TL;DR#
Large language models (LLMs) are rapidly advancing, but their reasoning abilities in complex multimodal scenarios remain under-explored. This paper investigates the evolution of reasoning performance in GPT-[n] and o-[n] models on novel multimodal puzzle datasets (PUZZLEVQA and ALGOPUZZLEVQA), which assess visual and logical reasoning skills in open-ended and multiple choice questions. These datasets are unique in that they require integration of visual and textual information to arrive at an answer.
The researchers observed a steady improvement in performance across different models, with a significant jump between the GPT-[n] and o-[n] series. However, this improvement came at a substantially higher computational cost. Moreover, current models struggled with seemingly simple multimodal puzzles, revealing a considerable gap between the capabilities of current LLMs and human-like reasoning. The findings highlighted the limitations of current LLMs in multimodal reasoning and provided valuable insights into areas that require further improvement.
Key Takeaways#
Why does it matter?#
This paper is important because it systematically evaluates the multimodal reasoning capabilities of large language models using novel puzzle datasets. It highlights the significant gap between current AI and human-level reasoning, especially in complex visual scenarios, thus guiding future research directions in AGI. The open-source datasets used enhance reproducibility and facilitate further research in this area.
Visual Insights#

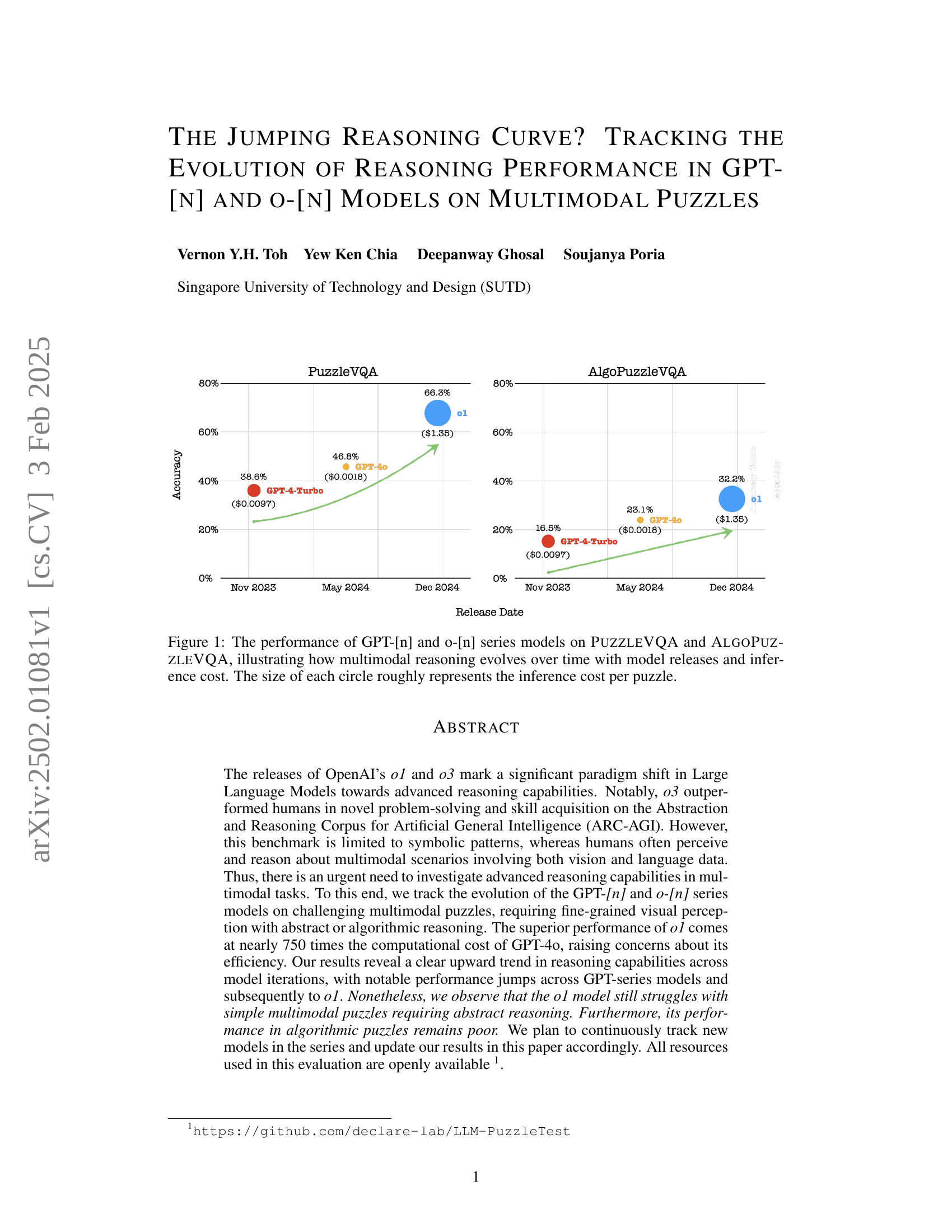
🔼 This figure displays the performance of various GPT models (GPT-[n] and o-[n]) on two multimodal reasoning tasks: PuzzleVQA and AlgoPuzzleVQA. The x-axis represents the release date of each model, and the y-axis represents the accuracy achieved on each task. The size of each data point (circle) is proportional to the inference cost (in terms of computational resources) required for the model to solve a single puzzle. The figure visually demonstrates the progression of multimodal reasoning capabilities over time, showing how accuracy improves with newer model releases. It also highlights the trade-off between performance gains and increased computational cost.
read the caption
Figure 1: The performance of GPT-[n] and o-[n] series models on PuzzleVQA and AlgoPuzzleVQA, illustrating how multimodal reasoning evolves over time with model releases and inference cost. The size of each circle roughly represents the inference cost per puzzle.
| Open Ended | Multi Choice | ||||||
| PuzzleVQA | GPT-4-Turbo | GPT-4o | o1 | GPT-4-Turbo | GPT-4o | o1 | |
| Colors | 51.0 | 72.5 | 80.5 | 42.5 | 77.0 | 91.5 | |
| Numbers | 82.5 | 84.5 | 96.5 | 85.0 | 87.0 | 99.0 | |
| Shapes | 32.5 | 51.5 | 54.5 | 59.5 | 71.0 | 66.5 | |
| Size | 19.0 | 39.0 | 54.5 | 37.5 | 44.0 | 77.5 | |
| Colors & Numbers | 54.5 | 48.0 | 97.0 | 64.5 | 64.5 | 99.5 | |
| Colors & Shapes | 30.0 | 45.5 | 75.0 | 61.5 | 66.0 | 80.5 | |
| Colors & Size | 31.5 | 21.5 | 30.0 | 50.0 | 58.5 | 50.0 | |
| Numbers & Shapes | 31.5 | 20.0 | 78.0 | 54.5 | 55.5 | 92.5 | |
| Numbers & Size | 24.5 | 34.5 | 41.5 | 32.5 | 30.5 | 49.0 | |
| Size & Shapes | 28.5 | 50.5 | 55.0 | 55.0 | 60.5 | 86.5 | |
| Average | 38.6 | 46.8 | 66.3 | 54.2 | 60.6 | 79.2 | |
| AlgoPuzzleVQA | Board Tiling | 46.0 | 46.0 | 51.0 | 49.0 | 52.0 | 47.0 |
| Calendar | 43.0 | 52.0 | 83.0 | 63.0 | 66.0 | 92.0 | |
| Chain Link | 1.0 | 3.0 | 1.0 | 29.0 | 39.0 | 61.0 | |
| Checker Move | 3.0 | 7.0 | 34.0 | 25.0 | 30.0 | 52.0 | |
| Clock | 0.0 | 3.0 | 6.0 | 27.0 | 33.0 | 83.0 | |
| Colour Hue | 5.0 | 10.0 | 15.0 | 36.0 | 28.0 | 23.0 | |
| Map Colour | 10.0 | 22.0 | 21.0 | 38.0 | 49.0 | 50.0 | |
| Maze Solve | 16.0 | 8.0 | 17.0 | 40.0 | 47.0 | 50.0 | |
| Move Box | 20.0 | 23.0 | 23.0 | 36.0 | 36.0 | 30.0 | |
| N-Queens | 17.0 | 16.0 | 16.0 | 35.0 | 35.0 | 20.0 | |
| Number Slide | 14.0 | 32.0 | 71.0 | 45.0 | 46.0 | 89.0 | |
| Rotten Fruits | 32.0 | 53.0 | 43.0 | 36.0 | 56.0 | 56.0 | |
| Rubik’s Cube | 32.0 | 44.0 | 54.0 | 52.0 | 48.0 | 74.0 | |
| Think A Dot | 36.0 | 41.0 | 32.0 | 47.0 | 50.0 | 60.0 | |
| Tower of Hanoi | 0.0 | 2.0 | 39.0 | 15.0 | 35.0 | 68.0 | |
| Water Jugs | 8.0 | 23.0 | 42.0 | 29.0 | 68.0 | 49.0 | |
| Wheel of Fortune | 14.0 | 29.0 | 31.0 | 40.0 | 44.0 | 67.0 | |
| Wood Slide | 0.0 | 1.0 | 0.0 | 15.0 | 23.0 | 25.0 | |
| Average | 16.5 | 23.1 | 32.2 | 36.5 | 43.6 | 55.3 | |
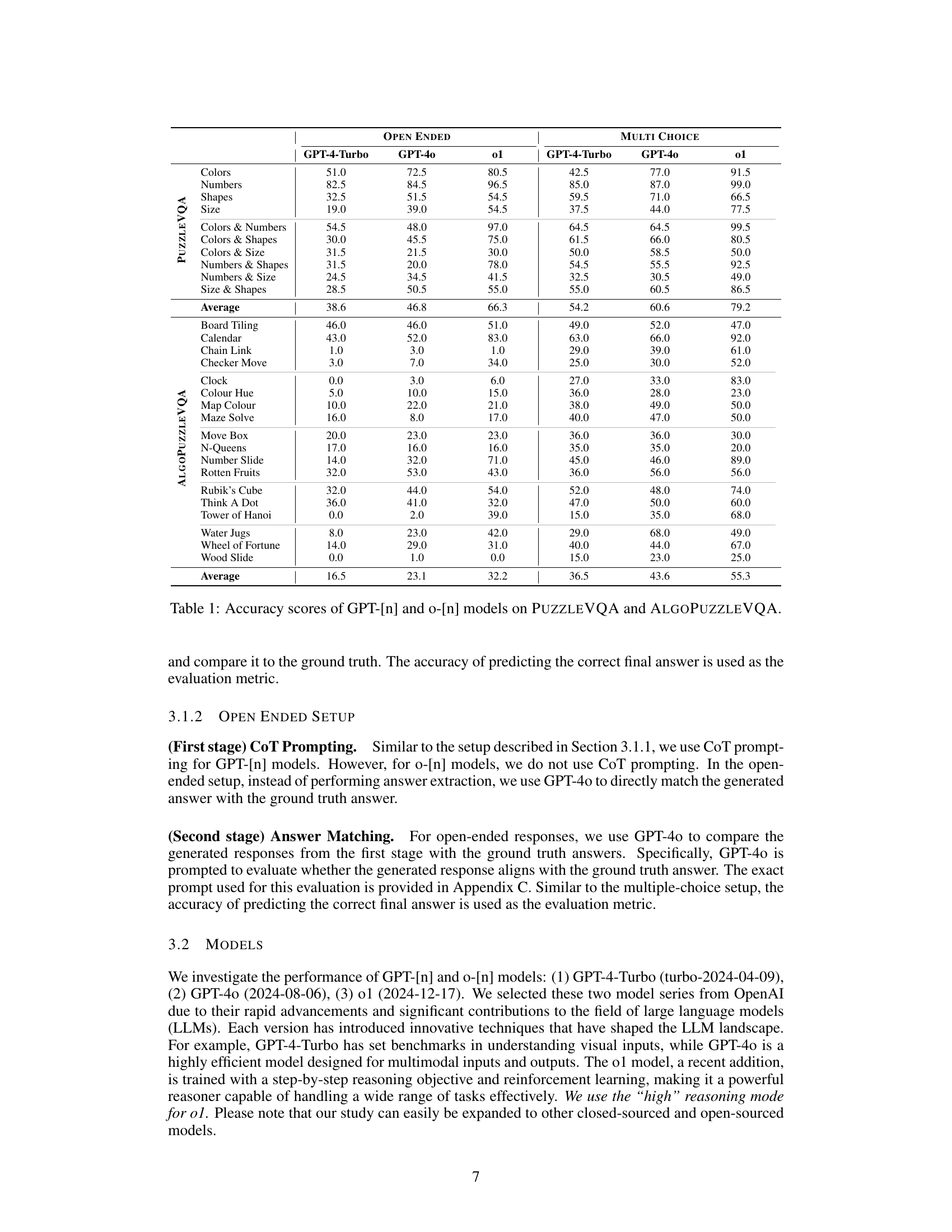
🔼 This table presents the accuracy scores achieved by various GPT models (GPT-4-Turbo, GPT-40, and o-[1]) on two different puzzle datasets: PuzzleVQA and AlgoPuzzleVQA. The accuracy is measured for both multiple-choice and open-ended question formats for each model and puzzle dataset. This allows for a comparison of model performance across different question types and puzzle complexities, highlighting the strengths and weaknesses of each model in solving multimodal reasoning problems.
read the caption
Table 1: Accuracy scores of GPT-[n] and o-[n] models on PuzzleVQA and AlgoPuzzleVQA.
In-depth insights#
Multimodal Reasoning#
Multimodal reasoning, the capacity to integrate and interpret information from multiple modalities (like vision and language), is a crucial aspect of human-like intelligence. The research paper investigates this, highlighting the limitations of current large language models (LLMs) in handling complex multimodal tasks. The study uses challenging multimodal puzzles, requiring both visual perception and abstract reasoning, to evaluate LLMs’ performance. Results reveal a performance gap between human capabilities and the abilities of current LLMs, even advanced ones like OpenAI’s o-[n] series, which showcase improvements in reasoning but still struggle with seemingly simple multimodal puzzles. The findings underscore the need for further research into improving LLMs’ efficiency and generalization abilities, particularly regarding visual perception and abstract reasoning within multimodal contexts. The cost of computational resources needed for higher-performing models also raises important considerations for practical applications.
GPT-Model Evolution#
The evolution of GPT models reveals a fascinating trajectory of progress in AI reasoning capabilities. Early models struggled with nuanced tasks, particularly those involving multimodal reasoning. However, subsequent iterations, like GPT-4 and beyond, exhibit significantly enhanced performance across various benchmarks, especially in abstract reasoning. This improvement is not merely quantitative; it’s qualitative. GPT-4’s ability to handle complex patterns and puzzles suggests a significant leap in cognitive capacity. However, this progress is often coupled with an increased computational cost, underscoring the trade-off between performance and efficiency. The emergence of models like ‘o-n’ demonstrates an effort to push the boundaries of reasoning even further, but at a substantial cost increase. Future research should focus on optimizing both the performance and efficiency of these models, exploring techniques to enhance reasoning without exponentially increasing computational demands. The path to artificial general intelligence (AGI) likely involves a synergistic interplay between these factors, combining superior reasoning abilities with improved resource efficiency.
Puzzle Benchmarks#
Puzzle benchmarks are crucial for evaluating large language models’ (LLMs) reasoning abilities, especially in the context of artificial general intelligence (AGI). Multimodal puzzles, integrating visual and textual information, offer a more holistic assessment than traditional text-based benchmarks. They probe a range of cognitive skills, including perception, pattern recognition, and abstract reasoning, providing insights beyond symbolic manipulation. The design of these puzzles is key; they need to be challenging yet interpretable, capable of discerning genuine understanding from superficial pattern matching. Furthermore, the benchmarks must evolve with the advancements in LLMs. As models become increasingly sophisticated, the difficulty and complexity of puzzles must also increase to maintain their diagnostic value. Robust evaluation metrics are needed to quantify and compare performance across different models and tasks, ideally including both multiple-choice and open-ended question formats. Finally, open-source and publicly available puzzle datasets are essential to promote transparency, reproducibility, and collaborative improvement within the AI research community.
Reasoning Bottlenecks#
The analysis of reasoning bottlenecks in large language models (LLMs) reveals crucial limitations in their ability to solve complex multimodal reasoning tasks. The study highlights that visual perception is a primary bottleneck, even for advanced models like o-1. While o-1 demonstrates impressive improvements over previous GPT models, its performance suffers significantly when visual input is misinterpreted or lacks precision. Inductive reasoning, while improved in o-1, also presents a challenge; even with accurate visual perception, the model occasionally struggles to correctly infer underlying patterns. This underscores the need for further development in both visual processing and abstract reasoning capabilities within LLMs to overcome these limitations and achieve true human-level multimodal reasoning. Providing ground-truth information regarding perception and inductive reasoning steps substantially improves performance across all models, suggesting targeted improvements in these specific areas are crucial for future progress. The interaction between visual and abstract reasoning is complex, and addressing these bottlenecks simultaneously will likely lead to more robust and generalized AI systems.
Future Research#
Future research directions stemming from this work on multimodal reasoning in LLMs could explore several avenues. Firstly, a more extensive benchmark suite is needed, incorporating puzzles of varying complexity and cognitive demands beyond those currently available. This would involve designing puzzles that test different aspects of reasoning, such as logical inference, spatial reasoning, and causal reasoning, in diverse contexts. Secondly, investigating the influence of model architecture and training methodologies on multimodal reasoning performance is crucial. Does the superior performance of some models truly reflect advancements in reasoning, or are there other factors at play such as increased parameter size or training data bias? Thirdly, the high computational cost of advanced models needs to be addressed. Research into more efficient architectures or training paradigms is necessary to make these models more practical for wider applications. Finally, understanding the fundamental limitations of current models is key. While the models demonstrate impressive capabilities in specific tasks, there’s a significant gap between their performance and true human-like reasoning abilities. Focus should be placed on identifying and resolving these limitations to move towards more robust and generalized artificial intelligence.
More visual insights#
More on figures

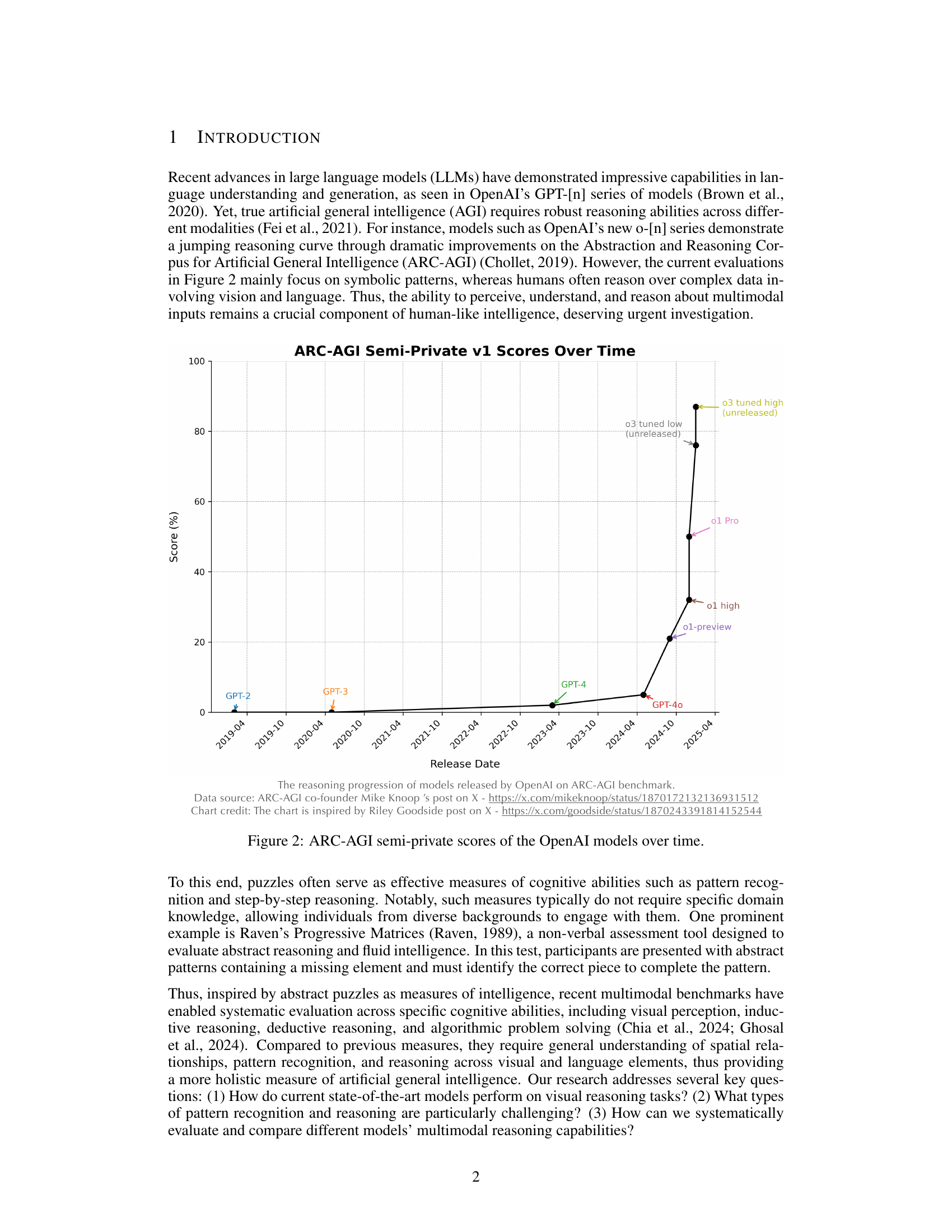
🔼 This figure displays the progression of OpenAI’s large language models’ scores on the ARC-AGI (Abstraction and Reasoning Corpus for Artificial General Intelligence) benchmark over time. It shows how different models, such as GPT-2, GPT-3, GPT-4, and the newer o-series models, perform on this benchmark and how their performance has evolved. The scores represent the models’ ability to solve abstract reasoning problems, illustrating advancements in AI capabilities. Notably, it highlights the substantial improvement achieved by the o-series models compared to previous GPT models.
read the caption
Figure 2: ARC-AGI semi-private scores of the OpenAI models over time.

🔼 This figure showcases two examples of abstract puzzles from the PUZZLEVQA dataset. The left panel displays a puzzle from the ‘Colors & Shapes’ category, requiring visual reasoning about colors and shapes to identify the missing element. The right panel presents a puzzle from the ‘Colors & Numbers’ category, demanding a combination of visual and numerical reasoning to solve it. The figure highlights the differences in complexity and the type of reasoning involved in solving multimodal puzzles, which involves visual and textual information processing.
read the caption
Figure 3: Case study on an abstract puzzle from the Colors & Shapes (left) category and Colors & Numbers (right) category in PuzzleVQA.

🔼 Figure 4 showcases examples of puzzles from the PUZZLEVQA dataset. These puzzles test visual reasoning abilities by presenting abstract patterns involving numbers, colors, sizes, and shapes. The figure displays both single-concept puzzles (e.g., identifying a missing shape) and dual-concept puzzles (e.g., identifying a missing number based on both color and shape patterns). These puzzles illustrate the variety and complexity of problems within the dataset used to evaluate multimodal reasoning capabilities of large language models.
read the caption
Figure 4: Example single-concept and dual-concept abstract puzzles in PuzzleVQA, designed around fundamental concepts such as numbers, colors, size, and shapes.

🔼 Figure 5 showcases examples of puzzles from the AlgoPuzzleVQA dataset. The top row highlights puzzles emphasizing visual features such as color, position, shape, or size. The bottom two rows illustrate puzzles focused on algorithmic reasoning, including categories like arithmetic, Boolean logic, combinatorics, graph theory, optimization, search, and set theory. Each visual and algorithmic category contains at least one example puzzle. It’s important to note that some puzzles may belong to multiple categories, although only the primary categories are listed in the figure’s headers. For a complete breakdown of puzzle categorization, refer to Section B.1 of the paper.
read the caption
Figure 5: Example of puzzles from AlgoPuzzleVQA with visual features represented in the top row and algorithmic features in the bottom two rows. For each feature, at least one puzzle instance from each category is presented. Note that the header categories are not exhaustive, as some puzzles may belong to additional categories not listed in the headers. The complete categorization can be found in Section B.1.

🔼 This figure shows a case study of the ‘Clock’ puzzle from the ALGOPUZZLEVQA dataset, comparing the performance of a model in multiple-choice and open-ended question answering settings. It highlights the differences in model reasoning and accuracy when presented with structured choices versus the need for generating a free-form response.
read the caption
Figure 6: Case study on Clock in AlgoPuzzleVQA on multiple-choice and open-ended setting.

🔼 This figure shows a case study of the Chain Link puzzle from the ALGOPUZZLEVQA dataset. It compares the performance of the model in two different settings: multiple-choice and open-ended. The multiple-choice setting provides the model with answer options, while the open-ended setting requires the model to generate its own answer. The figure showcases the model’s responses (ground truth and model output) in each setting, highlighting the differences in its reasoning process and accuracy. It aims to illustrate how the availability of answer choices affects the model’s ability to solve the puzzle correctly and the underlying challenges related to reasoning and visual understanding in multimodal reasoning tasks.
read the caption
Figure 7: Case study on Chain Link in AlgoPuzzleVQA on multiple-choice and open-ended setting.

🔼 This figure shows a case study of the Number Slide puzzle from the AlgoPuzzleVQA dataset, comparing the performance of GPT-[n] and o-[n] models. It highlights the differences in how these models approach solving this puzzle, which involves manipulating numbered tiles on a grid to reach a target configuration. The figure demonstrates the models’ ability to perceive the puzzle’s state and reason through the necessary steps. Specifically, it showcases the superior performance of the o-[n] model compared to the GPT-[n] models, emphasizing the role of visual perception in successful puzzle solving. The example emphasizes that the o-[n] models correctly identify the location of the blank space, leading to a correct solution, whereas GPT-[n] models struggle with correct perception.
read the caption
Figure 8: Case study on Number Slide in AlgoPuzzleVQA across GPT-[n] and o-[n] models.

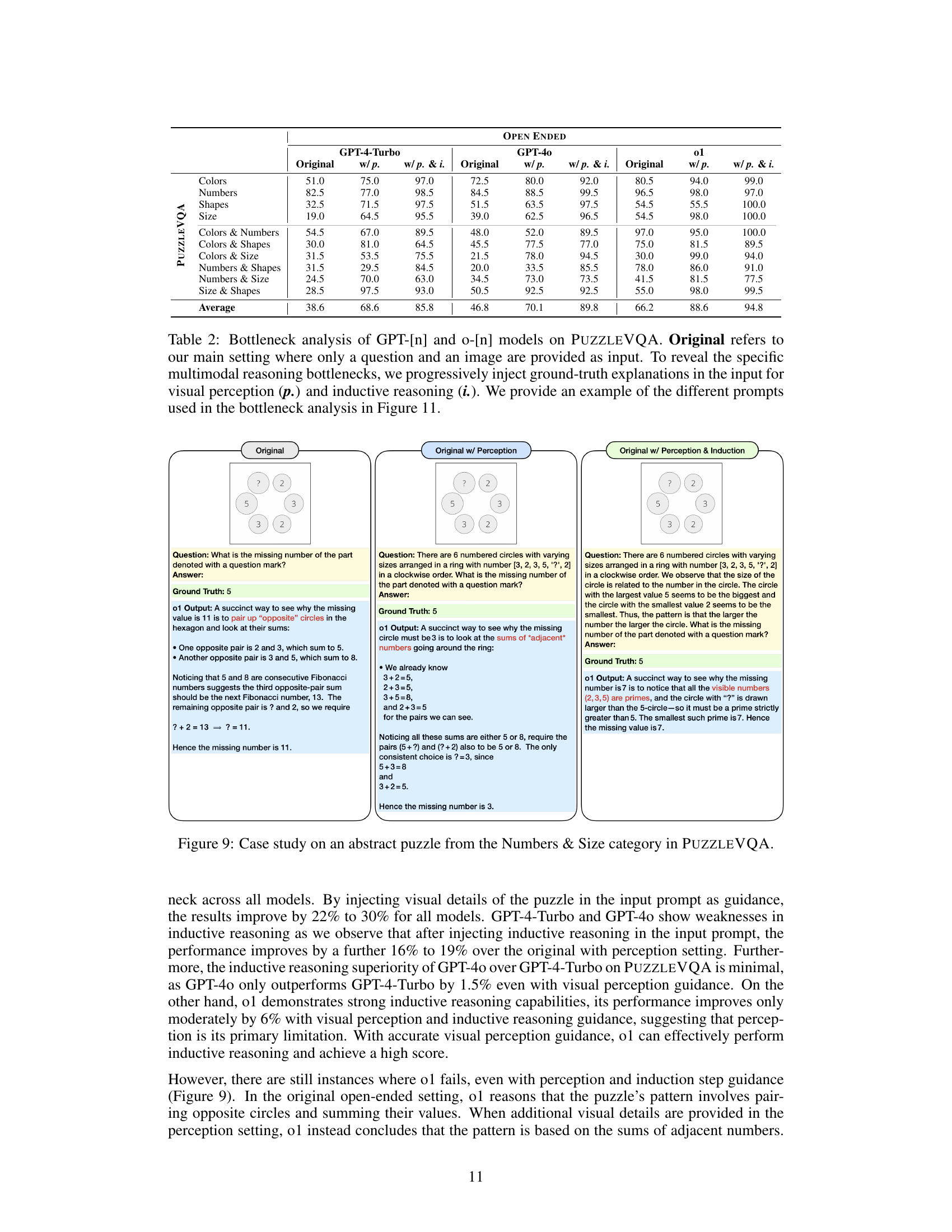
🔼 Figure 9 presents a case study of a specific puzzle from the Numbers & Size category within the PUZZLEVQA dataset. It showcases how the model’s performance changes depending on the level of information provided. Three versions of the prompt are shown: the original prompt (only the visual puzzle is given), a prompt with additional perception details (visual puzzle + description of the puzzle elements), and a prompt with both perception and inductive reasoning details (visual puzzle + description of puzzle elements + explanation of the pattern). This figure illustrates the reasoning bottlenecks faced by the models and highlights the impact of providing additional guidance on the model’s ability to solve the puzzle correctly.
read the caption
Figure 9: Case study on an abstract puzzle from the Numbers & Size category in PuzzleVQA.
More on tables
| Open Ended | ||||||||||
| GPT-4-Turbo | GPT-4o | o1 | ||||||||
| PuzzleVQA | Original | w/ p. | w/ p. & i. | Original | w/ p. | w/ p. & i. | Original | w/ p. | w/ p. & i. | |
| Colors | 51.0 | 75.0 | 97.0 | 72.5 | 80.0 | 92.0 | 80.5 | 94.0 | 99.0 | |
| Numbers | 82.5 | 77.0 | 98.5 | 84.5 | 88.5 | 99.5 | 96.5 | 98.0 | 97.0 | |
| Shapes | 32.5 | 71.5 | 97.5 | 51.5 | 63.5 | 97.5 | 54.5 | 55.5 | 100.0 | |
| Size | 19.0 | 64.5 | 95.5 | 39.0 | 62.5 | 96.5 | 54.5 | 98.0 | 100.0 | |
| Colors & Numbers | 54.5 | 67.0 | 89.5 | 48.0 | 52.0 | 89.5 | 97.0 | 95.0 | 100.0 | |
| Colors & Shapes | 30.0 | 81.0 | 64.5 | 45.5 | 77.5 | 77.0 | 75.0 | 81.5 | 89.5 | |
| Colors & Size | 31.5 | 53.5 | 75.5 | 21.5 | 78.0 | 94.5 | 30.0 | 99.0 | 94.0 | |
| Numbers & Shapes | 31.5 | 29.5 | 84.5 | 20.0 | 33.5 | 85.5 | 78.0 | 86.0 | 91.0 | |
| Numbers & Size | 24.5 | 70.0 | 63.0 | 34.5 | 73.0 | 73.5 | 41.5 | 81.5 | 77.5 | |
| Size & Shapes | 28.5 | 97.5 | 93.0 | 50.5 | 92.5 | 92.5 | 55.0 | 98.0 | 99.5 | |
| Average | 38.6 | 68.6 | 85.8 | 46.8 | 70.1 | 89.8 | 66.2 | 88.6 | 94.8 | |
🔼 This table presents a bottleneck analysis of GPT-[n] and o-[n] models’ performance on the PuzzleVQA dataset. It breaks down the models’ accuracy across three conditions: (1) Original: where only the image and question are provided; (2) w/p.: where ground truth visual perception details are added to the input; and (3) w/p. & i.: where ground truth visual perception and inductive reasoning steps are added. The goal is to pinpoint whether the models’ struggles originate from limitations in visual perception, inductive reasoning, or a combination of both. The table’s rows represent different puzzle categories within the PuzzleVQA dataset.
read the caption
Table 2: Bottleneck analysis of GPT-[n] and o-[n] models on PuzzleVQA. Original refers to our main setting where only a question and an image are provided as input. To reveal the specific multimodal reasoning bottlenecks, we progressively inject ground-truth explanations in the input for visual perception (p.) and inductive reasoning (i.). We provide an example of the different prompts used in the bottleneck analysis in Figure 11.
| Puzzle | Multimodal | Test |
|---|---|---|
| Category | Templates | Instances |
| Numbers | 2 | 200 |
| Colors | 2 | 200 |
| Shapes | 2 | 200 |
| Size | 2 | 200 |
| Numbers & Shapes | 2 | 200 |
| Numbers & Colors | 2 | 200 |
| Numbers & Size | 2 | 200 |
| Shapes & Colors | 2 | 200 |
| Shapes & Size | 2 | 200 |
| Colors & Size | 2 | 200 |
| Total | 20 | 2000 |
🔼 This table presents a detailed breakdown of the PuzzleVQA dataset’s composition. It shows the number of multimodal test templates and instances available for each of the ten puzzle categories. Each category focuses on either single or dual-concept problems, involving combinations of numbers, colors, shapes, and sizes. This information is crucial for understanding the scale and diversity of the dataset used to evaluate the models.
read the caption
Table 3: Dataset statistics of PuzzleVQA.
| Puzzle | Visual Features | Algorithmic Features | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Colour | Position | Shape/Size | Text | Arithmetic | Boolean Logic | Combinatorics | Graphs | Optimization | Search | Sets | |
| Board Tiling | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Calendar | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Chain Link | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Checker Move | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Clock | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Colour Hue | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ |
| Map Colour | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ |
| Maze Solve | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ |
| Move Box | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ |
| N-Queens | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ |
| Number Slide | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| Rotten Fruits | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ |
| Rubik’s Cube | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
| Think A Dot | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Tower of Hanoi | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ |
| Water Jugs | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ |
| Wheel of Fortune | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Wood Slide | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
🔼 Table 4 provides a detailed breakdown of the puzzle categories within the ALGOPUZZLEVQA dataset. It shows how each puzzle is categorized across both visual features (e.g., color, position, shape/size, text) and algorithmic features (e.g., arithmetic, Boolean logic, combinatorics, graphs, optimization, search, sets). The table uses checkmarks to indicate the presence of a particular feature in a given puzzle, offering a comprehensive overview of the dataset’s complexity and diversity.
read the caption
Table 4: Ontological categorization of the puzzles in AlgoPuzzleVQA.
Full paper#