TL;DR#
Current open-source multimodal models struggle with fluent interactions across modalities and lack end-to-end audio generation. This limits their broad applications. The quality of user interaction experiences is also compromised, especially within multimodal dialogue systems.
The paper introduces Baichuan-Omni-1.5, an omni-modal model designed to address these issues. It uses a comprehensive dataset, a novel audio tokenizer, and a multi-stage training strategy to achieve fluent and high-quality interactions across modalities without compromising any modality’s capabilities. Baichuan-Omni-1.5 demonstrates significant improvements over existing models, particularly in medical image understanding.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces Baichuan-Omni-1.5, a leading omni-modal model that excels in various benchmarks, particularly in medical image understanding. Its open-source nature and comprehensive evaluation across multiple modalities make it a valuable resource for researchers working on multi-modal large language models. The work also opens avenues for further research into enhancing omni-modal understanding and high-quality end-to-end audio generation capabilities.
Visual Insights#

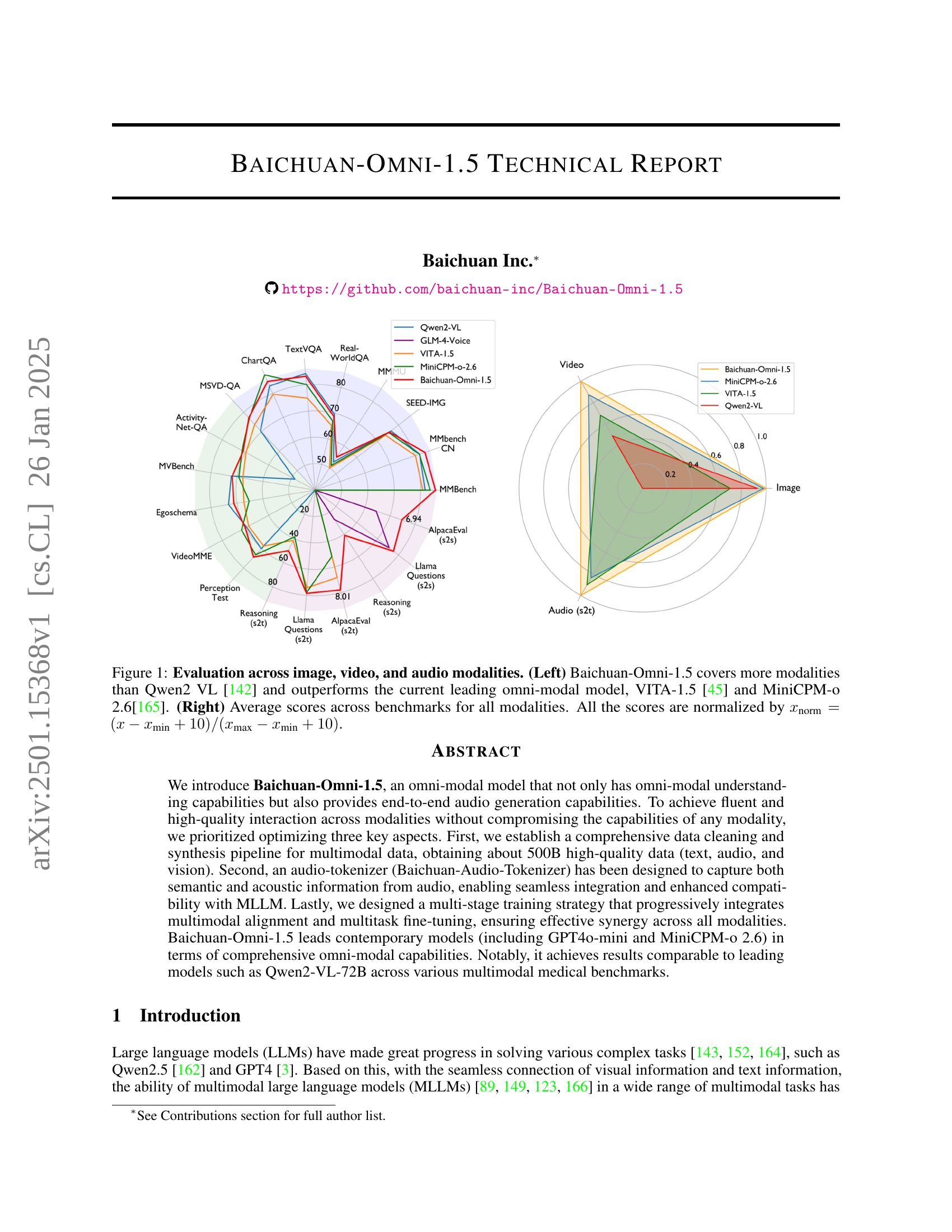
🔼 Figure 1 presents a comparative analysis of Baichuan-Omni-1.5 against other leading multimodal models (Qwen2-VL, VITA-1.5, and MiniCPM-0 2.6) across various modalities (image, video, and audio). The left panel is a radar chart visualizing the relative performance of these models on multiple benchmarks. It highlights that Baichuan-Omni-1.5 surpasses the others in terms of both the number of modalities it supports and its overall performance. The right panel displays average benchmark scores, again demonstrating Baichuan-Omni-1.5’s superiority. Note that all scores are normalized using a specified formula to ensure fair comparison.
read the caption
Figure 1: Evaluation across image, video, and audio modalities. (Left) Baichuan-Omni-1.5 covers more modalities than Qwen2 VL [142] and outperforms the current leading omni-modal model, VITA-1.5 [45] and MiniCPM-o 2.6[165]. (Right) Average scores across benchmarks for all modalities. All the scores are normalized by xnorm=(x−xmin+10)/(xmax−xmin+10)subscript𝑥norm𝑥subscript𝑥min10subscript𝑥maxsubscript𝑥min10x_{\text{norm}}=(x-x_{\text{min}}+10)/(x_{\text{max}}-x_{\text{min}}+10)italic_x start_POSTSUBSCRIPT norm end_POSTSUBSCRIPT = ( italic_x - italic_x start_POSTSUBSCRIPT min end_POSTSUBSCRIPT + 10 ) / ( italic_x start_POSTSUBSCRIPT max end_POSTSUBSCRIPT - italic_x start_POSTSUBSCRIPT min end_POSTSUBSCRIPT + 10 ).
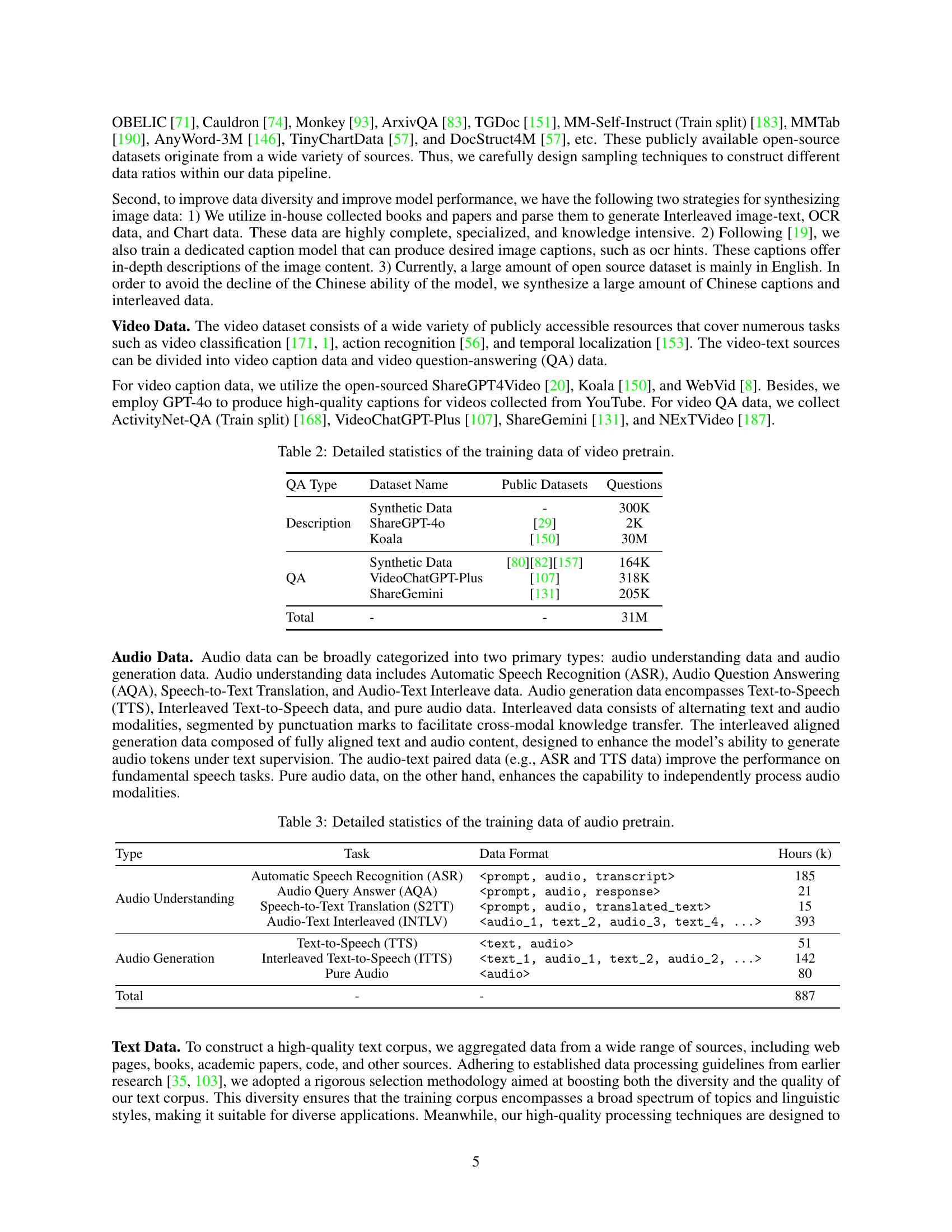
| Phase | Type | Public Datasets | Public | In-House |
| Pretrain | Pure-Text | - | - | 150.7M |
| Caption | [86][67][189][23] | 33.2M | 49.1M | |
| Interleaved | [71] | 19.1M | 28.7M | |
| OCR | [57] | 12.4M | 7.8M | |
| Total | - | - | 71.3M | 238.2M |
🔼 Table 1 presents a detailed breakdown of the image pre-training data used in the Baichuan-Omni-1.5 model. It shows the quantity of data for each phase (pre-training) and type (pure text, caption, and interleaved data), distinguishing between publicly available and internally collected datasets. The total amount of data used in the image pre-training phase is also provided.
read the caption
Table 1: Detailed statistics of the training data of image pretrain.
In-depth insights#
Omni-modal prowess#
The concept of “Omni-modal prowess” in a research paper would likely explore a model’s ability to seamlessly integrate and process information from multiple modalities, such as text, images, audio, and video. A high-performing omni-modal model should not only understand each modality independently but also exhibit cross-modal understanding, allowing it to effectively connect information across different sensory inputs. The paper might benchmark performance across various tasks, demonstrating how the model leverages this combined information for superior results. Key metrics would likely be accuracy and efficiency, highlighting the model’s ability to handle diverse inputs swiftly and accurately. A deeper analysis could also investigate the architecture’s design choices, such as the use of shared representations or separate modality-specific encoders, which impact the model’s capacity for omni-modal processing. Ultimately, “Omni-modal prowess” would showcase the advanced capabilities of a model beyond single-modality strengths.
Data synthesis#
Data synthesis in large language models (LLMs) is crucial for bridging the gap between limited real-world data and the vast amount of training required for optimal performance. Effective data synthesis strategies focus on augmenting existing datasets, rather than solely relying on real-world data collection. This is especially important for tasks like multimodal understanding, where obtaining sufficient high-quality data across different modalities is challenging. The paper highlights the use of various techniques, including data cleaning and synthesis pipelines, to obtain high-quality multimodal data. A comprehensive data cleaning process is essential to eliminate noise and inconsistencies, ensuring that the synthesized data aligns with the desired model capabilities. Careful data preprocessing and synthesis are key to improving both the efficiency and effectiveness of model training. The creation of interleaved image-audio-text and video-audio-text data is highlighted as a particularly innovative method in the research paper to enhance the cross-modal interaction capabilities and improve model performance in various downstream tasks. Furthermore, the method of synthesizing data by interleaving various modalities (text, audio, and visual) into a unified model emerged as crucial for improving overall model performance.
Training strategy#
The research paper details a multi-stage training strategy for Baichuan-Omni-1.5, a large multimodal language model. This approach prioritizes optimizing three key aspects: data cleaning and synthesis, tokenizer design, and a progressive training scheme. High-quality data (500B tokens) is crucial, encompassing text, audio, and visual modalities, highlighting a focus on data diversity and quality control. The Baichuan-Audio-Tokenizer is designed to capture semantic and acoustic information, allowing for seamless audio integration within the multimodal framework. The multi-stage training progressively integrates multimodal alignment, starting with separate image-text and then image-audio-text pretraining before a final omni-modal stage. This phased approach aims to mitigate modality conflicts, ensuring fluency and quality across all modalities. The final supervised fine-tuning stage focuses on enhancing performance across diverse tasks, using high-quality data. The multi-stage strategy demonstrates a thoughtful approach, balancing the optimization of individual modalities with the seamless integration of multimodal understanding and generation, ultimately improving model robustness and capabilities.
Medical potential#
The research paper highlights the significant medical potential of advanced multimodal large language models (MLLMs). MLLMs, by integrating diverse data modalities such as text, images, and audio, demonstrate enhanced capabilities in medical image analysis, diagnosis support, and even drug discovery. The paper showcases the superior performance of their Baichuan-Omni-1.5 model on medical benchmarks, surpassing existing models. This improved performance stems from the model’s ability to seamlessly integrate and interpret complex medical data, thus enabling more accurate diagnoses and facilitating breakthroughs in clinical practice and research. Key improvements include higher precision in medical image understanding and enhanced cross-modal interactions, suggesting wider applicability in various clinical scenarios. However, the research also acknowledges the need for further development to address challenges such as improving the model’s robustness and ensuring data privacy and security within the medical context.
Future outlook#
The future of multimodal large language models (MLLMs) appears exceptionally promising, driven by the continued advancements in model architectures and training techniques. Improved data synthesis and cleaning processes will be crucial, leading to more comprehensive and higher-quality multimodal datasets. Developing more effective strategies to resolve modality conflicts and achieve seamless integration of diverse data types will be a key area of focus. This may involve novel model architectures or innovative training approaches. Real-time performance and efficient processing for diverse input types (text, audio, image, video) will also be a key factor, along with enhancing models’ abilities to deal with complex and nuanced scenarios. The integration of increasingly diverse and specialized modalities, like medical and scientific data, will enhance application scope. We can expect even more natural and efficient human-computer interaction with the development of more human-like qualities, such as expressiveness in speech generation.
More visual insights#
More on figures

🔼 Baichuan-Omni-1.5 is a multimodal model that can process various input modalities (text, audio, image, and video) and generate corresponding outputs (text and audio). The figure details the model’s architecture. It shows how visual and audio information is encoded and fed into a shared LLM decoder. This decoder alternately generates text and audio tokens. The audio tokens are then passed to an audio decoder to generate the final audio output. This allows for end-to-end audio generation and seamless integration across modalities.
read the caption
Figure 2: Architecture of Baichuan-Omni-1.5 . Our model is designed to process both pure text/audio inputs and combinations of video/image with text/audio. When generating audio, the Baichuan-Omni-1.5 LLM Decoder alternately predicts text tokens and audio tokens. The audio tokens are then decoded by the Audio Decoder to produce the final audio.

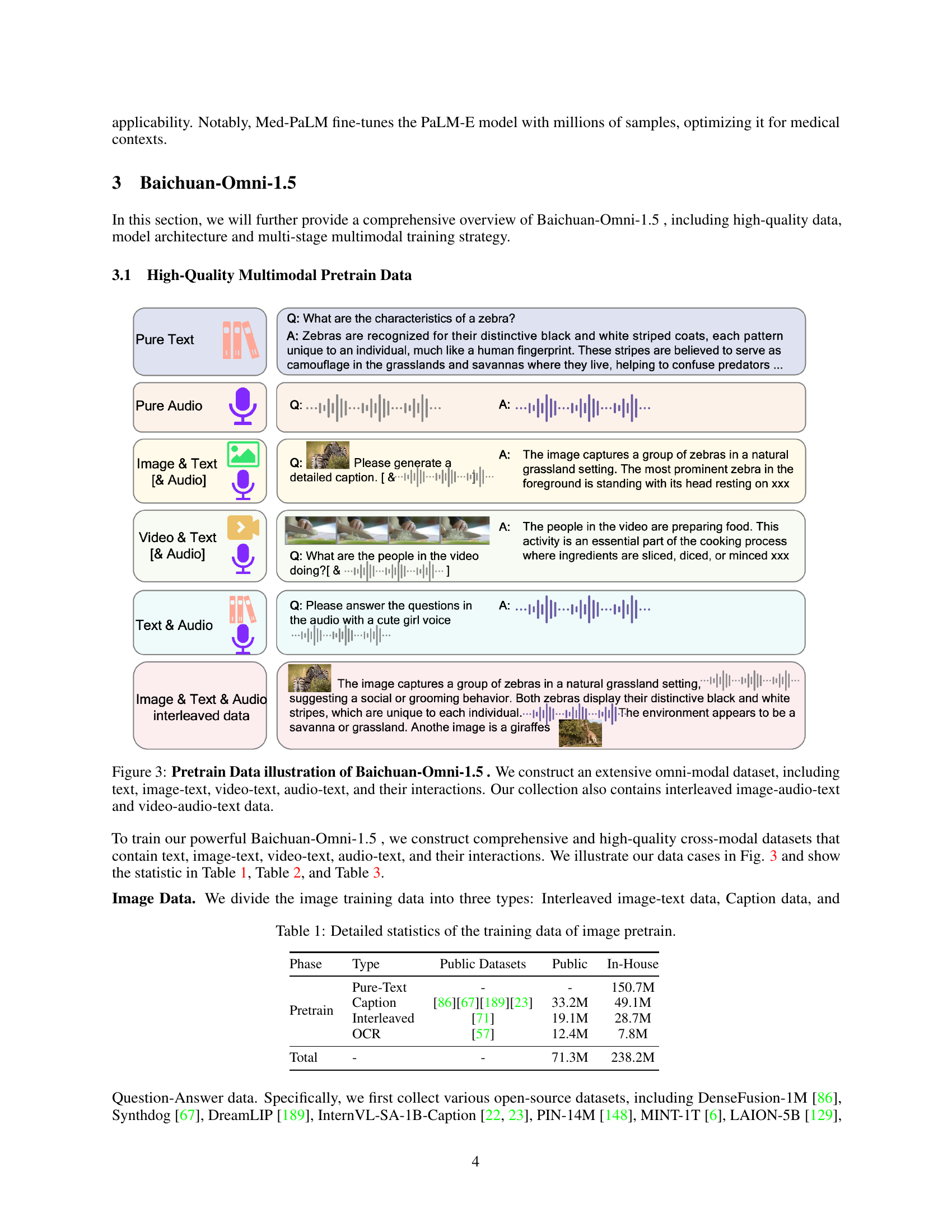
🔼 Figure 3 illustrates the diverse multimodal data used to pre-train Baichuan-Omni-1.5. The dataset includes various data types: pure text, image-text pairs, video-text pairs, and audio-text pairs. Importantly, it also incorporates more complex interleaved data formats, such as image-audio-text triplets and video-audio-text triplets. This rich and varied dataset allows the model to learn comprehensive cross-modal relationships and achieve a high level of multimodal understanding.
read the caption
Figure 3: Pretrain Data illustration of Baichuan-Omni-1.5 . We construct an extensive omni-modal dataset, including text, image-text, video-text, audio-text, and their interactions. Our collection also contains interleaved image-audio-text and video-audio-text data.

🔼 This figure illustrates the architecture of the Baichuan-Omni-1.5 model’s audio branch. It uses a Residual Vector Quantization (RVQ) based audio tokenizer to convert raw audio into discrete tokens, which are then processed by a Large Language Model (LLM). The audio tokens are further decoded into a speech waveform using a flow-matching model based on a U-Net architecture and a HiFi-GAN vocoder. The model utilizes a multi-stage training strategy to improve speech quality, incorporating techniques such as multi-scale Mel loss. The figure highlights the different components of the audio processing pipeline and their interactions, showing how raw audio is transformed into meaningful representations understandable by the LLM, then ultimately converted back into speech.
read the caption
Figure 4: Audio tokenizer and audio decoder based on flow matching model.

🔼 This figure illustrates the training pipeline of the Baichuan-Omni-1.5 model. The training process is divided into four stages. Stage 1 pre-trains the model on image-text data to enable visual understanding. Stage 2 incorporates audio using a newly designed audio tokenizer and embedding layer, enabling end-to-end audio processing. Stage 3 integrates image, audio, video, and text data to achieve comprehensive omni-modal understanding, extending the model’s maximum sequence length for handling longer inputs. Finally, Stage 4 fine-tunes the model through supervised learning using omni-modal data, with specific sub-stages focusing on improving both instruction following and audio generation capabilities.
read the caption
Figure 5: Training Pipeline of Baichuan-Omni-1.5 . The pretraining phase is divided into three stages to incrementally incorporate vision and audio into the LLM while relieving modality conflicts. Stage 1 focuses on image-text training, which extends an LLM to process and understand visual input. Stage 2 extends an LLM pre-trained on visual data to understand audio input in end-to-end manner by incorporating our Baichuan-Audio-Tokenizer, a newly introduced audio embedding layers and an independent audio head. Stage 3 focuses on training Baichuan-Omni-1.5 using high-quality cross-modal interaction datasets encompassing image-audio-text and video-audio-text format, and extends the maximum sequence length to 64k to support long audio and video stream. Stage 4 enhances the model’s instruction following and audio capabilities through supervised fine-tuning with omni-modal data. Stage 4.1: Freeze the Audio Head using omni-modal understanding data to boost modality interactivity and multitasking comprehension. Stage 4.2: Activate only the Audio Head and Audio Embed layer, with audio generation data to improve speech generation capabilities.
More on tables
| QA Type | Dataset Name | Public Datasets | Questions |
| Description | Synthetic Data | - | 300K |
| ShareGPT-4o | [29] | 2K | |
| Koala | [150] | 30M | |
| QA | Synthetic Data | [80][82][157] | 164K |
| VideoChatGPT-Plus | [107] | 318K | |
| ShareGemini | [131] | 205K | |
| Total | - | - | 31M |
🔼 This table presents a detailed breakdown of the video training data used in the Baichuan-Omni-1.5 model. It categorizes the data into question-answering (QA) and description types, specifying the dataset source (public or synthetic), and the number of questions and descriptions available for training.
read the caption
Table 2: Detailed statistics of the training data of video pretrain.
| Type | Task | Data Format | Hours (k) |
| Audio Understanding | Automatic Speech Recognition (ASR) | <prompt, audio, transcript> | 185 |
| Audio Query Answer (AQA) | <prompt, audio, response> | 21 | |
| Speech-to-Text Translation (S2TT) | <prompt, audio, translated_text> | 15 | |
| Audio-Text Interleaved (INTLV) | <audio_1, text_2, audio_3, text_4, ...> | 393 | |
| Audio Generation | Text-to-Speech (TTS) | <text, audio> | 51 |
| Interleaved Text-to-Speech (ITTS) | <text_1, audio_1, text_2, audio_2, ...> | 142 | |
| Pure Audio | <audio> | 80 | |
| Total | - | - | 887 |
🔼 This table presents a detailed breakdown of the audio training data used in the Baichuan-Omni-1.5 model. It shows the different types of audio data used (audio understanding and audio generation), their specific tasks (ASR, AQA, etc.), the data format, and the total number of hours of audio data for each task. This information highlights the scale and diversity of the audio data used to train the model’s audio capabilities.
read the caption
Table 3: Detailed statistics of the training data of audio pretrain.
| Category | Text | Image | Video | Audio | Image-Audio |
| Quantity | 400K | 16M | 100K | 282K | 60K |
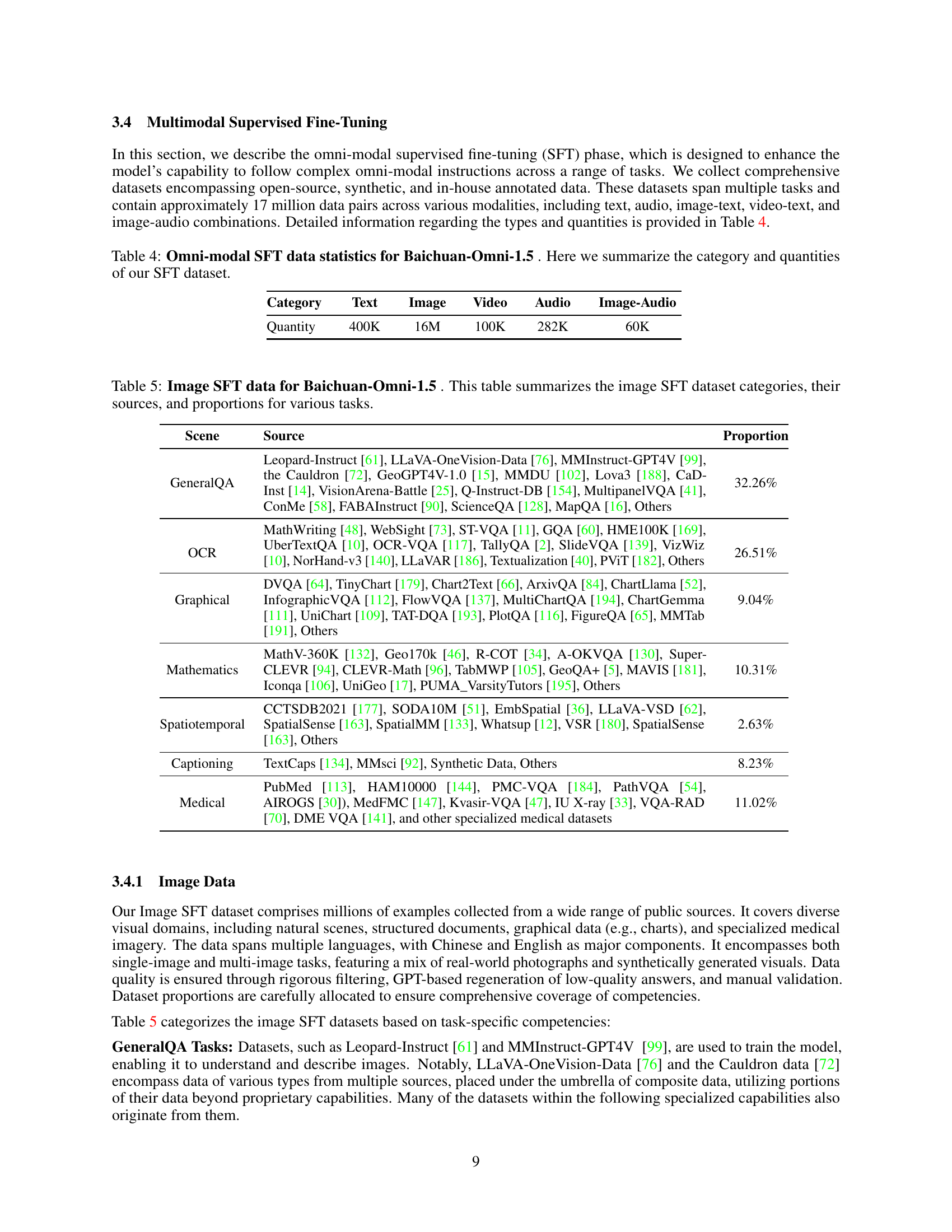
🔼 Table 4 presents a summary of the dataset used for the supervised fine-tuning stage of the Baichuan-Omni-1.5 model. It details the quantity of data in various modalities (text, image, video, audio) and combinations thereof that were used to train the model to perform more effectively on a wider range of complex tasks involving multiple modalities. The table breaks down the data by category and provides counts to illustrate the scale and diversity of the training data.
read the caption
Table 4: Omni-modal SFT data statistics for Baichuan-Omni-1.5 . Here we summarize the category and quantities of our SFT dataset.
| Scene | Source | Proportion |
| GeneralQA | Leopard-Instruct [61], LLaVA-OneVision-Data [76], MMInstruct-GPT4V [99], the Cauldron [72], GeoGPT4V-1.0 [15], MMDU [102], Lova3 [188], CaD-Inst [14], VisionArena-Battle [25], Q-Instruct-DB [154], MultipanelVQA [41], ConMe [58], FABAInstruct [90], ScienceQA [128], MapQA [16], Others | 32.26% |
| OCR | MathWriting [48], WebSight [73], ST-VQA [11], GQA [60], HME100K [169], UberTextQA [10], OCR-VQA [117], TallyQA [2], SlideVQA [139], VizWiz [10], NorHand-v3 [140], LLaVAR [186], Textualization [40], PViT [182], Others | 26.51% |
| Graphical | DVQA [64], TinyChart [179], Chart2Text [66], ArxivQA [84], ChartLlama [52], InfographicVQA [112], FlowVQA [137], MultiChartQA [194], ChartGemma [111], UniChart [109], TAT-DQA [193], PlotQA [116], FigureQA [65], MMTab [191], Others | 9.04% |
| Mathematics | MathV-360K [132], Geo170k [46], R-COT [34], A-OKVQA [130], Super-CLEVR [94], CLEVR-Math [96], TabMWP [105], GeoQA+ [5], MAVIS [181], Iconqa [106], UniGeo [17], PUMA_VarsityTutors [195], Others | 10.31% |
| Spatiotemporal | CCTSDB2021 [177], SODA10M [51], EmbSpatial [36], LLaVA-VSD [62], SpatialSense [163], SpatialMM [133], Whatsup [12], VSR [180], SpatialSense [163], Others | 2.63% |
| Captioning | TextCaps [134], MMsci [92], Synthetic Data, Others | 8.23% |
| Medical | PubMed [113], HAM10000 [144], PMC-VQA [184], PathVQA [54], AIROGS [30]), MedFMC [147], Kvasir-VQA [47], IU X-ray [33], VQA-RAD [70], DME VQA [141], and other specialized medical datasets | 11.02% |
🔼 Table 5 details the composition of the image data used for supervised fine-tuning of the Baichuan-Omni-1.5 model. It breaks down the data by task category (GeneralQA, OCR, Graphical, Mathematics, Spatiotemporal, Captioning, Medical), listing the specific datasets contributing to each category and the percentage of the overall image SFT dataset each category represents. This provides insight into the diversity and distribution of training data used to enhance the model’s capabilities in various visual understanding tasks.
read the caption
Table 5: Image SFT data for Baichuan-Omni-1.5 . This table summarizes the image SFT dataset categories, their sources, and proportions for various tasks.
| Comprehensive Tasks | |||||||||||||||
| Model |
|
|
|
|
| ||||||||||
| Proprietary Models | |||||||||||||||
| GPT-4o | 88.0♢ | 78.3♢ | 62.3♢ | 86.0♢ | - | ||||||||||
| GPT-4o-mini | 82.0 | 67.6 | 52.2 | 63.6 | 70.8 | ||||||||||
| Open-source Models (Pure text) | |||||||||||||||
| MAP-Neo (7B) | 58.2 | 55.1 | 33.9 | 57.5 | - | ||||||||||
| Qwen1.5-Chat (7B) | 61.5 | 68.0 | 39.3 | 68.8 | - | ||||||||||
| Llama3-Instruct (8B) | 67.1 | 51.7 | 38.4 | 50.7 | - | ||||||||||
| OLMo (7B) | 28.4 | 25.6 | 19.9 | 27.3 | - | ||||||||||
| Open-source Models (Omni-modal) | |||||||||||||||
| VITA (8x7B) | 71.0∗ | 46.6 | 46.2∗ | 56.7∗ | - | ||||||||||
| VITA-1.5 (7B) | 71.0 | 75.1 | 47.9 | 65.6 | 57.4 | ||||||||||
| Baichuan-Omni (7B) | 65.3 | 72.2 | 47.7 | 68.9 | - | ||||||||||
| MiniCPM-o 2.6 (7B) | 65.3 | 63.3 | 50.9 | 61.5 | 56.3 | ||||||||||
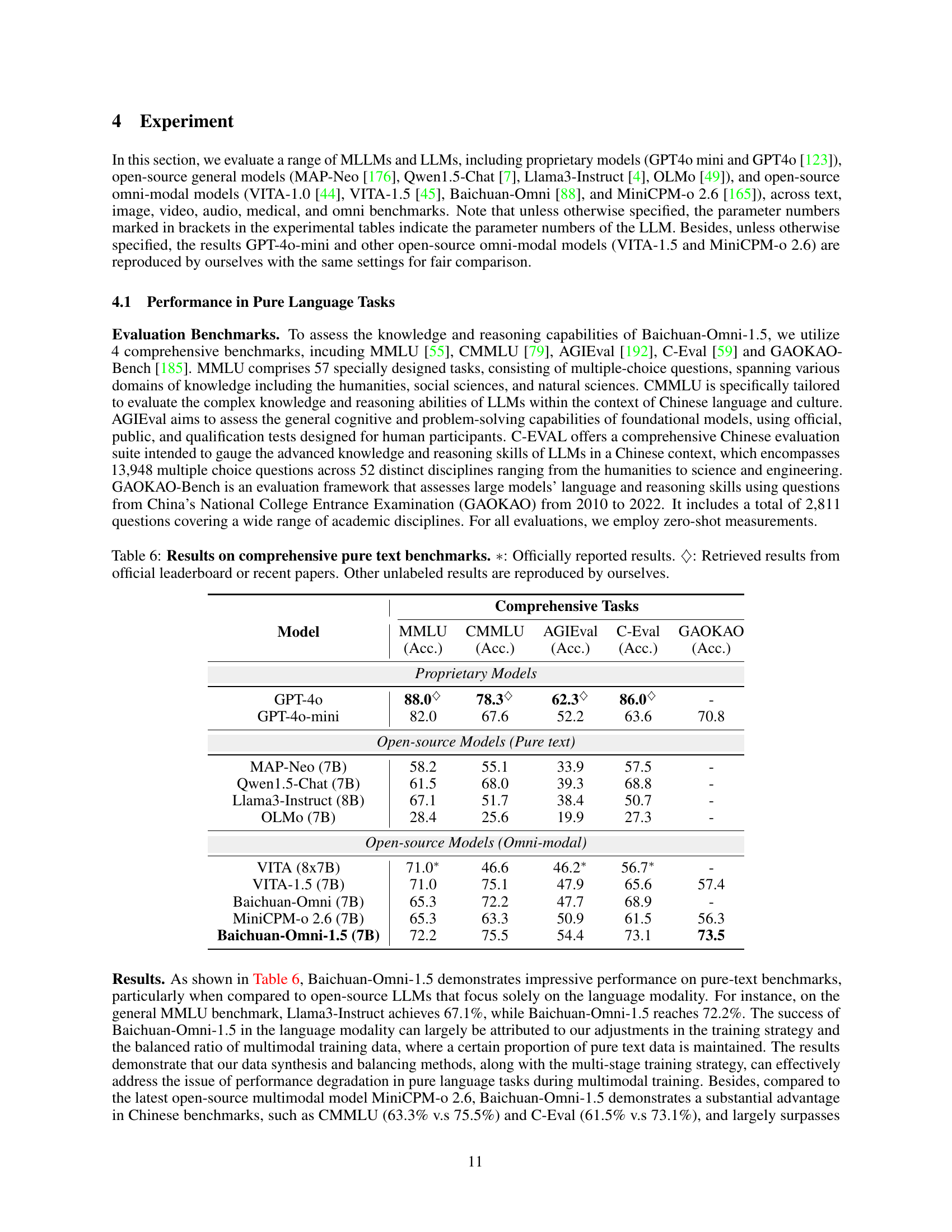
| Baichuan-Omni-1.5 (7B) | 72.2 | 75.5 | 54.4 | 73.1 | 73.5 | ||||||||||
🔼 Table 6 presents a comprehensive comparison of various large language models (LLMs) on several prominent pure text benchmarks. It includes both proprietary models (those developed by companies and not publicly available) and open-source models (those available for public use). The benchmarks used assess general knowledge, reasoning abilities, and Chinese language understanding. Results are shown as accuracy scores, with distinctions made for officially reported scores, scores retrieved from leaderboards, and scores reproduced by the authors. This allows for a nuanced comparison of the models’ capabilities across different assessment types.
read the caption
Table 6: Results on comprehensive pure text benchmarks. ∗*∗: Officially reported results. ♢♢\diamondsuit♢: Retrieved results from official leaderboard or recent papers. Other unlabeled results are reproduced by ourselves.
| MMLU |
| (Acc.) |
🔼 Table 7 presents a comparison of various models’ performance on multiple-choice and yes/no question benchmarks related to image understanding. The models are categorized into proprietary (closed-source) models and open-source models (further divided into vision-language models and omni-modal models). The benchmarks used assess accuracy across different visual question answering tasks, reflecting the models’ abilities in understanding image content and responding accordingly. Results marked with ∗ are officially reported scores, while those marked with ♢ are obtained from official leaderboards or recent papers. The remaining results were reproduced by the authors of the paper for fair comparison.
read the caption
Table 7: Results on Multi-choice benchmarks and Yes-or-No benchmarks. ∗*∗: Officially reported results. ♢♢\diamondsuit♢: Retrieved results from official leaderboard or recent papers. Other unlabeled results are reproduced by ourselves.
| CMMLU |
| (Acc.) |
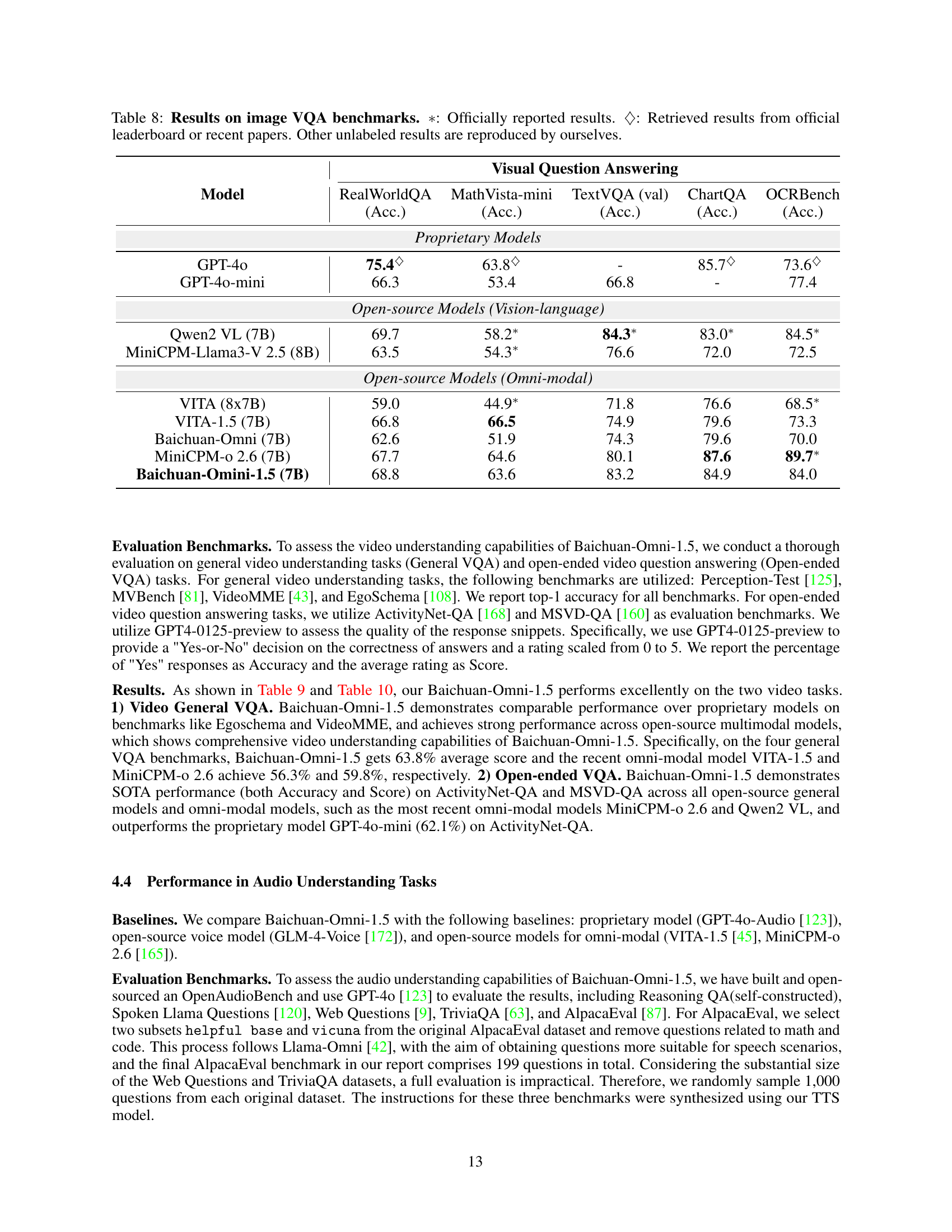
🔼 Table 8 presents a comparison of various models’ performance on several Image Visual Question Answering (VQA) benchmarks. The benchmarks assess a model’s ability to understand and answer questions about images. The table includes both proprietary models (those developed and maintained by companies like OpenAI) and open-source models (publicly available models). For each model, the table shows the accuracy achieved on each benchmark. Results marked with a * are officially reported by the model’s developers, while those marked with a ♢ were taken from official leaderboards or recent research papers. The remaining results were reproduced by the authors of this paper to ensure consistent comparison. This allows for a fair comparison across different models, considering potential variations in testing conditions.
read the caption
Table 8: Results on image VQA benchmarks. ∗*∗: Officially reported results. ♢♢\diamondsuit♢: Retrieved results from official leaderboard or recent papers. Other unlabeled results are reproduced by ourselves.
| AGIEval |
| (Acc.) |
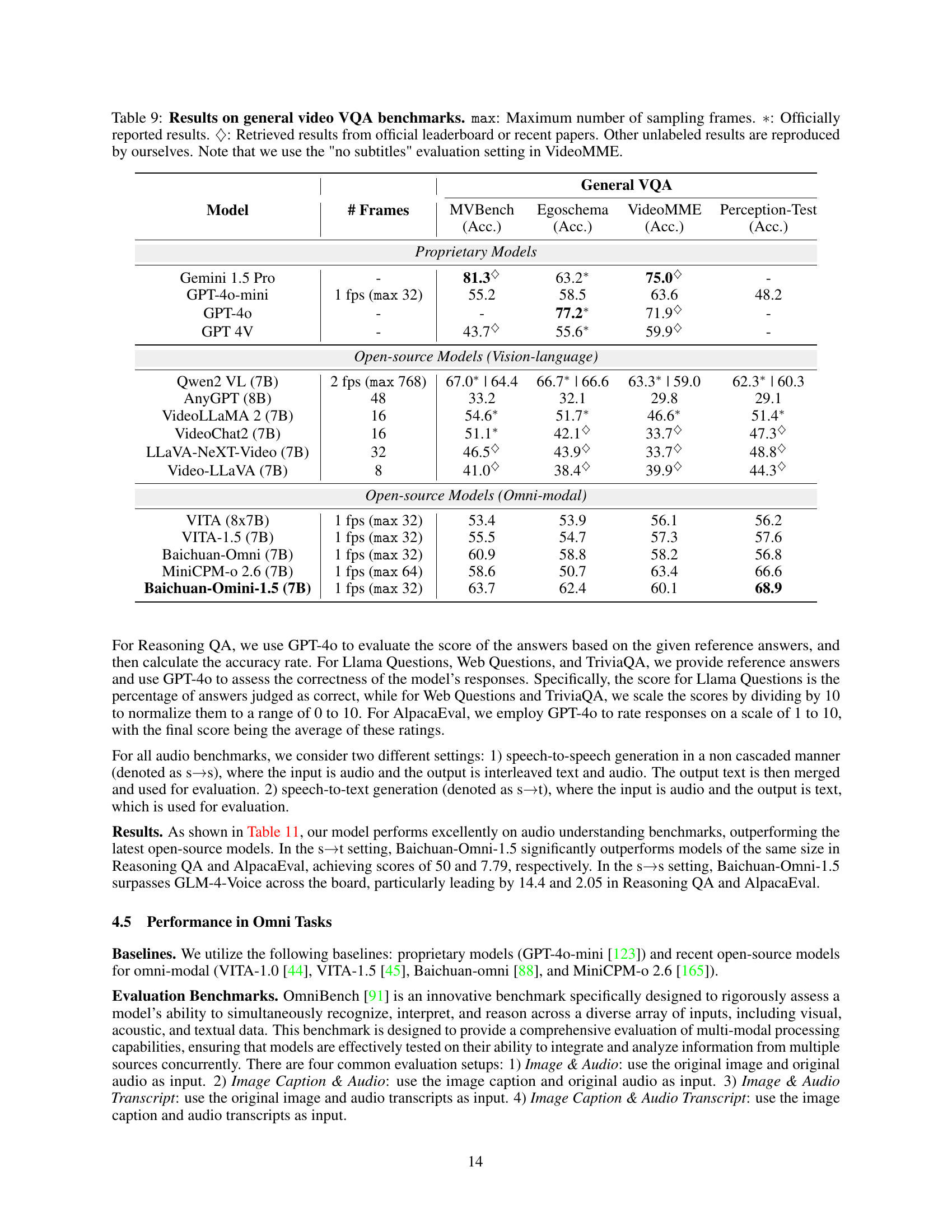
🔼 Table 9 presents the results of general video question answering (VQA) benchmarks. It compares various models’ performance across four metrics: MVBench, Egoschema, VideoMME, and Perception-Test. The table differentiates between proprietary models (those developed by companies and not publicly released), open-source vision-language models, and open-source omni-modal models. Results are shown as accuracy (%). The maximum number of frames sampled for evaluation is also specified. Note that a specific setting (’no subtitles’) was used for the VideoMME benchmark. Results marked with * represent officially reported scores from the original papers or leaderboards. Results with ♢ represent scores obtained from official leaderboards or recent papers. The remaining scores were reproduced by the authors of this paper using consistent evaluation settings for fair comparison.
read the caption
Table 9: Results on general video VQA benchmarks. max: Maximum number of sampling frames. ∗*∗: Officially reported results. ♢♢\diamondsuit♢: Retrieved results from official leaderboard or recent papers. Other unlabeled results are reproduced by ourselves. Note that we use the 'no subtitles' evaluation setting in VideoMME.
| C-Eval |
| (Acc.) |
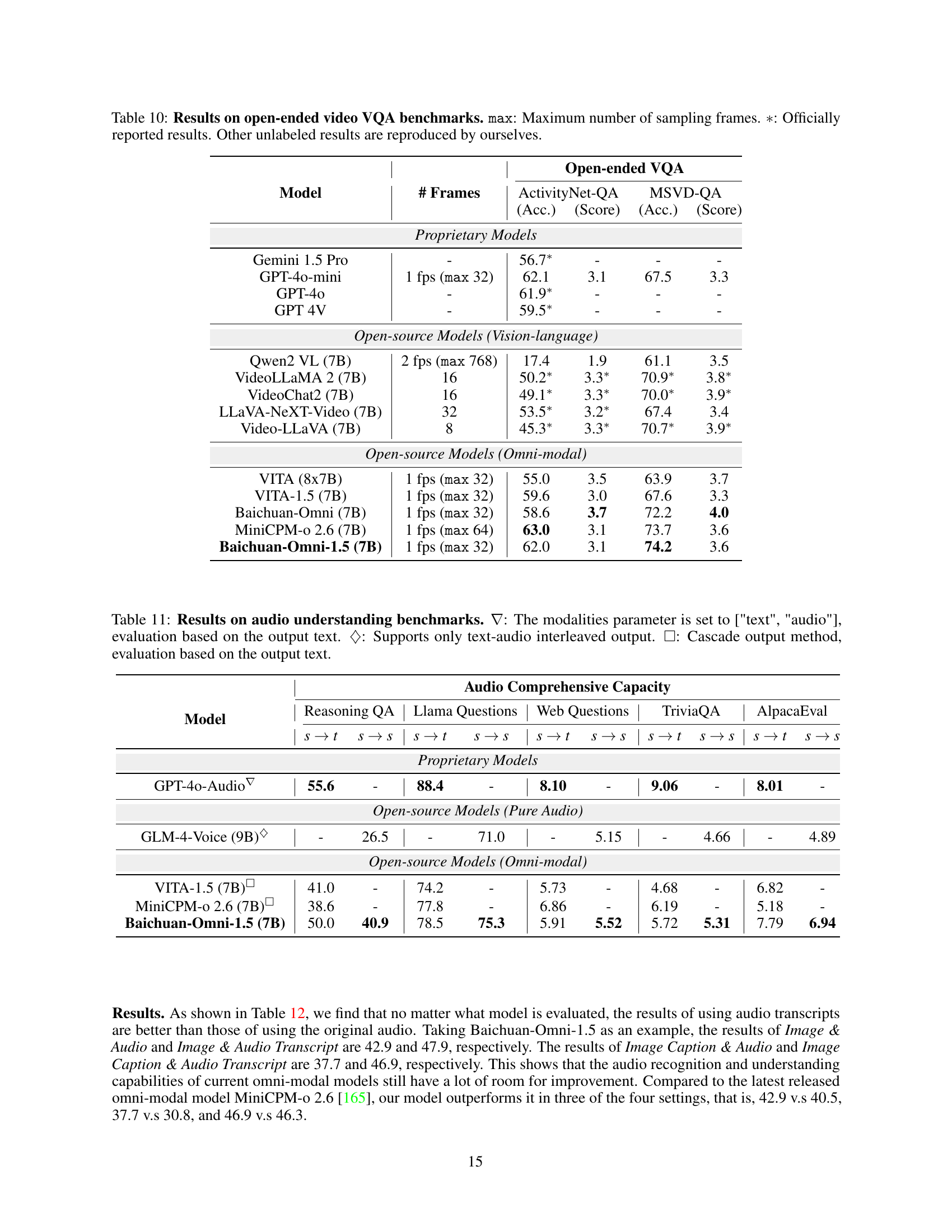
🔼 Table 10 presents the results of open-ended Video Question Answering (VQA) benchmark evaluations. It compares the performance of several models, including proprietary models (Gemini 1.5 Pro, GPT-4 mini, GPT-4, GPT-4V) and open-source models (Qwen2-VL, VideoLLaMA 2, VideoChat2, LLaVA-NeXT-Video, Video-LLaMA, VITA, VITA-1.5, Baichuan-Omni, MiniCPM-0 2.6, Baichuan-Omni-1.5). The models are evaluated on two benchmarks: ActivityNet-QA and MSVD-QA. The table shows the accuracy (Acc.) and score achieved by each model on both benchmarks. The number of frames sampled from each video is also indicated, with some models using a maximum number of frames and others a fixed frames per second.
read the caption
Table 10: Results on open-ended video VQA benchmarks. max: Maximum number of sampling frames. ∗*∗: Officially reported results. Other unlabeled results are reproduced by ourselves.
| GAOKAO |
| (Acc.) |
🔼 Table 11 presents the results of evaluating various models on several audio understanding benchmarks. The benchmarks assess different aspects of audio comprehension, including reasoning, question answering, and general knowledge. The table compares the performance of proprietary models (GPT-40-Audio) and open-source models (GLM-4-Voice, VITA-1.5, MiniCPM-0 2.6, Baichuan-Omni-1.5) across these benchmarks. Different evaluation methods are employed, as denoted by symbols in the caption: ∇∇\nabla∇ indicates text-only evaluation on text-audio interleaved outputs; ♢♢\diamondsuit♢ specifies text-audio interleaved output only; and □□\square□ denotes a cascaded output approach, with evaluation based on the produced text. This allows for a multifaceted comparison of the models’ abilities in various audio understanding tasks.
read the caption
Table 11: Results on audio understanding benchmarks. ∇∇\nabla∇: The modalities parameter is set to ['text', 'audio'], evaluation based on the output text. ♢♢\diamondsuit♢: Supports only text-audio interleaved output. □□\square□: Cascade output method, evaluation based on the output text.
| Multi-choice & Yes-or-No Question | |||||||||||||||
| Model |
|
|
|
|
| ||||||||||
| Proprietary Models | |||||||||||||||
| GPT-4o | 83.4♢ | 82.1♢ | - | 69.1♢ | 55.0♢ | ||||||||||
| GPT-4o-mini | 77.7 | 76.9 | 72.3 | 59.3 | 45.8 | ||||||||||
| Open-source Models (Vision-language) | |||||||||||||||
| Qwen2 VL (7B) | 81.7 | 81.9 | 76.5 | 52.7 | 50.6∗ | ||||||||||
| MiniCPM-Llama3-V 2.5 (8B) | 76.7 | 73.3 | 72.4 | 45.8∗ | 42.5 | ||||||||||
| Open-source Models (Omni-modal) | |||||||||||||||
| VITA (8x7B) | 74.7 | 71.4 | 72.6 | 45.3 | 39.7∗ | ||||||||||
| VITA-1.5 (7B) | 80.8 | 80.2 | 74.2 | 50.8 | 44.8 | ||||||||||
| Baichuan-Omni (7B) | 76.2 | 74.9 | 74.1 | 47.3 | 47.8 | ||||||||||
| MiniCPM-o 2.6 (7B) | 83.6 | 81.8 | 75.4 | 51.1 | 50.1 | ||||||||||
| Baichuan-Omni-1.5 (7B) | 85.6 | 83.6 | 75.7 | 53.9 | 49.7 | ||||||||||
🔼 Table 12 presents a comprehensive comparison of the overall omni-understanding capabilities of several large language models (LLMs), including both proprietary models (GPT-40-mini) and open-source omni-modal models. The models are evaluated across four distinct scenarios, each involving a unique combination of input modalities: Image & Audio, Image Caption & Audio, Image & Audio Transcript, and Image Caption & Audio Transcript. The table highlights the accuracy scores achieved by each model in each scenario, offering a nuanced assessment of their cross-modal understanding performance. Note that for the GPT-40-mini model, audio input was not directly supported; therefore, audio data was transcribed before input for fair comparison.
read the caption
Table 12: Overall Omni-Undesratnding Results. All the results are reproduced by ourselves. GPT-4o-mini does not support audio input, we use its audio API and transcribe the audio and then input it.
| MMBench-EN |
| (Acc.) |
🔼 Table 13 presents the performance comparison of various models on medical image understanding benchmarks. The benchmarks used are GMAI-MMB-VAL and OpenMM-Medical. The results shown represent accuracy scores achieved by each model on each benchmark. All results were reproduced by the authors of the paper for fair comparison. This table is crucial for assessing the models’ capabilities to handle medical image data, a particularly challenging domain requiring high accuracy and reliability.
read the caption
Table 13: Results on medical benchmarks. All the results are reproduced by ourselves.
Full paper#