TL;DR#
Current speech generation models struggle to capture the spontaneity and variability of real-world human speech due to reliance on limited, formal datasets. This reliance hinders progress in creating truly natural-sounding AI voices. Addressing this challenge requires more diverse and extensive training data.
This paper introduces Emilia-Pipe, an open-source preprocessing pipeline designed to extract high-quality speech data from vast amounts of in-the-wild audio. Using this pipeline, the researchers created Emilia and Emilia-Large, two multilingual speech datasets encompassing over 216,000 hours of speech across six languages. The results show that these datasets significantly improve the quality and naturalness of AI-generated speech compared to models trained on traditional datasets. This work offers a valuable resource to researchers looking to improve speech synthesis capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of current speech generation models by creating a massive, multilingual dataset (Emilia and Emilia-Large) with diverse and spontaneous speech. This resource will significantly advance research, enabling the development of more natural and human-like speech synthesis. It also opens avenues for investigating data scaling laws and cross-lingual speech generation techniques.
Visual Insights#

🔼 The Emilia-Pipe pipeline processes raw in-the-wild speech data to create a high-quality dataset for training speech generation models. It begins with standardization of the input audio to a consistent format. Next, source separation isolates human speech from background noise and music. Speaker diarization then separates speech from multiple speakers. Fine-grained segmentation using voice activity detection (VAD) further divides the audio into shorter, manageable segments. Automated speech recognition (ASR) transcribes the speech segments into text. Finally, a filtering step removes low-quality segments based on criteria such as language, DNSMOS score (objective speech quality score), and average character duration.
read the caption
Figure 1: An overview of the Emilia-Pipe processing pipeline. It consists of six steps, namely, standardization, source separation, speaker diarization, fine-grained segmentation by voice activity detection (VAD), automated speech recognition (ASR), and filtering.
| Dataset | Data Source | Total Duration (hours) | Language | Samp. Rate (Hz) | Dynamic | |
| LJSpeech [17] | Audiobook | 24 | En | 22.05k | ||
| AutoPrepWild [12] | In-the-wild | 39 | Zh | 24k/44.1k | ✓(Proprietary) | |
| VCTK [18] | Studio Recording | 44 | En | 48k | ||
| AISHELL-3 [19] | Studio Recording | 85 | Zh | 44.1k | ||
| LibriTTS [20] | Audiobook | 585 | En | 24k | ||
| GigaSpeech [21] | In-the-wild | 10k | En | 16k | ||
| WenetSpeech4TTS [13] | In-the-wild | 12k | Zh | 16k | ✓(Proprietary) | |
| Libri-Heavy [22] | Audiobook | 50k | En | 16k | ||
| MLS [11] | Audiobook | 51k | En/Fr/De/Nl/Es/It/Pt/Pl | 16k | ||
| Libri-Light [10] | Audiobook | 60k | En | 16k | ||
| Emilia | In-the-wild | 101k | En/Zh/De/Fr/Ja/Ko | 24k | ✓ | |
| Emilia-Large | In-the-wild | 216k | En/Zh/De/Fr/Ja/Ko | 24k | ✓ |
🔼 This table compares the Emilia and Emilia-Large speech generation datasets with other existing datasets. It shows key characteristics such as the data source (e.g., audiobooks, in-the-wild recordings), total duration in hours, the number of languages included, sample rate, and whether the dataset creation involved a proprietary dynamic pipeline. This allows for a quantitative comparison of dataset size, scope, and characteristics, highlighting the relative strengths and limitations of each.
read the caption
TABLE I: A comparison of Emilia and Emilia-Large datasets with existing datasets for speech generation.
In-depth insights#
Emilia-Pipe Pipeline#
The Emilia-Pipe pipeline is a crucial contribution of the research, addressing the critical need for an efficient and open-source method to process large-scale, multilingual in-the-wild speech data. Its six core steps—standardization, source separation, speaker diarization, fine-grained segmentation (VAD), ASR, and filtering—demonstrate a comprehensive approach to data cleaning and preparation. The pipeline’s multilingual capabilities are particularly noteworthy, overcoming limitations of previous, monolingual pipelines. Its open-source nature fosters wider accessibility and collaborative improvements, which is essential for advancing the field. Furthermore, optimization for efficiency is highlighted, emphasizing the scalability and practicality of the pipeline for processing vast datasets, ultimately enabling the creation of Emilia and Emilia-Large. The pipeline’s impact extends beyond the datasets’ creation; its open availability and effectiveness potentially accelerate progress in speech generation research globally.
Dataset Construction#
The creation of the Emilia speech dataset is a multi-stage process, beginning with the development of Emilia-Pipe, a novel and open-source preprocessing pipeline. Emilia-Pipe is crucial, as it addresses the challenges of using raw, in-the-wild data by incorporating standardization, source separation, speaker diarization, voice activity detection, automated speech recognition (ASR), and filtering steps. This pipeline is designed for efficiency and scalability, enabling the creation of a significantly large dataset. The dataset is extensive, multilingual (English, Chinese, German, French, Japanese, Korean), and importantly, diverse, containing spontaneous speech reflecting real-world variability. The incorporation of spontaneous speech differentiates Emilia from previous datasets largely based on formal, read-aloud audio-books. The expansion to Emilia-Large, exceeding 216k hours of speech, showcases the scalability of Emilia-Pipe and further enhances the dataset’s value for research. The careful design and rigorous processing steps ensure high-quality data suitable for training sophisticated speech generation models.
Data Scaling Laws#
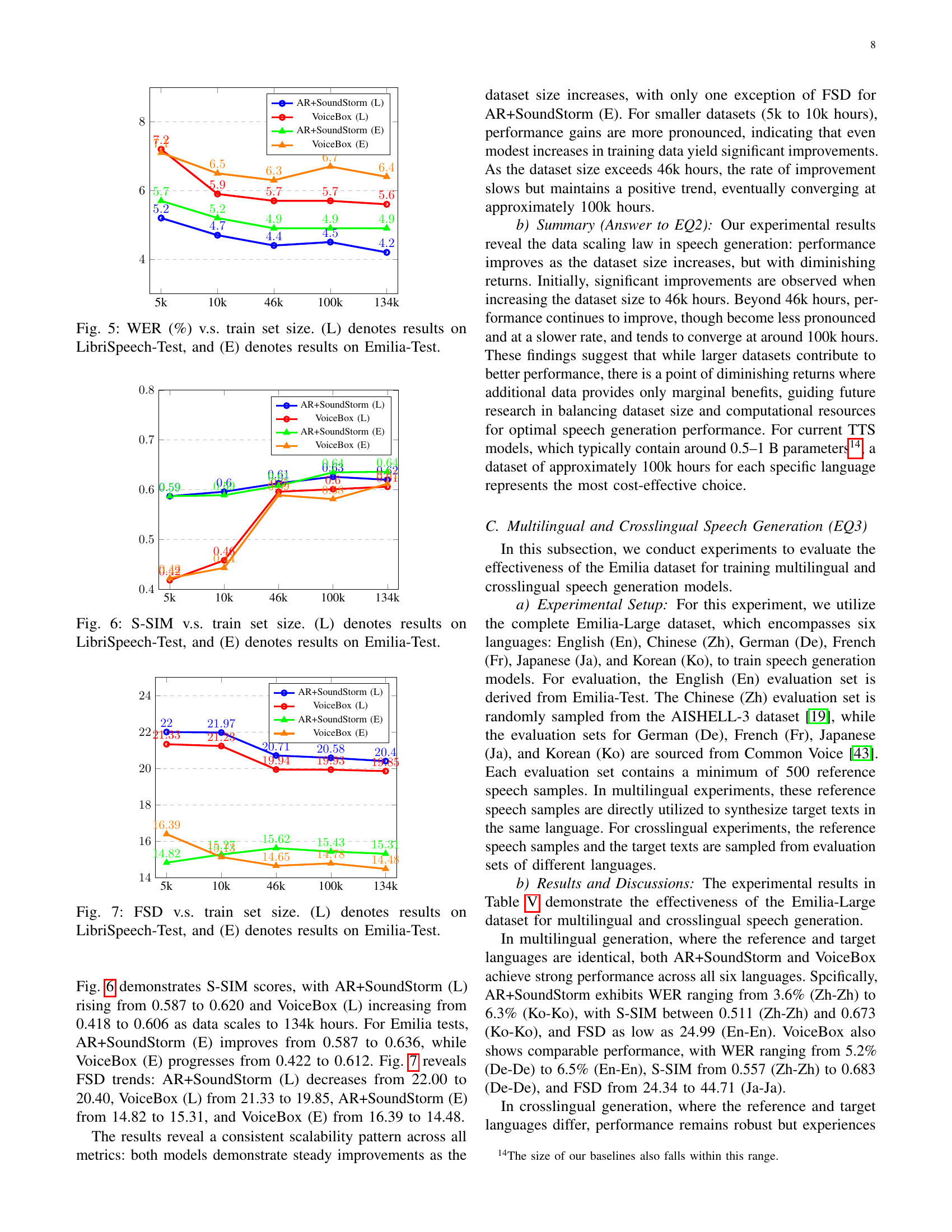
The concept of “Data Scaling Laws” in the context of speech generation research explores the relationship between the size of a training dataset and the performance of the resulting model. Larger datasets generally lead to improved model performance, but this improvement follows a pattern of diminishing returns. Initial gains are significant with moderate dataset size increases, showcasing substantial performance enhancements. However, as the dataset size grows substantially, the performance improvements become less pronounced, eventually reaching a point of convergence where further data expansion yields minimal added benefit. This observation highlights the importance of finding an optimal balance between dataset size and computational resources. Excessively large datasets, while potentially beneficial, can incur significant computational costs and might not justify the marginal gains in model performance. Therefore, understanding these scaling laws is crucial for researchers to make informed decisions about dataset size, resource allocation, and the overall efficiency of speech generation research.
Multilingual Analysis#
A multilingual analysis of a speech generation dataset would involve a multifaceted investigation. It would necessitate comparing the performance of speech generation models across multiple languages, examining how well models trained on one language generalize to others. Furthermore, this would involve a detailed analysis of the dataset itself; checking for potential biases or imbalances in representation across different languages. This would include evaluating the quantity, quality, diversity of accents and dialects, as well as the overall linguistic features of the data within each language. A key consideration would be determining whether models trained on a resource-rich language adequately translate their performance to low-resource languages. The analysis would also need to address whether the model’s ability to accurately capture nuances such as pronunciation, intonation, and rhythm is consistent across all languages. Ultimately, a robust multilingual analysis is crucial to assess the fairness, inclusivity, and generalizability of speech generation models, especially when considering application in diverse global communities.
Future Directions#
Future research should prioritize expanding the Emilia dataset to encompass a wider range of languages and demographics, enhancing its diversity and global applicability. Addressing the limitations of the current speaker diarization and separation techniques is crucial to improve the quality of the processed data. Investigating the effect of different audio durations on speech generation performance is important, potentially optimizing the pipeline for longer or shorter segments. Furthermore, exploring advanced strategies to mitigate the performance gap in cross-lingual speech generation is necessary. Finally, researching robust methods to detect and filter out synthetic or manipulated speech within in-the-wild datasets is vital for the trustworthiness and reliability of future speech generation models. This combined approach would lead to more robust and versatile speech generation models, overcoming the current limitations and propelling the field forward.
More visual insights#
More on figures

🔼 This figure shows a pie chart visualizing the distribution of languages in the Emilia dataset. Each slice of the pie represents a different language (English, Chinese, German, French, Japanese, Korean), with its size proportional to the amount of speech data available for that language. It provides a clear visual representation of the multilingual nature of the dataset and the relative proportion of each language.
read the caption
(a) Emilia

🔼 The pie chart visualizes the distribution of speech data across six languages within the Emilia-Large dataset. It shows the relative proportion of each language (English, Chinese, German, French, Japanese, Korean) in the dataset, highlighting the relative abundance of each language. The sizes of the slices directly correspond to the amount of data available for each language. This allows for a quick visual comparison of the dataset’s multilingual balance.
read the caption
(b) Emilia-Large
More on tables
| Dataset | Duration (s) | DNSMOS | Total Duration (hours) | ||||
| min | max | avg ± std | min | max | avg ± std | ||
| Raw | 9.22 | 18,056.98 | 1,572.53 ± 1,966.66 | 1.08 | 3.51 | 2.50 ± 0.62 | 598.87 (100.00%) |
| Processed w/o Filtering | 1.00 | 30.00 | 7.18 ± 5.06 | 0.91 | 3.67 | 2.86 ± 0.51 | 340.54 (56.86%) |
| Processed | 3.00 | 30.00 | 8.98 ± 4.99 | 3.00 | 3.67 | 3.26 ± 0.14 | 176.22 (29.43%) |
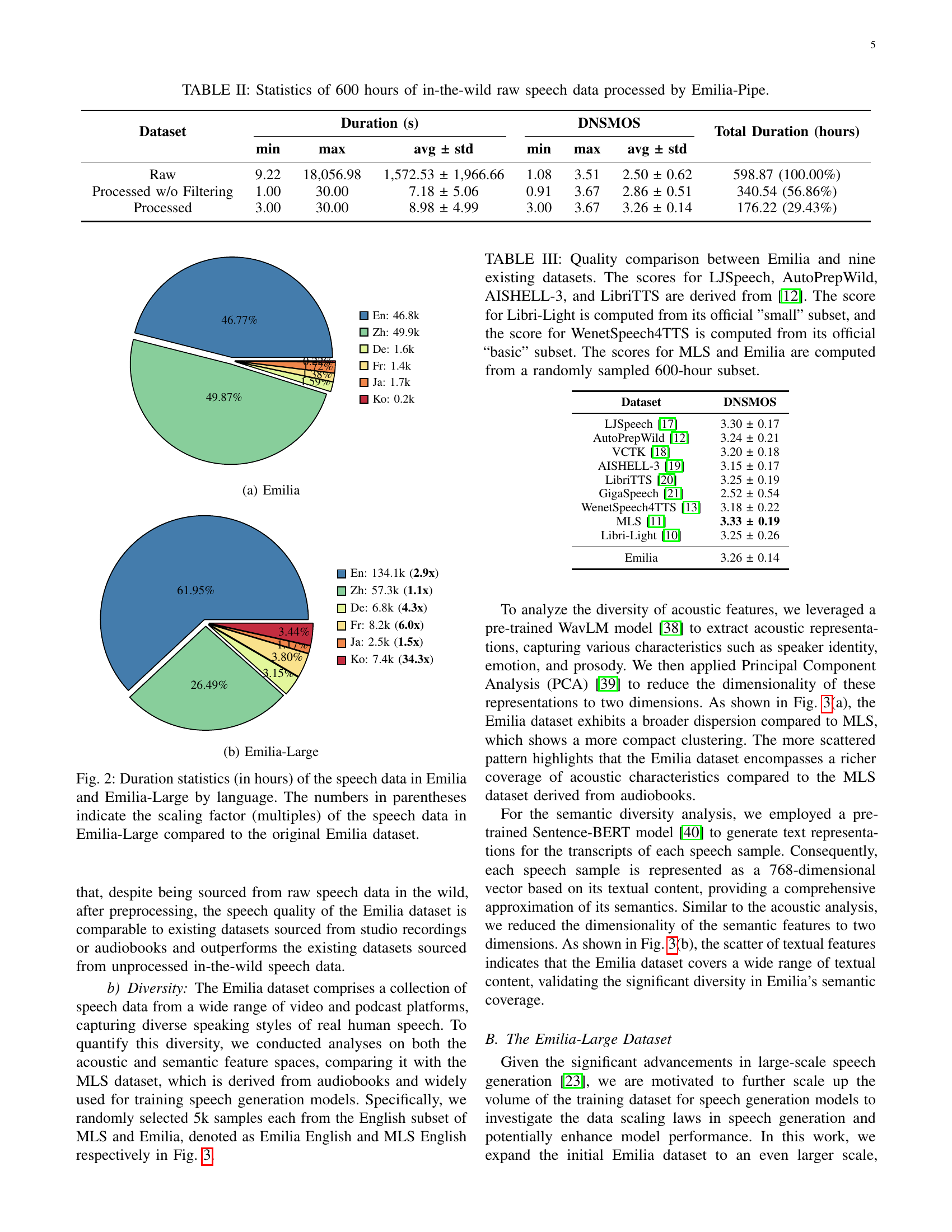
🔼 This table presents a statistical analysis of 600 hours of raw, in-the-wild speech data before and after processing with the Emilia-Pipe. It shows the minimum, maximum, and average duration of speech segments (in seconds), along with their standard deviations. Furthermore, it details the distribution of DNSMOS (Deep Neural Network-based objective speech quality metric) scores, indicating the perceived quality of the speech segments before and after processing. Finally, it provides the total duration of speech data retained after each stage of processing. This data quantifies the effect of Emilia-Pipe in enhancing the quality and usability of raw, in-the-wild speech data.
read the caption
TABLE II: Statistics of 600 hours of in-the-wild raw speech data processed by Emilia-Pipe.
| Dataset | DNSMOS |
| LJSpeech [17] | 3.30 ± 0.17 |
| AutoPrepWild [12] | 3.24 ± 0.21 |
| VCTK [18] | 3.20 ± 0.18 |
| AISHELL-3 [19] | 3.15 ± 0.17 |
| LibriTTS [20] | 3.25 ± 0.19 |
| GigaSpeech [21] | 2.52 ± 0.54 |
| WenetSpeech4TTS [13] | 3.18 ± 0.22 |
| MLS [11] | 3.33 ± 0.19 |
| Libri-Light [10] | 3.25 ± 0.26 |
| Emilia | 3.26 ± 0.14 |
🔼 Table III presents a comparison of the speech quality, as measured by the DNSMOS score, across ten speech datasets. It highlights the relative quality of Emilia compared to other datasets, including both audiobook-based datasets (like LibriTTS and Libri-Light) and those derived from in-the-wild recordings (like AutoPrepWild). Note that for certain datasets (Libri-Light and WenetSpeech4TTS), scores are from specific subsets, and for Emilia and MLS, scores are based on a randomly chosen 600-hour subset to ensure a fair comparison. This allows for a clear understanding of Emilia’s quality relative to existing options, showing how its quality compares to both audiobook and in-the-wild datasets.
read the caption
TABLE III: Quality comparison between Emilia and nine existing datasets. The scores for LJSpeech, AutoPrepWild, AISHELL-3, and LibriTTS are derived from [12]. The score for Libri-Light is computed from its official ”small” subset, and the score for WenetSpeech4TTS is computed from its official “basic” subset. The scores for MLS and Emilia are computed from a randomly sampled 600-hour subset.
| Model | Training Set | LibriSpeech-Test | Emilia-Test | ||||||||
| WER | S-SIM | FSD | CMOS | SMOS | WER | S-SIM | FSD | CMOS | SMOS | ||
| AR+SoundStorm | MLS | 8.9% | 0.612 | 49.11 | -0.36 | 3.13 | 7.7% | 0.587 | 20.76 | 0.09 | 3.71 |
| Emilia-En | 8.4% | 0.577 | 24.73 | -0.19 | 3.28 | 6.6% | 0.618 | 12.73 | 0.19 | 3.73 | |
| VoiceBox | MLS | 6.1% | 0.625 | 16.83 | 0.36 | 3.62 | 8.2% | 0.528 | 15.94 | 0.28 | 3.61 |
| Emilia-En | 7.2% | 0.585 | 23.24 | 0.42 | 3.77 | 7.4% | 0.601 | 14.07 | 0.28 | 3.76 | |
🔼 Table IV presents a detailed comparison of the performance of two state-of-the-art text-to-speech (TTS) models, AR+SoundStorm and VoiceBox, trained on two different datasets: Emilia-En (English subset of the Emilia dataset) and MLS (an audiobook dataset). The models’ performance is evaluated using both objective and subjective metrics on two distinct test sets: LibriSpeech-Test, containing formal read-aloud speech, and Emilia-Test, featuring more spontaneous, human-like speech. Objective metrics include Word Error Rate (WER), Speaker Similarity Score (S-SIM), and Fréchet Speech Distance (FSD). Subjective metrics comprise Speaker Mean Opinion Score (SMOS) and Comparative Mean Opinion Score (CMOS). The table highlights the best-performing model for each metric in bold, allowing for a direct comparison of the models’ abilities to generate high-quality speech in both formal and spontaneous contexts.
read the caption
TABLE IV: Objective and subjective evaluation results of TTS models trained with Emilia-En and MLS on LibriSpeech-Test and Emilia-Test evaluation sets. The best results for each model are highlighted in bold.
| Metric | AR+SoundStorm | VoiceBox | |||||||||||
| En | Zh | Fr | De | Ja | Ko | En | Zh | Fr | De | Ja | Ko | ||
| WER | 5.9% | 5.8% | 6.4% | 5.9% | 6.3% | 8.3% | 6.5% | 7.9% | 8.8% | 8.6% | 8.3% | 10.2% | |
| En | S-SIM | 0.568 | 0.431 | 0.452 | 0.529 | 0.446 | 0.443 | 0.588 | 0.386 | 0.458 | 0.490 | 0.425 | 0.442 |
| FSD | 24.99 | 99.40 | 82.84 | 26.62 | 89.40 | 98.36 | 24.34 | 91.29 | 78.53 | 68.62 | 92.54 | 89.49 | |
| WER | 5.3% | 3.6% | 5.2% | 5.4% | 4.9% | 5.7% | 8.6% | 5.6% | 6.7% | 5.9% | 6.4% | 7.0% | |
| Zh | S-SIM | 0.507 | 0.511 | 0.509 | 0.504 | 0.516 | 0.523 | 0.524 | 0.557 | 0.524 | 0.522 | 0.543 | 0.591 |
| FSD | 56.15 | 40.09 | 56.75 | 57.10 | 56.71 | 52.60 | 109.67 | 40.04 | 58.47 | 72.47 | 64.73 | 57.90 | |
| WER | 5.3% | 5.3% | 5.3% | 5.2% | 5.8% | 8.1% | 7.0% | 6.3% | 5.6% | 6.9% | 7.5% | 9.3% | |
| Fr | S-SIM | 0.596 | 0.527 | 0.596 | 0.596 | 0.572 | 0.557 | 0.565 | 0.485 | 0.589 | 0.582 | 0.547 | 0.556 |
| FSD | 39.89 | 66.21 | 39.88 | 38.48 | 51.13 | 54.41 | 91.08 | 80.76 | 42.38 | 58.16 | 63.36 | 61.51 | |
| WER | 4.5% | 4.5% | 4.7% | 4.2% | 4.8% | 6.8% | 5.2% | 7.4% | 6.8% | 5.2% | 6.9% | 8.9% | |
| De | S-SIM | 0.619 | 0.545 | 0.603 | 0.639 | 0.596 | 0.591 | 0.639 | 0.519 | 0.577 | 0.683 | 0.538 | 0.586 |
| FSD | 39.96 | 57.82 | 44.86 | 33.16 | 53.38 | 55.12 | 83.37 | 72.18 | 54.77 | 34.41 | 67.89 | 67.46 | |
| WER | 4.6% | 4.4% | 4.7% | 4.5% | 4.8% | 6.6% | 7.4% | 5.5% | 6.9% | 6.7% | 6.2% | 6.6% | |
| Ja | S-SIM | 0.622 | 0.557 | 0.626 | 0.618 | 0.641 | 0.633 | 0.556 | 0.525 | 0.521 | 0.557 | 0.584 | 0.596 |
| FSD | 49.42 | 68.70 | 44.67 | 50.47 | 44.28 | 52.19 | 103.68 | 76.65 | 63.55 | 72.41 | 44.71 | 56.34 | |
| WER | 6.2% | 4.1% | 6.1% | 6.2% | 6.2% | 6.3% | 8.0% | 5.6% | 7.8% | 8.3% | 5.6% | 6.0% | |
| Ko | S-SIM | 0.657 | 0.593 | 0.665 | 0.656 | 0.673 | 0.673 | 0.589 | 0.567 | 0.545 | 0.597 | 0.595 | 0.648 |
| FSD | 36.71 | 58.85 | 32.27 | 37.20 | 31.95 | 30.27 | 86.57 | 63.49 | 53.75 | 57.19 | 52.85 | 38.82 | |
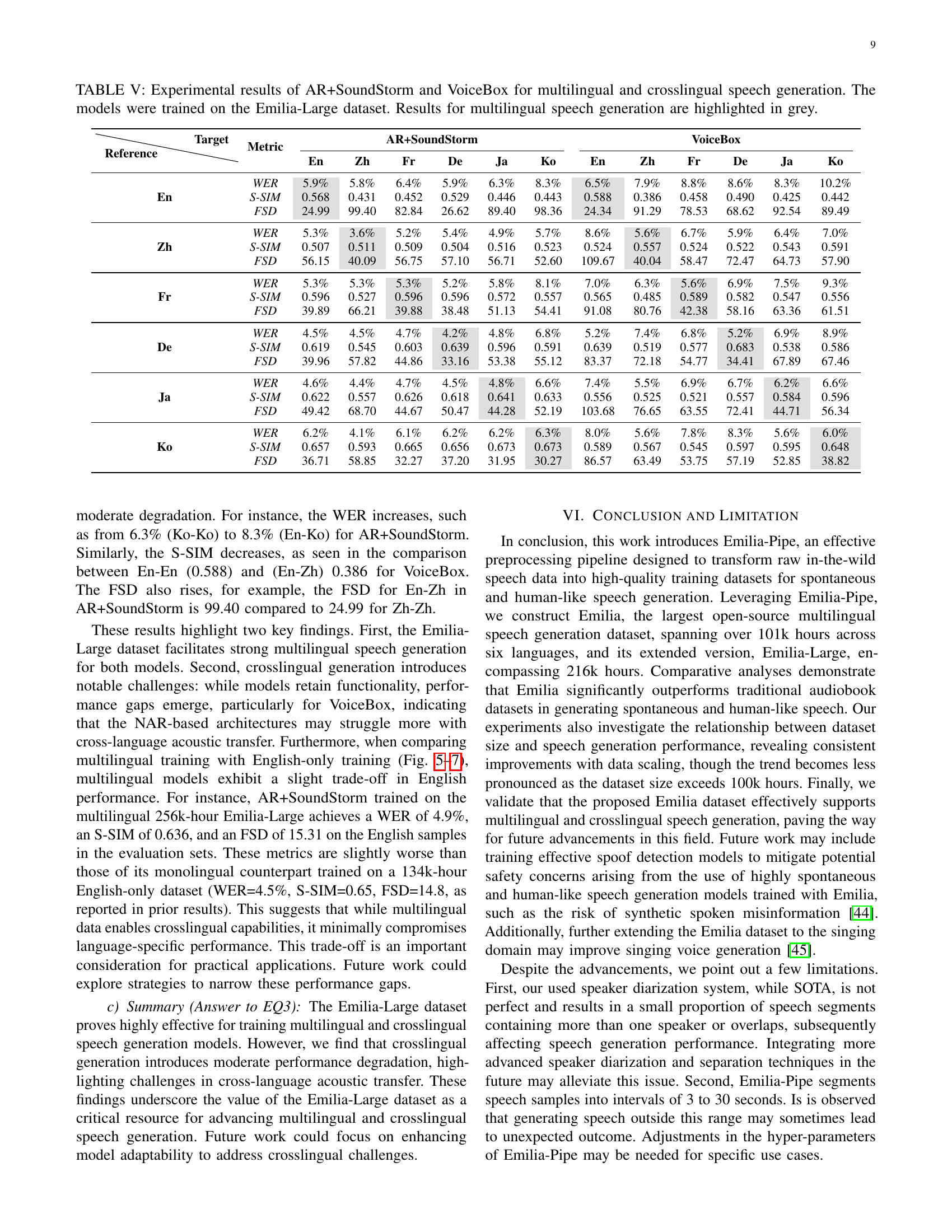
🔼 Table V presents the multilingual and cross-lingual speech generation performance of two state-of-the-art models, AR+SoundStorm and VoiceBox, trained using the Emilia-Large dataset. The table displays metrics such as Word Error Rate (WER), Speaker Similarity (S-SIM), and Fréchet Speech Distance (FSD) for six different languages (English, Chinese, German, French, Japanese, Korean). Results are shown for both multilingual scenarios (same source and target language) and cross-lingual scenarios (different source and target languages). Multilingual results are highlighted in gray for easy identification.
read the caption
TABLE V: Experimental results of AR+SoundStorm and VoiceBox for multilingual and crosslingual speech generation. The models were trained on the Emilia-Large dataset. Results for multilingual speech generation are highlighted in grey.
Full paper#