TL;DR#
The effectiveness of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) in improving the generalization of foundation models remains unclear. This paper investigates whether these methods enhance generalization or primarily lead to memorization of the training data. It focuses on text-based and visual environments and uses carefully designed tasks to separate memorization from the acquisition of transferable principles.
This research used two tasks: GeneralPoints, an arithmetic reasoning card game; and V-IRL, a real-world navigation environment. They compared the performance of models trained with SFT and RL on these tasks, evaluating both in-distribution and out-of-distribution generalization. The study finds that RL generally leads to better generalization, especially when outcome-based rewards are used, while SFT often memorizes the training data and struggles to generalize to unseen scenarios. Furthermore, the research reveals that RL training improves the model’s underlying visual recognition capabilities, and that SFT plays a supporting role in stabilizing RL training.
Key Takeaways#
Why does it matter?#
This paper is crucial because it directly addresses the critical question of generalization in foundation models, a major hurdle in AI development. The findings challenge existing assumptions about SFT and RL, suggesting a paradigm shift in how we approach model post-training. This opens exciting avenues for improving the robustness and generalizability of AI systems.
Visual Insights#

🔼 Figure 1 illustrates a comparative analysis of Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) methods applied to the V-IRL visual navigation task. The key focus is on out-of-distribution (OOD) generalization. The figure shows how the success rate of each method changes as computational resources used for training increase. Importantly, separate curves show the in-distribution performance (using the same textual action space during training and testing) and out-of-distribution performance (using a different action space during testing than during training). This comparison highlights the relative ability of RL and SFT to generalize learned knowledge to new, unseen scenarios.
read the caption
Figure 1: A comparative study of RL and SFT on the visual navigation environment V-IRL (Yang et al., 2024a) for OOD generalization. OOD curves represent performance on the same task, using a different textual action space. See detailed descriptions of the task in Section 5.1.
In-depth insights#
SFT vs RL Generalization#
The comparative study of supervised fine-tuning (SFT) and reinforcement learning (RL) in the context of foundation model post-training reveals crucial differences in generalization capabilities. SFT, while effective for aligning model outputs to a specific format, exhibits a tendency towards memorization of training data, struggling to generalize to unseen variations in rules or visual inputs. In contrast, RL demonstrates superior generalization, particularly when using outcome-based rewards. RL agents are able to learn transferable principles, enabling them to adapt to novel textual and visual tasks variants, exceeding SFT’s performance in both rule-based and visually-oriented challenges. This contrast highlights a fundamental trade-off: SFT prioritizes accuracy within the training distribution, while RL focuses on developing robust and generalizable skills. However, the study also finds that SFT plays a crucial role in stabilizing RL training, particularly by establishing a consistent output format that facilitates the RL learning process. Therefore, an optimal strategy might involve leveraging the strengths of both methods—SFT’s format-alignment capabilities followed by RL’s ability to develop generalized knowledge—in a synergistic approach.
GeneralPoints & V-IRL#
The study uses two novel tasks, GeneralPoints and V-IRL, to evaluate the generalization capabilities of models trained with supervised fine-tuning (SFT) and reinforcement learning (RL). GeneralPoints, a card game requiring arithmetic reasoning, tests rule-based generalization by presenting variations in both textual instructions and visual representations of cards. V-IRL, a visual navigation task, assesses generalization to unseen environments and visual variations. This dual-task approach provides a comprehensive evaluation across modalities and task types. The results highlight RL’s superior generalization, demonstrating its capacity to learn transferable principles, whereas SFT shows a tendency to memorize training data. This contrast is particularly pronounced in the visual domain, where RL significantly improves visual recognition capabilities which aids its generalization. Thus, the combined use of GeneralPoints and V-IRL offers a strong methodology for studying and comparing the generalization properties of SFT and RL in complex scenarios.
Visual Recognition Role#
The research explores the interplay between visual recognition capabilities and the effectiveness of reinforcement learning (RL) in foundation models. RL’s superior generalization performance is linked to improvements in visual recognition, suggesting that enhanced visual understanding facilitates better adaptability to unseen variations in visual data. This is a significant finding, as it highlights the potential for RL to not only improve task-specific performance, but also to strengthen the foundational visual processing abilities of the model. Conversely, supervised fine-tuning (SFT) struggles with generalization, often memorizing training data instead of learning transferable visual features. This difference in generalization can be attributed to the distinct learning paradigms: SFT focuses on optimizing for specific inputs/outputs, leading to overfitting, while RL promotes learning generalizable representations and strategies which prove crucial for robust visual recognition in novel situations. Further investigation into the specific mechanisms by which RL enhances visual recognition would be valuable. Understanding this relationship could lead to improvements in training strategies for visual learning and more robust foundation models in tasks demanding strong visual comprehension.
SFT’s Help for RL#
The research explores the synergistic relationship between supervised fine-tuning (SFT) and reinforcement learning (RL) in enhancing foundation models. The findings suggest that while RL excels at promoting generalization, enabling models to adapt to unseen variations in tasks and environments, SFT plays a crucial role in stabilizing the model’s output format. This stable format is essential for effective RL training, as it provides a well-defined structure for the RL algorithm to optimize upon. In essence, SFT acts as a crucial facilitator, setting the stage for RL’s performance gains. Without the stabilizing influence of SFT, the model’s output might be inconsistent and unpredictable, hindering the RL process. The paper therefore highlights the importance of considering SFT as a pre-processing step before applying RL, suggesting that a combined approach is more effective than using either technique alone for achieving optimal results in complex scenarios.
RL’s Future Directions#
Reinforcement learning (RL)’s future hinges on addressing its current limitations. Scaling RL to more complex tasks remains a challenge, particularly those involving high-dimensional state and action spaces, and long horizons. Improving sample efficiency is crucial; current RL methods often require vast amounts of data for training. Developing more robust and generalizable algorithms is necessary to handle variations in environments and tasks, avoiding overfitting and ensuring reliable performance. Combining RL with other machine learning techniques, such as supervised learning or imitation learning, can offer synergistic benefits. Addressing safety and interpretability concerns is vital for building trustworthy RL systems that can be deployed in real-world applications. Focus on specific domains, such as robotics or healthcare, can provide tailored solutions and facilitate faster progress. Exploration of new reward functions is essential; crafting appropriate reward designs remains a significant hurdle in RL’s successful application. Further development of theoretical foundations that provide better understanding and guarantees of algorithm performance will lead to more efficient and powerful RL methods. Finally, creating standardized benchmarks and datasets is essential for facilitating comparative studies and advancing the field as a whole.
More visual insights#
More on figures

🔼 Figure 2 illustrates the multi-turn reinforcement learning process with a verifier. The model doesn’t simply generate a single answer; instead, it iteratively refines its responses based on feedback from a verifier. At each step, the model receives the initial prompt (system prompt), all previous model outputs (answers), and the verifier’s feedback on those previous answers. This combined information forms the input for generating the next answer. The verifier evaluates the model’s output and provides a reward and additional textual information (e.g., indicating correctness or errors), which is then incorporated into the next round of the process. This iterative refinement allows the model to learn from its mistakes and improve its answer accuracy.
read the caption
Figure 2: An example of the sequential revision formulation with a verifier. The model generate the next answer 𝐯t+1outsubscriptsuperscript𝐯out𝑡1\mathbf{v}^{\text{out}}_{t+1}bold_v start_POSTSUPERSCRIPT out end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT conditioned on all previous answers and information (𝐯iout,𝐯tver,0≤i≤t)subscriptsuperscript𝐯out𝑖subscriptsuperscript𝐯ver𝑡0𝑖𝑡(\mathbf{v}^{\text{out}}_{i},\mathbf{v}^{\text{ver}}_{t},0\leq i\leq t)( bold_v start_POSTSUPERSCRIPT out end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , bold_v start_POSTSUPERSCRIPT ver end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , 0 ≤ italic_i ≤ italic_t ) from the verifier.

🔼 Figure 3 illustrates how the prompt is updated iteratively in a multi-turn reinforcement learning setting. The input prompt for each turn (vint+1) is constructed by concatenating the previous turn’s prompt, the model’s output from the previous turn (voutt), and the verifier’s output from the previous turn (vert). The figure highlights the different components of the prompt: the brown sections represent the task description and other task-related information that remains constant across turns, while the purple sections show the state-specific information (st) which changes at each turn. The blue section is the model’s output (voutt), and the red section is the verifier’s feedback (vert). This iterative prompt construction allows the model to refine its response based on previous interactions and feedback.
read the caption
Figure 3: An template of our prompt update for constructing 𝐯t+1insubscriptsuperscript𝐯in𝑡1\mathbf{v}^{\text{in}}_{t+1}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT. The brown parts marks the task and related information, and the purple parts denote the state (st)subscript𝑠𝑡(s_{t})( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) specific info. The blue and red describe the output from the model and verifier, respectively.

🔼 This figure illustrates a single navigation task within the V-IRL (Visual-IRL) environment. The top part visually depicts the agent’s journey through a series of locations. The agent moves from place to place based on textual instructions. The sequence of locations and actions, along with corresponding visual observations, shows a step-by-step progression of the navigation process. Key elements in the visual observations are color-coded: Green highlights visual information that guides the agent, while orange indicates the actions the agent takes.
read the caption
Figure 4: Demonstration of one navigation task in V-IRL. Agent navigates from place to place following the given linguistic navigation instructions in V-IRL. The navigation procedure is shown at the top, with the navigation instructions displayed below. Visual observation-related information is highlighted in green, while action-related information is marked in orange.

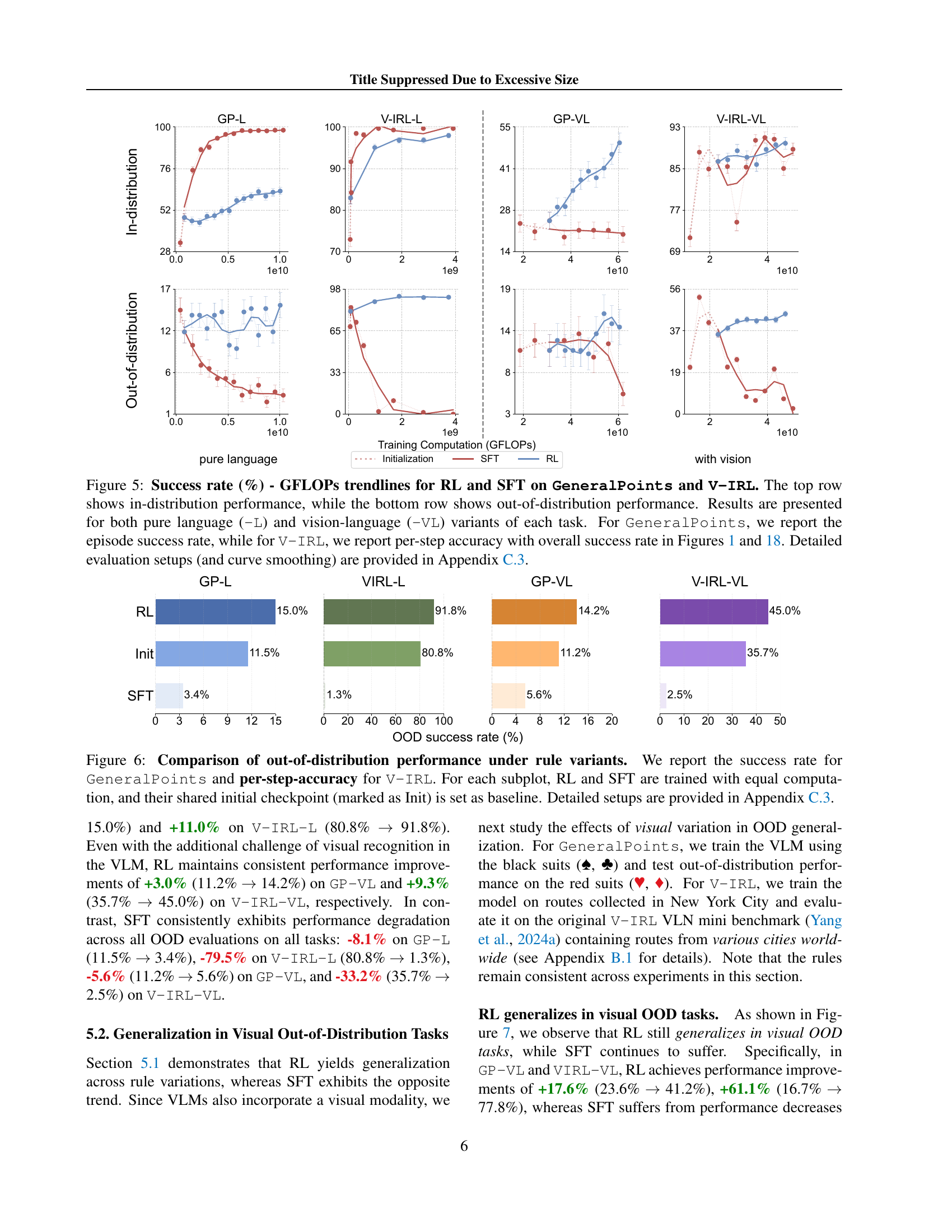
🔼 This figure displays a comparison of the performance of Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) on two tasks: GeneralPoints and V-IRL. The tasks are presented in two variants each: one using only language (’-L’) and the other using both language and vision (’-VL’). The top half of the figure shows the success rate (in-distribution) of each method on each task variant, plotted against the amount of computational resources (GFLOPs) used for training. The bottom half shows the same, but for out-of-distribution performance, testing the models’ ability to generalize to unseen data or rules. For GeneralPoints, the metric used is episode success rate, while for V-IRL, per-step accuracy is used with overall success rate referenced to other figures in the paper. The figure demonstrates the comparative generalization capabilities of RL versus SFT for both textual and visual tasks.
read the caption
Figure 5: Success rate (%) - GFLOPs trendlines for RL and SFT on GeneralPoints and V-IRL. The top row shows in-distribution performance, while the bottom row shows out-of-distribution performance. Results are presented for both pure language (-L) and vision-language (-VL) variants of each task. For GeneralPoints, we report the episode success rate, while for V-IRL, we report per-step accuracy with overall success rate in Figures 1 and 19. Detailed evaluation setups (and curve smoothing) are provided in Section C.3.

🔼 This figure compares the out-of-distribution (OOD) generalization performance of Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) on two tasks: GeneralPoints (a rule-based arithmetic reasoning task) and V-IRL (a visual navigation task). For each task, both RL and SFT are trained with the same computational budget. The figure shows the success rates (GeneralPoints) and per-step accuracy (V-IRL) for both in-distribution (ID) and OOD scenarios. The ‘Init’ point represents the performance of the model before any post-training. The results demonstrate the generalization capabilities of RL compared to SFT, which tends to memorize the training data.
read the caption
Figure 6: Comparison of out-of-distribution performance under rule variants. We report the success rate for GeneralPoints and per-step-accuracy for V-IRL. For each subplot, RL and SFT are trained with equal computation, and their shared initial checkpoint (marked as Init) is set as baseline. Detailed setups are provided in Section C.3.

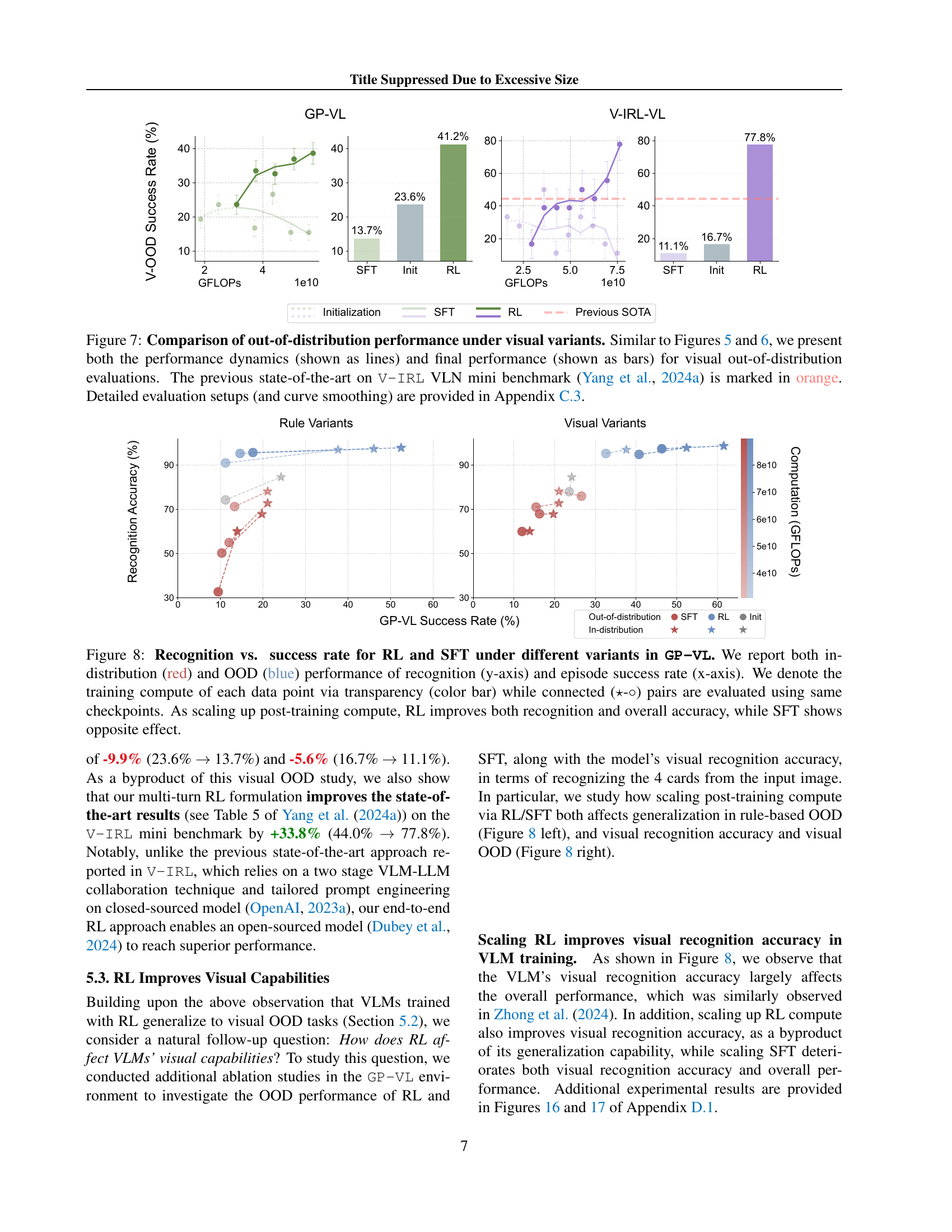
🔼 Figure 7 displays a comparison of the out-of-distribution performance of RL and SFT models when faced with visual variations in the V-IRL VLN task. The figure shows both the performance trends over training computation (as lines) and the final performance levels (as bars) for both in-distribution and out-of-distribution scenarios. This allows for a direct comparison of how well each method generalizes to unseen visual data. Notably, the previous state-of-the-art result from Yang et al. (2024a) is included as a reference point (in orange), highlighting RL’s superior performance. More details on the experimental setup and data smoothing techniques can be found in Section C.3 of the paper.
read the caption
Figure 7: Comparison of out-of-distribution performance under visual variants. Similar to Figures 5 and 6, we present both the performance dynamics (shown as lines) and final performance (shown as bars) for visual out-of-distribution evaluations. The previous state-of-the-art on V-IRL VLN mini benchmark (Yang et al., 2024a) is marked in orange. Detailed evaluation setups (and curve smoothing) are provided in Section C.3.

🔼 Figure 8 presents a comparative analysis of Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) methods on the GeneralPoints-VL task (a visual variant of an arithmetic reasoning card game). The figure uses two line graphs to showcase the relationship between visual recognition accuracy and episode success rate for both RL and SFT. The x-axis represents the episode success rate, and the y-axis represents the visual recognition accuracy. Different colors and transparency levels of the lines represent varying computational budgets used during training. Connected star and circle pairs indicate that these data points share the same checkpoint. The results demonstrate that as computational resources increase, RL improves both visual recognition accuracy and the overall task success rate, unlike SFT which shows the opposite trend.
read the caption
Figure 8: Recognition vs. success rate for RL and SFT under different variants in GP-VL. We report both in-distribution ( red) and OOD ( blue) performance of recognition (y-axis) and episode success rate (x-axis). We denote the training compute of each data point via transparency (color bar) while connected (⋆⋆\star⋆-∘\circ∘) pairs are evaluated using same checkpoints. As scaling up post-training compute, RL improves both recognition and overall accuracy, while SFT shows opposite effect.

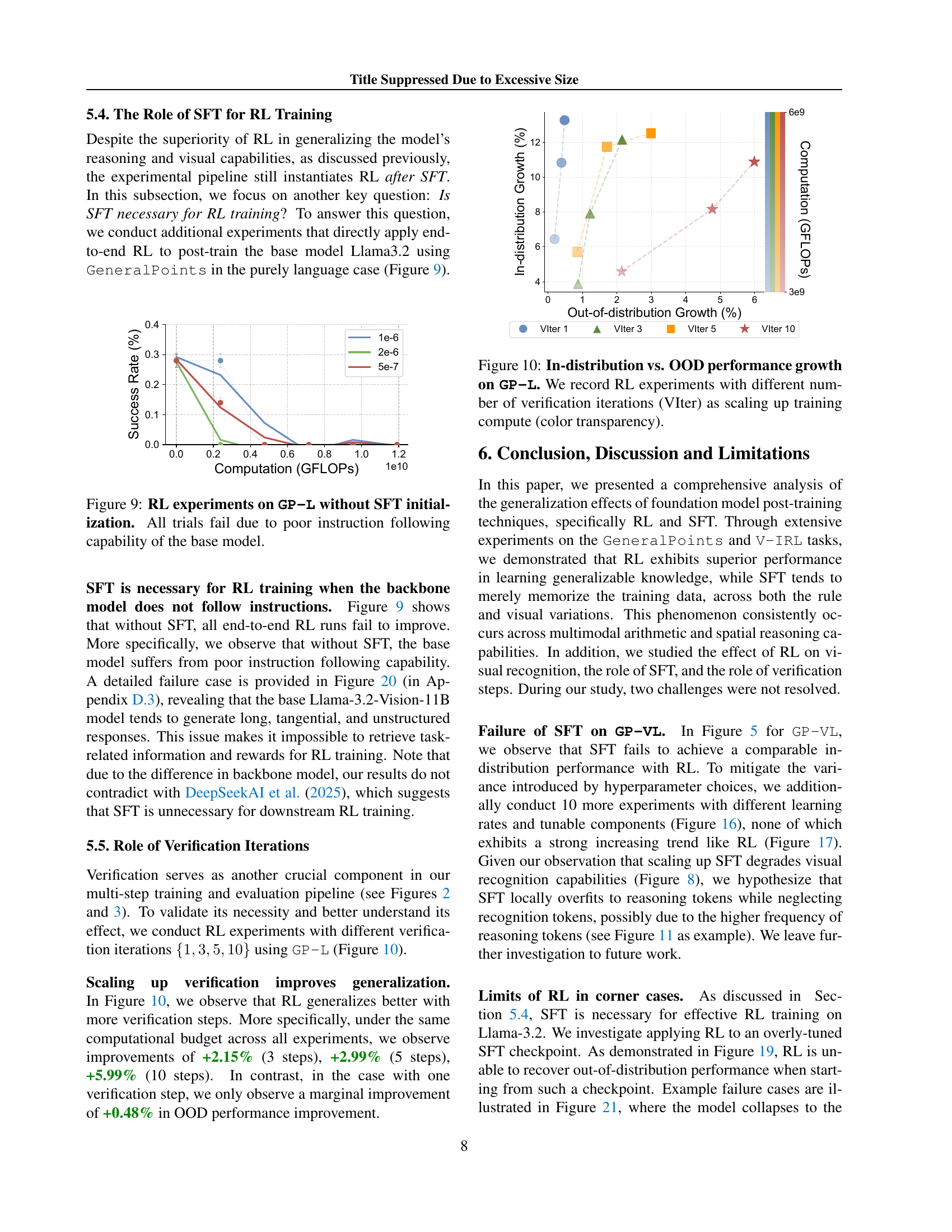
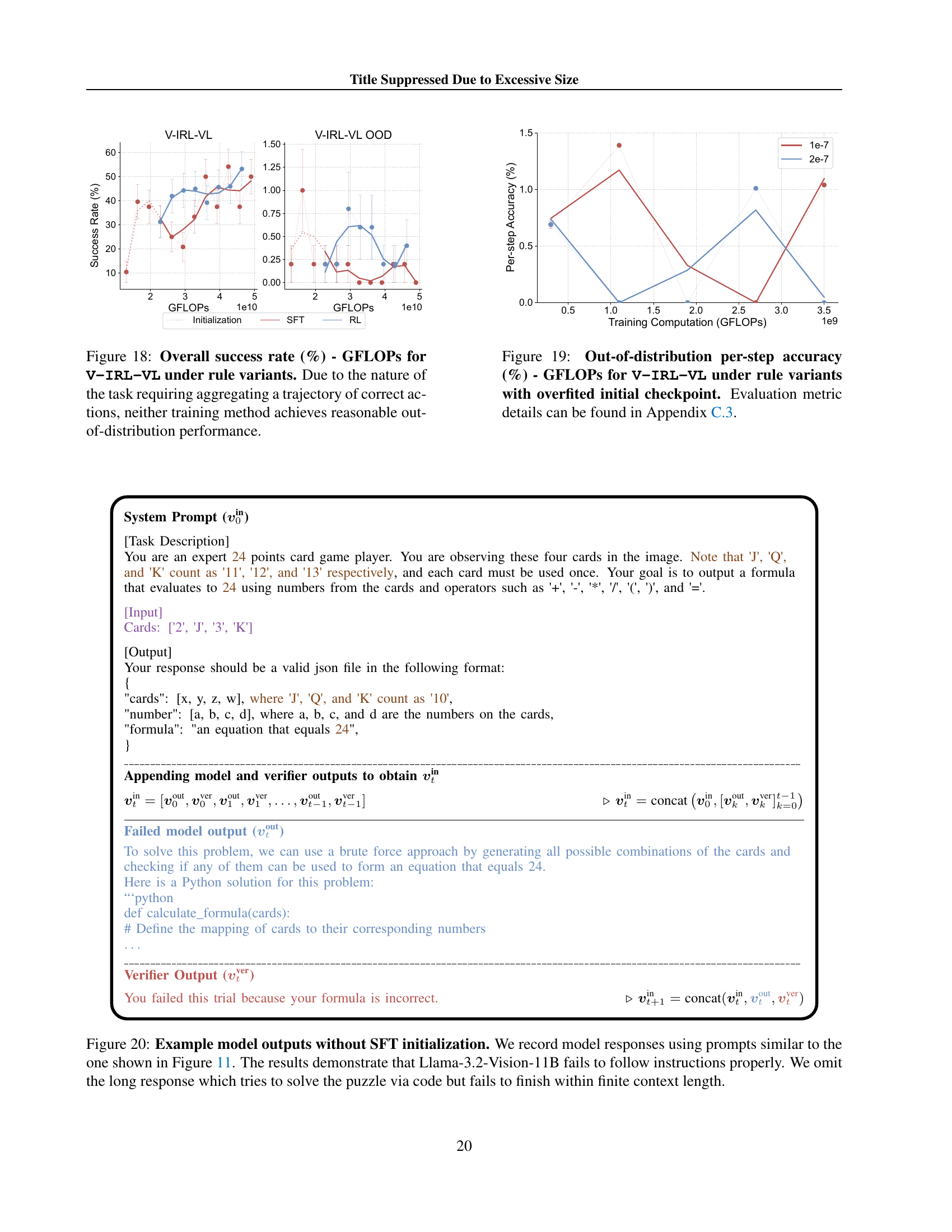
🔼 This figure displays the results of reinforcement learning (RL) experiments conducted on the General Points-Language (GP-L) task without any prior supervised fine-tuning (SFT). The experiment aimed to assess whether RL alone could effectively train the language model to solve arithmetic reasoning problems presented in a textual format. The results show that all RL training attempts failed. This failure is attributed to the base language model’s inherent deficiency in accurately following instructions, highlighting the critical role SFT plays in stabilizing the model’s behavior and enabling successful RL training.
read the caption
Figure 9: RL experiments on GP-L without SFT initialization. All trials fail due to poor instruction following capability of the base model.

🔼 This figure shows how the in-distribution and out-of-distribution performance of the General Points (GP-L) task changes with increasing computational resources used for training. The x-axis represents the training computation in GigaFLOPS (GFLOPS). The y-axis shows the percentage growth of both in-distribution (ID) and out-of-distribution (OOD) performance. Different lines represent different numbers of verification iterations used during training (VIter). The color transparency of the lines represents the amount of computational resources used. The results indicate that increasing computation generally improves both ID and OOD performance, especially when more verification iterations are used. This suggests that using more verification iterations during RL training leads to more generalizable models.
read the caption
Figure 10: In-distribution vs. OOD performance growth on GP-L. We record RL experiments with different number of verification iterations (VIter) as scaling up training compute (color transparency).

🔼 Figure 11 illustrates how the model’s input prompt is updated iteratively during the multi-turn reinforcement learning process. The initial prompt (vint) contains the task description. After each turn, the model’s output (voutt) and the verifier’s feedback (vvert) are appended to the prompt, creating the new input for the next turn (vint+1). The figure highlights the different components of the prompt: the task instructions (brown), the current state information (purple), the model’s response (blue), and the verifier’s response (red). The inclusion of an image in the prompt demonstrates how the model handles both textual and visual information, adding a visual recognition challenge for visual language models.
read the caption
Figure 11: An example of our prompt update for constructing 𝐯t+1insubscriptsuperscript𝐯in𝑡1\mathbf{v}^{\text{in}}_{t+1}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT using 𝐯tin,𝐯toutsubscriptsuperscript𝐯in𝑡subscriptsuperscript𝐯out𝑡\mathbf{v}^{\text{in}}_{t},\mathbf{v}^{\text{out}}_{t}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_v start_POSTSUPERSCRIPT out end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT and 𝐯tversubscriptsuperscript𝐯ver𝑡\mathbf{v}^{\text{ver}}_{t}bold_v start_POSTSUPERSCRIPT ver end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. This example provides an optional vision input for VLMs, adding a visual recognition challenge. The brown parts marks the task and related information, and the purple parts denote the state (st)subscript𝑠𝑡(s_{t})( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) specific info. The blue and red describe the output from the model and verifier, respectively.

🔼 Figure 12 illustrates how the prompt is updated iteratively in a multi-turn reinforcement learning setting. The initial prompt (𝑣𝑖𝑛) includes the task description and any relevant information. After each turn, the model’s output (𝑣𝑜𝑢𝑡) and the verifier’s feedback (𝑣𝑣𝑒𝑟) are appended to the prompt to form the next input (𝑣𝑖𝑛𝑡+1). This example showcases a visual input variant where an image of cards is included, adding a layer of visual processing. Different colors highlight different parts of the prompt: brown for the task and related information, purple for the current state’s information, blue for the model’s output and red for the verifier’s output.
read the caption
Figure 12: An example of our prompt update for constructing 𝐯t+1insubscriptsuperscript𝐯in𝑡1\mathbf{v}^{\text{in}}_{t+1}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT using 𝐯tin,𝐯toutsubscriptsuperscript𝐯in𝑡subscriptsuperscript𝐯out𝑡\mathbf{v}^{\text{in}}_{t},\mathbf{v}^{\text{out}}_{t}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_v start_POSTSUPERSCRIPT out end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT and 𝐯tversubscriptsuperscript𝐯ver𝑡\mathbf{v}^{\text{ver}}_{t}bold_v start_POSTSUPERSCRIPT ver end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. This example provides an optional vision input for VLMs, adding a visual recognition challenge. The brown parts marks the task and related information, and the purple parts denote the state (st)subscript𝑠𝑡(s_{t})( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) specific info. The blue and red describe the output from the model and verifier, respectively.

🔼 Figure 13 illustrates the process of updating the prompt used by the model at each step of the multi-turn reinforcement learning process. The input to the model at time step t+1 (vint+1) is constructed by concatenating the previous input (vint), the model’s output at time step t (voutt), and the verifier’s output at time step t (vvert). The figure highlights the different parts of the prompt: the brown sections represent task instructions and related information, while the purple sections show state-specific details relevant to the current step in the process. Finally, the blue and red text indicate outputs from the model and verifier, respectively.
read the caption
Figure 13: An example of our prompt update for constructing 𝐯t+1insubscriptsuperscript𝐯in𝑡1\mathbf{v}^{\text{in}}_{t+1}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT using 𝐯tin,𝐯toutsubscriptsuperscript𝐯in𝑡subscriptsuperscript𝐯out𝑡\mathbf{v}^{\text{in}}_{t},\mathbf{v}^{\text{out}}_{t}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_v start_POSTSUPERSCRIPT out end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT and 𝐯tversubscriptsuperscript𝐯ver𝑡\mathbf{v}^{\text{ver}}_{t}bold_v start_POSTSUPERSCRIPT ver end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. The brown parts marks the task and related information, and the purple parts denote the state (st)subscript𝑠𝑡(s_{t})( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) specific info. The brown parts marks the task and related information, and the purple parts denote the state (st)subscript𝑠𝑡(s_{t})( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) specific info. The blue and red describe the output from the model and verifier, respectively.

🔼 Figure 14 illustrates how the prompt is updated iteratively in a multi-turn reinforcement learning (RL) setting for a vision-language model (VLM). The initial prompt (vin) contains the task instructions. After each turn, the model’s output (vout) and the verifier’s feedback (vver) are appended to the prompt to form the input for the next turn (vint+1). This iterative process allows the model to refine its response based on the verifier’s assessment. The figure highlights the visual input component for VLMs, the task-related information, and state-specific information which is essential for the model to perform the task. Different color codings are used to differentiate the different parts of the prompt.
read the caption
Figure 14: An example of our prompt update for constructing 𝐯t+1insubscriptsuperscript𝐯in𝑡1\mathbf{v}^{\text{in}}_{t+1}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT using 𝐯tin,𝐯toutsubscriptsuperscript𝐯in𝑡subscriptsuperscript𝐯out𝑡\mathbf{v}^{\text{in}}_{t},\mathbf{v}^{\text{out}}_{t}bold_v start_POSTSUPERSCRIPT in end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_v start_POSTSUPERSCRIPT out end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT and 𝐯tversubscriptsuperscript𝐯ver𝑡\mathbf{v}^{\text{ver}}_{t}bold_v start_POSTSUPERSCRIPT ver end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. This example provides an optional vision input for VLMs, adding a visual recognition challenge. The brown parts marks the task and related information, and the purple parts denote the state (st)subscript𝑠𝑡(s_{t})( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) specific info. The blue and red describe the output from the model and verifier, respectively.

🔼 This figure displays the results of experiments using Supervised Fine-Tuning (SFT) on the General Points (GP-L) task, where the model is trained on suboptimal trajectories instead of optimal ones. Suboptimal trajectories contain errors and verification messages, making the training data more diverse and less clean compared to what was used in Figure 5. The graph shows the in-distribution and out-of-distribution success rates of the model as a function of computational resources (GFLOPS). Despite the increased diversity in training data, the results are consistent with Figure 5: SFT still significantly overfits the training data, failing to generalize well to unseen instances.
read the caption
Figure 15: SFT experiments on GP-L with suboptimal trajectories. Similar to results in Figure 5, SFT overfits the training data even we increase the trajectory diversity.
Full paper#