TL;DR#
Current LLM benchmarks often focus on highly specialized knowledge, making them inaccessible to non-experts and obscuring potential weaknesses in general reasoning abilities. This paper introduces a novel benchmark based on the NPR Sunday Puzzle, a widely known challenge requiring only general knowledge but posing substantial difficulty for humans and machines alike. This allows for easier verification of answers and clear identification of model mistakes.
The new benchmark reveals significant performance differences between state-of-the-art LLMs, highlighting capabilities not evident in other tests. Furthermore, analysis unveils new kinds of model failures such as premature ‘give-up’ responses or generation of answers without sufficient reasoning. The researchers also investigated the effectiveness of extended reasoning, measuring improvement accuracy to identify optimal reasoning time for increased accuracy. This contribution provides valuable insights into current LLM limitations, paving the way for future research focusing on improving general reasoning abilities.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel benchmark for evaluating large language models’ reasoning capabilities using general knowledge puzzles. It identifies limitations of current models and suggests new research directions. This is crucial for improving LLMs and helps address the problem of creating unbiased and broadly accessible benchmarks.
Visual Insights#

🔼 The figure presents a bar chart comparing the accuracy of various large language models (LLMs) on the NPR Sunday Puzzle Challenge. The challenge uses general knowledge questions that are difficult even for humans to solve, but solutions are easily verifiable. The results highlight how these puzzles reveal performance differences between LLMs not apparent in benchmarks focusing on specialized, technical knowledge. Models like OpenAI’s 01 perform significantly better on these general knowledge puzzles compared to other models that achieve comparable performance on more technical benchmarks.
read the caption
Figure 1: We benchmark the latest reasoning models on the NPR Sunday Puzzle Challenge. The questions exercise general knowledge and are difficult for humans to solve, but the answers are easy to verify. These general knowledge puzzles show capability differences between reasoning models that are not evident from benchmarks that exercise deep technical knowledge.
In-depth insights#
Reasoning Benchmarks#
Reasoning benchmarks are crucial for evaluating large language models (LLMs), but current benchmarks often suffer from limitations. Many require specialized, high-level knowledge, making them inaccessible to non-experts and hindering broader evaluation. General knowledge benchmarks, like the one proposed using NPR’s Sunday Puzzle, offer a more inclusive and easier-to-verify assessment. These puzzles reveal model capabilities beyond specialized knowledge, uncovering new failure modes such as models prematurely giving up or exhibiting uncertainty. The focus should shift towards developing diverse and accessible benchmarks that can evaluate not only the accuracy but also the robustness and reasoning processes of LLMs. This will aid in advancing LLM research and development, ultimately leading to more reliable and versatile AI systems.
LLM Reasoning Gaps#
Large language models (LLMs), despite advancements, exhibit significant reasoning gaps. The research highlights that current benchmarks often focus on specialized, high-level knowledge, obscuring more fundamental limitations. A key finding is the discrepancy between LLMs’ performance on specialized knowledge tests versus general knowledge reasoning. Models like OpenAI’s 01 excel on niche tasks but struggle with common-sense reasoning problems, as demonstrated by the NPR Sunday Puzzle challenge. This suggests a need for more comprehensive benchmarks that evaluate a broader range of reasoning abilities. Furthermore, the analysis reveals novel failure modes, such as models prematurely conceding (‘giving up’) or producing answers they know to be incorrect. These shortcomings underscore the need for improved inference-time techniques to enhance the completion rate and accuracy of LLM reasoning. Finally, the research emphasizes the importance of evaluating the effectiveness of extended reasoning. While longer reasoning times can enhance accuracy, there’s a point of diminishing returns, highlighting the need for strategies to optimize reasoning efficiency.
Model Failure Modes#
Large language models (LLMs), while demonstrating impressive capabilities, are not without their flaws. Analyzing model failure modes reveals crucial insights into their limitations and potential areas for improvement. Arithmetic errors, even on simple calculations, highlight vulnerabilities in fundamental numerical processing. Hallucinations, where the model fabricates information, point to issues with fact verification and knowledge grounding. The tendency for models to ‘give up’ prematurely before exploring all potential solutions suggests limitations in their perseverance and search strategies. Further investigation reveals that models may sometimes violate constraints imposed by the problem, highlighting shortcomings in constraint satisfaction. Finally, the uncertain and vacillating nature of responses from some models, demonstrated through repeated revisions and contradictory claims, exposes inconsistencies in reasoning and a lack of confident conclusion-making. Addressing these failure modes is crucial for enhancing the robustness and reliability of LLMs.
Inference Time Limits#
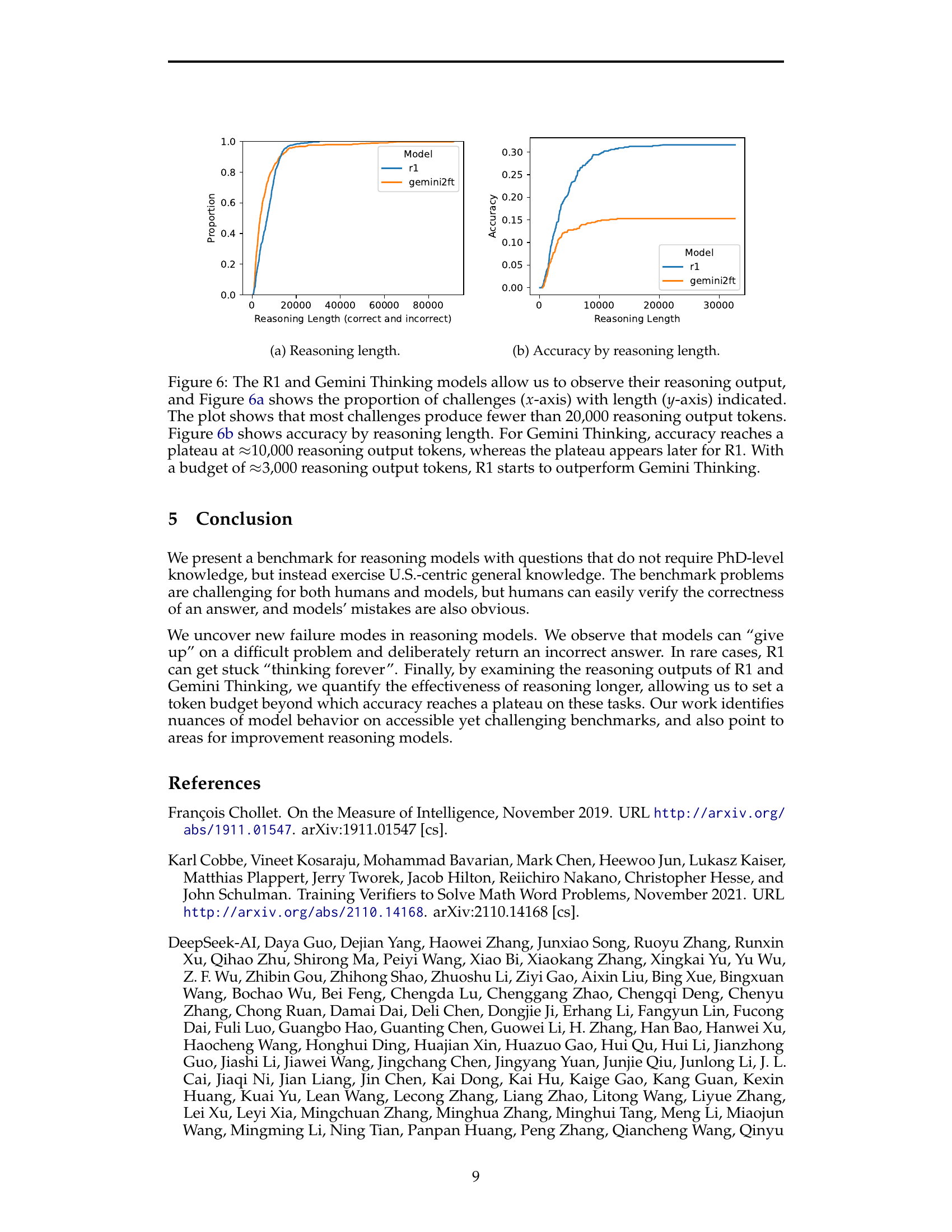
Inference time limits represent a critical constraint in large language model (LLM) reasoning. The research highlights how LLMs, particularly DeepSeek R1, frequently reach context window limits before completing their reasoning processes. This leads to premature answers or the model conceding, even when possessing the knowledge to solve the problem. The study proposes the need for inference-time techniques that can “wrap up” reasoning before context window exhaustion. This is crucial because extending reasoning beyond a certain point may not significantly improve accuracy, as demonstrated by analysis of R1 and Gemini Thinking’s performance. A key insight is that the optimal “reasoning budget” varies across models, with some reaching peak accuracy at lower token counts than others. The paper emphasizes the importance of understanding and managing inference time limits to better utilize LLMs and avoid incomplete or faulty solutions, ultimately improving overall reasoning capabilities.
General Knowledge Tests#
This research explores the limitations of current large language models (LLMs) by introducing general knowledge tests, specifically using the NPR Sunday Puzzle Challenge. The key innovation is shifting away from specialized, PhD-level knowledge benchmarks towards puzzles requiring common knowledge and reasoning abilities, making evaluation accessible to a wider audience. The study reveals significant performance disparities between LLMs, highlighting unexpected failure modes such as premature surrender or “giving up” before finding a solution. This approach provides a more nuanced understanding of LLM capabilities beyond highly specialized domains. The findings emphasize the need for improved inference-time techniques to enhance the effectiveness of reasoning within LLMs and the development of benchmarks that are challenging yet verifiable by non-experts. This methodology promotes a more comprehensive evaluation of LLMs by assessing their general reasoning skills in a readily interpretable manner.
More visual insights#
More on figures

🔼 The figure displays the final portion of DeepSeek R1’s output when attempting to solve Challenge 4.2 from the NPR Sunday Puzzle Challenge benchmark. It illustrates a failure mode where the model, despite extensive reasoning, ultimately fails to arrive at the correct answer, providing an incorrect response instead.
read the caption
Figure 2: The last few lines of R1’s output on Challenge 4.2.

🔼 Figure 3 displays the final portion of DeepSeek R1’s response to Challenge 4.2 from the NPR Sunday Puzzle Challenge benchmark. It showcases R1’s reasoning process leading up to its answer, revealing its uncertainty and tendency to explore multiple possibilities before concluding (or giving up). The example highlights R1’s potential for reaching an incorrect conclusion despite initially seeming on the right track. The figure illustrates a novel failure mode of reasoning models; getting stuck reasoning and arriving at a wrong answer.
read the caption
Figure 3: The last few lines of R1’s output on Challenge 4.2.
Full paper#