TL;DR#
Large Language Models (LLMs) often produce inaccurate results due to limitations in their knowledge base. Retrieval-Augmented Generation (RAG) aims to address this by incorporating external information, but current RAG methods suffer from inefficient retrieval and redundant information. This paper introduces DeepRAG, a new framework that addresses these issues.
DeepRAG models the retrieval process as a Markov Decision Process (MDP), allowing for strategic and adaptive retrieval. It uses a binary tree search to explore different retrieval strategies, learning effective retrieval patterns through imitation learning and refining its decision-making through calibration. Experiments show that DeepRAG significantly outperforms existing methods in terms of accuracy and retrieval efficiency, demonstrating its potential for building more robust and reliable LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the critical issue of factual hallucination in large language models (LLMs) by proposing a novel framework, DeepRAG. DeepRAG improves upon existing retrieval-augmented generation (RAG) methods by incorporating adaptive retrieval, leading to more accurate and efficient reasoning. This offers a significant advancement for researchers working on improving LLM reliability and reasoning capabilities, opening new avenues for research in adaptive information retrieval and efficient knowledge integration.
Visual Insights#

🔼 This figure illustrates the parallel between human reasoning and DeepRAG’s approach to retrieval-augmented generation. The left side shows a human’s thought process when answering a complex question: first understanding the question, then breaking it down into smaller, manageable parts, searching for relevant information as needed, and finally combining the gathered information to formulate a complete answer. DeepRAG mimics this process using two key components: the retrieval narrative (ensuring a well-structured and adaptive flow of subqueries, building upon previous retrieval results) and atomic decisions (strategically deciding at each step whether to use external information retrieval or rely only on the model’s existing knowledge). This systematic approach contrasts with less efficient methods that may retrieve excessive information.
read the caption
Figure 1: Correspondence between human thinking processes and DeepRAG. Specifically, retrieval narrative ensures a structured and adaptive retrieval flow, generating subqueries informed by previously retrieved information, and atomic decisions dynamically determines whether to retrieve external knowledge or rely solely on the parametric knowledge for each subquery.
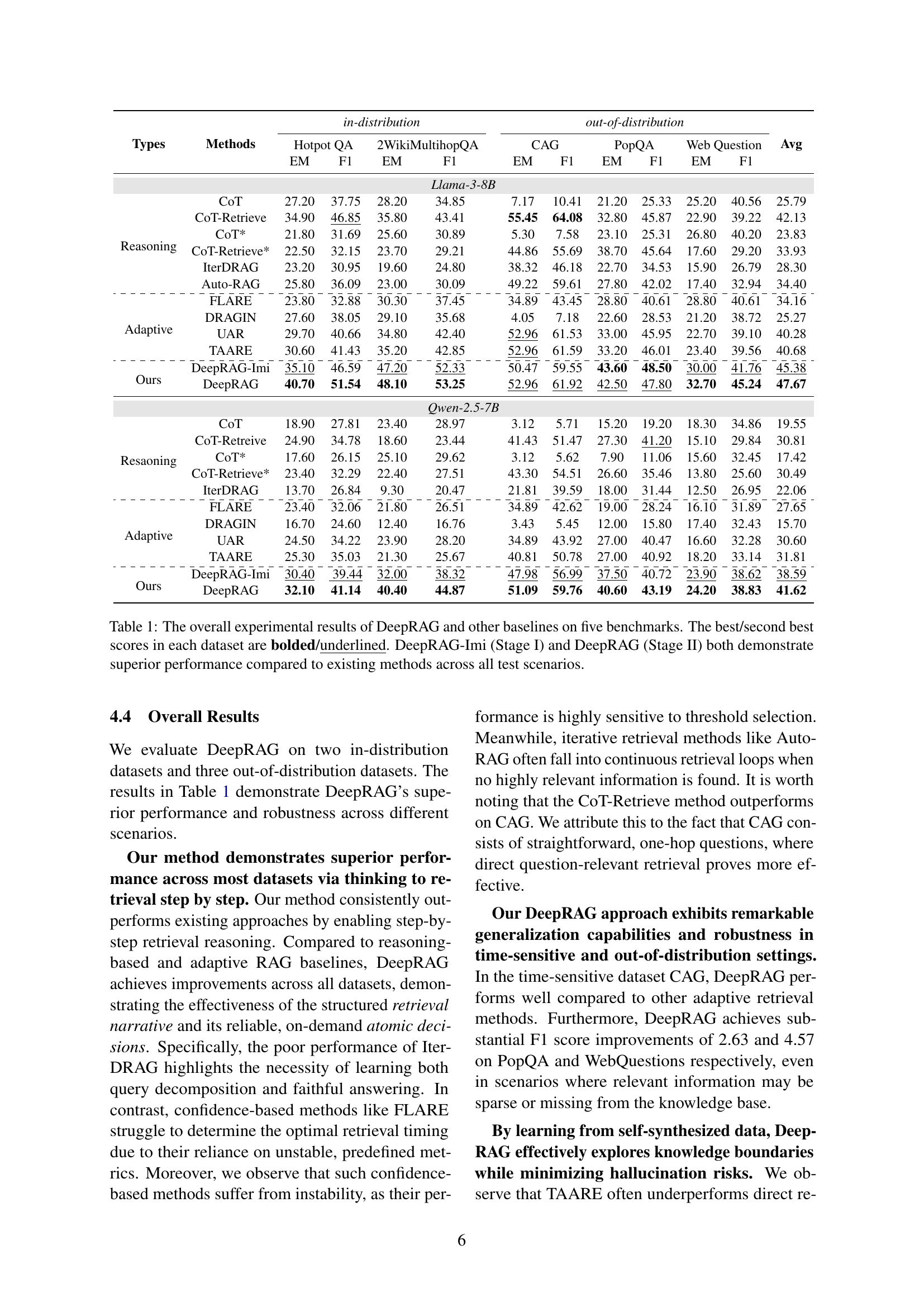
| Types | Methods | in-distribution | out-of-distribution | Avg | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hotpot QA | 2WikiMultihopQA | CAG | PopQA | Web Question | |||||||||
| EM | F1 | EM | F1 | EM | F1 | EM | F1 | EM | F1 | ||||
| Llama-3-8B | |||||||||||||
| Reasoning | CoT | 27.20 | 37.75 | 28.20 | 34.85 | 7.17 | 10.41 | 21.20 | 25.33 | 25.20 | 40.56 | 25.79 | |
| CoT-Retrieve | 34.90 | 46.85 | 35.80 | 43.41 | 55.45 | 64.08 | 32.80 | 45.87 | 22.90 | 39.22 | 42.13 | ||
| CoT* | 21.80 | 31.69 | 25.60 | 30.89 | 5.30 | 7.58 | 23.10 | 25.31 | 26.80 | 40.20 | 23.83 | ||
| CoT-Retrieve* | 22.50 | 32.15 | 23.70 | 29.21 | 44.86 | 55.69 | 38.70 | 45.64 | 17.60 | 29.20 | 33.93 | ||
| IterDRAG | 23.20 | 30.95 | 19.60 | 24.80 | 38.32 | 46.18 | 22.70 | 34.53 | 15.90 | 26.79 | 28.30 | ||
| Auto-RAG | 25.80 | 36.09 | 23.00 | 30.09 | 49.22 | 59.61 | 27.80 | 42.02 | 17.40 | 32.94 | 34.40 | ||
| \hdashlineAdaptive | FLARE | 23.80 | 32.88 | 30.30 | 37.45 | 34.89 | 43.45 | 28.80 | 40.61 | 28.80 | 40.61 | 34.16 | |
| DRAGIN | 27.60 | 38.05 | 29.10 | 35.68 | 4.05 | 7.18 | 22.60 | 28.53 | 21.20 | 38.72 | 25.27 | ||
| UAR | 29.70 | 40.66 | 34.80 | 42.40 | 52.96 | 61.53 | 33.00 | 45.95 | 22.70 | 39.10 | 40.28 | ||
| TAARE | 30.60 | 41.43 | 35.20 | 42.85 | 52.96 | 61.59 | 33.20 | 46.01 | 23.40 | 39.56 | 40.68 | ||
| \hdashlineOurs | DeepRAG-Imi | 35.10 | 46.59 | 47.20 | 52.33 | 50.47 | 59.55 | 43.60 | 48.50 | 30.00 | 41.76 | 45.38 | |
| DeepRAG | 40.70 | 51.54 | 48.10 | 53.25 | 52.96 | 61.92 | 42.50 | 47.80 | 32.70 | 45.24 | 47.67 | ||
| Qwen-2.5-7B | |||||||||||||
| Resaoning | CoT | 18.90 | 27.81 | 23.40 | 28.97 | 3.12 | 5.71 | 15.20 | 19.20 | 18.30 | 34.86 | 19.55 | |
| CoT-Retreive | 24.90 | 34.78 | 18.60 | 23.44 | 41.43 | 51.47 | 27.30 | 41.20 | 15.10 | 29.84 | 30.81 | ||
| CoT* | 17.60 | 26.15 | 25.10 | 29.62 | 3.12 | 5.62 | 7.90 | 11.06 | 15.60 | 32.45 | 17.42 | ||
| CoT-Retrieve* | 23.40 | 32.29 | 22.40 | 27.51 | 43.30 | 54.51 | 26.60 | 35.46 | 13.80 | 25.60 | 30.49 | ||
| IterDRAG | 13.70 | 26.84 | 9.30 | 20.47 | 21.81 | 39.59 | 18.00 | 31.44 | 12.50 | 26.95 | 22.06 | ||
| \hdashlineAdaptive | FLARE | 23.40 | 32.06 | 21.80 | 26.51 | 34.89 | 42.62 | 19.00 | 28.24 | 16.10 | 31.89 | 27.65 | |
| DRAGIN | 16.70 | 24.60 | 12.40 | 16.76 | 3.43 | 5.45 | 12.00 | 15.80 | 17.40 | 32.43 | 15.70 | ||
| UAR | 24.50 | 34.22 | 23.90 | 28.20 | 34.89 | 43.92 | 27.00 | 40.47 | 16.60 | 32.28 | 30.60 | ||
| TAARE | 25.30 | 35.03 | 21.30 | 25.67 | 40.81 | 50.78 | 27.00 | 40.92 | 18.20 | 33.14 | 31.81 | ||
| \hdashlineOurs | DeepRAG-Imi | 30.40 | 39.44 | 32.00 | 38.32 | 47.98 | 56.99 | 37.50 | 40.72 | 23.90 | 38.62 | 38.59 | |
| DeepRAG | 32.10 | 41.14 | 40.40 | 44.87 | 51.09 | 59.76 | 40.60 | 43.19 | 24.20 | 38.83 | 41.62 | ||
🔼 This table presents a comprehensive comparison of DeepRAG’s performance against several baseline models across five distinct question answering benchmarks. The benchmarks encompass diverse question types and complexities, allowing for a thorough evaluation of the model’s capabilities. DeepRAG’s performance is shown in two stages: DeepRAG-Imi (Stage I) represents the model’s performance after imitation learning, while DeepRAG (Stage II) incorporates the chain of calibration step. The table highlights the best and second-best scores for each metric (EM and F1) in each dataset. It demonstrates that DeepRAG significantly outperforms existing methods across all scenarios, showcasing improvements in both accuracy and retrieval efficiency.
read the caption
Table 1: The overall experimental results of DeepRAG and other baselines on five benchmarks. The best/second best scores in each dataset are bolded/underlined. DeepRAG-Imi (Stage I) and DeepRAG (Stage II) both demonstrate superior performance compared to existing methods across all test scenarios.
In-depth insights#
Adaptive RAG#
Adaptive Retrieval Augmented Generation (RAG) methods aim to improve the efficiency and effectiveness of traditional RAG by dynamically deciding when and how to retrieve external knowledge. Strategies vary, including classifier-based approaches that train models to predict retrieval needs, confidence-based methods that leverage uncertainty metrics, and LLM-based methods that utilize the generative capabilities of LLMs for decision-making. A key challenge lies in accurately determining knowledge boundaries, as inappropriate retrieval can introduce noise and reduce accuracy. Successful adaptive RAG systems must strike a balance between leveraging external knowledge and relying on the LLM’s internal capabilities, effectively navigating the trade-off between recall and precision. Furthermore, adaptive strategies should consider the specific query characteristics, the available knowledge sources, and the computational constraints, to optimize retrieval performance for varying contexts and information needs. The design of effective decision-making mechanisms remains a central area of ongoing research and development within this evolving field.
MDP for Retrieval#
Modeling retrieval as a Markov Decision Process (MDP) offers a powerful framework for optimizing information access in complex scenarios. The state space would represent the current query state, encompassing the initial question and any accumulated information. Actions would be choices like: retrieve information from an external source or attempt answering from existing knowledge. Reward functions would need careful design to balance retrieval efficiency against accuracy. A successful MDP approach would learn a policy to guide the retrieval process dynamically, leading to more efficient and accurate responses. Challenges involve designing a sufficiently rich yet manageable state and action space, as well as creating a reward function that appropriately incentivizes both retrieval accuracy and minimizing unnecessary retrieval actions. This necessitates careful consideration of computational costs and the trade-offs between potentially more accurate but expensive retrievals versus potentially less accurate, yet faster, responses based solely on existing knowledge. The effectiveness of such an MDP model ultimately hinges on the quality of the training data and the ability of the MDP algorithm to learn an optimal strategy that generalizes well to unseen situations.
Knowledge Boundary#
The concept of “Knowledge Boundary” in large language models (LLMs) is crucial. LLMs struggle to reliably distinguish between known and unknown information. This uncertainty leads to factual hallucinations and unreliable responses. The research highlights how this boundary problem significantly impacts Retrieval-Augmented Generation (RAG) systems. Ineffective knowledge boundary awareness results in inefficient retrieval, as the model may unnecessarily retrieve external knowledge even when the answer is readily available within its internal parameters. Conversely, failure to recognize knowledge limitations leads to hallucinations, since the model fabricates answers instead of admitting its lack of knowledge. DeepRAG directly addresses this by explicitly modeling the decision of whether to retrieve or rely on parametric reasoning as a key part of the process, allowing for a more strategic and effective approach to information seeking. This is a vital area of research as it directly impacts the reliability and trustworthiness of LLMs and RAG systems.
Chain of Calibration#
The “Chain of Calibration” section likely details a crucial refinement process in the DeepRAG model. It addresses the challenge of making accurate decisions about when to retrieve external information versus relying on the model’s internal knowledge. This is achieved by iteratively refining the model’s understanding of its own knowledge boundaries. The approach likely involves synthesizing data (e.g., preference pairs showing optimal retrieval choices), then using this data to fine-tune the model’s ability to distinguish between situations where retrieval is necessary and those where internal reasoning suffices. This calibration step is critical for improving both the accuracy and efficiency of the DeepRAG system. The process aims to reduce unnecessary retrievals, which can add computational cost and introduce noise, leading to improved performance and faster inference times. A key aspect is likely the use of a loss function to guide the calibration process, focusing on the model’s accurate estimation of when to utilize external knowledge versus its existing knowledge base. The result should be a more informed and adaptive RAG model.
Retrieval Efficiency#
Analyzing retrieval efficiency in a large language model (LLM) for question answering reveals crucial insights into its resource usage and performance. DeepRAG’s strategic approach, combining parametric reasoning and external knowledge retrieval, demonstrates significant improvements over existing methods. The core idea is to dynamically decide when to retrieve, minimizing unnecessary searches and enhancing efficiency. This adaptive strategy contrasts with baseline methods exhibiting inconsistent retrieval behaviors or excessive retrieval operations. DeepRAG’s ability to balance internal knowledge and external retrieval optimizes resource utilization, ultimately leading to higher accuracy with fewer retrieval attempts. This approach highlights the importance of a thoughtful balance between LLM’s inherent reasoning capabilities and external information access for efficient and accurate question answering.
More visual insights#
More on figures

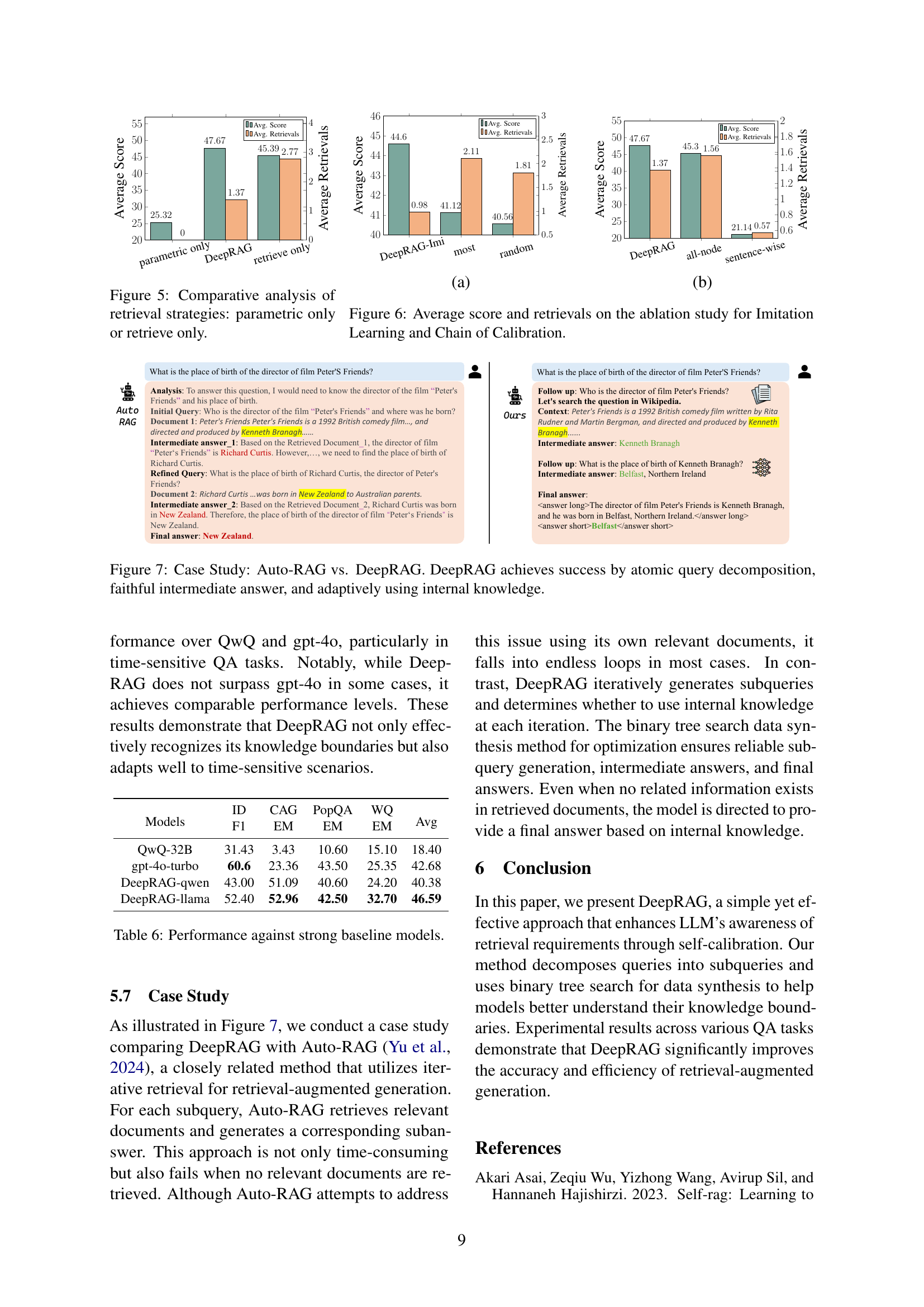
🔼 DeepRAG is composed of three stages: Binary Tree Search, Imitation Learning, and Chain of Calibration. First, a binary tree search method systematically explores different reasoning paths, combining retrieval and parametric knowledge. This generates training data that shows the model how to make decisions about when retrieval is necessary. Then, Imitation Learning uses this data to teach the model effective retrieval strategies. Finally, Chain of Calibration further refines the model’s ability to recognize its knowledge boundaries, leading to more accurate decisions about when to retrieve external information and improving the overall effectiveness of retrieval-augmented reasoning.
read the caption
Figure 2: An overview of DeepRAG, our framework comprises three steps: (1) Binary Tree Search, (2) Imitation Learning, and (3) Chain of Calibration. Given a dataset, we first employ binary tree search to synthesize data for imitation learning, enabling the model to learn retrieval patterns. Subsequently, we use binary tree search to construct preference data for further calibrating the LLM’s awareness of its knowledge boundaries.

🔼 This figure presents a visual representation of the distribution of subquery counts and retrieval attempts during the question-answering process using DeepRAG. Panel (a) shows the number of subqueries generated for each question, indicating the complexity of question decomposition. Panel (b) illustrates the number of retrieval attempts made for each question, reflecting the frequency of external knowledge retrieval within the DeepRAG framework. This visualization helps to understand the efficiency and the extent of knowledge base utilization within DeepRAG’s multi-step reasoning process.
read the caption
Figure 3: (a) Subquery Statistics. (b) Retrieval Statistics.
More on tables
| Dataset | Method | EM | Avg. Retrievals | ||
|---|---|---|---|---|---|
| All | Correct | Incorrect | |||
| 2WMQA | FLARE | 30.30 | 0.99 | 1.00 | 0.99 |
| DRAGIN | 29.10 | 1.03 | 1.03 | 1.03 | |
| UAR | 34.80 | 0.81 | 0.68 | 0.89 | |
| TAARE | 35.20 | 0.93 | 0.93 | 0.97 | |
| IterDRAG | 19.60 | 2.46 | 2.49 | 2.45 | |
| Auto-RAG | 23.00 | 6.26 | 4.13 | 1.81 | |
| DeepRAG-Imi | 47.20 | 1.13 | 0.95 | 1.28 | |
| DeepRAG | 48.10 | 1.09 | 0.92 | 1.25 | |
| WQ | FLARE | 28.80 | 0.00 | 0.00 | 0.00 |
| DRAGIN | 21.20 | 0.00 | 0.00 | 0.00 | |
| UAR | 22.70 | 0.96 | 0.95 | 0.97 | |
| TAARE | 23.40 | 0.66 | 0.65 | 0.66 | |
| IterDRAG | 15.90 | 2.25 | 2.16 | 2.27 | |
| Auto-RAG | 17.40 | 4.52 | 3.03 | 2.35 | |
| DeepRAG-Imi | 30.00 | 0.43 | 0.13 | 0.56 | |
| DeepRAG | 32.70 | 0.28 | 0.12 | 0.36 | |
🔼 This table presents a comparison of retrieval efficiency across various adaptive retrieval methods, specifically focusing on two datasets: 2WikiMultihopQA and WebQuestions. It shows the average number of retrieval attempts made by each method, broken down into two categories: instances where the model generated correct answers and instances with incorrect answers. This analysis highlights the trade-off between retrieval efficiency and accuracy for different approaches.
read the caption
Table 2: Retrieval frequency analysis on 2WikiMultihopQA(2WMQA) and WebQuestions(WQ) across different adaptive retrieval methods. 'Correct' indicates the average number of retrievals for instances where the model produced correct answers, while 'Incorrect' represents the average retrievals for cases with incorrect answers.
| Method | F1 | Acc | Balanced Acc | MCC |
|---|---|---|---|---|
| FLARE | 0.000 | 0.718 | 0.500 | 0.000 |
| DRAGIN | 0.007 | 0.709 | 0.495 | -0.045 |
| UAR | 0.481 | 0.756 | 0.648 | 0.341 |
| TAARE | 0.127 | 0.712 | 0.518 | 0.078 |
| Iter-DRAG | 0.000 | 0.718 | 0.500 | 0.000 |
| Auto-RAG | 0.000 | 0.718 | 0.500 | 0.000 |
| DeepRAG-Imi | 0.580 | 0.732 | 0.709 | 0.393 |
| DeepRAG | 0.621 | 0.749 | 0.743 | 0.451 |
🔼 This table presents a detailed analysis of how effectively different adaptive retrieval methods utilize a model’s internal knowledge before resorting to external retrieval. It compares the performance of various methods on the 2WikiMultihopQA dataset, focusing on metrics that assess not only accuracy (F1 score, Accuracy) but also the balance of correct predictions across classes (Balanced Accuracy) and the overall correlation between predicted and actual retrieval needs (Matthews Correlation Coefficient). The analysis aims to highlight which methods best identify when to leverage internal knowledge versus when external knowledge is necessary.
read the caption
Table 3: Analysis of internal knowledge utilization across different adaptive retrieval methods on 2WikiMultihopQA.
| Method | ID | CAG | PopQA | WebQuestion | Avg |
|---|---|---|---|---|---|
| F1 | EM | EM | EM | ||
| DeepRAG-Imi | 49.46 | 50.47 | 43.60 | 30.00 | 44.60 |
| most | 47.31 | 51.09 | 31.30 | 28.00 | 41.12 |
| random | 44.76 | 51.40 | 34.80 | 27.10 | 40.56 |
🔼 This table presents the results of an ablation study focusing on the Imitation Learning stage of the DeepRAG model. The study investigates the impact of different data synthesis strategies on the model’s performance. It compares the default DeepRAG approach with two alternative strategies: using data generated from paths with maximum retrieval cost and a random selection of paths. The table shows the average F1 scores and Exact Match (EM) scores for the in-distribution datasets HotpotQA and 2WikiMultihopQA (indicated as ‘ID’), and out-of-distribution datasets CAG, PopQA, and WebQuestions. This allows for evaluation of both in-distribution and out-of-distribution generalization capabilities of the model trained under different data generation strategies.
read the caption
Table 4: Experiment results of the ablation study on the Imitation Learning Stage. ID refers to the average score of two in-distribution dataset HotpotQA and 2WikiMultihopQA.
| Method | ID | CAG | PopQA | WebQuestion | Avg |
|---|---|---|---|---|---|
| F1 | EM | EM | EM | ||
| DeepRAG | 52.40 | 61.92 | 47.80 | 45.24 | 47.67 |
| all-node | 50.92 | 50.47 | 41.50 | 32.70 | 45.30 |
| sentence-wise | 30.16 | 12.46 | 20.00 | 12.90 | 21.14 |
🔼 This table presents the results of an ablation study focusing on the Chain of Calibration stage within the DeepRAG model. It compares the model’s performance using three different strategies for constructing preference data during the calibration phase: the default DeepRAG approach, a method using all nodes in the binary tree, and a method utilizing only sentence-level pairs. The performance is evaluated across multiple metrics on various datasets (HotpotQA, 2WMQA, CAG, PopQA, and WebQuestion) to assess the impact of the different calibration strategies on the model’s accuracy and retrieval efficiency. The metrics include F1 score and exact match (EM) on each dataset, along with an average score across all datasets.
read the caption
Table 5: Experiment results of the ablation study on the Chain of Calibration Stage.
| Models | ID | CAG | PopQA | WQ | Avg |
|---|---|---|---|---|---|
| F1 | EM | EM | EM | ||
| QwQ-32B | 31.43 | 3.43 | 10.60 | 15.10 | 18.40 |
| gpt-4o-turbo | 60.6 | 23.36 | 43.50 | 25.35 | 42.68 |
| DeepRAG-qwen | 43.00 | 51.09 | 40.60 | 24.20 | 40.38 |
| DeepRAG-llama | 52.40 | 52.96 | 42.50 | 32.70 | 46.59 |
🔼 This table presents a comparison of DeepRAG’s performance against two strong baseline large language models: QwQ-32B-preview and gpt-40-turbo. The comparison is done across five datasets: two in-distribution datasets (HotpotQA and 2WikiMultihopQA) used for training, and three out-of-distribution datasets (CAG, PopQA, and WebQuestions) used for evaluation. The results show the F1 score and Exact Match (EM) scores for each model on each dataset, as well as an average score across all datasets. This allows for an assessment of DeepRAG’s generalizability and performance relative to state-of-the-art models.
read the caption
Table 6: Performance against strong baseline models.
| HotpotQA | 2WMQA | CAG | PopQA | WebQuestion | Avg | |
|---|---|---|---|---|---|---|
| F1 | F1 | EM | EM | EM | ||
| DeepRAG-Imi | 46.59 | 52.33 | 50.47 | 43.60 | 30.00 | 44.60 |
| most | 47.73 | 46.88 | 51.09 | 31.30 | 28.00 | 41.12 |
| random | 46.78 | 42.75 | 51.40 | 34.80 | 27.10 | 40.56 |
🔼 This table presents a detailed breakdown of the ablation study conducted on the Imitation Learning stage of the DeepRAG model. It shows the performance (F1 score and Exact Match (EM) accuracy) achieved on five different datasets (HotpotQA, 2WikiMultihopQA, CAG, PopQA, and WebQuestions) when using three different strategies during the imitation learning process: the default strategy, a strategy that maximizes retrieval cost, and a random strategy. The results allow for a comparison of the effectiveness of the different strategies in learning to generate effective retrieval narratives.
read the caption
Table 7: Detailed Experiment results of the ablation study on the Imitation Learning Stage.
| HotpotQA | 2WMQA | CAG | PopQA | WebQuestion | Avg | |
|---|---|---|---|---|---|---|
| F1 | F1 | EM | EM | EM | ||
| DeepRAG | 51.54 | 53.25 | 61.92 | 47.80 | 45.24 | 47.67 |
| all-node | 49.99 | 51.85 | 50.47 | 41.50 | 32.70 | 45.30 |
| sentence-wise | 29.03 | 31.28 | 12.46 | 20.00 | 12.90 | 21.14 |
🔼 This table presents a detailed breakdown of the ablation study conducted on the Chain of Calibration stage within the DeepRAG model. It shows the impact of different calibration strategies on the model’s performance across multiple metrics and datasets. Specifically, it compares the performance of DeepRAG using the default calibration approach against two alternative methods: one that uses all nodes in the binary tree for calibration and another that uses sentence-level partial order pairs for calibration. The results help to illustrate the effectiveness of the chosen calibration strategy and its contribution to DeepRAG’s overall performance.
read the caption
Table 8: Detailed experiment results of the ablation study on the Chain of Calibration Stage.
Full paper#