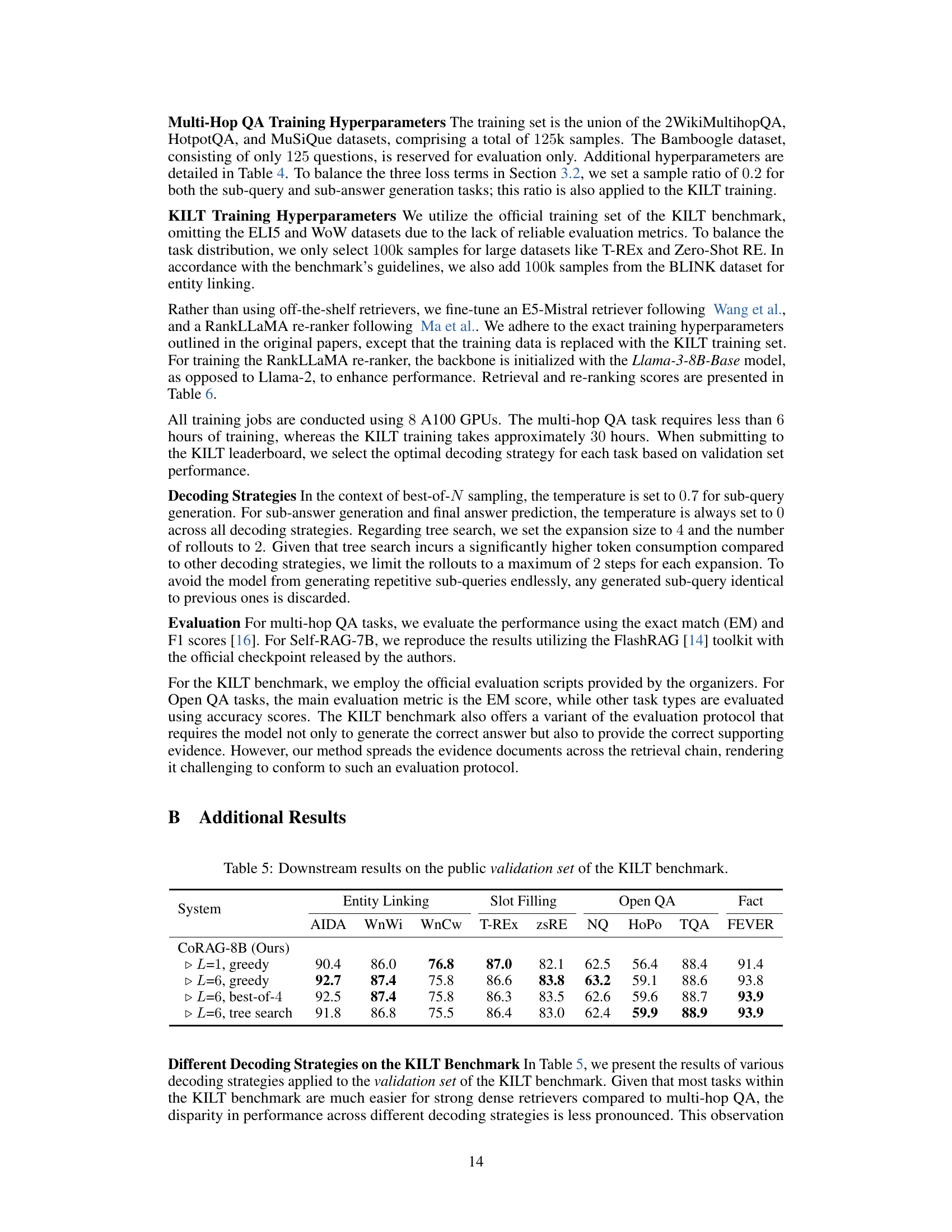
🔼 Table 5 presents the performance of the CoRAG model on the hidden test set of the KILT benchmark. KILT is a comprehensive benchmark for knowledge-intensive language tasks, encompassing various downstream tasks like entity linking, slot filling, and open QA. The table shows the model’s performance on each task compared against several strong baselines. This allows for a comparison of CoRAG’s performance across a diverse set of knowledge-intensive tasks, demonstrating its generalizability.
read the caption
Table 5: Downstream results on the public validation set of the KILT benchmark.
| System | Entity Linking | Slot Filling | Open QA | Fact | |||||
|---|---|---|---|---|---|---|---|---|---|
| AIDA | WnWi | WnCw | T-REx | zsRE | NQ | HoPo | TQA | FEVER | |
| Fine-tuned E5 | 92.9 | 86.7 | 76.0 | 80.5 | 95.3 | 77.7 | 66.7 | 78.9 | 90.9 |
| w/ re-ranking | 93.3 | 88.0 | 77.1 | 83.2 | 97.6 | 78.2 | 78.2 | 81.5 | 92.3 |
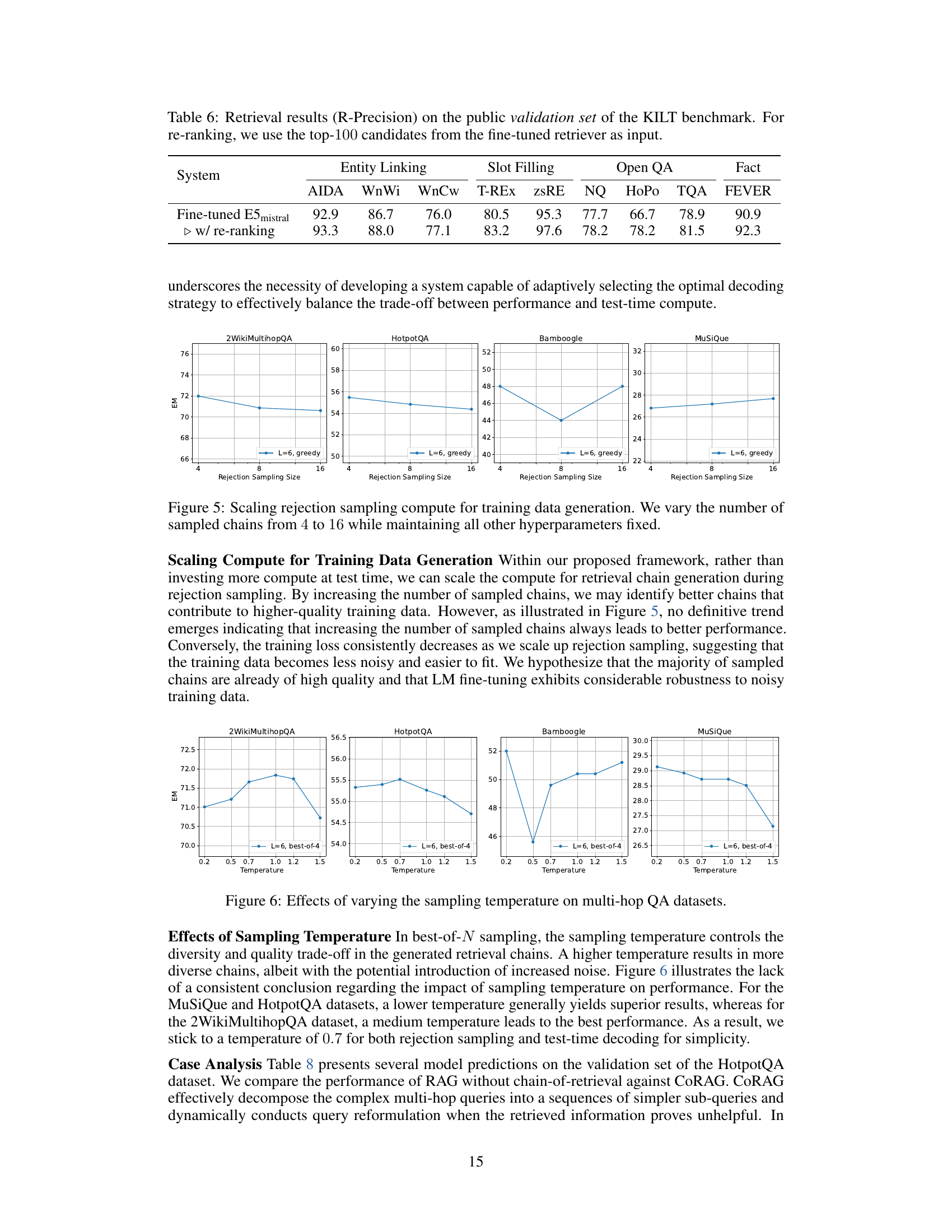
🔼 Table 6 presents the results of retrieval performance, specifically R-Precision scores, on the public validation subset of the KILT benchmark. R-Precision measures the proportion of relevant documents retrieved among the top retrieved documents. The experiment used a fine-tuned retriever to get the top 100 candidates, which were then used as input for re-ranking. The table breaks down the R-Precision scores across different tasks within the KILT benchmark, including entity linking (AIDA, WnWi, WnCw), slot filling (T-Rex, zsRE), and open QA tasks (NQ, HoPo, TQA, FEVER).
read the caption
Table 6: Retrieval results (R-Precision) on the public validation set of the KILT benchmark. For re-ranking, we use the top-100100100100 candidates from the fine-tuned retriever as input.
| Dataset | Task Description |
|---|---|
| HotpotQA / 2WikiMultihopQA | answer multi-hop questions |
| NQ | answer natural questions from Google search |
| AidaYago 2 / WnWi / WnCw / Blink | link the mention surrounded by [START_ENT] and [END_ENT] to the title of the correct Wikipedia page |
| FEVER | verify if the claim is supported or refuted |
| T-REx / Zero-Shot RE | given head entity and relation separated by [SEP], find the correct tail entity, return the title of its Wikipedia page |
| Trivia QA | answer trivia questions |
| MuSiQue / Bamboogle | answer multi-hop questions |
🔼 This table provides detailed descriptions of the various tasks involved in the different datasets used for evaluating the model. For each dataset (HotpotQA, NQ, AidaYago, FEVER, T-REX, TriviaQA, MuSiQue, Bamboogle), it specifies the nature of the tasks, such as answering multi-hop questions, verifying claims, or linking entities, and offers a brief explanation for better understanding.
read the caption
Table 7: Task descriptions for each dataset.
| |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||
| |||||||||||||||||
|
🔼 This table presents four examples from the HotpotQA validation dataset to illustrate how the Chain-of-Retrieval Augmented Generation (CoRAG) model improves performance compared to a standard RAG model. Each example shows the original query, the final answer generated by the standard RAG, and the intermediate steps and final answer provided by CoRAG. Correct answers are marked in blue, incorrect answers in red. For brevity, the retrieved documents at each step are not shown.
read the caption
Table 8: Examples from the validation set of the HotpotQA dataset. For conciseness, all retrieved documents at each step are omitted. Correct answers are highlighted in blue, while incorrect answers are highlighted in red.
Full paper#