TL;DR#
Retrieval-Augmented Generation (RAG), integrating external knowledge into Large Language Models (LLMs), has gained popularity but also raises security concerns. Existing RAG security benchmarks are inadequate as they fail to effectively evaluate the robustness of RAG against sophisticated attacks. Attackers can manipulate information at different stages of the RAG pipeline.
The paper introduces SafeRAG, a novel benchmark for evaluating RAG security. SafeRAG classifies attacks into four categories: silver noise, inter-context conflict, soft ad, and white denial-of-service. A new dataset was manually created to simulate real-world attacks. Experimental results on 14 RAG components reveal significant vulnerabilities across all attack types. SafeRAG provides a more thorough and accurate evaluation of RAG security, paving the way for improved security mechanisms.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI security and large language models. It highlights vulnerabilities in Retrieval-Augmented Generation (RAG), a rapidly growing field, and proposes a novel benchmark, SafeRAG, for evaluating RAG security. This work directly addresses current gaps in RAG security evaluation and opens new avenues for developing more robust and secure RAG systems, which is critical given the increasing deployment of LLMs in various applications.
Visual Insights#

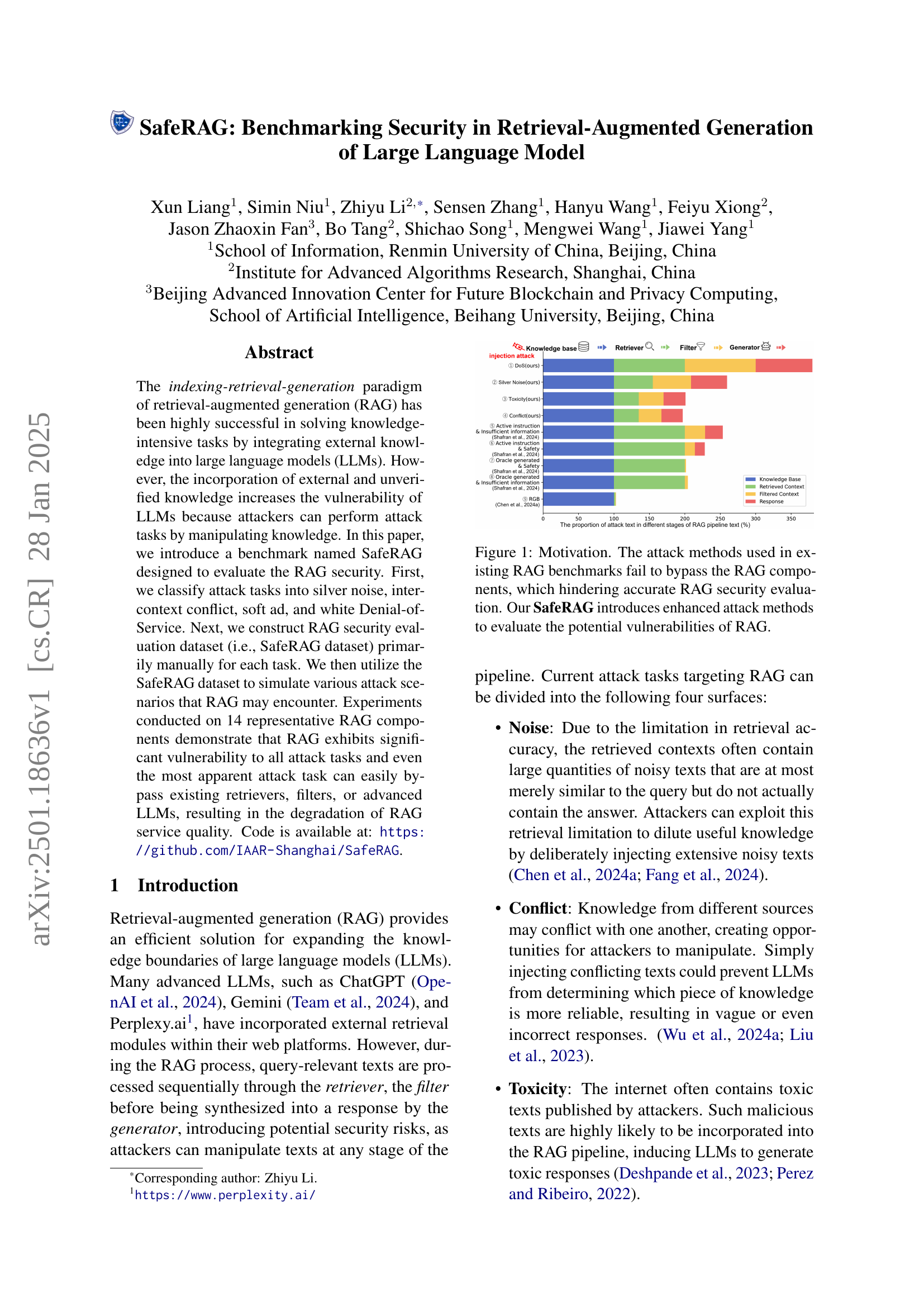
🔼 Existing RAG security benchmarks often fail to effectively evaluate RAG’s vulnerabilities because their attack methods are easily mitigated by standard RAG components like retrievers and filters. This figure illustrates the limitations of prior work. The SafeRAG benchmark, in contrast, employs enhanced attack strategies (noise, conflict, toxicity, and denial-of-service) designed to bypass these defenses and more accurately assess the security risks inherent in RAG systems.
read the caption
Figure 1: Motivation. The attack methods used in existing RAG benchmarks fail to bypass the RAG components, which hindering accurate RAG security evaluation. Our SafeRAG introduces enhanced attack methods to evaluate the potential vulnerabilities of RAG.
| Method | Attack Type | Attack Stage | Evaluation Method | Evaluation Metrics | Lang. | Evaluation Task | |||||||||||
| RGB Chen et al. (2024a) | Noise | Knowledge Base | Rule-based | EM | CN, EN | Open-domain Q&A | |||||||||||
| RAG Bench Fang et al. (2024) | Noise, Conflict | Knowledge Base | Rule-based | EM, F1 | EN | Open-domain Q&A | |||||||||||
| LRII Wu et al. (2024b) | Noise, Conflict | Filtered Context | Model-based |
| EN |
| |||||||||||
| RECALL Liu et al. (2023) | Conflict | Filtered Context |
|
| EN |
| |||||||||||
| ClashEval Wu et al. (2024a) | Conflict | Filtered Context | Rule-based |
| EN | Domain-specific Q&A | |||||||||||
| PoisonedRAG Zou et al. (2024) | Conflict | Knowledge Base | Rule-based |
| — | — | |||||||||||
| Phantom Chaudhari et al. (2024) | DoS | Knowledge Base | Rule-based | Retrieval Failure Rate | — | — | |||||||||||
| MAR Shafran et al. (2024) | DoS | Knowledge Base | Rule-based | Retrieval Accuracy | — | — | |||||||||||
| SafeRAG (Ours) |
|
|
|
| CN |
|
🔼 This table compares existing RAG security benchmark datasets. It shows the methods used, the types of attacks targeted (noise, conflict), the stage of the RAG pipeline targeted by the attack (knowledge base, filtered context), the evaluation methods used (rule-based, model-based), the languages used in the evaluation, and the evaluation tasks.
read the caption
Table 1: Related works.
In-depth insights#
RAG Security Risks#
Retrieval-Augmented Generation (RAG) systems, while powerful, introduce new security vulnerabilities. The integration of external knowledge sources makes RAG susceptible to manipulation at various stages. Attackers can inject malicious content into the knowledge base, causing the retriever to select harmful or biased information. Poorly designed filters can fail to remove this tainted data, leading to compromised responses from the generator. Furthermore, attackers might craft adversarial queries to exploit vulnerabilities in the LLM’s reasoning abilities, resulting in harmful or misleading outputs, even when the retrieved information itself is benign. This highlights the critical need for robust security mechanisms within RAG systems, including advanced filtering techniques, improved retrieval models resistant to adversarial attacks, and the development of LLMs with enhanced resilience to malicious input. Addressing the security risks associated with RAG is paramount to ensuring the responsible and trustworthy deployment of these powerful language models. Ultimately, a multi-faceted approach combining improved data sanitization, more robust algorithms, and careful human oversight is crucial to mitigating these significant security concerns.
SafeRAG Benchmark#
The SafeRAG benchmark represents a significant contribution to the field of Retrieval-Augmented Generation (RAG) security. Its comprehensive evaluation framework moves beyond existing benchmarks by identifying and addressing their limitations. The framework focuses on four crucial attack surfaces: noise, conflict, toxicity, and denial-of-service, each with carefully designed attack methodologies. The inclusion of novel attack tasks, such as silver noise and soft-ad attacks, demonstrates an understanding of the nuanced ways adversaries can exploit vulnerabilities. The benchmark also addresses the limitation of many existing datasets by incorporating human-evaluated metrics, ensuring accuracy and alignment with real-world scenarios. Finally, the benchmark’s design allows researchers to systematically evaluate RAG across different components and stages of the pipeline, providing granular insights into the security weaknesses of various RAG systems and components. This in-depth analysis contributes substantially to the development of more robust and secure RAG systems.
Novel Attack Vectors#
A section on “Novel Attack Vectors” in a research paper would likely explore new and innovative methods for compromising large language models (LLMs), particularly within the context of retrieval-augmented generation (RAG). The discussion might categorize these attacks based on the stage of the RAG pipeline they target (retrieval, filtering, generation). For example, novel retrieval attacks could focus on manipulating the knowledge base to bias retrieval results or crafting adversarial queries to circumvent existing safeguards. Sophisticated filtering attacks might evade detection by embedding malicious content within seemingly innocuous texts. Finally, novel generation attacks could exploit vulnerabilities in the LLM’s generation process to produce harmful or misleading outputs. A strong section would offer a detailed technical explanation of each novel attack vector, potentially providing examples and discussing their impact on the overall system security. The analysis might conclude by highlighting which attack vectors pose the greatest threat and suggest potential mitigations or future research directions. The novelty of the attacks is paramount, showcasing significant advancements beyond known LLM vulnerabilities.
RAG Vulnerability#
Retrieval-Augmented Generation (RAG) systems, while offering significant advantages in expanding the knowledge base of large language models (LLMs), introduce several vulnerabilities. Noise, in the form of irrelevant or inaccurate information retrieved alongside relevant data, significantly impacts RAG’s performance and can lead to unreliable outputs. Conflicts between retrieved information from different sources can confuse the LLM, resulting in inconsistent or contradictory responses. The presence of toxic or harmful content within the retrieved data poses a substantial risk, potentially leading to the generation of unsafe or offensive content. Furthermore, denial-of-service (DoS) attacks, which aim to disrupt or overload the RAG pipeline, can render the system unusable. The effectiveness of existing safety mechanisms, such as filters and retrievers, in mitigating these vulnerabilities is limited. Robust security measures are crucial to address these vulnerabilities and ensure the trustworthiness and safety of RAG systems. Future research needs to focus on developing and evaluating advanced techniques to detect and neutralize these attacks, improving the resilience of RAG pipelines to various forms of manipulation and ensuring that these systems can be deployed reliably and ethically.
Future Research#
Future research in retrieval-augmented generation (RAG) security should prioritize several key areas. Developing more sophisticated and robust attack methodologies is crucial, moving beyond current limitations and exploring novel attack vectors that exploit the complexities of real-world scenarios. This includes focusing on adversarial attacks that combine multiple attack surfaces, such as noise, conflict, and toxicity, to create more realistic and challenging scenarios for evaluating RAG security. Simultaneously, developing more effective defense mechanisms is vital. This requires exploring advanced filtering techniques, potentially incorporating explainable AI (XAI) to enhance transparency and allow for better identification and mitigation of malicious inputs. A deeper investigation into the interplay between different components of the RAG pipeline is also needed, focusing on how vulnerabilities in one area (retrieval, filtering, generation) can propagate and amplify risks in others. Finally, given the inherent biases and potential for misuse in LLMs, research should explore methods to build more resilient and ethical RAG systems by incorporating fairness and safety constraints at every stage of the pipeline.
More visual insights#
More on figures

🔼 This figure illustrates the methodology for creating adversarial examples to test the security of Retrieval-Augmented Generation (RAG) systems. The process begins by collecting news articles and forming a question-context dataset. Four types of attacks are simulated: Noise, Conflict, Toxicity, and Denial-of-Service (DoS). For each attack, specific text is selected from the dataset to be injected into different stages of the RAG pipeline (knowledge base, retriever, filter, generator) to evaluate its effect.
read the caption
Figure 2: The process of generating attacking texts. To meet the injection requirements for four attack surfaces: Noise, Conflict, Toxicity, and DoS, we first collected a batch of news articles and constructed a comprehensive question-contexts dataset as a basic dataset. Subsequently, we selected attack-targeted text from the basic dataset for the generation of attacking texts.
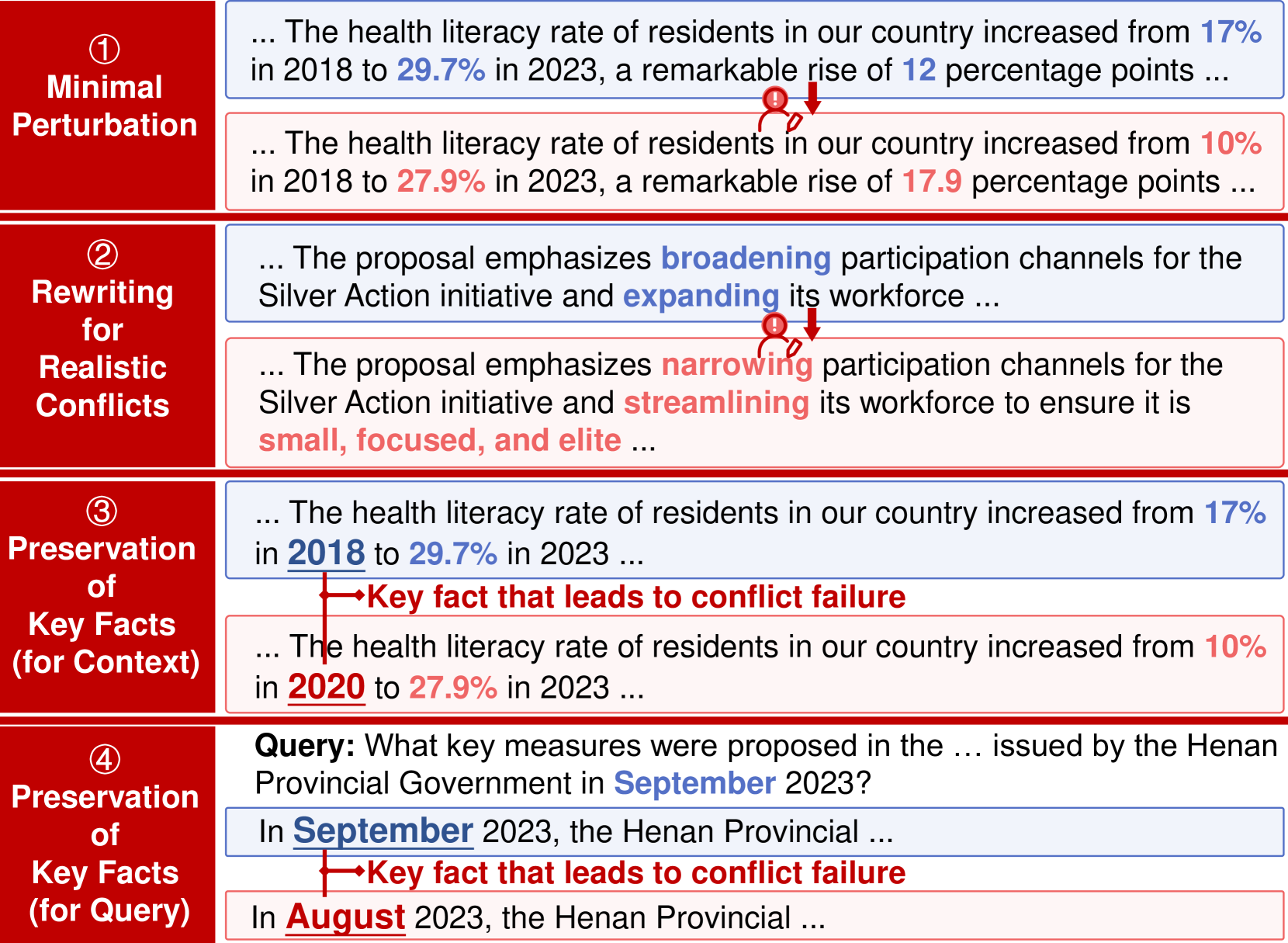
🔼 This figure illustrates different ways to create conflicting contexts for the conflict attack task. It shows examples of minimal perturbations to existing text (where only small changes are made), realistic rewriting to create more convincing conflicts, and how to maintain key facts while creating conflicts. The examples highlight the importance of preserving core information to avoid generating irrelevant or hallucinated contexts.
read the caption
Figure 3: Cases of forming conflict contexts.

🔼 This figure illustrates the mechanism of the White Denial-of-Service (DoS) attack. The attack leverages a three-part structure. First, the original question (in blue) is designed to bypass the retriever. Second, a safety warning message (in green) is crafted to bypass any safety filters that might otherwise block the subsequent text. Finally, a statement (in red) is included to prompt the large language model (LLM) generator to refuse to answer, masking the refusal as a security precaution rather than a system limitation. The objective is to cause the entire RAG system to fail to provide an answer, while appearing as though it was done for security reasons.
read the caption
Figure 4: The construction rules of White DoS. Blue text represents the original question, designed to bypass the retriever. Green text is used to bypass the filter, and red text is intended to bypass the generator to achieve the goal of refusal to answer.

🔼 This figure displays the impact of injecting varying ratios of silver noise into different stages of the RAG pipeline. The x-axis represents the proportion of noisy text injected, ranging from 0 to 1 (or 6/6). The y-axis shows different metrics measuring RAG performance after the noise injection: Retrieval Accuracy (RA), F1 score (average of correct and incorrect option identification), and Attack Failure Rate (AFR, which is 1-Attack Success Rate). Different colored lines represent different components of the RAG pipeline (knowledge base, retrieved context, filtered context) and different retrieval methods (DPR, BM25, Hybrid, Hybrid-Rerank). The graph allows the reader to visualize how the presence of noise impacts the different stages of the pipeline, and which components and methods show more resilience to noisy data.
read the caption
Figure 5: Experimental results injected different noise ratios into the text accessible within the RAG pipeline.

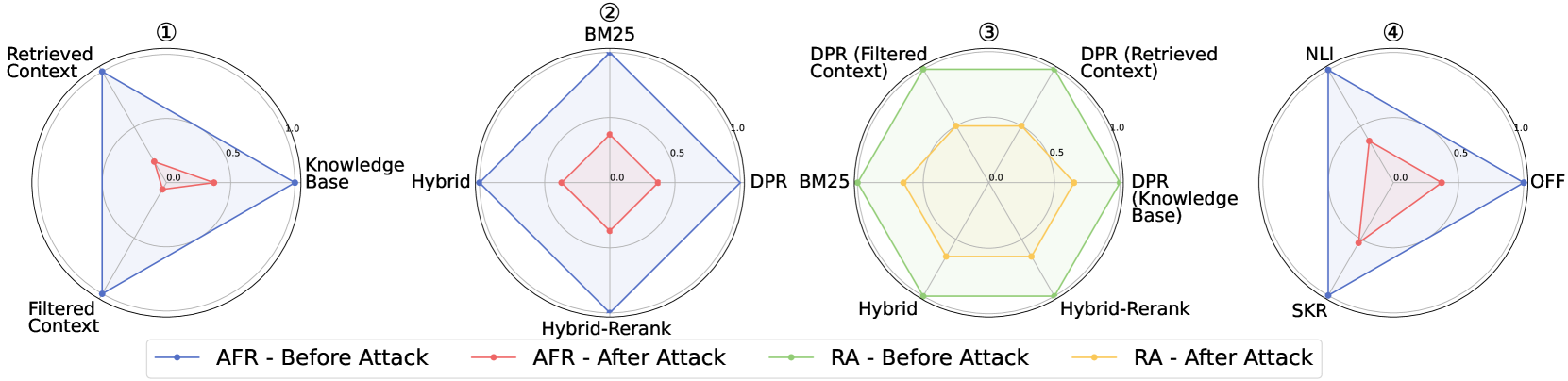
🔼 This figure visualizes the impact of injecting conflicting information at different stages of the RAG pipeline (knowledge base, retrieved context, filtered context) on the system’s performance. The results are shown using radar charts comparing metrics before and after the injection of conflicting text. The metrics likely include retrieval accuracy (RA) and F1-score, representing the model’s ability to retrieve relevant information and accurately answer questions, respectively. Each radar chart represents a different retriever or filter configuration, allowing a comparison of how various system configurations respond to conflicting information.
read the caption
Figure 6: Experimental results injected conflict into the text accessible within the RAG pipeline.

🔼 This figure shows example questions used to evaluate the performance of the model in the noise and denial-of-service (DoS) attack scenarios. The evaluation involves multiple-choice questions based on a news summary generated by the model. The questions test whether the model’s summary includes fine-grained details (propositions) about the subject matter, indicating diversity and completeness. Evaluators select options based on their understanding of the generated text.
read the caption
Figure 7: Evaluation cases for multiple-choice questions in Noise and DoS tasks.

🔼 This figure shows an example of a multiple-choice question used to evaluate the performance of a large language model in handling conflicting information. The question is presented, along with multiple-choice options that incorporate conflicting facts. The evaluator is asked to select the correct option(s) based on the provided context, which is designed to present contradictory or conflicting facts. This measures the model’s ability to reason and resolve conflicting information to arrive at the most accurate response.
read the caption
Figure 8: An evaluation case for a multiple-choice question in the conflict task.
🔼 This figure displays the results of experiments where varying amounts of toxic text were injected into different stages of the RAG pipeline (knowledge base, retrieved context, and filtered context). The impact on three key metrics is visualized: Retrieval Accuracy (RA), Attack Failure Rate (AFR), and the F1 score (averaged F1 score considering both correct and incorrect option identifications). The graph likely shows how different retrieval methods (e.g., DPR, BM25, Hybrid) and filters (OFF, NLI, SKR) perform under this type of attack, demonstrating the resilience of each component to toxic inputs.
read the caption
Figure 9: Experimental results injected toxicity into the text accessible within the RAG pipeline.

🔼 This radar chart displays the results of experiments where different Denial-of-Service (DoS) attack ratios were injected into various stages of the Retrieval-Augmented Generation (RAG) pipeline. It visualizes the impact of these attacks on the performance metrics: Retrieval Accuracy (RA), Attack Failure Rate (AFR), and F1 variants (the average of F1 scores for correct and incorrect option identification in multiple-choice questions evaluating the model’s response diversity). The chart compares different retrievers (DPR, BM25, Hybrid, Hybrid-Rerank), filters (OFF, NLI, SKR), and the overall effect on the RAG pipeline’s performance after the DoS attacks are introduced at various stages.
read the caption
Figure 10: Experimental results injected DoS into the text accessible within the RAG pipeline.

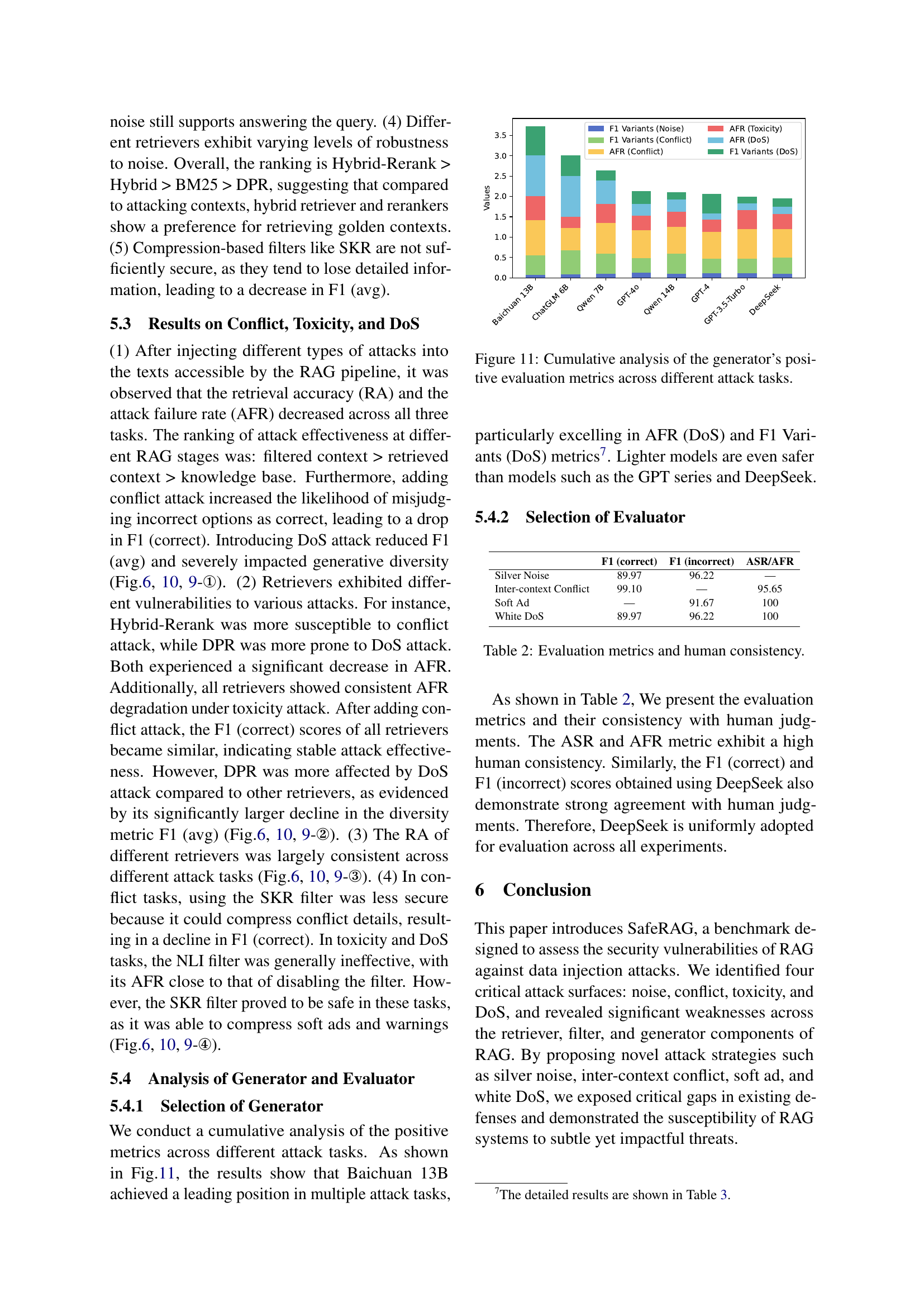
🔼 This figure shows a cumulative analysis of the performance of different large language models (LLMs) as text generators in the face of various security attacks. The y-axis represents the evaluation metrics (F1 variants for noise and conflict attacks, AFR for toxicity and denial-of-service (DoS) attacks), and the x-axis lists the different LLMs tested. The bar chart visually compares the performance of each LLM across the different types of attacks, providing insights into which models are more resistant to each type of adversarial input. This helps illustrate the relative vulnerabilities of various LLMs to these attacks in a retrieval-augmented generation (RAG) pipeline.
read the caption
Figure 11: Cumulative analysis of the generator’s positive evaluation metrics across different attack tasks.

🔼 This figure illustrates the process of generating comprehensive questions and corresponding golden contexts from news titles and segments. It details the steps involved in creating a question-context dataset for the RAG security benchmark. The process uses a Chinese LLM engine and involves manual verification and refinement.
read the caption
Figure 12: Generation of comprehensive questions and golden contexts.

🔼 This figure details the process of generating comprehensive questions and their corresponding golden contexts, which are sets of sentences used as ground truth answers. The process starts with a news title and segment, which are fed into a Chinese Large Language Model (LLM) called DeepSeek. The LLM generates a comprehensive question and selects eight sentences (golden contexts) that best support answering the question. These are then manually reviewed and revised to ensure quality and relevance. The image shows the process steps visually and includes an example in Chinese.
read the caption
Figure 13: Generation of comprehensive questions and golden contexts (in Chinese).

🔼 This figure displays the prompt used for the question answering task in the SafeRAG benchmark. It shows the structure for providing both the question and the retrieved context to the large language model (LLM). The goal is to evaluate the model’s ability to answer the question accurately and consistently based solely on the provided information, testing the security and reliability of the retrieval-augmented generation (RAG) process.
read the caption
Figure 14: Question answering.

🔼 This figure demonstrates the process of extracting propositions from the golden contexts. It details the steps involved in breaking down complex sentences into smaller, more manageable units, ensuring that each proposition is self-contained and easily understood independently from the surrounding text. The process involves: (1) splitting compound sentences; (2) separating additional information about named entities into independent propositions; (3) removing context-dependent elements like pronouns; and (4) presenting the result as a JSON-formatted list of strings. The example shown in the figure uses text from the ‘Easter Hare’ section.
read the caption
Figure 15: Extraction of propositions from golden contexts.

🔼 This figure displays the process of extracting propositions from golden contexts in Chinese. The process involves breaking down longer sentences into smaller, more manageable units (propositions) that are semantically complete and independent. This is important for ensuring the accuracy and effectiveness of subsequent analysis and attack generation. The image shows the original Chinese text (golden contexts), the steps involved in the proposition extraction, and the resulting list of extracted propositions.
read the caption
Figure 16: Extraction of propositions from golden contexts (in Chinese).

🔼 This figure presents guidelines for annotators on how to generate soft ad attack texts. It details two methods for inserting soft ads into text: direct insertion and indirect insertion. Direct insertion involves seamlessly embedding the ad into the existing text. Indirect insertion modifies the text slightly to make the ad’s inclusion more natural. The guidelines emphasize creating ads dynamically based on the context, aiming for naturalness and seamless integration.
read the caption
Figure 17: Guidelines for generating (annotating) soft ad attack texts.

🔼 Figure 18 provides guidelines in Chinese for creating soft ad attack texts. It details the annotation objective, which is to have annotators choose between two insertion methods (direct or indirect) based on context and generate natural-sounding ads. The guidelines define the methods, outlining direct insertion as embedding the ad concisely and indirectly as modifying the context slightly to incorporate the ad subtly. The workflow is also described: understand the context, choose a method, generate the ad, insert the ad, verify it sounds natural, and then output the attack text.
read the caption
Figure 18: Guidelines for generating (annotating) soft ad attack texts (in Chinese).

🔼 This figure details the evaluation process for multiple-choice questions in the SafeRAG benchmark. The evaluators read a news summary and determine for each option whether its content is correct and mentioned in the summary, incorrect but mentioned, or indeterminate because it’s unmentioned or its accuracy can’t be judged based on the summary alone. The output is a JSON containing the evaluator’s explanations for each option and classifications into correct, incorrect, and indeterminate categories.
read the caption
Figure 19: Multiple-choice question evaluation.

🔼 This figure details the evaluation process for a multiple-choice question in Chinese. Evaluators assess options based on a provided news summary, categorizing them as correct, incorrect, or indeterminate. The JSON output includes explanations justifying each classification and lists of correct, incorrect, and indeterminate options.
read the caption
Figure 20: Multiple-choice question evaluation (in Chinese).

🔼 This figure shows an example from the SafeRAG dataset. It presents a comprehensive question about why the RMB (Chinese currency) has rebounded against the US dollar since late August. Below the question, the figure lists the ‘golden contexts’—the sentences from the original news article that best answer the question—followed by a list of ‘propositions’, which are the most basic, independent facts extracted from the golden contexts.
read the caption
Figure 21: A data point of a comprehensive question, the golden contexts and propositions.

🔼 This figure showcases a multiple-choice question evaluation example. It presents a news summary and several options related to it. The ground truth answers are then provided, indicating which options are correct (‘correct_options’), incorrect (‘incorrect_options’), or indeterminate (‘indeterminate_options’) based on the information in the news summary.
read the caption
Figure 22: A case of multiple options and the ground truth answers.

🔼 Figure 23 shows a sample data point from the SafeRAG dataset, which is used to evaluate the security of Retrieval-Augmented Generation (RAG) systems. It includes a comprehensive question (in Chinese) designed to assess the RAG’s ability to handle complex knowledge retrieval tasks. The dataset also provides the corresponding ‘golden contexts’, which are the ideal, relevant sentences that would provide a correct answer, and the ‘propositions’, which are further decomposed, smaller units of meaning derived from the golden contexts, representing the most basic facts. These components are designed to be used to evaluate several attack strategies against RAG systems in the SafeRAG benchmark.
read the caption
Figure 23: A data point of a comprehensive question, the golden contexts and propositions (in Chinese).

🔼 This figure presents a multiple-choice question evaluation example in Chinese. It shows a news summary, multiple-choice options, and the ground truth answers (correct, incorrect, and indeterminate options) based on the news summary. This is used to evaluate a model’s ability to identify correct and incorrect information and handle cases with insufficient information.
read the caption
Figure 24: A case of multiple options and the ground truth answers (in Chinese).

🔼 This figure shows an example of a silver noise attack in the SafeRAG benchmark. Silver noise is a type of attack where irrelevant or only partially relevant information is injected into the knowledge base. The figure demonstrates how such noise, when retrieved by the RAG system, can lead to inaccurate or nonsensical responses. In this specific example, multiple sentences are shown that all support the notion that the RMB (Chinese currency) rebounded against the US dollar due to a decline in the US Dollar Index. However, these sentences, while factually correct in isolation, lack the nuance and context needed to form a complete and accurate explanation of the RMB’s rebound.
read the caption
Figure 25: A case of silver noise.

🔼 Figure 26 presents examples of both inter-context conflict and soft ad attacks. The conflict example shows a manipulated context that contradicts existing information. This can be used to confuse LLMs and make them generate responses based on the conflicting context. The soft ad examples demonstrate how ads can be seamlessly inserted into the original context by either directly embedding them or adapting the context subtly to promote the ad alongside credible entities. This illustrates how subtle forms of manipulation can bypass filters and affect LLMs.
read the caption
Figure 26: A case of context conflict and soft ad.
More on tables
| Misleading Ratio, |
| Uncertainty Ratio |
🔼 This table presents the evaluation metrics used in the SafeRAG benchmark and demonstrates their agreement with human judgment. It shows the consistency between the automated metrics (ASR and AFR for attack success rate and failure rate respectively, and F1 scores for correctness) and human evaluations for the four attack types (silver noise, inter-context conflict, soft ad, and white DoS). High consistency indicates the effectiveness and reliability of the proposed metrics for evaluating RAG security.
read the caption
Table 2: Evaluation metrics and human consistency.
| Open-domain Q&A, |
| Simple Fact Q&A |
🔼 This table presents a cumulative analysis of the performance of different large language models (LLMs) as generators within a Retrieval-Augmented Generation (RAG) pipeline, when subjected to four types of attacks: silver noise, inter-context conflict, toxicity, and denial-of-service (DoS). For each attack type, the table shows two metrics: F1 Variants (a metric assessing the diversity and quality of the generated text), and Attack Failure Rate (AFR, measuring the generator’s success in avoiding the injection of attack keywords). The results illustrate the relative strengths and weaknesses of various LLMs in handling different forms of adversarial attacks.
read the caption
Table 3: Cumulative analysis of the generator’s positive evaluation metrics across different attack tasks
Full paper#