TL;DR#
Creating realistic, animatable full-body avatars is a challenging problem in computer graphics, hindered by the difficulty of modeling complex light transport in articulated figures. Previous methods often lacked either high fidelity or the ability to relight the avatars in real-time, limiting their applications. This paper tackles this challenge by introducing a novel approach, ‘Relightable Full-Body Gaussian Codec Avatars’.
This approach uses 3D Gaussian Splatting for efficient geometry representation. It leverages learned radiance transfer functions, employing zonal harmonics for diffuse light and deferred shading for specular light to accurately capture complex light interactions. The key innovation lies in efficiently handling the rotation of light transport functions, ensuring realism for various body poses and lighting conditions. The results demonstrate the superior quality and efficiency of the proposed method compared to existing approaches.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to creating high-fidelity, relightable full-body avatars. This is a significant advancement in computer graphics and has implications for various applications, including virtual and augmented reality, video games, and digital filmmaking. The techniques presented, particularly the use of zonal harmonics and deferred shading, offer new avenues for efficient and realistic rendering of complex 3D models. The work also addresses the challenge of modeling realistic light transport in articulated figures, a problem that has hindered progress in many areas. This research opens up new directions for research in areas such as animation, virtual humans, and real-time rendering.
Visual Insights#

🔼 This figure showcases the capabilities of ‘Relightable Full Body Gaussian Codec Avatars,’ a novel approach for creating realistic digital avatars. It demonstrates the reconstruction of a complete human model, including body, face, and hands, from input data. The key innovation is the ability to relight the avatar under various lighting conditions (as shown in the ‘Env. map relighting’ section) and animate it expressively (‘Animation’), even showing unseen poses. The technique achieves photorealism through a combination of learned diffuse radiance transport (modeling how light interacts with the avatar’s surface) and deferred shading for specular effects (like highlights and reflections). This combined approach allows for complex light transport simulations, including global illumination, making the avatars look lifelike even in dynamic poses.
read the caption
Figure 1. Relightable Full Body Gaussian Codec Avatars. We present the first approach that enables reconstruction, relighting and expressive animation of full-body avatars including body, face, and hands. Our approach combines learned, orientation-dependent diffuse radiance transport and deferred-shading-based specular radiance transport to enable complex light transport such as global illumination for fully articulated human bodies.
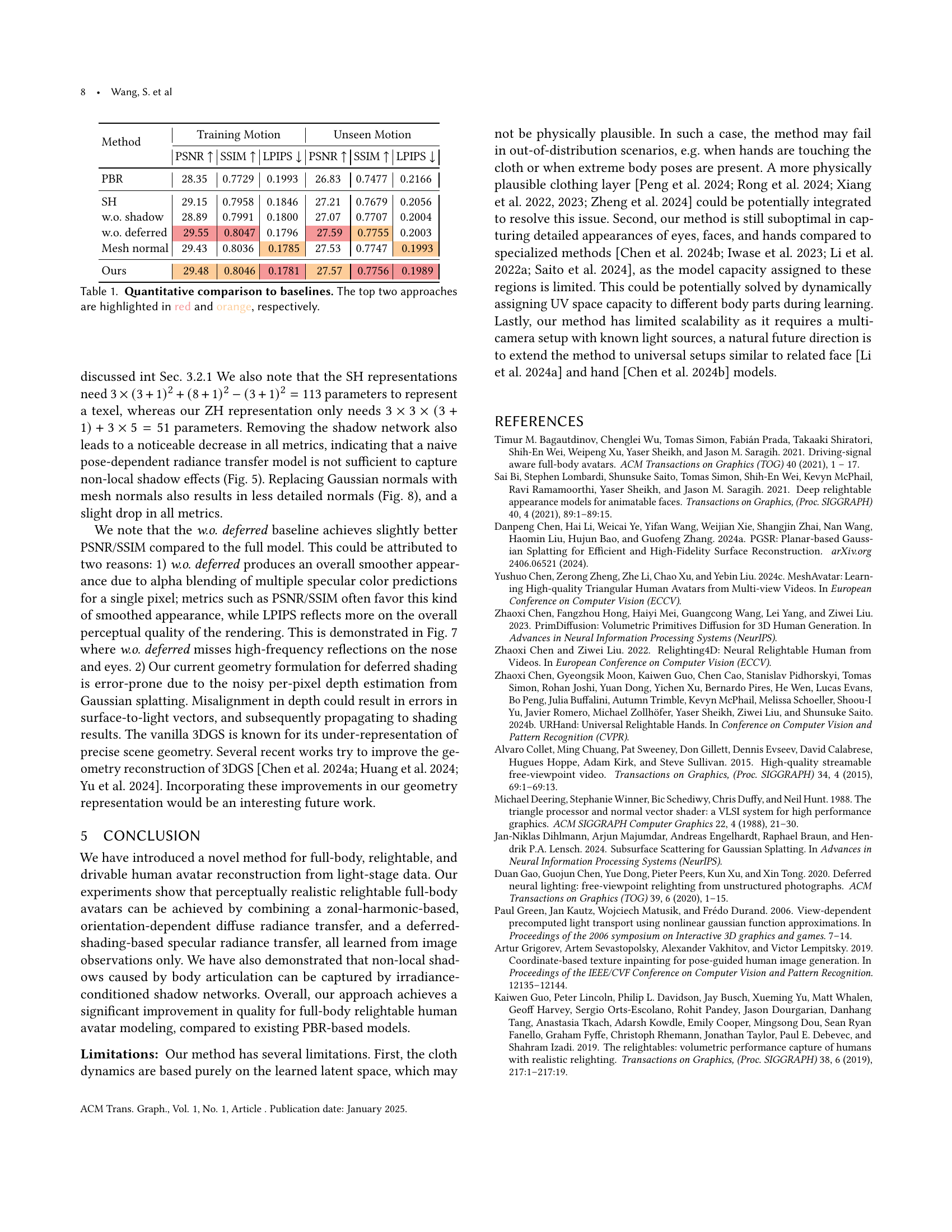
| Method | Training Motion | Unseen Motion | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| PBR | 28.35 | 0.7729 | 0.1993 | 26.83 | 0.7477 | 0.2166 |
| SH | 29.15 | 0.7958 | 0.1846 | 27.21 | 0.7679 | 0.2056 |
| w.o. shadow | 28.89 | 0.7991 | 0.1800 | 27.07 | 0.7707 | 0.2004 |
| w.o. deferred | 29.55 | 0.8047 | 0.1796 | 27.59 | 0.7755 | 0.2003 |
| Mesh normal | 29.43 | 0.8036 | 0.1785 | 27.53 | 0.7747 | 0.1993 |
| Ours | 29.48 | 0.8046 | 0.1781 | 27.57 | 0.7756 | 0.1989 |
🔼 This table presents a quantitative comparison of the proposed Relightable Full-Body Gaussian Codec Avatars method against several baseline methods. The metrics used for comparison include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The results are shown for two scenarios: ‘Training Motion’ which uses poses from the training data and ‘Unseen Motion’ which evaluates performance on unseen poses. Higher PSNR and SSIM values indicate better image quality, while a lower LPIPS value signifies better perceptual similarity to the ground truth. The top two performing methods in each scenario are highlighted for easy identification.
read the caption
Table 1. Quantitative comparison to baselines. The top two approaches are highlighted in red and orange, respectively.
In-depth insights#
Zonal Harmonics#
The concept of “Zonal Harmonics” in the context of relightable full-body avatars offers a computationally efficient approach to modeling diffuse radiance transfer. Unlike spherical harmonics, which require expensive rotations when dealing with articulated body parts, zonal harmonics provide a local coordinate frame representation, allowing for the efficient calculation of diffuse shading even under significant body pose changes. This is achieved by learning the light transport coefficients in the local frame, eliminating the need for costly rotations to the world coordinate system. The advantage lies in disentangling the local radiance transfer from the global articulation, significantly improving efficiency and reducing computational costs for real-time applications. This methodology shows promise for improving the realism and performance of full-body avatars by offering a more practical, yet effective, solution compared to previous methods. By combining zonal harmonics with a shadow network to address non-local effects, the framework achieves a balance between accuracy and real-time rendering feasibility, thus enabling the creation of highly realistic relightable full-body avatars. The choice of zonal harmonics is a key innovation, demonstrating the effectiveness of tailored mathematical solutions for the specific challenges presented by 3D human modeling.
Shadow Networks#
The concept of ‘Shadow Networks’ in the context of relightable full-body avatars is crucial for achieving photorealism. Avatars, especially full-bodied ones, exhibit complex self-occlusions and cast shadows that significantly affect their appearance. A straightforward approach, like ray tracing, is computationally expensive. Thus, a ‘Shadow Network’ offers a learned, efficient alternative. It likely takes precomputed irradiance maps (illumination data) as input, learns the relationships between body pose and resulting shadows, and then predicts shadows for novel poses and lighting conditions. This enables real-time or near real-time rendering, as the network doesn’t need to perform costly ray tracing during rendering. The success of a ‘Shadow Network’ hinges on the quality of the training data. Accurate, high-resolution irradiance maps and diverse body poses are critical. The network architecture itself would need to be carefully designed to capture the intricate nature of shadows while maintaining computational efficiency. Furthermore, generalization to unseen poses and lighting scenarios is a significant challenge. The network would need to learn a robust, abstract representation of shadowing phenomena rather than memorizing specific examples. A well-designed ‘Shadow Network’ is essential to achieve high fidelity and computationally efficient relightable full-body avatar rendering. It bridges the gap between photorealism and real-time performance.
Deferred Shading#
The concept of deferred shading, in the context of relightable full-body avatars, offers a powerful technique for enhancing the realism of specular reflections. By deferring the computation of specular lighting until after the geometry and other surface properties have been processed, it allows for a more accurate and efficient rendering of highlights, especially crucial for handling complex geometries and dynamic situations found in full-body models. This approach effectively separates the rendering of diffuse and specular components, resulting in improved rendering performance and increased visual fidelity. It is particularly beneficial for creating detailed specular effects in regions like eyes and skin without necessitating an excessive increase in the number of Gaussian primitives, which significantly improves computational efficiency and avoids blurring of specular highlights. This strategy leverages the fact that specular highlights are highly dependent on surface normals and viewing direction. The combination of deferred shading with learnable radiance transfer functions represents a significant advancement in realistically rendering relightable avatars, and it addresses limitations found in traditional methods which struggle to efficiently capture high-frequency specular detail in dynamic, articulated models.
Full-Body Avatar#
The concept of a “Full-Body Avatar” in this research paper signifies a significant advancement in digital human modeling. It moves beyond previous limitations of focusing solely on the head or partial body representations to achieve comprehensive, realistic modeling of the entire human form, encompassing the body, face, and hands. This holistic approach presents considerable challenges, necessitating novel solutions for accurate geometry reconstruction and, critically, realistic lighting and relighting capabilities. The paper’s focus on relightable avatars necessitates handling complex light transport effects, including global illumination and intricate shadowing caused by body articulation. Achieving this level of realism requires advanced rendering techniques that go beyond traditional methods, highlighting the importance of learning-based approaches for efficiently modeling the complex interactions between light and the human form. The successful creation of such avatars has profound implications for applications like virtual reality, animation, and digital human modeling, where accuracy, realistic appearance and dynamic behavior are paramount.
Future: Physics#
A section titled “Future: Physics” in a research paper would likely explore how physics-based modeling can improve future iterations of the presented work. This could involve integrating more sophisticated physical simulations, such as realistic cloth dynamics or advanced subsurface scattering, to enhance realism and accuracy. The discussion might also consider incorporating more robust handling of complex light transport phenomena. Improved methods for handling occlusion and shadows could be another area of focus. Exploring the integration of physically accurate material properties would provide a significant advancement in the realism of the generated avatars. Finally, the “Future: Physics” section might discuss limitations of the current physics-based approach and potential directions for future research to overcome these limitations and achieve even more lifelike and believable virtual humans.
More visual insights#
More on figures

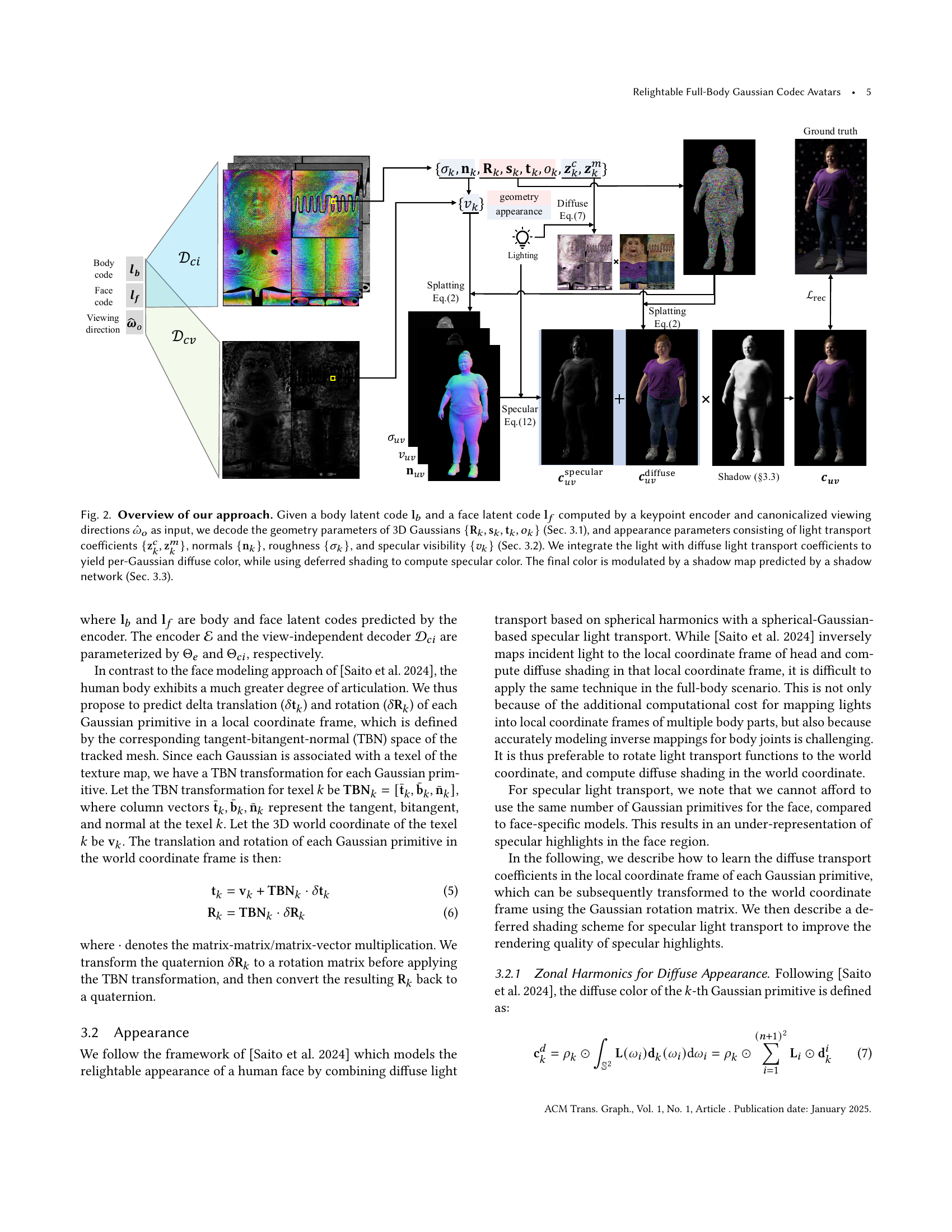
🔼 Figure 2 illustrates the process of generating relightable full-body avatars. The input consists of latent codes representing body and face geometry (obtained from a keypoint encoder), along with viewing directions. These inputs are fed into decoders that output 3D Gaussian parameters (position, orientation, scale, opacity) and appearance parameters (diffuse and specular light transport, normals, roughness, and specular visibility). Diffuse color is computed by integrating light with diffuse transport coefficients. Specular color is determined using deferred shading. Finally, a shadow map from a dedicated network adjusts the final color for realistic shadowing effects.
read the caption
Figure 2. Overview of our approach. Given a body latent code 𝐥bsubscript𝐥𝑏\mathbf{l}_{b}bold_l start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT and a face latent code 𝐥fsubscript𝐥𝑓\mathbf{l}_{f}bold_l start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT computed by a keypoint encoder and canonicalized viewing directions ω^osubscript^𝜔𝑜\hat{\mathbf{\omega}}_{o}over^ start_ARG italic_ω end_ARG start_POSTSUBSCRIPT italic_o end_POSTSUBSCRIPT as input, we decode the geometry parameters of 3D Gaussians {𝐑k,𝐬k,𝐭k,ok}subscript𝐑𝑘subscript𝐬𝑘subscript𝐭𝑘subscript𝑜𝑘\{\mathbf{R}_{k},\mathbf{s}_{k},\mathbf{t}_{k},o_{k}\}{ bold_R start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT , bold_s start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT , bold_t start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT , italic_o start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT } (Sec. 3.1), and appearance parameters consisting of light transport coefficients {𝐳kc,𝐳km}superscriptsubscript𝐳𝑘𝑐superscriptsubscript𝐳𝑘𝑚\{\mathbf{z}_{k}^{c},\mathbf{z}_{k}^{m}\}{ bold_z start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_c end_POSTSUPERSCRIPT , bold_z start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT }, normals {𝐧k}subscript𝐧𝑘\{\mathbf{n}_{k}\}{ bold_n start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT }, roughness {σk}subscript𝜎𝑘\{\sigma_{k}\}{ italic_σ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT }, and specular visibility {vk}subscript𝑣𝑘\{v_{k}\}{ italic_v start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT } (Sec. 3.2). We integrate the light with diffuse light transport coefficients to yield per-Gaussian diffuse color, while using deferred shading to compute specular color. The final color is modulated by a shadow map predicted by a shadow network (Sec. 3.3).
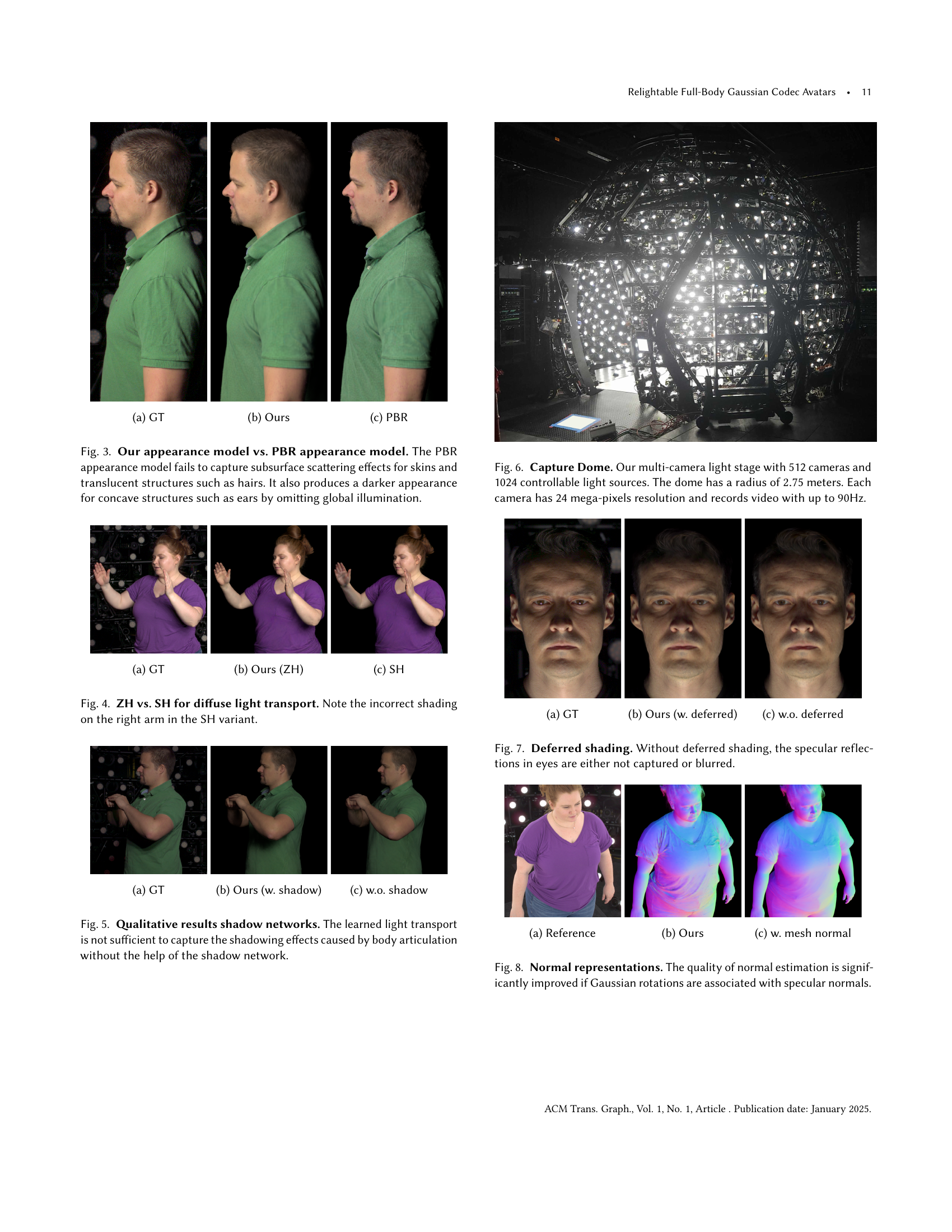
🔼 This figure shows a comparison of the relightable full-body avatar generation results. Subfigure (a) displays the ground truth (GT) image of a person from a multi-view light stage capture. The other subfigures show results from different methods. It highlights the differences in the quality and accuracy of rendering of various aspects like skin, hair, and specular highlights and shadows, especially under relighting conditions.
read the caption
(a) GT
🔼 This figure shows a qualitative comparison of the proposed relightable full-body avatar model with the ground truth. The image showcases the high-fidelity rendering capabilities of the model, especially in capturing fine details like hair strands and subtle skin textures. The image demonstrates the model’s ability to accurately represent complex lighting interactions and body articulation, resulting in photorealistic and consistent appearance across various poses and lighting conditions. This is in contrast to simpler methods that fail to capture subtle lighting effects or struggle with realistic rendering of hair and detailed skin features.
read the caption
(b) Ours
🔼 This figure shows a comparison of the results from the proposed method and a physically based rendering (PBR) based approach. The PBR approach fails to capture the subsurface scattering effects in the skin and translucent structures such as hair. It also omits global illumination, resulting in darker appearances for concave structures such as ears.
read the caption
(c) PBR
🔼 This figure compares the visual results of two different appearance models: the authors’ novel model and a physically based rendering (PBR) model. The comparison highlights the limitations of the PBR model in accurately representing the subtle details of human appearance. Specifically, the PBR model struggles to capture subsurface scattering effects, which are responsible for the realistic rendering of skin and translucent structures like hair. This leads to an unrealistic appearance in the PBR model, whereas the authors’ model successfully renders these details. Moreover, the PBR model produces a darker appearance in concave areas like the ears, due to the absence of global illumination effects which are handled more effectively in the authors’ model. This demonstrates the superior performance of the proposed model in generating more photorealistic and detailed human avatars.
read the caption
Figure 3. Our appearance model vs. PBR appearance model. The PBR appearance model fails to capture subsurface scattering effects for skins and translucent structures such as hairs. It also produces a darker appearance for concave structures such as ears by omitting global illumination.
🔼 (a) shows the ground truth image of a person. The figure is a comparison of different methods for generating relightable full-body avatars. (b) and (c) show the results of other methods, highlighting differences in the quality of the generated avatars with respect to the ground truth.
read the caption
(a) GT
🔼 This figure shows a comparison of the results of diffuse light transport using zonal harmonics (ZH), a method introduced in the paper, versus spherical harmonics (SH). The image shows three different views of a person’s arm and hand. The first image is the ground truth (GT) image. The second image is generated using the zonal harmonics method from the paper, and the third image is generated using spherical harmonics. The figure highlights the improved shading and realism of the ZH method, especially in the rendering of the shadows on the right arm which appear more natural and accurate in the ZH image.
read the caption
(b) Ours (ZH)
🔼 This figure shows a comparison of relighting results using spherical harmonics (SH) for diffuse light transport. The image on the right demonstrates incorrect shading, particularly noticeable on the right arm, highlighting the limitations of SH in accurately modeling diffuse light transport for highly articulated body parts.
read the caption
(c) SH
🔼 This figure compares the results of using zonal harmonics (ZH) and spherical harmonics (SH) for modeling diffuse light transport in a full-body avatar. The left side shows the ground truth (GT) rendering, while the middle and right sides depict renderings using ZH and SH, respectively. The comparison highlights that using SH leads to inaccuracies, particularly evident in incorrect shading on the avatar’s right arm, as shown in the GT, whereas ZH produces more accurate results closer to the ground truth.
read the caption
Figure 4. ZH vs. SH for diffuse light transport. Note the incorrect shading on the right arm in the SH variant.
🔼 This figure shows a comparison of the generated full-body avatar’s appearance with ground truth (GT) and the result from a physically-based rendering (PBR) model. The GT images are high-quality reference images of the full body captured under various lighting conditions and poses. The ‘Ours’ column displays the output from the proposed method, which is the relightable full-body Gaussian Codec Avatar model. This model demonstrates a significant improvement in realism compared to the PBR model, particularly in capturing the subtle effects of lighting and skin details. The PBR approach falls short in accurately representing the nuances of human appearance due to its limitations in handling global illumination and subsurface scattering. Specifically, the PBR model produces unrealistic shadows and lacks the fine-scale details found in the GT and the proposed model’s output.
read the caption
(a) GT

🔼 This figure shows a comparison of the model’s performance with and without the shadow network. The image shows a person in various poses. The left image is the ground truth, showing realistic shadows. The middle image is the output of the model when using the shadow network, demonstrating accurate shadowing that matches the ground truth. The right image is the output of the model without using the shadow network. Notice how the lack of shadows significantly reduces the realism and visual fidelity of the rendered human figure. This highlights the critical role of the shadow network in improving the model’s ability to accurately capture and represent shadows.
read the caption
(b) Ours (w. shadow)
🔼 This figure shows a qualitative comparison of the proposed method with and without the shadow network. The image in the left column is the ground truth, the middle column shows the result from the proposed method, and the right column shows the result when the shadow network is not used. This demonstrates the impact of the shadow network on the overall rendering quality of the model. The shadow network is particularly beneficial in enhancing the realism of the shadows, especially in areas where body parts occlude each other, resulting in more natural-looking shadows.
read the caption
(c) w.o. shadow
🔼 Figure 5 presents a comparison of relightable full-body avatars rendered with and without a dedicated shadow network. The leftmost image is the ground truth. The middle image shows the result when only the learned light transport is used to model shadows, which is insufficient for accurately capturing shadows cast by body articulation. The rightmost image shows the result when a shadow network is added to predict shadows explicitly. This demonstrates the importance of the shadow network in capturing the full range of shadowing effects caused by body articulation.
read the caption
Figure 5. Qualitative results shadow networks. The learned light transport is not sufficient to capture the shadowing effects caused by body articulation without the help of the shadow network.
🔼 This image shows the multi-camera light stage used for data capture in the research. The setup consists of a dome with a 2.75-meter radius, housing 512 cameras and 1024 individually controllable light sources. Each camera captures high-resolution (24 megapixels) video at a frame rate of up to 90 frames per second. This sophisticated system allows for the capture of highly detailed, multi-viewpoint data under precisely controlled lighting conditions.
read the caption
Figure 6. Capture Dome. Our multi-camera light stage with 512 cameras and 1024 controllable light sources. The dome has a radius of 2.752.752.752.75 meters. Each camera has 24 mega-pixels resolution and records video with up to 90Hz.
🔼 Figure 3 shows a comparison of the appearance model presented in the paper against a physically based rendering (PBR) model. The images are side-by-side comparisons of the ground truth (GT), the authors’ model, and a PBR baseline. The comparison highlights that the PBR model fails to capture subtle effects such as subsurface scattering in the skin and translucency in hair, resulting in a less realistic rendering. The authors’ model produces a more accurate and lifelike rendering, particularly in areas like the ears, where the PBR model omits global illumination leading to a darker appearance.
read the caption
(a) GT
🔼 This figure shows a comparison of the specular reflections rendered with and without deferred shading. The image (b) shows results from the proposed method that uses deferred shading for specular radiance transfer, leading to sharper and more realistic specular highlights. The comparison highlights the method’s effectiveness in capturing high-fidelity specular reflections in real-time.
read the caption
(b) Ours (w. deferred)
🔼 This figure shows a qualitative comparison of relighting results obtained with and without deferred shading. The image labeled ‘(c) w.o. deferred’ represents the outcome when deferred shading is not used in the rendering process. This demonstrates that deferred shading is crucial for producing realistic specular reflections. Without deferred shading, specular highlights appear blurry or under-represented, especially in areas like the eyes, which typically show strong specular effects.
read the caption
(c) w.o. deferred

🔼 This figure demonstrates the effectiveness of deferred shading in rendering realistic specular reflections. The leftmost image is the ground truth, showing sharp and detailed specular highlights, particularly in the eyes. The middle image shows the result with deferred shading, closely matching the ground truth’s fidelity. The rightmost image, however, lacks the same level of detail, showcasing blurred or missing specular highlights in the eyes. This comparison highlights the importance of deferred shading in capturing high-frequency specular details, especially when dealing with limited computational resources or representations.
read the caption
Figure 7. Deferred shading. Without deferred shading, the specular reflections in eyes are either not captured or blurred.

🔼 This figure shows a comparison of the quality of normal estimation. (a) shows the ground truth normal map of a human body. (b) shows the normal map generated by the proposed method, which leverages the Gaussian rotations to produce detailed normal maps, especially in regions with fine details. (c) shows the normal map generated by an alternative method that uses mesh normals for normal estimation. The comparison highlights the improvement achieved by associating Gaussian rotations with specular normals in the proposed method.
read the caption
(a) Reference

🔼 This image shows a comparison between the ground truth (GT) and the results generated by the proposed method. The figure highlights the capabilities of the model in capturing fine-grained details and handling complex lighting scenarios, showcasing the superiority of the ‘Ours’ approach in terms of visual fidelity and accuracy.
read the caption
(b) Ours

🔼 This figure shows a qualitative comparison of the results obtained using different normal estimation methods. The image (c) specifically shows the results when using mesh normals for specular radiance transfer, indicating a comparison to other methods of estimating normals for the purpose of rendering specular reflections (such as eye-glints). The use of mesh normals in this context likely aims to improve the accuracy of these reflections by leveraging geometry from a mesh-based representation.
read the caption
(c) w. mesh normal

🔼 Figure 8 showcases a comparison of normal estimations for a relightable full-body avatar. It demonstrates that associating Gaussian rotations directly with specular normals yields a significant improvement in the accuracy and detail of the normal maps. This leads to more realistic and high-fidelity specular highlights and reflections in the final rendered images of the avatar.
read the caption
Figure 8. Normal representations. The quality of normal estimation is significantly improved if Gaussian rotations are associated with specular normals.

🔼 This figure showcases the relighting capabilities of the proposed Relightable Full-Body Gaussian Codec Avatars on unseen motion sequences. The left two columns display results using environment map-based relighting, demonstrating the model’s ability to realistically adjust the avatar’s appearance under various global illumination conditions. The right two columns show the results obtained using point-light-based relighting, highlighting the model’s flexibility in handling diverse and complex lighting scenarios. The consistent, high-quality rendering across different poses and lighting conditions underscores the robustness and accuracy of the proposed method in generating photorealistic avatars.
read the caption
Figure 9. Relighting result on unseen motion. We show environment-map-based relighting on the left two columns and point-light-based relighting on the right two columns.
Full paper#