TL;DR#
Existing human animation models suffer from limited datasets and overfitting, resulting in unrealistic or limited animations. This restricts their applications in areas like virtual reality and gaming. They often rely on highly filtered datasets to simplify the learning process and are usually limited to specific scenarios, for example, facial animation or animation with full-body images from a fixed perspective.
OmniHuman tackles this by introducing a novel ‘omni-conditions training’ strategy. This innovative method combines multiple conditioning signals (text, audio, pose) during training. This allows leveraging a broader range of data and significantly improves generalization capability. The model achieves highly realistic and versatile human video generation supporting various portrait styles and interactions, demonstrating improved accuracy in gesture generation compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical challenge of scaling up data in human animation models. Current methods struggle with limited datasets and overfitting, hindering the creation of realistic and versatile models. OmniHuman’s approach of combining multiple conditioning signals offers a significant advancement, opening new avenues for generating high-quality human animations across diverse scenarios. This work will directly influence future research in video generation, human animation, and related fields.
Visual Insights#

🔼 This figure showcases example video frames generated by the OmniHuman model. The input to the model is both audio and an image. The model outputs a video featuring realistic human movement that is synchronized to the input audio. This includes head and hand gestures, along with corresponding facial expressions. A key feature highlighted is the model’s ability to generate these videos at various aspect ratios and with different body proportions. The authors also emphasize that OmniHuman significantly outperforms previous models in generating accurate gestures and realistic object interactions, largely due to the benefits of the novel ‘omni-conditions training’ approach.
read the caption
Figure 1: The video frames generated by OmniHuman based on input audio and image. The generated results feature head and gesture movements, as well as facial expressions, that match the audio. OmniHuman generates highly realistic videos with any aspect ratio and body proportion, and significantly improves gesture generation and object interaction over existing methods, due to the data scaling up enabled by omni-conditions training.
In-depth insights#
OmniHuman: Scaling Up#
OmniHuman tackles the challenge of scaling up one-stage conditioned human animation models. Existing methods struggle with data limitations due to strict filtering requirements for audio and pose conditioning, hindering generalization. OmniHuman’s novel approach addresses this by integrating multiple conditions (text, audio, pose) during training, leveraging a mixed-conditions training strategy. This allows the model to learn richer motion patterns from a significantly larger and more diverse dataset. The core concept involves leveraging weaker conditioned tasks to boost data usage and adjusting the training ratio according to condition strength (stronger condition = lower training ratio). This strategy effectively mitigates data wastage and enhances the model’s capability to generalize across varied styles, perspectives and body poses. The results showcase improvements in realism, gesture generation, and object interaction, surpassing the performance of existing methods. The success of OmniHuman underscores the importance of thoughtful data scaling strategies, moving beyond simple data augmentation towards leveraging the synergistic relationship between different conditioning signals. This strategy has the potential to advance the field of human animation, leading to more versatile and robust models for diverse applications.
Mixed-Condition Training#
The core idea behind “Mixed-Condition Training” is to enhance the generalization and scalability of human animation models by training with multiple, diverse conditioning signals simultaneously. Instead of relying on a single condition (like audio for audio-driven animation), the approach leverages a combination of conditions (e.g., audio, pose, text, and reference image) of varying strengths. This approach mitigates the limitations of single-condition models, which often require heavily filtered datasets, thus discarding valuable data. Weaker conditions (e.g., audio) are combined with stronger conditions (e.g., pose) to guide the model’s training. The training strategy also incorporates the concept of a progressive learning process. Starting with weaker conditions, stronger conditions are progressively introduced during training. This enables the model to effectively leverage a larger, more diverse dataset. The principle of leveraging weaker conditions to scale up data is crucial, allowing for the inclusion of data points previously discarded due to filtering. The proposed training principles ensure that the model does not over-rely on any single condition, thereby improving its robustness and generalization to unseen scenarios. This method is expected to produce more realistic and versatile human animation models that perform well with diverse inputs and challenging scenarios.
Data Scaling Strategies#
The core challenge addressed in the paper is scaling up training data for high-quality human animation models. Directly increasing data size proves insufficient due to the inherent complexities of audio-visual correlation and the need for precise lip-sync and pose accuracy. The proposed solution, omni-conditions training, cleverly circumvents this limitation. By incorporating multiple conditioning signals (text, audio, pose), the method allows for the effective use of data that would otherwise be discarded due to imperfect conditions in a single-modality approach. This strategy leverages two key principles: stronger conditions can utilize data from weaker ones, and stronger conditions should have a lower training ratio. This mixed-condition training approach leads to a significantly larger and more diverse dataset, fostering better generalization and improved animation realism, particularly regarding gesture generation and complex body poses. The effectiveness of this strategy is empirically validated through various ablation studies which analyze the influence of different data ratios on model performance.
Ablation Study Insights#
Ablation studies within the context of the OmniHuman model reveal crucial insights into its design and performance. The impact of varying training ratios for different conditioning signals (audio and pose) is particularly noteworthy. A balanced approach, where stronger conditions like pose receive lower training weight than weaker conditions like audio, proves optimal for preventing overfitting to strong signals and fully leveraging the information present in all conditions. The ablation studies strongly support the two key principles underpinning OmniHuman’s training strategy: the leveraging of weaker conditions’ data by stronger ones and the inverse relationship between conditioning strength and training ratio. These findings highlight the efficacy of the proposed omni-conditions training, demonstrating that it is not simply about increasing data quantity, but also about intelligently mixing various conditioning signals to improve model generalization and quality. Furthermore, the results emphasize the importance of appropriate reference image ratio during training, indicating that the model’s ability to maintain visual identity and background fidelity hinges on this balance. Finally, the ablation experiments underscore that a carefully considered training regime, guided by a principled understanding of the various modalities’ relative strengths and their influence on training dynamics, is paramount for achieving high-quality, generalizable human animation. These insights underscore the meticulous design and experimental validation that underpins the successful scaling up of the OmniHuman model.
Future Directions#
Future research directions for OmniHuman and similar models should focus on improving the diversity and quality of training data, exploring more sophisticated conditioning methods beyond audio and pose, and addressing the challenges of generating longer, more coherent videos. Exploring alternative model architectures beyond the Diffusion Transformer could unlock further advancements in efficiency and realism. Addressing biases present in existing datasets is crucial, and developing techniques for controlling and mitigating such biases within generated videos should be a priority. Finally, ethical considerations related to deepfakes and misuse of human animation technology need to be carefully considered and proactively addressed, perhaps through the development of robust detection and verification methods.
More visual insights#
More on figures

🔼 Figure 2 illustrates the OmniHuman framework, detailing its two main components: the OmniHuman model and the omni-conditions training strategy. The OmniHuman model, built upon the Diffusion Transformer (DiT) architecture, is capable of simultaneous conditioning using text, image, audio, and pose inputs to generate human videos. The omni-conditions training strategy uses a progressive, multi-stage approach, starting with weaker conditions (like text) and gradually incorporating stronger ones (like pose), to maximize the utilization of diverse training data. This mixed-condition training allows for scaling up by using data that would be typically excluded due to strict filtering requirements in single-condition training methods, resulting in a more robust and generalizable model.
read the caption
Figure 2: The framework of OmniHuman. It consists of two parts: (1) the OmniHuman model, which is based on the DiT architecture and supports simultaneous conditioning with multiple modalities including text, image, audio, and pose; (2) the omni-conditions training strategy, which employs progressive, multi-stage training based on the motion-related extent of the conditions. The mixed condition training allows the OmniHuman model to benefit from the scaling up of mixed data.

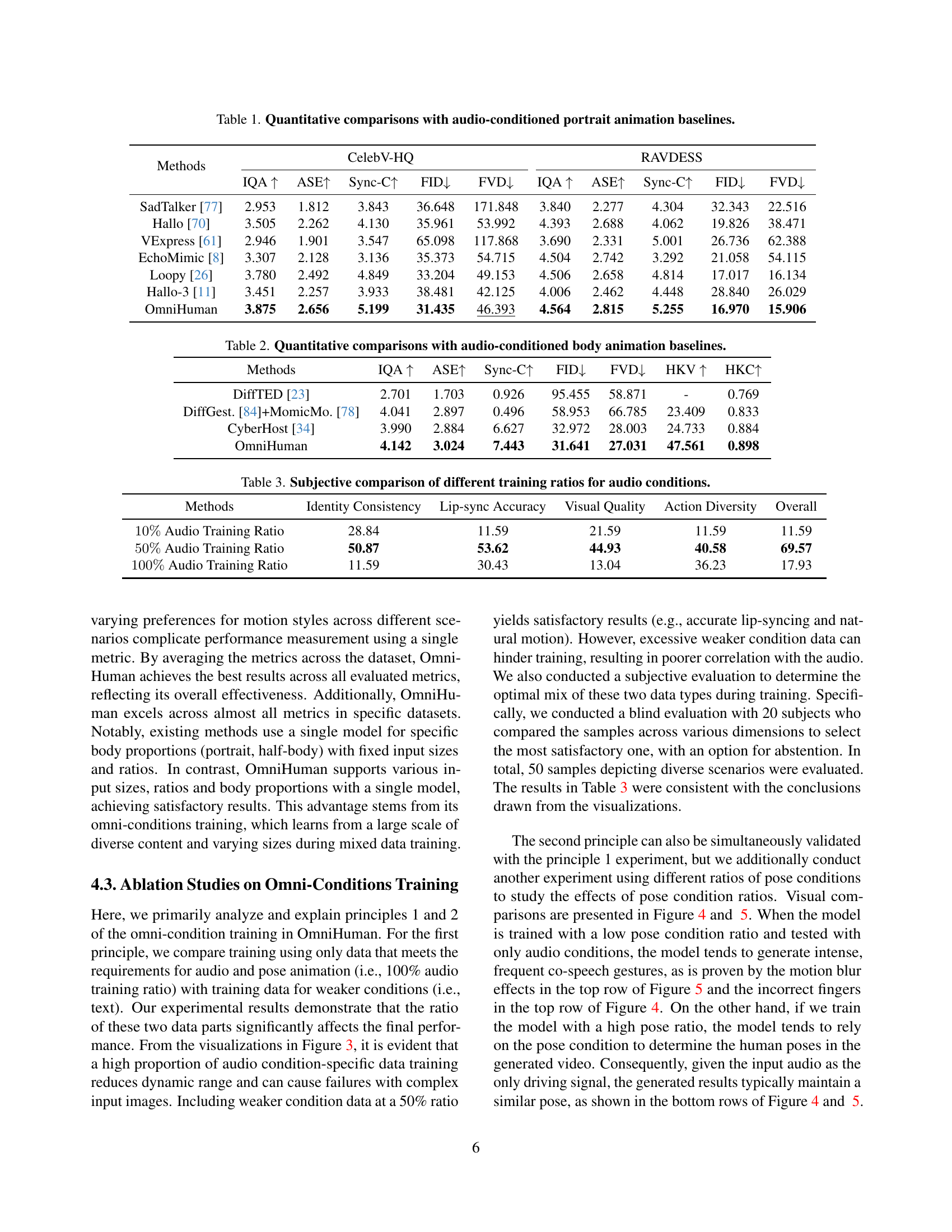
🔼 This figure presents a quantitative comparison of OmniHuman against several existing audio-conditioned portrait animation baselines. The comparison uses various metrics to evaluate aspects like image quality (IQA, ASE), audio-visual synchronization (Sync-C), and the realism of the generated videos (FID, FVD). The results demonstrate OmniHuman’s performance relative to state-of-the-art methods on two popular benchmark datasets: CelebV-HQ and RAVDESS.
read the caption
Figure 3: Quantitative comparisons with audio-conditioned portrait animation baselines.

🔼 This figure presents a quantitative comparison of OmniHuman’s performance against other state-of-the-art baselines for audio-conditioned body animation. It likely shows key metrics such as FID (Fréchet Inception Distance) and FVD (Fréchet Video Distance) scores, which evaluate the quality and realism of the generated videos. The metrics might also include measures of lip synchronization accuracy and the quality of generated hand movements. By comparing these metrics across different methods, the table helps demonstrate the superior performance of OmniHuman in producing realistic and high-quality body animations based on audio input.
read the caption
Figure 4: Quantitative comparisons with audio-conditioned body animation baselines.

🔼 This figure displays a subjective comparison of using different ratios of audio data during training for an audio-driven human animation model. It visually demonstrates how varying the proportion of audio-specific training data affects the model’s performance, particularly in terms of identity consistency, lip-sync accuracy, visual quality, action diversity, and overall quality. Different percentages of audio-related data are used for training, and the resulting videos from each training condition are subjectively evaluated and compared.
read the caption
Figure 5: Subjective comparison of different training ratios for audio conditions.

🔼 This ablation study investigates the effect of varying the proportion of audio data used during training on the performance of an audio-driven video generation model. Three models were trained with different audio ratios: 10%, 50%, and 100%. The results show that using only a small amount of audio data (10%) leads to poor generation quality, while using too much audio data (100%) can also negatively impact performance, possibly due to overfitting. A balanced approach (50%) seems to yield the best results.
read the caption
Figure 6: Ablation study on different audio condition ratios. The models are trained with different audio ratios (top: 10%, middle: 50%, bottom: 100%) and tested in an audio-driven setting with the same input image and audio.

🔼 This figure presents an ablation study on the impact of varying pose condition ratios during the training of a human animation model. Three models were trained with different pose condition ratios: 20%, 50%, and 80%. Each model was then tested on the same audio and image input in an audio-driven setting. The visual results allow for a comparison of the generated human motion videos across different pose condition ratios. This helps to analyze how the proportion of pose conditioning data during training affects the quality and realism of the generated animations, specifically focusing on the accuracy of pose representation in the output videos.
read the caption
Figure 7: Ablation study on different pose condition ratios. The models are trained with different pose ratios (top: 20%, middle: 50%, bottom: 80%) and tested in an audio-driven setting with the same input image and audio.

🔼 This figure shows an ablation study on the impact of different training ratios for pose conditions on the performance of an audio-driven human animation model. Three models were trained with varying pose condition ratios: 20%, 50%, and 80%. All three models were tested using the same input image and audio. The results visually demonstrate how the training ratio affects the model’s ability to generate realistic and coherent human movements in an audio-driven setting. The differences in motion generation quality, particularly in the synchronization of body movements with audio, can be observed by comparing the results of the three models.
read the caption
Figure 8: Ablation study on different pose condition ratios. The models are trained with different pose ratios (top: 20%, middle: 50%, bottom: 80%) and tested in an audio-driven setting with the same input image and audio.
Full paper#