TL;DR#
Current methods for evaluating the quality of critiques generated by Large Language Models (LLMs) are inadequate because they lack a closed-loop feedback mechanism. The open-ended nature of critique evaluation makes it difficult to establish definitive quality judgments. Existing benchmarks struggle to measure the effectiveness of critiques in driving actual improvements to outputs.
This research proposes RealCritic, a novel benchmark that addresses these challenges. It employs a closed-loop methodology, directly linking critique quality to the improvements it generates in subsequent outputs. It includes self-critique, cross-critique, and iterative critique scenarios, offering a more comprehensive evaluation than existing methods. The results demonstrate that advanced reasoning models significantly surpass classical models across various critique scenarios, particularly in self-critique and iterative critique.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel benchmark, RealCritic, for evaluating language model critique capabilities. It addresses the limitations of existing methods by using a closed-loop methodology that directly assesses the effectiveness of critiques. This is highly relevant to current research on improving language models, as it provides a more effective way to measure and compare their ability to provide constructive feedback and improve their reasoning. The introduction of advanced evaluation scenarios, including self-critique, cross-critique, and iterative critique, opens up new avenues for further investigation into the nuances of language model reasoning.
Visual Insights#

🔼 The figure presents a benchmark comparison of self-critique and cross-critique abilities across various Large Language Models (LLMs). It showcases the performance differences between classical LLMs and advanced reasoning-based LLMs, highlighting the superior performance of the o1-mini model in both self and cross-critique scenarios. The bar chart visually demonstrates the average performance improvement (or decline) after critique for each model. The results indicate that while classical LLMs show little to no improvement in self-critique and modest gains in cross-critique, the o1-mini model exhibits significant performance increases. This underscores the importance of advanced reasoning capabilities for effective critique generation.
read the caption
Figure 1: Caption
| Benchmark |
|
|
|
|
|
|
| ||||||||||||||
| CriticBench-Google | C+V | Self+Cross | Verdict Judging | ✗ | ✗ | 0 | ✗ | ||||||||||||||
| CriticBench-THU | C+V | Cross | Verdict Judging | ✗ | ✓ | 3,825 | ✓ | ||||||||||||||
| CriticEval | C+S | Cross | Score Judging | ✗ | ✗ | 3,608 | ✓ | ||||||||||||||
| Shepherd | C | Cross | GPT-4 Comparison | ✗ | ✗ | 352 | ✗ | ||||||||||||||
| Auto-J | C | Cross | GPT-4 Comparison | ✗ | ✗ | 232 | ✓ | ||||||||||||||
| RealCritic | C+V+Corr | Self+Cross | Correction Matching | ✓ | ✗ | 2,093 | ✓ | ||||||||||||||
| Note: C = Critique, V = Verdict, S = Score, Corr = Correction. ✓= Yes, ✗ = No. | |||||||||||||||||||||
🔼 Table 1 compares different approaches to evaluating the quality of critiques generated by large language models (LLMs). It highlights key features of each approach, such as the type of output (critique, verdict, score, correction), the type of critique (self, cross, iterative), the evaluation method used, and whether the benchmark offers iterative support, a specified test data size, and public data release. It showcases the novel aspects of the RealCritic framework which includes a large-scale publicly available benchmark and a comprehensive evaluation of critique abilities.
read the caption
Table 1: Comparison of critique evaluation approaches. Our RealCritic framework introduces several key innovations while providing a large-scale, publicly available benchmark for comprehensive critique ability evaluation.
In-depth insights#
Critique Benchmark#
A critique benchmark in the context of large language models (LLMs) is a critical tool for evaluating the quality and effectiveness of LLM-generated critiques. Such benchmarks must move beyond simple accuracy metrics and incorporate nuanced aspects of critique, such as the actionability of suggestions, depth of analysis, and constructive nature of feedback. A robust benchmark should include diverse tasks and models, assessing critiques across various domains and difficulty levels. Furthermore, the benchmark should evaluate not just the immediate quality of a critique but also its impact on subsequent model performance. This could involve a closed-loop evaluation system where the critique leads to a refined solution, thus directly measuring its contribution to improvement. Self-critique and iterative critique should also be part of any comprehensive benchmark, reflecting the dynamic nature of real-world improvement cycles. By addressing these multifaceted considerations, a well-designed critique benchmark can significantly advance the development and deployment of more capable and helpful LLMs.
Closed-Loop Eval#
A closed-loop evaluation framework offers a powerful paradigm shift in assessing the effectiveness of language model critiques. Instead of the traditional open-loop approach, which evaluates critiques in isolation, closed-loop evaluation directly measures a critique’s impact on subsequent model performance. This is achieved by incorporating the critique’s suggested corrections back into the model’s process, thus creating a feedback loop. The final, corrected output’s quality then serves as the metric for evaluating the original critique’s effectiveness. This approach is more holistic and realistic, as it acknowledges that a critique’s true value lies in its contribution to improved results, not just in its standalone analysis. The closed-loop method addresses inherent limitations of open-loop evaluations, which often lack a clear ground truth for evaluating critique quality and struggle to capture the dynamic nature of the iterative refinement process. By focusing on downstream impact, closed-loop evaluation provides a more rigorous and effective way to benchmark and advance the state-of-the-art in LLM critique generation.
Critique Paradigms#
The concept of “Critique Paradigms” in evaluating large language models (LLMs) centers on the various approaches to assessing the quality of critiques generated by these models. Self-critique focuses on the model’s ability to identify and correct its own errors, offering a valuable introspective measure. Cross-critique, in contrast, involves evaluating how well the model critiques the outputs of other models. This approach assesses the model’s ability to function as an external evaluator, identifying flaws in diverse solution styles. Finally, iterative critique extends the process by evaluating the model’s performance in refining its critique over multiple rounds of feedback. This multi-round approach provides a more robust test of the model’s long-horizon reasoning and error-correction capabilities. The effectiveness of each paradigm is contingent on the task’s complexity and the model’s inherent strengths and limitations. A comprehensive evaluation framework should incorporate all three to provide a holistic assessment of the LLM’s critique abilities. Closed-loop methodologies, which assess the quality of critiques based on their effectiveness in driving solution refinement, are crucial for measuring critique quality accurately.
Iterative Critique#
The concept of “Iterative Critique” in the context of large language model (LLM) evaluation offers a compelling approach to assess the model’s ability to refine its understanding and solutions over multiple rounds of feedback. Unlike a single-round critique which only measures immediate analysis capabilities, iterative critique focuses on the long-term impact of feedback, mimicking the iterative refinement processes often employed by humans. This dynamic, multi-round evaluation is crucial because it highlights a model’s capacity for adaptive problem-solving and its ability to learn and improve from repeated correction. Iterative critique effectively tests the model’s capacity for long-horizon reasoning and error-correction dynamics. It helps move beyond simply assessing the accuracy of immediate analysis to observing a model’s ability to iteratively converge towards a correct solution. The success of an iterative critique approach relies on a properly designed prompt and evaluation method that ensures the process doesn’t simply lead to the model generating a new solution from scratch each time, but instead promotes true refinement based on the previous feedback.
Future Work#
Future research directions stemming from this work could focus on several key areas. First, expanding the benchmark to encompass a wider variety of tasks and reasoning styles is crucial. While the current benchmark uses mathematical reasoning and multiple-choice questions, including tasks involving natural language understanding, code generation, and common sense reasoning would improve its generalizability and applicability. Second, investigating the impact of different model architectures and training methodologies on critique effectiveness would provide valuable insights for improving critique abilities in LLMs. This involves exploring the interaction between model design choices and their inherent strengths and limitations concerning critique functions. Third, developing more sophisticated evaluation metrics that move beyond simple accuracy measures is important. While accuracy is a valuable initial metric, a more nuanced system that captures the overall quality of the critique’s analysis, suggestions, and resulting improvements is needed. Finally, exploring the potential for human-in-the-loop evaluation to enhance the efficiency and accuracy of benchmark development and assessment is warranted. This would allow for more detailed qualitative feedback which could prove highly beneficial in refining the framework and identifying areas where automated evaluation falls short.
More visual insights#
More on figures

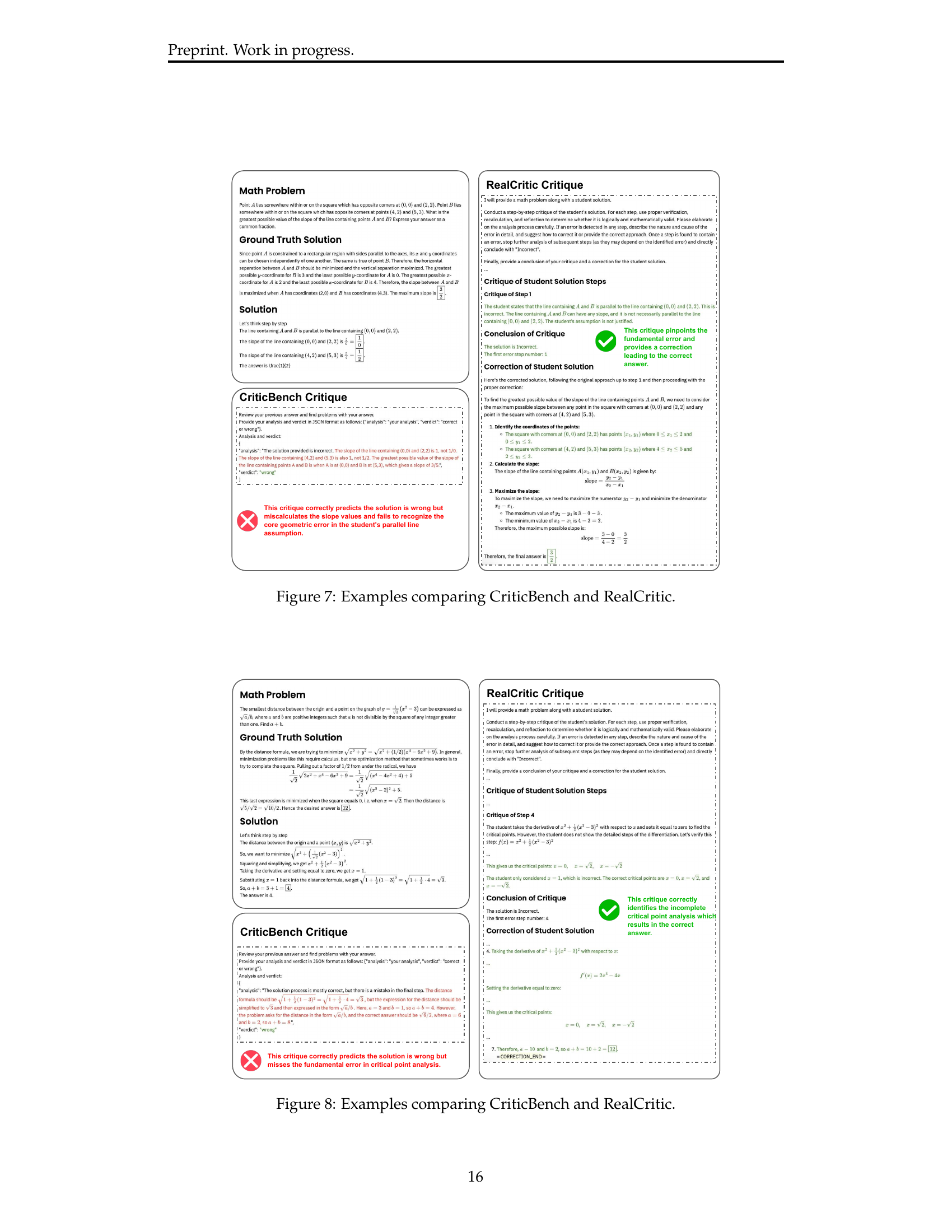
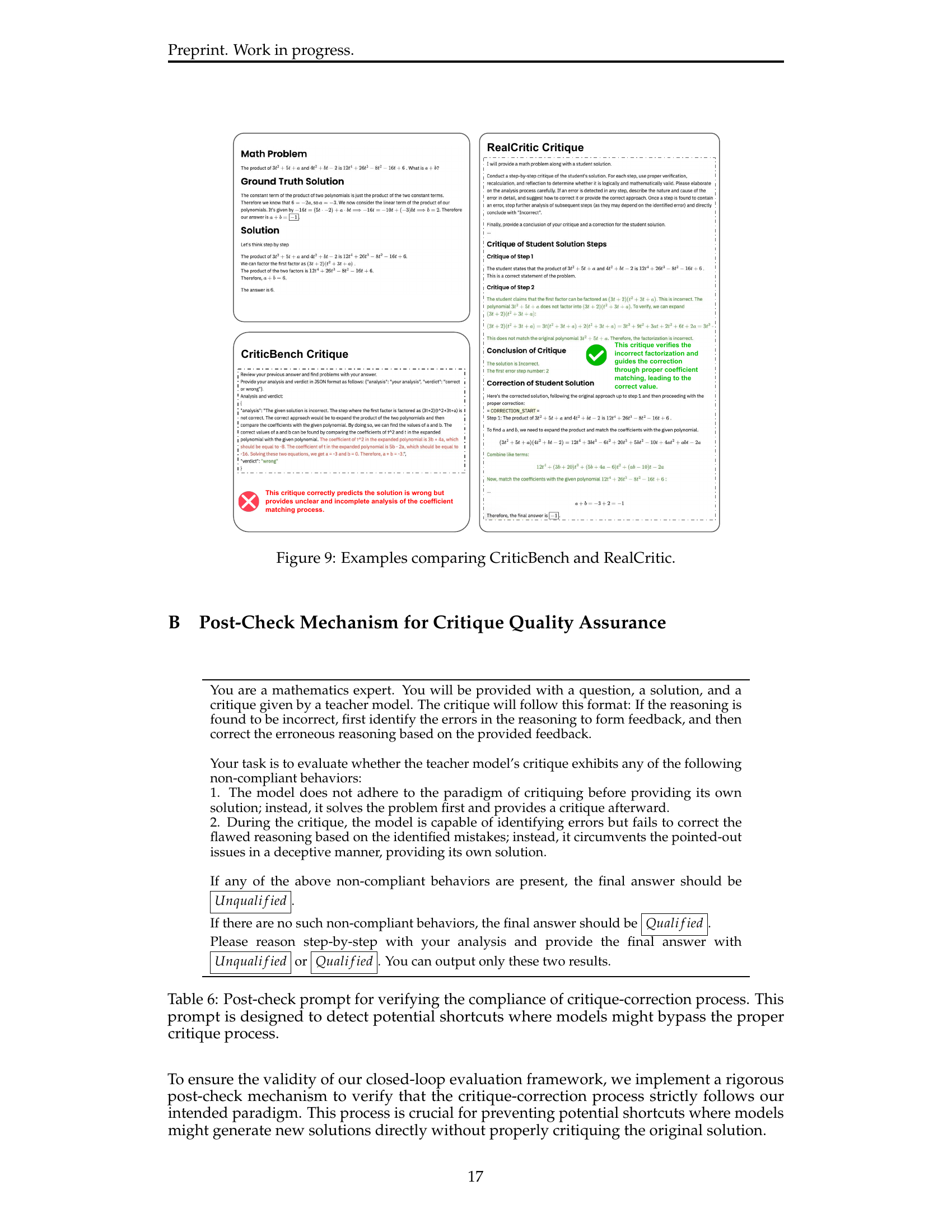
🔼 This figure presents two examples to illustrate the limitations of the CriticBench benchmark in evaluating critique quality. CriticBench assesses critique quality solely based on the accuracy of the critique’s verdict (correct or incorrect) regarding the input solution’s correctness. The figure showcases that CriticBench may incorrectly classify low-quality critiques as high-quality because the critique correctly predicted the solution’s inaccuracy, even though the critique itself was flawed and didn’t effectively guide the correction process. In contrast, the RealCritic approach, which measures critique quality based on its effectiveness in improving the solution, accurately identifies the high-quality critique, demonstrating that the evaluation methodology is crucial for a robust benchmark.
read the caption
Figure 2: TODO.

🔼 This figure compares the evaluation methods used in CriticBench and RealCritic. CriticBench uses an open-loop approach, evaluating critiques in isolation based on the correctness of their verdicts (good/bad). RealCritic, in contrast, employs a closed-loop methodology. It assesses critique quality by measuring the accuracy of the solution that results from applying the critique and subsequent correction. The closed-loop approach is represented in the figure as the correction feeding back into the system.
read the caption
Figure 3: Caption.

🔼 This figure illustrates the process of constructing datasets for evaluating the critique abilities of large language models (LLMs). The process involves two main steps. First, it begins with a pool of candidate datasets encompassing diverse question types (open-ended mathematical problems and multiple-choice questions) and difficulty levels. These datasets are then filtered based on the capabilities of several LLMs to ensure that the chosen datasets provide a balanced representation of difficulty and challenge model capabilities appropriately. The second step shows that solutions from several different LLMs are generated for all questions in the filtered dataset. Then, the solutions are filtered to ensure a balance of correct and incorrect solutions for evaluation. An example of a question with the associated LLM response, score and source dataset is also shown.
read the caption
Figure 4: Caption

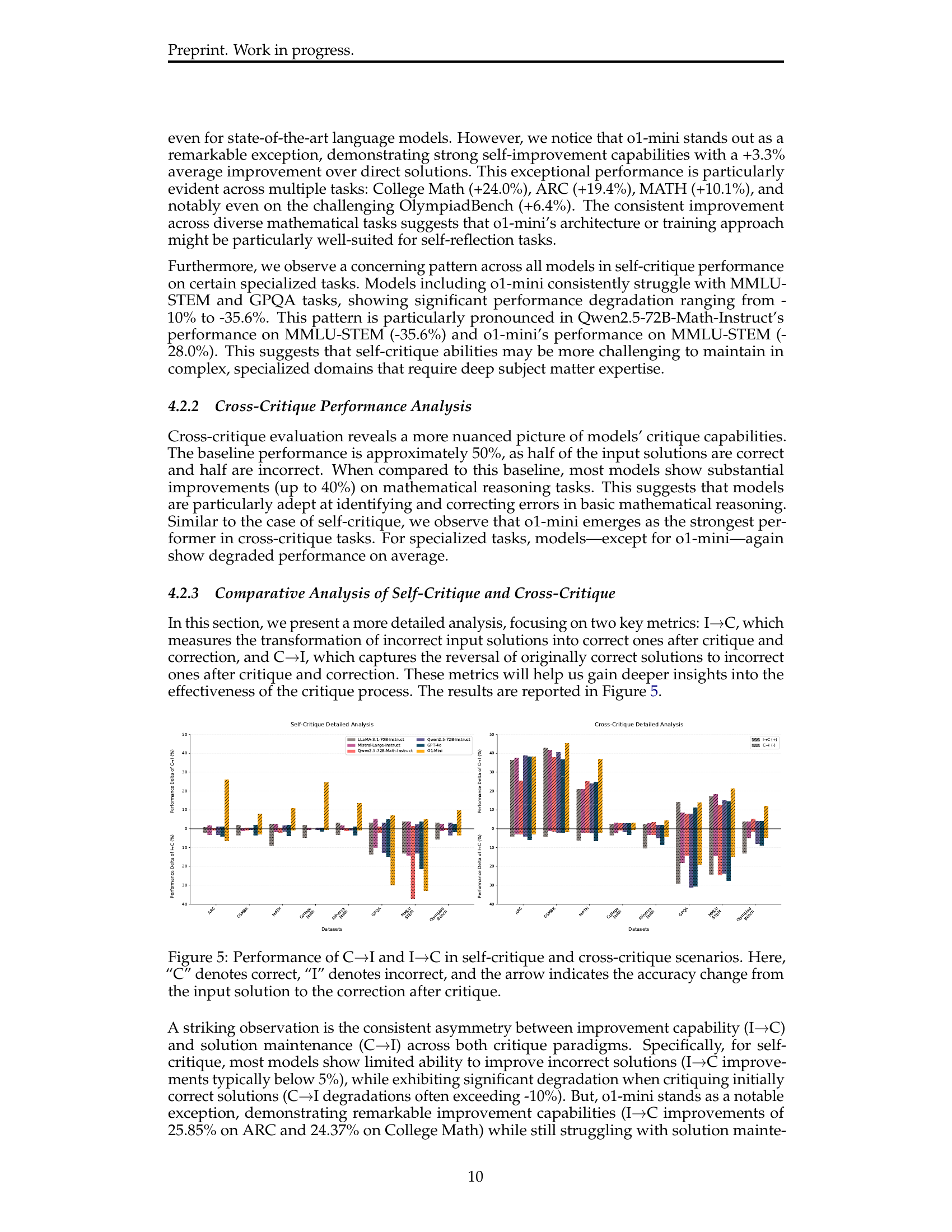
🔼 Figure 5 presents a comparative analysis of the performance of different LLMs across self-critique and cross-critique tasks. The charts visualize the percentage change in solution correctness after critique, categorized into two scenarios: I→C (improving incorrect solutions) and C→I (degrading correct solutions). The results highlight the asymmetry between a model’s ability to improve incorrect solutions versus maintain the correctness of already correct solutions. This asymmetry is observed across various LLMs on both self- and cross-critique tasks.
read the caption
Figure 5: Caption

🔼 Figure 6 presents the performance of iterative critique, averaging results across eight tasks. The iterative critique process involves multiple rounds of critique and correction, allowing for the refinement of initial solutions. The figure shows how performance, measured by the change in accuracy compared to the baseline, changes over successive rounds. Different models exhibit varied trajectories. Some models show a consistent decline, others maintain consistent improvement, and still others initially improve before declining. These trends highlight the varying dynamics and effectiveness of iterative critique across different models.
read the caption
Figure 6: Caption
More on tables
| Output |
| Format |
🔼 Table 2 presents a detailed analysis of the critique quality within the CriticBench-THU dataset. Despite a high accuracy rate (55.4%) in predicting whether a given solution is correct or incorrect, the overall quality of the critiques themselves is rather low (68.8% are classified as low quality). This discrepancy highlights the difficulty of generating critiques that are both accurate and truly helpful in improving the quality of solutions.
read the caption
Table 2: Quality analysis of critiques in CriticBench-THU. All values are in percentages (%). Despite achieving correct verdicts in many cases (55.4%), the majority of critiques (68.8%) are still of low quality, highlighting the challenge in generating effective critiques.
| Critique |
| Type |
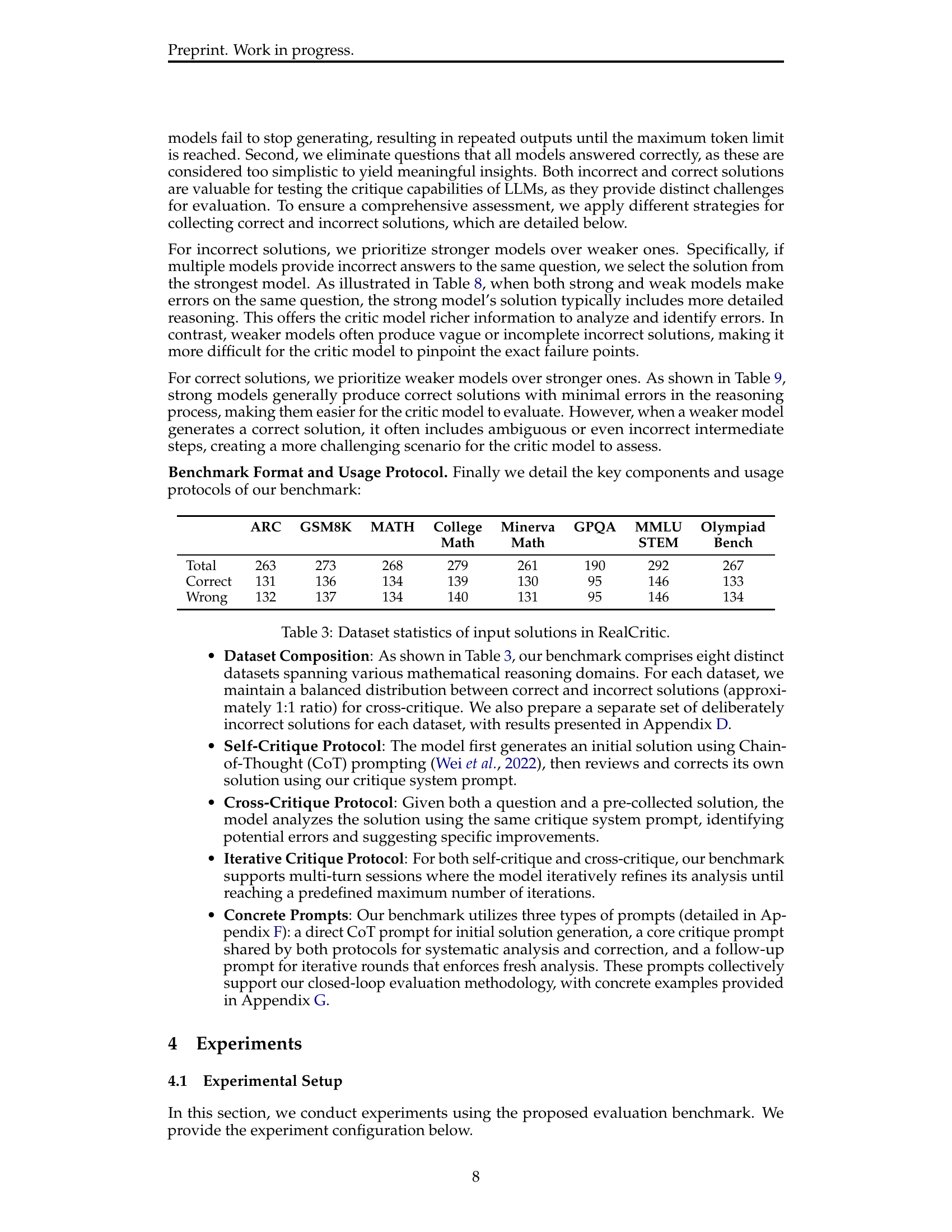
🔼 Table 3 shows the breakdown of questions within the RealCritic benchmark dataset. It details the total number of questions in each of the eight subsets, categorized by whether the associated solution is correct or incorrect. This provides insight into the dataset’s composition and balance of problem types.
read the caption
Table 3: The total number of questions in each subset of RealCritic. Along with how many questions come with incorrect solutions and how many come with correct solutions.
| Evaluation |
| Method |
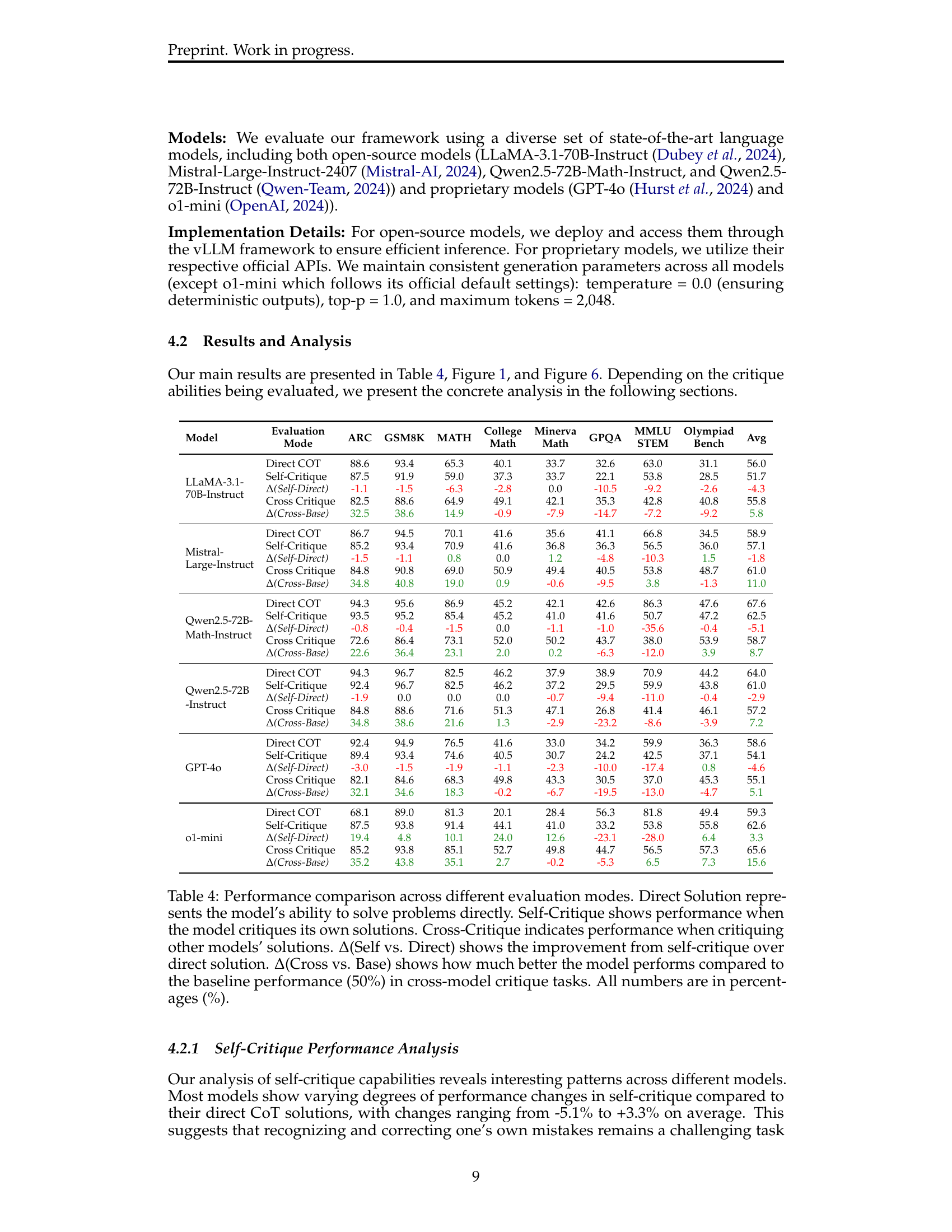
🔼 Table 4 presents a comprehensive comparison of various large language models (LLMs) across three different evaluation modes: direct problem-solving, self-critique, and cross-model critique. For each model, the table shows the percentage accuracy achieved in each mode. The Δ(Self vs. Direct) column quantifies the performance improvement (or decline) observed when the model self-critiques its own solutions compared to directly solving the problem. The Δ(Cross vs. Random) column reveals the improvement (or decline) of the model’s cross-model critique performance compared to a random baseline of 50%. Gray rows highlight these delta metrics for easier interpretation. All values are expressed as percentages.
read the caption
Table 4: Performance comparison across different evaluation modes. Direct Solution represents the model’s ability to solve problems directly. Self-Critique shows performance when the model critiques its own solutions. Cross-Model Critique indicates performance when critiquing other models’ solutions. Δ(Self vs. Direct) shows the improvement from self-critique over direct solution. Δ(Cross vs. Random) shows how much better the model performs compared to random chance (50%) in cross-model critique tasks. Gray rows highlight the delta metrics. All numbers are in percentages (%).
| Iterative |
| Support |
🔼 This table presents a detailed comparison of the performance of the O1-mini and Qwen2.5-72B-Instruct large language models across various critique evaluation metrics. It shows how each model performs on self-critique tasks (evaluating its own generated solutions), cross-critique tasks (evaluating solutions generated by other models), and direct chain-of-thought generation (solving the problem without critique). The results are broken down by dataset, highlighting the strengths and weaknesses of each model in different scenarios. The performance is measured as the percentage of correct solutions or as the delta between the performances with/without critiques, offering a comprehensive view of their critique abilities.
read the caption
Table 5: Performance comparison of O1-mini and Qwen2.5-72B-Instruct across different evaluation metrics
Full paper#