TL;DR#
Model-based reinforcement learning (MBRL) aims to improve sample efficiency by using a world model to plan actions, reducing the need for extensive real-world interactions. However, existing MBRL methods often struggle to generalize across different tasks and environments, limiting their practical applicability. This paper tackles these challenges by focusing on improving Transformer World Models (TWMs), a type of world model that leverages the power of transformers to process and understand complex information.
The researchers propose three key improvements to the standard MBRL framework using TWMs: a more efficient training scheme called “Dyna with warmup”, a novel image tokenization method using nearest neighbor search that simplifies the representation of visual inputs, and a modified training process called “block teacher forcing” that improves the quality of imagined trajectories. These innovations are combined with improvements to a model-free baseline, resulting in an MBRL algorithm that outperforms existing methods by a significant margin on the challenging Craftax-classic benchmark, even surpassing the performance of human players.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances model-based reinforcement learning (MBRL), a crucial area in AI research. The improved sample efficiency of the proposed MBRL algorithm is highly relevant to current trends seeking more data-efficient AI systems. The work also introduces novel techniques like the nearest neighbor tokenizer, which are valuable contributions to the field, opening up new research paths in world modeling and data representation. The substantial performance improvement on the challenging Crafter benchmark highlights the practical applicability of the developed techniques, demonstrating their potential to tackle complex real-world scenarios.
Visual Insights#

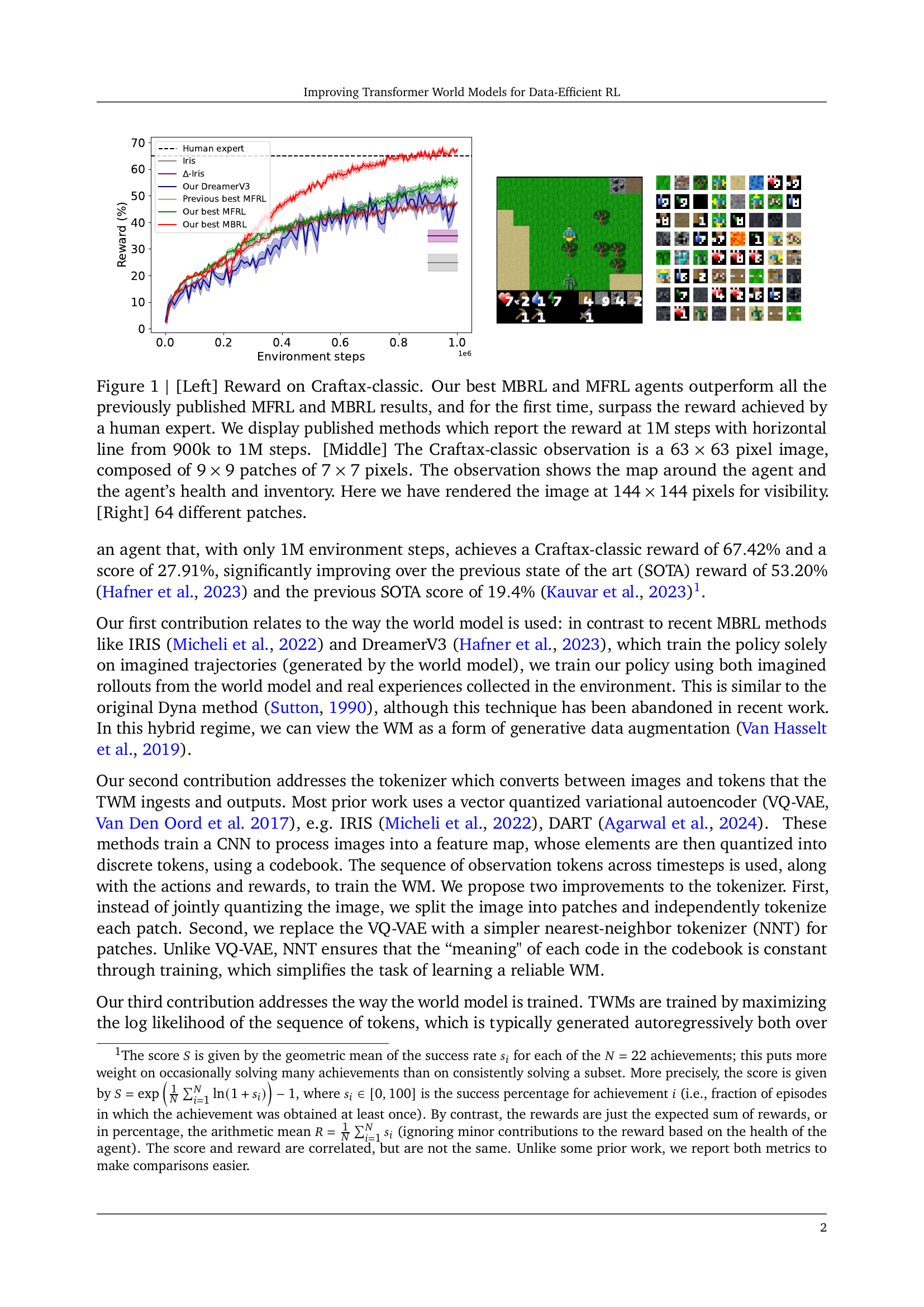
🔼 Figure 1 presents a comprehensive overview of the experimental results and the environment used in the study. The left panel shows a reward curve for various model-based reinforcement learning (MBRL) and model-free reinforcement learning (MFRL) algorithms on the Craftax-classic benchmark. The plot demonstrates that the proposed MBRL and MFRL agents surpass previously published results, achieving a reward exceeding human-level performance for the first time. The middle panel provides a visual representation of the Craftax-classic observation space. The agent’s observation consists of a 63x63 pixel image partitioned into 9x9 patches of 7x7 pixels, representing the agent’s vicinity and also including information about the agent’s inventory and health. The provided image has been upscaled to 144x144 pixels for clarity. The right panel displays 64 distinct image patches illustrating the variety of visual elements within the observation space. This figure thus effectively summarizes the key aspects of the environment, the performance of the proposed agents, and the data used for training.
read the caption
Figure 1: [Left] Reward on Craftax-classic. Our best MBRL and MFRL agents outperform all the previously published MFRL and MBRL results, and for the first time, surpass the reward achieved by a human expert. We display published methods which report the reward at 1M steps with horizontal line from 900k to 1M steps. [Middle] The Craftax-classic observation is a 63×63636363\times 6363 × 63 pixel image, composed of 9×9999\times 99 × 9 patches of 7×7777\times 77 × 7 pixels. The observation shows the map around the agent and the agent’s health and inventory. Here we have rendered the image at 144×144144144144\times 144144 × 144 pixels for visibility. [Right] 64646464 different patches.
 |
🔼 This table presents a comparison of the performance of various reinforcement learning (RL) agents on the Craftax-classic benchmark after 1 million environment interactions. The table includes the reward (percentage), score (percentage), and training time (in minutes) for each agent. It compares the performance of the authors’ best model-free RL (MFRL) and model-based RL (MBRL) agents to previously published results, highlighting the superiority of the authors’ approaches. Note that some results are from the Crafter environment, which is similar to but may not be exactly the same as Craftax-classic, and that training times are reported for a single A100 GPU. Differences between the reported and published DreamerV3 results are acknowledged, possibly due to hyperparameter variations, and the absence of standard error data for scores in IRIS and A-IRIS results is also noted.
read the caption
Table 1: Results on Craftax-classic after 1M environment interactions. * denotes results on Crafter, which may not exactly match Craftax-classic. — means unknown. †denotes the reported timings on a single A100 GPU. Our DreamerV3 results are based on the code from the author, but differ slightly from the reported number, perhaps due to hyperparameter discrepancies. IRIS and ΔΔ\Deltaroman_Δ-IRIS do not report standard errors for the score.
In-depth insights#
Data-Efficient RL#
The research paper explores data-efficient reinforcement learning (RL), a crucial area due to the massive data requirements of traditional RL methods. Model-based RL (MBRL) is highlighted as a key approach, aiming to reduce data needs by learning a world model (WM) to simulate the environment. The paper focuses on improving transformer-based WMs, specifically, their utilization, tokenization, and training. Sample efficiency improvements are presented, including a novel approach that combines real and imagined data (
Transformer WM#
The core of the presented model-based reinforcement learning (MBRL) approach centers around a Transformer World Model (TWM). This TWM leverages the power of transformer networks to effectively learn a generative model of the environment’s dynamics, enabling the agent to plan actions within an imagined environment. A key innovation is the utilization of a nearest-neighbor tokenizer for processing image patches as input, unlike previous methods relying on computationally expensive Vector Quantized Variational Autoencoders (VQ-VAEs). This novel technique contributes to a more stable and efficient TWM training process. Furthermore, the introduction of block teacher forcing, which allows the TWM to reason jointly about the future tokens of the next timestep, significantly enhances its predictive accuracy and enables faster training. The combination of the nearest-neighbor tokenizer and block teacher forcing, coupled with a Dyna-style training approach, leads to significant improvements in sample efficiency and overall performance, surpassing even human-level performance on the challenging Craftax-classic benchmark.
Dyna with Warmup#
The proposed “Dyna with Warmup” approach represents a hybrid model-based reinforcement learning (MBRL) strategy that cleverly combines the strengths of both model-free and model-based methods. Unlike purely model-based approaches that solely rely on imagined trajectories from a world model for training, Dyna with Warmup leverages both real experiences collected from the environment and imagined rollouts generated by the world model. This hybrid approach enhances sample efficiency and improves generalization, by providing the agent with a diverse range of training data. The “warmup” phase is a crucial aspect of this strategy, which gradually introduces imagined experiences only after the agent has collected sufficient real-world data. This cautious approach ensures the world model’s accuracy before relying on its predictions to guide the learning process, preventing the potential pitfalls of relying on inaccurate model estimations, particularly during initial stages of training. By combining real and imaginary data, Dyna with Warmup strikes a balance between exploration and exploitation, thus leading to improved data efficiency and superior performance.
Tokenizer Enhancements#
Tokenizer enhancements are crucial for efficient and effective model-based reinforcement learning (MBRL). The paper explores this by splitting the image into patches and tokenizing them independently. This approach allows the model to focus on local features, improving the learning process. The authors then replace the vector quantized variational autoencoder (VQ-VAE) with a simpler nearest-neighbor tokenizer (NNT). This substitution significantly simplifies the training process, leading to a more reliable world model and ultimately boosting performance. The benefits of using a static codebook with NNT, unlike the dynamically updating VQ-VAE, are also highlighted. This leads to a more stable learning environment, enhancing the reliability of the transformer world model and resulting in superior agent performance in the Craftax-classic environment.
Future Work#
The authors thoughtfully lay out several promising avenues for future research. Prioritized experience replay is highlighted as a potential method to accelerate the training of the Transformer World Model (TWM), a crucial component of their model-based reinforcement learning approach. They also suggest that an off-policy RL algorithm could enhance policy updates by effectively integrating both real and imaginary data. A particularly interesting direction involves generalizing the tokenizer to leverage large pre-trained models like SAM and Dino-V2. This could improve robustness by inheriting stable codebooks while reducing sensitivity to patch size and superficial appearance variations. Finally, they propose modifying the policy to directly accept latent tokens generated by the TWM, expanding the scope beyond reconstructive world models and enabling exploration of non-reconstructive models. This last point is especially significant, opening the door to a wider range of potential world model architectures.
More visual insights#
More on figures

🔼 Figure 2 illustrates two different approaches to training a Transformer World Model (TWM). The TWM takes a sequence of image tokens as input and predicts future tokens. The figure focuses on a simplified scenario with only two timesteps (T=2) and two tokens per timestep (L=2). Each token represents a patch of the input image. The left panel shows the standard autoregressive approach with teacher forcing, where the model predicts tokens sequentially, using previously predicted tokens as context. The right panel presents the block teacher forcing approach. In this method, all tokens for the next timestep are predicted simultaneously (in a block) using only the past timesteps’ tokens as context. The use of block causal attention allows the model to consider the relationships between all tokens in the next timestep before making any predictions. This is in contrast to the autoregressive approach which predicts tokens one at a time and only uses the already generated tokens from that timestep. The color-coding in the figure visually highlights the tokens belonging to the same timestep.
read the caption
Figure 2: Approaches for TWM training with L=2𝐿2L=2italic_L = 2, T=2𝑇2T=2italic_T = 2. qtℓsuperscriptsubscript𝑞𝑡ℓq_{t}^{\ell}italic_q start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_ℓ end_POSTSUPERSCRIPT denotes token ℓℓ\ellroman_ℓ of timestep t𝑡titalic_t. Tokens in the same timestep have the same color. We exclude action tokens for simplicity. [Left] Usual autoregressive model training with teacher forcing. [Right] Block teacher forcing predicts token qt+1ℓsuperscriptsubscript𝑞𝑡1ℓq_{t+1}^{\ell}italic_q start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_ℓ end_POSTSUPERSCRIPT from input token qtℓsuperscriptsubscript𝑞𝑡ℓq_{t}^{\ell}italic_q start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_ℓ end_POSTSUPERSCRIPT with block causal attention.

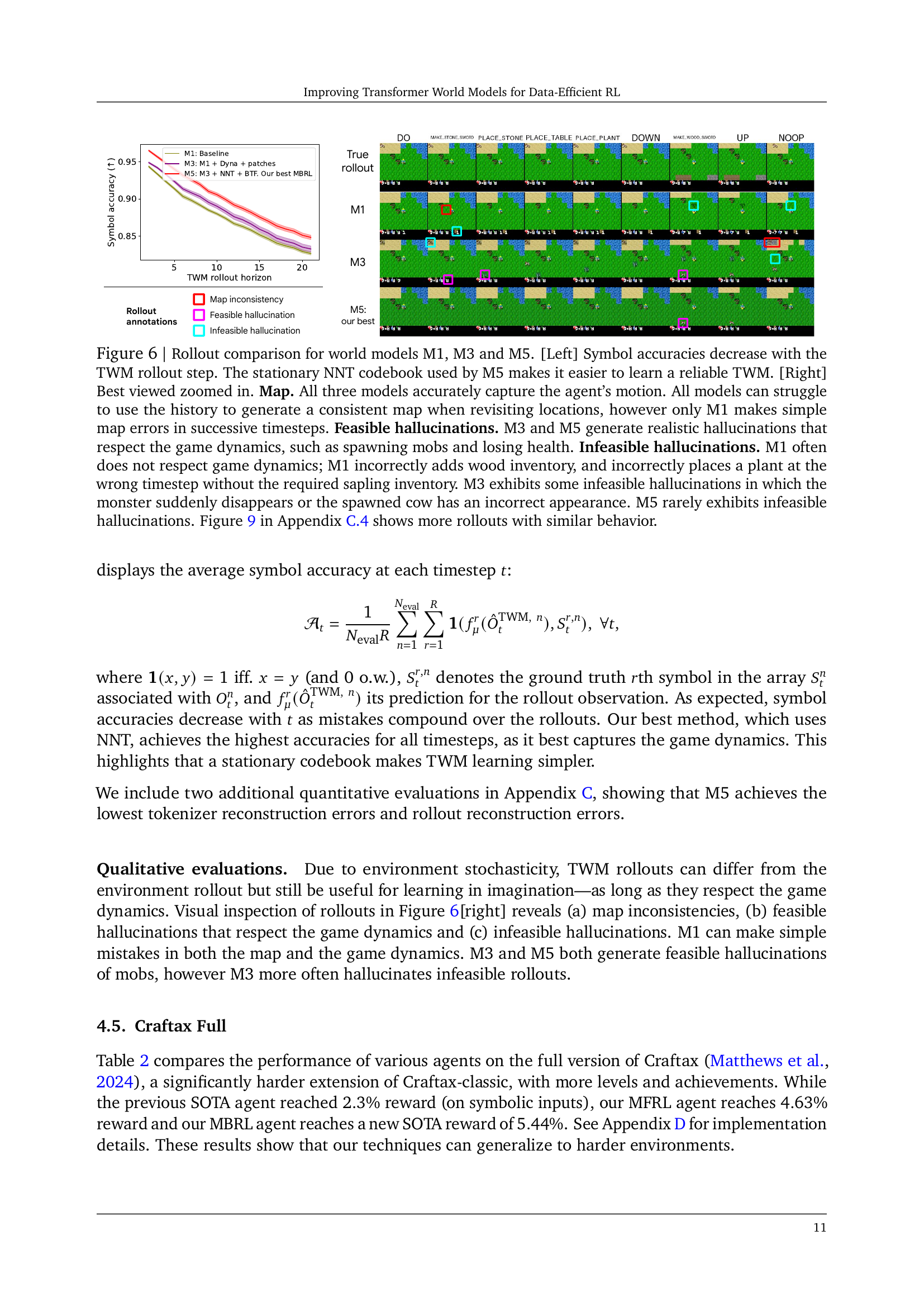
🔼 This figure shows the performance of different model-based reinforcement learning (MBRL) agents on the Craftax-classic environment. It demonstrates a series of improvements to a baseline MBRL agent, showing how each improvement cumulatively leads to better performance. Each line represents a different version of the agent, with the final model achieving state-of-the-art results. The dotted vertical line highlights the point (200k environment steps) at which the model starts training using imagined trajectories generated by a world model, rather than relying solely on real experience. This illustrates the contribution of the model-based component to improved sample efficiency.
read the caption
Figure 3: The ladder of improvements presented in Section 3 progressively transforms our baseline MBRL agent into a state-of-the-art method on Craftax-classic. Training in imagination starts at step 200k, indicated by the dotted vertical line.

🔼 This ablation study investigates the impact of various components of the proposed model-based reinforcement learning (MBRL) approach on the Craftax-classic benchmark. It measures the reward achieved after 1 million environment interactions, showing the effect of removing key elements such as Dyna (background planning), the nearest-neighbor tokenizer (NNT), and block teacher forcing (BTF). The experiment also examines the sensitivity of the NNT to patch sizes and the importance of quantization for the 7x7 patches. The results highlight the contributions of each component to the overall performance and demonstrate the necessity of these improvements for achieving state-of-the-art results.
read the caption
Figure 4: Ablations results on Craftax-classic after 1M environment interactions.

🔼 Figure 5 presents an ablation study to analyze the impact of different components of the proposed MBRL approach on its performance. The left panel shows that while using patches of different sizes with the nearest-neighbor tokenizer (NNT) maintains competitive performance, not quantizing the patches causes a significant drop in performance. The middle panel demonstrates that each improvement in the ’ladder of improvements’ significantly contributes to the overall performance, highlighting the cumulative effect of each component. The right panel illustrates the importance of warming up the world model before starting background planning, preventing the model from negatively affecting the learning of the policy.
read the caption
Figure 5: [Left] MBRL performance decreases when NNT uses patches of smaller or larger size than the ground truth, but it remains competitive. However, performance collapses if the patches are not quantized. [Middle] Removing any rung of the ladder of improvements leads to a drop in performance. [Right] Warming up the world model before using it to train the policy on imaginary rollouts is required for good performance. BP denotes background planning. For each method, training in imagination starts at the color-coded vertical line, and leads to an initial drop in performance.
More on tables
 |
🔼 This table presents a comparison of the performance of different reinforcement learning agents on the Craftax environment after 1 million environment interactions. The key distinction is that the previous state-of-the-art (SOTA) agent used symbolic input, whereas the agents evaluated in this study used image inputs. The table displays the reward and score achieved by each agent. Note that the score metric for the previous SOTA is unavailable because it used symbolic inputs.
read the caption
Table 2: Results on Craftax after 1M environment interactions. The previous SOTA reward uses symbolic input (score is unknown), whereas our results use image input.
 |
🔼 This table lists the hyperparameters used for training the model-free reinforcement learning (MFRL) agent. It details settings for the environment, such as the number of environments and the rollout horizon, and architectural choices regarding the sizes of different components like the CNN output, RNN hidden layer, and actor-critic (AC) network layers. Additionally, it specifies parameters for the Proximal Policy Optimization (PPO) algorithm, including those related to the optimization procedure (learning rate, gradient clipping), and those controlling the exploration-exploitation balance (entropy coefficient, discount factor).
read the caption
Table 3: MFRL hyperpameters.
 |
🔼 This table lists the hyperparameters used for training the transformer world model, a key component of the model-based reinforcement learning (MBRL) agent. It details settings for the model architecture (embedding dimension, number of layers and heads, type of attention mask), and training process (optimizer, learning rate, dropout rates). These parameters influence the model’s capacity, computational cost, and generalization ability, impacting the quality of imagined trajectories it generates for planning.
read the caption
Table 4: Hyperparameters for the transformer world model.
 |
🔼 This table lists the main hyperparameters used in the model-based reinforcement learning (MBRL) training pipeline. It details the settings for environment interaction (number of environments, rollout horizons), world model training (number of updates, minibatch size), and policy updates (number of updates, epochs, etc.). This information is crucial for understanding the experimental setup and reproducibility of the results.
read the caption
Table 5: MBRL main parameters.
| Method | Parameters | Reward (%) | Score (%) | Time (min) |
| Human Expert | NA | NA | ||
| M1: Baseline | ||||
| M2: M1 + Dyna | M | |||
| M3: M2 + patches | M | |||
| M4: M3 + NNT | M | |||
| M5: M4 + BTF. Our best MBRL | M | |||
| Previous best MFRL (Moon et al., 2024) | — | |||
| Previous best MFRL (our implementation) | ||||
| Our best MFRL | M | |||
| DreamerV3 (Hafner et al., 2023) | M | — | ||
| Our DreamerV3 | M | — | ||
| IRIS (Micheli et al., 2022) | M | † | ||
| -IRIS (Micheli et al., 2024) | 25M | † | ||
| Curious Replay (Kauvar et al., 2023) | — | — | —- |
🔼 This table compares the environment parameters of two game environments: Craftax-classic and Craftax (full). It contrasts various aspects such as image size, patch size, grid size, action space size, maximum reward, and symbolic input size. It also details the MFRL and MBRL parameters used in experiments conducted within each environment. Noteworthy differences highlight that Craftax (full) significantly expands on Craftax-classic in terms of complexity and scale.
read the caption
Table 6: Environment Craftax-classic vs Craftax (full).
Full paper#